目录
[8. ELF ---- 重谈地址空间](#8. ELF ---- 重谈地址空间)
[8.1 ELF Header](#8.1 ELF Header)
[8.2 节:Section](#8.2 节:Section)
[8.3 程序表头:Program header table](#8.3 程序表头:Program header table)
[9. ELF从形成到加载轮廓](#9. ELF从形成到加载轮廓)
[9.1 ELF形成可执行](#9.1 ELF形成可执行)
[9.2 ELF 可执行文件加载](#9.2 ELF 可执行文件加载)
[10 理解链接与加载](#10 理解链接与加载)
[10.1 静态链接](#10.1 静态链接)
[10.2 虚拟地址/逻辑地址](#10.2 虚拟地址/逻辑地址)
[10.2.1 进程如何看待动态库](#10.2.1 进程如何看待动态库)
[10.2.2 重新理解进程虚拟地址空间](#10.2.2 重新理解进程虚拟地址空间)
如果要实现对应的库函数,在动静态库中,不准存在main函数,如果带上,其它文件相连接的时候就会出现问题。
8. ELF ---- 重谈地址空间
任何一个文件和目录都有它的 inode,包括刚刚的动态库静态库,都有自己对应的 inode
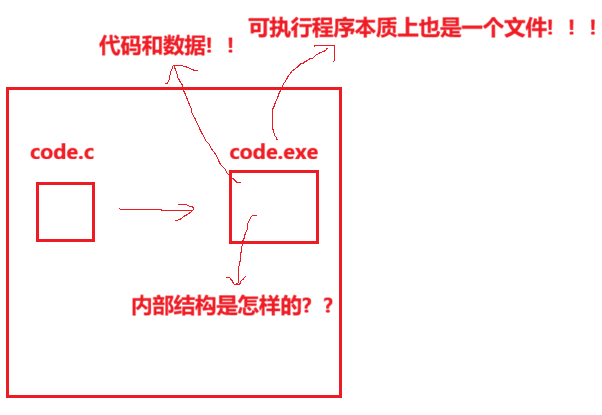
.o , .a , .so , .exe 二进制,都是以ELF的格式,存在于磁盘上
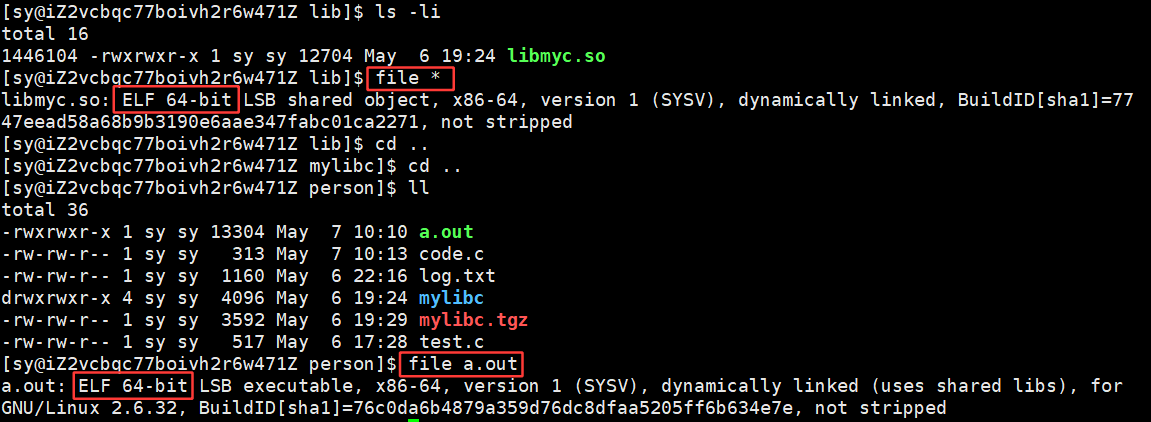
要理解编译链链接的细节,我们不得不了解⼀下ELF文件。其实有以下四种⽂件其实都是ELF文件:
- 可重定位文件(Relocatable File):即xxx.o 文件。包含适合于与其他目标文件链接来创建可执行文件或者共享目标文件的代码和数据。
- 可执行文件(Executable File):即可执行程序。
- 共享目标文件((Shared Object File):即xxx.so文件
- 内存转储(core dumps):存放当前进程的执行上下文,用于dump信号触发。
一个ELF文件由以下四部分组成:
- ELF头(ELF header):描述文件的主要特性。其位于文件的开始位置,它的主要目的是定位文件的其他部分。
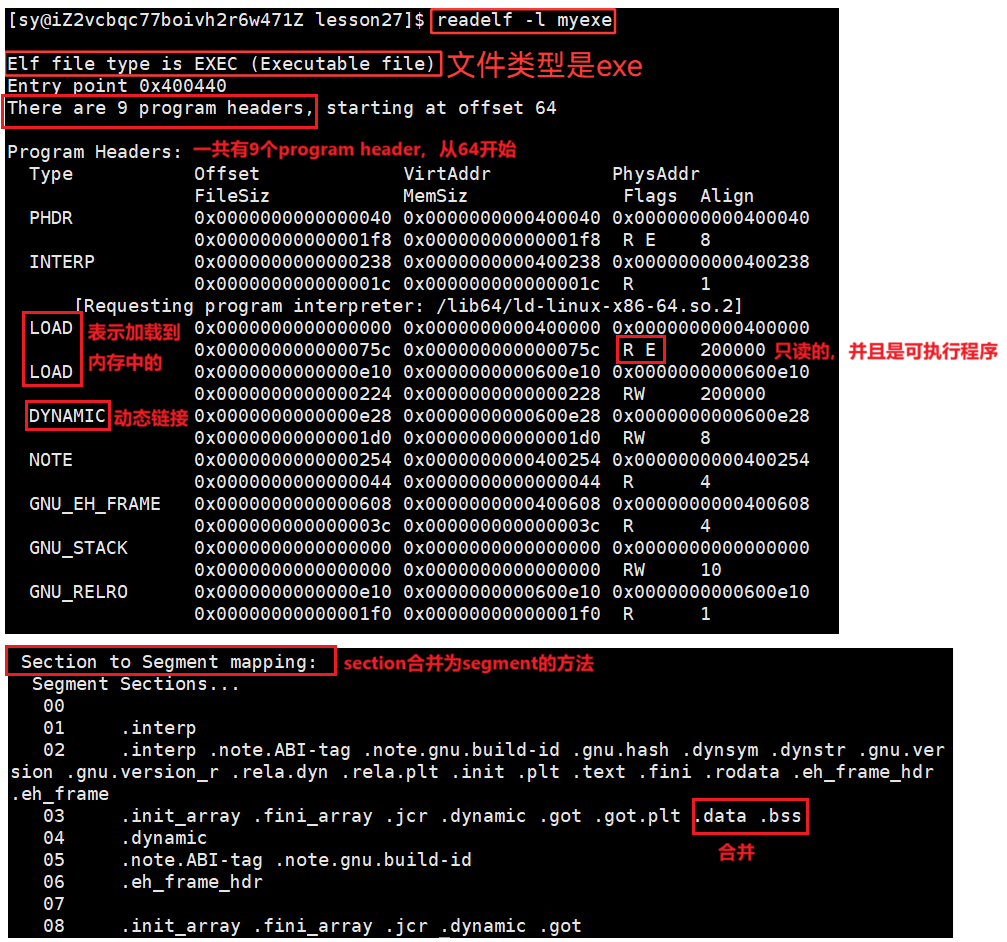
- 程序头表(Program header table):列举了所有有效的段(segments)和它们的属性。表里记着每个段的开始位置和位移(offset)、长度、毕竟这些段,都是紧密的放在二进制文件中,需要段表的描述信息,才能把它们每个段分割开。
- 节头表(Section header table):包含对节(section)的描述。
- 节(Section):ELF文件中的基本组成单位。包含了特定类型的数据。ELF文件的各种信息和数据都存储在不同的节中,如代码节存储了可执行代码,数据节存储了全局变量和静态数据等。
最常见的节:
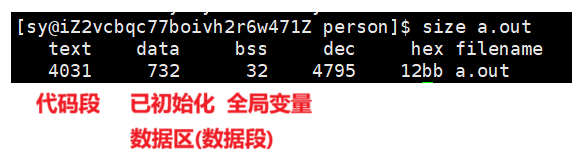
- 代码节(.text):用于保存机器指令,是程序的主要执行部分。
- 数据节(.data):保存已初始化的全局变量和局部静态变量。
一个可执行程序没有加载到内存时就已经有了代码段和数据段的概念了,如何确定??
