
火山引擎向量数据库 Milvus 版在近日正式发布了云上 Milvus 2.6 版本,提供一系列托管能力,同时完全兼容开源 Milvus 2.6 版本。这次版本升级是为了给企业级的用户提供一个在性能、成本和稳定性上都达到新高度的 AI 应用基础设施。
相比于 2.5 版本,火山引擎 Milvus 2.6 版本通过引入流批分离架构、冷热分层存储(Tiered Storage)、RaBitQ 1-bit 量化技术以及多项检索能力增强,使用户在构建大规模、高性能的 AI 应用的时候,能够以更低的成本获得更快的响应速度和更稳定的运维体验。
核心升级亮点:更快、更省、更稳
Milvus 作为主流的向量数据库,当前最紧迫的挑战是如何在有效控制成本的同时,还可以实现高效规模化。而此次 Milvus 2.6 大版本通过一系列架构和能力的更新,将能够更好的解决这些问题。所以火山引擎向量数据库 Milvus 版迅速的跟进了此次版本升级,将这些新能力以全托管服务的形式,更好的提供给云上用户。
- 更快: 通过对 BM25 全文检索和 JSON Path 索引的深度优化,在特定场景下的检索性能远超从前。
- 更省: 全新的 RaBitQ 1-bit 量化技术与冷热分层存储是本次升级的两大降本"杀手锏"。RaBitQ 1-bit 量化技术在保持高召回准确率的同时,还能凭借1比特压缩技术实现资源与性能上的优化;分层存储还可以在典型场景下降低最高 80% 的本地资源与成本。
- 更稳: 架构演进带来了更高的稳定性。Milvus 2.6 引入 Streaming Node 实现流批分离,并通过合并协调器(MixCoord)、移除 Index Node 等方式简化了架构,显著提升了系统在负载、滚动更新、故障恢复这些场景下的可控性与可维护性。
Milvus 2.6 vs 2.5:一次深刻的进化
Milvus 2.6 版本的升级并非简单的功能叠加,相较于 Milvus 2.5 版本,它是一次深刻的架构性进化。这些变化对于用户而言,可以带来显著的价值。
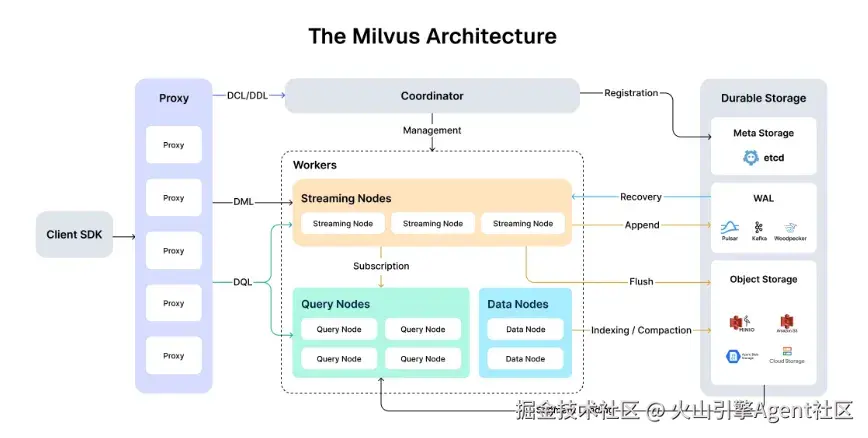
Milvus 2.6 版本架构图
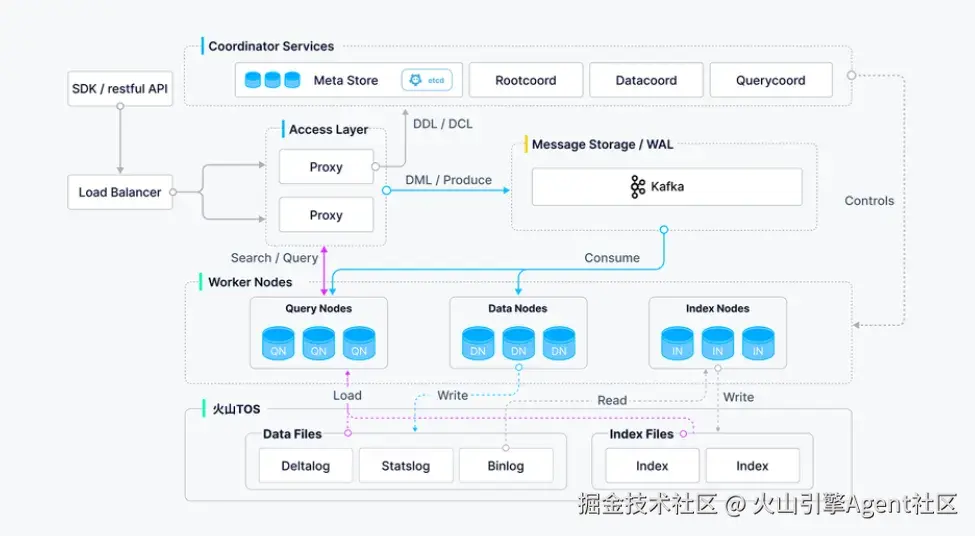
Milvus 2.5 版本架构图
架构:从耦合到分离
在Milvus 2.5 架构中,流处理与批处理任务在多个组件中存在的耦合问题增加了系统复杂度和运维难度。所以Milvus 2.6 引入了独立的 Streaming Node,可以专门处理实时数据流的消费、写入与即时查询,这也使得 Data Node 和 Query Node 能更专注于历史数据的批处理任务。这种流批分离的设计,不仅让架构更清晰,也为系统的横向扩展和故障恢复能力奠定了坚实基础。
成本:从全量加载到智能分层
Milvus 2.5 采用"全量加载"模型,也就是说无论数据访问频率高低,都需要将整个 Collection 加载至本地,因而导致资源成本高昂。而 Milvus 2.6 的 Tiered Storage(冷热分层存储)彻底改变了这一模式,通过"懒加载"与"局部加载"机制,使得使用者只有在查询需要时才将冷数据从对象存储拉取至本地缓存。
能力:从单一到融合
Milvus 2.6 在检索能力上实现了多维度增强。除了对 BM25 全文检索的性能优化,还引入了 JSON Path索引 ,使得对复杂元数据的过滤查询效率提升近百倍。除此之外,Data-in, Data-out 能力也让用户可以直接在数据库侧完成从文本到向量的转换,很大程度上简化了 AI 应用的开发流程。
火山引擎全托管服务:释放 Milvus 2.6 全部潜力
作为一款云上完全托管的服务,火山引擎向量数据库 Milvus 版致力于让用户摆脱繁琐的底层运维,从而专注于业务创新,它结合了 Milvus 2.6 的强大功能,提供了覆盖实例全生命周期的企业级能力:
