1、什么是 SpringAI?
Spring AI 是 Spring 官方推出的 AI 应用开发框架 ,旨在帮助 Java 开发者以统一、便捷的方式将 AI 能力集成到企业级应用中。你可以把它理解为 Java 生态中的 "AI 万能转接头"。🎯 核心定位:简化 Java 开发者的 AI 集成。它的核心目标是解决 AI 模型 API 碎片化的问题。通过提供一套标准化的抽象接口,让开发者可以用一套代码调用 OpenAI、阿里云通义千问、DeepSeek 等几乎所有主流模型,更换底层服务只需修改配置,无需改动业务代码。
1.1 🧱SpringAI 核心架构:分层设计,职责清晰
Spring AI 的架构设计遵循了 Spring 生态一贯的"约定优于配置"理念,核心组件包括:
| 组件 | 作用 | 大白话解释 |
|---|---|---|
| ChatModel | 底层抽象接口,定义了与 AI 模型对话的基本契约。 | 功能手机,能打电话,但功能单一。 |
| ChatClient | 构建在 ChatModel 之上的高级 API,提供流式、链式调用等便捷方法。 |
智能手机,不仅打电话,还内置了通讯录、应用商店等丰富功能。 |
| Advisor | 拦截器机制,可在调用 AI 前后执行日志、安全检查、提示词优化等操作。 | 安检通道,在进入 AI 核心前对请求和响应进行预处理。 |
| VectorStore | 向量数据库抽象层,为检索增强生成(RAG)提供支持,让 AI 能"查阅"你的私有资料。 | AI 的外部硬盘,存储私有知识,方便随时调用。 |
1.2 ⚙️SpringAI 关键技术:构建强大 AI 应用的"三板斧"
基于上述架构,Spring AI 支持实现以下关键功能:
-
模型对话 :通过
ChatClient轻松实现聊天机器人、智能问答等基础应用。 -
函数调用 :利用
@Tool注解让 AI 调用外部 API(如查询天气、操作数据库),拓展其能力边界。 -
检索增强生成 :结合
VectorStore和Advisor,让 AI 能基于你的私有数据回答问题,有效减少"幻觉"并提供可追溯来源。
2、什么是 SAA?
SAA 是 SpringAI Alibaba 的缩写。随着生成式 AI 的快速发展,基于 AI 开发框架构建 AI 应用的诉求迅速增长,涌现出了包括 LangChain、LlamaIndex 等开发框架,它们为 Python 开发者提供了方便的 API 抽象。但这些开发框架对于国内习惯了 Spring 开发范式的 Java 开发者而言,并非十分友好和丝滑。因此,阿里在基于 Spring AI 发布并快速演进 Spring AI Alibaba,通过提供一种方便的 API 抽象,帮助 Java 开发者简化 AI 应用的开发,一步迈入 AI 原生时代。
2.1 SpringAI 与 SpringAI Alibaba 的对比
Spring AI 是 标准规范和基础接口,由 Spring 官方维护。
Spring AI Alibaba 是 阿里云对 Spring AI 标准的完整实现和增强 。它不仅提供了对阿里云通义系列模型的接入,还额外增加了 Agent 框架、工作流编排、可视化调试(Studio/Admin)等企业级功能。
选择上可以这样理解:如果你希望代码不绑定特定云厂商,就用标准的 Spring AI;如果你深度使用阿里云服务并需要更强大的智能体开发能力,Spring AI Alibaba 是更好的选择。
Spring AI 定位 AI 应用开发底层框架,提供了 AI 开发需要的底层原子抽象,包括模型适配、工具定义、向量数据库存取等;Spring AI Alibaba 定位 AI 智能体开发框架,提供了基于图算法的智能体编程 Graph 框架,让开发者更容易开发工作流、multi-agent 应用。为方便理解,举个不完全正确的类比例子,如果说 Spring AI 是 LangChain 生态中的 Langchain 框架的话,则 Spring AI Alibaba 则是 Langchain 生态中的 Langraph 框架。
除了框架本身外,Spring AI Alibaba 是阿里云基于 Spring AI 框架的企业级智能体开发最佳实践与整体解决方案输出,与阿里开源生态、阿里云平台服务等深度集成,包含:
- 与百炼 Dashscope 模型服务集成,支持 Qwen(千问)、Deepseek 等主流模型系列
- 与百炼智能体应用平台 AgentScope 集成,提供低代码、高代码双向转换,提升研发效率
- 与百炼析言 ChatBI 集成,提供自然语言到 SQL 的自动生成开源框架与服务
- 与阿里云云产品集成,包括向量检索库AnalyticDB、向量检索库OpenSearch、信息检索服务 IQS 等
- 与开源 Nacos、Higress 生态集成,提供 MCP 注册中心、MCP 智能路由、Prompt管理、模型代理等能力
- 提供前沿方向的智能体产品实现与整体解决方案,包括 JManus、DeepResearch、NL2SQL 等。
- 提供 AI 应用开发的完整配套生态,包括本地开发工具、项目构建平台等。
2.2 SpringAI Alibaba 的优势
SAA(Spring AI Alibaba) 开源项目基于 Spring AI 构建,是阿里云通义系列模型及服务在 Java AI 应用开发领域的最佳实践,提供高层次的 AI API 抽象与云原生基础设施集成方案,帮助开发者快速构建 AI 应用。
Spring AI Alibaba 作为开发 AI 应用程序的基础框架,定义了以下抽象概念与 API,并提供了 API 与通义系列模型的适配。
- 开发复杂 AI 应用的高阶抽象 Fluent API --- ChatClient
- 提供多种大模型服务对接能力,包括主流开源与阿里云通义大模型服务(百炼)等
- 支持的模型类型包括聊天、文生图、音频转录、文生语音等
- 支持同步和流式 API,在保持应用层 API 不变的情况下支持灵活切换底层模型服务,支持特定模型的定制化能力(参数传递)
- 支持 Structured Output,即将 AI 模型输出映射到 POJOs
- 支持矢量数据库存储与检索
- 支持函数调用 Function Calling
- 支持构建 AI Agent 所需要的工具调用和对话内存记忆能力
- 支持 RAG 开发模式,包括离线文档处理如 DocumentReader、Splitter、Embedding、VectorStore 等,支持 Retrieve 检索。
2.3 当前主流 Java AI 框架对比
| 对比维度 | Spring AI Alibaba | Spring AI | LangChain4J |
|---|---|---|---|
| Spring Boot 集成 | 原生支持 | 原生支持 | 社区适配 |
| 文本模型 | 主流模型,可扩展 | 主流模型,可扩展 | 主流模型,可扩展 |
| 音视频、多模态、向量模型 | 支持 | 支持 | 支持 |
| RAG | 模块化 RAG | 模块化 RAG | 模块化 RAG |
| 向量数据库 | 主流向量数据库 阿里云ADB、OpenSearch等 | 主流向量数据库 | 主流向量数据库 |
| MCP 支持 | 支持 Nacos MCP Registry 支持 | 支持 | 支持 |
| 函数调用 | 支持(20+官方工具集成) | 支持 | 支持 |
| 提示词模版 | 硬编码,无声明式注解 | 硬编码,无声明式注解 | 声明式注解 |
| 提示词管理 | Nacos 配置中心 | 无 | 无 |
| Chat Memory | 优化版JDBC、Redis、ElasticSearch | JDBC、Neo4j、Cassandra | 多种实现适配 |
| 可观测性 | 支持,可接入阿里云ARMS | 支持 | 部分支持 |
| 工作流 Workflow | 支持,兼容 Dify、百炼 DSL | 无 | 无 |
| 多智能体 Multi-agent | 支持,官方通用智能体实现 | 无 | 无 |
| 模型评测 | 支持 | 支持 | 支持 |
| 社区活跃度与文档健全性 | 官方社区,活跃度高 | 官方社区,活跃度高 | 个人发起社区 |
| 开发提效组件 | 丰富,包括调试、代码生成工具等 | 无 | 无 |
| Example 仓库 | 丰富,活跃度高 | 较少 | 丰富,活跃度高 |
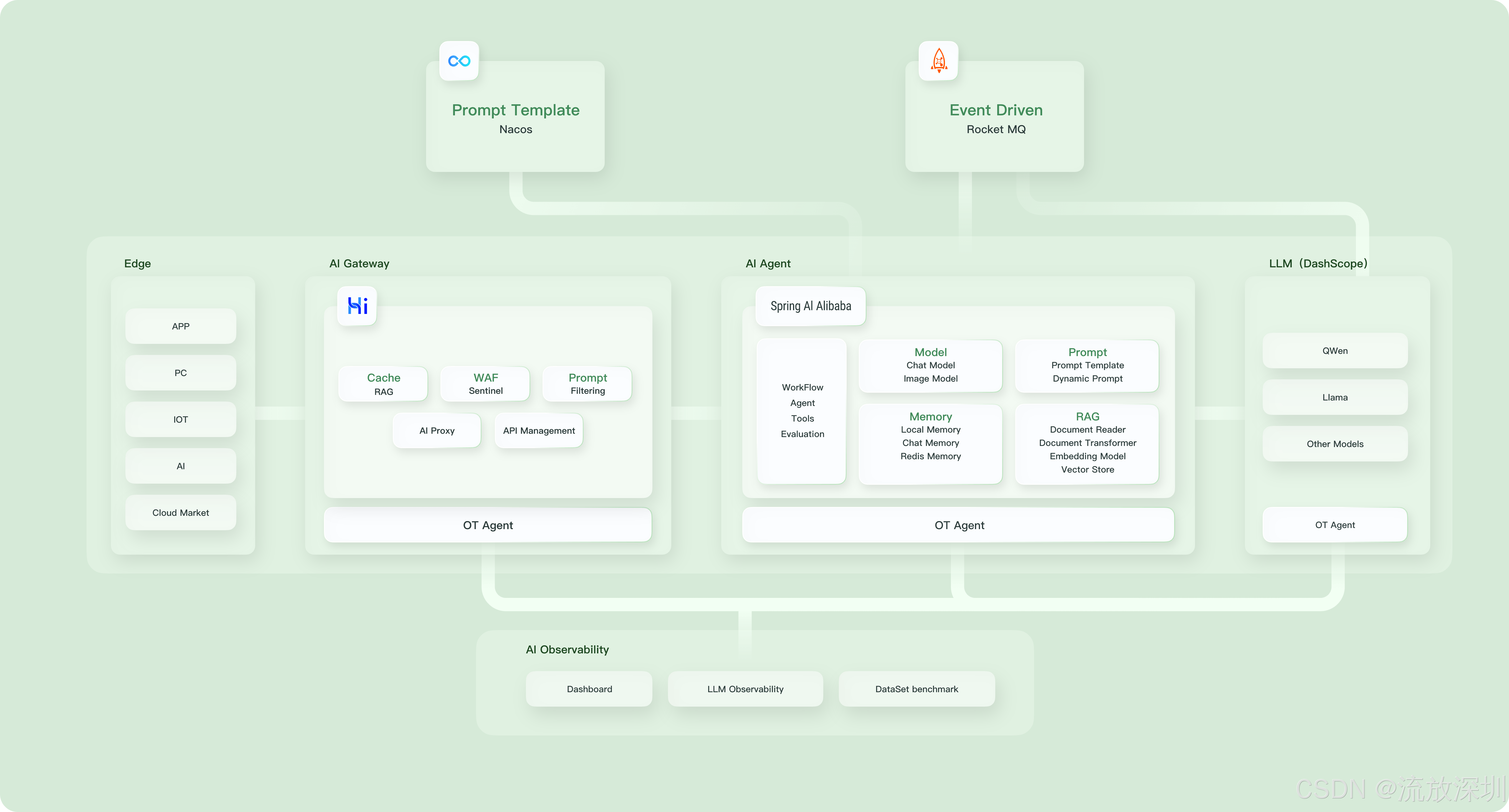
官网:https://sca.aliyun.com/en/docs/ai/overview/
2.4 技术选型对比
| 维度 | Spring AI + Ollama | Spring AI Alibaba + DashScope |
|---|---|---|
| 网络要求 | 可离线运行 | 必须联网 |
| 数据隐私 | 完全本地,不出网 | 数据上传阿里云 |
| 费用 | 免费(需自备硬件) | 按 API 调用量计费 |
| 模型选择 | 任意开源模型(Qwen/Llama/DeepSeek) | 通义系列模型 |
| 响应速度 | 依赖本地 GPU/CPU | 依赖网络延迟 |
| 并发能力 | 受本地硬件限制 | 云服务弹性伸缩 |
| 适用场景 | 开发测试、隐私敏感、边缘计算 | 企业生产、高并发要求 |
出于本篇博客仅用于学习来考虑,只考虑使用 Spring AI + Ollama 来学习,不使用 Spring AI Alibaba + DashScope。
3、智能体相关核心概念
简单介绍 Spring AI 框架使用的核心概念。我们建议仔细阅读,以了解框架实现背后的思想。
对话模型(Chat Model)、嵌入模型(Embedding Model)、工具(Function Calling)、对话记忆、提示词(Prompt)、Token、文档检索(Document Retriever)、格式化输出(Structured Output)、向量存储(Vector Store)
3.0、Chat Client
ChatClient提供了与 AI 模型通信的 Fluent API(流式API),它支持同步和反应式(Reactive)编程模型。与ChatModel、Message、ChatMemory等原子 API 相比,使用ChatClient可以将与 LLM 及其他组件交互的复杂性隐藏在背后,因为基于 LLM 的应用程序通常要多个组件协同工作(例如,提示词模板、聊天记忆、LLM Model、输出解析器、RAG 组件:嵌入模型和存储),并且通常涉及多个交互,因此协调它们会让编码变得繁琐。当然使用ChatModel等原子 API 可以为应用程序带来更多的灵活性,成本就是您需要编写大量样板代码。ChatClient 类似于应用程序开发中的服务层,它为应用程序直接提供
AI 服务,开发者可以使用 ChatClient Fluent API 快速完成一整套 AI 交互流程的组装。包括一些基础功能,如:
- 定制和组装模型的输入(Prompt)
- 格式化解析模型的输出(Structured Output)
- 调整模型交互参数(ChatOptions)
还支持更多高级功能:
- 聊天记忆(Chat Memory)
- 工具/函数调用(Function Calling)
- RAG
3.1、对话模型(Chat Model)
对话模型(Chat Model)接收一系列消息(Message)作为输入,与模型 LLM 服务进行交互,并接收返回的聊天消息(Chat Message)作为输出。相比于普通的程序输入,模型的输入与输出消息(Message)不止支持纯字符文本,还支持包括语音、图片、视频等作为输入输出。同时,在 Spring AI Alibaba 中,消息中还支持包含不同的角色,帮助底层模型区分来自模型、用户和系统指令等的不同消息。
Spring AI Alibaba 复用了 Spring AI 抽象的 Model API,并与通义系列大模型服务进行适配(如通义千问、通义万相等),目前支持纯文本聊天、文生图、文生语音、语音转文本等。以下是框架定义的几个核心 API:
- ChatModel,文本聊天交互模型,支持纯文本格式作为输入,并将模型的输出以格式化文本形式返回。
- ImageModel,接收用户文本输入,并将模型生成的图片作为输出返回。
- AudioModel,接收用户文本输入,并将模型合成的语音作为输出返回。
Spring AI Alibaba 支持以上 Model 抽象与通义系列模型的适配,并通过
spring-ai-alibaba-starterAutoConfiguration 自动初始化了默认实例,因此我们可以在应用程序中直接注入 ChatModel、ImageModel 等 bean,当然在需要的时候也可以自定义 Model 实例。
3.2、嵌入模型(Embedding Model)
嵌入(
Embedding)的工作原理是将文本、图像和视频转换为称为向量(Vectors)的浮点数数组。这些向量旨在捕捉文本、图像和视频的含义。嵌入数组的长度称为向量的维度(Dimensionality)。嵌入模型(
EmbeddingModel)是嵌入过程中采用的模型。当前EmbeddingModel的接口主要用于将文本转换为数值向量,接口的设计主要围绕这两个目标展开:
- 可移植性:该接口确保在各种嵌入模型之间的轻松适配。它允许开发者在不同的嵌入技术或模型之间切换,所需的代码更改最小化。这一设计与 Spring 模块化和互换性的理念一致。
- 简单性:嵌入模型简化了文本转换为嵌入的过程。通过提供如
embed(String text)和embed(Document document)这样简单的方法,它去除了处理原始文本数据和嵌入算法的复杂性。这个设计选择使开发者,尤其是那些初次接触 AI 的开发者,更容易在他们的应用程序中使用嵌入,而无需深入了解其底层机制。
3.3、工具(Function Calling)
"工具(Tool)"或"功能调用(Function Calling)"允许大型语言模型(LLM)在必要时调用一个或多个可用的工具,这些工具通常由开发者定义。工具可以是任何东西:网页搜索、对外部 API 的调用,或特定代码的执行等。LLM 本身不能实际调用工具;相反,它们会在响应中表达调用特定工具的意图(而不是以纯文本回应)。然后,我们应用程序应该执行这个工具,并报告工具执行的结果给模型。
3.4、对话记忆
"大模型的对话记忆"这一概念,根植于人工智能与自然语言处理领域,特别是针对具有深度学习能力的大型语言模型而言,它指的是模型在与用户进行交互式对话过程中,能够追踪、理解并利用先前对话上下文的能力。 此机制使得大模型不仅能够响应即时的输入请求,还能基于之前的交流内容能够在对话中记住先前的对话内容,并根据这些信息进行后续的响应。这种记忆机制使得模型能够在对话中持续跟踪和理解用户的意图和上下文,从而实现更自然和连贯的对话。
3.5、提示词(Prompt)
Prompt 是引导 AI 模型生成特定输出的输入格式,Prompt 的设计和措辞会显著影响模型的响应。
Prompt 最开始只是简单的字符串,随着时间的推移,prompt 逐渐开始包含特定的占位符,例如 AI 模型可以识别的 "USER:"、"SYSTEM:" 等。阿里云通义模型可通过将多个消息字符串分类为不同的角色,然后再由 AI 模型处理,为 prompt 引入了更多结构。每条消息都分配有特定的角色,这些角色对消息进行分类,明确 AI 模型提示的每个部分的上下文和目的。这种结构化方法增强了与 AI 沟通的细微差别和有效性,因为 prompt 的每个部分在交互中都扮演着独特且明确的角色。
Prompt 中的主要角色(Role)包括:
- 系统角色(System Role):指导 AI 的行为和响应方式,设置 AI 如何解释和回复输入的参数或规则。这类似于在发起对话之前向 AI 提供说明。
- 用户角色(User Role):代表用户的输入 - 他们向 AI 提出的问题、命令或陈述。这个角色至关重要,因为它构成了 AI 响应的基础。
- 助手角色(Assistant Role):AI 对用户输入的响应。这不仅仅是一个答案或反应,它对于保持对话的流畅性至关重要。通过跟踪 AI 之前的响应(其"助手角色"消息),系统可确保连贯且上下文相关的交互。助手消息也可能包含功能工具调用请求信息。它就像 AI 中的一个特殊功能,在需要执行特定功能(例如计算、获取数据或不仅仅是说话)时使用。
- 工具/功能角色(Tool/Function Role):工具/功能角色专注于响应工具调用助手消息返回附加信息。
3.6、Token
token是 AI 模型工作原理的基石。输入时,模型将单词转换为token。输出时,它们将token转换回单词。
在英语中,一个token大约对应一个单词的 75%。作为参考,莎士比亚的全集总共约 90 万个单词,翻译过来大约有 120 万个token。
也许更重要的是 "token = 金钱"。在托管 AI 模型的背景下,您的费用由使用的token数量决定。输入和输出都会影响总token数量。
此外,模型还受到 token 限制,这会限制单个 API 调用中处理的文本量。此阈值通常称为"上下文窗口"。模型不会处理超出此限制的任何文本。
3.7、文档检索(Document Retriever)
文档检索(
DocumentRetriever)是一种信息检索技术,旨在从大量未结构化或半结构化文档中快速找到与特定查询相关的文档或信息。文档检索通常以在线(online)方式运行。
DocumentRetriever通常基于向量搜索。它将用户的查询问题(query)转化为Embeddings后,在存储文档中进行相似性搜索,返回相关的片段。片段的用途之一是作为提示词(prompt)的一部分,发送给大模型(LLM)汇总处理后,作为答案呈现给用户。
DocumentRetriever API提供了简单、灵活的方式,供开发者使用自定义的检索系统。
3.8、格式化输出(Structured Output)
如果您想从 LLM 接收结构化输出,Structured Output 可以协助将
ChatModel/ChatClient方法的返回类型从 String 更改为其他类型。LLM 生成结构化输出的能力对于依赖可靠解析输出值的下游应用程序非常重要。开发人员希望快速将 AI 模型的结果转换为可以传递给其他应用程序函数和方法的数据类型,例如 JSON、XML 或 Java 类。Spring AI 结构化输出转换器有助于将 LLM 输出转换为结构化格式。
3.9、向量存储(Vector Store)
向量存储(
VectorStore)是一种用于存储和检索高维向量数据的数据库或存储解决方案,它特别适用于处理那些经过嵌入模型转化后的数据。在 VectorStore 中,查询与传统关系数据库不同。它们执行相似性搜索,而不是精确匹配。当给定一个向量作为查询时,VectorStore 返回与查询向量"相似"的向量。VectorStore 用于将您的数据与 AI 模型集成。在使用它们时的第一步是将您的数据加载到矢量数据库中。然后,当要将用户查询发送到 AI 模型时,首先检索一组相似文档。然后,这些文档作为用户问题的上下文,并与用户的查询一起发送到 AI 模型。这种技术被称为检索增强生成(
Retrieval Augmented Generation,RAG)。
3.10、检索增强生成 (RAG)
检索增强生成 (RAG) 是一种使用来自私有或专有数据源的信息来辅助文本生成的技术。它将检索模型(设计用于搜索大型数据集或知识库)和生成模型(例如大型语言模型 (LLM),此类模型会使用检索到的信息生成可供阅读的文本回复)结合在一起。
通过从更多数据源添加背景信息,以及通过训练来补充 LLM 的原始知识库,检索增强生成能够提高搜索体验的相关性。这能够改善大型语言模型的输出,但又无需重新训练模型。额外信息源的范围很广,从训练 LLM 时并未用到的互联网上的新信息,到专有商业背景信息,或者属于企业的机密内部文档,都会包含在内。
RAG 对于诸如回答问题和内容生成等任务,具有极大价值,因为它能支持生成式 AI 系统使用外部信息源生成更准确且更符合语境的回答。它会实施搜索检索方法(通常是语义搜索或混合搜索)来回应用户的意图并提供更相关的结果。
4、环境搭建
4.1 Ollama 本地大模型部署
Ollama 是一个让你能在自己电脑上免费、离线运行大语言模型的工具。你可以把它想象成一个"大模型的App Store和运行器"------通过简单的命令,就能一键下载并运行像 Llama、通义千问这类开源模型。
4.1.1 Ollama与远程API调用的区别:
| 对比维度 | 🏠 Ollama (本地运行) | ☁️ 远程API (如OpenAI) |
|---|---|---|
| 网络要求 | 完全离线,无需联网 | 必须联网 |
| 数据隐私 | 数据100%留在本地,无泄露风险 | 数据需上传至第三方服务器 |
| 使用成本 | 完全免费 | 通常按使用量付费 |
| 硬件门槛 | 较低,普通电脑即可运行小模型(如7B参数模型约需8GB内存) | 无硬件要求,但依赖网络 |
| 响应速度 | 本地响应,延迟低 | 取决于网络状况,可能有延迟 |
简单来说,如果你担心数据隐私 ,或者想在没有网络的环境 下使用AI,或者只是想免费、无限制地学习和实验,Ollama 是一个绝佳的选择。
4.1.2 下载并自定义安装Ollama
下载:官网地址:https://ollama.com/ 根据电脑操作系统进行下载。
安装:注意,由于 Ollama 是管理大模型的工具,会默认安装到 C 盘系统盘,大模型是很占用内存空间的,因此我们不要默认安装,要选择性安装到其它盘作为 Ollama 的工作目录。
在下载好 Ollama 的地址栏目录,直接输入 cmd 回车,
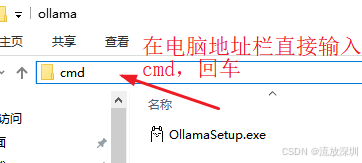
系统会调用 cmd 命令窗口,并默认进入到当前目录,然后将 Ollama 自定义安装到指定目录,如图:
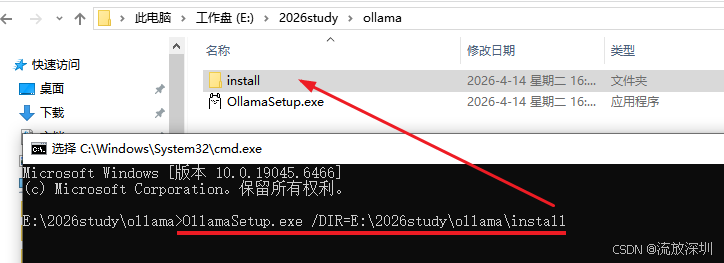
根据你自定义的安装目录,输入命令行,回车:
OllamaSetup.exe /DIR=E:\2026study\ollama\install在弹出的对话框选择安装即可。如图:
安装好之后,可以看到 ollama app.exe 可执行文件,这就是 Ollama 的程序运行入口:
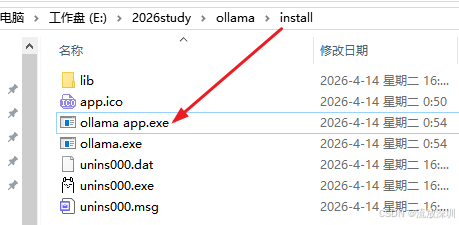
4.1.3 指定大模型存储目录
Ollama 是管理大模型的工具,我们后续学习或者工作会用到很多大模型,Ollama 会默认下载到C盘,因此我们需要指定 Ollama 下载大模型到其它盘。
4.1.3.1 方式1:通过界面指定大模型存储目录(此方式简单明了)
运行 Ollama 程序,点击左边菜单 Settings,设置大模型下载目录到指定磁盘:

