JS 可以写 3D 渲染,但它通常不是"JS 自己在 CPU 上一个像素一个像素画 3D",而是 JS 调浏览器提供的 GPU 图形 API。
Three.js 这种库,它是 JS 写的,但它不是靠 JS 手搓全部渲染结果。它本质上是封装了 WebGL/WebGPU。MDN 对 WebGL 的定义就是:WebGL 是一个 JavaScript API,用来在浏览器中渲染高性能交互式 2D 和 3D 图形,并且能利用设备硬件图形加速。MDN Web Docs
最底层如果不用库,你可以直接用 WebGL 写:
但这很底层,接近 OpenGL ES 风格。
Three.js 则是更上层的封装:
JavaScript
const scene = new THREE.Scene();
const camera = new THREE.PerspectiveCamera();
const renderer = new THREE.WebGLRenderer();
renderer.render(scene, camera);Three.js 官方 WebGLRenderer 文档里说,它会用给定的 camera 渲染 scene / 3D object,渲染到 canvas 或 render target。Three.js 也就是说你写的是 JS 场景代码,Three.js 负责把它转换成 WebGL 调用。
MDN 全称现在是 MDN Web Docs ,历史上叫 Mozilla Developer Network 。MDN 官方 About 页面写得很直接:MDN 是一个开源协作项目,归 Mozilla Corporation 所有,由 Mozilla 和社区、合作伙伴共同开发维护。MDN Web Docs
你会感觉它像"微软文档",主要是因为后来 Web 标准文档逐渐集中到 MDN。2017 年左右,Mozilla、Microsoft、Google、W3C、Samsung 等一起推动跨浏览器 Web 文档协作,目标是让开发者不要分别查 Firefox / Chrome / Edge / Safari 各自一套文档。Mozilla 当时也宣布 Microsoft、Google、W3C、Samsung 会参与 MDN Web Docs 的协作。Mozilla Blog W3C 也确认过它和 Mozilla、Microsoft、Google、Samsung 一起支持 MDN 文档。W3C
所以正确关系是:
WebGL
是 Web 标准/浏览器图形 API
MDN
是 Mozilla 主导的 Web 技术文档站
Microsoft
不是 MDN 所有者,但参与过 Web 文档协作,也会把一些 Web API 文档指向 MDN
Google / W3C / Samsung / Open Web Docs
也参与过或支持过相关文档生态WebGL 使用文档 → MDN 是最常用参考之一
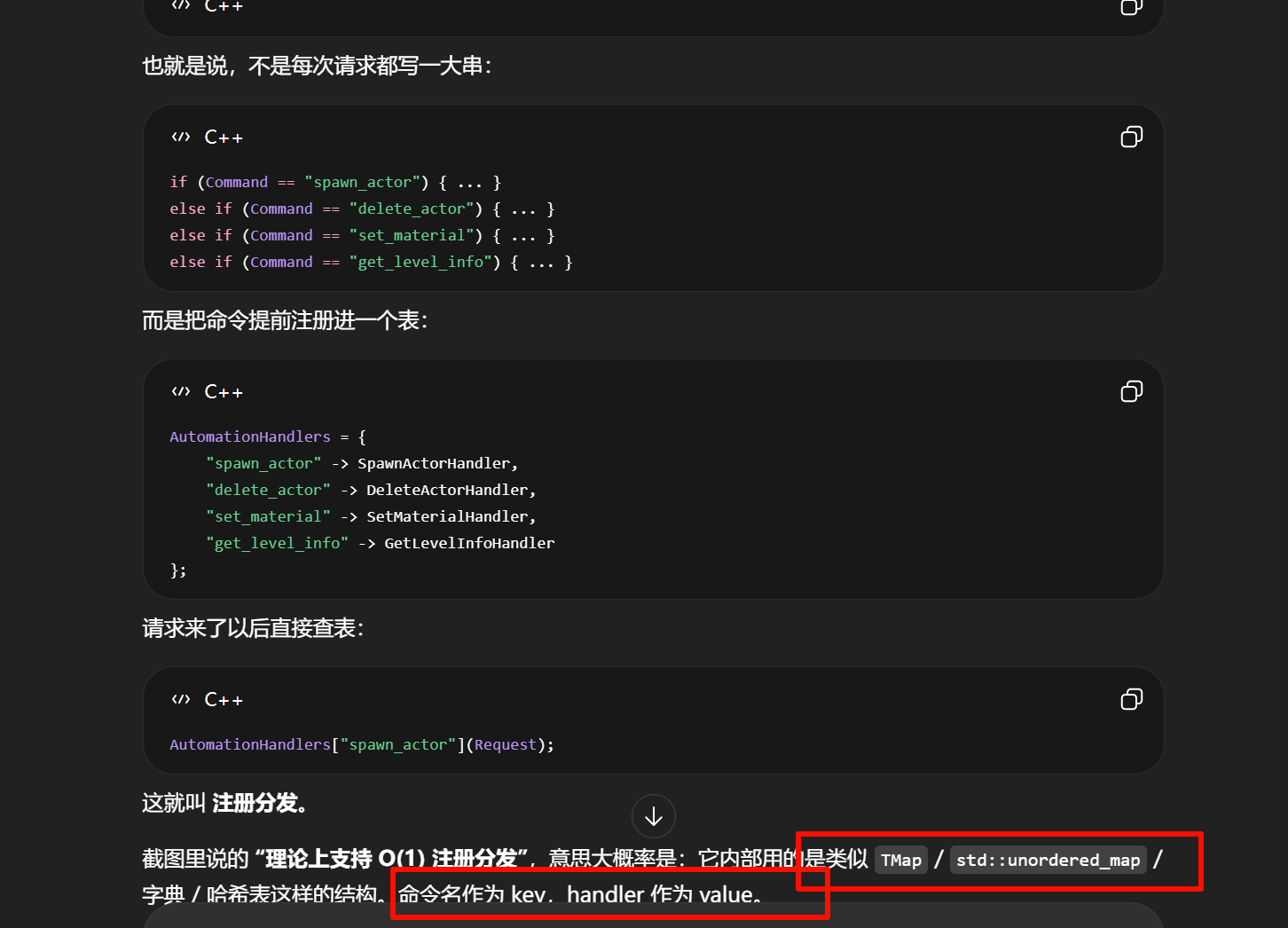
