数据结构与算法|第十五章:排序算法(下)--- 非比较类排序
- [第十五章 排序算法(下)--- 非比较类排序](#第十五章 排序算法(下)— 非比较类排序)
-
- [15.1 非比较类排序的核心原理](#15.1 非比较类排序的核心原理)
-
- [15.1.1 为什么可以突破 O(n log n)](#15.1.1 为什么可以突破 O(n log n))
- [15.1.2 三种算法关系图](#15.1.2 三种算法关系图)
- [15.2 计数排序(Counting Sort)](#15.2 计数排序(Counting Sort))
-
- [15.2.1 基本思想](#15.2.1 基本思想)
- [15.2.2 代码实现](#15.2.2 代码实现)
- [15.3 桶排序(Bucket Sort)](#15.3 桶排序(Bucket Sort))
-
- [15.3.1 基本思想](#15.3.1 基本思想)
- [15.3.2 代码实现](#15.3.2 代码实现)
- [15.4 基数排序(Radix Sort)](#15.4 基数排序(Radix Sort))
-
- [15.4.1 基本思想](#15.4.1 基本思想)
- [15.4.2 LSD 基数排序(以计数排序为子过程)](#15.4.2 LSD 基数排序(以计数排序为子过程))
- [15.4.3 LSD vs MSD 对比](#15.4.3 LSD vs MSD 对比)
- [15.5 排序算法实战总结](#15.5 排序算法实战总结)
-
- [15.5.1 Arrays.sort() 与 Collections.sort() 源码分析](#15.5.1 Arrays.sort() 与 Collections.sort() 源码分析)
- [15.5.2 海量数据排序(外部排序)](#15.5.2 海量数据排序(外部排序))
- [15.5.3 排序算法的实际工程选型](#15.5.3 排序算法的实际工程选型)
- 总结与预告
下篇:第十六章、二分查找与搜索
第十五章 排序算法(下)--- 非比较类排序
上一章我们深入学习了六种基于比较的排序算法。尽管它们在最坏情况下各有千秋,但都受制于一个根本性的理论上限------任何基于比较的排序算法,其最坏时间复杂度不可能低于 O ( n log n ) O(n \log n) O(nlogn) 。这是信息论中决策树模型给出的严格下界: n n n 个元素的排列共有 n ! n! n! 种可能,每次比较最多排除一半,因此至少需要 ⌈ log 2 ( n ! ) ⌉ ≈ n log 2 n \lceil \log_2(n!) \rceil \approx n \log_2 n ⌈log2(n!)⌉≈nlog2n 次比较。
那么问题来了------有没有可能突破 O ( n log n ) O(n \log n) O(nlogn) ?
答案是:有,但必须放弃"比较"这一基本操作。
非比较类排序不通过比较元素大小来决定顺序,而是利用元素本身的分布特征 (如取值范围、位数、桶区间)直接定位。它们可以在 O ( n ) O(n) O(n) 时间内完成排序------但代价是对数据有额外的"硬性要求"。
本章我们先逐一拆解三种核心非比较排序算法,最后深入分析 JDK 源码中 Arrays.sort() 和 Collections.sort() 的底层实现(TimSort),以及海量数据场景下的外部排序策略。
15.1 非比较类排序的核心原理
15.1.1 为什么可以突破 O(n log n)
比较类排序的信息论下界 O ( n log n ) O(n \log n) O(nlogn) 建立在元素之间可以是任意顺序 的前提下。但如果我们知道元素的额外信息,就可以绕过"比较"这一瓶颈:
| 非比较排序 | 利用的信息 | 必要条件 |
|---|---|---|
| 计数排序 | 元素的取值范围(min ~ max) | 范围不能太大 |
| 桶排序 | 元素的分布(均匀分布最佳) | 能均匀划分桶 |
| 基数排序 | 元素的数位结构(个位、十位...) | 元素可被"切割"为多个键 |
核心思想:将排序问题转化为"计数"或"分配"问题,用空间换时间。
15.1.2 三种算法关系图
作为子过程
桶内排序
LSD版本
MSD版本
非比较类排序
计数排序 Counting Sort
桶排序 Bucket Sort
基数排序 Radix Sort
插入排序 / 快速排序
从低位到高位逐位排序
从高位到低位递归排序
15.2 计数排序(Counting Sort)
15.2.1 基本思想
计数排序:统计每个元素出现的次数 ,然后根据计数直接"还原"出有序序列。它假设输入数据的取值范围是已知且有限的。
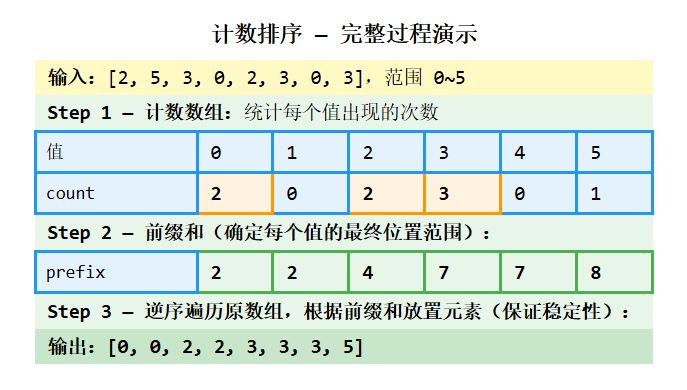
逆序遍历的作用 :从后往前放置元素,并将前缀和递减,这样相同值的元素会按照原顺序反向放置到输出数组的"最后一个可用位置",从而保证稳定性。
15.2.2 代码实现
java
import java.util.Arrays;
/**
* 计数排序(稳定版)
* 时间复杂度:O(n + k),其中 k = max - min + 1
* 空间复杂度:O(n + k)
* 稳定性:稳定
*
* 适用条件:输入数据取值范围有限(k 不能太大)
*/
public void countingSort(int[] arr) {
if (arr == null || arr.length <= 1) return;
int n = arr.length;
// 1. 找到最小值和最大值,确定计数数组大小
int min = arr[0], max = arr[0];
for (int num : arr) {
if (num < min) min = num;
if (num > max) max = num;
}
int range = max - min + 1;
int[] count = new int[range];
// 2. 统计每个元素出现的次数
for (int num : arr) {
count[num - min]++;
}
// 3. 计算前缀和:count[i] = 值 <= (min + i) 的元素个数
// 即每个值的最后一个元素在输出数组中的"索引 + 1"
for (int i = 1; i < range; i++) {
count[i] += count[i - 1];
}
// 4. 逆序遍历原数组,放置元素到正确位置(保证稳定性)
int[] output = new int[n];
for (int i = n - 1; i >= 0; i--) {
int idx = arr[i] - min; // 该值在 count 中的索引
output[count[idx] - 1] = arr[i]; // 放到正确位置
count[idx]--; // 位置指针前移
}
// 5. 拷回原数组
System.arraycopy(output, 0, arr, 0, n);
}算法分析 :当 k = O ( n ) k = O(n) k=O(n) 时,计数排序的时间复杂度为 O(n) 。但如果 k k k 很大(例如对 1, 1000000 排序),时间退化为 O(k),空间也浪费严重。计数排序的适用前提是数据范围 k 与数据量 n 处于同一数量级。
15.3 桶排序(Bucket Sort)
15.3.1 基本思想
桶排序:将数据均匀分配到若干个桶 中,每个桶内单独排序,最后按桶的顺序依次取出所有元素。它的核心假设是输入数据均匀分布。
类比:将一堆考卷按分数段分到不同盒子(0-10、11-20...),每个盒子内排好序后,按盒子顺序收集即可。
输入:[0.42, 0.32, 0.78, 0.15, 0.57, 0.93, 0.21, 0.64]
桶数 = 5,每个桶覆盖 [0, 0.2]、[0.2, 0.4]、...
桶0 [0, 0.2) → [0.15]
桶1 [0.2, 0.4) → [0.32, 0.21] → 排序 → [0.21, 0.32]
桶2 [0.4, 0.6) → [0.42, 0.57] → 排序 → [0.42, 0.57]
桶3 [0.6, 0.8) → [0.78, 0.64] → 排序 → [0.64, 0.78]
桶4 [0.8, 1.0] → [0.93]
输出:[0.15, 0.21, 0.32, 0.42, 0.57, 0.64, 0.78, 0.93]15.3.2 代码实现
java
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
/**
* 桶排序(适用于 [0, 1) 范围内的浮点数)
* 时间复杂度:平均 O(n + k),k 为桶数;最坏 O(n²)(所有元素落入同一桶)
* 空间复杂度:O(n + k)
* 稳定性:取决于桶内排序算法(此处用 Collections.sort 是稳定的)
*/
public void bucketSort(double[] arr) {
if (arr == null || arr.length <= 1) return;
int n = arr.length;
int bucketCount = n; // 通常桶数取 n
// 1. 创建桶
@SuppressWarnings("unchecked")
List<Double>[] buckets = new ArrayList[bucketCount];
for (int i = 0; i < bucketCount; i++) {
buckets[i] = new ArrayList<>();
}
// 2. 将元素分配到对应的桶
for (double num : arr) {
int bucketIdx = (int)(num * bucketCount); // 映射到桶
// 边界情况:num == 1.0 时防止越界
if (bucketIdx >= bucketCount) bucketIdx = bucketCount - 1;
buckets[bucketIdx].add(num);
}
// 3. 对每个桶内排序,并依次写回原数组
int idx = 0;
for (List<Double> bucket : buckets) {
Collections.sort(bucket); // 桶内排序(JDK 默认 TimSort)
for (double num : bucket) {
arr[idx++] = num;
}
}
}桶排序 vs 计数排序 :计数排序可以看作桶排序的一种极端特例 ------每个"值"就是一个桶。桶排序更灵活,可以处理浮点数等连续数据,但性能极度依赖数据的均匀分布。如果所有数据落入同一个桶,桶排序退化为桶内排序算法的复杂度。
15.4 基数排序(Radix Sort)
15.4.1 基本思想
基数排序:不直接比较元素大小,而是将每个元素视为**多个"位"(digit)**的组合,从最低位(LSD)或最高位(MSD)开始,逐位进行稳定的排序。
类比:对一组日期排序------先按"日"排,再按"月"排,最后按"年"排。由于每轮排序是稳定的,"年"相同的日期中,"月"的顺序不会被破坏。
LSD(Least Significant Digit) :从个位 → 十位 → 百位......逐位使用稳定排序(如计数排序)。
MSD(Most Significant Digit) :从最高位开始,将数据按高位分组,再递归地对每组排序。
15.4.2 LSD 基数排序(以计数排序为子过程)
java
import java.util.Arrays;
/**
* LSD 基数排序(非负整数)
* 时间复杂度:O(d × (n + k)),d 为最大位数,k 为基数(十进制 k=10)
* 空间复杂度:O(n + k)
* 稳定性:稳定
*/
public void radixSort(int[] arr) {
if (arr == null || arr.length <= 1) return;
int n = arr.length;
// 找到最大值,确定位数
int max = arr[0];
for (int num : arr) {
if (num > max) max = num;
}
// 逐位进行计数排序(个位 → 十位 → 百位 → ...)
int[] output = new int[n];
for (int exp = 1; max / exp > 0; exp *= 10) {
countingSortByDigit(arr, output, exp);
}
}
/** 按第 exp 位(1=个位, 10=十位, ...)进行计数排序 */
private void countingSortByDigit(int[] arr, int[] output, int exp) {
int n = arr.length;
int[] count = new int[10]; // 十进制:0~9
// 1. 统计当前位上每个数字出现的次数
for (int num : arr) {
int digit = (num / exp) % 10;
count[digit]++;
}
// 2. 前缀和
for (int i = 1; i < 10; i++) {
count[i] += count[i - 1];
}
// 3. 逆序放置(保证稳定性)
for (int i = n - 1; i >= 0; i--) {
int digit = (arr[i] / exp) % 10;
output[count[digit] - 1] = arr[i];
count[digit]--;
}
// 4. 拷回
System.arraycopy(output, 0, arr, 0, n);
}基数排序 vs 计数排序 :计数排序一次性对所有值建立直方图,适合范围小的场景 ;基数排序逐位处理,适合范围大但位数少的场景 (如对 32 位整数排序,基数取 2 16 2^{16} 216 只需 2 轮)。
15.4.3 LSD vs MSD 对比
| 维度 | LSD(最低位优先) | MSD(最高位优先) |
|---|---|---|
| 处理方向 | 个位 → 十位 → 百位 | 百位 → 十位 → 个位 |
| 实现方式 | 迭代(for 循环) | 递归(高位分组后递归处理低位) |
| 子排序稳定性要求 | 必须稳定 | 必须稳定 |
| 中间结果 | 每轮产生完整中间排序 | 高位分组后就地处理子组 |
| 适合场景 | 定长整数 | 变长字符串(字典序) |
| 空间开销 | 需要输出数组 | 递归栈 + 计数数组 |
15.5 排序算法实战总结
学完九种排序算法(第 9 章的堆排序 + 第 14 章的 6 种比较类 + 本章的 3 种非比较类)后,让我们回到现实------在实际工程中,JDK 到底用的是什么排序算法?
15.5.1 Arrays.sort() 与 Collections.sort() 源码分析
JDK 对不同类型的数据采用了不同的排序策略:
| 排序方法 | 排序的数据类型 | 底层算法 | 说明 |
|---|---|---|---|
Arrays.sort(int[]) |
基本类型数组 | 双轴快速排序(Dual-Pivot Quicksort) | 不需要稳定性,追求极致性能 |
Arrays.sort(long[]) |
基本类型数组 | 双轴快速排序 | 同上 |
Arrays.sort(Object[]) |
对象数组 | TimSort | 需要稳定性 |
Collections.sort(List<T>) |
集合 | TimSort(委托给 Arrays.sort) |
需要稳定性 |
关键设计决策 :基本类型排序不需要稳定性(1 和 1 谁先谁后没有区别),所以用最快的快排;引用类型排序必须稳定(用户可能依赖相等元素的原始顺序),所以用 TimSort。
TimSort 核心原理:
TimSort 由 Tim Peters 于 2002 年为 Python 设计,后被 Java、Android、V8 等广泛采用。它是归并排序 + 插入排序的混合体:
TimSort 的核心思路:
1. 扫描数组,识别"自然有序片段"(Run),每个 Run 至少为 MIN_RUN(通常 32)
2. 如果 Run 很短或是降序的,用二分插入排序将其整理为升序
3. 将 Run 压入栈,维护栈的不变性(相邻 Run 长度递减)
4. 当栈顶三个 Run 不满足不变性时,合并相邻 Run(归并)
5. 最终合并所有 Run
原始数组: [5, 1, 3, 8, 2, 7, 6, 4, | 9, 10, 12, 11, | 15, 13, 14]
└── Run 1(32以内)──┘ └── Run 2 ──┘ └── Run 3 ──┘
Step 1: 识别 Runs,用二分插入排序整理
Step 2: 栈合并 [Run1, Run2] → 更大的有序段
Step 3: 栈合并 [合并结果, Run3] → 最终有序数组TimSort 的巧妙之处:
- 利用了真实数据中普遍存在的部分有序性(如日志的时间戳、数据库的自增 ID)
- 在近乎有序的数据上能达到 O(n)!
- 二分插入排序处理小 Run 时,常数因子极小
- 归并时使用"飞奔模式(Galloping)"------当一侧连续多次被选中时,切换到指数搜索加速合并
15.5.2 海量数据排序(外部排序)
当数据量大到无法全部装入内存 时(如 10GB 的日志文件),传统的排序算法全部失效------我们需要外部排序(External Sorting)。
核心策略:多路归并排序
┌─────────────────────────────────────────────────┐
│ 外部排序(External Sort) │
├─────────────────────────────────────────────────┤
│ 阶段一:分块排序(Sort Phase) │
│ 将大文件切分为 N 个能装入内存的块 │
│ 每块读入内存 → 内部排序 → 写回临时文件 │
│ │
│ 10GB 文件 │
│ ┌────┬────┬────┬────┬────┐ │
│ │ 1G │ 1G │ 1G │ 1G │ 1G │ ... ×10块 │
│ └────┴────┴────┴────┴────┘ │
│ ↓ ↓ ↓ ↓ ↓ │
│ 排序 排序 排序 排序 排序 │
│ ↓ ↓ ↓ ↓ ↓ │
│ 块1 块2 块3 块4 块5 ... (有序临时文件) │
│ │
│ 阶段二:K 路归并(Merge Phase) │
│ 同时打开 K 个临时文件 │
│ 每个文件读取一小部分到输入缓冲区 │
│ 用最小堆(K 大小)选出当前最小值 → 写入输出文件 │
│ │
│ 块1: [1, 5, 9, ...] ┐ │
│ 块2: [2, 3, 7, ...] ├─→ 最小堆 ─→ 输出文件 │
│ 块3: [0, 4, 6, ...] ┘ (K路归并) │
│ │
│ K 值取决于可用内存 ÷ 每路的缓冲区大小 │
└─────────────────────────────────────────────────┘
java
/**
* 外部排序的核心:K 路归并(使用优先队列)
* 此代码演示 K 路归并的原理,实际外部排序还需处理文件 I/O
* @param sortedChunks 每个内部有序的数据块
* @return 合并后的有序结果
*/
public List<Integer> kWayMerge(List<List<Integer>> sortedChunks) {
List<Integer> result = new ArrayList<>();
int k = sortedChunks.size();
// 小顶堆:存储 (值, 来自哪个块)
PriorityQueue<int[]> pq = new PriorityQueue<>((a, b) -> a[0] - b[0]);
// 每个块的当前读取指针
int[] pointers = new int[k];
// 初始化:将每个块的第一个元素入堆
for (int i = 0; i < k; i++) {
List<Integer> chunk = sortedChunks.get(i);
if (!chunk.isEmpty()) {
pq.offer(new int[]{chunk.get(0), i});
pointers[i] = 1;
}
}
// 持续从堆中取最小值
while (!pq.isEmpty()) {
int[] min = pq.poll();
result.add(min[0]);
int chunkIdx = min[1];
// 从对应块中取下一个元素
List<Integer> chunk = sortedChunks.get(chunkIdx);
if (pointers[chunkIdx] < chunk.size()) {
pq.offer(new int[]{chunk.get(pointers[chunkIdx]), chunkIdx});
pointers[chunkIdx]++;
}
}
return result;
}外部排序的关键参数:
- 块大小 = 可用内存(留出堆和缓冲区空间)
- K 路归并的 K = 可用内存 ÷ 每路缓冲区大小
- 替换-选择排序(Replacement Selection):一种更优的初始块生成算法,能产生比内存更大的有序块
15.5.3 排序算法的实际工程选型
综合第 14 章和本章,我们已掌握九种排序算法。以下是最终的工程选型决策树:
否
是
是
否
n < 50
n >= 50
是
否
基本类型
范围小
均匀分布
位数少
通用
对象
近乎有序
随机
开始:需要排序?
数据能全部
装入内存?
外部排序
(多路归并)
需要稳定性?
数据规模?
数据类型?
插入排序
基本类型?
TimSort
(JDK默认)
TimSort
Collections.sort
分布特征?
计数排序
O(n+k)
桶排序
基数排序
双轴快速排序
Arrays.sort
已知有序?
TimSort O(n)
归并排序 / TimSort
一句话总结:
| 场景 | 最佳选择 |
|---|---|
| 面试 / 考试 | 快速排序(双路 / 三路) |
| Java 基本类型数组 | Arrays.sort() --- 双轴快排 |
| Java 对象集合 | Collections.sort() --- TimSort |
| 数据量小(n < 50) | 插入排序 |
| 数据取值范围小(0~1000) | 计数排序 |
| 均匀分布的浮点数 | 桶排序 |
| 大量等长整数 / 字符串 | 基数排序 |
| 数据太大放不进内存 | 外部排序(K 路归并) |
| 链表排序 | 归并排序(O(1) 空间合并链表) |
总结与预告
本章和上一章共同构成了排序算法的完整版图。回顾整个排序专题:
| 排序算法 | 最好 | 平均 | 最坏 | 空间 | 稳定 | 分类 |
|---|---|---|---|---|---|---|
| 冒泡排序 | O(n) | O(n²) | O(n²) | O(1) | ✅ | 比较类 |
| 选择排序 | O(n²) | O(n²) | O(n²) | O(1) | ❌ | 比较类 |
| 插入排序 | O(n) | O(n²) | O(n²) | O(1) | ✅ | 比较类 |
| 希尔排序 | O(n log n) | O(n^{3/2}) | O(n²) | O(1) | ❌ | 比较类 |
| 归并排序 | O(n log n) | O(n log n) | O(n log n) | O(n) | ✅ | 比较类 |
| 快速排序 | O(n log n) | O(n log n) | O(n²) | O(log n) | ❌ | 比较类 |
| 堆排序 | O(n log n) | O(n log n) | O(n log n) | O(1) | ❌ | 比较类 |
| 计数排序 | --- | O(n + k) | O(n + k) | O(n + k) | ✅ | 非比较 |
| 桶排序 | --- | O(n + k) | O(n²) | O(n + k) | ✅ | 非比较 |
| 基数排序 | --- | O(d·n) | O(d·n) | O(n + k) | ✅ | 非比较 |
核心结论:
- 比较类排序的下界是 O ( n log n ) O(n \log n) O(nlogn)------归并排序和堆排序在任何情况下都能达到此下界,快速排序在平均情况下最优
- 非比较类排序可以突破到 O ( n ) O(n) O(n)------但前提是数据的分布/范围满足特定条件
- JDK 对基本类型用双轴快排 (不要求稳定性,追求速度),对对象用 TimSort(要求稳定性,利用部分有序性加速)
- 海量数据用外部排序------核心是"分块内排 + K 路归并"
- 实际工程中直接用
Arrays.sort()/Collections.sort()就好------JDK 已经帮你做了最优选择!
下一章我们将进入二分查找与搜索的世界------从最基本的二分搜索框架出发,深入到各种变体(查找第一个/最后一个等于 target 的位置、旋转数组中的二分查找),以及跳跃搜索、插值搜索等高效搜索策略。
下篇:第十六章、二分查找与搜索