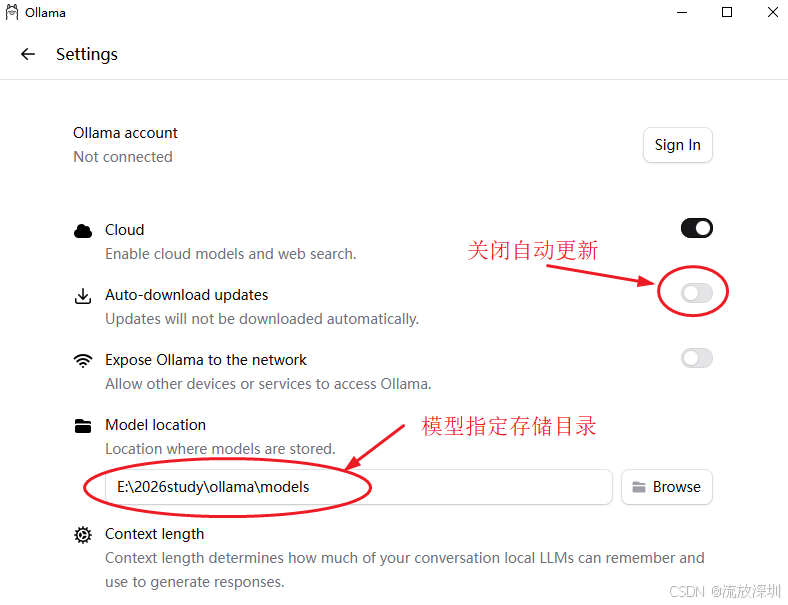
4.1.3.2 方式2:通过系统环境变量指定大模型存储目录
在系统变量里,新建一个键值对
变量名:OLLAMA_MODELS
变量值:对应你要存放大模型的目录
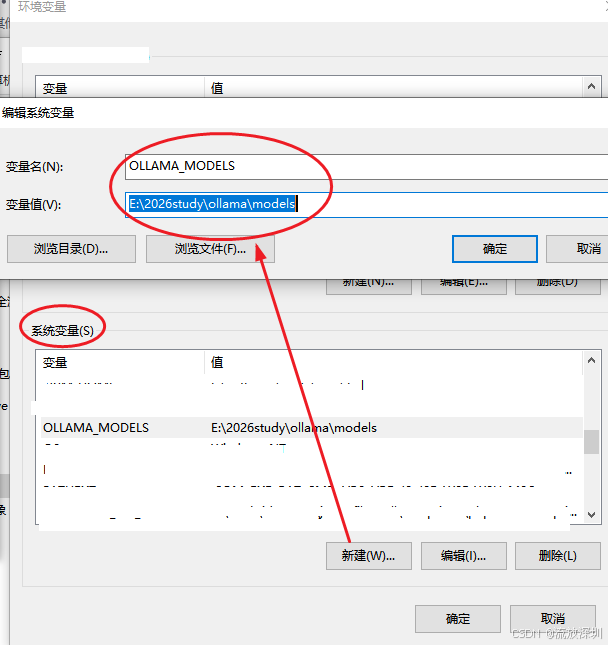
4.1.4 下载大模型到本地
Ollama 的命令行与 docker 的差不多,可以通过在 cmd 命令行输入 ollama help 来调出相关命令提示,如图:
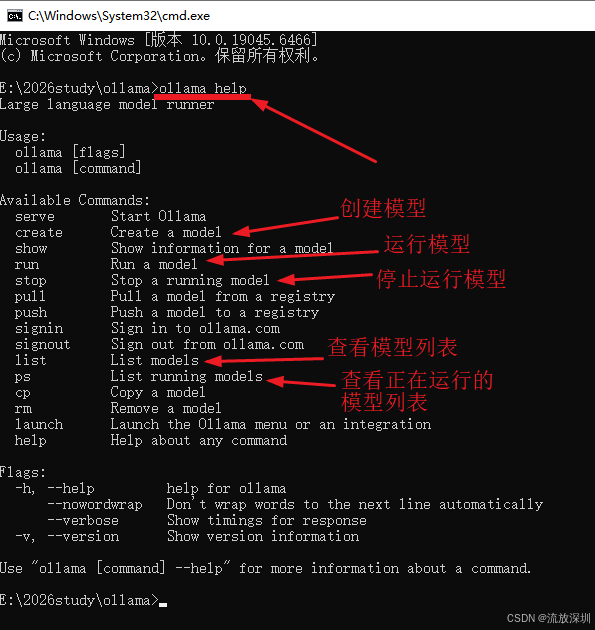
4.1.4.1 ollama 常用命令
ollama 常用命令:
1、ollama run 模型名:运行一个模型(没有则从远程下载)
2、ollama stop 模型名:停止运行一个模型
3、ollama list : 查看已下载到本地的模型列表
4、ollama ps : 查看正在运行的模型列表
5、ollama rm 模型名:删除本地的一个模型
6、ollama help : 查看命令行帮助。
我们可以通过 Ollama 官网,查看已支持下载的大模型列表:https://ollama.com/search
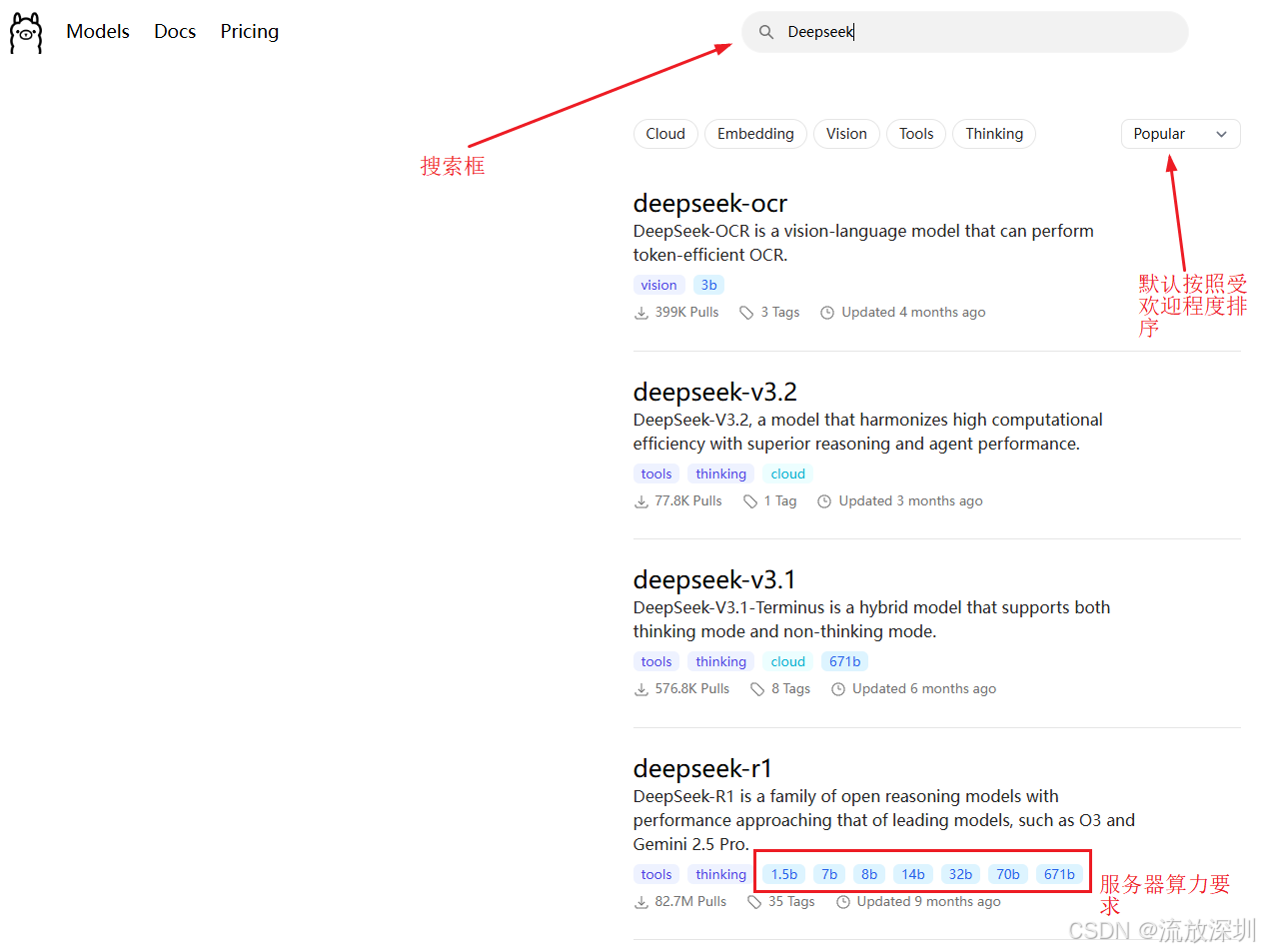
B 是 Billion(十亿) 的缩写。
1B 即代表模型有 10亿 个参数。
671B 代表模型有 6710亿 个参数。
⚙️ 参数量对使用的影响
参数量是衡量模型规模、能力和硬件需求的核心指标,主要影响以下三个方面:
能力与智能 :通常,参数量越大,模型的知识储备、逻辑推理和解决复杂问题的能力就越强。例如,671B 的 DeepSeek-R1 是能力最强的版本。
运行速度 :参数量越大,模型文件越大,运行时对显存(VRAM)和内存的要求就越高,生成回答的速度也可能相对较慢。
硬件门槛:这是你关心的核心。不同参数量的模型,对运行它的硬件要求天差地别。
这里有一个大致的参考:
| 模型参数量 | 大致所需显存 | 运行门槛 | 适用场景 |
|---|---|---|---|
| 1B - 3B | 2GB - 4GB | 很低 | 普通笔记本电脑(甚至部分配置较好的手机)即可流畅运行。 |
| 7B - 8B | 6GB - 8GB | 中等 | 需要一张中端消费级显卡(如 RTX 3060/4060 8GB),或较好的CPU+大内存(16GB+)。一般旧电脑跑起来会卡。 |
| 14B - 32B | 12GB - 20GB | 较高 | 需要高端消费级显卡(如 RTX 3090/4090 24GB),或通过CPU运行但速度会很慢。 |
| 70B - 72B | 40GB+ | 很高 | 通常需要多张显卡组合(如2张 RTX 3090),或使用大内存服务器(64GB+)通过CPU极其缓慢地运行。 |
| 671B (MoE) | 数百GB | 极高 | 个人电脑无法运行。只能在大型服务器集群或通过云端API调用。 |
总结
1B:表示这是一个 "迷你"模型,对电脑性能要求极低,几乎任何电脑都能跑,但能力有限,适合简单任务或低功耗设备。
7B/8B:目前个人本地部署的"黄金标准",在性能和硬件要求上取得了较好的平衡,一张8GB显存的显卡就能获得不错的体验。
671B:DeepSeek 的旗舰超大模型,能力最强,但个人电脑无法本地运行,通常需要通过官方或第三方API使用。
模型选择和下载,"千问"是阿里生态,活跃度比较高,更新迭代比较快,qwen3.5支持图文输入,因此比较推荐。SpringAI Alibaba 也兼容市面上绝大多数的模型开发:
1、qwen2.5:3b 或者 qwen2.5:1.5b
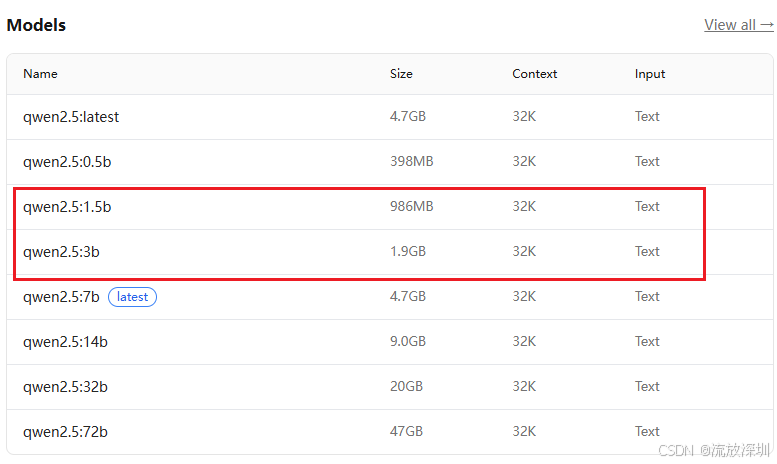
在cmd命令行输入以下的下载命令即可下载大模型到本地:
ollama run qwen2.5:3b
如果不指定算力版本,默认下载最新版。官网地址:https://ollama.com/library/qwen2.5
2、qwen3:4b 或者 qwen3:1.7b
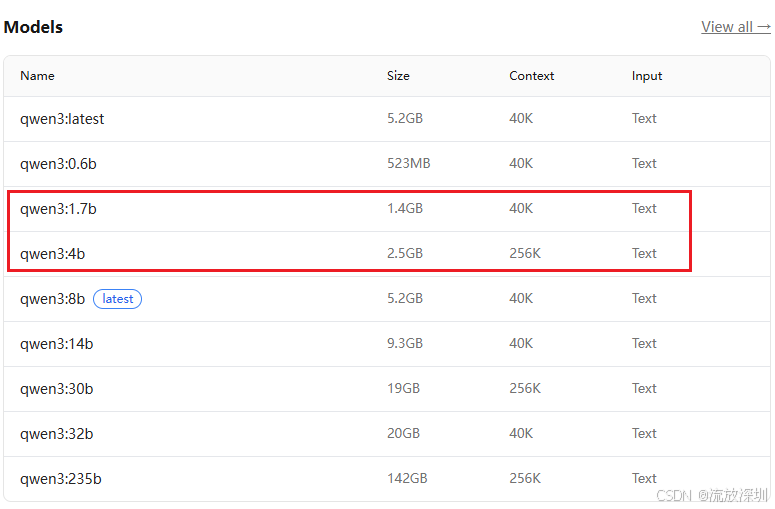
在cmd命令行输入以下的下载命令即可下载大模型到本地:
ollama run qwen3:4b
如果不指定算力版本,默认下载最新版。官网地址:https://ollama.com/library/qwen3
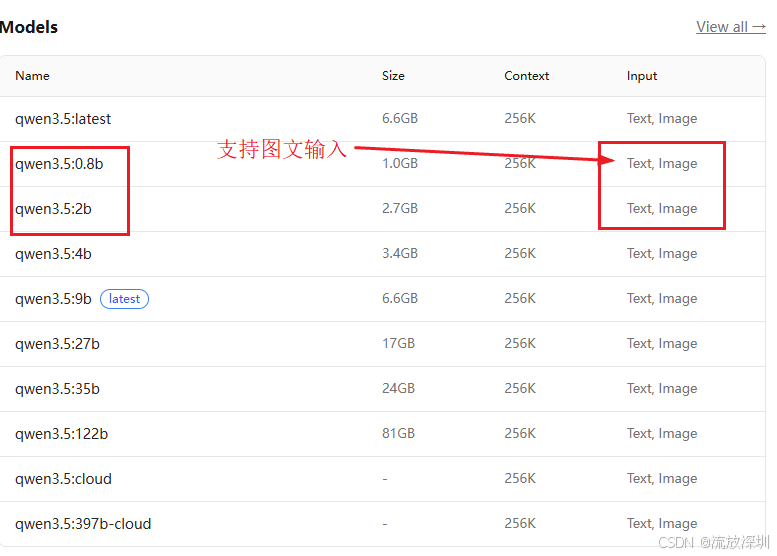
3、qwen3.5:0.8b 或者 qwen3.5:2b(支持输入文字和图片)
在cmd命令行输入以下的下载命令即可下载大模型到本地:
ollama run qwen3.5:0.8b
如果不指定算力版本,默认下载最新版。官网地址:https://ollama.com/library/qwen3.5
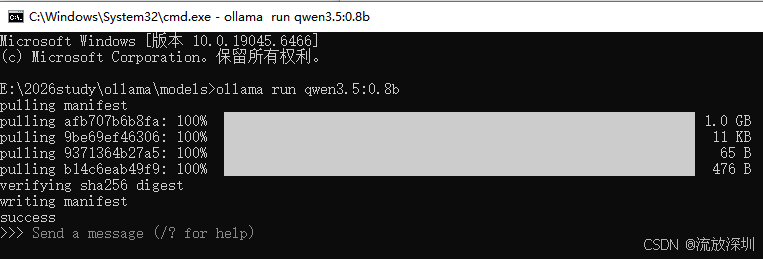
4.1.5 查看大模型在本地的安装目录
blobs 目录主要存放大模型源文件,manifests 目录主要存放大模型的列表。
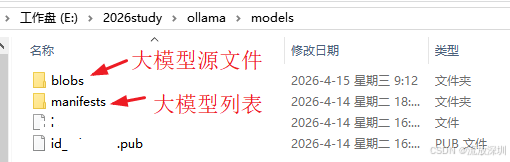
4.1.6 使用 ollama 客户端发起会话
通过 ollama 客户端选择某个大模型,实际上就是模拟了在 cmd 命令行输入了启动模型的命令。如图:
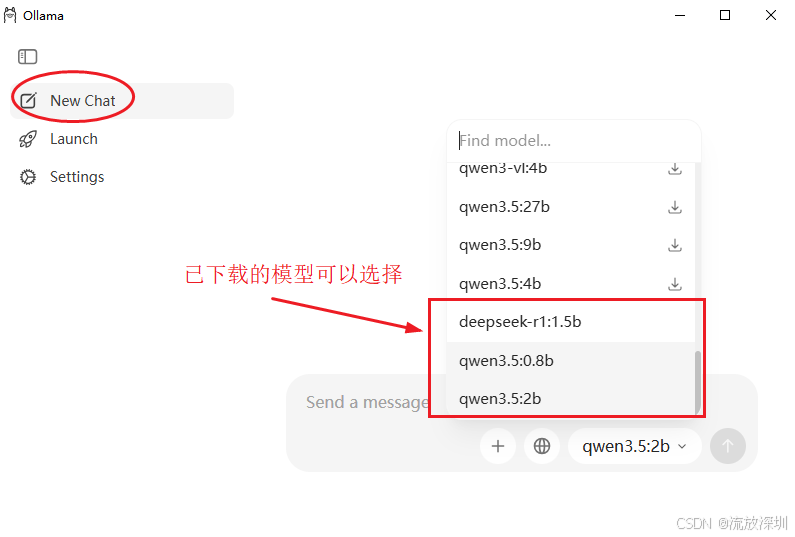
通过 ollama ps 命令行可以看到已启动的大模型:

