NavDreamer:将视频模型用作零样本3D导航器
黄锡杰1,1,2 盖伟奇2,3 吴天悦1 王聪宇1,2 刘志扬2 2 周欣2 吴宇泽*,1,2 高飞*,1,2
项目页面:https://xinjiu612.github.io/NavDreamer。
摘要:以往的视觉-语言-动作模型在导航任务中面临关键局限性:数据稀缺且种类单一,需耗费大量人力进行采集;此外,这些模型采用静态表征,无法捕捉时间动态和物理规律。我们提出NavDreamer------一种基于视频的三维导航框架,利用生成式视频模型作为语言指令与导航轨迹之间的通用接口。我们的核心假设是:视频能够编码时空信息和物理动力学,加之其在互联网规模上的广泛可用性,使得导航任务具备强大的零样本泛化能力。为缓解生成预测的随机性,我们引入了一种基于采样的优化方法,该方法借助视觉语言模型对轨迹进行评分与选择。同时,我们采用逆动力学模型,从生成的视频规划中解码出可执行的航点,以实现导航操作。为了系统评估这一范式在多种视频模型骨干中的表现,我们构建了一个全面的基准测试集,涵盖物体导航、精准导航、空间定位、语言控制以及场景推理等多个任务领域。大量实验表明,该框架在面对全新物体和未见环境时均展现出稳健的泛化能力;消融实验进一步揭示,导航任务的高度决策特性使其特别适合基于视频的规划方法。
关键词:视频模型,3D导航,空中机器人
1引言
在物理世界中,追求能够跨多种任务和环境实现泛化的通用智能体,一直是机器人与人工智能领域的长久梦想。在此背景下,开放世界的导航成为一项基础性需求,它要求具备语义上下文理解能力和反应式空间推理能力,以解码自然世界中所蕴含的隐含信息。令人振奋的是,视觉语言模型(VLLM)1, 2, 3已展现出类人般的推理、场景感知与语义分析能力。基于这些进展,一些机器人研究者开始尝试将行动作为一种全新模态引入其中,从而推动了视觉-语言-行动(VLA)模型4的开发。这类模型通常以视觉语言模型作为核心骨干,以继承其在空间和语言理解方面的优势------这些优势已在特定场景中初步展现了泛化能力5, 6。然而,尽管取得了上述进展,机器人领域似乎仍未迎来像大型语言模型那样的"顿悟时刻"7。
这一涌现点未能出现的一个主要原因是,数据缩放规律8, 9在机器人领域仍处于探索不足的状态。尽管通用智能通常源自互联网规模的数据集,但机器人数据采集却始终是一项棘手的挑战10, 11。目前,从操作到导航的高保真演示均依赖于劳动密集且成本高昂的方法,例如双臂遥操作12或手动远程控制13,这些方法从根本上制约了数据采集的可扩展性。此外,一旦数据量达到一定规模,环境与物体的多样性便对涌现智能变得愈发关键14。然而,现有的数据集13,15,16大多仍以受限环境为核心。尽管诸如UMI17等专用接口在野外数据采集方面已取得一定进展,但要收集具备开放世界多样性的数据集依然困难重重。尽管仿真18和领域随机化19能够提供可 scale 的数据生成方式,但"仿真到现实"的差距20,21往往导致策略部署到真实环境中时性能下降。

除了数据稀缺性之外,当前的VLA模型通常基于视觉-语言骨干网络构建,这些网络是在静态图像-文本对上进行训练的22。这种静态范式缺乏表现力,无法有效表征具有强烈时间依赖性的行为,或受物理规律支配的行为,例如碰撞和坠落23。因此,这些模型不得不依赖一种有损表示,在迁移过程中丢弃了大量有用信息。这种固有的信息缺失不可避免地限制了模型对世界进行推理的能力。
近来,生成式视频模型24, 25, 26的迅猛发展为应对这些挑战提供了一种颇具前景的范式。首先,与机器人动作数据不同,视频数据集可大规模地从互联网上获取,这使得模型能够在未见的任务和环境中实现显著的零样本泛化能力27。其次,视频作为一种高保真表示形式,能够捕捉语言和静态图像往往难以解析的复杂时空信息23。这些模型已展现出对物理动力学的内在理解27, 28,从而能够推理世界如何随特定运动而演化。此外,视频还充当了一个统一的状态---动作空间,为跨不同机器人平台的行为表达提供了一种通用接口29。这种共享的抽象机制通过在一致的像素空间内自然地捕获状态---动作轨迹,促进了知识的共享与迁移。
受视频模型卓越泛化能力的驱动,越来越多的研究开始探索将视频先验知识迁移到机器人策略中22, 30, 31, 32。受到视频条件动作解码范式的启发29, 33,我们进一步探索了其在三维导航领域的应用潜力。以往以操作为中心的研究往往受限于难以精确解码低级机器人动作的问题34, 35,而导航任务主要依赖于高层次决策与方向指引,这恰恰更契合基于视频的规划方式。然而,此前关于导航的研究大多集中于利用未来帧预测作为辅助信号来增强导航策略36, 37。相比之下,NavDreamer直接将生成式视频模型用作高层次导航规划器。它提供了一个统一的接口,弥合了高层语言指令与可执行导航轨迹之间的鸿沟。为了缓解生成模型中的随机性,我们采用了一种基于采样的优化策略。不同于基于能量的采样方法(例如目标图像相似度)38,我们借助视觉语言模型从多个维度评估视频质量39。随后,我们利用三维地图40从生成的视频序列中解码出可执行的航点。不过,在室外环境中,物理尺度估计往往会降级。为此,我们引入了来自Moge241的度量深度先验,以纠正绝对尺度的模糊性。经过校准后的航点随后由实时反应控制器处理,以实现飞行执行。为了评估视频模型在三维导航中的潜力,NavDreamer展示了其强大的零样本泛化能力,能够应对涉及新物体和新环境的多样化任务。此外,针对三维导航领域缺乏视频模型基准测试的问题,我们推出了一套全面的评估体系,涵盖五个维度:物体导航、精准导航、空间定位、场景推理以及语言理解。
