PyTorch强化学习实战------使用交叉熵方法解决 FrozenLake 环境
-
- [0. 前言](#0. 前言)
- [1. FrozenLake 环境](#1. FrozenLake 环境)
- [2. 使用交叉熵方法解决 FrozenLake 环境](#2. 使用交叉熵方法解决 FrozenLake 环境)
- [3. 改进交叉熵方法解决 FrozenLake 问题](#3. 改进交叉熵方法解决 FrozenLake 问题)
0. 前言
我们已经学习了如何使用交叉熵方法解决 CartPole 环境,神经网络学会了仅通过观察值和奖励信号就学会了如何应对环境,完全不需要对观测值进行任何人工解读。虽然我们使用 CartPole 环境为例,但完全可以替换为其他场景,如以商品库存量为观察值、以营业收入为奖励的仓储模型。实现并不依赖于环境的具体细节,这正是强化学习模型的精妙之处,接下来我们将学习如何将完全相同的方法应用于 Gymnasium 库中的另一个环境,FrozenLake。
1. FrozenLake 环境
在本节中,尝试使用交叉熵方法解决 FrozenLake 环境。该环境属于典型的网格世界 (grid world),智能体在 4×4 的网格中活动,可以执行上、下、左、右四种移动动作。智能体始终从左上角出发,目标是到达网格右下角的终点单元格。网格固定位置分布着冰洞,一旦落入其中,回合立即终止且奖励归零;若成功抵达目标单元格,则获得 1.0 的奖励并结束回合。

为了增加挑战性,湖面具有打滑特性,因此智能体的动作并不总是如预期执行,有 33% 的几率会滑到右边或左边。例如,发出智能体向左移动的指令,实际上仅有 33% 概率正确左移,另有 33% 概率滑向正上方单元格,剩下 33% 概率滑向正下方单元格。这种特性会显著增加训练难度。
查看该环境在 Gymnasium API 中的具体表示方式:
shell
>>> import gymnasium as gym
>>> e = gym.make("FrozenLake-v1", render_mode="ansi")
>>> e.observation_space
Discrete(16)
>>> e.action_space