测试使用 qwen3.5:2b 模型,在模型推断过程中,CPU直接飙升。因为模型思考和推断是需要算力的,也就是主要是使用 GPU,但是本地电脑CPU较差,所以还是使用CPU来处理。
离线大模型有个问题,就是知识库的内容不是时时更新的,比如无法查询某个城市的时时天气:
4.1.7 测试本机电脑大模型 token 的速度
测试 Qwen 模型的 Token 生成速度,最直接的方法就是在 Ollama 中通过命令行加 --verbose 参数来测试,命令参考如下:
java
# 测试 Qwen2.5 模型
ollama run qwen2.5:3b --verbose "介绍一下人工智能"
# 测试 Qwen3 模型
ollama run qwen3:4b --verbose "介绍一下人工智能"
# 测试 Qwen3.5 模型
ollama run qwen3.5:2b --verbose "介绍一下人工智能"测试结果各项参数说明:
total duration: 3.2s # 总耗时(含模型加载) load duration: 18ms # 模型加载到显存的时间 prompt eval count: 32 token(s) prompt eval duration: 0.1s prompt eval rate: 320 tokens/s eval count: 87 token(s) # 生成的 token 数量 eval duration: 2.1s # 生成这些 token 花费的时间 eval rate: 41.4 tokens/s # ⭐ 生成速度(每秒生成的 token 数)核心关注
eval rate:
如果低于 20 tokens/s:可能有性能问题,需要优化
如果达到 30-50 tokens/s:正常水平
如果达到 60+ tokens/s:说明性能很好
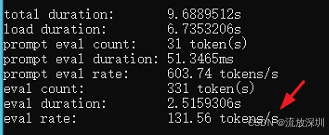
qwen2.5:1.5b 结果如下(131 tokens/s):
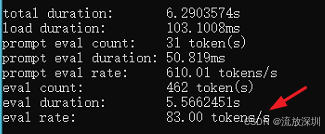
qwen2.5:3b 结果如下(83 tokens/s,推荐使用):
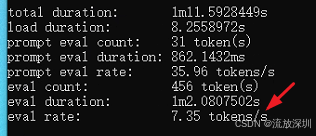
qwen2.5:7b 结果如下(7 tokens/s,很慢!不推荐用于学习):
qwen3:1.7b(55 tokens/s,推荐使用):
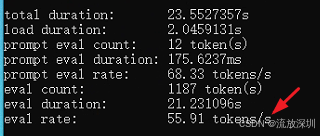
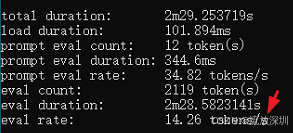
qwen3:4b(14 tokens/s,比较慢,不推荐用于学习):
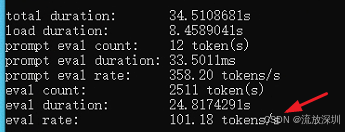
qwen3.5:0.8b 结果如下(101 tokens/s,但是高级设置不生效,不推荐):
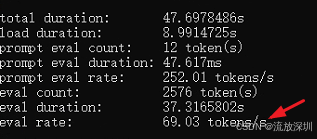
qwen3.5:2b 结果如下(69 tokens/s,推荐使用):
qwen3.5:4b 结果如下(14 tokens/s,很慢!不推荐用于学习):
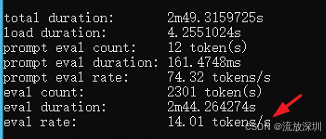
小结:通过多次测试和验证,发现:
1、所有模型 7b 的电脑跑起来都很卡很卡,根本无法正常开发,接口响应超级慢!
2、平时开发推荐使用 qwen2.5:3b 或者 qwen3:1.7b 或者 qwen3.5:2b。
4.1.8 测试本机电脑大模型是否使用了 CPU
用 ollama ps 命令快速确认电脑是否使用了 CPU 跑大模型
PROCESSOR 列的含义:
100% GPU→ ✅ 完全在 GPU 上运行(理想状态)
100% CPU→ ❌ 完全在 CPU 上运行(这就是慢的原因!)
48%/52% CPU/GPU→ ⚠️ 部分卸载到 GPU,部分在 CPU(性能介于两者之间)
测试结果:
当跑 qwen3.5:4b 模型时,只用了 61% 的GPU,39% 的CPU:

当跑 qwen3.5:2b 模型时,用了 100% 的GPU:

4.1.9 让模型"常驻"显存,告别重复加载
Ollama 为了节省资源,默认在请求结束后,会释放模型占用的显存。这会导致一个很严重的问题:
第一次请求 :耗时 = 加载模型时间 (2-3秒) + 生成文本时间
第二次请求 :耗时 = 再次加载模型时间 (2-3秒) + 生成文本时间
每次请求都要重新把模型"搬"到显卡里,这无疑会带来巨大的额外开销,让你感觉每次对话都很"卡顿"。特别是 Java 调用 API 时,卡顿更明显。
解决方案是:设置
keep_alive参数,让模型在内存中多待一会儿,可以极大地减少重复加载的等待时间。
4.1.9.1 通过 Java 代码设置 keep_alive 参数
java
// 在你的请求参数中加入 keep_alive
Map<String, Object> request = Map.of(
"model", "qwen3:1.7b",
"prompt", prompt,
"stream", true,
"keep_alive", "12h" // 请求结束后,模型在内存中保持12小时
);4.1.9.2 在 Ollama 服务端设置环境变量 OLLAMA_KEEP_ALIVE 来全局配置
Windows 系统
找到系统环境变量设置:
在 Windows 搜索框输入"环境变量",点击"编辑系统环境变量"。
在弹出的"系统属性"窗口中,点击"环境变量"。
添加变量:
在"系统变量"区域,点击"新建"。
在"变量名"输入:
OLLAMA_KEEP_ALIVE在"变量值"输入:
12h(或其他值,如-1代表永久,0代表立即卸载)。重启 Ollama 服务:
设置完成后,需要完全退出 Ollama。右键点击系统托盘中的 Ollama 图标,选择 "Quit" 或"退出"。
然后从开始菜单重新启动 Ollama,配置就会生效。
可以通过命令行 ollama ps 查看 UNTIL:

4.2 微服务调用 Ollama 本地模型
4.2.1 SpringBoot 版本要求 3.x
注意:因为 Spring AI Alibaba 基于 Spring Boot 3.x 开发,因此本地 JDK 版本要求为 17 及以上。
简单了解 Spring Boot 2.x 与 Spring Boot 3.x 的区别:
| 对比维度 | Spring Boot 2.x | Spring Boot 3.x | 影响与说明 |
|---|---|---|---|
| 基石与环境 | Java 8 起步,支持至Java 17 | 强制要求 Java 17 或更高版本-1-3 | 可以利用Java 17的新语法(如文本块、record类),也意味着开发环境必须升级-6。 |
Java EE 8 (包名 javax.*) |
Jakarta EE 9+ (包名 jakarta.*)-1-10 |
这是最繁琐的改动点。所有涉及Web、事务、JPA的导入语句都需要全局替换。 | |
| 核心框架 | 基于 Spring Framework 5.x | 基于 Spring Framework 6.x -1-8 | 框架底层全面革新,带来性能与API层面的变化。 |
| 关键特性 | 无官方支持 | 支持 GraalVM 原生镜像 (Native Image)-1-9 | 革命性特性。能将应用编译成二进制可执行文件,实现毫秒级启动和极低内存占用,完美适配Serverless和云原生场景。 |
| 安全配置 | 继承 WebSecurityConfigurerAdapter 类 |
移除 WebSecurityConfigurerAdapter,采用组件式安全配置-2-10 |
安全配置方式发生了破坏性变更,需要按新方式重写。 |
| 可观测性 | 需要较多手动配置和集成 | 深度集成 Micrometer ,提供开箱即用的指标、追踪和日志关联能力-1-4 | 应用的可观测性(Metrics, Tracing)变得更简单、更强大。 |
| 依赖升级 | Tomcat 9, Hibernate 5, Lombok (需特定版本) | Tomcat 10, Hibernate 6, Lombok (需1.18.20+)-1-2 | 所有相关的第三方库都需要升级到支持Jakarta EE的版本,否则会报错。 |
| 新特性 | 无官方虚拟线程支持 | 支持 Java 21 虚拟线程 (Virtual Threads)-4 | 通过 spring.threads.virtual.enabled=true 即可开启,能以极低成本处理高并发。 |
| 已移除/过时 | - | 移除 spring.factories 自动配置方式-9 移除 CommonsMultipartFile-10 移除 springfox (建议改用 springdoc)-10 |
一些老旧或不再维护的库和用法被彻底移除。 |
Spring AI Alibaba 的版本与 Spring Boot 版本有明确的对应关系。官方最新的版本兼容表,可以直接对照使用。
| Spring AI Alibaba | Spring AI | Spring Boot | 说明 |
|---|---|---|---|
| 1.1.2.2(当前最新) | 1.1.2 | 3.5.x | 支持 Agent Skills,提供 Supervisor、Routing 等 Multi-agent 能力 |
| 1.1.0.0 | 1.1.0 | 3.4.x | 1.1.0 首个正式版 |
| 1.0.0.2 | 1.0.0 | 3.4.5 | 1.0 系列稳定版 |
| 1.0.0-M6.1 | 1.0.0-M6 | 3.4.2 | 1.0 系列里程碑版本 |
版本对应规则
Spring AI Alibaba 使用四位版本号 的版本管理方式,前三位版本号与 Spring AI 主版本对应,社区在前三位主版本基础上持续迭代第四位版本号。查看 Spring AI Alibaba 各个版本仓库地址:https://mvnrepository.com/artifact/com.alibaba.cloud.ai/spring-ai-alibaba-starter-dashscope
简单来说:
SAA
1.0.x系列 → Spring Boot3.4.xSAA
1.1.x系列 → Spring Boot3.4.x或3.5.x
两个容易混淆的概念:
Spring Cloud Alibaba:微服务架构解决方案(Nacos、Sentinel、Seata 等),版本体系不同
Spring AI Alibaba :AI 应用开发框架,基于 Spring AI,深度集成阿里云百炼平台 -7
两者是独立的产品,不要搞混。如果你之前用过 Spring Cloud Alibaba 的版本对应关系,那是另一套体系。
4.2.2 编码对接本地大模型
我们通过 SpringAI 对接 Ollama 来对接本地大模型。
项目结构图:

1、pom.xml
html
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>ai</artifactId>
<description>我的第一个AI项目</description>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
</properties>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.5</version>
</parent>
<dependencies>
<!-- 引入 spring-ai-starter-model-ollama 依赖-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
<version>1.1.3</version>
<scope>compile</scope>
</dependency>
<!-- 测试依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
</dependency>
</dependencies>
</project>2、application.yml
html
spring:
ai:
ollama:
# Ollama API URL,默认端口号 11434
base-url: http://localhost:11434
# 模型名称
chat:
model: qwen2.5:3b说明:SpringBoot 默认端口号 8080,Ollama 默认端口号 11434
3、AiApplication.java
java
package ai.study;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @author CSDN流放深圳
* @description
* @create 2026-04-13 10:50
* @since 1.0.0
*/
@SpringBootApplication
public class AiApplication {
public static void main(String[] args) {
SpringApplication.run(AiApplication.class, args);
System.out.println(
"`--------------------------`()'--------------------------' \n" +
" || \n" +
" __ || __ \n" +
" ] ****---...._ .' / \n" +
" _,-***==============`--. .'/)/ \n" +
" ,' ) ,--. .-----. `.___________________.' ///_ \n" +
" .' / /___| |_____| _______ () _> \n" +
" / / /____| |__|__| ,----**** `// \\ \n" +
" .<`=='===========================.' (/`. \\ \n" +
" ( `.----------------------------/ `._\\ \n" +
" `-._\\_ 成功起飞! ____...--' \n" +
" ***--666--'***666* \n" +
" .____//______//___, \n" +
" `-----------------' "
);
}
}4、OllamaController.java
java
package ai.study.controller;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
/**
* @author CSDN流放深圳
* @description
* @create 2026-04-15 16:41
* @since 1.0.0
*/
@RestController
public class OllamaController {
@Resource
private ChatModel chatModel;
/**
* 默认调用
* @param msg
* @return
*/
@GetMapping("/call/chat")
public String callChat(@RequestParam(name="msg", defaultValue = "你好") String msg) {
Long start = System.currentTimeMillis();
String result = chatModel.call(msg);
System.out.println("对话结果:" + result);
System.out.println("耗时:" + (System.currentTimeMillis() - start) + "ms");
return result;
}
/**
* 流式返回调用
* stream 方法是一种异步的、持续获得模型响应的方式
* @param msg
* @return
*/
@GetMapping("/stream/chat")
public Flux<String> streamChat(@RequestParam(name="msg", defaultValue = "你好") String msg) {
Long start = System.currentTimeMillis();
Flux<String> result = chatModel.stream(msg);
System.out.println("耗时:" + (System.currentTimeMillis() - start) + "ms");
return result;
}
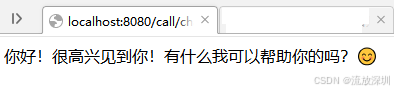
}运行程序,访问接口:http://localhost:8080/call/chat?msg=你好
返回如图,说明 SpringBoot 对接 Ollama 调用本地大模型成功。
测试流式调用效果:http://localhost:8080/stream/chat?msg=介绍一下你自己
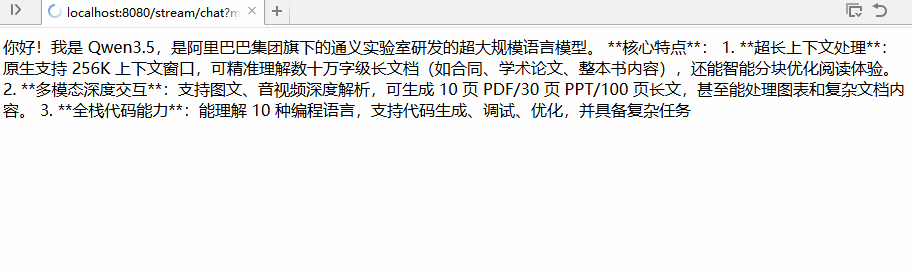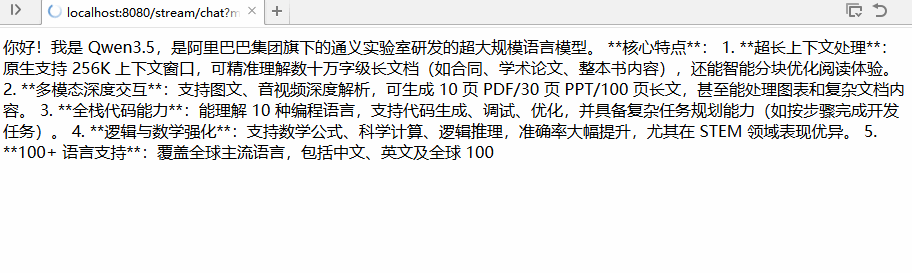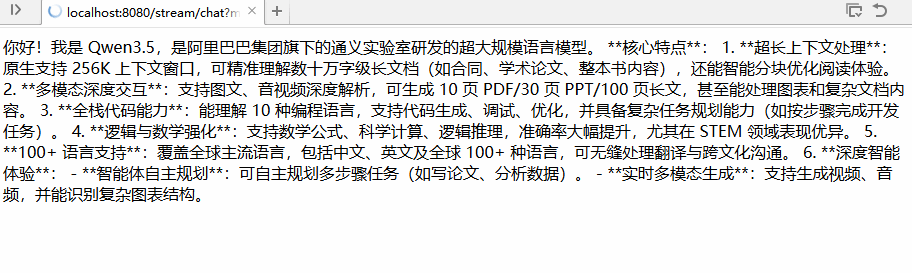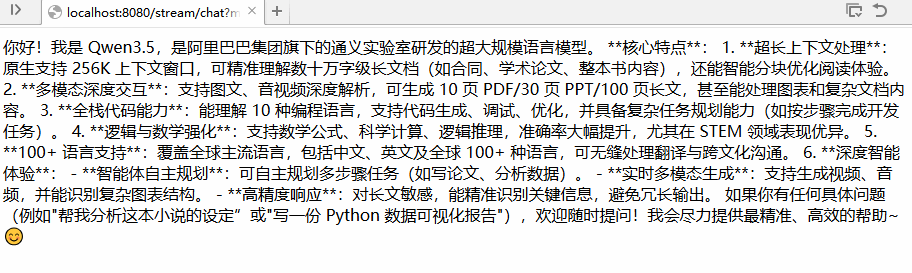
简单说明:
stream 流式输出是一种逐步返回大模型生成结果的技术,生成一点返回一点,允许服务器响应内容分批次实时传输给客户端,而不是等待全部内容生成完毕后再一次性返回。这种机制能显著提升用户体验,尤其适用于大模型响应较慢的场景。
4.2.3 Flux 响应式编程简单了解
Flux 是 SpringWebFlux 中的一个核心组件,属于响应式编程模型的一部分。它主要应用于处理异步、非阻塞的流式数据,能够高效的处理高并发场景。Flux可以生成和处理一系列事件或者数据输出等。
SAA中的流式输出是通过 ReacterStreams 技术实现的和SpringWebFlux 的底层实现是一样的技术,具体流程是:ReactorStreams会订阅数据,当有数据时,ReactorStreams 以分块流的方式发送给客户端用户。
4.2.4 对接局域网其它电脑部署的大模型
要让局域网内的其他电脑调用部署了 Ollama 的机器上的大模型,核心操作是修改服务端电脑的环境变量 ,让 Ollama 服务从"仅本机可见"变为"局域网可见",然后客户端再通过IP地址 进行连接。整个过程主要分两步:配置服务端(跑模型的电脑) 和 连接客户端(你想用模型的电脑)。
🖥️ 第一步:配置服务端(跑模型的电脑)
Ollama 为了安全,默认只允许本机访问(地址是 127.0.0.1),所以我们需要修改它的监听地址。
1. 设置环境变量
Windows操作系统:
打开"系统属性" -> "高级" -> "环境变量"。
在"系统变量 "里点"新建",变量名填
OLLAMA_HOST,变量值填0.0.0.0,然后保存。必须重启 Ollama(可以退出任务栏图标再启动,或者重启电脑)。
macOS / Linux操作系统:
macOS :在终端执行
launchctl setenv OLLAMA_HOST "0.0.0.0"后,重启 Ollama 应用。Linux :编辑 Ollama 服务文件,在
[Service]下添加Environment="OLLAMA_HOST=0.0.0.0",然后执行systemctl daemon-reload和systemctl restart ollama⚠️ 注意事项
跨域问题 :如果客户端是网页(Web)应用,浏览器可能会因为安全策略报错。可以在服务端再新建一个环境变量
OLLAMA_ORIGINS,值设为*,然后重启 Ollama 来解决。安全性:一旦开放局域网访问,同网络下的所有设备都能连接。如果担心安全问题,建议:
只在家庭或受信任的办公网络中使用。
更稳妥的做法是配合 VPN 使用,而不是直接把端口暴露出去。
2. 开放防火墙端口
Ollama 默认使用 11434 端口。你需要确保 Windows 防火墙允许外部设备访问这个端口。
简单方法:直接关闭防火墙(不推荐用于生产环境)。
推荐方法 :在"高级安全防火墙"中新建一条"入站规则",允许 TCP 协议的 11434 端口连接。
在 Windows 高级安全防火墙中为 Ollama 开放 11434 端口的入站规则,可以按以下步骤操作:
第一步:打开高级安全防火墙
按下键盘上的 Win + R 组合键,输入以下任一个命令后按回车:
firewall.cpl 或 wf.msc然后在打开的"Windows Defender 防火墙"窗口左侧,点击 "高级设置"。
第二步:新建入站规则
在左侧导航栏中,选中 "入站规则"。
在右侧的"操作"面板中,点击 "新建规则..."。
第三步:选择规则类型
在弹出的"新建入站规则向导"中:
- 选择 "端口",然后点击"下一步"。
第四步:指定协议和端口
确保选中 "TCP"(Ollama 服务使用 TCP 协议)。
选中 "特定本地端口"。
在输入框中填入
11434。点击"下一步"。
如果需要开放多个端口,可以用英文逗号分隔,例如:
11434,8080,3000。第五步:允许连接
- 选择 "允许连接",然后点击"下一步"。
第六步:选择配置文件(重要)
在此处勾选所有三个网络位置类型,这样可以确保无论服务端电脑连接到何种网络(公司域、家庭/工作网络、公共场所网络),规则都能生效:
域 (Domain)
专用 (Private)
公用 (Public)
勾选完成后,点击"下一步"。
第七步:命名规则
在"名称"框中输入一个容易识别的名字,例如 "Ollama Allow Port 11434"。
(可选)在"描述"框中填写说明,如"允许局域网内其他设备访问 Ollama 服务"。
点击 "完成"。
💻 第二步:连接客户端(跑代码的电脑)
通过 API 地址连接(通用方法)
无论你用的是 Chatbox、Open WebUI、NextChat 还是自定义脚本,核心就是将 API 地址 (或 Base URL)改为:http://服务端IP地址:11434
如果是调用局域网内的电脑部署的模型,没有设置防火墙,会报错:
2026-04-15T18:36:05.750+08:00 WARN 47680 --- nio-8080-exec-1 o.s.a.r.a.SpringAiRetryAutoConfiguration : Retry error. Retry count: 1, Exception: I/O error on POST request for "http://192.168.xx.xx:11434/api/chat": null
5、深入浅出 ChatClient
ChatClient 类似于应用程序开发中的服务层,它为应用程序直接提供
AI 服务,开发者可以使用 ChatClient Fluent API 快速完成一整套 AI 交互流程的组装。包括一些基础功能,如:
- 定制和组装模型的输入(Prompt)
- 格式化解析模型的输出(Structured Output)
- 调整模型交互参数(ChatOptions)
还支持更多高级功能:
- 聊天记忆(Chat Memory)
- 工具/函数调用(Function Calling)
- RAG
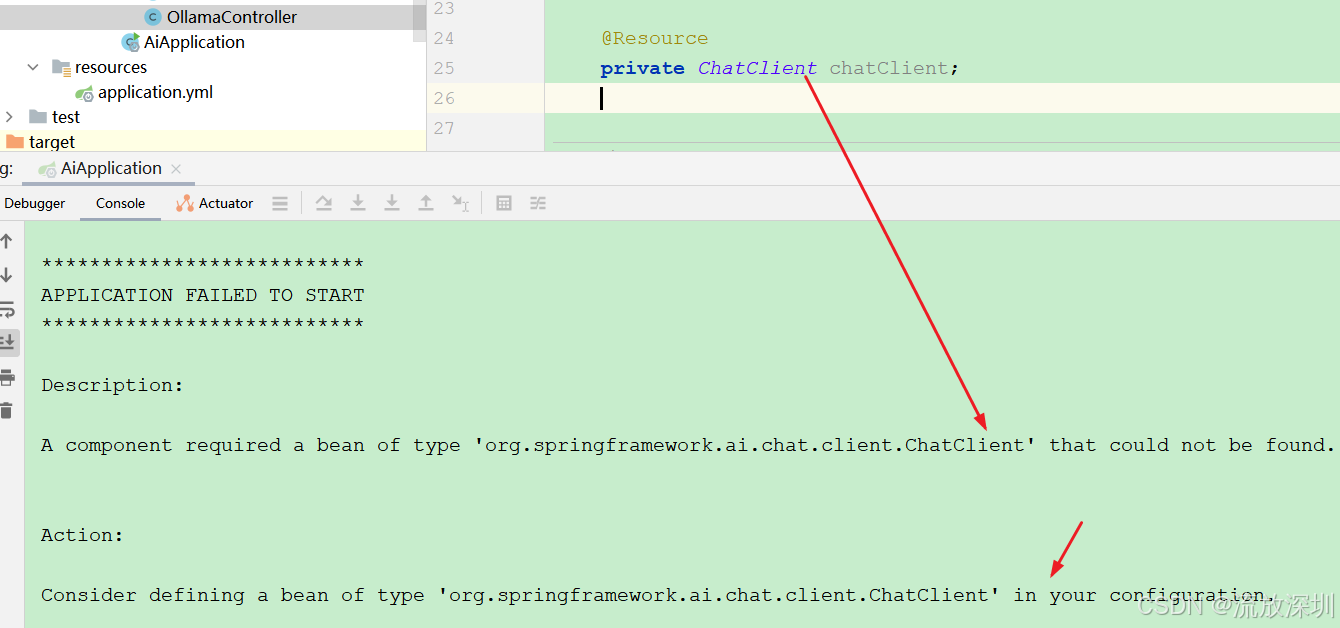
5.1 ChatClient 无法自动注入,需要手动注入
ChatClient 是基于 ChatModel 协同多个组件(例如,提示词模板、聊天记忆、LLM Model、输出解析器、RAG 组件:嵌入模型和存储)并且通常涉及多个交互,因此协调它们会让编码变得繁琐。如果使用自动注入会报错:
A component required a bean of type 'org.springframework.ai.chat.client.ChatClient' that could not be found.
5.1.1 使用 ChatClient.Builder 对象创建 ChatClient 实例
通过编程方式自行创建一个 ChatClient.Builder 实例并用它来得到 ChatClient 实例:
java
package ai.study.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
/**
* @author CSDN流放深圳
* @description
* @create 2026-04-16 16:41
* @since 1.0.0
*/
@RestController
public class ChatClientController {
private ChatClient chatClient;
/**
* 使用的 Spring Boot 自动装配默认生成的 ChatClient.Builder 的 bean,把它注入到自己的类中
* @param chatModel
*/
public ChatClientController(ChatModel chatModel) {
this.chatClient = ChatClient.builder(chatModel).build();
}
/**
* 调用 ChatClient
* @param msg
* @return
*/
@GetMapping("/chatClient/chat")
public String chatClient(@RequestParam(name="msg", defaultValue = "你好") String msg) {
Long start = System.currentTimeMillis();
String result = this.chatClient.prompt()
.user(msg)
.call()
.content();
System.out.println("对话结果:" + result);
System.out.println("耗时:" + (System.currentTimeMillis() - start) + "ms");
return result;
}
}在这个示例中,首先设置了用户消息的内容,call 方法向 AI 模型发送请求,content 方法以字符串形式返回 AI 模型的响应。访问接口:http://localhost:8080/chatClient/chat
5.1.2 通过自定义配置类注入 ChatClient 对象
在实际开发中,大部分情况下还是需要通过自定义配置类来注入 ChatClient 对象:
java
package ai.study.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author CSDN流放深圳
* @description
* @create 2026-04-16 18:17
* @since 1.0.0
*/
@Configuration
public class ChatClientConfig {
/**
* 创建 ChatClient
*
* @param chatModel
* @return
*/
@Bean
public ChatClient getChatClient(ChatModel chatModel) {
return ChatClient.builder(chatModel).build();
}
}使用自定义注解类:
java
package ai.study.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
/**
* @author CSDN流放深圳
* @description
* @create 2026-04-16 16:41
* @since 1.0.0
*/
@RestController
public class ChatClientController {
private ChatClient chatClient;
/**
* 使用的 Spring Boot 自动装配默认生成的 ChatClient.Builder 的 bean,把它注入到自己的类中
* @param chatModel
*/
public ChatClientController(ChatModel chatModel) {
this.chatClient = ChatClient.builder(chatModel).build();
}
@Autowired
private ChatClient myChatClient;
/**
* 调用 ChatClient
* @param msg
* @return
*/
@GetMapping("/chatClient/chat")
public String chatClient(@RequestParam(name="msg", defaultValue = "你好") String msg) {
Long start = System.currentTimeMillis();
String result = this.chatClient.prompt()
.user(msg)
.call()
.content();
System.out.println("对话结果:" + result);
System.out.println("耗时:" + (System.currentTimeMillis() - start) + "ms");
return result;
}
/**
* 使用自定义注解注入 ChatClient
* @param msg
* @return
*/
@GetMapping("/myChatClient/chat")
public String myChatClient(@RequestParam(name="msg", defaultValue = "下午好") String msg) {
Long start = System.currentTimeMillis();
String result = myChatClient.prompt()
.user(msg)
.call()
.content();
System.out.println("对话结果:" + result);
System.out.println("耗时:" + (System.currentTimeMillis() - start) + "ms");
return result;
}
}接口访问地址:http://localhost:8080/myChatClient/chat

