既然大家对于图片是怎么识别,有所了解,那么声音又是怎么识别的?(▽)?毕竟它可不想图片一样那么容易描述
如果你去听一段录音,你听到的是高低起伏的音调。
但如果你把这段录音喂给 AI,它首先会启动一个名为 MFCC 的"翻译官"。
1. MFCC:声音的"素描师"
MFCC(梅尔频率倒谱系数) 并不是深度学习模型,而是一个经典的信号处理算法。它的任务是把看不见摸不着的声波,转换成一张**"声音指纹图"**。
- 第一步:分帧。 声音太快了,AI 反应不过来。MFCC 会把声音像切香肠一样,切成一个个极短的时间片(比如 25 毫秒)。
- 第二步:频率分析。 对每个时间片进行"扫描",看看里面包含哪些频率(高音还是低音)。
- 第三步:模拟人耳。 这是最聪明的一步。人耳对低频的变化很敏感,对高频很迟钝。MFCC 会模仿人耳的这种"偏见",过滤掉那些没用的高频杂音,强化重要的特征。
最终产物: 一张纵轴是"频率"、横轴是"时间"、颜色深度代表"能量"的声谱图。
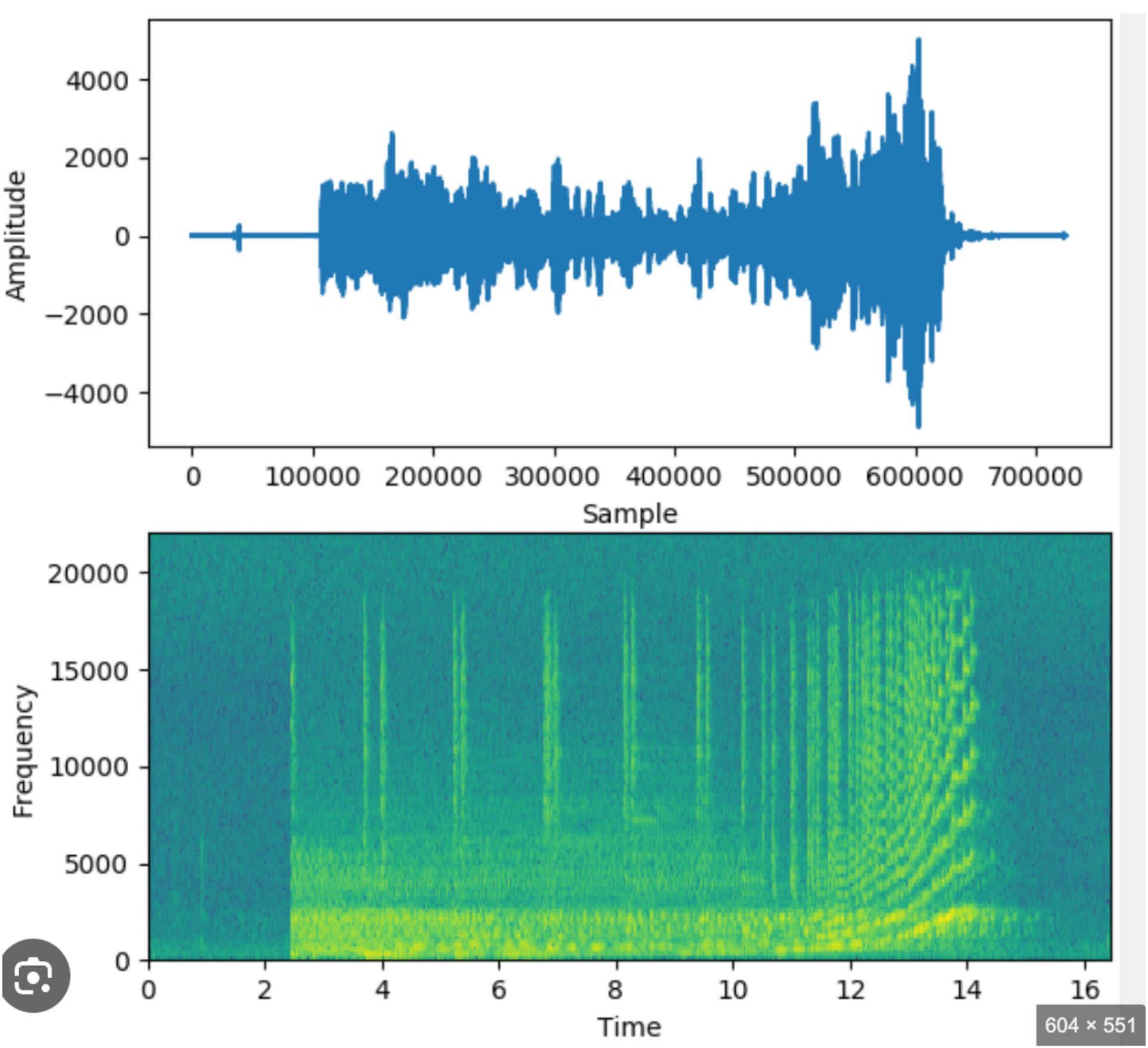
2. 把声谱图拿给CNN进行特征提取
一旦声音变成了这张图,我们第二篇讲到的 CNN 就可以大显身手了!
- 纹理识别: 在声谱图上,不同的发音有不同的纹理。
- 比如元音(如"啊")会有几条平行的横杠(共振峰)。
- 比如爆破音(如"啪")会像是一道突然出现的垂直闪电。
- 空间相关性: 声音在时间上是连续的。CNN 的蓝色方块(卷积层)通过扫描这张图,可以轻易地把相邻的时间片段组合在一起,识别出一个完整的音节。
3. 总结:跨界的智慧
在深度学习的世界里,并没有所谓的"视觉模型"或"听觉模型"之分。
- 只要你能把数据转换成具备局部相关性的矩阵(图);
- 你就能用堆叠隐层的方法去提取它的高层特征。
📢 下集预告:
我们已经看过了 AI 如何"看图",也看过了 AI 如何将声音转化成图来"听音"。你可能会发现,不管是图片、声音还是脑电波,AI 处理它们的手段似乎大同小异。
面对 HuggingFace 上成千上万个让人眼花缭乱的模型名字,以及 PyTorch、TensorFlow 这些复杂的工具,你是否感到头晕目眩?其实,深度学习的世界并没有那么复杂,它本质上是一场精妙的"乐高拼装游戏"。
下一篇,我们将拨开迷雾,带你拆解 AI 的"零件库",看透那些顶级模型背后的真实马甲!
敬请期待第四篇:《看破 AI 的"马甲"------从算子到 ChatGPT》