Discrete(4)
>>> e.reset()
(0, {'prob': 1})
>>> print(e.render())
SFFF
FHFH
FFFH
HFFG2. 使用交叉熵方法解决 FrozenLake 环境
在 FrozenLake 环境中,观察空间 (observation space) 是离散型的,即一个取值范围为 0 到 15 (含)的整数。显然,这个数字代表智能体在网格中的当前位置。动作空间 (action space) 同样是离散型,但取值范围是 0 到 3。虽然动作空间与 CartPole 类似,但观察空间的表示方式却截然不同。为使现有代码需要做的改动最小化,我们可以对离散输入采用经典独热编码 (one-hot encoding) 处理------这意味着网络的输入将是包含 16 个浮点数的向量,其中只有当前网格位置对应的索引值为 1,其余全部为 0。
由于这种转换仅影响环境观察值,因此可以,将其实现为 ObservationWrapper 子类,将其命名为 DiscreteOneHotWrapper:
python
class DiscreteOneHotWrapper(gym.ObservationWrapper):
def __init__(self, env: gym.Env):
super(DiscreteOneHotWrapper, self).__init__(env)
assert isinstance(env.observation_space, gym.spaces.Discrete)
shape = (env.observation_space.n, )
self.observation_space = gym.spaces.Box(0.0, 1.0, shape, dtype=np.float32)
def observation(self, observation):
res = np.copy(self.observation_space.low)
res[observation] = 1.0
return res应用该包装器后,环境的观察空间和动作空间就能完全兼容为 CartPole 设计的解决方案。但实际运行时会发现,训练过程中的得分始终无法提升:
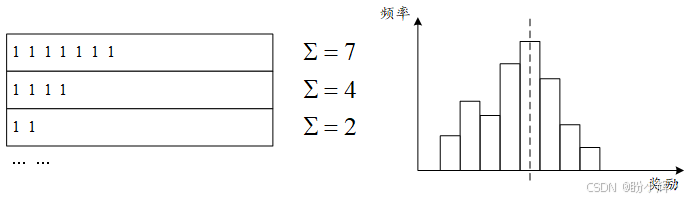
要深入理解问题根源,需要对比两个环境的奖励机制差异。在CartPole中,智能体每保持平衡一步就能获得 1.0 奖励,直到杆子倒下为止。所以,智能体平衡杆子的时间越长,累计奖励就越高。由于行为存在随机性,不同训练回合的持续时间各不相同,使得奖励值呈现良好的正态分布特征。通过设定奖励阈值,筛除表现较差的回合,并学习如何复现成功回合的行为模式(基于精英回合数据训练):
而在 FrozenLake 环境中,训练回合及其奖励呈现完全不同的特征。只有当智能体抵达终点时才会获得 1.0 的奖励,这个单一数值根本无法反映每个回合的实际表现质量------究竟是高效直达目标,还是在冰面上随机绕行数圈后侥幸抵达终点?奖励机制无法给出任何区分度,奖励只有 1.0 这一种结果。更严重的是,奖励分布呈现典型的二元分化特征:要么获得 1.0 (成功),要么获得 0 (失败),而在训练初期随机探索阶段,失败回合必然占据绝对多数。
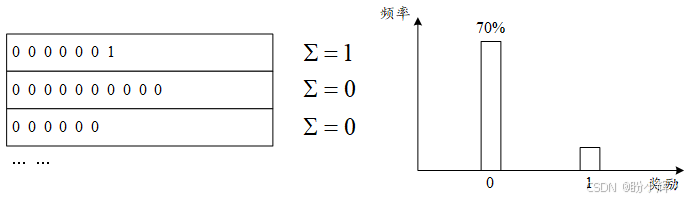
这就导致我们基于百分位筛选优质回合的标准完全失效,最终选出的训练样本质量不佳,根本无法提供有效的学习信号,这正是训练失败的根源所在。
这个示例揭示了交叉熵方法的局限性:
- 回合长度要求:训练回合必须有限(理论上可以是无限的),且最好较短。
- 奖励区分度:回合总奖励需具备足够差异性以区分优劣
- 奖励时序分布:在回合过程中拥有中间奖励,比只在回合结束时才获得奖励更有效
3. 改进交叉熵方法解决 FrozenLake 问题
如果想改进交叉熵方法解决FrozenLake问题,需要在代码中进行以下修改:
- 增加回合的批次大小:在
CartPole中,每次迭代有16个回合就足够了,但FrozenLake至少需要100个回合才能获得一些成功的回合 - 奖励折扣因子:为了让回合的总奖励依赖于回合的长度,并且增加回合之间的变化性,可以使用带有折扣因子的总奖励,折扣因子 γ = 0.9 γ = 0.9 γ=0.9 或 0.95 0.95 0.95。这样,短回合的奖励将高于长回合的奖励,增加了奖励分布的变化性,有助于避免如上图所示的情况
