今年3月,我开源了 Hermes Agent CN,一个轻量级 AI Agent 框架。几个月来,社区反馈最多的问题是:"Agent 怎么操作真实的软件界面?"
之前的方案依赖于 DOM、CSS 选择器、坐标定位------每种界面都得写不同的解析逻辑,浏览器、桌面软件、3D 工具、游戏,各有各的"方言"。
而人类操作界面从来不需要这些。我们看一眼就知道按钮在哪。
这正是 browser-agent(包名 gui-agent-vlm)要解决的问题------让 AI 通过纯视觉理解操作任何界面。
一个真实测试:AI 完整操作小红书
今天做了个端到端测试,验证 AI 是否真的能像人一样"看屏幕操作":
任务线:打开小红书 → 找一篇笔记点赞 → 返回首页 → 搜索指定内容 → 找到结果页 → 点赞 → 完成7 步任务编排,全部自动完成,中间没有一行硬编码的 CSS 选择器。AI 通过截图观察页面,理解每个元素是什么,决定下一步做什么。
测试用的模型是 Qwen/Qwen3-VL-8B-Thinking(硅基流动云端 API),每次操作前先截图分析,识别按钮位置,调用对应工具执行。
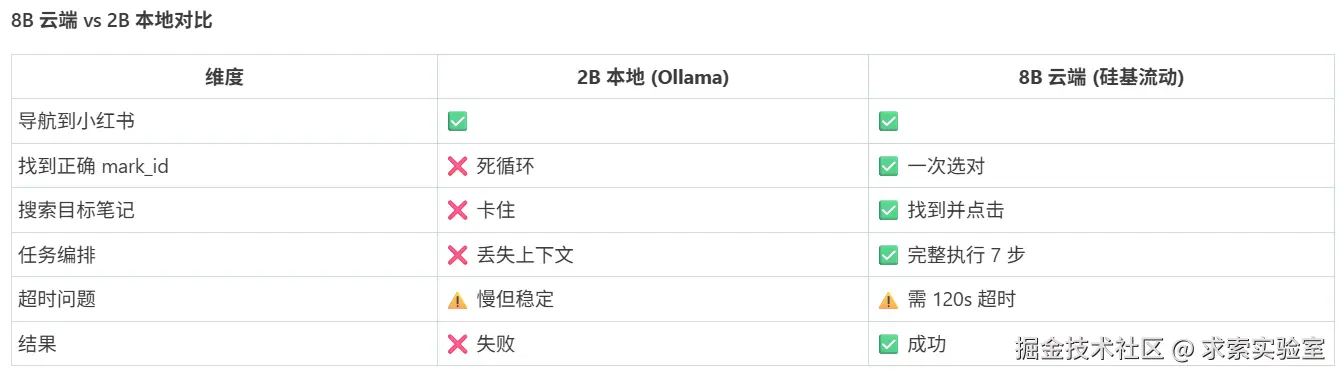
测试过程中,我们也对比了不同规模 VLM 的效果差异:
Ollama qwen3-vl:2b(本地) --- 2B 模型在复杂多步任务中很快暴露瓶颈:视觉精度不够,经常把"导航按钮"和"搜索输入框"搞混;POI 检测到交互元素后,模型在两步操作之间就开始"遗忘"页面状态,反复做同一操作陷入死循环。它对"页面加载完成"和"操作成功"的视觉反馈几乎无感。7 步任务链跑到第 3 步就卡死了。
 Qwen/Qwen3-VL-8B-Thinking(硅基流动) --- 同样是纯视觉截图驱动,8B 模型整条链路走通。关键差异在于:它能正确区分"导航到新页面 ≠ 在当前页搜索",能够感知点赞后的 UI 反馈(心形变红),遇到意外弹窗(如登录提示)能自然跳过继续任务。
Qwen/Qwen3-VL-8B-Thinking(硅基流动) --- 同样是纯视觉截图驱动,8B 模型整条链路走通。关键差异在于:它能正确区分"导航到新页面 ≠ 在当前页搜索",能够感知点赞后的 UI 反馈(心形变红),遇到意外弹窗(如登录提示)能自然跳过继续任务。
 结论很清晰:GUI 自动化场景下,8B 是复杂任务的入门之选。 2B/4B 适合单一页面内的简单点击(如"点一下弹窗确认"),但涉及页面切换、搜索、状态判断的多步编排,参数规模直接决定了可用性。从实测看,本地 8B(如 qwen3-vl:8b 的 Ollama 版本)效果也会接近云端,8GB VRAM 即可部署。
结论很清晰:GUI 自动化场景下,8B 是复杂任务的入门之选。 2B/4B 适合单一页面内的简单点击(如"点一下弹窗确认"),但涉及页面切换、搜索、状态判断的多步编排,参数规模直接决定了可用性。从实测看,本地 8B(如 qwen3-vl:8b 的 Ollama 版本)效果也会接近云端,8GB VRAM 即可部署。
架构:不是另一个自动化工具
市面上做浏览器自动化的项目不少。但 browser-agent 的定位不一样------它是编排器,不是执行器。
scss
用户/Agent 下达任务
│
▼
browser-agent (编排器)
ModelRouter 自动选模型
│
├── PlaywrightExecutor (浏览器)
│ └── 通过 VLM 截图理解 + 操作
│
└── ManoPExecutor (桌面 GUI)
└── 纯视觉定位(Mano-P 云端 API)三层可插拔架构
第一层:执行器抽象
PlaywrightExecutor 负责浏览器,ManoPExecutor 负责桌面 GUI。每个执行器只需实现 observe()(观察)和 act()(操作)两个接口。想支持新界面?写个新执行器就行。
第二层:模型自动检测
不绑死任何模型。ModelRouter 自动检测可用 VLM:
| 优先级 | 模型源 | 适用场景 |
|---|---|---|
| P0 | 手动指定 | 生产环境固定配置 |
| P1 | Ollama / vLLM / LM Studio 本地 VLM | 离线/私有化部署 |
| P2 | 调用方 Agent 注入 | Hermes Agent 等框架集成 |
甚至支持 Agent 把自己的模型注入给 browser-agent 用,省去单独部署一套推理服务。
第三层:监督纠错
操作前后自动截图,pHash 比对验证页面是否发生变化。超过阈值自动重试,避免"以为点了但页面没动"的经典死循环。
三种调用方式
python
# 1. Python API
from browser_agent import BrowserAgent
agent = BrowserAgent()
result = agent.run("搜索深圳天气")
print(result.text)
bash
# 2. CLI
browser-agent "搜索深圳天气"
browser-agent --no-headless "帮我登录 GitHub" # 调试模式
json
// 3. MCP Server(跨框架兼容)
{
"mcpServers": {
"browser-agent": {
"command": "python",
"args": ["-m", "browser_agent.mcp_server"]
}
}
}MCP Server 模式意味着 Cline、Cursor、Continue、甚至你现在正在用的编辑器------任何支持 MCP 的 Agent 框架都可以直接调用。
今天,gui-agent-vlm 正式发布到 PyPI
pip install gui-agent-vlm
playwright install chromium- 29 个单元测试 + 3 个模拟 E2E 场景,全部通过
- 与 Hermes Agent CN 深度集成(自带 SKILL.md,MCP 配置即用)
- 跨平台:Linux / Windows / macOS / WSL2
后续规划
- 更多执行器:Mano-P 本地推理(等 NVIDIA CUDA 开源)、Selenium、Puppeteer
- 更智能的监督:执行前预测结果 vs 执行后实际结果对比
- 大规模 E2E 测试:多站点、复杂交互场景
最后
browser-agent 尝试回答一个很简单的问题------
如果 AI 能像人一样"看屏幕"操作,那我们还需要为每种软件写适配器吗?
我觉得不需要。欢迎试试。
GitHub: github.com/xyshanren/b... PyPI: pypi.org/project/gui...
守一 | 求索实验室
聚焦 AI Agent、GUI 自动化、开源工具