5.2 ChatClient 和 ChatModel 对比
在Spring AI框架中,ChatModel和ChatClient虽然都能实现与大模型的通信,但它们的设计定位和抽象层级 有本质区别。简单来说,ChatModel是底层的"发动机 ",负责最基础的通信协议;而ChatClient是上层的"智能驾驶舱",为开发者提供了极其便利的链式调用和高级功能。
| 对比维度 | ChatModel (底层模型接口) | ChatClient (高级客户端门面) |
|---|---|---|
| 🎯 核心定位 | 底层模型适配器 。作为框架的核心抽象,直接封装与AI模型(如OpenAI、通义千问)的HTTP API通信,是"发动机"的角色。 | 高级对话门面 。构建于 ChatModel 之上,为开发者提供的功能更全面的"智能驾驶舱",旨在提升开发效率和工程体验。 |
| 📝 API风格 | 直接调用 。代码通常较为底层,需要开发者手动构造 Prompt、Message 等请求对象,并处理 ChatResponse 响应。 |
链式调用 (Fluent API)。采用 Builder 模式,代码语义清晰、简洁直观,可以一行链式完成请求构建与发送。 |
| ⚙️ 功能扩展 | 功能单一,灵活性高 。主要提供call()和stream()两个核心方法,但给予开发者对请求参数最精细的控制权。 |
功能丰富,开箱即用 。内置了诸多高级能力,如SystemMessage设置、提示词模板、结构化输出 (entity())、对话记忆(Advisor)、RAG等。 |
| 🚀 易用性 | 中等 。需要理解 Prompt、Message 等内部概念,代码量相对较大,适合需要深度定制的场景。 |
非常高。对初学者友好,代码简洁,通过链式API可读性极强,是官方推荐的日常开发方式。 |
| 🏆 适用场景 | - 需要精确控制 每个API参数。 - 进行框架底层开发 或自定义Starter。 - 需要使用某个模型独有的、尚未被ChatClient封装的特性。 |
- 日常业务开发 (如智能客服、RAG应用)。 - 快速构建原型 ,追求开发效率。 - 需要集成结构化输出、对话记忆、工具调用等高级功能。 |
总的来说,ChatClient与ChatModel并非互斥,而是相辅相成的关系。ChatClient内部依赖并持有ChatModel来完成最终的模型调用。在日常开发中,建议优先使用ChatClient,它能极大提升你的开发效率。只有当需要绕过ChatClient的封装,对请求进行最底层的精细控制时,才直接使用ChatModel。
6、浅谈 SSE
6.1 了解 SSE 概念
SSE(Server Sen Events)服务器发送事件,是一种允许服务端可以持续推送数据片段(逐句)到前端Web的技术,通过单向的HTTP长连接,使用一个长期存在的连接,让服务器可以主动将数据"推"给客户端。SSE是轻量级的单向通信协议,适合AI对话这类服务器主导的场景。
SSE的核心思想是:客户端发起一个请求,服务器保持这个连接打开,并在有数据时通过这个连接将数据发送给客户端。它是基于HTTP协议,可以传输文本,复杂性较低,连接开销低。与传统的请求-响应模式有本质区别(客户端请求一次,服务端响应一次)。
6.2 SSE 与 WebSocket 的简单对比

6.4 SSE 之 ChatModel 实现流式输出且多模型共存
实际项目中,我们通常会使用几个大模型一起提供服务,因此实现多模型共存也需要掌握。以下案例分别是 ChatModel 和 ChatClient 实现多模型共存的案例。
6.4.1 ChatModel 实现多模型共存
增加配置类:SaaLLMConfig,代码如下:
java
package ai.study.config;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.ai.ollama.api.OllamaApi;
import org.springframework.ai.ollama.api.OllamaChatOptions;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
/**
* @author CSDN流放深圳
* @description 多模型共存配置类
* @create 2026-04-20 18:20
* @since 1.0.0
*/
@Configuration
public class SaaLLMConfig {
private final String QWEN_2_MODEL_NAME = "qwen2.5:7b";
private final String QWEN_3_MODEL_NAME = "qwen3:4b";
@Value("${spring.ai.ollama.base-url}")
private String BASE_URL;
/**
* 创建一个 qwen2.5 的 ChatModel
* @return
*/
@Bean(name = "qwen2")
@Primary
public ChatModel qwen2() {
// 1. 先创建 OllamaApi,配置 base-url
OllamaApi ollamaApi = OllamaApi.builder()
.baseUrl(BASE_URL)
.build();
//2、通过 OllamaApi 创建 OllamaChatModel
return OllamaChatModel.builder()
.ollamaApi(ollamaApi)
.defaultOptions(OllamaChatOptions.builder()
.model(QWEN_2_MODEL_NAME)
.build())
.build();
}
/**
* 创建一个 qwen3 的 ChatModel
* @return
*/
@Bean(name = "qwen3")
public ChatModel qwen3() {
// 1. 先创建 OllamaApi,配置 base-url
OllamaApi ollamaApi = OllamaApi.builder()
.baseUrl(BASE_URL)
.build();
//2、通过 OllamaApi 创建 OllamaChatModel
return OllamaChatModel.builder()
.ollamaApi(ollamaApi)
.defaultOptions(OllamaChatOptions.builder()
.model(QWEN_3_MODEL_NAME)
.build())
.build();
}
}注意:在创建 Bean 时,我们需要指定一个优先级,比如我们设置 qwen2 为优先级最高,需要增加注解:
import org.springframework.context.annotation.Primary;否则会报错:
Consider marking one of the beans as @Primary, updating the consumer to accept multiple beans, or using @Qualifier to identify the bean that should be consumed
这个提示通常出现在 Spring 容器中有多个相同类型的 Bean,而你在某个地方尝试用
@Autowired或构造器注入时,Spring 无法确定具体要注入哪一个。三种解决方案:
方案 说明 示例 @Primary 标记一个 Bean 为首选的,当没有明确指定时使用这个 @Bean @Primary public ChatModel llama3ChatModel() {...}@Qualifier 在注入点和 Bean 定义处都指定名称 @Qualifier("qwenChatModel") ChatModel chatModel接受多个 Bean 注入为 List或Map,由代码决定使用哪个public void process(List<ChatModel>
测试类:SaaController
java
package ai.study.controller;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
/**
* @author CSDN流放深圳
* @description 多模型共存测试类
* @create 2026-04-21 10:41
* @since 1.0.0
*/
@RestController
public class SaaController {
@Autowired
@Qualifier("qwen2")
private ChatModel chatModelQwen2;
@Autowired
@Qualifier("qwen3")
private ChatModel chatModelQwen3;
/**
* 调用 qwen2,流式返回
* stream 方法是一种异步的、持续获得模型响应的方式
* @param msg
* @return
*/
@GetMapping("/qwen2/chat")
public Flux<String> qwen2Chat(@RequestParam(name="msg", defaultValue = "你好,你是谁?") String msg) {
Long start = System.currentTimeMillis();
Flux<String> result = chatModelQwen2.stream(msg);
System.out.println("耗时:" + (System.currentTimeMillis() - start) + "ms");
return result;
}
/**
* 调用 qwen3,流式返回
* stream 方法是一种异步的、持续获得模型响应的方式
* @param msg
* @return
*/
@GetMapping("/qwen3/chat")
public Flux<String> qwenChat3(@RequestParam(name="msg", defaultValue = "你好,你是谁?") String msg) {
Long start = System.currentTimeMillis();
Flux<String> result = chatModelQwen3.stream(msg);
System.out.println("耗时:" + (System.currentTimeMillis() - start) + "ms");
return result;
}
}测试接口1:http://localhost:8080/qwen2/chat

测试接口2:http://localhost:8080/qwen3/chat

6.4.2 ChatClient 实现多模型共存
在 6.4.1 的基础上,修改 ChatClientConfig 代码,如下:
java
package ai.study.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
/**
* @author CSDN流放深圳
* @description 多模型共存配置类
* @create 2026-04-16 18:17
* @since 1.0.0
*/
@Configuration
public class ChatClientConfig {
/**
* 创建 ChatClient
*
* @param chatModel
* @return
*/
@Bean
public ChatClient getChatClient(ChatModel chatModel) {
return ChatClient.builder(chatModel).build();
}
/**
* 创建 qwen2ChatClient
* @param chatModel
* @return
*/
@Bean(name = "qwen2ChatClient")
@Primary
public ChatClient qwen2ChatClient(@Qualifier("qwen2")ChatModel chatModel) {
return ChatClient.builder(chatModel).build();
}
/**
* 创建 qwen3ChatClient
*
* @param chatModel
* @return
*/
@Bean(name = "qwen3ChatClient")
public ChatClient qwen3ChatClient(@Qualifier("qwen3")ChatModel chatModel) {
return ChatClient.builder(chatModel).build();
}
}注意:在创建 Bean 时,我们需要指定一个优先级,比如我们设置 qwen2ChatClient 为优先级最高,需要增加注解:
import org.springframework.context.annotation.Primary;否则会报错:
Consider marking one of the beans as @Primary, updating the consumer to accept multiple beans, or using @Qualifier to identify the bean that should be consumed
这个提示通常出现在 Spring 容器中有多个相同类型的 Bean,而你在某个地方尝试用
@Autowired或构造器注入时,Spring 无法确定具体要注入哪一个。三种解决方案:
方案 说明 示例 @Primary 标记一个 Bean 为首选的,当没有明确指定时使用这个 @Bean @Primary public ChatModel llama3ChatModel() {...}@Qualifier 在注入点和 Bean 定义处都指定名称 @Qualifier("qwenChatModel") ChatModel chatModel接受多个 Bean 注入为 List或Map,由代码决定使用哪个public void process(List<ChatModel>
测试类 ChatClientController,增加代码如下:
java
@Autowired
@Qualifier("qwen2ChatClient")
private ChatClient qwen2ChatClient;
@Autowired
@Qualifier("qwen3ChatClient")
private ChatClient qwen3ChatClient;
/**
* 使用自定义注解注入 qwen2ChatClient
* @param msg
* @return
*/
@GetMapping("/qwen2ChatClient/chat")
public String qwen2ChatClient(@RequestParam(name="msg", defaultValue = "你好,你是谁?") String msg) {
Long start = System.currentTimeMillis();
String result = qwen2ChatClient.prompt()
.user(msg)
.call()
.content();
System.out.println("对话结果:" + result);
System.out.println("耗时:" + (System.currentTimeMillis() - start) + "ms");
return result;
}
/**
* 使用自定义注解注入 qwen3ChatClient
* @param msg
* @return
*/
@GetMapping("/qwen3ChatClient/chat")
public String qwen3ChatClient(@RequestParam(name="msg", defaultValue = "你好,你是谁?") String msg) {
Long start = System.currentTimeMillis();
String result = qwen3ChatClient.prompt()
.user(msg)
.call()
.content();
System.out.println("对话结果:" + result);
System.out.println("耗时:" + (System.currentTimeMillis() - start) + "ms");
return result;
}测试结果:
1、接口访问:http://localhost:8080/qwen2ChatClient/chat