所以,可执行程序是有自己的格式的,读取二进制文件里面是有自己特定的格式的,从哪里开始到哪里结束属于什么区域都是规定好的。代码和数据都是以section来存放好的。
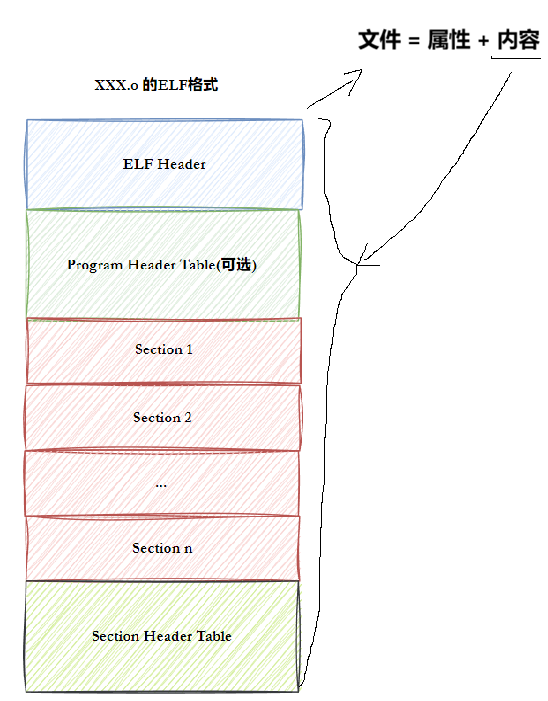
所以,ELF分为四部分,其实是把可执行程序的内容分为四部分,用的是文件系统,但是和文件系统无关。
只有源文件,没有头文件,但是方法实现有的话是可以直接链接的:
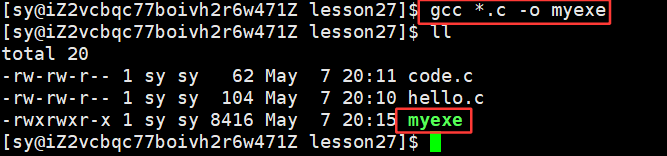


虽然打开myexe文件是乱码,但是却是有格式的!!
8.1 ELF Header
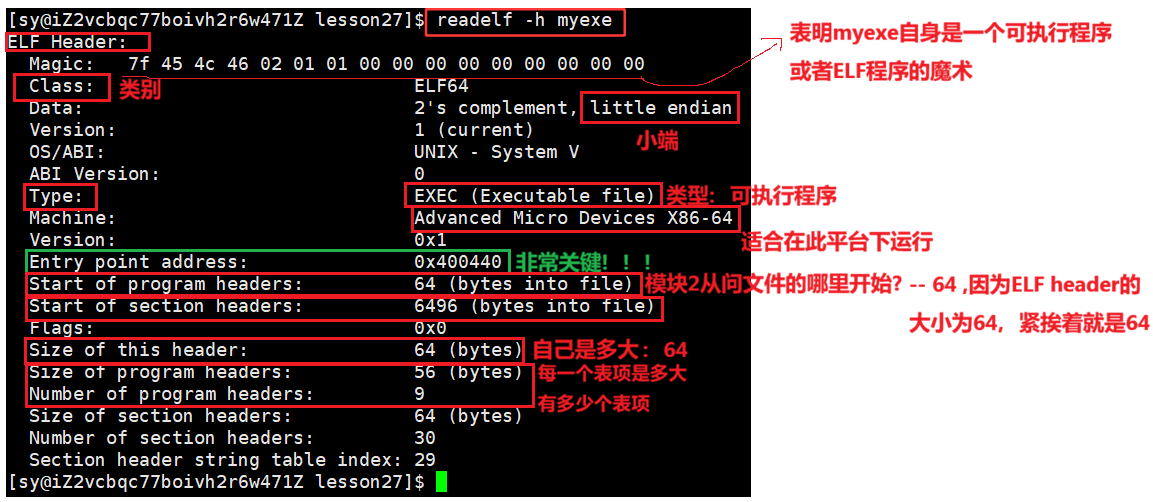
查看 ELF header的命令:
readelf -h 要访问的程序:显示ELF文件的文件头信息。文件头包含了ELF文件的基本信息,比如文件类型、机器类型、版本、入口点地址、程序头表和节点表的位置和大小等。


cpp
// 内核中关于ELF Header相关的数据结构
// 没错,操作系统自己必须能够识别特定格式的可执行程序:/linux/include/elf.h
typedef struct elf32_hdr {
unsigned char e_ident[EI_NIDENT];
Elf32_Half e_type;
Elf32_Half e_machine;
Elf32_Word e_version;
Elf32_Addr e_entry; /* Entry point */
Elf32_Off e_phoff;
Elf32_Off e_shoff;
Elf32_Word e_flags;
Elf32_Half e_ehsize;
Elf32_Half e_phentsize;
Elf32_Half e_phnum;
Elf32_Half e_shentsize;
Elf32_Half e_shnum;
Elf32_Half e_shstrndx;
} Elf32_Ehdr;
typedef struct elf64_hdr {
unsigned char e_ident[EI_NIDENT]; /* ELF "magic number" */
Elf64_Half e_type;
Elf64_Half e_machine;
Elf64_Word e_version;
Elf64_Addr e_entry; /* Entry point virtual address */
Elf64_Off e_phoff; /* Program header table file offset */
Elf64_Off e_shoff; /* Section header table file offset */
Elf64_Word e_flags;
Elf64_Half e_ehsize;
Elf64_Half e_phentsize;
Elf64_Half e_phnum;
Elf64_Half e_shentsize;
Elf64_Half e_shnum;
Elf64_Half e_shstrndx;
} Elf64_Ehdr;8.2 节:Section
一个一个的section称为一个一个的数据节,表示的是文件中的基本组成单位,包含特定类型的数据。ELF文件的各种信息和数据都存储在不同的节中,比如,编译代码时有代码区、代码中的全局变量和各种符号表,定义的字符串,调用的函数等等。
查看具体的 Section 信息:
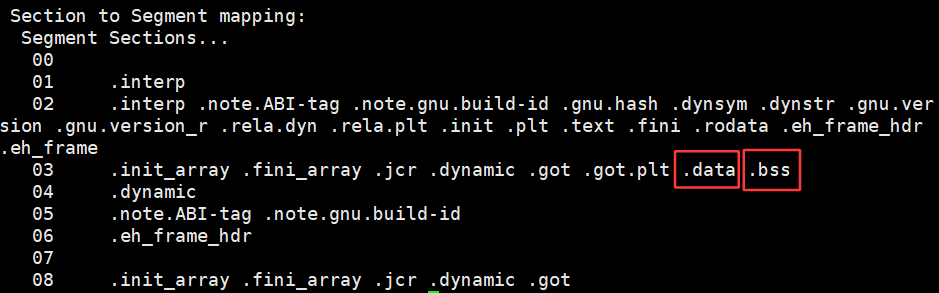
readelf -S myexe:-S不是用来读取一个一个的节,是用来读取Section Header Table 的,Section Header Table 描述的是整个ELF对应的整个的节相关的信息,一共有多少个节
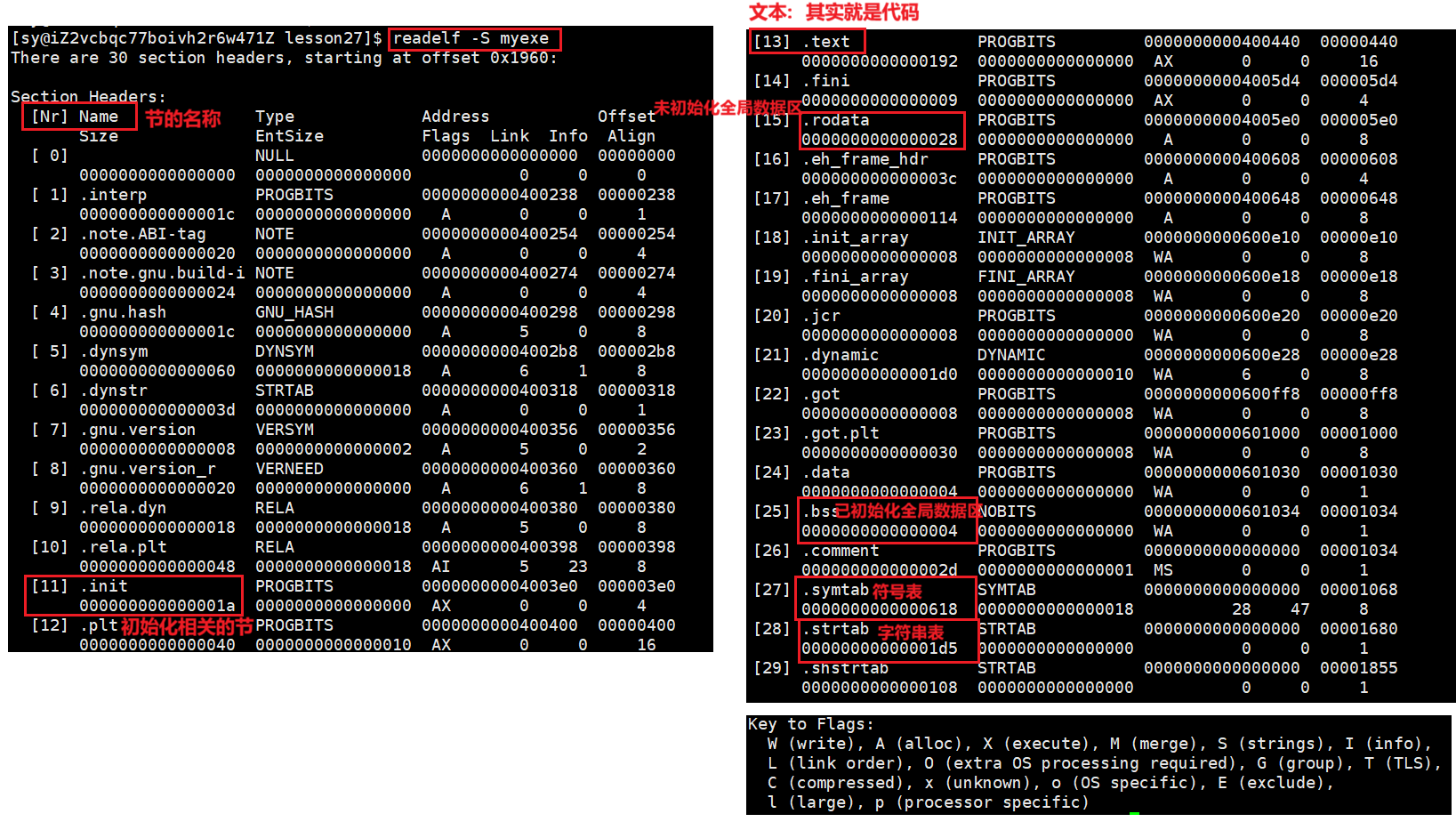
Section Header会记录下来一共有多少个节,每一个节叫什么?每一个节的起始偏移量是多少?都是会记录下来的

offset 表示的是对应的节在原始文件中的偏移量,把每一个节的起始地址都记录下来了,也记录了每一个节的大小,未来读取ELF Header就能找到Section Header Table,以此每一个Section就能读出来。
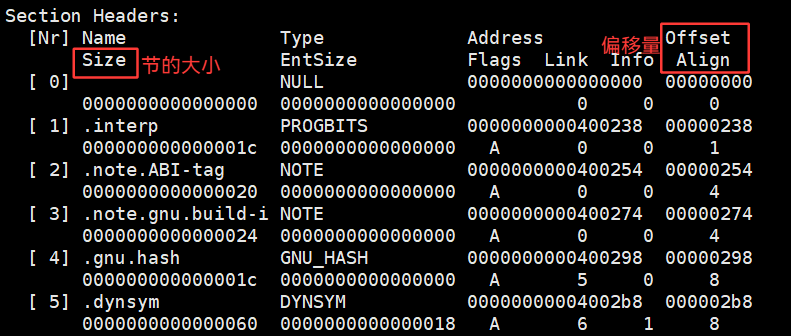
Flags:中X表示可执行的,A表示alloc表示需要自己在内存申请空间的,M表示的是需要合并的。
Section Header Table 本质也是一个结构体!!!
