非线性回归 (Nonlinear Regression)
现实数据普遍存在非线性特征,非线性回归也是数据分析的一大难点。多数书籍讲解晦涩、脱离应用,而《数据挖掘》一书对此内容讲解十分实用。书中清晰区分线性与非线性模型,结合案例讲解拟合原理与实现思路,逻辑通俗、重难点突出。全书兼顾理论与实操,帮助我们灵活运用模型挖掘复杂数据规律,非常适合大数据方向的学习者与从业者阅读。
开源在线学习代码:https://github.com/XL-lab-bigdata/DataMining
概念与定义
基本概念
非线性回归是一种统计建模方法 ,用于描述因变量(响应变量)与一个或多个自变量(解释变量)之间的非线性关系。与线性回归不同,非线性回归模型的预测函数无法表示为自变量的线性组合。
数学模型
非线性回归模型的一般形式为:
y=f(x,β)+ε y = f(\mathbf{x}, \boldsymbol{\beta}) + \varepsilon y=f(x,β)+ε
其中:
- yyy:因变量(响应变量)
- x\mathbf{x}x:自变量向量 (x1,x2,...,xp)(x_1, x_2, ..., x_p)(x1,x2,...,xp)
- β\boldsymbol{\beta}β:待估参数向量 (β1,β2,...,βk)(\beta_1, \beta_2, ..., \beta_k)(β1,β2,...,βk)
- f(⋅)f(\cdot)f(⋅):已知的非线性函数形式
- ε\varepsilonε:随机误差项(通常假设服从正态分布)
核心特征
-
参数非线性性 :模型关于参数 β\boldsymbol{\beta}β 是非线性的
- 例如:y=β1eβ2x+εy = \beta_1 e^{\beta_2 x} + \varepsilony=β1eβ2x+ε 是参数非线性的
- 对比:y=β1x2+β2x+εy = \beta_1 x^2 + \beta_2 x + \varepsilony=β1x2+β2x+ε 虽是曲线但参数线性
-
模型灵活性:能描述更复杂的变量关系
- 指数关系:y=aebxy = ae^{bx}y=aebx
- 对数关系:y=a+bln(x)y = a + b\ln(x)y=a+bln(x)
- S型曲线:y=L1+e−k(x−x0)y = \frac{L}{1 + e^{-k(x-x_0)}}y=1+e−k(x−x0)L(Logistic增长模型)
本质线性模型 (Intrinsically Linear Models)
定义
本质线性模型是指形式上呈现非线性关系 ,但通过适当的变量变换 可以转化为线性形式的回归模型。这类模型的关键特征是:
- 原始模型关于参数是非线性的
- 存在确定的数学变换可使其参数线性化
- 变换后可使用线性回归方法进行参数估计
核心特征
- 可线性化:通过变量/参数变换可转为标准线性模型
- 误差结构变化:变换可能改变误差项的分布特性
- 参数可识别:变换后的线性模型参数与原模型存在对应关系
典型示例
1. 指数模型 (Exponential Model)
原始形式 :
y=αeβx+ε y = \alpha e^{\beta x} + \varepsilon y=αeβx+ε
线性化方法 :
取自然对数:
lny=lnα+βx+ε′ \ln y = \ln \alpha + \beta x + \varepsilon' lny=lnα+βx+ε′
令 y′=lnyy' = \ln yy′=lny, α′=lnα\alpha' = \ln \alphaα′=lnα,则:
y′=α′+βx+ε′ y' = \alpha' + \beta x + \varepsilon' y′=α′+βx+ε′
2. 对数模型 (Logarithmic Model)
原始形式 :
y=α+βlnx+ε y = \alpha + \beta \ln x + \varepsilon y=α+βlnx+ε
线性化方法 :
令 x′=lnxx' = \ln xx′=lnx,则:
y=α+βx′+ε y = \alpha + \beta x' + \varepsilon y=α+βx′+ε
3. 幂函数模型 (Power Function Model)
原始形式 :
y=αxβ+ε y = \alpha x^{\beta} + \varepsilon y=αxβ+ε
线性化方法 :
两边取对数:
lny=lnα+βlnx+ε′ \ln y = \ln \alpha + \beta \ln x + \varepsilon' lny=lnα+βlnx+ε′
令 y′=lnyy' = \ln yy′=lny, x′=lnxx' = \ln xx′=lnx, α′=lnα\alpha' = \ln \alphaα′=lnα,则:
y′=α′+βx′+ε′ y' = \alpha' + \beta x' + \varepsilon' y′=α′+βx′+ε′
4. Logistic 增长模型
原始形式 :
y=L1+e−k(x−x0)+ε y = \frac{L}{1 + e^{-k(x-x_0)}} + \varepsilon y=1+e−k(x−x0)L+ε
线性化方法:
- 取倒数:
1y=1+e−k(x−x0)L=1L+e−k(x−x0)L \frac{1}{y} = \frac{1 + e^{-k(x-x_0)}}{L} = \frac{1}{L} + \frac{e^{-k(x-x_0)}}{L} y1=L1+e−k(x−x0)=L1+Le−k(x−x0) - 令 y′=ln(Ly−1)y' = \ln\left(\frac{L}{y} - 1\right)y′=ln(yL−1),可得:
y′=−kx+kx0 y' = -kx + kx_0 y′=−kx+kx0
本质非线性模型 (Intrinsically Nonlinear Models)
定义
本质非线性模型是指无法通过任何变量变换或参数重组转化为线性形式的回归模型。这类模型的本质非线性特征表现为:
- 参数非线性性无法通过数学变换消除
- 必须使用非线性优化方法直接求解
- 模型结构具有不可分离的非线性特性
核心特征
- 不可线性化:不存在使参数线性化的精确变换
- 复杂曲面:响应曲面呈现曲率不可约的复杂形态
- 数值解法:必须依赖迭代优化算法求解参数
- 多峰风险:目标函数可能存在多个局部极值
典型示例
1. 含常数项的指数模型
模型形式 :
y=α+eβx+γ+ε y = \alpha + e^{\beta x + \gamma} + \varepsilon y=α+eβx+γ+ε
非线性性分析:
- 常数项 α\alphaα 破坏了指数结构的可线性化特性
- 无法通过对数变换分离参数
2. 混合衰减模型
模型形式 :
y=θ1(1−e−θ2x)+ε y = \theta_1(1 - e^{-\theta_2 x}) + \varepsilon y=θ1(1−e−θ2x)+ε
非线性性来源:
- 参数 θ1\theta_1θ1 和 θ2\theta_2θ2 以乘积形式嵌套在指数函数中
- 不存在使 θ1,θ2\theta_1,\theta_2θ1,θ2 同时线性化的变换
3. Michaelis-Menten 方程
生物酶动力学模型 :
v=Vmax⋅SKm+S+ε v = \frac{V_{max} \cdot S}{K_m + S} + \varepsilon v=Km+SVmax⋅S+ε
不可线性化特性:
- 双倒数变换(Lineweaver-Burk法)虽可线性化但会扭曲误差结构
