目录
[关键词检索:BM25 算法](#关键词检索:BM25 算法)
[BM25 是什么------一句话概括](#BM25 是什么——一句话概括)
[BM25 的核心思想](#BM25 的核心思想)
[2.1 词频(TF):出现越多越相关,但有上限](#2.1 词频(TF):出现越多越相关,但有上限)
[2.2 逆文档频率(IDF):越稀有的词越有区分度](#2.2 逆文档频率(IDF):越稀有的词越有区分度)
[2.3 文档长度归一化:长文档不能占便宜](#2.3 文档长度归一化:长文档不能占便宜)
[BM25 vs 向量检索:不是谁替代谁](#BM25 vs 向量检索:不是谁替代谁)
[Milvus 中的 BM25 支持](#Milvus 中的 BM25 支持)
[混合检索:向量 + 关键词,取长补短](#混合检索:向量 + 关键词,取长补短)
[两种架构方案:Milvus 原生 vs ES + Milvus](#两种架构方案:Milvus 原生 vs ES + Milvus)
[.1 方案一:Milvus 原生混合检索(推荐)](#.1 方案一:Milvus 原生混合检索(推荐))
[2.2 方案二:Elasticsearch + Milvus 双系统](#2.2 方案二:Elasticsearch + Milvus 双系统)
[4.1 RRF 的计算方式](#4.1 RRF 的计算方式)
[2.1 Bi-Encoder vs Cross-Encoder](#2.1 Bi-Encoder vs Cross-Encoder)
[2.2 为什么不直接用 Cross-Encoder 做检索](#2.2 为什么不直接用 Cross-Encoder 做检索)