2、接口访问:http://localhost:8080/qwen3ChatClient/chat

7、提示词(Prompt)
7.1 概念
Prompt 是引导 AI 模型生成特定输出的输入格式,Prompt 的设计和措辞会显著影响模型的响应。
Prompt 最开始只是简单的字符串,随着时间的推移,prompt 逐渐开始包含特定的占位符,例如 AI 模型可以识别的 "USER:"、"SYSTEM:" 等。阿里云通义模型可通过将多个消息字符串分类为不同的角色,然后再由 AI 模型处理,为 prompt 引入了更多结构。每条消息都分配有特定的角色,这些角色对消息进行分类,明确 AI 模型提示的每个部分的上下文和目的。这种结构化方法增强了与 AI 沟通的细微差别和有效性,因为 prompt 的每个部分在交互中都扮演着独特且明确的角色。
Prompt 中的4个主要角色(Role)包括:
- 系统角色(System Role):指导 AI 的行为和响应方式,设置 AI 如何解释和回复输入的参数或规则。这类似于在发起对话之前向 AI 提供说明。比如:设定系统角色为医生、律师,那么大模型回复的内容就仅限于医学、法学内容。
- 用户角色(User Role):代表用户的输入 - 他们向 AI 提出的问题、命令或陈述。这个角色至关重要,因为它构成了 AI 响应的基础。
- 助手角色(Assistant Role):AI 对用户输入的响应。这不仅仅是一个答案或反应,它对于保持对话的流畅性至关重要。通过跟踪 AI 之前的响应(其"助手角色"消息),系统可确保连贯且上下文相关的交互。助手消息也可能包含功能工具调用请求信息。它就像 AI 中的一个特殊功能,在需要执行特定功能(例如计算、获取数据或不仅仅是说话)时使用。
- 工具/功能角色(Tool/Function Role):工具/功能角色专注于响应工具调用助手消息返回附加信息。比如:调用第三方API、工具等。
官网参考地址:https://sca.aliyun.com/en/docs/ai/tutorials/prompt/?spm=7145af80.321ad293.0.0.72aa5e63qesI7A
7.2 API 概览
1、Prompt:
通常使用 ChatModel 的 call() 方法,该方法接受 Prompt 实例并返回 ChatResponse。
Prompt 类充当有组织的一系列 Message 对象和请求 ChatOptions 的容器。每条消息在提示中都体现了独特的角色,其内容和意图各不相同。这些角色可以包含各种元素,从用户查询到 AI 生成的响应再到相关背景信息。这种安排可以实现与 AI 模型的复杂而详细的交互,因为提示是由多条消息构成的,每条消息都被分配了在对话中扮演的特定角色。
下面是 Prompt 类的定义:
javapublic class Prompt implements ModelRequest<List<Message>> { private final List<Message> messages; private ChatOptions chatOptions; }2、Message:
Message 接口封装了一个提示文本、一组元数据属性以及一个称为 MessageType 的分类。该接口定义如下:
javapublic interface Content { String getContent(); Map<String, Object> getMetadata(); } public interface Message extends Content { MessageType getMessageType(); }Message 接口的各种实现对应 AI 模型可以处理的不同类别的消息。模型根据对话角色区分消息类别。
3、Role:
角色在 Spring AI 中表示为枚举,如下所示:
javapublic enum MessageType { USER("user"), ASSISTANT("assistant"), SYSTEM("system"), TOOL("tool"); }4、Prompt Template:
Spring AI 中用于提示模板的关键组件是 PromptTemplate 类。该类使用 Terence Parr 开发的 OSS StringTemplate 引擎来构建和管理提示。PromptTemplate 类旨在促进结构化提示的创建,然后将其发送到 AI 模型进行处理
javapublic class PromptTemplate implements PromptTemplateActions, PromptTemplateMessageActions { // Other methods to be discussed later }该类实现的接口支持提示创建的不同方面:
PromptTemplateStringActions 专注于创建和呈现提示字符串,代表提示生成的最基本形式。
PromptTemplateMessageActions 专门用于通过生成和操作 Message 对象来创建提示。
PromptTemplateActions 旨在返回 Prompt 对象,该对象可以传递给 ChatModel 以生成响应。
虽然这些接口可能在许多项目中没有得到广泛使用,但它们展示了创建提示的不同方法。
实现的接口是:
javapublic interface PromptTemplateStringActions { String render(); String render(Map<String, Object> model); }方法 String render():将提示模板渲染为最终字符串格式,无需外部输入,适用于没有占位符或动态内容的模板。
方法 String render(Map<String, Object> model):增强渲染功能以包含动态内容。它使用 Map<String, Object>,其中映射键是提示模板中的占位符名称,值是要插入的动态内容。
javapublic interface PromptTemplateMessageActions { Message createMessage(); Message createMessage(List<Media> mediaList); Message createMessage(Map<String, Object> model); }方法 Message createMessage():创建一个不带附加数据的 Message 对象,用于静态或预定义消息内容。
方法 Message createMessage(List mediaList):创建一个带有静态文本和媒体内容的 Message 对象。
方法 Message createMessage(Map<String, Object> model):扩展消息创建以集成动态内容,接受 Map<String, Object>,其中每个条目代表消息模板中的占位符及其对应的动态值。
javapublic interface PromptTemplateActions extends PromptTemplateStringActions { Prompt create(); Prompt create(ChatOptions modelOptions); Prompt create(Map<String, Object> model); Prompt create(Map<String, Object> model, ChatOptions modelOptions); }方法 Prompt create():生成不带外部数据输入的 Prompt 对象,非常适合静态或预定义提示。
方法 Prompt create(ChatOptions modelOptions):生成一个 Prompt 对象,无需外部数据输入,但具有聊天请求的特定选项。
方法 Prompt create(Map<String, Object> model):扩展提示创建功能以包含动态内容,采用 Map<String, Object>,其中每个映射条目都是提示模板中的占位符及其关联的动态值。
方法 Prompt create(Map<String, Object> model, ChatOptions modelOptions):扩展提示创建功能以包含动态内容,采用 Map<String, Object>,其中每个映射条目都是提示模板中的占位符及其关联的动态值,以及聊天请求的特定选项。
7.3 system 角色编码测试
系统角色(System Role):指导 AI 的行为和响应方式,设置 AI 如何解释和回复输入的参数或规则。这类似于在发起对话之前向 AI 提供说明。比如:设定系统角色为医生、律师,那么大模型回复的内容就仅限于医学、法学内容。
7.3.1 ChatModel 整合提示词案例
新增一个测试类 PromptController,代码如下:
java
package ai.study.controller;
import org.springframework.ai.chat.messages.SystemMessage;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
/**
* @author CSDN流放深圳
* @description 提示词测试类
* @create 2026-04-22 10:28
* @since 1.0.0
*/
@RestController
public class PromptController {
@Autowired
@Qualifier("qwen2")
private ChatModel qwen2ChatModel;
/**
* 调用 qwen2,流式返回
* stream 方法是一种异步的、持续获得模型响应的方式
* @param msg
* @return
*/
@GetMapping("/prompt/chatmodel/chat")
public Flux<String> qwen2Chat(@RequestParam(name="msg", defaultValue = "你好,你是谁?") String msg) {
Long start = System.currentTimeMillis();
//系统消息
SystemMessage systemMessage = new SystemMessage("你是一名律师,只回答法律问题。其他问题回复,我只能回答与法律相关的问题,其它问题暂时无法回答。");
//用户消息
UserMessage userMessage = new UserMessage(msg);
//构建提示词对象
Prompt prompt = new Prompt(systemMessage, userMessage);
Flux<ChatResponse> chatResponseMap = qwen2ChatModel.stream(prompt);
Flux<String> result = chatResponseMap.map(r -> r.getResults().get(0).getOutput().getText());
System.out.println("耗时:" + (System.currentTimeMillis() - start) + "ms");
return result;
}
}接口访问测试:http://localhost:8080/prompt/chatmodel/chat?msg=我想吃饭
结果:

7.3.2 ChatClient 整合提示词案例
在测试类:PromptController,增加 ChatClient 代码,如下:
java
@Autowired
@Qualifier("qwen2ChatClient")
private ChatClient qwen2ChatClient;
/**
* 提示词测试,流式返回
* stream 方法是一种异步的、持续获得模型响应的方式
* @param msg
* @return
*/
@GetMapping("/prompt/chatClient/chat")
public Flux<String> promptChat(@RequestParam(name="msg", defaultValue = "你好,你是谁?") String msg) {
Long start = System.currentTimeMillis();
Flux<String> result = qwen2ChatClient.prompt()
.system("你是一名厨师,只回答厨艺问题。其他问题回复,我只能回答与厨艺相关的问题,其它问题暂时无法回答。")//设定系统角色
.user(msg)
.stream()
.content();
System.out.println("耗时:" + (System.currentTimeMillis() - start) + "ms");
return result;
}说明:案例中限定大模型的角色是一名厨师,只能回答厨艺问题。
测试接口:
http://localhost:8080/prompt/chatClient/chat?msg=今年最好看的电影是什么?
结果:
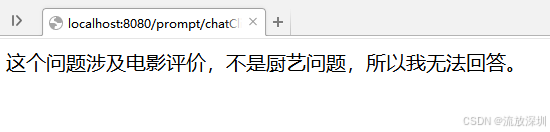
提问厨艺相关的问题:http://localhost:8080/prompt/chatClient/chat?msg=白切鸡怎么做?

7.4 提示词模板(Prompt Template)
Spring AI 中用于提示模板的关键组件是 PromptTemplate 类。该类使用 Terence Parr 开发的 OSS StringTemplate 引擎来构建和管理提示。PromptTemplate 类旨在促进结构化提示的创建,然后将其发送到 AI 模型进行处理
javapublic class PromptTemplate implements PromptTemplateActions, PromptTemplateMessageActions { // Other methods to be discussed later }该类实现的接口支持提示创建的不同方面:
PromptTemplateStringActions 专注于创建和呈现提示字符串,代表提示生成的最基本形式。
PromptTemplateMessageActions 专门用于通过生成和操作 Message 对象来创建提示。
PromptTemplateActions 旨在返回 Prompt 对象,该对象可以传递给 ChatModel 以生成响应。
虽然这些接口可能在许多项目中没有得到广泛使用,但它们展示了创建提示的不同方法。
实现的接口是:
javapublic interface PromptTemplateStringActions { String render(); String render(Map<String, Object> model); }方法 String render():将提示模板渲染为最终字符串格式,无需外部输入,适用于没有占位符或动态内容的模板。
方法 String render(Map<String, Object> model):增强渲染功能以包含动态内容。它使用 Map<String, Object>,其中映射键是提示模板中的占位符名称,值是要插入的动态内容。
javapublic interface PromptTemplateMessageActions { Message createMessage(); Message createMessage(List<Media> mediaList); Message createMessage(Map<String, Object> model); }方法 Message createMessage():创建一个不带附加数据的 Message 对象,用于静态或预定义消息内容。
方法 Message createMessage(List mediaList):创建一个带有静态文本和媒体内容的 Message 对象。
方法 Message createMessage(Map<String, Object> model):扩展消息创建以集成动态内容,接受 Map<String, Object>,其中每个条目代表消息模板中的占位符及其对应的动态值。
javapublic interface PromptTemplateActions extends PromptTemplateStringActions { Prompt create(); Prompt create(ChatOptions modelOptions); Prompt create(Map<String, Object> model); Prompt create(Map<String, Object> model, ChatOptions modelOptions); }方法 Prompt create():生成不带外部数据输入的 Prompt 对象,非常适合静态或预定义提示。
方法 Prompt create(ChatOptions modelOptions):生成一个 Prompt 对象,无需外部数据输入,但具有聊天请求的特定选项。
方法 Prompt create(Map<String, Object> model):扩展提示创建功能以包含动态内容,采用 Map<String, Object>,其中每个映射条目都是提示模板中的占位符及其关联的动态值。
方法 Prompt create(Map<String, Object> model, ChatOptions modelOptions):扩展提示创建功能以包含动态内容,采用 Map<String, Object>,其中每个映射条目都是提示模板中的占位符及其关联的动态值,以及聊天请求的特定选项。
7.4.1 提示词模板的基本使用
使用方法 **Prompt create(Map<String, Object> model)**来构建模板,测试类代码如下:
java
package ai.study.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
import java.util.Map;
/**
* @author CSDN流放深圳
* @description 提示词模板测试类
* @create 2026-04-21 10:41
* @since 1.0.0
*/
@RestController
public class PromptTemplateController {
@Autowired
@Qualifier("qwen2ChatClient")
private ChatClient qwen2ChatClient;
/**
* 提示词模板的基本使用
* @param title
* @param outputFormat
* @param wordCount
* @return
*/
@GetMapping("/template/chat")
public Flux<String> qwenChatClient(String title, String outputFormat, String wordCount) {
Long start = System.currentTimeMillis();
PromptTemplate promptTemplate = new PromptTemplate("写一篇关于{title}的作文,并以{outputFormat}格式输出,字数限制在{wordCount}字以内");
Prompt prompt = promptTemplate.create(Map.of(
"title",title,
"outputFormat",outputFormat,
"wordCount",wordCount));
Flux<String> result = qwen2ChatClient.prompt(prompt).stream().content();
System.out.println("耗时:" + (System.currentTimeMillis() - start) + "ms");
return result;
}
}调用该方法需要传递3个参数:title、outputFformat、wordCount(或者你自定义别的参数名),测试接口:http://localhost:8080/template/chat?title=游玩动物园的一天&outputFormat=markDown&wordCount=500
测试结果:

7.4.2 提示词的嵌套使用
案例:
java
/**
* 提示词模板的嵌套使用
* @param systemTopic 系统消息,用于设定AI的行为规则和功能边界(角色是什么、什么格式返回、字数限制多少)
* @param userTopic 用户消息,用于描述用户想要获取的信息
* @return
*/
@GetMapping("/template/chat2")
public Flux<String> qwenChatClient2(String systemTopic, String userTopic) {
Long start = System.currentTimeMillis();
//系统级别模板
SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate("你是{systemTopic}职业,只回答{systemTopic}相关的问题,其它问题不作回答,以markdown的格式输出。");
Message systemMessage = systemPromptTemplate.createMessage(Map.of("systemTopic",systemTopic));
//用户级别模板
PromptTemplate promptTemplate = new PromptTemplate("请解释一下什么叫做{userTopic}");
Message userMessage = promptTemplate.createMessage(Map.of("userTopic",userTopic));
//组合多个Message
Prompt prompt = new Prompt(List.of(systemMessage,userMessage));
Flux<String> result = qwen2ChatClient.prompt(prompt).stream().content();
System.out.println("耗时:" + (System.currentTimeMillis() - start) + "ms");
return result;
}测试接口1:http://localhost:8080/template/chat2?systemTopic=医生&userTopic=阑尾炎
结果1:

测试接口2:http://localhost:8080/template/chat2?systemTopic=医生&userTopic=西游记
结果2:

测试结果说明:
1、使用 qwen2.5:3b 来测试系统角色是医生,提问与医学无关的话题。回答速度很快,但是回答内容错误。比如让医生来回答西游记,医生直接解释了西游记,解释内容正确,但是不应该解释,因为系统设定了医生拒绝回答非医学相关问题。
2、使用 qwen2.5:7b 来测试系统角色是医生,提问与医学无关的话题。回答速度一般(推理需要较长时间),但是回答内容正确。
3、使用 qwen3:1.7b 来测试系统角色是医生,提问与医学无关的话题。回答速度较快,偶发正确回答。但是多次提问,用户提问什么就回答什么,回答的内容是正确。但是不应该解释,因为系统设定了医生拒绝回答非医学相关问题。
4、使用 qwen3:4b 来测试系统角色是医生,提问与医学无关的话题。回答速度很慢(推理需要较长时间),但是回答内容正确,有时候响应超时。
5、使用 qwen3.5:2b 来测试系统角色是医生,提问与医学无关的话题。回答速度很慢(推理需要较长时间),但是回答内容正确,有时候响应超时。
结论:
对于一般的开发电脑和CPU情况,qwen2.5:7b 目前是比较好的选择;qwen3、qwen3.5 回答速度都比较慢,特别是 qwen3.5:7b 简直卡到爆。
7.4.3 流式编程:提示词的嵌套使用
java
/**
* 流式编程:提示词模板的嵌套使用
* @param userTopic
* @return
*/
@GetMapping("/template/chat3")
public Flux<String> qwenChatClient3(String userTopic) {
Long start = System.currentTimeMillis();
Flux<String> result = qwen2ChatClient.prompt()
.system("你是程序员,只回答编程相关的问题,其它问题不作回答。")
.user(userTopic)
.stream()
.content();
System.out.println("耗时:" + (System.currentTimeMillis() - start) + "ms");
return result;
}测试结果:http://localhost:8080/template/chat3?userTopic=烤乳鸽

测试:http://localhost:8080/template/chat3?userTopic=用Java写一个九九乘法表
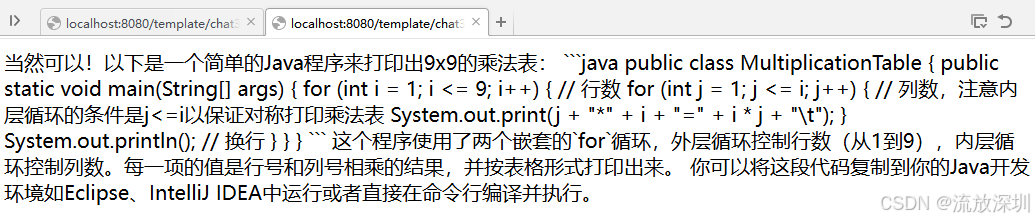
8、格式化输出(Structured Output)
如果您想从 LLM 接收结构化输出,Structured Output 可以协助将
ChatModel/ChatClient方法的返回类型从 String 更改为其他类型。LLM 生成结构化输出的能力对于依赖可靠解析输出值的下游应用程序非常重要。开发人员希望快速将 AI 模型的结果转换为可以传递给其他应用程序函数和方法的数据类型,例如 JSON、XML 或 Java 类。Spring AI 结构化输出转换器有助于将 LLM 输出转换为结构化格式。
当前 Spring AI 提供的 Converter 实现有
AbstractConversionServiceOutputConverter,
AbstractMessageOutputConverter,
BeanOutputConverter,
MapOutputConverterandListOutputConverter。
- BeanOutputConverter - 使用指定的 Java 类(例如 Bean)或 ParameterizedTypeReference 配置,此转换器指示 AI 模型生成符合 DRAFT_2020_12 的 JSON 响应,JSON 模式派生自指定的 Java 类,随后,它利用 ObjectMapper 将 JSON 输出反序列化为目标类的 Java 对象实例。
- MapOutputConverter - 该实现指导 AI 模型生成符合 RFC8259 的 JSON 响应,此外,它还包含一个转换器实现,该实现利用提供的 MessageConverter 将 JSON 负载转换为 java.util.Map<String, Object> 实例。
- ListOutputConverter - 该实现指导 AI 模型生成逗号分隔的格式化输出,最终转换器将模型文本输出转换为 java.util.List。
新增 Student 实体类:
java
package ai.study.entity;
import lombok.Data;
/**
* @author CSDN流放深圳
* @description 学生实体
* @create 2026-04-24 15:29
* @since 1.0.0
*/
@Data
public class Student {
// 学生姓名
private String userName;
// 学生年龄
private Integer age;
// 学生邮箱
private String email;
//自我介绍
private String introduce;
}新增测试类:
java
package ai.study.controller;
import ai.study.entity.Student;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @author CSDN流放深圳
* @description 格式化输出测试类
* @create 2026-04-24 15:27
* @since 1.0.0
*/
@RestController
public class OutputController {
@Autowired
@Qualifier("qwen2ChatClient")
private ChatClient qwen2ChatClient;
/**
* 格式化输出的基本使用
* @param userName
* @param age
* @param email
* @return
*/
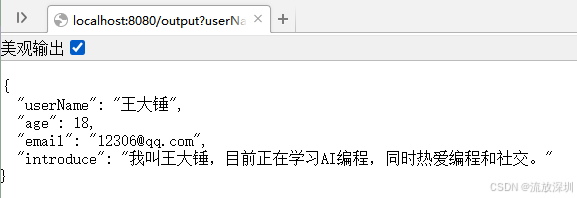
@GetMapping("/output")
public Student output(String userName, Integer age, String email) {
String myself = "我叫{userName},今年{age}岁,邮箱地址是{email},我喜欢撸代码,还喜欢泡妞!我现在正在学AI编程。";
Student entity = qwen2ChatClient.prompt()
.user(m -> m.text(myself)
.param("userName", userName)
.param("age", age)
.param("email", email))
.call().entity(Student.class);
return entity;
}
}测试接口:http://localhost:8080/output?userName=王大锤&age=18&email=12306@qq.com
结果:
9、Chat Memory 连续对话保存和持久化
大型语言模型(LLM)是无状态的,这意味着它们不会保留之前交互的信息。当您希望在多次交互中保持上下文或状态时,这可能是一个限制。为了解决这个问题,Spring AI提供了聊天记忆功能,允许您在与大型语言模型的多次交互中存储和检索信息。
"大模型的对话记忆"这一概念,根植于人工智能与自然语言处理领域,特别是针对具有深度学习能力的大型语言模型而言,它指的是模型在与用户进行交互式对话过程中,能够追踪、理解并利用先前对话上下文的能力。 此机制使得大模型不仅能够响应即时的输入请求,还能基于之前的交流内容能够在对话中记住先前的对话内容,并根据这些信息进行后续的响应。这种记忆机制使得模型能够在对话中持续跟踪和理解用户的意图和上下文,从而实现更自然和连贯的对话。
为什么需要持久化?因为大模型本身是不存储数据的,需要将历史对话的信息一次性提供给它,以实现连续对话,不然服务一旦重启数据就全部丢失了,所以需要持久化。
本章学习,我们编写代码,将会话存储于 Redis 中。
以下是 SpringAI 和 SpringAI Alibaba 的技术对比,其中最重要的一点是使用 Redis 的要求。
| 对比项 | 阿里云方案 | Spring AI 2.0.0-M2 官方方案 |
|---|---|---|
| 依赖 | spring-ai-alibaba-starter-memory-redis |
spring-ai-chat-memory-repository-redis |
| Redis 要求 | 普通 Redis(无需模块) | 需要 Redis Stack(RediSearch 模块) |
| 核心类 | JedisRedisChatMemoryRepository |
RedisChatMemoryRepository |
| 初始化命令 | 使用 SET/GET/EXPIRE 等标准命令 |
使用 FT._LIST/FT.CREATE 等搜索命令 |
| 依赖版本 | 与 Spring AI 1.x 兼容 | 需要 Spring AI 2.0.0-M2+ |
9.1 使用Spring AI Alibaba 整合 Chat Memory
说明:Spring AI 1.1.5 官方提供的 ChatMemory 存储实现中,确实没有 Redis 的实现类。在 2.0.0 之后的版本才明确支持 Redis。
官方文档明确列出的内置仓库实现(Built-in Repository)只有以下这些:
In-Memory Repository (内存)
JdbcChatMemoryRepository (关系型数据库,如 MySQL、PostgreSQL)
CassandraChatMemoryRepository (Cassandra 数据库)
Neo4jChatMemoryRepository (Neo4j 图数据库)
CosmosDBChatMemoryRepository (Azure Cosmos DB)
MongoChatMemoryRepository (MongoDB)
所以这里使用阿里巴巴的来做技术替代。
1、配置 pom.xml 增加阿里云 Spring AI Alibaba Redis 记忆存储和 Jedis 依赖:
html
<!-- 阿里云 Spring AI Redis 记忆存储 -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-memory-redis</artifactId>
<version>1.1.2.2</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.2.0</version>
<scope>compile</scope>
</dependency>手动创建 MyChatMemoryConfig:
java
package ai.study.config;
import com.alibaba.cloud.ai.memory.redis.JedisRedisChatMemoryRepository;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
/**
* @author CSDN流放深圳
* @description ChatMemory配置(redis)
* @create 2026-04-24 17:10
* @since 1.0.0
*/
@Configuration
public class MyChatMemoryConfig {
// Redis 主机地址
@Value("${spring.data.redis.host:127.0.0.1}")
private String host;
// Redis 端口号
@Value("${spring.data.redis.port:6379}")
private int port;
// Redis 密码
@Value("${spring.data.redis.password}")
private String password;
// Redis 连接库
@Value("${spring.data.redis.database}")
private int database;
@Bean
@Primary
public JedisRedisChatMemoryRepository initRepository() {
// 使用阿里云的 JedisRedisChatMemoryRepository
return JedisRedisChatMemoryRepository.builder()
.host(host)
.port(port)
.database(database)
.password(password).build();
}
}ChatMemoryRepository:
大型语言模型(LLM)是无状态的,这意味着它们不会保留之前交互的信息。当您希望在多次交互中保持上下文或状态时,这可能是一个限制。为了解决这个问题,Spring AI提供了聊天记忆功能,允许您在与大型语言模型的多次交互中存储和检索信息。
ChatMemory抽象允许您实现各种类型的内存,以支持不同的用例。消息的底层存储由ChatMemoryRepository处理,其唯一职责是存储和检索消息。由ChatMemory实现决定保留哪些消息以及何时删除它们。策略示例可能包括保留最后N条消息、在特定时间段内保留消息,或保留消息直到达到某个标记限制。
消息窗口聊天记忆:MessageWindowChatMemory
MessageWindowChatMemory 维护一个消息窗口,最多可达指定的最大大小。当消息数超过最大值时,将删除旧的消息,同时保留系统消息。默认窗口大小为20条。
顾问:MessageChatMemoryAdvisor,Advisors
SpringAI Alibaba的一个关键特性是Advisor API。这是一个拦截器链设计模式,允许你通过注入检索数据(Retrieval Context)和对话历史(Chat Memory)来修改传入的 Prompt。
在 application.yml 里增加 Redis 配置:
html
spring:
# redis 相关配置
data:
redis:
host: "输入你的具体IP"
port: 6379
password: "输入你的具体连接密码"
database: 3 #连接的库,不指定默认是db0修改 ChatClient 初始化配置,增加:消息窗口聊天记忆:MessageWindowChatMemory和顾问:MessageChatMemoryAdvisor。
java
/**
* 创建 qwen2ChatClient
* @param chatModel
* @return
*/
@Bean(name = "qwen2ChatClient")
@Primary
public ChatClient qwen2ChatClient(@Qualifier("qwen2")ChatModel chatModel, JedisRedisChatMemoryRepository repository) {
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.builder()
.chatMemoryRepository(repository)
.maxMessages(20) // 最多保存20条消息
.build();
return ChatClient.builder(chatModel)
.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
.build();
}ChatClient 整合 ChatMemory,创建测试类 MemoryController:
java
package ai.study.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @author CSDN流放深圳
* @description 会话存储测试类
* @create 2026-04-24 15:27
* @since 1.0.0
*/
@RestController
public class MemoryController {
@Autowired
@Qualifier("qwen2ChatClient")
private ChatClient chatClient;
/**
* chatClient 整合 ChatMemory
* @param msg
* @param userId
* @return
*/
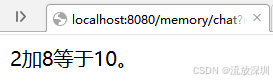
@GetMapping("/memory/chat")
public String memoryChat(String msg, String userId) {
String result = chatClient.prompt(msg)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, userId)) //用户ID,固定值 chat_memory_conversation_id
.call()
.content();
return result;
}
}测试接口:http://localhost:8080/memory/chat?msg=2加8等于多少?&userId=5
结果:
继续测试:http://localhost:8080/memory/chat?msg=再加6等于多少?&userId=5

查看 Redis 相关数据(根据你的 Redis 配置来查看):
说明:SpringAi-Alibaba 默认的 Redis key 前缀是:spring_ai_alibaba_chat_memory
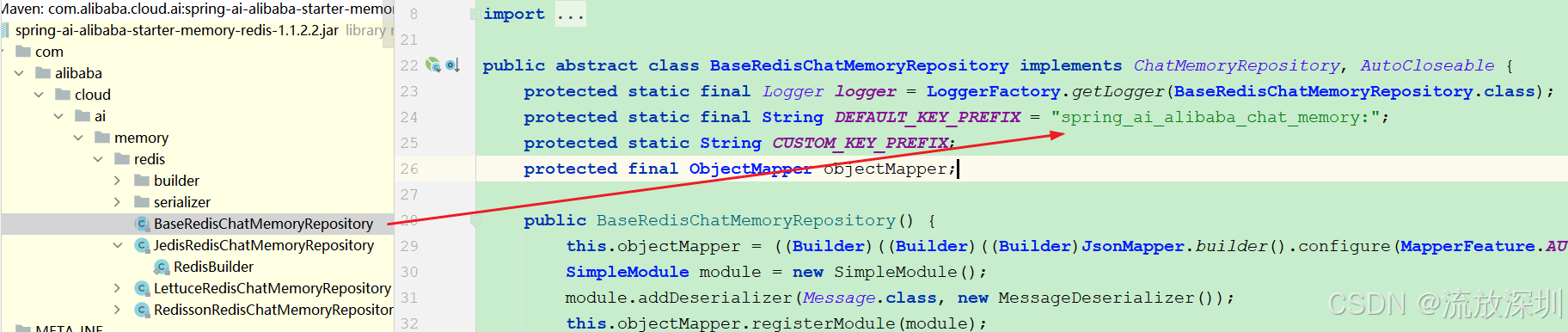
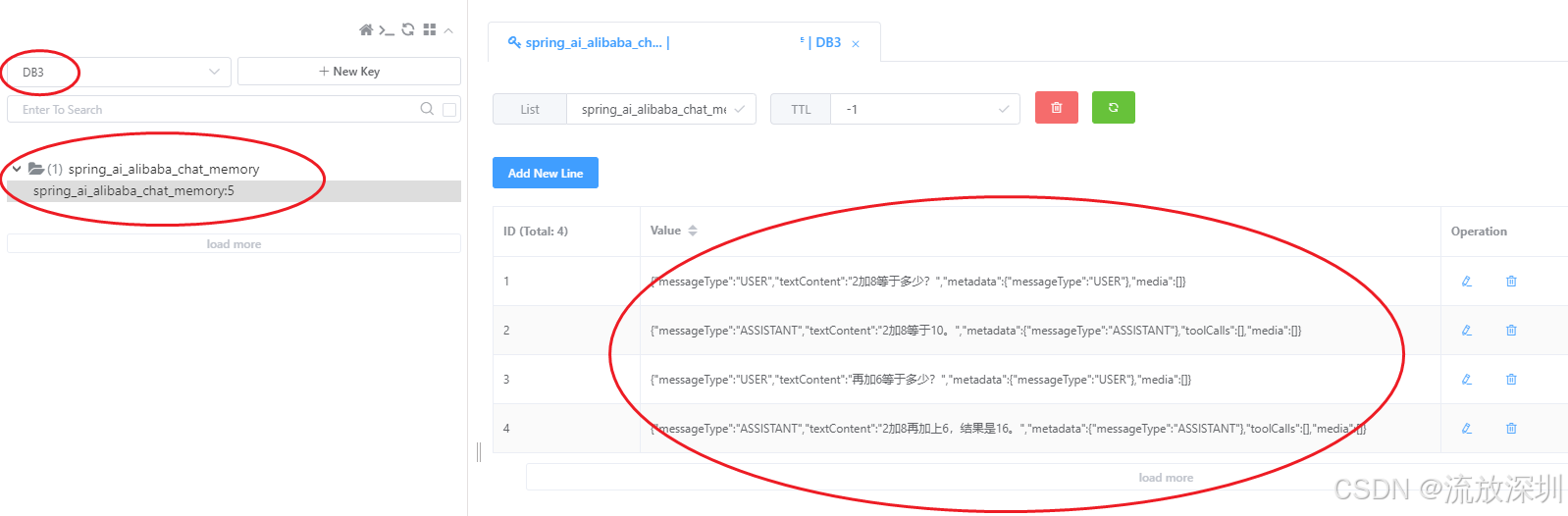
Redis 里记录了所有与大模型对话交互的结果。
10、向量化和向量数据库
10.1 向量的概念
向量概念:Vector是向量或者矢量的意思。向量是数学里的概念,矢量是物理的概念,二者可以理解为同一个概念。
向量是用来表示具有大小和方向的量。
10.2 向量存储(Vector Store)
向量存储(
VectorStore)是一种用于存储和检索高维向量数据的数据库或存储解决方案,它特别适用于处理那些经过嵌入模型转化后的数据。在 VectorStore 中,查询与传统关系数据库不同。它们执行相似性搜索,而不是精确匹配。当给定一个向量作为查询时,VectorStore 返回与查询向量"相似"的向量。VectorStore 用于将您的数据与 AI 模型集成。在使用它们时的第一步是将您的数据加载到矢量数据库中。然后,当要将用户查询发送到 AI 模型时,首先检索一组相似文档。然后,这些文档作为用户问题的上下文,并与用户的查询一起发送到 AI 模型。这种技术被称为检索增强生成(
Retrieval Augmented Generation,RAG)。VectorStore API提供了简单易用的接口供开发者对 VectorStore 进行操作,接下来的部分描述相关接口以及一些高层次的示例用法。
SpringAI 目前支持的向量数据库:
https://docs.spring.io/spring-ai/reference/api/vectordbs.html