注册 = 把某个功能挂到一个表里。
分发 = 请求来了以后,根据名字/类型/ID,从表里找到对应功能并调用。
"注册分发"可以拆成两个动作看:
在 MCP / UE 插件这种架构里,它通常长这样:
C++
// 注册阶段:把 "spawn_actor" 这个名字,对应到某个处理函数
RegisterHandler("spawn_actor", SpawnActorHandler);
// 分发阶段:收到请求
ProcessAutomationRequest(Request)
{
Handler = AutomationHandlers[Request.CommandName];
Handler(Request);
}
overflow-visible!
TMap<FString, TFunction<void(const FRequest&)>> AutomationHandlers;所以查找 handler 的复杂度平均接近 O(1),也就是"给我命令名,我几乎可以直接找到对应函数",不用从头遍历一大串命令。
截图后半句也说了重点:"但实际大量逻辑仍集中在 ProcessAutomationRequest() 的一长串 handler callback 里。"
McpAutomationBridge 已经有"命令名 → 处理函数"的注册表机制,理论上新增命令可以注册进去,然后请求来了自动分发到对应 handler。但是它现在的实际代码组织可能还是偏集中式,很多功能逻辑没有被拆成独立 command/handler/service,而是堆在一个大函数或大类里。
MCP 到底是"一个能执行东西的程序",还是"一个规定能调用什么的规则"?
MCP 本身不是执行器。MCP 是一套"让 AI 知道有哪些外部工具、怎么调用、用什么参数调用、返回什么结果"的协议。真正能做什么,取决于 MCP Server 内部写了哪些 tool。
MCP Client
↓ JSON-RPC
Claude / ChatGPT / Cursor / Codex
↓
MCP Client
↓ JSON-RPC / stdio / HTTP
UE Bridge 插件
↓
Unreal Editor API这种情况下,UE Bridge 直接负责:
tools/list
tools/call
参数 schema
JSON-RPC 请求响应
调用 UE C++ / Editor API这就可以直接叫 MCP Server。
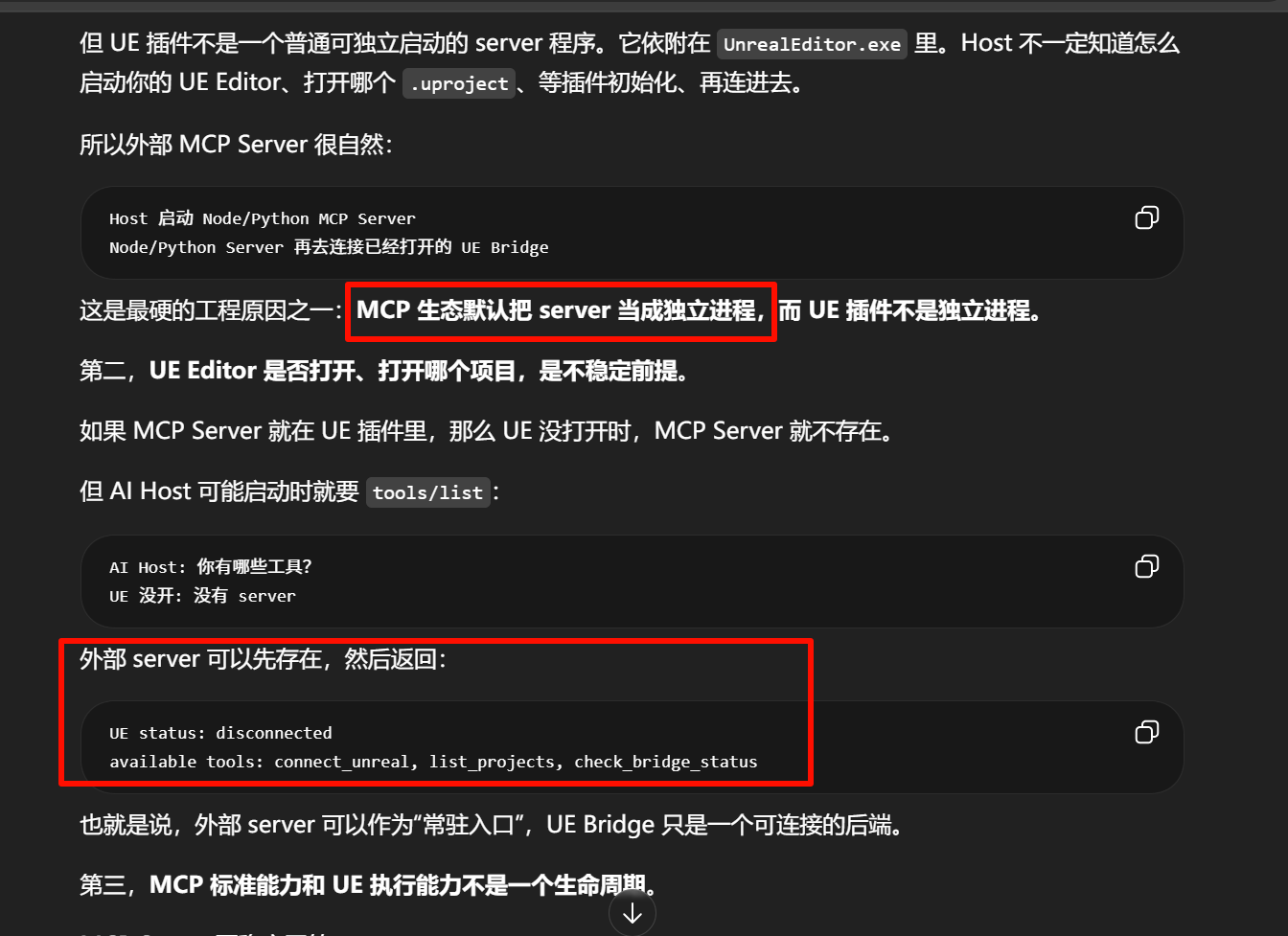
第二种更常见:外部 MCP Server + UE Bridge 插件。
Claude / ChatGPT / Cursor / Codex
↓
MCP Client
↓ JSON-RPC
外部 MCP Server,例如 Node.js / Python
↓ WebSocket / HTTP / TCP / 本地 IPC
UE Bridge 插件
↓
Unreal Editor API这种情况下,严格说:
外部 Node/Python 程序 = MCP Server
UE Bridge 插件 = MCP Server 的后端执行端 / UE Adapter / Editor Bridge它不是直接面对 MCP Host 的 server,而是 server 后面的 Unreal 执行层。
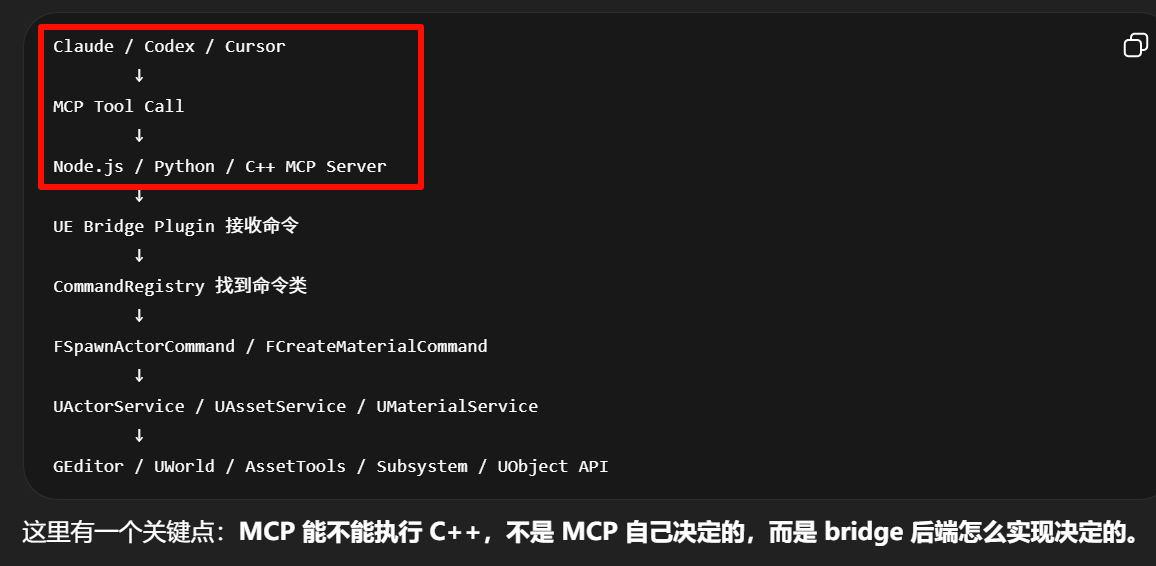
MCP Server / 外部入口层。
它负责接收外部 AI 客户端的请求,比如:
call_tool("spawn_actor", { class: "StaticMeshActor", location: [...] })
call_tool("get_selected_actors", {})
call_tool("create_material", { name: "M_WetRock" })这一层的问题是:外部世界只知道"工具名"和"参数 JSON"。它并不知道 UE 里面应该调用哪个 C++ 函数、蓝图函数、Editor Utility、Python API,或者哪个子系统。
所以需要第二层。
第二层就是 Command Registry + Command 类。
Command Registry 可以理解为一个命令表:
"spawn_actor" -> FSpawnActorCommand
"get_selected_actors" -> FGetSelectedActorsCommand
"create_material" -> FCreateMaterialCommand
"set_actor_transform" -> FSetActorTransformCommand它的作用是:
外部传进来一个字符串命令名,Registry 负责找到对应的 Command 对象,然后调用它。
典型伪代码大概是:
C++
class ICommand
{
public:
virtual FString GetName() const = 0;
virtual FCommandResult Execute(const FJsonObject& Args) = 0;
};然后每个命令单独写一个类:
C++
class FSpawnActorCommand : public ICommand
{
public:
FString GetName() const override
{
return TEXT("spawn_actor");
}
FCommandResult Execute(const FJsonObject& Args) override
{
// 解析 JSON 参数
// 校验 class / location / rotation
// 调用 Service 层执行真正的 UE 操作
return ActorService->SpawnActor(Args);
}
};Registry 负责注册:
C++
CommandRegistry.Register(MakeShared<FSpawnActorCommand>());
CommandRegistry.Register(MakeShared<FGetSelectedActorsCommand>());
CommandRegistry.Register(MakeShared<FCreateMaterialCommand>());收到请求时:
C++
auto Command = CommandRegistry.Find(CommandName);
return Command->Execute(Args);这个结构的核心意义是:把"外部命令名"从"具体实现逻辑"里解耦出来。
否则你会写出一大坨:
C++
if (CommandName == "spawn_actor") { ... }
else if (CommandName == "get_selected_actors") { ... }
else if (CommandName == "create_material") { ... }
else if (CommandName == "set_actor_transform") { ... }这种写法一开始快,后面会变成灾难。命令越多,分支越长,参数校验、权限、日志、错误处理、UE 操作全部混在一起,架构就不干净。
第三层是 Service 层。
Service 层才是真正操作 UE Editor / Runtime 的地方。比如:
ActorService
AssetService
MaterialService
LevelService
BlueprintService
SelectionService
ViewportService
WorldService业务动作交给 Service。

Sequence 不是"视频文件本身",而是 PR 里的时间线容器。
它可以只包含一段视频,也可以包含很多视频、音频、字幕、图片、Adjustment Layer、嵌套序列等。你现在拖入的第一个音频/视频创建了一条时间线,所以 PR 自动生成了一个默认序列,名字通常就是 Sequence 01。
名为 Sequence 01 的时间线的 Transcript 导出文本。
Adobe 官方也把这个叫 sequence transcript:当你把 clips 加入 timeline 后,Premiere 会创建一个新的 sequence transcript;这个 transcript 可以跟时间线同步,用于 Text-Based Editing。
Nasdaq 交易所 :撮合买卖股票的市场基础设施。
Nasdaq-100 指数 :Nasdaq 公司编制的一个产品化指数。
追踪 Nasdaq-100 的 ETF / 指数基金 / 衍生品:必须尽量复制这个指数的投资产品。
AUM
指数本身不会下单。Nasdaq 不会因为 48% 被触发就亲自去卖苹果、英伟达、微软。真正交易的是追踪指数的基金。
short for exchange-traded fund.