- 延长精英样本保留期:在
CartPole训练中,我们从环境中抽取回合,使用优质回合后直接丢弃。而在FrozenLake中,成功的回合更为稀少,因此需保留多个迭代周期以供训练 - 降低学习率:较小的学习率能减弱新数据对模型的影响,让神经网络有更多时间整合训练样本
- 延长训练时间:由于成功回合稀少且行动结果随机,神经网络更难掌握特定情境下的最佳策略。要达到
50%的成功率,约需5000次训练迭代
要实现这些调整,需修改 filter_batch 函数以计算折扣奖励,并返回需保留的精英回合:
python
def filter_batch(batch: tt.List[Episode], percentile: float) -> tt.Tuple[tt.List[Episode], tt.List[np.ndarray], tt.List[int], float]:
reward_fun = lambda s: s.reward * (GAMMA ** len(s.steps))
disc_rewards = list(map(reward_fun, batch))
reward_bound = np.percentile(disc_rewards, percentile)
train_obs: tt.List[np.ndarray] = []
train_act: tt.List[int] = []
elite_batch: tt.List[Episode] = []
for example, discounted_reward in zip(batch, disc_rewards):
if discounted_reward > reward_bound:
train_obs.extend(map(lambda step: step.observation, example.steps))
train_act.extend(map(lambda step: step.action, example.steps))
elite_batch.append(example)
return elite_batch, train_obs, train_act, reward_bound接着,在训练循环中,存储之前的精英回合,以便在下一次训练迭代时传递给前面的函数:
python
full_batch = []
for iter_no, batch in enumerate(iterate_batches(env, net, BATCH_SIZE)):
reward_mean = float(np.mean(list(map(lambda s: s.reward, batch))))
full_batch, obs, acts, reward_bound = filter_batch(full_batch + batch, PERCENTILE)
if not full_batch:
continue
obs_v = torch.FloatTensor(np.vstack(obs))
acts_v = torch.LongTensor(acts)
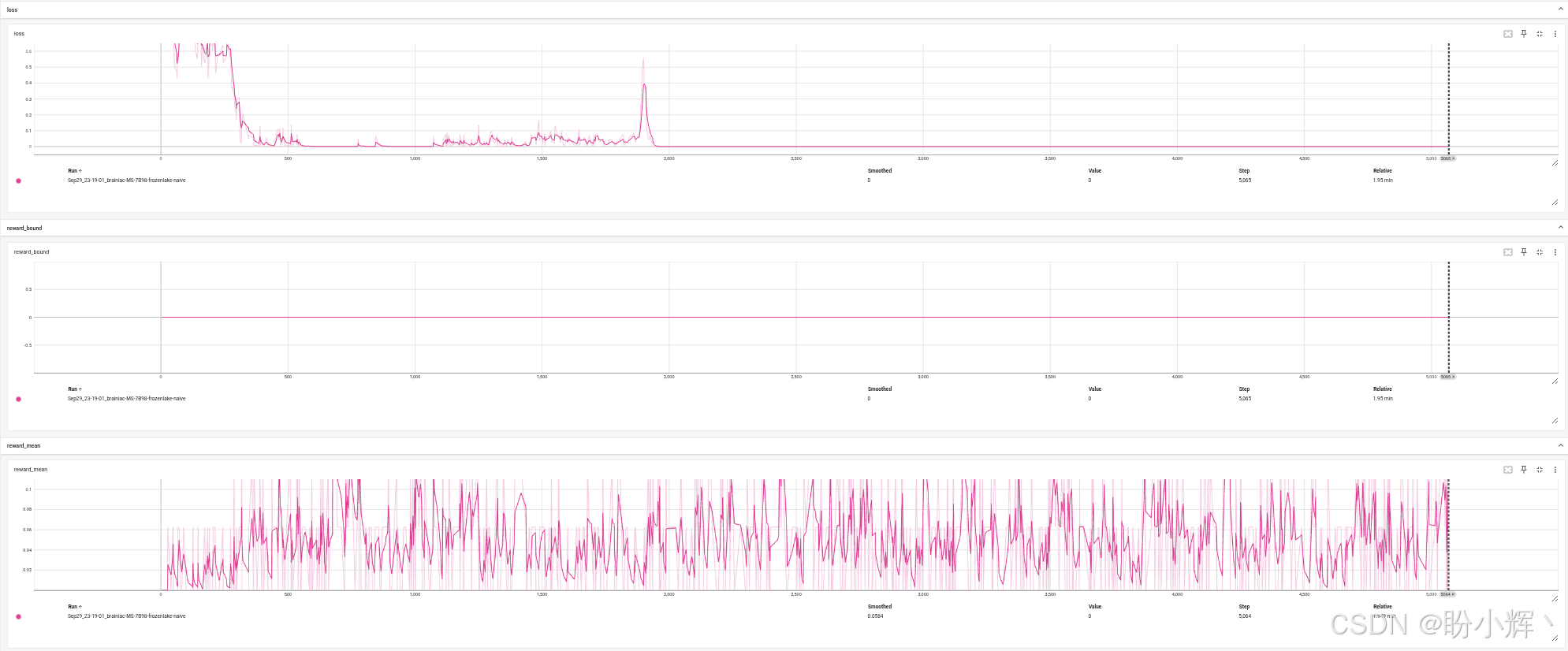
full_batch = full_batch[-500:]其余代码保持不变,只是学习率降低了 10 倍,并将 BATCH_SIZE 设置为 100,可以看到模型的训练在约有 55% 的回合成功率时停止:
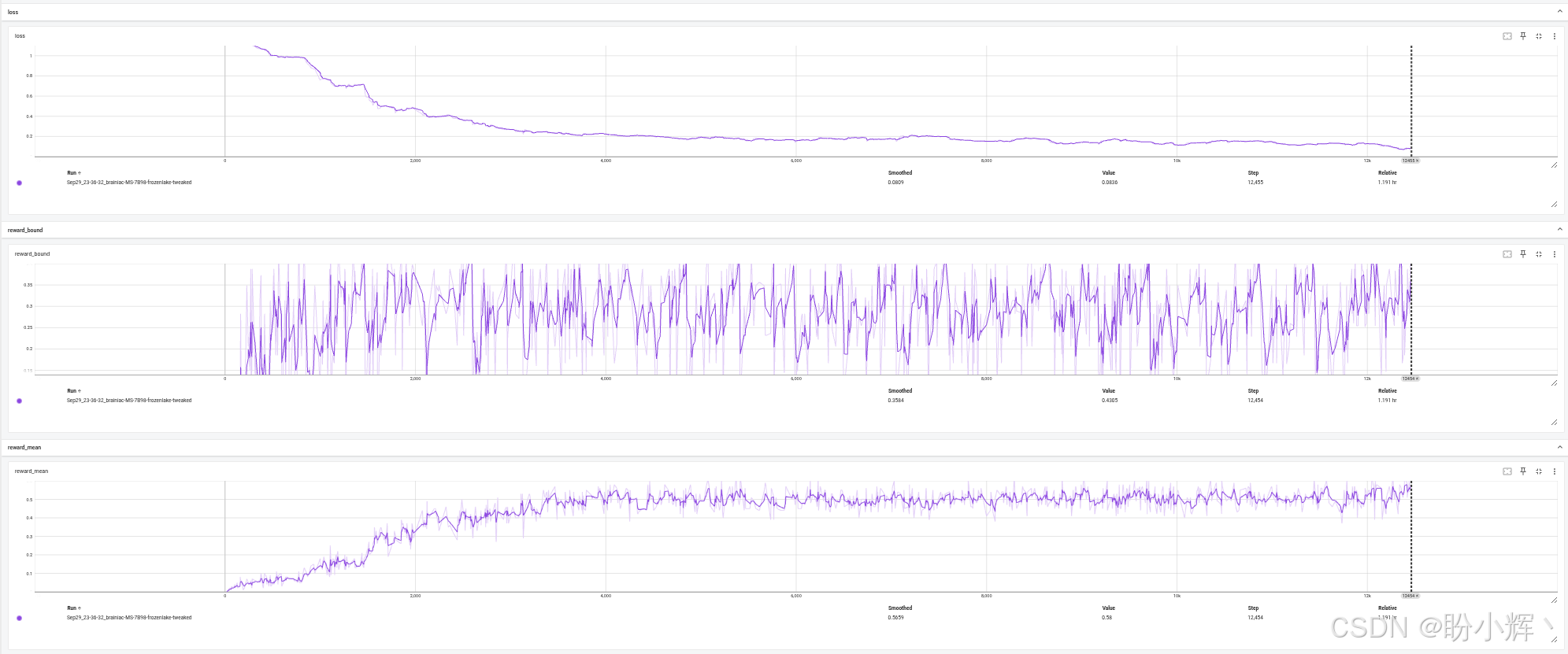
最后需要注意的是 FrozenLake 环境中的滑移效应。每个动作有 33% 的概率会被替换为 90 度旋转的动作(例如"向上"动作仅有 0.33 的成功概率,另有 0.33 概率被替换为"向左",0.33 概率替换为"向右")。Gymnasium 中还存在无滑移版本的 FrozenLake 环境,使用强化学习解决该环境的唯一区别是在环境创建部分:
python
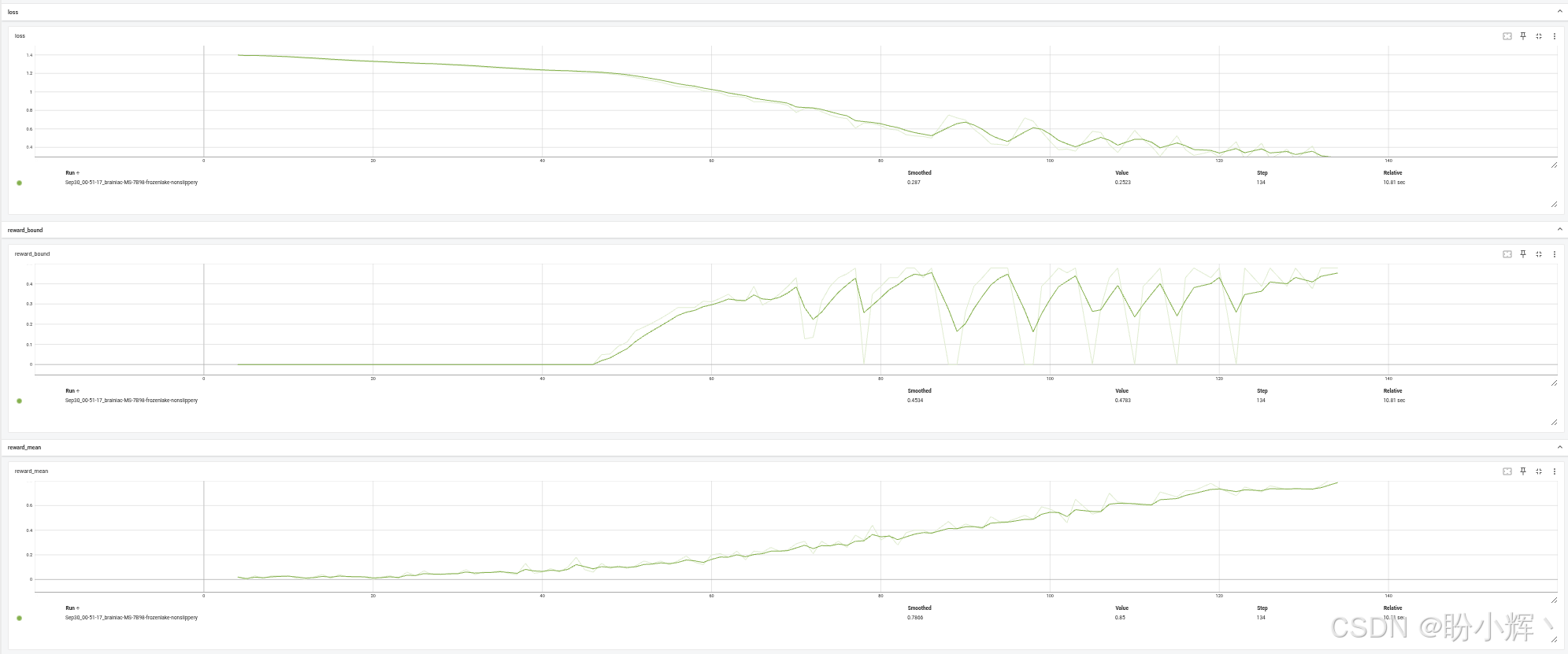
env = DiscreteOneHotWrapper(gym.make("FrozenLake-v1", is_slippery=False))无滑动版本的环境仅需 120-140 次批量迭代即可解决,比滑动版本的环境的训练速度快 100 倍:
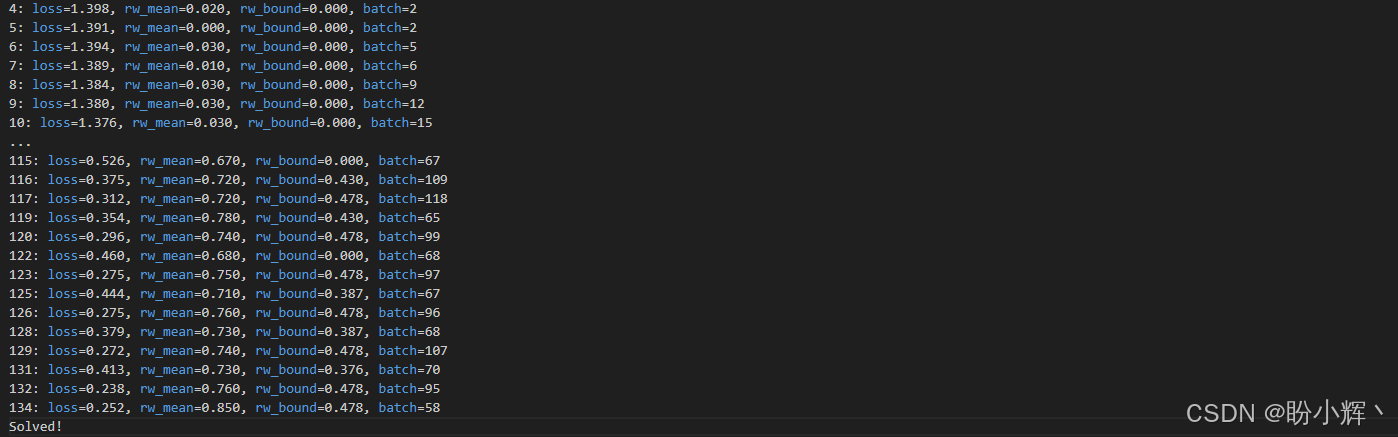
训练过程曲线如下所示: