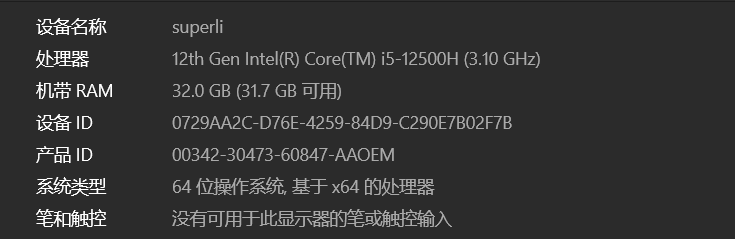
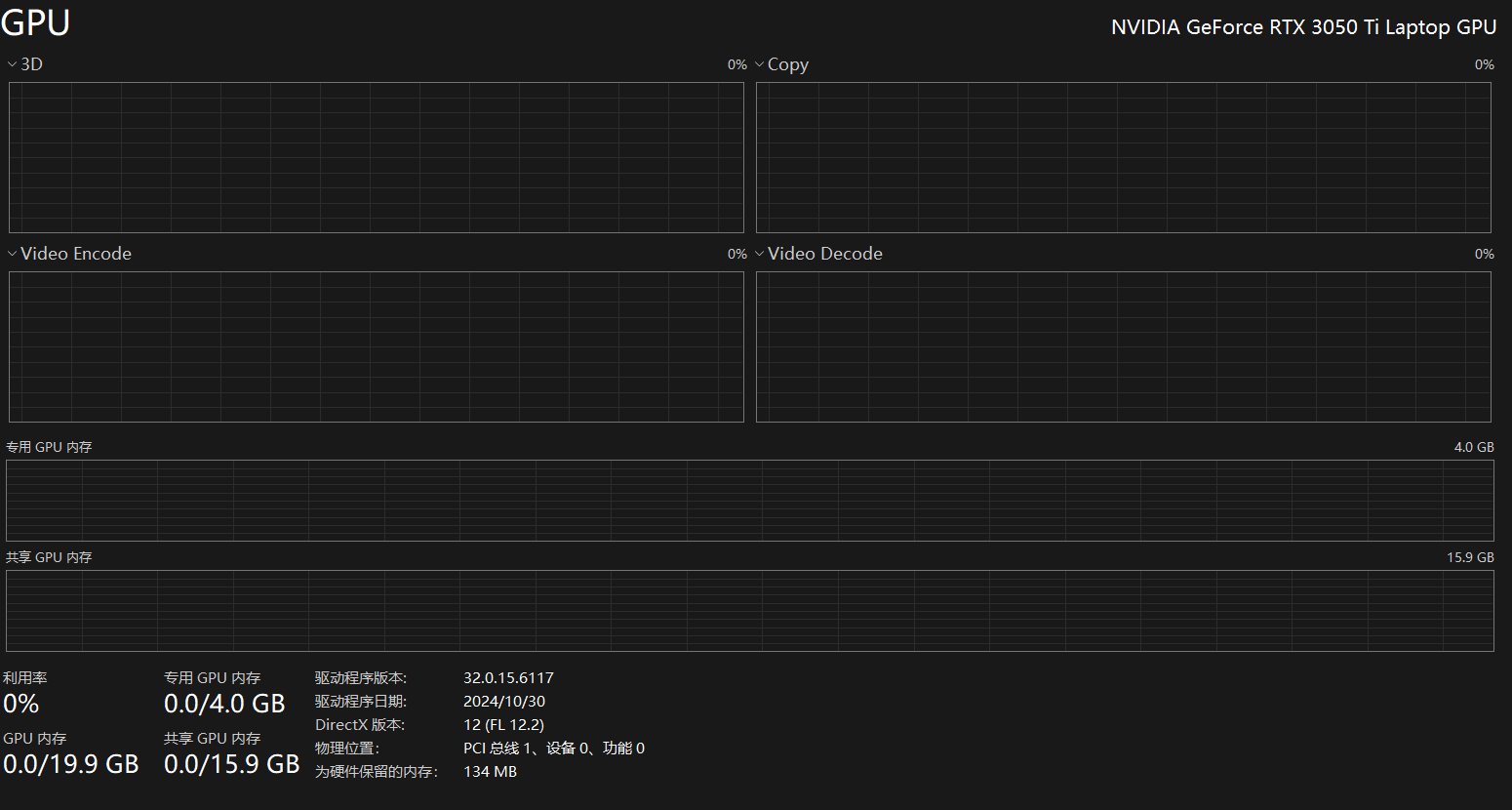
基础配置
笔记本配置信息
依赖
pip install torch requests transformers langchain-community serpapi
源码
python
import torch
import requests
import json
import time
import os
from transformers import AutoTokenizer, AutoModelForCausalLM, TextIteratorStreamer
from threading import Thread
from langchain_community.utilities import SerpAPIWrapper
from pathlib import Path
from datetime import datetime
API_KEY = "你的千帆api授权key"
def ask_save_file(search_result: str) -> bool:
"""询问用户是否保存搜索结果"""
print("\n" + "="*50)
print("📌 是否保存本次搜索结果到文件?")
print("="*50)
print("1. 保存")
print("2. 不保存")
print("3. 自定义文件名保存")
while True:
choice = input("请选择 (1/2/3): ").strip()
if choice == '1':
# 自动生成文件名
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
filename = f"search_{timestamp}.txt"
return filename,search_result, True
elif choice == '2':
return None,search_result, False
elif choice == '3':
filename = input("请输入文件名: ").strip()
if filename:
return filename,search_result, True
else:
print("文件名不能为空!")
else:
print("请输入正确的选项!")
# 增强版文件创建器 - 自动识别内容类型
class FileCreator:
"""智能文件创建器 - 自动识别内容类型"""
def __init__(self, output_dir: str = "output"):
self.output_dir = os.path.join(os.getcwd(), output_dir)
os.makedirs(self.output_dir, exist_ok=True)
EXTENSION_MAP = {
'python': '.py',
'javascript': '.js',
'html': '.html',
'css': '.css',
'json': '.json',
'xml': '.xml',
'sql': '.sql',
'markdown': '.md',
'yaml': '.yaml',
'shell': '.sh',
'bat': '.bat',
'powershell': '.ps1'
}
def create_file(self, filename: str, content: str) -> dict:
"""智能保存内容到文件"""
# 如果没有扩展名,尝试自动识别
name, ext = os.path.splitext(filename)
if not ext:
detected_type = self._detect_content_type(content)
ext = self.EXTENSION_MAP.get(detected_type, '.txt')
filename = name + ext
filepath = os.path.join(self.output_dir, filename)
with open(filepath, 'w', encoding='utf-8') as f:
f.write(content)
return {
"success": True,
"filepath": filepath,
"filename": filename,
"type": ext[1:] if ext else 'txt',
"size": len(content),
"lines": len(content.split('\n'))
}
def _detect_content_type(self, content: str) -> str:
"""根据内容自动识别类型"""
content_lower = content.lower()
if 'import ' in content or 'def ' in content or 'class ' in content:
return 'python'
elif '<!doctype' in content or '<html' in content:
return 'html'
elif 'function' in content or 'const ' in content or 'let ' in content:
return 'javascript'
elif content.strip().startswith('{') or content.strip().startswith('['):
return 'json'
elif 'select ' in content.lower() or 'insert ' in content.lower():
return 'sql'
elif '#' in content and 'def ' not in content:
return 'markdown'
return 'text'
def baidu_deep_search(query: str, API_KEY: str, max_retries: int = 3) -> str:
"""调用百度千帆深度搜索API"""
url = f"https://qianfan.baidubce.com/v2/ai_search/chat/completions"
headers = {
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
payload = {
"messages": [
{
"content": query,
"role": "user"
}
],
"stream": False, # 字符串形式
"model": "ernie-4.5-turbo-32k",
"instruction": "##",
"enable_corner_markers": True,
"enable_deep_search": True
}
# 手动序列化确保格式正确
json_str = json.dumps(payload, ensure_ascii=False)
for attempt in range(1, max_retries + 1):
try:
print(f"🔍 正在发送请求 (第{attempt}次)...")
start_time = time.time()
response = requests.post(
url,
headers=headers,
json=payload,
timeout=60
)
elapsed = time.time() - start_time
print(f"✅ 请求完成! 状态码: {response.status_code}, 耗时: {elapsed:.2f}秒")
# 检查HTTP状态码
if response.status_code != 200:
print(f"❌ HTTP错误: {response.status_code}")
if attempt < max_retries:
print(f"🔄 等待2秒后重试...")
time.sleep(2)
continue
else:
return f"HTTP错误: {response.status_code}"
# 解析JSON
result_json = response.json()
# 检查API返回错误
if "error" in result_json:
error_msg = result_json["error"].get("message", "未知错误")
print(f"❌ API错误: {error_msg}")
if attempt < max_retries:
print(f"🔄 等待2秒后重试...")
time.sleep(2)
continue
return f"API错误: {error_msg}"
# 提取content内容
if "choices" in result_json and result_json["choices"]:
content = result_json["choices"][0]["message"]["content"]
print(f"📋 搜索完成,内容长度: {len(content)} 字符")
return content
else:
print(f"❌ 响应格式异常: {result_json}")
return f"响应格式异常"
except requests.exceptions.Timeout:
print(f"❌ 请求超时 (第{attempt}次)")
if attempt < max_retries:
print(f"🔄 等待2秒后重试...")
time.sleep(2)
else:
return "搜索超时,请重试"
except requests.exceptions.RequestException as e:
print(f"❌ 请求异常: {e}")
if attempt < max_retries:
print(f"🔄 等待2秒后重试...")
time.sleep(2)
else:
return f"请求异常: {str(e)}"
except json.JSONDecodeError:
print(f"❌ JSON解析失败")
if attempt < max_retries:
time.sleep(2)
continue
return "JSON解析失败"
return "达到最大重试次数"
# 封装为 LangChain Tool 格式(可选)
def web_search(query: str) -> str:
print(f"🔍 正在搜索: {query}")
# 执行搜索
result = baidu_deep_search(query, API_KEY)
return result if result else "未找到相关信息"
# =========================================
# 判断是否需要搜索的关键词
SEARCH_TRIGGERS = [
"最新", "现在", "2024", "2025", "新闻", "搜索",
"查一下", "请问", "多少钱", "怎么", "如何",
"天气", "股票", "汇率", "比赛", "结果", "?"
]
def should_search(query: str) -> bool:
"""判断是否需要联网搜索"""
return any(trigger in query for trigger in SEARCH_TRIGGERS)
# 模型路径(替换为你自己的路径)
model_path = "E:\\github\\chandra\\models\\Qwen\\Qwen3.5-2B-Base"
# 检查设备
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用设备: {device}")
# 加载 tokenizer 和 model
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True,local_files_only=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token # 补全 pad_token
model = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
local_files_only=True, # 👈 就是它!救命稻草
torch_dtype=torch.float16 # 使用 float16 减少显存占用
).to(device).eval()
# 多轮对话历史(OpenAI 格式)
messages = []
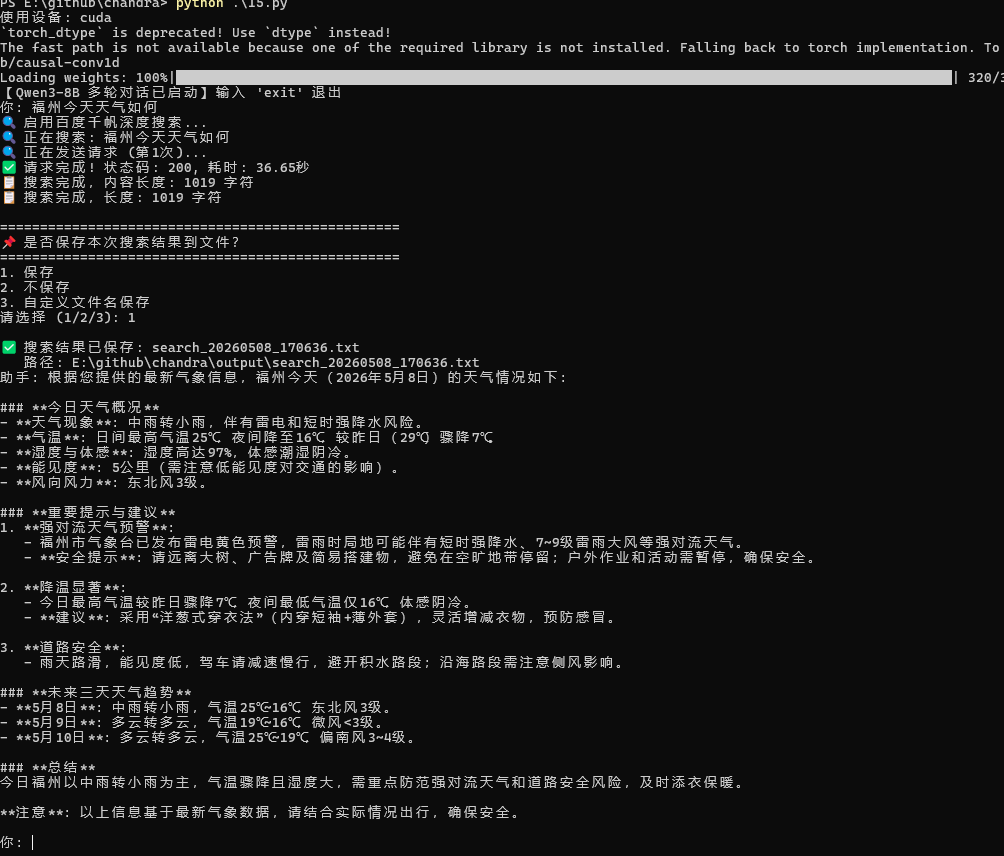
print("【Qwen3-8B 多轮对话已启动】输入 'exit' 退出")
def clean_markdown(text: str) -> str:
"""清理 Markdown 格式符号"""
import re
text = text.replace("**", "").replace("- ", "").replace("* ", "")
text = re.sub(r'#{1,6}\s?', '', text) # 去掉 # 标题
text = re.sub(r'`{1,3}', '', text) # 去掉代码标记
text = re.sub(r'\n{3,}', '\n\n', text) # 清理多余空行
return text.strip()
# 流式输出函数
def stream_generate():
# 构建 prompt
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = tokenizer(prompt, return_tensors="pt").to(device)
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
generate_kwargs = dict(
**inputs,
streamer=streamer,
max_new_tokens=102400,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
do_sample=True,
top_p=0.95,
top_k=50,
temperature=0.5,
use_cache=True # 必开!
)
thread = Thread(target=model.generate, kwargs=generate_kwargs)
thread.start()
print("助手:", end="", flush=True)
response = ""
for new_text in streamer:
print(new_text, end="", flush=True)
response += new_text
print()
return response
while True:
user_input = input("你:")
if user_input.lower() == 'exit':
print("对话结束。")
break
# 添加用户输入到 messages
messages.append({"role": "user", "content": user_input})
# 判断是否需要搜索
if should_search(user_input):
print("🔍 启用百度千帆深度搜索...")
# 执行搜索
search_result = web_search(user_input)
print(f"📋 搜索完成,长度: {len(search_result)} 字符")
# 将搜索结果加入对话
search_context = f"""以下是联网搜索到的相关信息,请根据这些最新信息回答用户问题:
搜索结果:
{search_result}
请根据以上信息,结合你的知识,给出准确、有帮助的回答:"""
save_filename, content_to_save, should_save = ask_save_file(search_result)
file_creator = FileCreator("output")
if should_save and save_filename:
try:
result = file_creator.create_file(save_filename, content_to_save)
print(f"\n✅ 搜索结果已保存: {result['filename']}")
print(f" 路径: {result['filepath']}")
except Exception as e:
print(f"❌ 保存失败: {e}")
messages.append({"role": "user", "content": search_context})
# 生成回答
response = stream_generate()
else:
# 流式生成回复
response = stream_generate()
# 添加助手回复到 messages
response_clean = clean_markdown(response)
messages.append({"role": "assistant", "content": response_clean})
运行效果