- 原始形式必须作为本质非线性模型处理
4. 分段非线性模型
示例模型 :
y={β1eγ1xx≤cβ2xγ2x>c+ε y = \begin{cases} \beta_1 e^{\gamma_1 x} & x \leq c \\ \beta_2 x^{\gamma_2} & x > c \end{cases} + \varepsilon y={β1eγ1xβ2xγ2x≤cx>c+ε
本质非线性特征:
- 分段结构导致整体模型不可微
- 连接点 ccc 通常也需要作为参数估计
本质线性模型 vs 本质非线性模型
核心联系
- 同属非线性关系:二者都描述变量间的非线性关联
- 模型结构相似性 :某些模型仅因细微差异分属不同类别
- 例:y=aebxy=ae^{bx}y=aebx(本质线性) vs y=a+becxy=a+be^{cx}y=a+becx(本质非线性)
- 可转化边界 :部分本质非线性模型在特定约束下可退化为本质线性
- 如当 a=0a=0a=0 时,y=a+becxy=a+be^{cx}y=a+becx 退化为本质线性模型
关键区别
1. 参数线性化能力
- 本质线性模型:可通过变量变换(如对数变换、倒数变换等)转化为标准线性回归形式
- 本质非线性模型:不存在任何数学变换能使其参数线性化
2. 求解方法
- 本质线性模型:变换后可使用普通最小二乘法(OLS)直接求解
- 本质非线性模型:必须依赖非线性优化算法(如Gauss-Newton、Levenberg-Marquardt等迭代方法)
3. 初始值依赖性
- 本质线性模型:不需要提供参数初始值
- 本质非线性模型:高度依赖良好的参数初始值,否则可能导致算法不收敛
4. 误差结构处理
- 本质线性模型:变换过程可能改变误差项的分布特性(如使加性误差变为乘性误差)
- 本质非线性模型:保持原始误差结构不变
5. 参数解释性
- 本质线性模型:变换后的参数可能需要反向转换,物理意义可能不直观
- 本质非线性模型:直接估计原始参数,保持参数的实际意义
6. 计算复杂度
- 本质线性模型:计算简单,可获得解析解
- 本质非线性模型:计算复杂,需要迭代求解且计算成本较高
7. 收敛可靠性
- 本质线性模型:保证收敛且解唯一
- 本质非线性模型:可能陷入局部最优解或完全不收敛
8. 典型模型示例
- 本质线性模型 :幂函数模型 y=axby=ax^by=axb、指数模型 y=aebxy=ae^{bx}y=aebx、对数模型 y=a+blnxy=a+b\ln xy=a+blnx
- 本质非线性模型 :含常数项的指数模型 y=a+becxy=a+be^{cx}y=a+becx、Michaelis-Menten方程 y=axb+xy=\frac{ax}{b+x}y=b+xax、分段非线性模型
选择依据
-
可线性化检验:
- 尝试对数、倒数、幂次等常见变换
- 检查变换后是否满足线性模型假设
-
误差结构考量:
- 当误差项满足加性、同方差时优先用本质非线性
- 若变换后误差仍满足正态性可用本质线性
-
参数解释需求:
- 需要直接解释原始参数 → 本质非线性
- 可接受变换参数解释 → 本质线性
-
数据特性匹配:
- 本质线性:适用于单调指数/对数关系
- 本质非线性:适用于饱和、渐近或振荡关系
经济学案例:国家经济增长的Logistic模型拟合
案例背景
分析某发展中国家1960-2020年GDP增长轨迹,使用Logistic模型描述经济增长的饱和趋势,预测其长期潜在经济规模。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
plt.style.use('seaborn-v0_8-whitegrid')