[3.1 一个容易忽略的调优顺序](#3.1 一个容易忽略的调优顺序)
[3.2 线上观测指标建议](#3.2 线上观测指标建议)
纯向量检索的短板:语义很强,但关键词很弱
场景一:精确关键词丢失
场景二:专有名词和缩写
场景三:数字和编号
向量检索和关键词检索的互补关系

关键词检索:BM25 算法
BM25 是什么------一句话概括
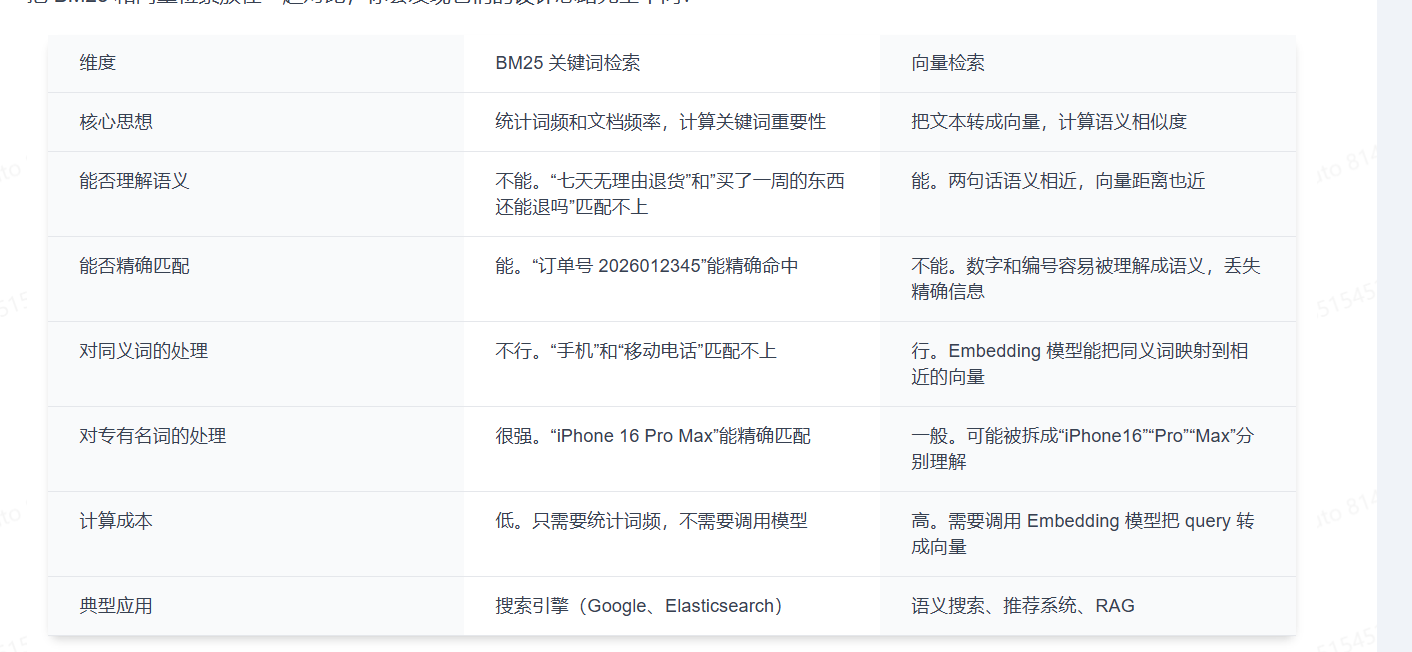
BM25(Best Matching 25)是一个经典的关键词检索算法,用来衡量一个查询词在某个文档中有多重要。它是搜索引擎(如 Elasticsearch)的默认排序算法,也是混合检索中关键词检索部分的核心。
BM25 的核心思想
BM25 不需要理解语义,它只看三个核心因素:
2.1 词频(TF):出现越多越相关,但有上限
用一句话概括:出现越多越相关,但有上限,避免长文档刷词占便宜。
2.2 逆文档频率(IDF):越稀有的词越有区分度
用一句话概括:越稀有的词越有区分度,越能帮你找到目标文档。
2.3 文档长度归一化:长文档不能占便宜
用一句话概括:长文档不能因为块头大就占便宜,要按长度归一化。
BM25 vs 向量检索:不是谁替代谁
Milvus 中的 BM25 支持
Milvus 从 2.5 版本开始内置了全文检索能力,支持 BM25 算法。你可以在创建 Collection 时指定一个 VarChar 字段用于全文检索,Milvus 会自动对这个字段做分词和倒排索引,支持 BM25 检索。
如果你用的 Milvus 版本低于 2.5,或者对中文分词有更高要求,也可以用外部方案------比如用 Elasticsearch 做关键词检索,Milvus 做向量检索,应用层把两路结果融合起来。这种方案架构复杂一些,但全文检索能力更强。
这一篇咱们用 Milvus 2.5+ 的原生方案,降低环境搭建成本。
混合检索:向量 + 关键词,取长补短
混合检索的基本思路
混合检索(Hybrid Search)的核心思路很简单:同时执行向量检索和关键词检索,把两路结果融合成一个最终排序。
用一张图来表示:
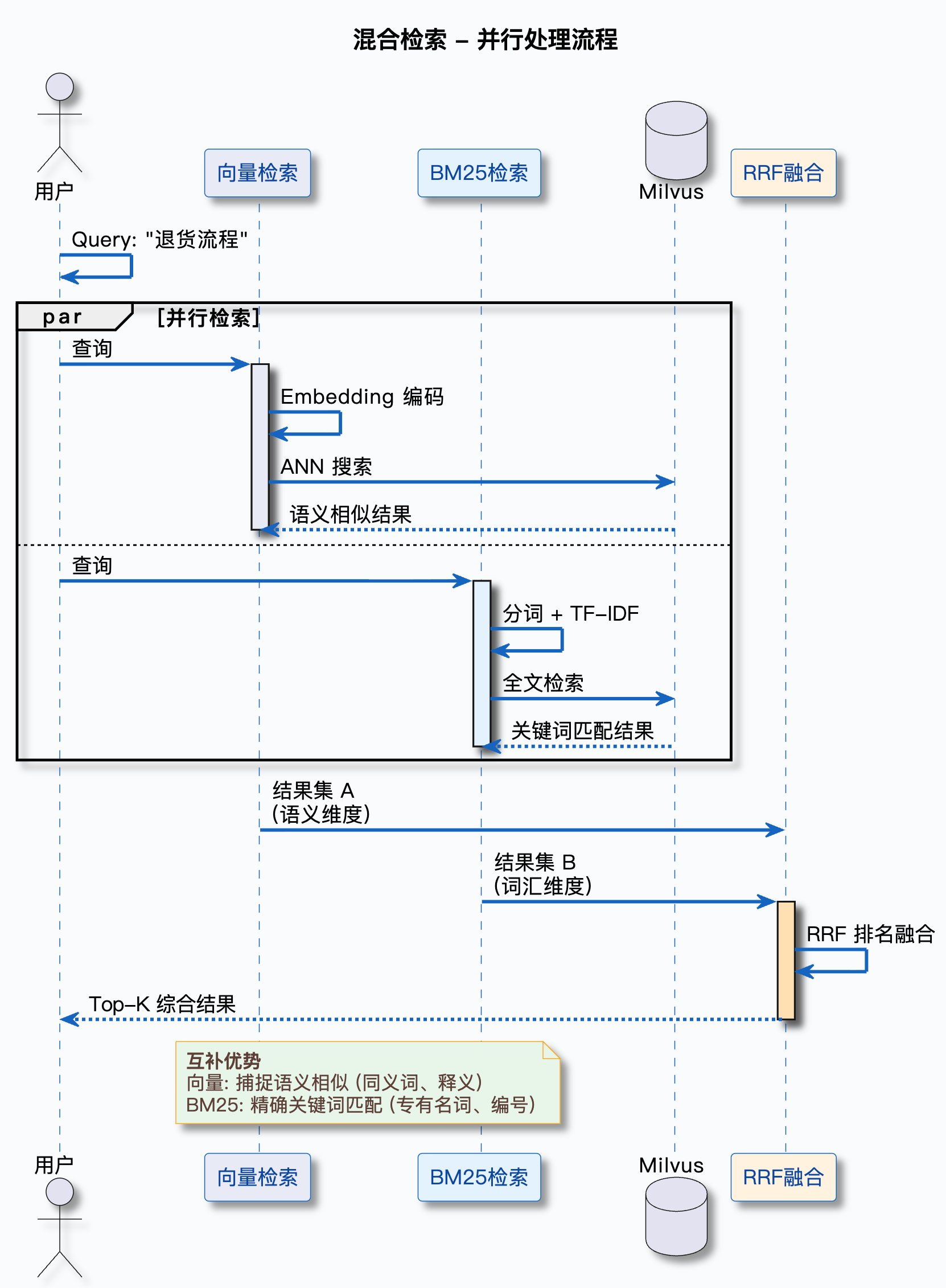
这张图展示了混合检索的基本流程:用户提问后,同时走向量检索和关键词检索两条路,最后把两路结果融合起来。
两种架构方案:Milvus 原生 vs ES + Milvus
.1 方案一:Milvus 原生混合检索(推荐)
Milvus 2.5+ 内置 BM25 全文检索能力,一个系统同时搞定向量检索和关键词检索。
优点:
- 架构简单,不需要维护多套系统
- 数据不用双写,避免一致性问题
- Hybrid Search API 原生支持 RRF 融合
- 运维成本低,只需要管理一个 Milvus 集群
缺点:
- 全文检索能力相比 ES 偏基础
- 中文分词能力有限,不如 ES 的 IK 分词器等插件丰富
- 查询语法不如 ES 丰富(布尔查询、短语查询、聚合等)
2.2 方案二:Elasticsearch + Milvus 双系统
ES 负责关键词检索,Milvus 负责向量检索,应用层做结果融合。
优点:
- ES 的全文检索能力成熟强大
- 中文分词生态好(IK 分词器、HanLP 等)
- 查询语法丰富,支持复杂的布尔查询、短语查询、同义词扩展等
- 适合已有 ES 基础设施的团队
缺点:
- 需要维护两套系统,运维复杂度高
- 数据双写带来一致性问题(写入 Milvus 成功但写入 ES 失败怎么办?)
- 融合逻辑需要自己实现,增加开发成本
- 故障面扩大(任何一个系统挂了都会影响检索质量)
RRF(倒数排名融合):最简单有效的融合策略
RRF 不依赖分数本身,只看排名。核心思想:一个结果在两路检索中排名都靠前,那它大概率是最相关的。
4.1 RRF 的计算方式
对于某个 chunk d,它的 RRF 分数计算公式是:
RRF(d) = Σ 1 / (k + rank_i(d))这里:
rank_i(d)是 chunk d 在第 i 路检索中的排名(从 1 开始)k是一个平滑常数,通常取 60Σ表示对所有检索路求和
重排序(Reranking):对候选结果做精细化排序
为什么需要重排序
混合检索已经能把相关的 chunk 召回来了,为什么还需要重排序?
因为召回阶段(向量检索 / BM25 / 混合检索)追求的是快速召回尽可能多的相关结果 ,但排序不一定精准。打个比方,你在图书馆找书,召回阶段是把可能相关的书都搬到桌子上 ,重排序是仔细翻看每本书,把最相关的几本排到最前面 。
最终给 LLM 的上下文窗口很小,真正关键的是 Top-3 或 Top-5 的排序是否正确。如果 Top-1 是不相关的 chunk,LLM 很可能被误导,生成错误的答案。重排序就是解决这一步------用更强的模型对候选集重新打分,把最相关的结果排到最前面。
重排序的工作原理
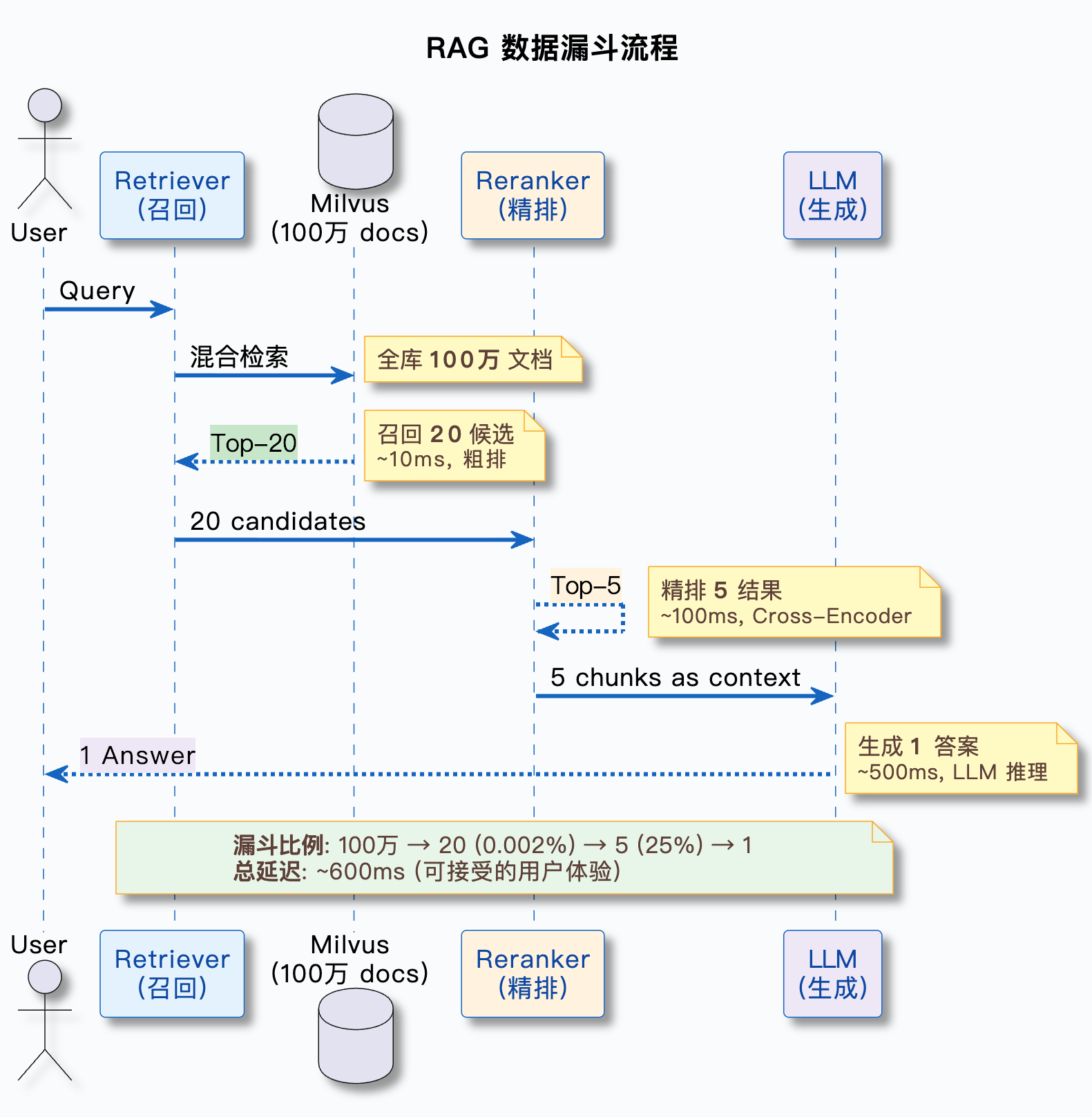
重排序的基本流程是:
-
- 初检阶段(向量检索 / 混合检索)快速召回候选集,比如 Top-20 或 Top-50
-
- 重排序模型逐个评估这个 chunk 和用户问题到底有多相关,给每个候选打分
-
- 按重排序分数重新排序,取 Top-K(比如 Top-5)作为最终结果
用一张图来表示:
2.1 Bi-Encoder vs Cross-Encoder
这里需要理解两种编码器的区别:
- Bi-Encoder(双编码器):query 和 chunk 分别编码成向量,然后计算向量相似度。这就是 Embedding 模型的工作方式。优点是速度快,可以提前把所有 chunk 编码好存起来,查询时只需要编码 query;缺点是精度有限,因为 query 和 chunk 是独立编码的,无法捕捉它们之间的细粒度交互关系。
- Cross-Encoder(交叉编码器):把 query 和 chunk 拼接在一起(比如
[CLS] query [SEP] chunk [SEP]),一起输入模型,模型能看到 query 和 chunk 的完整交互,输出一个相关性分数。优点是精度更高,能捕捉更细粒度的语义关系;缺点是速度慢,每个 (query, chunk) 对都要过一遍模型。
重排序通常用 Cross-Encoder,因为候选集已经很小了(比如 20~50 个),可以接受慢一点的速度,换取更高的精度。
2.2 为什么不直接用 Cross-Encoder 做检索
你可能会问:既然 Cross-Encoder 精度更高,为什么不直接用它做检索,还要搞两阶段?
因为太慢了。假设你的知识库有 100 万个 chunk,用户提问时,你需要把这 100 万个 chunk 逐个和 query 拼接起来过 Cross-Encoder,这需要 100 万次模型推理,延迟和成本都不可接受。
所以工程上一定是两阶段策略:
- 粗检索(Bi-Encoder):快速从 100 万个 chunk 中召回 Top-20 或 Top-50,延迟低,覆盖面广
- 精排序(Cross-Encoder):对这 20~50 个候选逐个打分,延迟可接受,精度高
这就是快召回 + 慢精排的核心思想。
常用的重排序模型
对比几个主流的 Reranker 模型(截至 2026 年 2 月):

完整检索流程:从用户提问到最终结果
四种检索策略的完整对比
用同一条 query:iPhone 16 Pro Max 拆封后还能退吗,分别跑四种检索策略,对比效果。
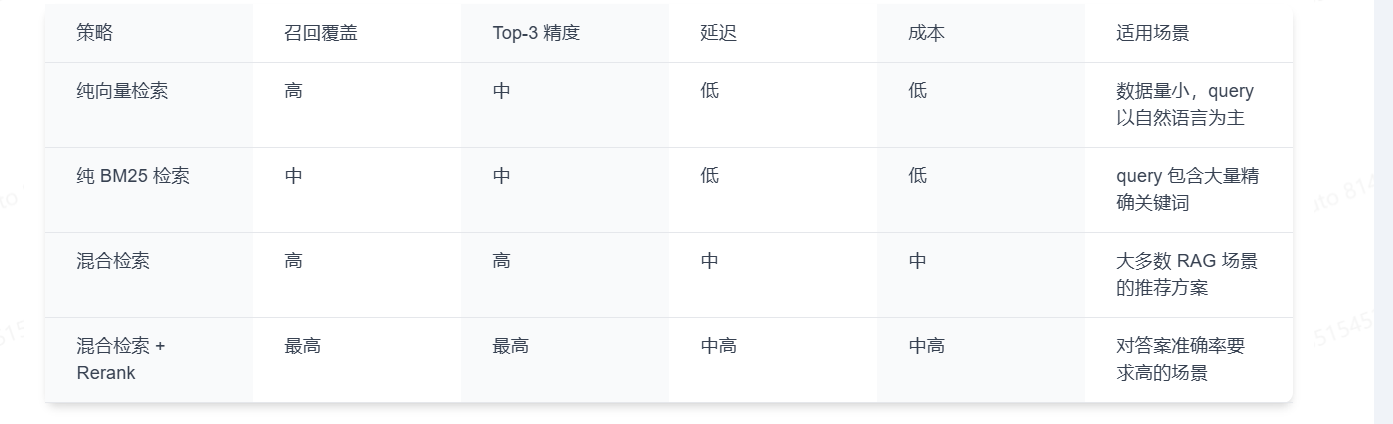
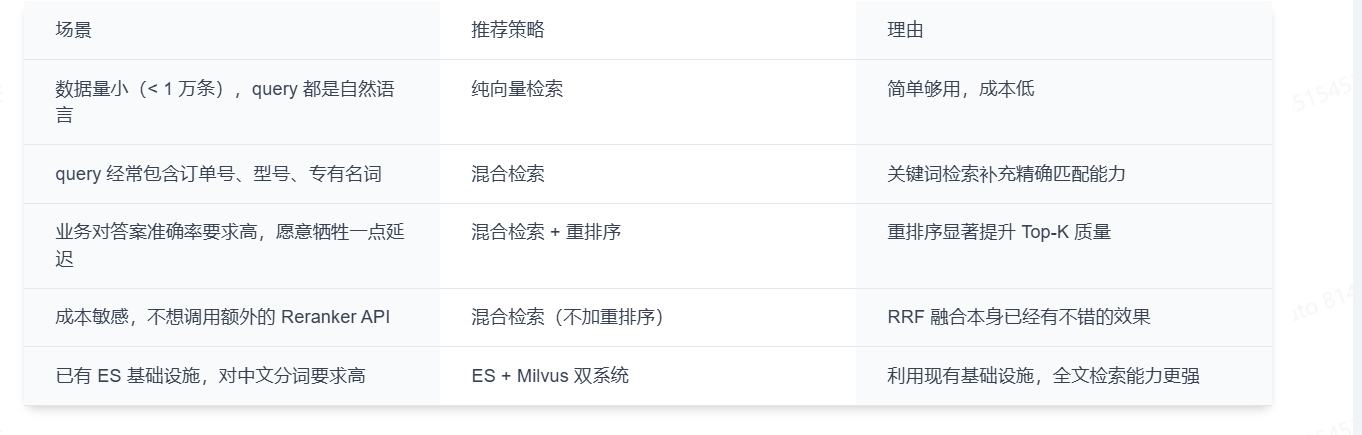
检索策略的选型建议
给出一个简单的决策表:
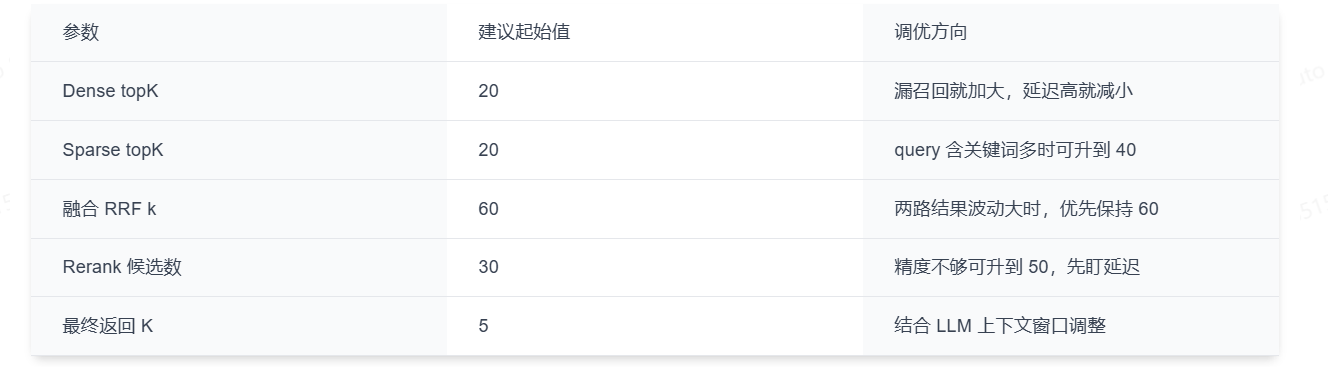
检索参数调优
先给一组可直接上线试跑的经验值:
3.1 一个容易忽略的调优顺序
先调召回覆盖,再调排序精度。
很多团队一上来就调 Reranker,结果其实是召回阶段已经漏掉了关键 chunk,后面怎么重排都救不回来。正确的调优顺序是:
-
- 先看召回覆盖率(Recall@20 或 Recall@50),确保相关的 chunk 都被召回了
-
- 再看排序精度(MRR、nDCG@10),优化 Top-K 的排序质量
-
- 最后看业务指标(人工标注准确率、用户追问率、答非所问率)
3.2 线上观测指标建议
至少盯这三类指标:
- 召回指标:Recall@20(Top-20 候选集中包含相关 chunk 的比例)