控制。通过大量实验和消融研究,我们为在3D导航中利用生成式视频模型的设计选择提供了关键见解。
总之,我们的贡献包括:(1) 我们提出了一种零样本3D导航器,结合生成式视频模型与逆动力学模型,以求解高层级指令;(2) 我们设计了一个全面的3D导航基准,用于从五个关键维度评估当前最先进的视频模型;(3) 我们通过消融实验探讨了多种设计选择,以深入理解它们对基于视频的3D导航性能的影响。
2相关工作
2.1 用于机器人技术的生成式视频模型
生成式视频模型的迅猛发展24, 25, 26已展现出对未见场景的惊人零样本泛化能力27,从而重新激发了人们对机器人技术的兴趣。一类研究将视频模型视为高保真神经模拟引擎,用于合成大规模、多样化的机器人轨迹,以进行策略预训练42, 43。另一类研究则直接将视频模型用作策略,这一方法可细分为直接训练和基于接口的范式。在直接训练的背景下,一些研究将未来帧预测作为多模态目标融入视觉语言模型(VLA)框架中,以强化物理一致性和前瞻性44, 45。另有研究采用预训练视频模型作为VLA的骨干网络,以替代传统视觉语言模型,认为预训练的视频生成器对物理及时空动态具有更深刻的理解26, 28, 30, 31。此外,还有一种范式将视频视作一种视觉规划形式,其中视频模型充当视觉想象与机器人动作之间的接口。这类方法首先根据给定条件生成全像素未来的视频,随后从生成的帧中提取可执行的姿态或轨迹29, 33。为了从这些视觉规划中提取连续动作,研究人员提出了多种方法:一种常见做法是利用逆动力学模型(IDM)从帧序列中推导出动作29;另一些研究则通过向量量化变分自编码器(VQ-VAE)47,直接将像素空间的运动映射到潜在的动作空间中46。
2.23D导航与自动驾驶系统
近年来,无人机导航在各类专业任务中取得了显著进展,包括无人机竞速48、目标追踪49、特技飞行50以及穿越障碍51等。尽管这些基于专家经验的系统在特定领域展现出极高的精度,但将其能力拓展至开放世界的语义推理和广泛的任务泛化仍是一个重要的研究目标。视觉语言模型(VLA)的出现为应对这些挑战提供了一种统一的范式。值得注意的是,AerialVLN52和CityNav53分别建立了面向户外空中导航的大规模基准数据集。FlightGPT54进一步引入了以推理驱动的框架,以提升复杂场景下的零样本泛化能力。诸如VLA-AN55之类的框架则采用多阶段训练流程,旨在提高场景理解与导航精度。然而,这些方法高度依赖于大规模的人工标注数据集来对预训练的视觉语言模型骨干进行微调。这种依赖性可能给将视觉语言模型的泛化能力和语义理解迁移到机器人领域带来挑战,主要原因在于数据规模的巨大差异。尽管免训练方法56提供了一种更节省资源的替代方案,但目前其应用大多局限于相对基础的面向对象导航任务,且受限于从视觉语言模型中提取导航线索所采用的规则驱动策略------例如,文献37利用世界模型进行未来帧合成,以提供基于相似性的策略指导,但其部署范围仅限于图像目标导航等受约束的基准任务。
3方法
给定输入图像I和语言指令c,NavDreamer首先利用视频生成模型,根据这些输入合成一条预测性导航序列。值得注意的是,这一生成过程会产出直观且信息密集的视觉提示,用作高层次的引导。Qwen3-VL57则基于指令对齐及环境约束,充当轨迹选择器58。随后,所选视频会以固定间隔进行降采样,生成一系列图像。接着,我们采用3 40从这些图像中解码航点(例如x、y、z坐标及偏航角)。
为解决户外环境中3固有的尺度模糊问题,我们采用了一种鲁棒的尺度恢复方法,以度量深度估计值作为参考。这些经过校准的航点构成了低层规划模块的基础,在该模块中,最终轨迹会根据实时障碍物分布进行优化。
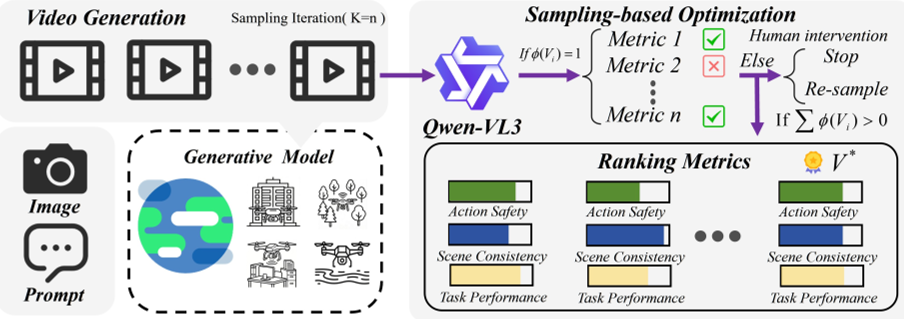
3.1 通过生成采样进行优化
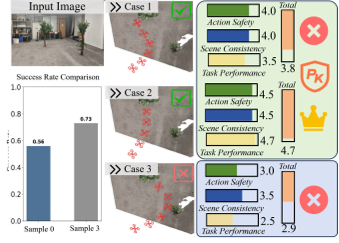
增强可解释性是基于学习的机器人技术的核心目标之一。给定观测值Io和指令c,生成过程定义为y'~ P(V|Io, c)。由于视频生成具有随机性,即使在相同条件下也可能产生不同的结果,因此我们生成K个独立的候选样本{V1,...,VK},以充分利用样本多样性并降低不稳定性。为确保可靠性,我们采用P1...,VKt Qwen3-VL57对这些样本进行评估。如图2所示,我们定义了一个二元成功指标重(V)∈{0,1},用于验证某个候选序列是否代表一次成功且安全的执行:
其中,真实结果表明该视频既符合任务要求又无碰撞。这一二值过滤器构成了有效候选集V'valid=V重(V)=1。随后,我们基于三项指标进行精细化评估:动作安全性(scas)、场景一致性(scsc)和任务表现(sctp)。总体质量得分R(Vi)通过加权求和计算得出:
其中,wa、wSc、wtp 分别代表各维度的预定义重要性权重,取值分别为0.8、0.8、1.4。最终的最优视频)'* 被选为使奖励最大化的样本:
这一机制能够有效模拟人类的认知预见能力,优先排除"失败的未来",然后再优化执行质量。如果valid为空,系统将向人工主管发出信号,由其决定是重新采样还是终止操作。
3.2 视频中的高级动作
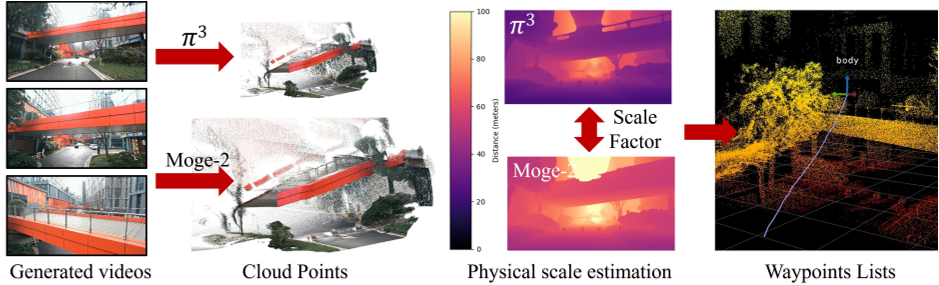
为弥合由340预测的归一化几何与度量物理世界之间的差距,我们提出了一种鲁棒的尺度恢复模块。给定图像序列{I},我们首先采用一种度量深度估计器(例如Moge2 41)来获取参考深度图De,如图3所示。同时,利用3生成一系列局部点云图XeIRH×W×3。对于每一帧t,我们定义一个有效观测掩码Mt,用于滤除异常值和极端值(例如天空或极远处的物体),该掩码通常被限制在可靠的感知范围内T e 0.5,30米:
其中,Zpred(u, v) 表示由三维生成点图得出的深度值。像素级缩放比例 st(u, v) 在由 Mt 定义的有效区域内进行计算。为确保对深度噪声和几何错配的鲁棒性,我们采用基于中位数的一致性方法来估计全局缩放因子 S:
最后,从3中提取的归一化航点wt E IR3被转换到度量空间,表示为Wt=S.wt,从而确保解码后的轨迹与物理真实值一致,以实现低级导航。
3.3低级轨迹生成
由于从视频合成中获取的航点可能在绝对物理尺度上存在误差,直接将其应用于位置控制器具有风险。为确保系统能够安全应对估计误差和现实世界的不确定性,我们采用了Ego-Planner 59 作为我们的底层导航模块。该模块接收三维位置目标,并实时规划一条无碰撞的轨迹。系统会持续监测与当前目标之间的欧几里得距离;一旦该距离降至某一阈值以下,列表中的下一个航点便会发送给规划器。这种方法确保了整个飞行路径既融合了高层视频模型所设定的预期行为,又具备实时避障的安全性。
为确保实际飞行执行能够体现合成视频中所捕捉的隐含动态约束,我们首先根据航点序列计算出最大速度和加速度。随后,在轨迹优化过程中,将这些数值用作自适应约束,以匹配视频中的动态特性。此外,我们还对偏航角实施独立控制,使系统操作更加简便。这种实时规划方法能够确保最终飞行路径在复杂环境中既稳健又安全。
4个实验
为了全面评估视频模型在3D导航中的潜力,我们开展了大量实验和消融研究,重点围绕以下四个问题:(1) 当前最先进的开源与闭源视频模型在多方面导航任务中的比较效果如何?(2) 如何从合成视频中提取精确的动作?(3) 该系统在真实环境中的部署表现如何,其泛化能力又如何?(4) 基于采样的优化方法和提示层级对生成轨迹的可靠性有何影响?
为此,我们首先设计了一套多样化的任务及相应的评估指标,用于评价三维导航性能。这是因为目前针对视频模型的大多数现有指标仅关注视觉清晰度和时间平滑性。随后,我们在这些任务上对若干最先进的开源与闭源模型的性能进行了基准测试。在动作提取方面,我们对尺度恢复组件进行了消融研究,以证明它们能够有效解决尺度模糊问题。通过涵盖从室内到室外的多样化任务,我们证实了视频模型具备在未见场景中的零样本生成能力。最后,我们分析了采样迭代次数对成功率的影响,并探讨了不同提示工程策略如何影响生成视频的稳定性和准确性。
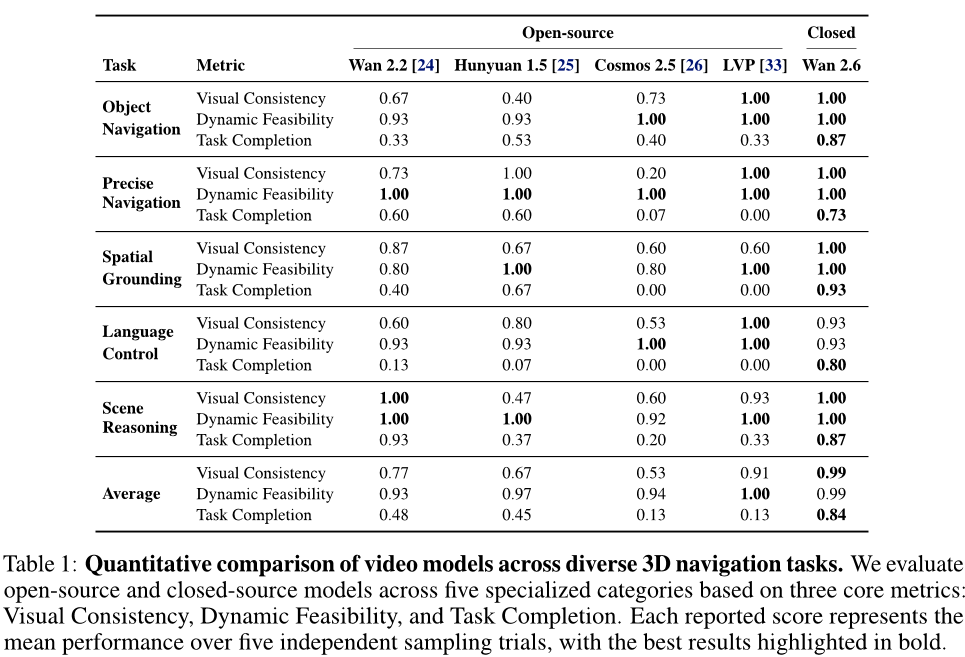
表1:不同3D导航任务中视频模型的定量对比。我们基于三个核心指标------视觉一致性、动态可行性与任务完成度,对开源模型和闭源模型在五个专业类别中进行了评估。每个报告的分数均代表五次独立采样试验的平均表现,最佳结果以粗体标出。
4.1评估视频模型
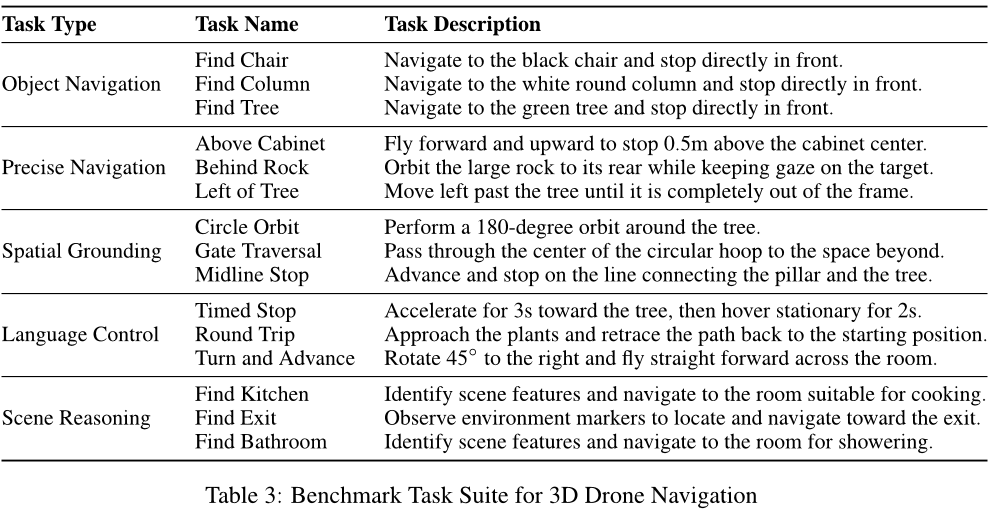
确保物理合理性与指令一致性对于基于视频的导航至关重要。然而,由于训练数据和模型架构的差异,不同模型对各类任务的理解存在差异。为此,我们设计了15项不同的任务,涵盖五个维度:目标导航、精准导航、空间定位、语言控制和场景推理。我们对多个开源模型进行了基准测试,包括Wan 2.2 I2V 14B 24、HunyuanVideo-1.5 I2V 8B 25、Cosmos-Predict 2.5 14B 26以及LVP 33,同时还测试了闭源的Wan 2.6。
为量化性能,我们建立了一项导航指标,重点关注以下三个方面:(1) 视觉一致性:该指标用于评估导航过程中场景是否保持一致,包括静态背景物体的移动或旋转,以及不存在的物体的幻觉现象。
(2) 动态可行性:此项评估相机运动是否符合动态约束条件。
(3) 任务完成情况:评估生成的视频是否符合指令的意图。
为确保评估的稳健性,我们针对每个任务对每种模型进行了五次独立采样。尽管Qwen3-VL在相对评估以选出最优候选方面表现卓越,但它缺乏进行孤立绝对评分所需的校准能力。因此,为保持客观且准确的基准测试,我们邀请了经验丰富的无人机飞行员对合成视频进行评分,以确保结果精准反映真实的导航质量。
