说明:这是一个实战项目(附带数据+代码+文档 ),如需数据+代码+文档 可以直接到文章最后关注 获取 或者私信获取。
1 . 项目背景
在医疗健康、公共卫生及社会科学研究中,计数型因变量(如患者年就诊次数、疾病发病次数等)极为常见。这类数据往往存在"过离散"(方差显著大于均值)现象,无法满足泊松回归的等离散假设。本项目以居民年度门诊就诊次数(visit_count)为研究目标,综合考虑年龄(age)、慢性病患病情况(chronic_disease)和收入水平(income)等关键因素,采用负二项回归模型进行建模分析。该模型通过引入离散参数有效处理过离散问题,不仅能准确估计各协变量对就诊频率的影响强度,还可计算发病率比(IRR),为理解就医行为驱动机制、优化医疗资源配置提供数据支持与决策依据。
2 . 数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
|------------|-----------------|------------|
| 编号 | 变量名称 | 描述 |
| 1 | visit_count | 就诊次数 |
| 2 | age | 年龄 |
| 3 | chronic_disease | 慢性病患病情况 |
| 4 | income | 收入水平 |
数据详情如下(部分展示):
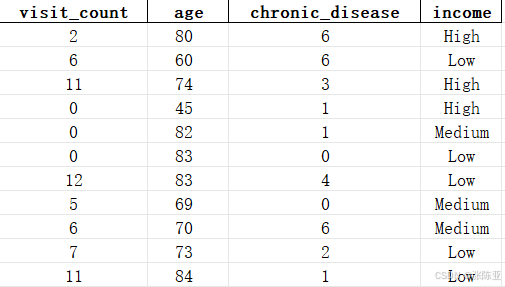
3. 数据预处理
3.1 查看数据
使用head()方法查看前五行数据:

关键代码:

3.2 数据缺失查看
数据缺失信息:

从上图可以看到,数据中无缺失值。
关键代码:
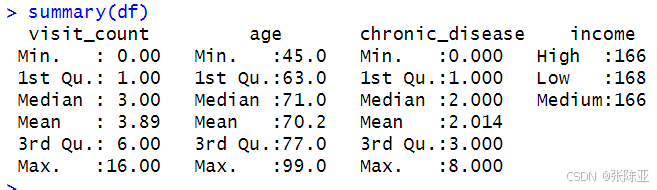
3. 3数据描述性统计
通过summary方法来查看数据的平均值、最小值、分位数、最大值。
关键代码如下:
4. 探索性数据分析
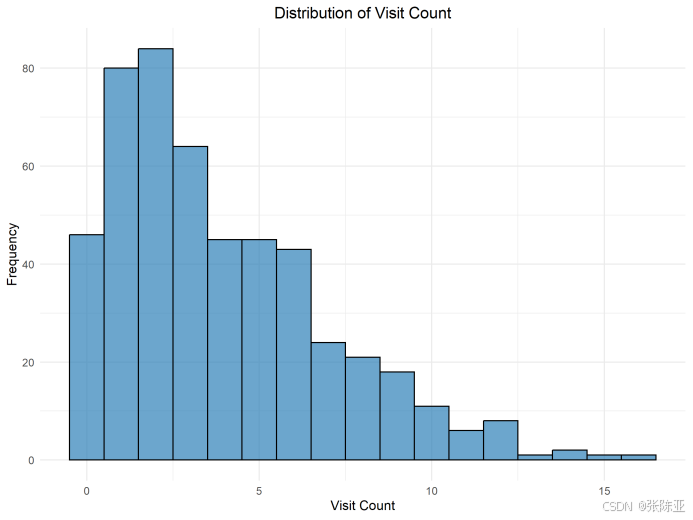
4 .1 分布直方图
用ggplot工具绘制直方图:
4 .2 相关性分析
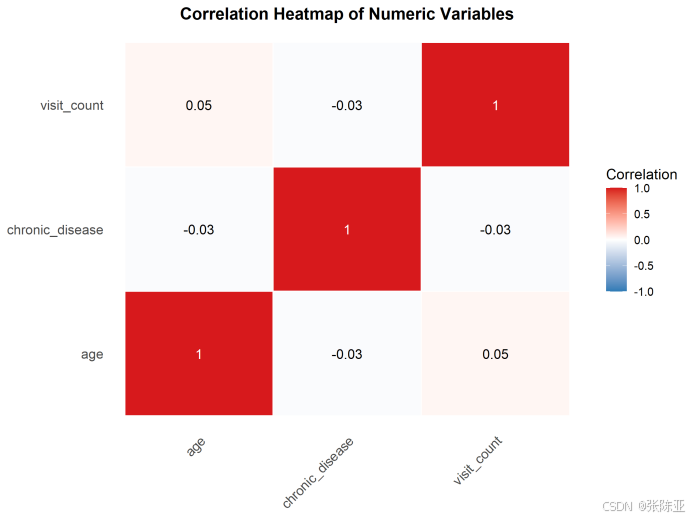
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5. 特征工程
5. 1 数据集拆分
通过createDataPartition方法按照80%训练集、20%测试集进行划分,关键代码如下:

6. 构建 负二项回归模型
主要通过R构建负二项回归模型,用于目标回归。
6. 1 构建模型
|------------|--------------|-----------------------------------------------|
| 编号 | 模型名称 | 参数 |
| 1 | 负二项回归模型 | visit_count ~ age + chronic_disease + income |
| 2 | 负二项回归模型 | data = train_data |
6. 2 模型摘要信息
|-----------------|-------------------------|------------------------|-------------|--------------|
| 变量 | 系数估计 (Estimate) | 标准误 (Std. Err) | z 值 | p 值 |
| (Intercept) | 0.9596 | 0.3031 | 3.166 | 0.0016*** |
| age | 0.0058 | 0.00409 | 1.417 | 0.1564 |
| chronic_disease | -0.01375 | 0.02832 | -0.486 | 0.6272 |
| incomeLow | 0.03372 | 0.09894 | 0.341 | 0.7333 |
| incomeMedium | -0.02118 | 0.10078 | -0.21 | 0.8335 |
该负二项回归模型结果显示,截距项显著为正(p = 0.0016),表明在参考水平(年龄为0、无慢性病、高收入)下,预期就诊次数的对数值显著大于0;然而,所有协变量------年龄(p = 0.156)、慢性病状态(p = 0.627)、收入水平(低收入 vs 高收入:p = 0.733;中收入 vs 高收入:p = 0.834)------均未达到统计显著性(p > 0.05),说明在当前样本中,这些因素对门诊就诊次数的影响尚无足够证据支持。模型整体拟合良好(AIC = 1930,残差偏差 ≈ 自由度),但提示可能需扩大样本量、引入非线性或交互效应以提升解释力。
7 . 模型评估
7.1评估指标及结果
测试集 RMSE: 3.277,测试集 MAE: 2.636。
关键代码如下:

7. 2 发病率比IRR
|-----------------|------|
| | IRR |
| (Intercept) | 2.61 |
| age | 1.01 |
| chronic_disease | 0.99 |
| incomeLow | 1.03 |
| incomeMedium | 0.98 |
模型的发病率比(IRR)结果显示:在控制其他变量的情况下,年龄每增加一岁,预期就诊次数约增加1%(IRR = 1.01);患有慢性病者的就诊次数约为无慢性病者的99%(IRR = 0.99),略低但差异微弱;低收入群体的就诊次数比高收入群体高约3%(IRR = 1.03),而中等收入群体则略低2%(IRR = 0.98)。截距项表明,参照组(年龄为0、无慢性病、高收入)的预期年就诊次数约为2.61次。总体来看,各协变量的IRR均非常接近1,结合此前不显著的p值,说明这些因素对门诊就诊频率的影响在统计上不显著,实际效应也微弱一些。
8. 结论与展望
综上所述,本文采用了R实现负二项回归模型项目实战,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。