开头:上篇留下的问号
上篇我们聊到,大模型的本质像是在玩一个"猜下一个词"的游戏。
你心里或许在想:如果它只是在计算概率,那它真的能"理解"我吗?它又是如何区分"France"(法国)这个国家和"France"(弗朗斯)这个人名的?
这正是这个系列文章要探索的核心。我们不是要拆开黑盒,而是要一起走进大模型的"认知世界",看看它如何从零开始,一步步地学习,最终接近我们人类"理解"语言的奇妙过程。
符号到数字:Token 不是词
让我们重温那个关键的瞬间
"模型以 99.2% 的概率预测 'Thank you very' 后面接 'much'。"
但在这背后,有一行代码揭示了模型真正的起点:
bash
tokenizer.encode("Thank you very") # → [10449, 345, 845]三个英文单词,变成了三个数字。
模型看到的不是 "Thank you very" ------而是这三个 token ID:[10449, 345, 845]。
这就是第一层理解:把人类语言切分成最小单位,再变成数字。
但等等,这算得上是"理解"吗?
token 只是编号。"猫"是 9246 号,"狗"是 9703 号,"手机"是 11399 号。
编号之间有什么关系?编号"9246"和"9703"很像吗?
完全不像。
编号只是标签,没有任何语义信息。就像身份证号 ------110101 和 110102 只是因为办证顺序不同,不代表哪怕一丁点血缘关系。
所以,第一层"理解"只是:我认识了每个词的编号。
Token 到底是什么?
token 是大模型的最小阅读单位。它可以是:
-
一个词:"Hello"、"cat"、"你好"
-
半个词:"Kubernetes" 被切成 "Kuber"、"net"、"es"
-
一个字符:某些中文词被切碎成字节(GPT-2 的中文)
-
甚至一个空格:"capital" 和 " capital" 是不同的 token(前面那个带空格)
这完全由分词算法(BPE)决定。
BPE:Token 是怎么切出来的
这里需要回答一个关键问题:模型怎么知道哪些字符该合成一个 token,哪些不该?
答案是一种叫 BPE(Byte Pair Encoding,字节对编码) 的算法。它的工作方式很像一个"贪心拼图"游戏:
举例。训练语料是这句话:
low low low low low lower lower newest newest newest widest
第一轮:(l, o) 这个相邻对出现次数最多(7次),合并成 "lo"。第二轮:(lo, w) 出现 7 次,合并成 "low"。第三轮:(e, s) 出现 4 次,合并成 "es"。......以此类推。
最终词表里,"low" 是一个完整 token(训练语料里出现次数多),"widest" 被切成 "w" + "id" + "est"(出现次数少)。
BPE 分词有三个核心特点,这能帮助我们理解它的"思维"起点:
第一,高频词 = 完整 token,低频词 = 碎片。 "Hello" 在互联网上出现极频繁,第一轮就被合并成一个完整 token。"Kubernetes" 很少见,始终被切成 4 个碎片。模型要从碎片中"拼"出含义。
第二,不同语言,切分粒度不同。 英文词表丰富,中文 token 效率天然差一些。GPT-2 把很多中文字符切到字节级别,两个字可能被切成 4 个甚至更多 token。这也是为什么中文大模型的 API 调用成本通常是英文的 2-3 倍。
第三,能处理从没见过的词。 "lowest" 可能不在训练语料里,但模型看到它,能切成 "low" + "est"------这两个子 token 都认识。BPE 天然处理"未登录词"问题。
到这里就能回答一个常见疑问:为什么大模型厂商都是按 token 收费,而不是按字数或按单词?
因为 token 的数量和字符数、单词数都不完全对等。同样一段话,英文 token 数大约是字数的 0.75 倍(1 个 token ≈ 0.75 个英文单词),而中文因为词表不够原生,token 数往往是字数的 1.5 到 3 倍。API 的计算成本直接取决于模型实际处理的 token 数量------而这个数量由 BPE 算法决定,所以按 token 收费对双方都是最公平的方式。
一个"视力陷阱"
理解了 BPE,我们就能看懂大模型那些看似"奇怪"的行为背后的逻辑。
问模型:"strawberry 这个词里有几个 r?"
它经常答错。
这并非模型的智力问题,而是一个"视力"问题------它的"视觉系统"和我们不一样。它看到的 "strawberry" 不是一串连续的字母,而是被切分成三个独立的 token:["st", "raw", "berry"]。模型无法感知到单个的 "r" 字符,要它去数 "r",就像是让一个只能看到色块的人去数像素点一样,从起点上就注定了困难。
模型的智力,受限于它的视力------而视力,由 BPE 词表决定。
核心认识 :token 代表符号。它记住了"这个编号对应哪个词符号",但没理解词和词之间的关系。
数字到空间:Embedding 把词变成坐标
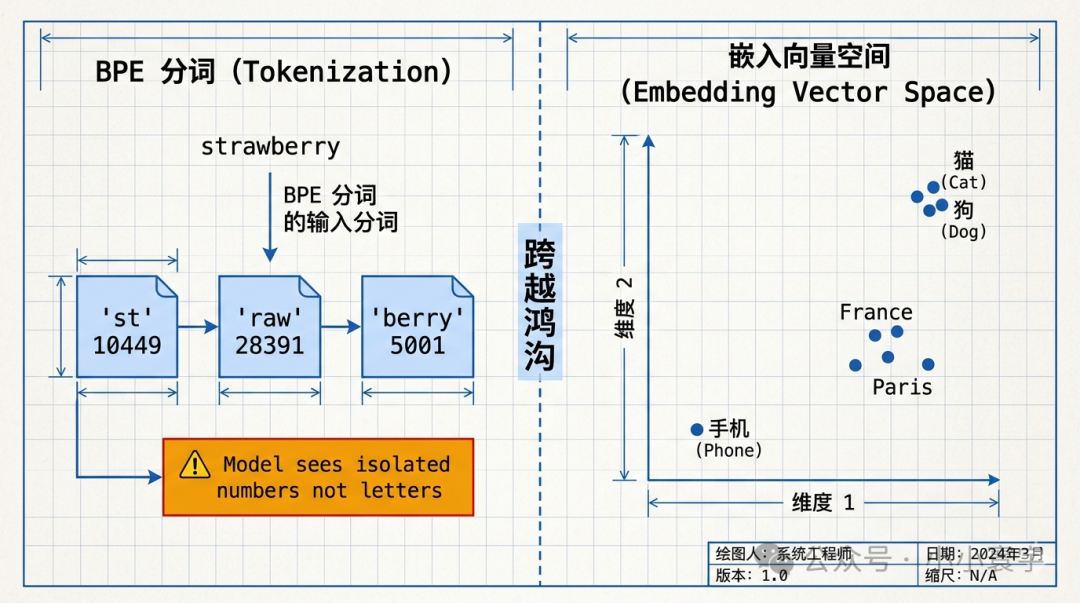
一个颠覆直觉的真相
我们已经知道,token 只是冷冰冰的编号,就像一串没有意义的数字。那问题就来了:模型是如何跨越这道鸿沟,从一堆无意义的数字中,感知到"France"和"Paris"、"国王"和"女王"之间的深刻联系的呢?
比如为什么 "France" 和 "Paris" 有关系?"国王"和"女王"有关系?
答案:Embedding 表,就是每个 token 的"能力档案"。
打个比方会更清楚:Token ID 像一张身份证号------只是一个编号标签,"猫"是 9246 号,"狗"是 9703 号,编号之间没有任何关系。
但 Embedding 是另一回事。它像是这个人的能力档案------"猫"会抓老鼠、体型小、是哺乳动物、会发出咕噜声......不是一句话,而是几十个维度的特征描述。把这些特征画成坐标,"猫"和"狗"的特征档案很接近,"手机"的相差很远。
Embedding 的"特征档案"里有什么?
为了更直观地说明,我们不妨用两个简单的维度来代表一个词:"萌度"和"机械感":
bash
猫: [0.9, 0.1] → 很萌,不机械
狗: [0.8, 0.2] → 也很萌,不机械
手机:[0.1, 0.9] → 不萌,很机械把这些跟坐标纸上,"猫"和"狗"自然挨在一起(都在 0.8, 0.2 附近),"手机"离得很远。
距离反映了语义关系 ------不需要人工标注"猫和狗相似",坐标本身就说明了一切。
大模型的真实情况:
-
不是 2 个维度,而是 768 个(甚至 4096 个)
-
不是"萌度""机械感",而是模型自己学出来的抽象特征
但核心原理是相通的:语义相近的词,其向量在高维空间中的坐标也会彼此靠近。
记住了这个词,就记住了它的"邻居"
单词一旦被 Embedding,自动就有了邻居:
-
"国王"的邻居是"女王"
-
"苹果"的邻居是"梨"
-
"Kubernetes" 的邻居是 "Docker"、"云原生"、"容器"
这些关系不是写死在代码里的,而是从数万亿个 token 的统计共现规律中自动涌现的。
关键洞察:训练数据里,"国王"和"女王"经常同时出现,"国王"经常和"男人"同时出现。模型为了更准确预测下一个词,自动发现了这些关系,并把它们放在向量空间里的相应位置。
这里的"涌现",其含义是惊人的:没有程序员在代码里写上"国王和女王有关系",也没有人手动规定这种联系。这些关系是模型在"预测下一个词"的单一目标驱动下,为了更准确地拟合海量文本的统计规律,而被迫"学"出来的。这是一种在压力下自动形成的副产品------不是我们设计的,而是模型在学习过程中被逼出来的深刻洞见。
Embedding 表是什么
这张表,模型在训练开始前就建好了,但数字不是固定的------最初随机生成,训练过程中通过反向传播逐步调整,最终形成编码语义关系的向量空间。
每一行对应词表里的一个 token ID,每一列是一个维度的数值。GPT-2 的 Embedding 表:
bash
embedding_table.shape # → torch.Size([50257, 768])-
50257 行:词表里每个 token 各占一行
-
768 列:每个 token 一个 768 维的向量
查表操作极其简单------没有计算,就是"去那一行,取出 768 个数"。但这 768 个数里,编码了整个语言的语义结构。
当模型想知道 "France" 和 "Paris" 有没有关系,它不靠编号,而是:查到两个词的向量,算出它们的"距离"(余弦相似度)。France 和 Paris 的相似度远高于 France 和 cat------模型由此"知道"它们有关系。
三个反直觉的事实
1. 向量的每个维度没有人类能理解的含义
Embedding 的单个维度是抽象的------单独看一个维度没意义,只有所有维度组合起来才编码了语义。
2. 这个编码不是人工设计的
没有工程师写代码:"把国家往左靠、城市往右靠、动物往下靠"。这个结构是从"预测下一个词"这个训练任务中自然涌现的。
3. 语义关系可以用向量做算术
这也是为什么大模型能做类比推理:
国王 − 男人 + 女人 ≈ 女王
从"国王"的概念里减去"男性"成分,加上"女性"成分------在向量空间里,得到的坐标最接近"女王"。这不是代码写出来的,是训练过程中自动学会的几何关系。
需要说明的是:在 GPT-2 这种规模的模型上,这种精确的类比推理(如"国王-男人+女人=女王")可能不会每次都完美成立。但这个例子的意义不在于其精确性,而在于它生动地揭示了一个核心事实:Embedding 空间确实自发地、从海量数据中学习到了这种有意义的语义方向。这并非靠工程师手动编码,而是模型在训练过程中自动学会的几何关系。
完整链条:从符号到语义的第一步
两篇文贯通起来,你看到了什么?
完整的输入处理流程
bash
"Thank you very much"
第一步:分词
["Thank", "you", "very", "much"]
→ [10449, 345, 845, 50257]
第二步:Token Embedding 查表
向量₁, 向量₂, 向量₃, 向量₄
→ 每个 token 从 Embedding 表取出 768 维向量
第三步:+ Position Embedding
向量₁', 向量₂', 向量₃', 向量₄'
→ 每个向量都被赋予了独一无二的位置信息(0, 1, 2, 3)
第三步(补充):为什么要加位置信息?"狗咬人"和"人咬狗"包含完全相同的三个词, 如果只看 Embedding 向量,两者完全一样------模型无法区分。因为模型的输入是一个向量序列,它本身并不知道哪个向量是第一个、哪个是第二个。我们不能简单地依赖向量在序列中的索引位置,因为模型的计算过程(如Attention机制)会打乱这些顺序,导致索引信息丢失。因此,我们需要将位置信息也编码成一个向量(即位置编码),并与词的Embedding向量相加。这样,位置信息就融入了向量本身,无论后续计算如何进行,模型都能"感知"到每个词的原始位置。
第四步:进入 Transformer
经过几十层 Attention 和 FFN
→ 每一层的向量都在动态地"理解"和"整合"上下文信息,从而不断调整自身的表达
第五步:输出概率
[概率₁, 概率₂, ..., 概率₅₀₂₅₇]
→ P("much") = 99.2%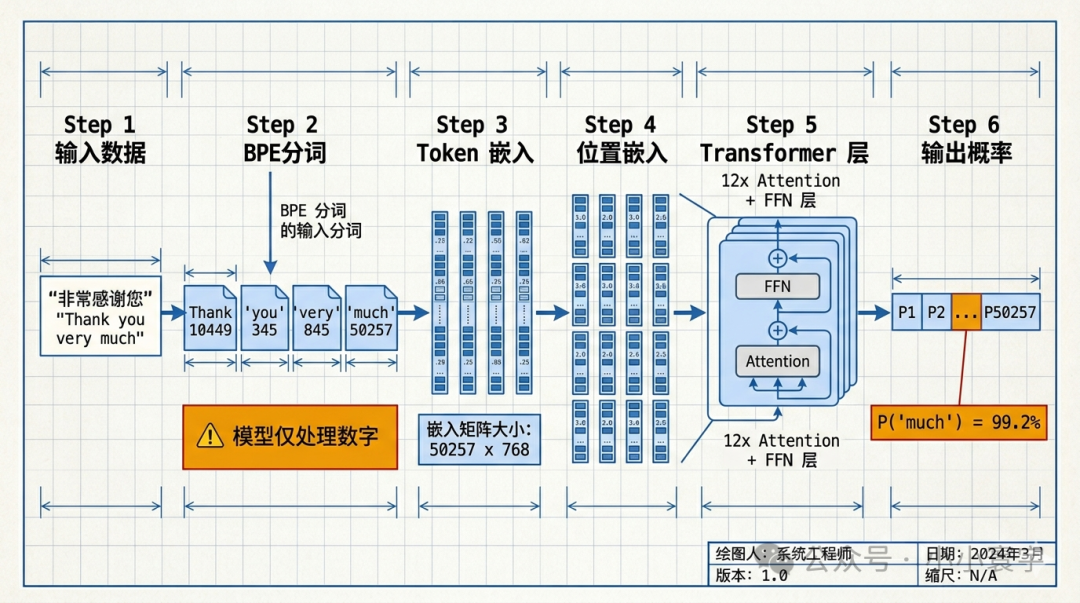
模型"理解"语言的三重境界
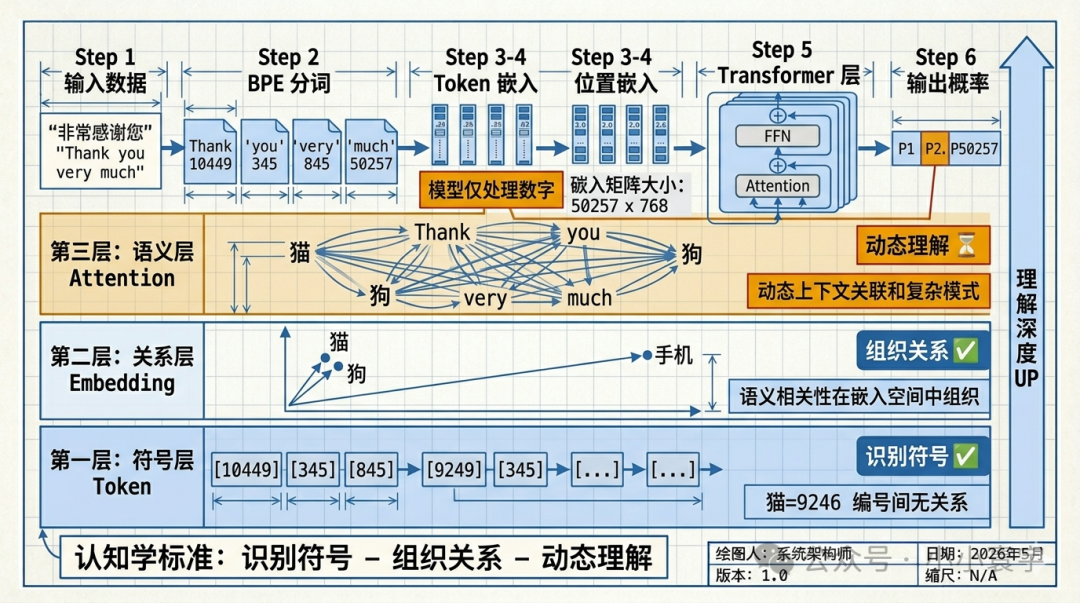
| 层面 | 表示 | 能力 | 例子 |
|---|---|---|---|
| 第一层(本文) | 索引数字 10449, 345, 845 | 认识符号 | "这个编号是 Thank 这个词" |
| 第二层(本文) | 向量 0.1, -0.3, ..., 0.8 | 认识关系 | "France" 和 "Paris" 向量接近 |
| 第三层(下文) | 上下文感知的语义表示 | 理解句子 | "苹果" 在不同语境下是"水果"还是"公司" |
为什么说"理解"?
认知学家说,理解一个概念,需要做到三件事:
根据这个标准,我们可以说大模型已经做到了前两层:
✅ 符号识别 :token 把词变成数字,记住了符号对应关系✅ 组织关系:Embedding 把词变成向量,自然聚类
但没有做到第三层------那个要在下一篇(Attention)来补。
结语
从最初那个"猜下一个词"的简单直觉,到最终实现对人类语言的深刻"理解",大模型的进化之路可以清晰地分为三步:
通过本文,我们已经清晰地看到了大模型实现"理解"的前两步。
下一篇我们会探讨:为什么同一个词,在不同的语境下会拥有截然不同的含义?比如"我今天买了一个苹果"和"苹果发布了新款 iPhone"------这里的"苹果"一个指水果,一个指科技公司,意义完全不同。模型是如何根据上下游戏副本来判断的?
这,正是下一篇文章将要为你揭开的,关于 Attention 的精彩故事。
让我们以这句话作为结尾,来感受人与模型之间的微妙差异:
"Between the human world and the model world, there is a thin layer of translation."
人和模型之间,确实隔着一层翻译------而我们今天所探讨的 tokenization,正是这层翻译的起点。
相关阅读
- 《大模型不神秘:它到底在做什么》------理解"猜下一个词"
- 下一篇:《理解上下文感知:Attention 如何让大模型"看懂"句子》
文章首发于 「小小寰宇」