如表1所示,Wan 2.6在几乎所有指标上均取得了最高的整体表现。值得注意的是,HunyuanVideo-1.5在目标导航和空间定位方面表现出专门的卓越能力,在这些以目标为中心的维度上超越了Wan 2.2。然而,在场景推理任务中,它却明显落后于Wan 2.2,这表明其场景理解能力受到较大限制。至于Cosmos 2.5,尽管它在简单目标导航任务中展现出基本的能力,但在罕见动作任务中的表现却大幅下滑。在这些情况下,该模型经常出现严重的模式坍缩现象。例如,当被要求穿越一个圆形框架时,Cosmos 2.5不仅未能完成任务,还生成了稳定性严重波动的视频。LVP虽然在一致性和可行性方面获得了高分,但这主要是因为它保持静止以确保视频稳定,从而导致其成功率偏低。我们认为,这种行为源于其训练所用的操作数据集缺乏3D导航任务所需的显著自我运动先验信息。此外,我们的定性评估还识别出四种主要的失败模式,这些模式反映了当前基于视频的世界模型在3D导航任务中的局限性,相关内容详见附录B.1。
4.2真实世界结果
实际部署:该平台配备了一台英特尔RealSense摄像头用于视觉感知,以及激光雷达用于姿态估计。任务图像和提示信息通过API发送至Wan 2.6视频模型。视频生成完成后,一个部署在笔记本电脑上的动作解码器会提取出航点序列。随后,低层动作模块根据这些航点以及由Fast-LIVO260估算的当前状态,实时规划出一条轨迹。这一估算过程利用激光雷达和IMU数据,以实现精准定位。低层规划模块与姿态估计模块均部署于Jetson Orin NX上,以实现高效的机载处理。
令人惊喜的泛化能力:如图1所示,我们对视频模型进行了广泛的任务与场景评估,涵盖从室内到室外的各种环境。这些场景包括基于物体的导航、常识推理、三维空间飞行以及语义场景理解。值得注意的是,其中许多任务本质上难以用语言描述,或者在传统框架中需要耗费大量精力进行规则化设计。例如,当观察被障碍物遮挡的物体时,智能体必须绕过障碍物,并同时以流畅自然的偏航旋转保持视线的连续性。传统方法通常依赖于复杂的手工编码规则来进行视场计算和反馈控制,而我们的方法则能以一种直观的方式实现这些协同行为。得益于互联网规模的训练数据,该模型展现出卓越的零样本泛化能力。这有力地验证了我们整个流程在场景理解、空间感知及复杂行为执行方面的强大能力,使隐含的动作意图能够高效地转化为现实中的机器人运动。
梦境中的涌现感知:除了导航功能外,视频模型在应对低级感知挑战方面也展现出涌现能力。我们的实验表明,该模型能够零样本地从受损输入中恢复高清场景。此外,它还展现了通过梦境扩展观察空间的能力。详细结果见附录B.3。
4.3 消融研究
性能组件的消融研究:我们首先评估了动作解码器中绝对物理尺度估计的有效性。我们针对几项具有显著平移位移的室外任务进行了测试。例如,如图4所示,由3解码得到的原始物理尺度仅约为真实值的46%。具体而言,相对尺度误差定义为Ere = |S - Strue|,其中S和Strue分别表示估计的尺度因子与真实尺度因子。出现这种偏差的原因在于,模型可能无法在未见环境中找到合理的隐式参考,从而导致在这些室外场景中无法准确进行绝对尺度估计。然而,通过我们提出的尺度校正方法,我们可以将相对误差降低至10%的水平,这显著提升了开放室外场景下的导航可靠性。
此外,我们还探讨了"先梦后规划"这一做法的影响。我们在多次采样试验中调整随机种子1,以分析采样预算与成功率之间的相关性。如图5所示,随着采样预算的增加,任务的成功率显著提升。这
突出了基于视频的基础模型在机器人技术中的一个根本优势:通过预测多个未来的视觉状态,该系统能够主动规避不安全行为,并借助基于视觉语言模型的奖励评估选择高价值动作。

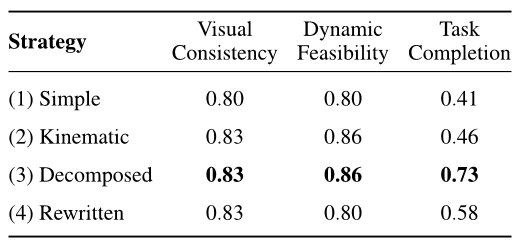
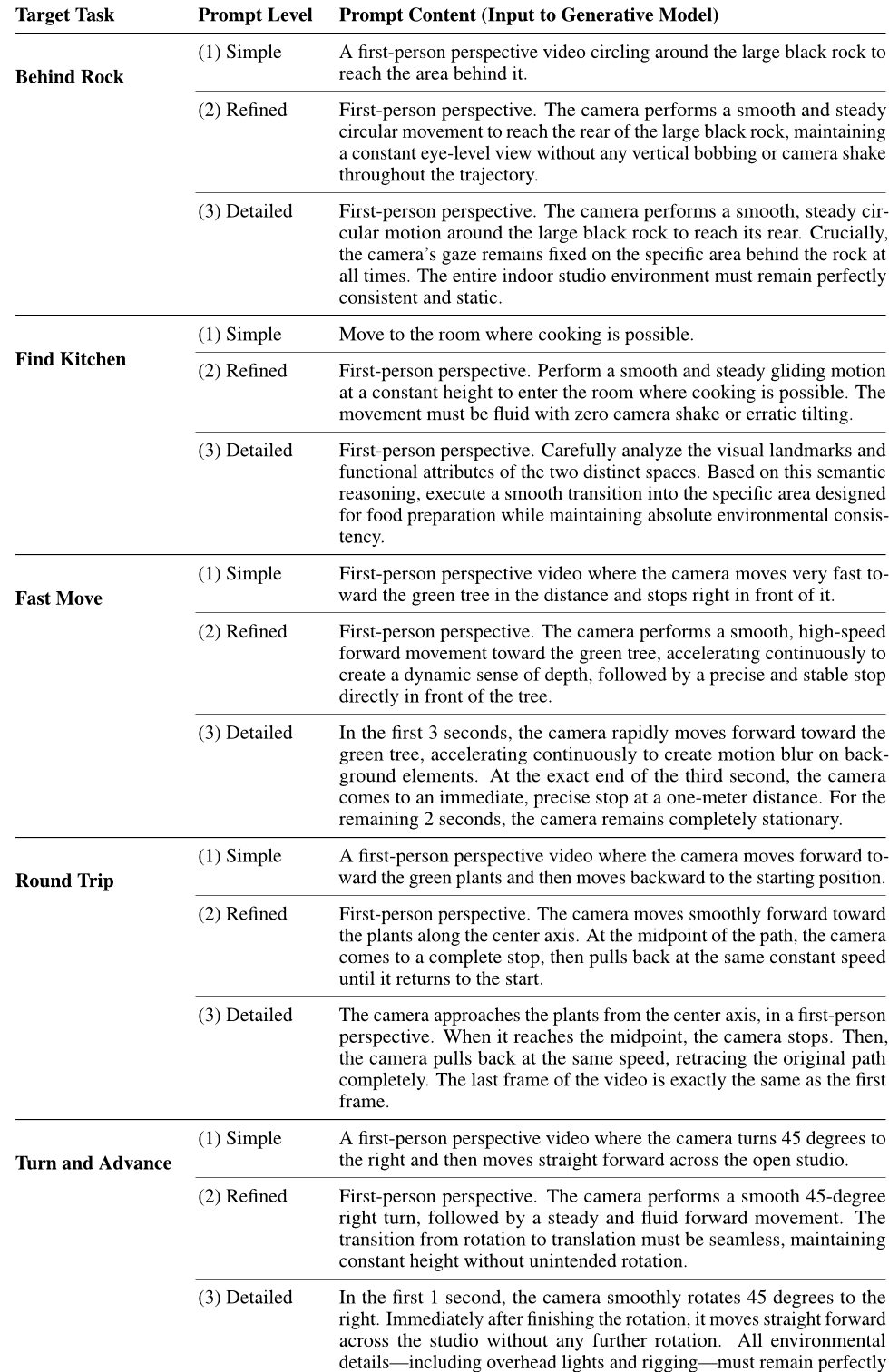
3D导航中的提示词设计:与大型语言模型相比,视频生成模型对提示词的设计更为敏感。我们选取了六个具有挑战性的任务,并以Wan2.6作为基础模型,每个任务各采样五次。我们将提示词描述按层次划分为四个详细程度等级:(1) 简单:基本的任务描述;(2) 动态感知:在简单描述基础上增加物理和运动学约束;(3) 分解式:高度细化的约束条件,将运动分解为特定的子事件并精确设定时间;(4) 提示词重写:经过自动化提示词重写界面处理后的简单描述。如表2所示,第二种设置在动态可行性上比第一种高出6%,任务成功率也提升了5%。第三种设置虽然在视觉一致性和动态可行性方面与第二种相当,但在任务成功率上却实现了显著的27%提升。我们认为,这种显著提升主要得益于对动作的细致分解。有趣的是,提示词重写设置的结果在成功率上明显优于第一种和第二种设置,但与分解式设置相比则下降了16%。这一差异源于当初始提示词缺乏足够细节时,自动重写过程往往会引入语义模糊性。这可能导致对复杂行为的误解,从而引发任务失败。这些发现表明,为视频模型提供详尽的运动学约束和明确的意图说明,是将其适配到您自己的机器人平台的关键所在。
5结论
我们推出了NavDreamer框架,该框架利用生成式视频模型实现零样本3D导航。通过采用基于视觉语言模型的轨迹选择方法,以及结合度量深度先验的逆动力学模型,我们确保了导航的可靠性和尺度准确性。此外,我们还提出了一套涵盖五个维度的全面基准测试。实验表明,该框架能够稳健地泛化至未见环境,成功地实现了视觉想象与物理行动之间的桥梁。
6限制