"investments in ETFs have not fallen"
ETF / 指数基金为了继续贴近 Nasdaq-100,就要按照新权重调仓。
如果不调仓,基金净值走势就会偏离指数,产生 tracking error。
指数基金的商业承诺就是"我尽量复制这个指数",所以它不能随便说"我觉得这次规则不合理,我不跟"。
这就是"强制交易"的含义。不是法律上有人拿枪逼基金交易,而是产品契约、跟踪误差、基金章程、投资者预期共同形成的强制性。
Nasdaq-100 的季度 rebalance 在 3、6、9、12 月进行;如果特殊集中度约束被打破,也可以触发 special rebalance。比如官方规则规定:没有一家公司权重可超过 24%;权重超过 4.5% 的公司合计权重不能超过 48%。如果触发,就会提前公告特别再平衡。Nasdaq Global Index Watch
QQQ 就是典型例子。Nasdaq 自己回顾 QQQ 历史时说,Nasdaq 在 1999 年创建了 QQQ ETF,用来追踪 Nasdaq-100 Index;2007 年又把 QQQ 卖给 PowerShares,也就是现在 Invesco 的一部分。nasdaq.com Invesco 现在也把 QQQ 表述为一个有 25 年以上历史、追踪 Nasdaq-100 的被动 ETF;其官网写明 QQQ 自 1999 年 3 月 10 日成立,总费用率为 0.18%。Invesco
可以把它类比成:
第一层:温度计显示今天 30°C。
第二层:有人发行一个合约,承诺你的收益尽量等于"这个温度计数值变化"。
第三层:为了兑现承诺,发行方必须不断调整自己的仓位。
Nasdaq-100 指数本身不买卖股票。
QQQ、QQQM、iShares Nasdaq-100 ETF、各类 UCITS ETF、养老金产品、结构票据、期货和掉期产品,才是真正要买卖股票的主体。
为什么它们必须交易?因为它们卖给投资者的不是"我帮你挑科技股",而是:
我尽量复制 Nasdaq-100 的表现。
BlackRock 加拿大的 iShares Nasdaq 100 Index ETF 就直接写明:该 ETF 的投资目标是通过复制 Nasdaq-100 Index 的表现,扣除费用后寻求长期资本增长。BlackRock 这类表述不是随口宣传,而是产品目标。基金如果长期偏离指数,就会出现 tracking error,也就是跟踪误差。
UE 还有**.modules / BuildId 机制避免加载过期二进制**,Epic 文档里也说明这是为了防止 stale binaries。参考:Epic 的 编辑Versioning of Binaries。
QQQ 官网显示总费用率 0.18%。Invesco 投资者每年把基金资产的一小部分交给基金管理人。资产规模越大,费用收入越多。假设一个 ETF 管 3000 亿美元,费用率 0.18%,年化毛费用就是约 5.4 亿美元。当然实际还要扣除运营、营销、授权、托管等成本。

开发期不应该强行保留 bUsePrecompiled = true。这个开关的语义是让模块使用预编译数据;如果你正在频繁改源码,它会让 UBT 更倾向于把这个模块当作已经预编译好的消费品,而不是当前源码开发模块。
稳定后再 package/build plugin,生成可分发版本,才切回 Installed/Precompiled 的消费形态。
指数基金和主动基金的根本区别。
主动基金卖的是:
"我比市场聪明,我来选股。"
指数基金卖的是:
"我不声称比市场聪明,我给你低成本、透明、可复制的市场暴露。"
没有这个承诺,ETF 的商业价值会崩掉。因为投资者买 Nasdaq-100 ETF,不是为了让基金经理自由判断苹果该不该减仓、英伟达该不该加仓、SpaceX IPO 后贵不贵。投资者买它,是为了获得一个明确的风险包:
100 家 Nasdaq 上市的大型非金融公司,按照 Nasdaq-100 方法论加权。
Source development
↓ build
Local compiled binary
↓ package / BuildPlugin
Packaged binary plugin
↓ install / enable
Installed precompiled plugin
↓ consume in project
Loaded UE module
Nasdaq-100 之所以能成为"可以提供子生态的大型环境",不是因为它只是一个指数,而是因为它变成了一个标准化风险接口。
它最初确实只是一个指数。Nasdaq-100 在 1985 年 1 月 31 日推出,用来追踪 Nasdaq 市场上 100 家最大的非金融公司;Nasdaq 后来把它描述为大型成长股、创新公司暴露的代表性指数。Nasdaq+1
但后来它长出了很多下游产品:ETF、期货、期权、共同基金、结构化票据、保险产品、模型组合、机构对冲工具。Nasdaq 2026 年文章称,围绕 Nasdaq-100 的生态规模已经达到约 1.4 万亿美元,覆盖 ETFs、derivatives、mutual funds、structured notes 和 insurance products。Nasdaq
这就是所谓"子生态"。
Nasdaq-100 把一堆复杂股票压缩成一个清晰标签:美国大型非金融成长股 / 科技创新股暴露。
投资者本来要自己判断苹果、微软、英伟达、亚马逊、Meta、谷歌、博通、特斯拉这些股票怎么配。但 Nasdaq-100 给了市场一个现成的组合规则:只要你买这个指数暴露,你就大致买到了"美国大型科技成长风险包"。
这件事很重要。金融市场讨厌每次都重新解释。它需要标准接口。Nasdaq-100 就像一个 API:
NDX = Nasdaq 上市的大型非金融成长公司风险敞口
有了这个 API,资产管理公司、券商、期货交易所、期权做市商、养老金、散户平台都可以围绕它继续开发产品。
QQQ 把这个指数变成了可交易入口。
1999 年,QQQ 这个 ETF 出现,目标就是追踪 Nasdaq-100。Nasdaq 自己回顾 QQQ 历史时说,QQQ 是 1999 年创建、用来追踪 Nasdaq-100 的 ETF;Invesco 现在也把 QQQ 定位为追踪 Nasdaq-100、成立于 1999 年 3 月 10 日的 ETF。Nasdaq+1
这一步的意义非常大。指数本身不能被买。ETF 让普通投资者和机构可以一键买入这个指数风险。
在 QQQ 之前,Nasdaq-100 更多是一个 benchmark。
在 QQQ 之后,Nasdaq-100 变成了一个可以直接交易、配置、对冲、套利的资产入口。
第三步,期货和期权让它从"投资产品"变成"交易基础设施"。
CME 的 E-mini Nasdaq-100 futures 允许投资者用一个期货合约获得接近 Nasdaq-100 的市场暴露,并且可以近乎 24 小时交易;CME 还强调 NQ futures 可以比直接交易 100 只股票更快、更灵活、更资本效率。CME Group+1
Nasdaq 也提供 Nasdaq-100 Index Options,例如 NDX / XND,用来管理风险、获取指数暴露、定制特定时间窗口的市场敞口。Nasdaq
这就形成第二层生态:
现货 ETF:QQQ、QQQM、各国 UCITS Nasdaq-100 ETF。
期货:NQ、Micro NQ。
期权:NDX options、XND options、QQQ options。
结构化产品:挂钩 Nasdaq-100 的票据、保险产品、收益凭证。
机构组合:以 Nasdaq-100 为 growth sleeve / tech sleeve / hedge sleeve。
到这一步,Nasdaq-100 已经不只是"指数"。它变成了一个金融市场的基础模块。
第四步,流动性本身会吸引更多流动性。
这叫网络效应。
为什么交易员喜欢 QQQ?因为它流动性深。
为什么它流动性深?因为很多交易员都用它。
为什么期权市场活跃?因为现货 ETF 活跃。
为什么机构愿意用它对冲?因为期货、ETF、期权都能互相转换。
为什么做市商愿意报价?因为成交量大,套利链条完整。
于是 Nasdaq-100 变成一个自我强化系统:
更多投资者使用
→ 更多 ETF 资产
→ 更多期权和期货成交
→ 更低交易成本
→ 更多机构策略接入
→ 更多衍生品和结构化产品
→ 更强品牌认知
→ 更多投资者继续使用
这就是"子生态"的本质:
不是一个产品成功,而是一套围绕同一风险接口互相喂养的产品族成功。
第五步,Nasdaq-100 有足够强的叙事。
S&P 500 的叙事是"美国大盘"。
Dow 的叙事是"传统蓝筹"。
Russell 2000 的叙事是"小盘股"。
Nasdaq-100 的叙事是"科技、成长、创新、AI、互联网、半导体、平台公司"。
这个叙事非常容易商品化。
基金公司可以卖:
"买美国创新。"
"买 AI 和大型科技。"
"买未来生产率。"
"买不含金融股的大型成长公司。"
Nasdaq-100 的官方描述也强调它包含 Nasdaq 市场上最大的国内和国际非金融公司,覆盖计算机硬件和软件、电信、零售/批发、生物技术等行业,并且不含金融公司。Nasdaq Global Index Watch
这比"我给你一个复杂多因子组合"更容易传播。
金融产品不只需要数学规则,也需要市场能理解的叙事包装。
指数生态不是自然长出来的,它需要指数公司、资产管理公司、交易所、做市商、数据商一起商业化。
Nasdaq 通过指数授权获得收入。
资产管理公司通过 ETF 管理费赚钱。
交易所通过期权、期货、上市、数据、交易服务赚钱。
券商通过订单流、融资融券、期权交易、结构化产品赚钱。
做市商通过报价、套利、对冲赚钱。
投资者则获得一个可交易的风险暴露工具。
所以 Nasdaq-100 的子生态本质上是一个多方分润系统。
不是只有 Nasdaq 赚。
Invesco、BlackRock、State Street、CME、Cboe / Nasdaq Options、券商、做市商、结构化产品发行商都可以围绕它赚钱。
.uplugin
插件名字、版本、描述、EnabledByDefault
CanContainContent:是否有插件自己的 Content
│
插件描述层
模块源码层:Source/ModuleName
│ ├─ Public/*.h:对外可 include 的 API
│ ├─ Private/*.cpp:内部实现
│ ├─ ModuleName.Build.cs:UBT 如何编译这个模块
│ └─ UCLASS/USTRUCT/UFUNCTION:交给 UHT 生成反射 glue code
构建规则层:Build.cs / Target.cs / UBT / UHT
编译产物层:Binaries / Intermediate
│ ├─ UnrealEditor-PluginName.dll
运行功能层:Subsystem / Command Registry / Handler / Service
"开发期不要 Installed / 不要 bUsePrecompiled"不是一个永久架构约束,最好不要写进 AGENTS.md 当长期规则。
它更像是当前阶段的工作模式:
- 现在你持续扩展插件:源码开发模式
- 以后插件稳定、要跨项目分发:预编译/Installed 模式
这种会随阶段变化的东西,写进 AGENTS.md 容易过期,之后反而误导 agent。
更合适的放法:
-
AGENTS.md:写长期不变的工程约束
比如"新增 MCP 能力走 registry,不要污染大 dispatcher"。
-
docs/McpAutomationBridgeDevelopment.md 或 README 的开发章节:写阶段性工作流
比如"开发期使用源码插件 + Live Coding;发布期再 BuildPlugin 预编译"。
-
如果要更强一点:在 AGENTS.md 里只写一句中性的长期规则:
"不要在开发期和发布期之间混用源码插件与预编译插件配置;切换模式时同步更新 .uplugin 和 .Build.cs。"
这不是固定某个模式,而是防止混用。
AI 实际上就变成了一个隐形上级:
domain 本来就是"领域、范围、管辖区、知识区域"的意思。比如:
legal domain 法律领域
medical domain 医学领域
business domain 业务领域
problem domain 问题领域
application domain 应用领域所以在软件里说 Asset domain / Actor domain / Blueprint domain,底层含义是:
这一组问题属于 Asset 这个知识范围
这一组操作由 Asset 这块负责
这一组代码应该按 Asset 的规则组织它不是 UE 专属词,也不是 MCP 专属词。
来自软件架构里的 Domain-Driven Design / DDD 文化。
在 DDD 里,domain 指的是软件真正服务的"业务世界"或"问题世界"。例如银行系统里,账户、转账、贷款、风控是 domain;电商系统里,订单、库存、支付、物流是 domain。
这个词的重点不是"文件夹分类",而是:
代码结构应该贴近真实问题世界的边界所以它反对把所有逻辑塞进一个巨大类里。因为巨大类通常意味着:
技术结构压过了问题结构比如:
BigSystemManager
- 订单
- 库存
- 用户
- 支付
- 日志
- 权限
- 通知这种结构从机器角度可以运行,但从人类理解角度会变得混乱。DDD 文化倾向于说:
Order domain
Inventory domain
Payment domain
User domain每个 domain 自己拥有自己的概念、规则、命令、错误、测试和扩展点。
所以 domain-owned handler 这个说法里,真正的重心是 owned。
它不是单纯说:
把 handler 放到不同文件夹而是说:
Asset 相关命令由 Asset 区域自己注册、自己维护、自己解释。
Actor 相关命令由 Actor 区域自己注册、自己维护、自己解释。
Core 不要知道每个功能的细节。
Core 只负责接收、调度、线程、安全、返回格式。这就是为什么 domain-owned registry architecture 听起来有一种"企业架构味"。它不是日常口语,而是架构设计语言。
一个复杂系统不应该靠中心大脑理解所有东西,
而应该让每个能力区域自己拥有自己的规则和入口。
专业交流中用 domain 往往更"架构化" ,但它也更抽象;feature 更接近"可交付的功能点 / 功能模块 / 产品能力"。你这个直觉是对的:很多情况下,feature 的范围通常比 domain 小。
domain
> feature area / capability area
> feature
> handler / command / function
所以 Unity 的层级大致是:
Rendering domain
> URP renderer customization area
> Scriptable Renderer Feature
> Scriptable Render PassCodex / Roo / Claude / Cursor 这类 AI 客户端
→ 读取某个 MCP 配置
→ 启动或连接一个 MCP server
→ MCP server 再通过 WebSocket / stdio / HTTP / 本地进程等方式访问外部系统
→ 这里外部系统就是 UE Editor 里的 bridge 插件。
所以你截图里 Codex 说的情况是合理的:UE 插件侧并没有启动 Node,它只是维护 WebSocket bridge;Node server 是由外部 MCP client 根据配置启动的。 图中提到 npx -y unreal-engine-mcp-server,这就是 Node 侧 MCP server 的启动方式。MCP 官方文档也把 MCP server 定义成给 AI 应用暴露工具、资源、能力的外部服务,而不是某个客户端私有功能。Model Context Protocol+1
关键点在这里:
你之前 Roo Code 能用 MCP,通常是因为项目里还有 .roo/mcp.json,或者全局 Roo 配置里还有 MCP server 配置。Roo 文档里也明确有 project/global MCP 配置的概念,例如 .roo/mcp.json 或全局 MCP 设置。Roo Code Docs+1
现在你换成 Codex 后还"能用",可能有三种情况。
第一种:Codex 自己也配置了同一个 MCP server。Codex 使用的是自己的配置体系,官方配置参考是 config.toml,MCP server 通常会以 [mcp_servers.xxx] 形式登记,而不是天然读取 Roo 的 .roo/mcp.json。OpenAI Developers 有些 MCP 项目会同时给 Cursor、Codex、Roo 等客户端提供配置示例,比如 Codex 侧常见是 .codex/config.toml 或 ~/.codex/config.toml。Awesome MCP Servers
第二种:虽然你删了 Roo Code 扩展,但项目里的 .roo/mcp.json 还在,Codex 或你当前项目中的某段脚本/插件逻辑把它当作参考读到了。严格说这不是 MCP 标准要求,而是具体工具/项目实现可以这么做。截图里 Codex 已经扫描到了 .roo/mcp.json,说明它至少把这个文件纳入了分析上下文。
第三种:MCP server 还在另一个地方以 Node 进程或 npx 方式被启动。删 VS Code 扩展不一定杀掉所有后台 Node 进程,也不一定删除 npm/npx 缓存、全局包、项目配置、UE 插件配置。MCP server 本质上只是一个可执行程序;只要有人启动它,它就还能工作。
bounded exponential backoff
退避的意思是:
第一次失败:1 秒后重试
第二次失败:2 秒后重试
第三次失败:4 秒后重试
第四次失败:8 秒后重试
......
最多不超过 30 秒心跳超时说明什么?说明"某个已经建立的连接可能死了"。它不说明"UE 监听端口本身坏了"。
旧逻辑如果心跳超时后直接把所有 server socket 也打掉,会发生误伤:
Node 连接断了
UE 认为 bridge 整体坏了
于是关闭监听端口
重新启动监听这会带来更大的不稳定。因为监听 socket 是"门口",客户端连接是"已经进门的那个人"。某个人没回应,不等于你要把整栋楼大门拆掉。
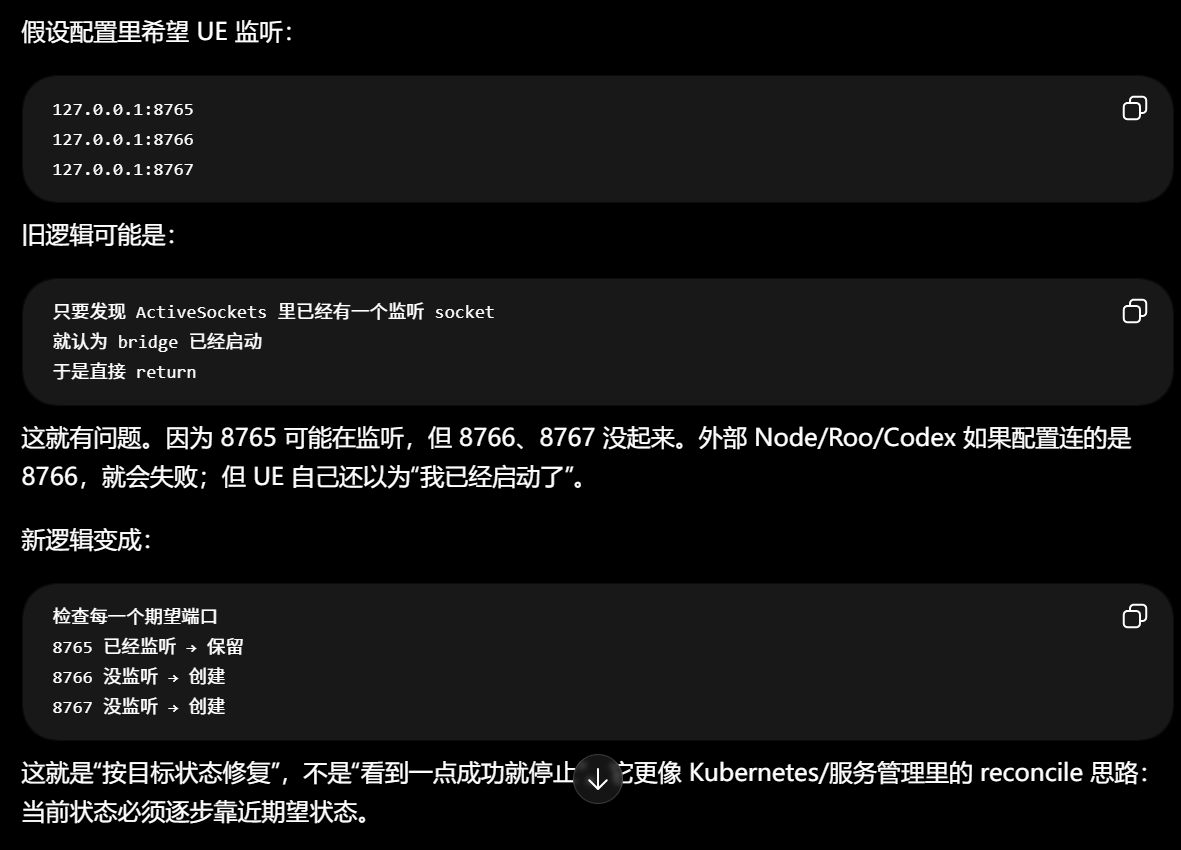
多个端口主要是为了这些情况:
1. 兼容旧配置:以前 Roo 用 8765,后来 Codex 用 8766。
2. 多个外部工具可能默认连不同端口。
3. 调试时避免端口冲突。
4. 以后支持多个 UE Editor / 多个项目实例。
5. 旧 Node server 和新 Node server 迁移期间同时兼容。不是要求你开多个端口,而是让"配置里如果有多个端口"时,代码别因为一个端口成功就误判全部成功。
是 UE Editor 进程里的 McpAutomationBridge 插件创建了一个 WebSocket server / socket listener。它会绑定到某个本地地址和端口,比如:
127.0.0.1:8765绑定成功后,UE Editor 就处于:
我在这个端口等外部程序连进来这个动作就叫 listening / 监听。