8.3 程序表头:Program header table
8.3.1 文件系统当中,可执行程序/文件它的内容存的就是ELF的内容,文件系统和磁盘进行IO的时候,是以4KB为基本单位进行IO的,所以当年磁盘块被格式化成了4KB,想把数据从磁盘搬到内存中,内存和磁盘都要以4KB为单位进行拷贝,复制、粘贴 。

**1. 所以,一个一个section,就一定是4KB的吗?? ---- 不是!!**如果一个一个节是4KB的话,在Section Header Table 中根本就不用记录下来在原始文件中的偏移量和对应的大小了。实际上是记录了下来,以此说明一个一个的section本身不一定是4KB的。
2. 多个section,可能会有相同的属性
前两点是在编译器的角度认为每一个section不一定的是4KB的,并且多个section会有相同的属性,section 1是代码区,section 6是字符常量,都是只读的,所以具有相同的属性,且两个大小都不是4KB的,可是在OS解读,进行IO的时候,必须是4KB的。
将一个一个 可执行程序ELF 加载到OS内时需要进行多section合并 ,合并成4KB对齐的大小,允许8KB、16KB,不允许是3KB。合并之后称为 segment(数据段)。所以,ELF加载到内存的时候,是会被OS自动合并成为多个Seg,加载到内存中!!!
那这里有许多的section,哪些节应该和哪些节进行合并呢?所以就得有一张合并的方法,合并的方法就是Program header Table,Program header Table记录的就是会形成多少个段,哪些section要合并,其实Program header Table就是一个合并成为Seg的方法表。
那么,合并是什么时候进行的,按照谁进行的???
----- 是在加载的时候合并的,是按照****Program header Table 记录下来合并的。换言之,在 ELF 里,只能看见合并前的一个一个section,看不见也不需要看到合并后的segment,在可执行程序中不需要记录一个一个被合并的segment,合并的segment是给内存/OS看的。
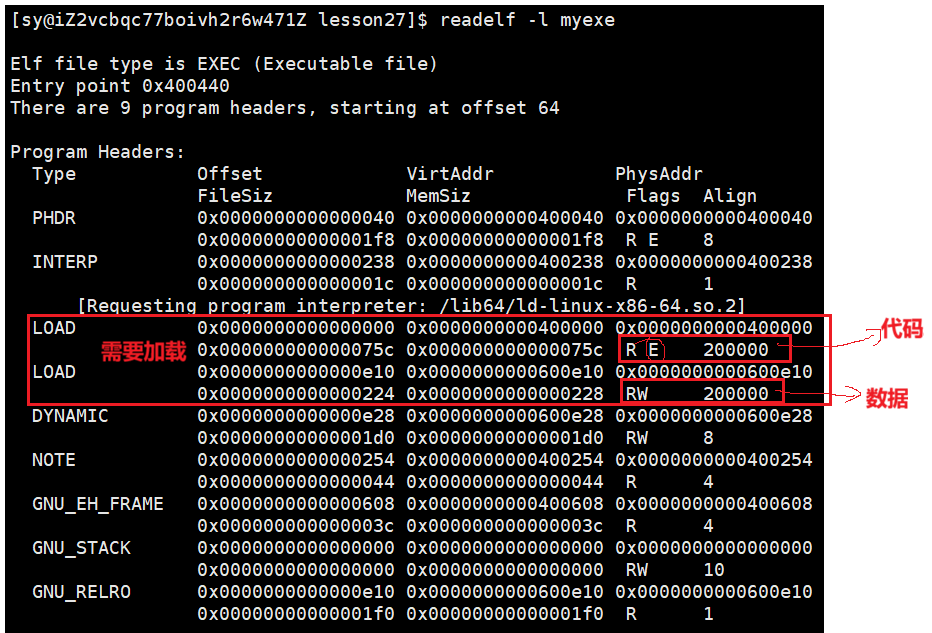
查看 Program header Table 的命令:
readelf -l myexe

9. ELF从形成到加载轮廓
9.1 ELF形成可执行
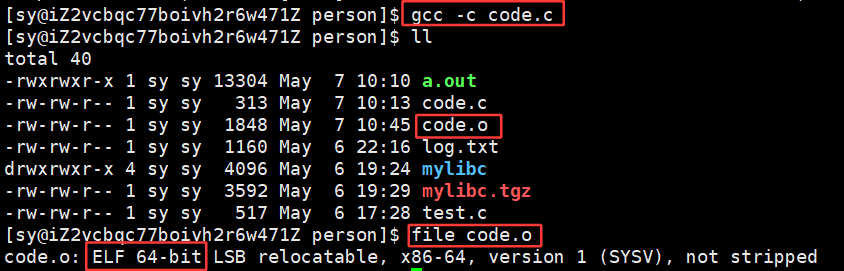
- 步骤1:将多份C/C++源代码,翻译成为目标 .o 文件 + 动静态库(ELF)
- 步骤2:将多份 .o 文件 section 进行合并
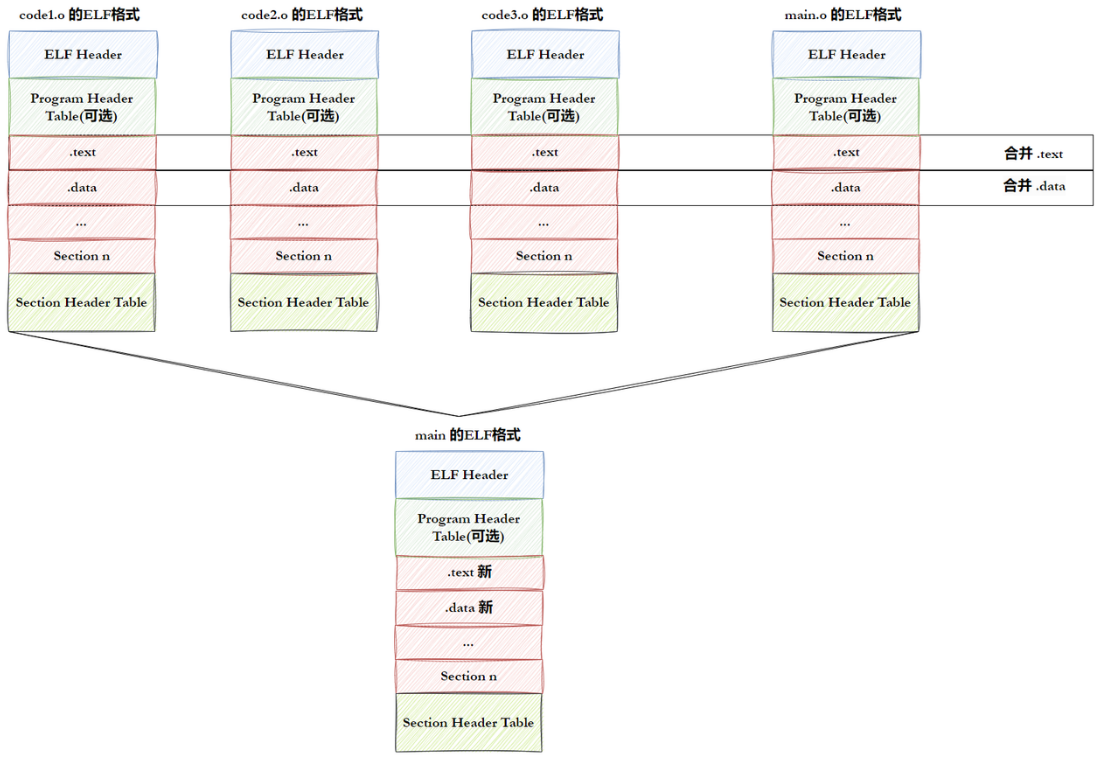
将所有的 .o 进行对应的链接,链接的本质就是把所有的 .o 文件的ELF 格式中的代码节合并形成一个更大的代码节,数据节形成一个更大的数据节,修改对应的管理属性,形成一个更大的ELF,这个工作就叫:链接!!!所以链接的本质就是所有的ELF的 .o 文件进行合并形成可执行程序。
动态库静态库也是 .o ,所以也能合并,也是ELF。目标文件,动静态库,可执行程序全都叫做ELF,能够进行.o 合并,因为都是ELF格式。
注意:
实际合并是在链接时进行的,但是并不是这么简单的合并,也是会涉及对库的合并,此处就不做过多的追究
9.2 ELF 可执行文件加载
- ⼀个ELF会有多种不同的Section,在加载到内存的时候,也会进行Section合并,形成segment(每一个segment也是有属性的)
- 合并原则:相同属性,比如:可读,可写,可执行,需要加载时申请空间等。
- 这样,即便是不同的Section,在加载到内存中,可能会以segment的形式,加载到⼀起
- 很显然,这个合并⼯作也已经在形成 ELF 的时候,合并⽅式已经确定了,具体合并原则被记录在了 ELF 的 程序头表(Program header table) 中
为什么要将 section 合并成为segment???
- Section合并的主要原因是为了减少页面碎片,提高内存使用效率。如果不进行合并,假设页面大小为4096字节(内存块基本大小,加载,管理的基本单位),如果.text部分为4097字节,.init 部分为512字节,那么它们将占用3个页面,而合并之后,它们只需要2个页面。
- 此外,OS在加载程序时,会将具有相同属性的section合并成为一个大的segment,这样就可以实现不同的访问权限,**(之前在创建进程时,虚拟地址空间形成页表,为什么页表就知道哪一个区域是只读的,哪一个区域是只写的....因为所对应的可执行程序在编译的时候,他已经交代清楚了对应的读、写、可执行,所以将可执行程序加载到内存的时候,OS读取ELF,读取ELF相关的报头section、segment的属性,用它的属性初始化页表,所以代码段才是只读的)**从而优化内存管理和权限访问控制。
- 所以在OS内加载的一个一个的segment,是以4KB为单位,是为了方便页表进行权限管理。
结论:
OS内的虚拟地址空间和页表,也和编译器和ELF有莫大的关系!!!
对于是 程序表头 和 节头表 又有什么用呢,其实 ELF 文件提供 2 个不同的视图/视角来让我们理解这两个部分:
- 链接视图(Linking view) --- 对应节头表Section header table
- ⽂件结构的粒度更细,将⽂件按功能模块的差异进行划分,静态链接分析的时候⼀般关注的是链接视图,能够理解 ELF 文件中包含的各个部分的信息。
- 为了空间布局上的效率,将来在链接⽬标⽂件时,链接器会把很多节(section)合并,规整成可执行的段(segment)、可读写的段、只读段等。合并了后,空间利用率就高了,否则,很小很小的⼀段,未来物理内存⻚浪费太大(物理内存⻚分配⼀般都是整数倍⼀块给你,比如4k),所以,链接器趁着链接就把小块们都合并了。
- 执行视图(execution view)--- 对应程序头表 Program header table
- 告诉操作系统,如何加载可执行文件,完成进程内存的初始化。⼀个可执行程序的格式中,
- ⼀定有 program header table 。
其实就是,一个在链接时作用,一个在运行加载时作用。
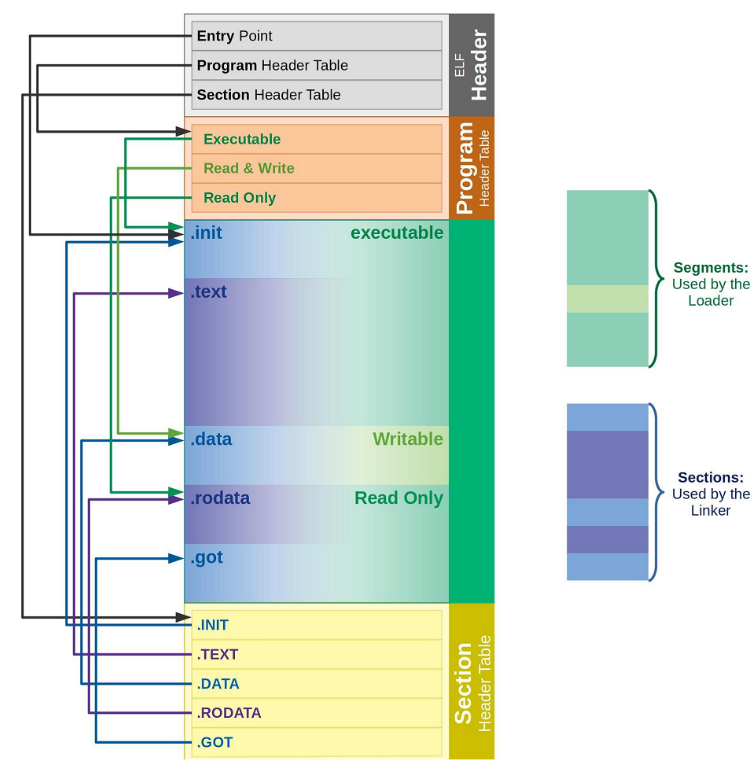
从 链接视图 来看:
- 命令 readelf -S hello.o 可以帮助查看ELF⽂件的 节头表。
- .text节 :是保存了程序代码指令的代码节。
- .data节 :保存了初始化的全局变量和局部静态变量等数据。
- .rodata节 :保存了只读的数据,如⼀⾏C语⾔代码中的字符串。由于.rodata节是只读的,所以只能存在于⼀个可执⾏⽂件的只读段中。因此,只能是在text段(不是data段)中找到.rodata节。
- .BSS节 :为未初始化的全局变量和局部静态变量预留位置
- .symtab节 : Symbol Table 符号表,就是源码⾥⾯那些函数名、变量名和代码的对应关系。
- .got.plt节 (全局偏移表-过程链接表):.got节保存了全局偏表。.got节和.plt节⼀起提供了对导⼊的共享库函数的访问入口,由动态链接器在运行时进行修改。对于GOT的理解,我们后面的文章中会提。
- 使⽤ readelf 命令查看 .so ⽂件可以看到该节。
从 执行视图 来看:
- 告诉操作系统哪些模块可以被加载进内存。
- 加载进内存之后哪些分段是可读可写,哪些分段是只读,哪些分段是可执⾏的。
我们可以在 ELF头 中找到⽂件的基本信息,以及可以看到ELF头是如何定位程序头表和节头表的。
10 理解链接与加载
10.1 静态链接
无论是自己的 .o ,还是静态库中的 .o ,本质都是把 .o 文件进行链接的过程
所以:研究静态链接,本质就是研究 .o 是如何链接的?
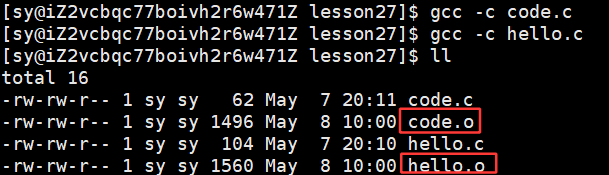
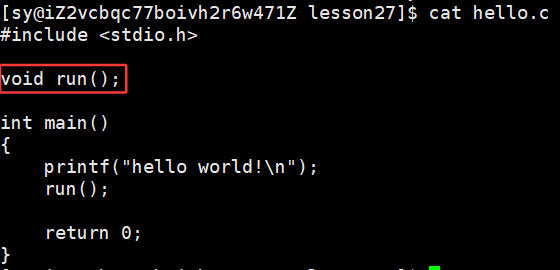
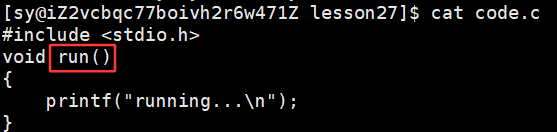
没有链接时,做预处理编译和汇编时是没有报错的,run函数的实现方法在code.o中,说明其实一个模块用了其他模块的方法,在链接之前,这个方法可以不用出现,编译时是能通过的。
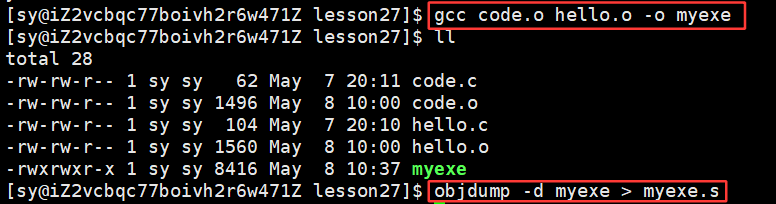
命令:objdump 是用来查反汇编的
objdump -d 命令:将代码段(.text)进行反汇编查看
objdump -S 命令:将所有的代码全部进行反汇编
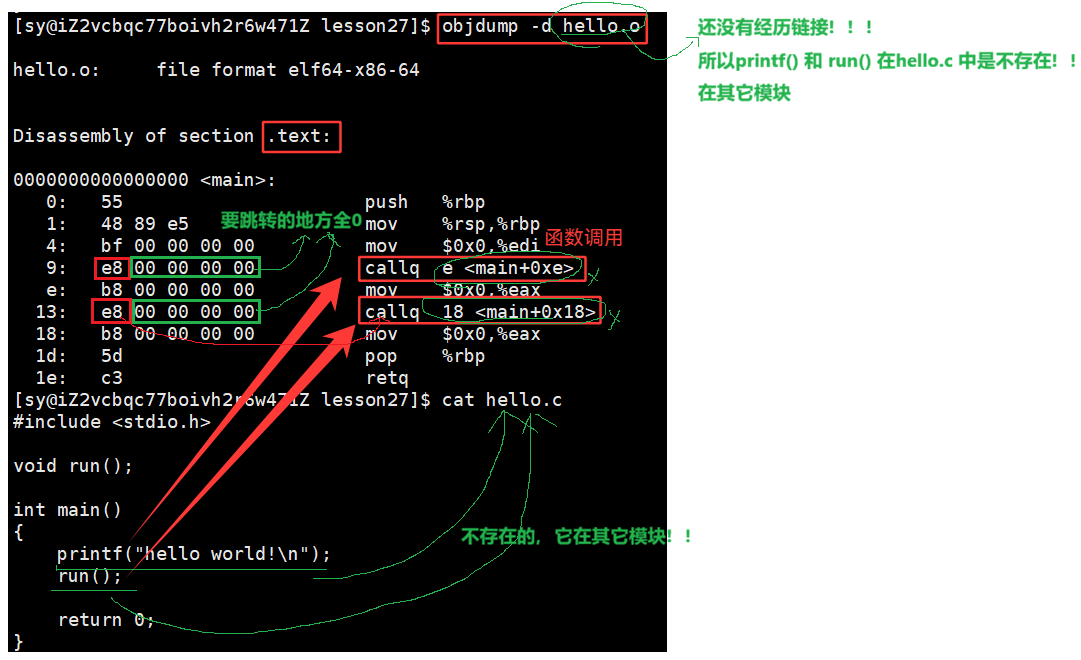
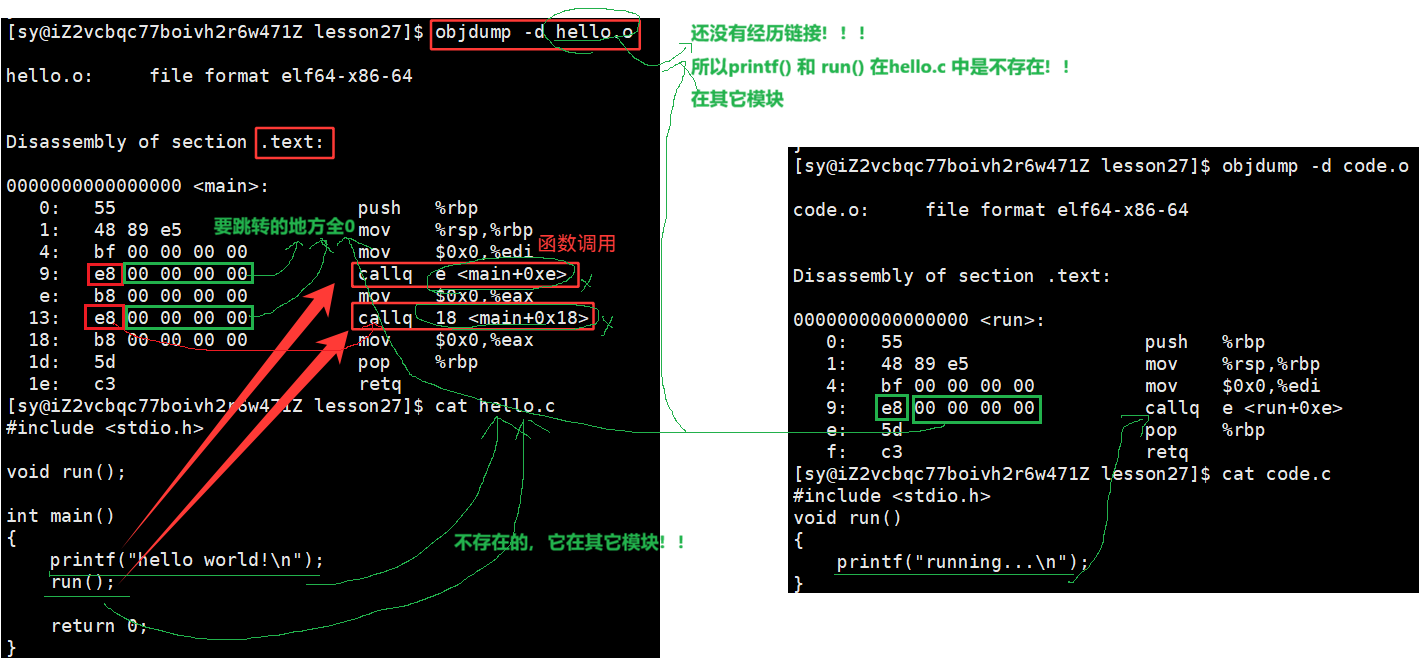
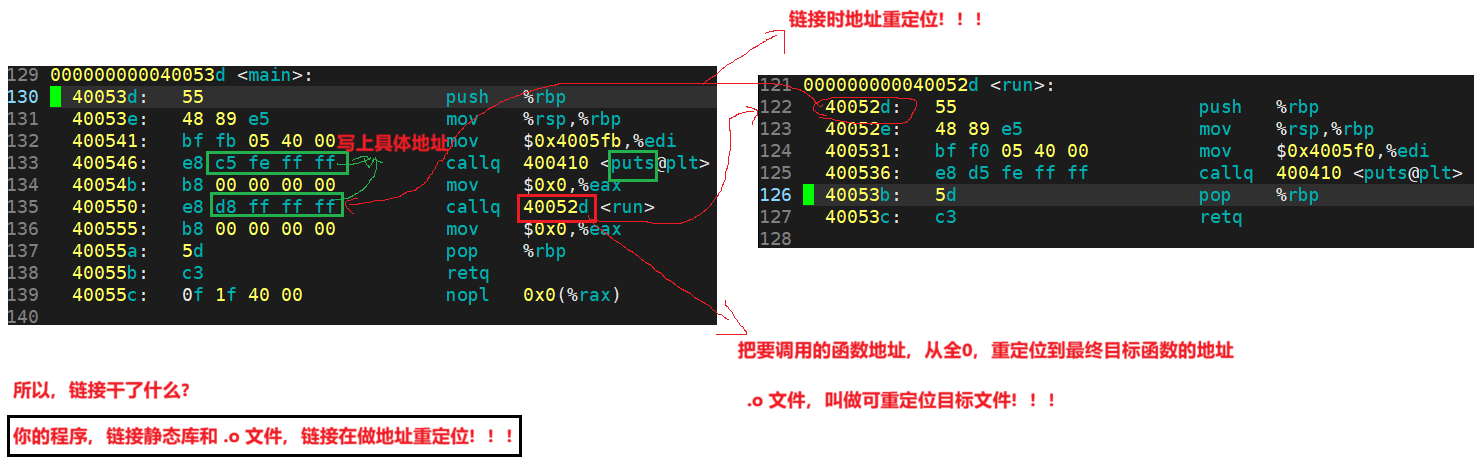
我们可以看到这⾥的call指令,它们分别对应之前调⽤的printf和run函数,但是你会发现他们的跳转地址都被设成了0。那这是为什么呢?
其实就是在编译 hello.c 的时候,编译器是完全不知道 printf 和 run 函数的存在的,比如他们位于内存的哪个区块,代码长什么样都是不知道的。因此,编译器只能将这两个函数的跳转地址先暂时设为0。
这个地址会在哪个时候被修正?链接的时候!code.o 和 hello.o 也是ELF的,链接的本质就是将两个ELF进行合并,其中一个ELF可能会调用其它的ELF,合并之后就会有新的地址,有了新的地址就将目标函数的地址,重新修改至你调用的地方。就会为了让链接器将来在链接时能够正确定位到这些被修正的地址。在代码块(.data)中还存在⼀个重定位表,这张表将来在链接的时候,就会根据表⾥记录的地址将其修正。
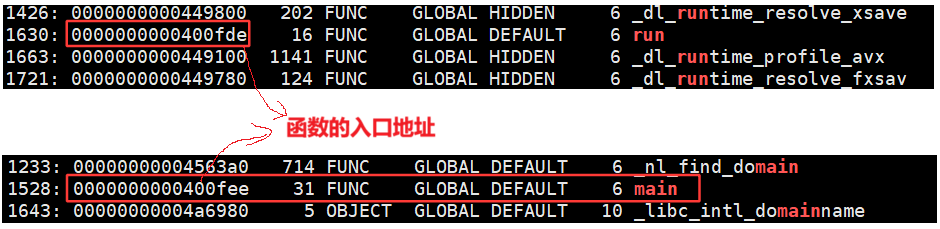
命令:readelf -s code.o 读取一个 .o 文件所对应的符号表,在ELF中特定的section中存符号表。
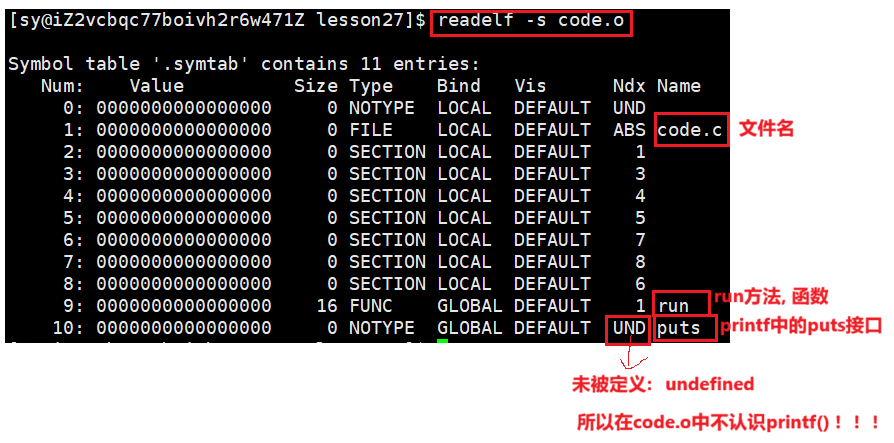
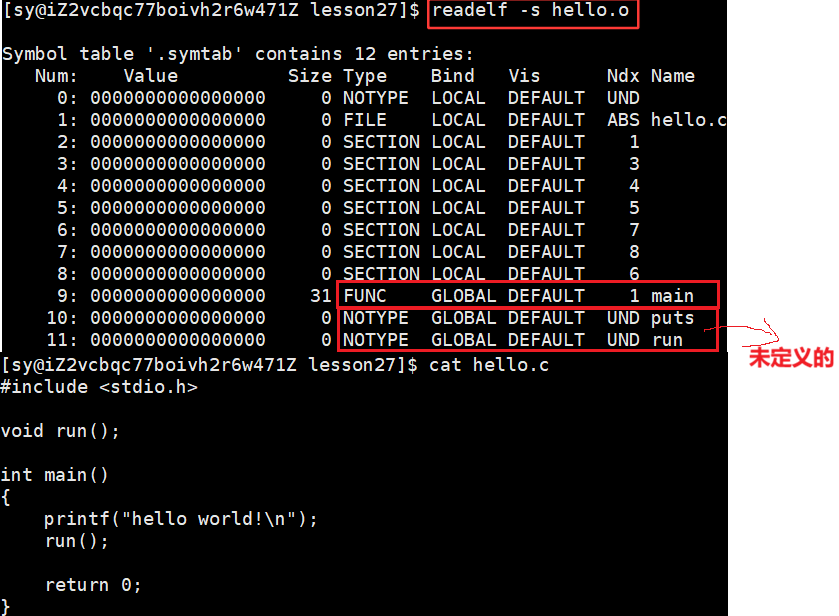
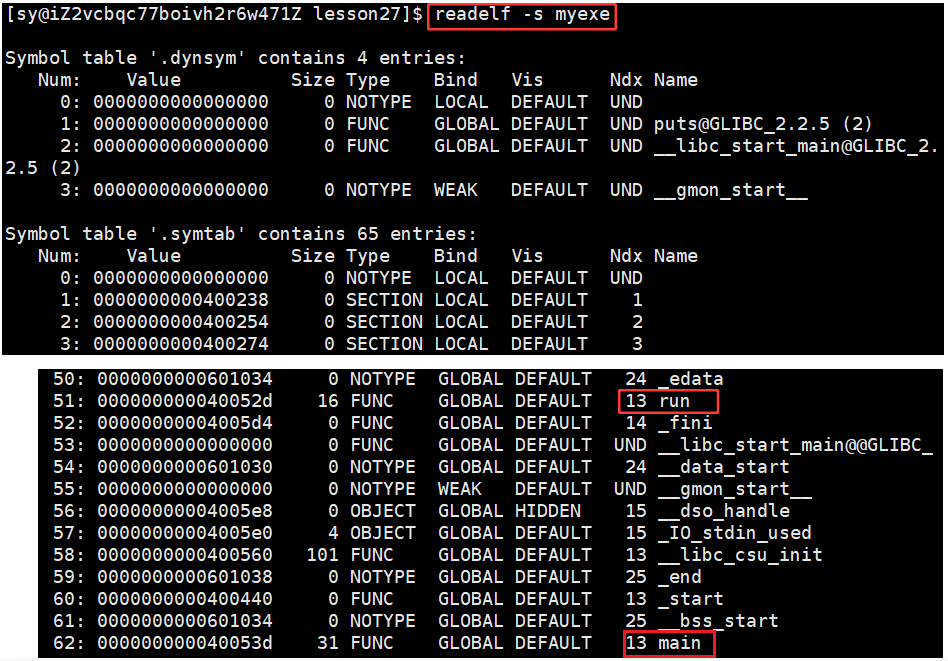
可以看见,run 和 main 方法都是 13,13:表示的就是run函数所在的section被合并最终的哪一个section中了,13就是下标。
printf() 在动态链接中是看不见的,换为静态链接:
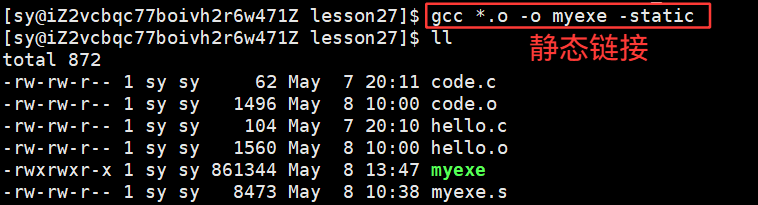
没有没有被定义的,所有的东西全部都被定义好了。
静态链接太大了,还是用动态链接:
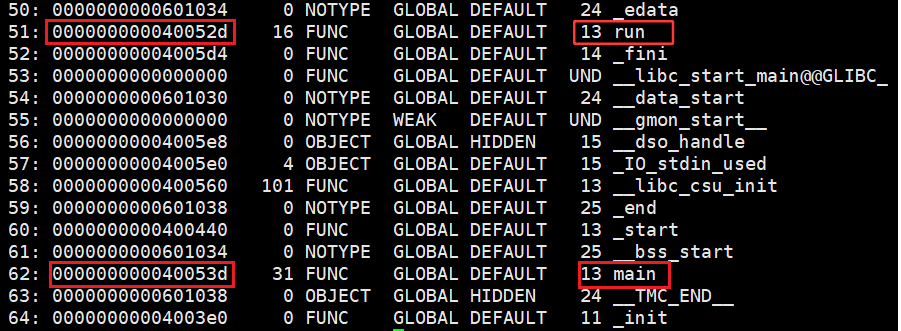
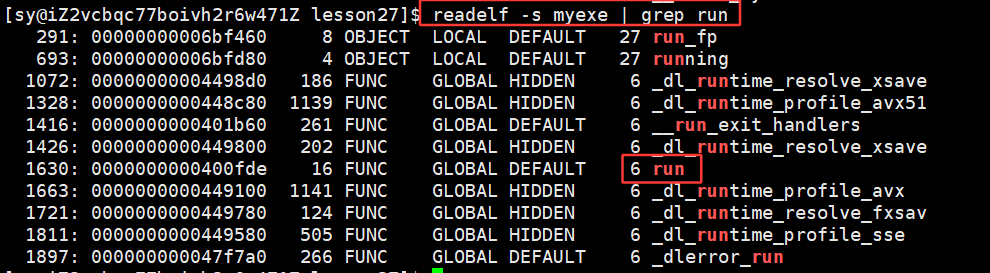
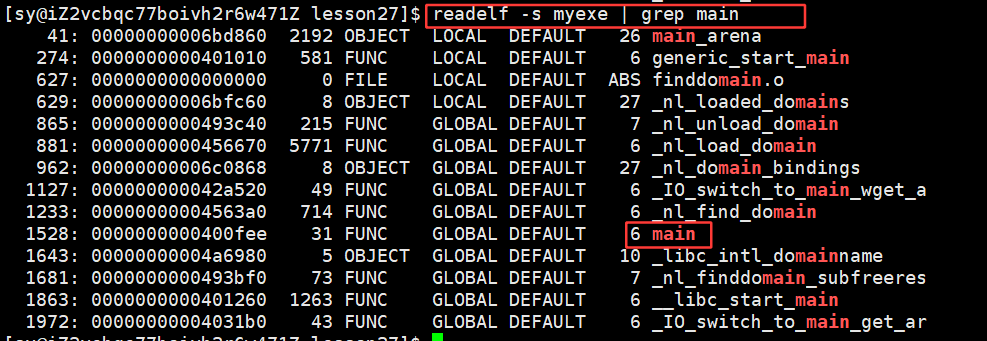
main方法和run方法都是代码,都在 .text 中

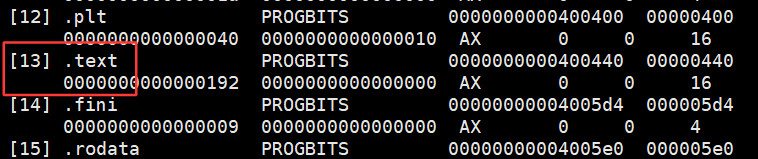
所以就将run方法和main方法就放在了第13个数据节中。
两个 .o 的代码段合并到了一起,并进行了统一的编址
链接的时候,会修改 .o 中没有确定的函数地址,在合并完成之后,进行相关 call 地址,完成代码调用。 ---- 这个过程叫做 :链接时地址重定位!!!所以将 .o /.obj 称为可重定位目标文件!!!所以 .o /.obj 在被链接时可以修改地址。
所以链接其实就是将编译之后的所有目标文件连同用到的一些静态库运行时库组合,拼装成一个独立的可执行文件。本质就是将ELF之间做合并。细节就是可以做地址的修改修订。没链接之前地址为0,链接之后,链接器会根据我们的 .o文件或者静态库中的重定位表找到那些需要被重定位的函数全局变量,从而修正它们的地址。这其实就是 静态链接 的过程。
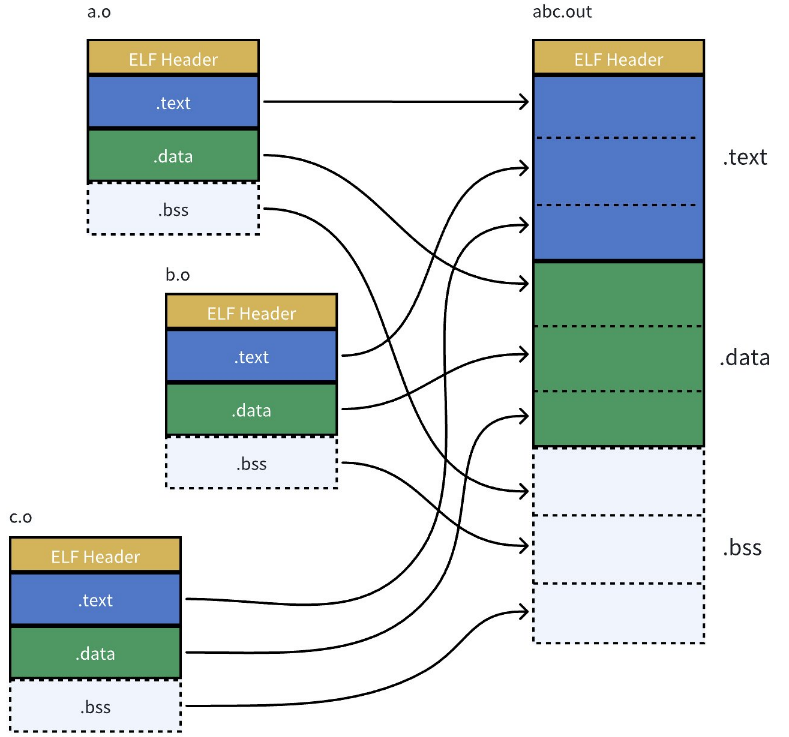
所以,链接过程中会涉及到对.o中外部符号进行地址重定位。
所以,在 extern 声明全局变量,编译成.o,声明变量的地址是为0的或是没被初始化的,在链接的时候才会被初始化。
10.2 虚拟地址/逻辑地址
10.2.1 进程如何看待动态库
问题1:
一个ELF可执行程序,在没有加载到内存的时候,有没有地址呢?为何什么??是什么地址??
一个ELF可执行程序,在没有加载到内存的时候,其实是已经有地址了!!!如何让证明呢?
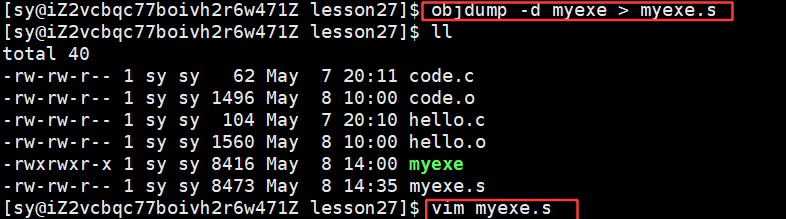
只是将二进制文件做反汇编了:
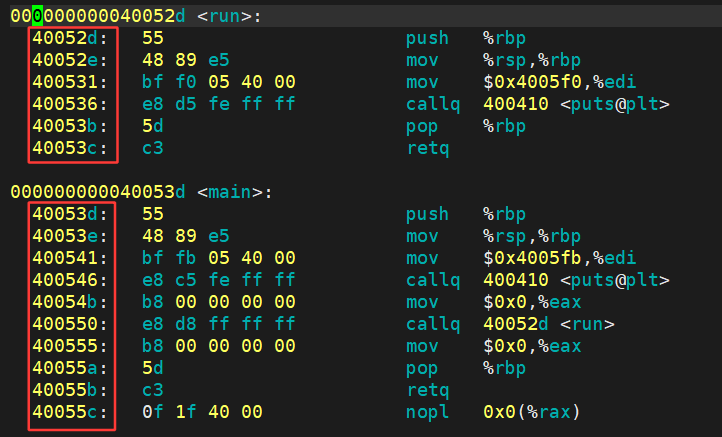