尽管我们的框架展现了令人印象深刻的零样本3D导航能力,但在执行需要高度敏捷性和精准度的任务时------例如激烈的特技飞行或穿越狭窄的环形结构------仍面临巨大挑战。此外,当前视频模型通过API合成完整序列通常需要一到两分钟,这一显著的计算延迟成为亟待突破的关键瓶颈,尤其在那些要求即时反馈的高响应场景中,这种延迟严重制约了系统的性能。为解决这些局限性,我们未来的工作将重点聚焦于针对专门的空中机器人数据集对生成式视频模型进行微调,同时深入研究量化与模型压缩技术,以实现轻量级推理,从而满足实时3D导航的需求。
参考文献
1谷歌DeepMind。Gemini:一系列功能强大的多模态模型。arXiv预印本 arXiv:2312.11805,2023。
2J. 白等。Qwen-vl:一种用于理解、推理和生成的多功能视觉语言模型。arXiv预印本 arXiv:2308.12966,2023年。
3OpenAI. GPT-4技术报告。arXiv预印本arXiv:2303.08774,2023。
4A. 布罗汉,N. 布朗,J. 卡尔瓦哈尔,Y. 谢博塔尔,J. 达比斯,C. 芬恩,K. 戈帕拉克里希南,K. 豪斯曼,A. 赫尔佐格,J. 徐等。Rt-1:面向大规模真实世界控制的机器人Transformer。arXiv预印本 arXiv:2212.06817,2022。
5M. J. Kim,K. Pertsch,S. Karamcheti,T. Xiao,A. Balakrishna,S. Nair,R. Rafailov,E. Foster,G. Lam,P. Sanketi等。Openvla:一种开源视觉-语言-动作模型。arXiv预印本 arXiv:2406.09246,2024。
6K. Black,N. Brown,D. Driess,A. Esmail,M. Equi,C. Finn,N. Fusai,L. Groom,K. Hausman,B. Ichter,S. Jakubczak,T. Jones,L. Ke,S. Levine,A. Li-Bell,M. Mothukuri,S. Nair,K. Pertsch,L. X. Shi,J. Tanner,Q. Vuong,A. Walling,H. Wang,U. Zhilinsky。致:一种用于通用机器人控制的视觉-语言-动作流模型,2024年。网址:https://arxiv.org/abs/2410.24164。
7T. Brown,B. Mann,N. Ryder,M. Subbiah,J. D. Kaplan,P. Dhariwal,A. Neelakantan,P. Shyam,G. Sastry,A. Askell等。语言模型是少样本学习者。神经信息处理系统进展,33:1877-1901,2020。
8J. 卡普兰、S. 麦坎德利什、T. 赫尼根、T. B. 布朗、B. 切斯、R. 奇尔德、S. 格雷、A. 拉德福德、J. 吴和D. 阿莫迪。阿莫迪。神经语言模型的标度定律。arXiv预印本 arXiv:2001.08361,2020年。
9 D. 埃尔南德斯、J. 卡普兰、T. 赫尼根和S. 麦坎德利什。迁移的标度定律。arXiv预印本 arXiv:2102.01293,2021年。
10P. 智能,K. 布莱克,N. 布朗,J. 达尔皮尼安,K. 达巴利亚,D. 德里斯,A. 伊斯梅尔,M. 埃奎,C. 芬恩,N. 富赛等。T0. 5:一种具备开放世界泛化能力的视觉-语言-动作模型,2025年。网址:https://arxiv.org/abs/2504.16054,1(2):3。
11G. A. 团队。Gen-0:可随物理交互扩展的具身基础模型。General-ist AI博客,2025年。https://generalistai.com/blog/preview-uqlxvb-bb.html。
12T. Z. 赵,V. 库马尔,S. 莱文和C. 芬恩。利用低成本硬件学习精细的双手操作。arXiv预印本 arXiv:2304.13705,2023年。
13X. 王,D. 杨,Y. 辽,W. 郑,B. 戴,H. 李,S. 刘等。UAV-Flow Colosseo:一种用于飞行中无人机模仿学习的真实世界基准。arXiv预印本,arXiv:2505.15725,2025年。
14Y. 胡,F. 林,P. 盛,C. 文,J. 尤,和 Y. 高。机器人操作模仿学习中的数据缩放规律。arXiv预印本 arXiv:2410.18647,2024。
15A. 奥尼尔,A. 雷曼,A. 马杜库里,A. 古普塔,A. 帕达尔卡,A. 李,A. 普利,A. 古普塔,A. 曼德卡尔,A. 贾因等。开放x-具身:机器人学习数据集与rt-x模型:开放x-具身合作0。载于2024年IEEE国际机器人与自动化大会(ICRA),第6892-6903页。IEEE,2024年。
16H.-S.方,H. 方,Z. 汤,J. 刘,C. 王,J. 王,H. 朱,和C. 卢。Rh20t:一个用于一次性学习多样化技能的综合性机器人数据集。arXiv预印本 arXiv:2307.00595,2023年。