- 开箱即用,全面兼容: 火山 Milvus 2.6 完全兼容开源 Milvus 生态,用户可以一键创建Milvus实例,也可通过火山引擎数据传输服务(DTS)从自建 Milvus 平滑迁移上火山引擎。提供可视化的参数配置、监控告警、快照备份与恢复、数据迁移工作流等一体化管理工具。
- 企业级高可用: 提供高可用多节点部署模式,服务节点与计算节点均可独立水平扩展,并已原生适配 Milvus 2.6 的 Streaming Node 架构,保障业务连续性。
- 最佳实践沉淀: 整合了 DiskANN + RaBitQ 等业界领先的索引与量化方案,并提供 API Playground 与丰富的最佳实践文档,帮助用户快速构建高质量的 RAG、多模态检索等 AI 应用。
- 灵活的部署选项: 目前已经在北京、上海、广州等多个城市提供服务,支持 Dedicated 和 Serverless 两种售卖形态,从而满足不同规模和弹性的业务需求。
典型场景与客户收益
- RAG 与智能知识库: 通过 Milvus 2.6 Data-in, Data-out 的 Embedding 能力与全文检索增强,企业可以更便捷地构建实时更新、精准应答的智能客服或内部知识库。
- 多模态推荐系统: 借助更高效的向量检索与丰富的数据类型支持(如地理空间、Array-of-Structs),电商、内容等平台在进行个性化推荐的时候,可以很好的提升精准度。
- AI Agent 与复杂应用: 流批分离架构可以给那些需要高吞吐、实时写入的 AI Agent 应用提供稳定的支撑,另外成本的大幅降低也可以让更大规模的向量应用成为可能。
立即体验
火山引擎向量数据库 Milvus 版现已正式支持 Milvus 2.6版本。我们诚邀您体验新一代向量数据库带来的极致性能与成本效益。您可以点击【阅读原文】访问火山引擎官网,申请免费试用或联系您的客户经理:www.volcengine.com/product/mil... AI 应用创新之旅。
火山引擎向量数据库 Milvus 版在近日正式发布了云上 Milvus 2.6 版本,提供一系列托管能力,同时完全兼容开源 Milvus 2.6 版本。这次版本升级是为了给企业级的用户提供一个在性能、成本和稳定性上都达到新高度的 AI 应用基础设施。
相比于 2.5 版本,火山引擎 Milvus 2.6 版本通过引入流批分离架构、冷热分层存储(Tiered Storage)、RaBitQ 1-bit 量化技术以及多项检索能力增强,使用户在构建大规模、高性能的 AI 应用的时候,能够以更低的成本获得更快的响应速度和更稳定的运维体验。
核心升级亮点:更快、更省、更稳
Milvus 作为主流的向量数据库,当前最紧迫的挑战是如何在有效控制成本的同时,还可以实现高效规模化。而此次 Milvus 2.6 大版本通过一系列架构和能力的更新,将能够更好的解决这些问题。所以火山引擎向量数据库 Milvus 版迅速的跟进了此次版本升级,将这些新能力以全托管服务的形式,更好的提供给云上用户。
- 更快: 通过对 BM25 全文检索和 JSON Path 索引的深度优化,在特定场景下的检索性能远超从前。
- 更省: 全新的 RaBitQ 1-bit 量化技术与冷热分层存储是本次升级的两大降本"杀手锏"。RaBitQ 1-bit 量化技术在保持高召回准确率的同时,还能凭借1比特压缩技术实现资源与性能上的优化;分层存储还可以在典型场景下降低最高 80% 的本地资源与成本。
- 更稳: 架构演进带来了更高的稳定性。Milvus 2.6 引入 Streaming Node 实现流批分离,并通过合并协调器(MixCoord)、移除 Index Node 等方式简化了架构,显著提升了系统在负载、滚动更新、故障恢复这些场景下的可控性与可维护性。
Milvus 2.6 vs 2.5:一次深刻的进化