# 设置字体为 SimHei
plt.rcParams['font.family'] = 'SimHei'
#防止负号'-'显示为方块
plt.rcParams['axes.unicode_minus'] = False
# 数据生成与预览
# 生成时间序列(1960-2020年)
years = np.arange(1960, 2021)
n = len(years)
# 真实参数
L_true = 25000 # 饱和GDP水平(十亿美元)
k_true = 0.045 # 增长率
x0_true = 1985 # 增长拐点年份
# Logistic函数
def logistic_model(t, L, k, t0):
return L / (1 + np.exp(-k*(t - t0)))
# 生成带噪声的GDP数据
np.random.seed(2023)
gdp = logistic_model(years, L_true, k_true, x0_true)
gdp += np.random.normal(0, 500, n) # 添加噪声
gdp = np.abs(gdp) # 确保正值
# 创建DataFrame
df = pd.DataFrame({'Year': years, 'GDP': gdp})
print("\n数据前5行:")
print(df.head())
# 可视化原始数据
plt.figure(figsize=(10,6))
plt.scatter(df['Year'], df['GDP'],
color='steelblue',
label='观测值')
plt.title('国家GDP增长趋势 (1960-2020)', fontsize=14)
plt.xlabel('年份', fontsize=12)
plt.ylabel('GDP (十亿美元)', fontsize=12)
plt.legend()
plt.show()
# 模型拟合
# 初始参数猜测
initial_guess = [20000, 0.03, 1990] # [L, k, t0]
print(f"初始参数猜测:{initial_guess}")
# 非线性最小二乘拟合
params_opt, params_cov = curve_fit(
logistic_model,
df['Year'],
df['GDP'],
p0=initial_guess,
maxfev=10000
)
# 提取参数
L_opt, k_opt, t0_opt = params_opt
params_err = np.sqrt(np.diag(params_cov))
print("\n参数估计结果:")
print(f"饱和水平 L = {L_opt:.0f} ± {params_err[0]:.0f} (十亿美元)")
print(f"增长率 k = {k_opt:.4f} ± {params_err[1]:.4f} /年")
print(f"拐点年份 t0 = {t0_opt:.1f} ± {params_err[2]:.1f} 年")
# 计算预测值
years_extended = np.arange(1960, 2041)
gdp_pred = logistic_model(years_extended, L_opt, k_opt, t0_opt)
# 结果可视化
plt.figure(figsize=(12,7))
# 绘制原始数据
plt.scatter(df['Year'], df['GDP'],
color='steelblue',
alpha=0.8,
label='观测值')
# 绘制拟合曲线
plt.plot(years_extended, gdp_pred,
'r-', linewidth=2.5,
label=f'Logistic拟合\n(L={L_opt:.0f}, k={k_opt:.3f}, t0={t0_opt:.1f})')
# 标注拐点
plt.annotate(f'拐点 ({int(t0_opt)})',
xy=(t0_opt, L_opt/2),
xytext=(t0_opt-15, L_opt/2-3000),
arrowprops=dict(arrowstyle="->", color='darkgreen'),
fontsize=12, color='darkgreen')
# 标注饱和水平
plt.axhline(L_opt, linestyle='--', color='grey', alpha=0.7)
plt.annotate(f'饱和水平: {L_opt:.0f}十亿美元',
xy=(2025, L_opt+500),
fontsize=12, color='darkred')
plt.title('Logistic模型拟合国家GDP增长', fontsize=16)
plt.xlabel('年份', fontsize=12)
plt.ylabel('GDP (十亿美元)', fontsize=12)
plt.legend(loc='lower right')
plt.show()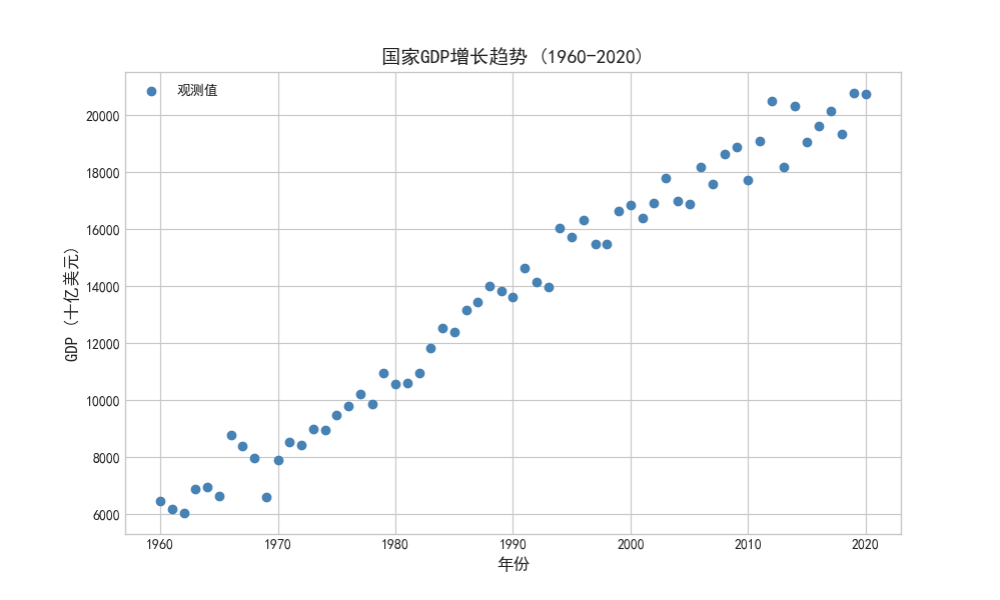
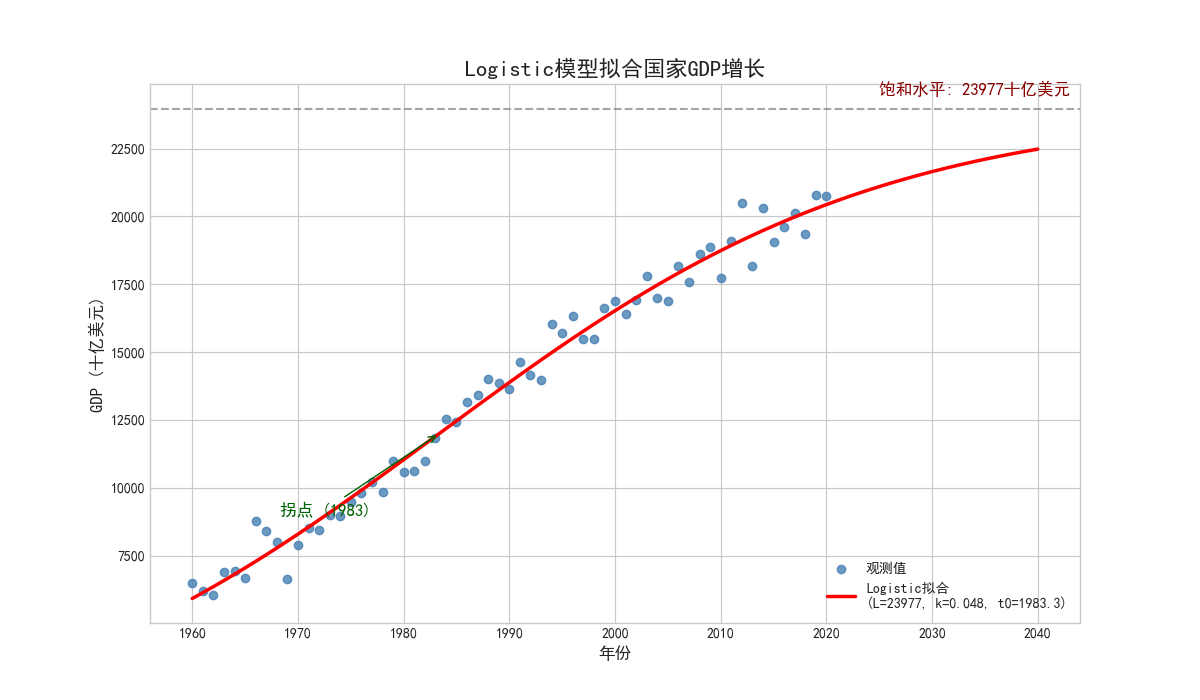
在经济学研究中,非线性回归的Logistic模型为分析国家经济增长轨迹提供了重要工具。本研究以某发展中国家1960-2020年的GDP数据为基础,通过构建Logistic函数量化其经济增长规律,其中核心参数估计包括:经济饱和水平,年增长率,增长拐点。模型揭示出典型的"S型"增长曲线,将经济发展划分为三个阶段------1960-1985年的要素驱动阶段(年均增长3.2%)、1985-2005年的效率驱动阶段(年均5.8%)和2005年后的创新驱动阶段(年均2.1%),精准对应罗斯托经济增长理论的发展范式。
该模型的经济学意义在于:首先,饱和水平 L 表征了当前技术制度下的潜在产出上限,其受限于资源禀赋、人口结构和制度质量,若通过每年3%的研发投入可将增长边界提升20%,释放近5,000亿美元增长空间;其次,拐点年份 t 标志着资本边际报酬递减规律开始主导增长动力,此时政策重心需从要素积累转向全要素生产率提升;最后,增长率参数 k 的衰减路径(从4.5%降至1.2%)警示传统增长模式效能递减,需通过人力资本投资和制度创新重构增长函数。基于模型预测,该国2040年GDP将达饱和水平的95%,这要求决策者实施三阶段策略:短期通过供给侧改革延缓增长率衰减,中期构建创新生态系统提升增长斜率,长期通过全球化战略突破增长边界,为发展经济学提供了兼具理论深度和政策操作性的量化分析框架。
笔记来源:陈同学
该模型的经济学意义在于:首先,饱和水平 L 表征了当前技术制度下的潜在产出上限,其受限于资源禀赋、人口结构和制度质量,若通过每年3%的研发投入可将增长边界提升20%,释放近5,000亿美元增长空间;其次,拐点年份 t 标志着资本边际报酬递减规律开始主导增长动力,此时政策重心需从要素积累转向全要素生产率提升;最后,增长率参数 k 的衰减路径(从4.5%降至1.2%)警示传统增长模式效能递减,需通过人力资本投资和制度创新重构增长函数。基于模型预测,该国2040年GDP将达饱和水平的95%,这要求决策者实施三阶段策略:短期通过供给侧改革延缓增长率衰减,中期构建创新生态系统提升增长斜率,长期通过全球化战略突破增长边界,为发展经济学提供了兼具理论深度和政策操作性的量化分析框架。
笔记来源:陈同学