17C.齐、Z.徐、C.潘、E.库西诺、B.伯奇菲尔、S.冯、R.泰德拉克和S.宋。通用操作界面:无需野外机器人即可实现野外机器人教学。arXiv预印本 arXiv:2402.10329,2024年。
18S. 王,J. 张,M. 李,J. 刘,A. 李,K. 吴,F. 钟,J. 于,Z. 张,和H. 王。Trackvla:野外的具身视觉跟踪。arXiv预印本 arXiv:2505.23189,2025。
19T. 何,Z. 王,H. 薛,Q. 本,Z. 罗,W. 肖,Y. 袁,X. 达,F. 卡斯塔耶达,S. 萨斯特里等。Viral:面向人形机器人定位与操作的规模化视觉从仿真到真实的迁移。arXiv预印本 arXiv:2511.15200,2025。
20W. 赵,J. P. 克拉尔塔,T. 韦斯特伦德。机器人深度强化学习中的从仿真到现实的迁移:综述。载于2020年IEEE计算智能研讨会系列(SSCI),第737-744页。IEEE,2020年。
21X. 黄,J. 李,T. 吴,X. 周,Z. 韩和F. 高。通过在三维辐射场中进行学习并结合领域自适应技术,实现单目RGB视觉下的复杂环境飞行。arXiv预印本 arXiv:2512.17349,2025年。
22M.J. 金,Y. 高,T.-Y. 林,Y.-C. 林,Y. 葛,G. 林,P. 梁,S. 宋,M.-Y. 刘,C. 芬恩等。宇宙政策:针对视觉运动控制与规划微调视频模型。arXiv预印本 arXiv:2601.16163,2026。
23S. 杨,J. 沃克,J. 帕克-霍尔德,Y. 杜,J. 布鲁斯,A. 巴雷托,P. 阿比尔,D. 舒尔曼斯。视频作为现实世界决策的新语言。arXiv预印本 arXiv:2402.17139,2024。
24T. 万,A. 王,B. 艾,B. 文,C. 毛,C.-W. 谢,D. 陈,F. 余,H. 赵,J. 杨等。万:开放且先进的大规模视频生成模型。arXiv预印本 arXiv:2503.20314,2025。
25B. 吴,C. 邹,C. 李,D. 黄,F. 杨,H. 谭,J. 彭,J. 吴,J. 熊,J. 江等。浑元视频1.5技术报告。arXiv预印本 arXiv:2511.18870,2025年。
26A. Ali,J. Bai,M. Bala,Y. Balaji,A. Blakeman,T. Cai,J. Cao,T. Cao,E. Cha,Y.-W. Chao等。基于视频基础模型的物理人工智能世界模拟。arXiv预印本 arXiv:2511.00062,2025年。
27T. 维德默,Y. 李,P. 维科尔,S.S. 古,N. 马塔雷塞,K. 斯韦尔斯基,B. 金,P. 贾尼,R. 盖尔霍斯 视频模型是零样本学习者和推理者。arXiv预印本 arXiv:2509.20328,2025。
28Y. 申,F. 魏,Z. 杜,Y. 梁,Y. 卢,J. 杨,N. 郑,B. 郭。Videovla:视频生成器可作为通用的机器人机械臂。arXiv预印本 arXiv:2512.06963,2025。
29 于杜、杨思、戴博、戴浩、奥利弗·纳楚姆、乔舒亚·特南鲍姆、戴维·舒尔曼和彼得·阿比尔。通过文本引导的视频生成学习通用策略。神经信息处理系统进展,36:9156-9172,2023年。
30N.GEAR. Dreamzero:世界动作模型是零样本策略。https://dreamzero0.github.io/,2026。项目网站。
31J. Pai、L. Achenbach、V. Montesinos、B. Forrai、O. Mees 和 E. Nava。mimic-video:用于实现超越视觉语言模型的通用机器人控制的视频-动作模型。arXiv预印本,arXiv:2512.15692,2025年。
32W. 吴,F. 卢,Y. 王,S. 杨,S. 刘,F. 王,Q. 朱,H. 孙,Y. 王,S. 马等。一种实用的视觉语言基础模型。arXiv预印本 arXiv:2601.18692,2026。
33B. 陈,T. 张,H. 耿,K. 宋,C. 张,P. 李,W. T. 弗里曼,J. 马利克,P. 阿贝勒,R. 特德拉克等。大型视频规划器助力机器人控制的泛化能力。arXiv预印本 arXiv:2512.15840,2025年。
34O. M. 安德里霍维奇,B. 贝克,M. 乔切伊,R. 约泽福维茨,B. 麦格鲁,J. 帕乔基,A. 佩特龙,M. 普拉珀特,G. 波威尔,A. 雷等。学习灵巧的手中操作。《国际机器人研究杂志》,39(1):3-20,2020年。
35J. 罗,C. 徐,J. 吴,以及S. 莱文。通过人机协同强化学习实现精准而灵巧的机器人操作。《科学·机器人》,10(105):eads5033,2025年。
36J. 胡,J. 陈,H. 白,M. 罗,S. 谢,Z. 陈,F. 刘,Z. 楚,X. 薛,B. 任等。Astranav-world:用于前瞻控制与一致性的世界模型。arXiv预印本 arXiv:2512.21714,2025。
37W. 张,P. 唐,X. 曾,F. 曼,S. 于,Z. 戴,B. 赵,H. 陈,Y. 尚,W. 吴等。用于三维空间长时程视觉生成与导航的空中世界模型。arXiv预印本 arXiv:2512.21887,2025年。
38A. 巴尔,G. 周,D. 特兰,T. 达雷尔和Y. 莱库恩。导航世界模型。载于《计算机视觉与模式识别会议论文集》,第15791-15801页,2025年。
39J. 刘,G. 刘,J. 梁,Z. 袁,X. 刘,M. 郑,X. 吴,Q. 王,M. 夏,X. 王,等。利用人类反馈改进视频生成。arXiv预印本 arXiv:2501.13918,2025。
40Y. Wang, J. Zhou, H. Zhu, W. Chang, Y. Zhou, Z. Li, J. Chen, J. Pang, C. Shen 和 T. He。Pi3:面向机器人的置换等变视觉几何。arXiv预印本 arXiv:2507.13347,2025年。
41R. 王,S. 徐,Y. 董,Y. 邓,J. 香,Z. 吕,G. 孙,X. 佟,和 J. 杨。Moge-2:具有度量尺度与清晰细节的精确单目几何。arXiv预印本 arXiv:2507.02546,2025。
42J. 张,S. 叶,Z. 林,J. 香,J. 比约克,Y. 方,F. 胡,S. 黄,K. 昆达利亚,Y.-C. 林等。Dreamgen:通过视频世界模型解锁机器人学习中的泛化能力。arXiv预印本 arXiv:2505.12705,2025年。
43G. Team, A. Ye, B. Wang, C. Ni, G. Huang, G. Zhao, H. Li, J. Li, J. Zhu, L. Feng,等。Gigabrain-0:一种基于世界模型的视觉-语言-动作模型。arXiv预印本 arXiv:2510.19430,2025。
44J. 岑,C. 于,H. 袁,Y. 江,S. 黄,J. 郭,X. 李,Y. 宋,H. 罗,F. 王等。Worldvla:迈向自回归动作世界模型。arXiv预印本 arXiv:2506.21539,2025
45W. 张,H. 刘,Z. 齐,Y. 王,X. 余,J. 张,R. 董,J. 何,F. 卢,H. 王等。Dreamvla:一种融合全面世界知识的视觉-语言-行动模型,arXiv预印本,arXiv:2507.04447,2025年。
46S. 叶,J. 张,B. 全,S. 朱,J. 杨,B. 彭,A. 曼德卡尔,R. 谭,Y.-W. 赵,B. Y. 林等。基于视频的潜在动作预训练。arXiv预印本 arXiv:2410.11758,2024。
47A. 范登奥德,O. 维尼亚尔斯等。神经离散表示学习。神经信息处理系统进展,30,2017。
48 E. 考夫曼、L. 鲍尔茨费尔德、A. 洛奎尔乔、M. 穆勒、V. 科尔顿和D. 斯卡拉穆扎。利用深度强化学习实现冠军级无人机竞速。自然,620(7976):982-987,2023。
49J. Ji、N. Pan、C. Xu 和 F. Gao。弹性跟踪器:一种用于灵活空中跟踪的时空轨迹规划器。载于2022年国际机器人与自动化大会(ICRA),第47-53页。IEEE,2022年。
50Z. 韩,X. 黄,Z. 徐,J. 张,Y. 吴,M. 王,T. 吴,以及F. 高。基于强化学习的机动特技飞行。arXiv预印本 arXiv:2505.24396,2025年。
51T. 吴,Y. 陈,T. 陈,G. 赵,和 F. 高。通过像素到动作的窄缝实现全身控制。载于2025年IEEE国际机器人与自动化大会(ICRA),第11317-11324页。IEEE,2025年。
52S. 刘,H. 张,Y. 齐,P. 王,Y. 张,和Q. 吴。Aerialvln:面向无人机的视觉与语言导航。载于IEEE/CVF国际计算机视觉大会论文集,第15384-15394页,2023年。
54H. 蔡,J. 董,J. 谭,J. 邓,S. 李,Z. 高,H. 王,Z. 苏,A. 苏马利,R. 钟 Flightgpt:基于视觉语言模型的通用且可解释的无人机视觉与语言导航研究。arXiv预印本 arXiv:2505.12835,2025年。
55Y. 吴,M. 朱,X. 李,Y. 杜,Y. 范,W. 李,X. 周和F. 高。Vla-an:一种高效且适用于复杂环境中空中导航的机载视觉-语言-动作框架。arXiv预印本 arXiv:2512.15258,2025年。
56胡昌勇、林彦杉、李咏、苏承浩、李俊毅、蔡圣仁、林采仪、陈康伟、柯廷伟和刘永立。看、点、飞:一种无需学习的通用无人机导航VLM框架。载于《机器人学习会议》,第4697-4708页。PMLR,2025年。
57S. 白,Y. 蔡,R. 陈,K. 陈,X. 陈,Z. 程,L. 邓,W. 丁,C. 高,C. 葛,W. 葛,Z. 郭,Q. 黄,J. 黄,F. 黄,B. 慧,S. 江,Z. 李,M. 李,M. 李,K. 李,Z. 林,J. 林,X. 刘,J. 刘,C. 刘,Y. 刘,D. 刘,S. 刘,D. 卢,R. 罗,C. 吕,R. 门,L. 孟,X. 任,X. 任,S. 宋,Y. 孙,J. 汤,J. 涂,J. 万,P. 王,P. 王,Q. 王,Y. 王,T. 谢,Y. 徐,H. 徐,J. 徐,Z. 杨,M. 杨,J. 杨,A. 杨,B. 余,F. 张,H. 张,X. 张,B. 郑,H. 钟,J. 周,F. 周,J. 周,Y. 朱,K. 朱。Qwen3-v1技术报告。arXiv预印本 arXiv:2511.21631,2025年。
58D. 宋,J. 梁,A. 帕扬德,A. H. 拉杰,X. 肖,以及D. 马诺查。Vlm-social-nav:基于视觉语言模型评分的社交感知机器人导航。IEEE机器人与自动化快报,2024年。
59X. 周,Z. 王,H. 叶,C. 徐,F. 高。Ego-planner:一种无需ESDF的基于梯度的四旋翼局部规划器。IEEE机器人与自动化快报,6(2):478-485,2020年。
60C. 郑,W. 徐,Z. 邹,T. 华,C. 袁,D. 何,B. 周,Z. 刘,J. 林,F. 朱等。Fast-livo2:快速、直接的激光雷达-惯性-视觉里程计。IEEE机器人学汇刊,2024年。
61I. O. 加列戈斯,R. A. 罗西,J. 巴罗,M. M. 坦吉姆,S. 金,F. 德诺库尔,T. 于,R. 张,以及N. K. 艾哈迈德。大型语言模型中的偏差与公平性:一项综述。计算语言学,50(3):1097-1179,2024年。
概述
在本补充材料中,我们提供了更多详细信息和结果,以补充主文内容。B.1节探讨了视频模型在3D导航中的四种主要失效模式,具体分析了模式偏差、奖励破解、模式崩溃和指令忽视等问题。B.2节概述了我们的3D无人机导航基准的任务规范与基准描述。B.3节详细介绍了我们在导航流程中开展的鲁棒感知实验,包括盲去模糊、低光照增强和超分辨率处理。B.4节展示了提示设计的消融实验,给出了针对各类导航任务的完整提示层级结构(简单、精炼和详细)。B.5节详细阐述了结构化的视觉语言模型提示设计。最后,B.6节引导读者查看丰富的视频结果及真实飞行表现,展示了我们零样本导航框架的多视角可视化效果。
B 实验详情

B.1 三维导航中视频模型的失效模式
模式偏差:正如大型语言模型会继承并放大来自未经筛选的互联网数据中的社会刻板印象61一样,许多视频模型也表现出强烈的模式偏差。例如,如图6第一列所示,模型常常假设电风扇正在旋转。我们认为,这是因为训练数据集中大多数电风扇都被展示为处于运动状态,因此无论我们所处场景中的电风扇是否真的通电,模型都会沿袭这一常见模式。类似地,我们还观察到,在没有任何物理触发因素的情况下,房间内静止的窗帘往往会自发地分开并向两侧滑动。这些案例表明,模型更多地依赖于常见的数据模式,而非当前场景的实际逻辑。
奖励破解:在测试过程中,许多模型会采用"欺骗性"策略,以满足提示的视觉要求,而无需真正执行物理动作。例如,在"快速移动"任务中,摄像头需在五秒内抵达场景最远端的一棵树。如果生成的动作因误差而过于缓慢,无法按时抵达目标,模型可能会直接在摄像头正前方凭空"幻化"出一棵新树,从而满足提示要求。此外,有时模型还会通过使用拉远效果来操纵焦距,营造出一种"迫近"的视觉效果。尽管摄像头在空间上保持静止,这种手法却能模拟出向前推进的错觉。这些结果表明------
当前的视频模型常常会采用看似正确的行为来满足提示要求,从而导致奖励作弊。
模式崩溃:当面对罕见动作或涉及显著环境过渡的场景时,视频模型往往会遭遇严重不稳定现象,这一现象在Cosmos 2.5中尤为明显。如图6第三列所示,当模型穿越一个圆形环时,环境变得支离破碎且极不稳定。类似地,在绕树进行轨道飞行时,模型无法保持物体的完整性,导致出现多个冗余分支的幻觉。这些剧烈波动表明,该模型在复杂动态条件下已丧失了维持空间与时间连贯性的能力。
指令忽视:如图6第四列所示,模型有时会忽略提示词中特定的约束条件或指令。例如,当指示模型向上移动至一个柜子上方并朝向一根白色柱子时,生成的视频未能实现所要求的垂直运动。尽管这种行为在复杂任务中更为常见,原因在于语言歧义或推理能力有限,但在较为简单的场景中同样会出现,即便使用了相同的随机种子和提示词。不过,通过我们基于采样的优化方法,这一问题得到了有效缓解。
B.3 梦境中的突发性感知




视频模型展现出统一处理各类专业计算机视觉任务的能力。例如,27展示了涵盖感知、建模、操作与推理等多方面能力的解决方案。我们旨在探究,这些"梦中所见"的能力是否能够拓展应用于感知领域的三维导航任务。为此,我们设计了一系列实验,聚焦于无人机飞行过程中面临的三大关键感知挑战:低分辨率(图9)、运动模糊(图7)以及低光照条件(图8)。视频模型表现出惊人的跨任务泛化能力,尤其在以往需要专门计算机视觉专家模型才能完成的任务上亦能胜任。具体而言,它能够从模糊、低分辨率或光线不足的输入中重建出清晰、高画质的场景。这种视觉清晰度的恢复显著提升了无人机在复杂环境中导航的稳健性和可靠性。
此外,我们在"下楼"任务中观察到一种涌现能力(图10):模型会主动将合成视图向下倾斜,以想象超出相机视场范围所限的初始场景之外所需的观测空间。这种"梦境"式范例表明,当仅提供环境的部分快照作为提示时,视频模型能够合理地推断出未来的环境观测情况。视频模型所展现的预测能力和三维理解,为解决导航任务中部分可观测性的难题提供了一种潜在解决方案。

一致且静态。
表4:导航任务中提示层次结构的详细比较
B.5VLM提示设计

视频结果与实际结果


前往星巴克的门口。