最左侧的就是ELF的虚拟地址,其实,严格意义上应该叫做逻辑地址(起始地址+偏移量), 但是我们认为起始地址是0。也就是说,其实虚拟地址在我们的程序还没有加载到内存的时候,就已经把可执行程序进行统⼀编址了。

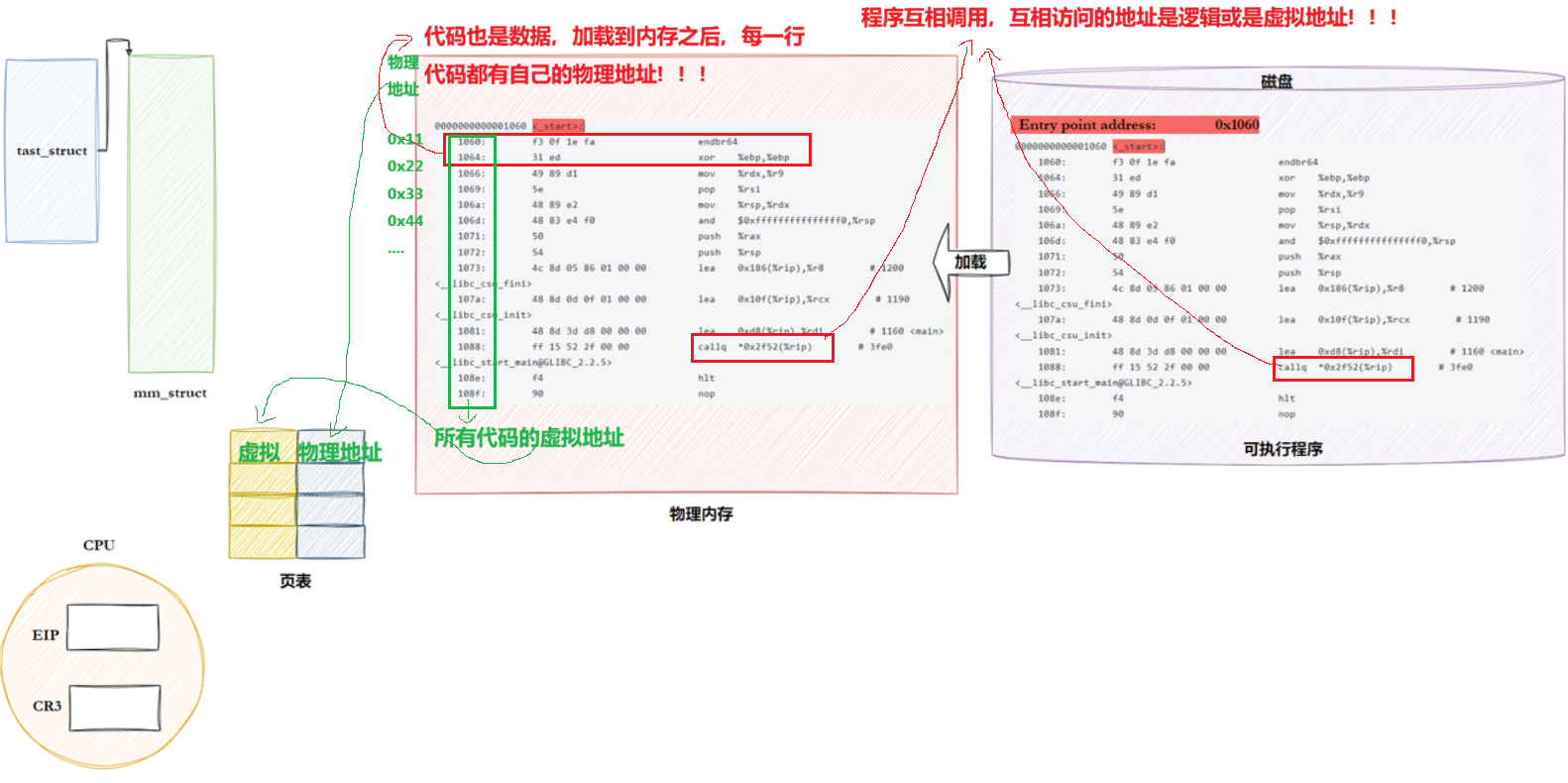
10.2.2 重新理解进程虚拟地址空间
问题2:
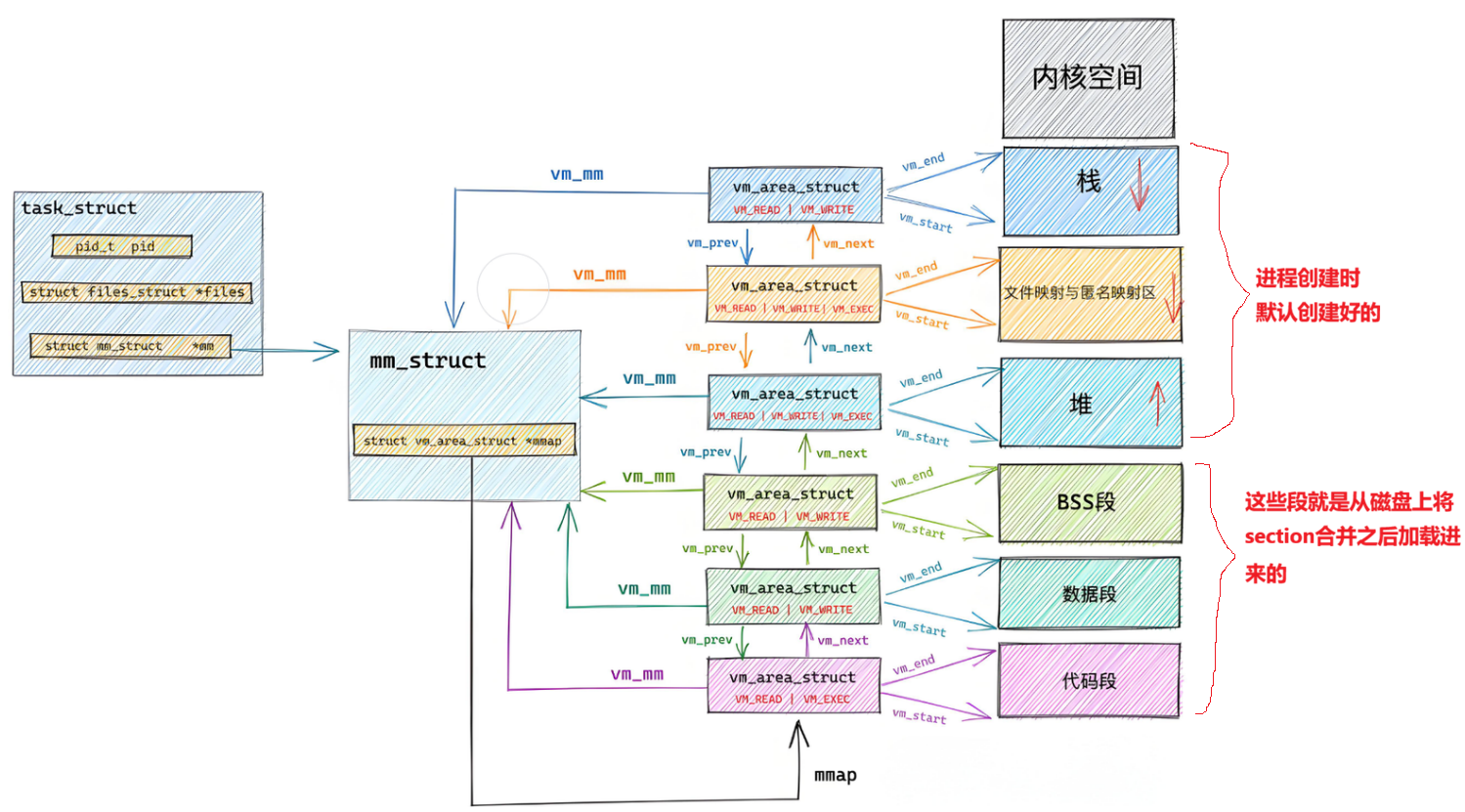
进程mm_struct、vm_area_struct 在进程刚刚创建的时候,初始化数据从哪里来的?
进程mm_struct、vm_area_struct在进程刚刚创建的时候,初始化数据从哪⾥来的?从ELF各个segment来,每个segment有⾃⼰的起始地址和⾃⼰的⻓度,⽤来初始化内核结构中的start, end
等范围数据,另外在用详细地址,填充页表。
进程如何跑起来?
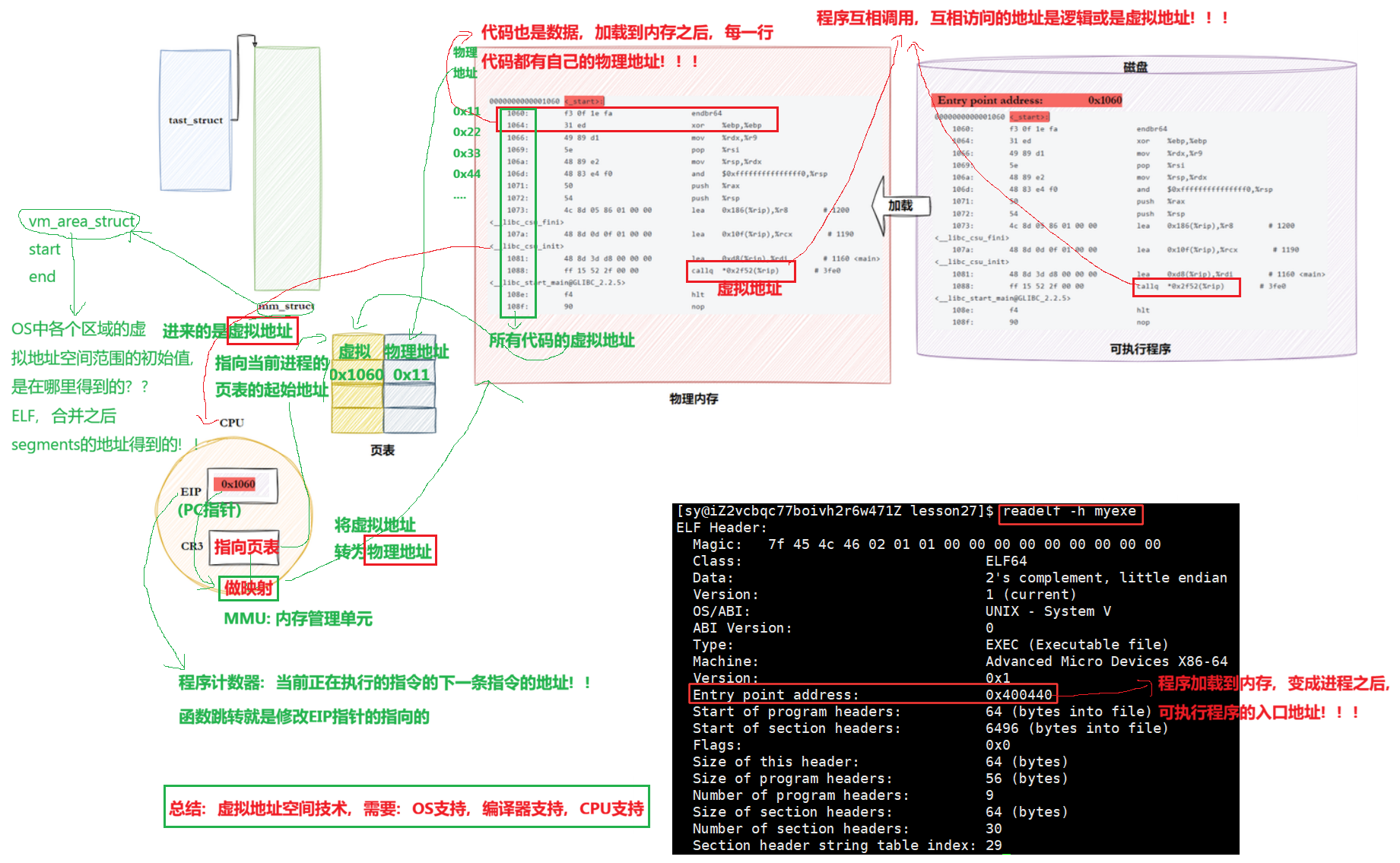
CPU出去的物理地址交给了谁??(扩展问题)
物理地址的本质:内存块的地址。
在内存当作有一个地址寄存器,物理地址就会被存放在地址寄存器中,当内存中的控制寄存器中的指令是1,假设代表是读,此时就将该地址拿到,重新抛到系统总线上,此时CPU就拿到对应的数据了。
所以在之前形成.o 文件时,call对应的全0,链接成功时,call之后的地址就被改了,改成了具体的地址,说明在链接的时候每一个函数就已经有了对应的入口地址,所以可执行程序在没被加载的时候,在磁盘内部就已经有了虚拟地址,在加载到内存时才会真正有物理地址。之后再加载的话,OS就会形成对应的地址空间、页表,在ELF中的整个程序的虚拟地址直接load到EIP中,整个代码就转起来了
再把问题过渡到地址空间上,一个可执行程序有自己的段吗?是有的,只不过是合并上了
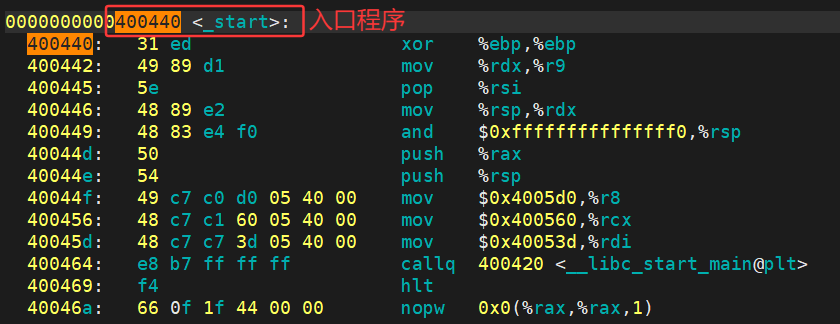
start 内部就会调用 main 函数。