- 排序指标:MRR(Mean Reciprocal Rank,第一个相关结果的平均排名倒数)、nDCG@10(归一化折损累积增益)
- 业务指标:人工标注准确率、用户追问率、答非所问率
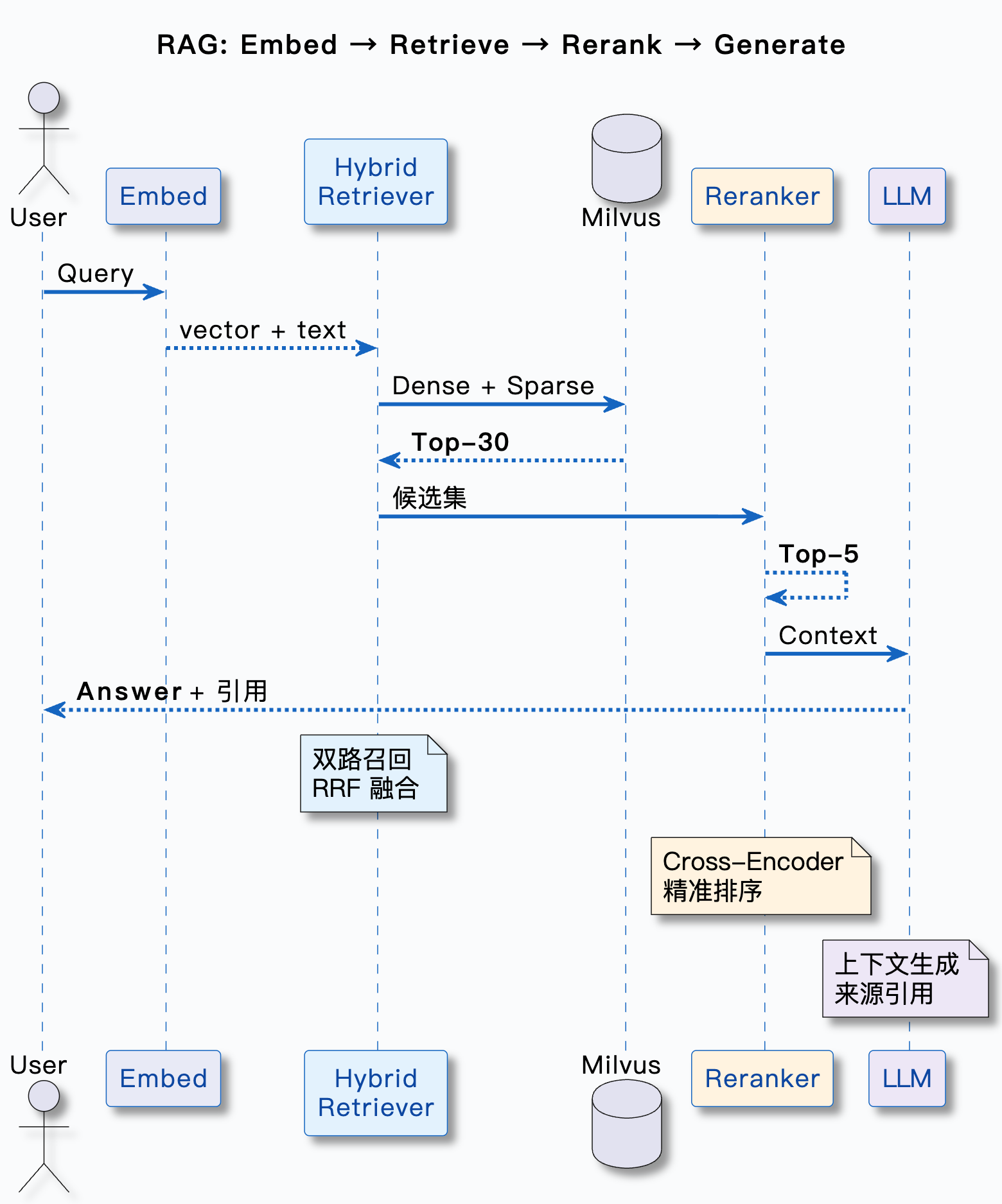
一张图看完整链路
把整个检索流程串起来,从用户提问到最终答案:
小结与下一篇预告
到这里,检索策略这块可以用一句话记住:
- 纯向量检索是基础能力,适合大多数自然语言 query
- 混合检索解决"语义强、关键词弱"的结构性短板,是生产环境的推荐方案
- 重排序决定最终给大模型的上下文质量上限,对答案准确率要求高的场景必备
如果你已经完成了分块、元数据、向量化、向量库、检索策略,下一步最值得讲的是生成阶段怎么控答案质量:
- 如何设计 Prompt 模板让模型少幻觉
- 如何做引用对齐与答案约束
- 如何把检索链路和生成链路连成完整可观测系统