Milvus 2.6 版本的升级并非简单的功能叠加,相较于 Milvus 2.5 版本,它是一次深刻的架构性进化。这些变化对于用户而言,可以带来显著的价值。
Milvus 2.6 版本架构图
Milvus 2.5 版本架构图
架构:从耦合到分离
在Milvus 2.5 架构中,流处理与批处理任务在多个组件中存在的耦合问题增加了系统复杂度和运维难度。所以Milvus 2.6 引入了独立的 Streaming Node,可以专门处理实时数据流的消费、写入与即时查询,这也使得 Data Node 和 Query Node 能更专注于历史数据的批处理任务。这种流批分离的设计,不仅让架构更清晰,也为系统的横向扩展和故障恢复能力奠定了坚实基础。
成本:从全量加载到智能分层
Milvus 2.5 采用"全量加载"模型,也就是说无论数据访问频率高低,都需要将整个 Collection 加载至本地,因而导致资源成本高昂。而 Milvus 2.6 的 Tiered Storage(冷热分层存储)彻底改变了这一模式,通过"懒加载"与"局部加载"机制,使得使用者只有在查询需要时才将冷数据从对象存储拉取至本地缓存。
能力:从单一到融合
Milvus 2.6 在检索能力上实现了多维度增强。除了对 BM25 全文检索的性能优化,还引入了 JSON Path索引 ,使得对复杂元数据的过滤查询效率提升近百倍。除此之外,Data-in, Data-out 能力也让用户可以直接在数据库侧完成从文本到向量的转换,很大程度上简化了 AI 应用的开发流程。
火山引擎全托管服务:释放 Milvus 2.6 全部潜力
作为一款云上完全托管的服务,火山引擎向量数据库 Milvus 版致力于让用户摆脱繁琐的底层运维,从而专注于业务创新,它结合了 Milvus 2.6 的强大功能,提供了覆盖实例全生命周期的企业级能力:
- 开箱即用,全面兼容: 火山 Milvus 2.6 完全兼容开源 Milvus 生态,用户可以一键创建Milvus实例,也可通过火山引擎数据传输服务(DTS)从自建 Milvus 平滑迁移上火山引擎。提供可视化的参数配置、监控告警、快照备份与恢复、数据迁移工作流等一体化管理工具。
- 企业级高可用: 提供高可用多节点部署模式,服务节点与计算节点均可独立水平扩展,并已原生适配 Milvus 2.6 的 Streaming Node 架构,保障业务连续性。
- 最佳实践沉淀: 整合了 DiskANN + RaBitQ 等业界领先的索引与量化方案,并提供 API Playground 与丰富的最佳实践文档,帮助用户快速构建高质量的 RAG、多模态检索等 AI 应用。
- 灵活的部署选项: 目前已经在北京、上海、广州等多个城市提供服务,支持 Dedicated 和 Serverless 两种售卖形态,从而满足不同规模和弹性的业务需求。
典型场景与客户收益
- RAG 与智能知识库: 通过 Milvus 2.6 Data-in, Data-out 的 Embedding 能力与全文检索增强,企业可以更便捷地构建实时更新、精准应答的智能客服或内部知识库。
- 多模态推荐系统: 借助更高效的向量检索与丰富的数据类型支持(如地理空间、Array-of-Structs),电商、内容等平台在进行个性化推荐的时候,可以很好的提升精准度。
- AI Agent 与复杂应用: 流批分离架构可以给那些需要高吞吐、实时写入的 AI Agent 应用提供稳定的支撑,另外成本的大幅降低也可以让更大规模的向量应用成为可能。
立即体验
火山引擎向量数据库 Milvus 版现已正式支持 Milvus 2.6版本。我们诚邀您体验新一代向量数据库带来的极致性能与成本效益。您可以点击【阅读原文】访问火山引擎官网,申请免费试用或联系您的客户经理:www.volcengine.com/product/mil... AI 应用创新之旅。