10.3 嵌入模型 (Embedding Model)
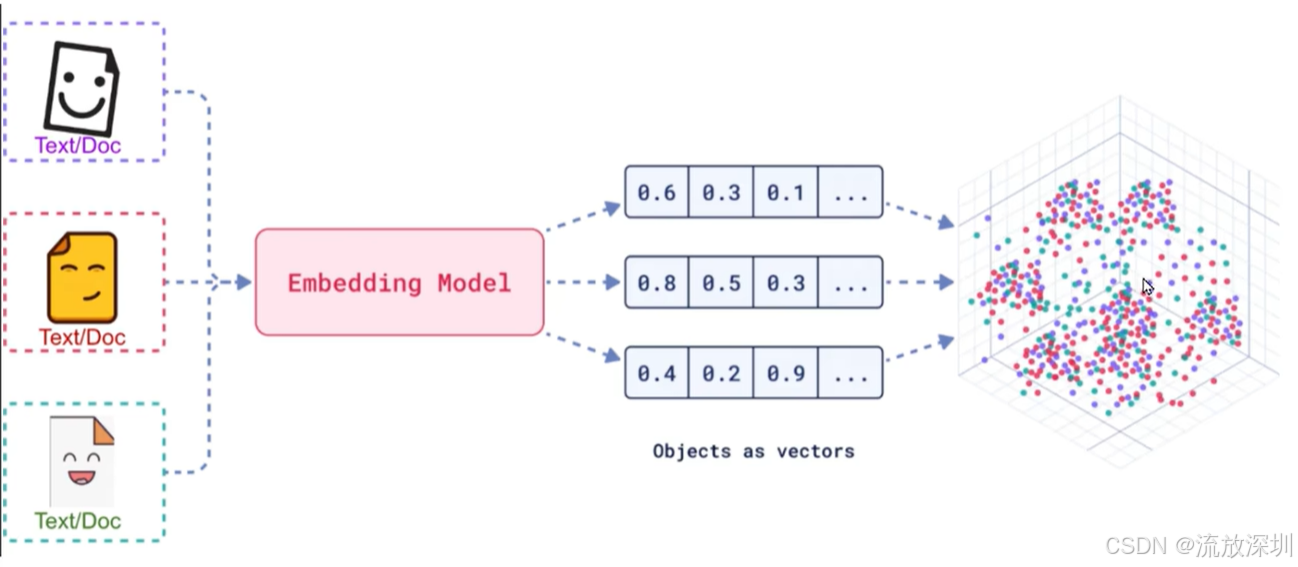
**嵌入(Embedding)的工作原理是将文本、图像和视频转换为称为向量(Vectors)的浮点数数组。**这些向量旨在捕捉文本、图像和视频的含义。嵌入数组的长度称为向量的维度(Dimensionality)。
嵌入模型(EmbeddingModel)是嵌入过程中采用的模型。当前EmbeddingModel的接口主要用于将文本转换为数值向量,接口的设计主要围绕这两个目标展开:
可移植性:该接口确保在各种嵌入模型之间的轻松适配。它允许开发者在不同的嵌入技术或模型之间切换,所需的代码更改最小化。这一设计与 Spring 模块化和互换性的理念一致。
简单性:嵌入模型简化了文本转换为嵌入的过程。通过提供如embed(String text)和embed(Document document)这样简单的方法,它去除了处理原始文本数据和嵌入算法的复杂性。这个设计选择使开发者,尤其是那些初次接触 AI 的开发者,更容易在他们的应用程序中使用嵌入,而无需深入了解其底层机制。
比如:将多个文档、图片、视频等文件通过模型转为浮点数组,然后落到具体的坐标体系。
10.4 安装 RedisStack
注意:SpringAI 支持的 Redis 并不是传统的 Redis,而是 Redis8 也叫做 RedisStack,Redis Stack 是基于 Redis 的扩展套件,集成了多个官方模块(如 RediSearch、RedisJSON、RedisTimeSeries、RedisGraph、RedisBloom),支持全文搜索、JSON 文档存储、图数据、时间序列分析等高级功能,适合构建实时复杂应用。
如果没有安装 RedisStack,可以参考博客:https://blog.csdn.net/BiandanLoveyou/article/details/160614418
原生 Redis 与 Redis Stack 的对比
|------|---------------|-----------------------------|
| 功能维度 | 原生Redis | Redis Stack增强功能 |
| 数据结构 | 字符串、列表、集合、哈希等 | 增加 JSON、图、时间序列、概率结构等 |
| 查询能力 | 仅限键值查询 | 支持全文搜索、向量搜索、图查询、JSON查询 |
| 使用场景 | 缓存、消息队列、计数器等 | 实时推荐、时序分析、知识图谱、文档数据、AI向量检索 |
| 开发体验 | 命令行操作、需手动拼装逻辑 | 提供RedisInsight和对象映射库、开发效率更高 |
RedisStack核心组件:
1、RedisSearch:提供全文搜索能力,支持复杂的文本搜索、聚合和过滤,以及向量数据的存储和检索。
2、RedisJSON:原生支持 JSON 数据的存储、索引和查询,可高效存储和操作嵌套的 JSON 文档。
3、RedisGraph:支持图数据模型,使用 Cypher 查询语言进行图遍历查询。
4、RedisBloom:支持 Bloom、Cuckoo、Count-Min Sketch 等概率数据结构。
10.5 SpringAI Vector 整合 RedisStack
SpringAI Vector 学习文档参考官网:https://docs.spring.io/spring-ai/reference/api/vectordbs/redis.html
接下来依次处理:文本向量化、向量化存储、向量化查询。
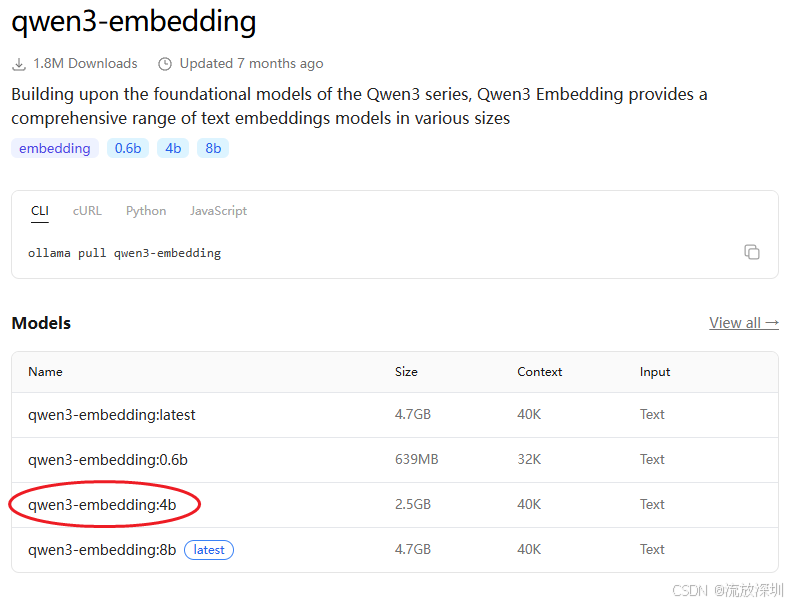
10.5.1 下载文本嵌入模型(qwen3-embedding)
qwen3 和 qwen3-embedding 是两个完全不同的模型,它们的用途和底层运行方式都不一样。
模型对比:Chat vs. Embedding 为了更清晰地理解它们的区别,整理了一个对比表格:
特性 模型 ( qwen3)模型 ( qwen3-embedding)模型类型 对话模型 (Chat Model) 嵌入模型 (Embedding Model) 主要用途 文本生成、问答、多轮对话 文本向量化、语义搜索、RAG 输入 你的问题或指令(如"你是谁?") 任何需要被索引或检索的文本 输出 模型生成的文字回复 一个代表语义的浮点数向量(数组),如 [0.01, -0.02, ...]代码调用 OllamaChatModelOllamaEmbeddingModel与Spring AI的配合 spring-ai-starter-model-ollama用于Chat功能spring-ai-starter-model-ollama用于Embedding功能。注:Spring AI的同一个starter包支持多种模型类型。从本质上说,qwen3 是一个模型家族的代号。在这个家族下,为不同任务训练出了专门的专业模型:qwen3:4b 专精于聊天对话,而 qwen3-embedding:4b 专精于文本向量化。
我们使用 qwen3-embedding 文本嵌入模型,下载地址参考:https://ollama.com/library/qwen3-embedding
10.5.2 pom 增加依赖
pom.xml 增加依赖 spring-ai-starter-vector-store-redis
html
<!-- SpringAI Redis Vector Store https://mvnrepository.com/artifact/org.springframework.ai/spring-ai-starter-vector-store-redis -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-redis</artifactId>
<version>1.1.5</version>
<scope>compile</scope>
</dependency>10.5.3 增加 EmbeddingModel 配置类
新建 EmbeddingModelConfig 用于初始化 EmbeddingModel 配置:
java
package ai.study.config;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.ollama.OllamaEmbeddingModel;
import org.springframework.ai.ollama.api.OllamaApi;
import org.springframework.ai.ollama.api.OllamaEmbeddingOptions;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
/**
* @author CSDN流放深圳
* @description 文本嵌入模型配置类
* @create 2026-04-30 14:00
* @since 1.0.0
*/
@Configuration
public class EmbeddingModelConfig {
@Value("${spring.ai.ollama.base-url}")
private String BASE_URL;
/**
* 模型名称
*/
private final String EMBEDDING_MODEL_NAME = "qwen3-embedding:4b";
/**
* 初始化文本嵌入模型
*
* @return
*/
@Bean
@Primary
public EmbeddingModel initEmbeddingModel() {
// 构建 Ollama API 客户端
OllamaApi ollamaApi = OllamaApi.builder()
.baseUrl(BASE_URL)
.build();
// 构建配置选项
OllamaEmbeddingOptions options = OllamaEmbeddingOptions.builder()
.model(EMBEDDING_MODEL_NAME)//模型名称
.keepAlive("12h")//模型驻留内存时间12小时[citation:1][citation:8]
.truncate(true)//超长文本截断
.numBatch(512) //批次大小
.numThread(4) //CPU线程数
.build();
// 创建 OllamaEmbeddingModel
return OllamaEmbeddingModel.builder()
.ollamaApi(ollamaApi)
.defaultOptions(options)
.build();
}
}10.5.4 增加测试类
创建测试类 VectorController:
java
package ai.study.controller;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.embedding.EmbeddingRequest;
import org.springframework.ai.embedding.EmbeddingResponse;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Arrays;
import java.util.List;
/**
* @author CSDN流放深圳
* @description 向量化测试类
* @create 2026-04-30 10:01
* @since 1.0.0
*/
@RestController
public class VectorController {
/**
* 文本向量化模型
*/
@Autowired
private EmbeddingModel embeddingModel;
/**
* 文本向量化
* @param msg
* @return
*/
@GetMapping("/text/embed")
public EmbeddingResponse textEmbed(String msg) {
EmbeddingResponse embeddingResponse = embeddingModel.call(
new EmbeddingRequest(List.of(msg), null)//options如果为null,则是使用默认的配置
);
System.out.println("向量化结果:" + Arrays.toString(embeddingResponse.getResult().getOutput()));
return embeddingResponse;
}
}测试接口:
http://localhost:8080/text/embed?msg=不到长城非好汉
结果:
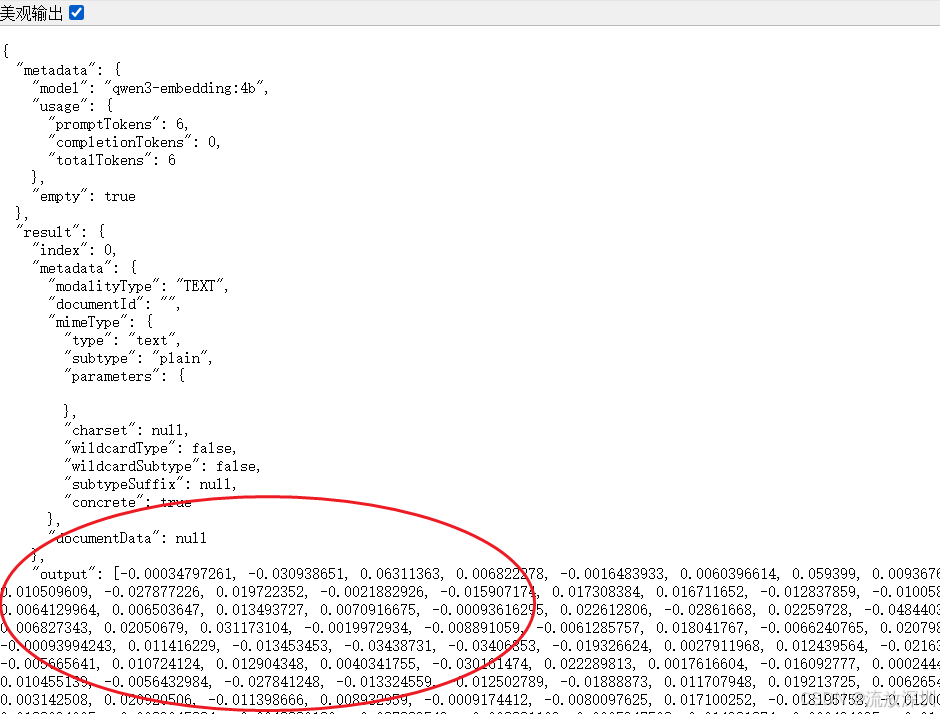
查看控制台:

理解了文本向量化,接下来我们要把文本向量化的结果存入向量数据库 RedisStack。
10.5.5 增加 VectorStore 向量存储配置类
通过阅读源码可知,VectorStore 有2个具体的实现类,一个是 SimpleVectorStore,另一个是 RedisVectorStore。其中 SimpleVectorStore 是默认是存储在内存中的(应用程序的堆内存(ConcurrentHashMap)),不会自动持久化到磁盘,应用重启后数据会丢失。因此我们使用 RedisVectorStore 来作为存储介质。

新建 VectorStoreConfig 用于配置向量存储类并使用 RedisVectorStore 来实现:
java
package ai.study.config;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.redis.RedisVectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import redis.clients.jedis.JedisPooled;
/**
* @author CSDN流放深圳
* @description 向量存储配置类
* @create 2026-04-30 14:10
* @since 1.0.0
*/
@Configuration
public class VectorStoreConfig {
/**
* 创建向量存储
*
* @param embeddingModel
* @param jedisPooled
* @return
*/
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel, JedisPooled jedisPooled) {
return RedisVectorStore.builder(jedisPooled, embeddingModel)
.indexName("my-index") // 索引名称
.prefix("my-embedding:") // Key 前缀
.initializeSchema(true) // 自动初始化索引
.build();
}
}这里的 JedisPooled 配置类是我们之前配置的 RedisStack,在 9.2.2 章节中配置有。
10.5.6 文本向量化并添加到向量存储中
VectorController 增加测试代码:
注意这里的 Document 导入的是:
import org.springframework.ai.document.Document;
java
@Autowired
private VectorStore vectorStore;
/**
* 文本向量化并添加到向量存储中
* @return
*/
@GetMapping("/embed/vector")
public String embedToVector() {
//转化成文档集合
List<Document> documentList = List.of(
new Document("2025年GDP排名第1的城市是:上海市"),
new Document("2025年GDP排名第2的城市是:北京市"),
new Document("2025年GDP排名第3的城市是:广东深圳市"),
new Document("2025年GDP排名第4的城市是:重庆市"),
new Document("2025年GDP排名第5的城市是:广东广州市")
);
//添加到向量存储中
vectorStore.add(documentList);
return "ok";
}测试接口:
http://localhost:8080/embed/vector
接口返回 ok,我们去 RedisStack 管理后台查看数据:
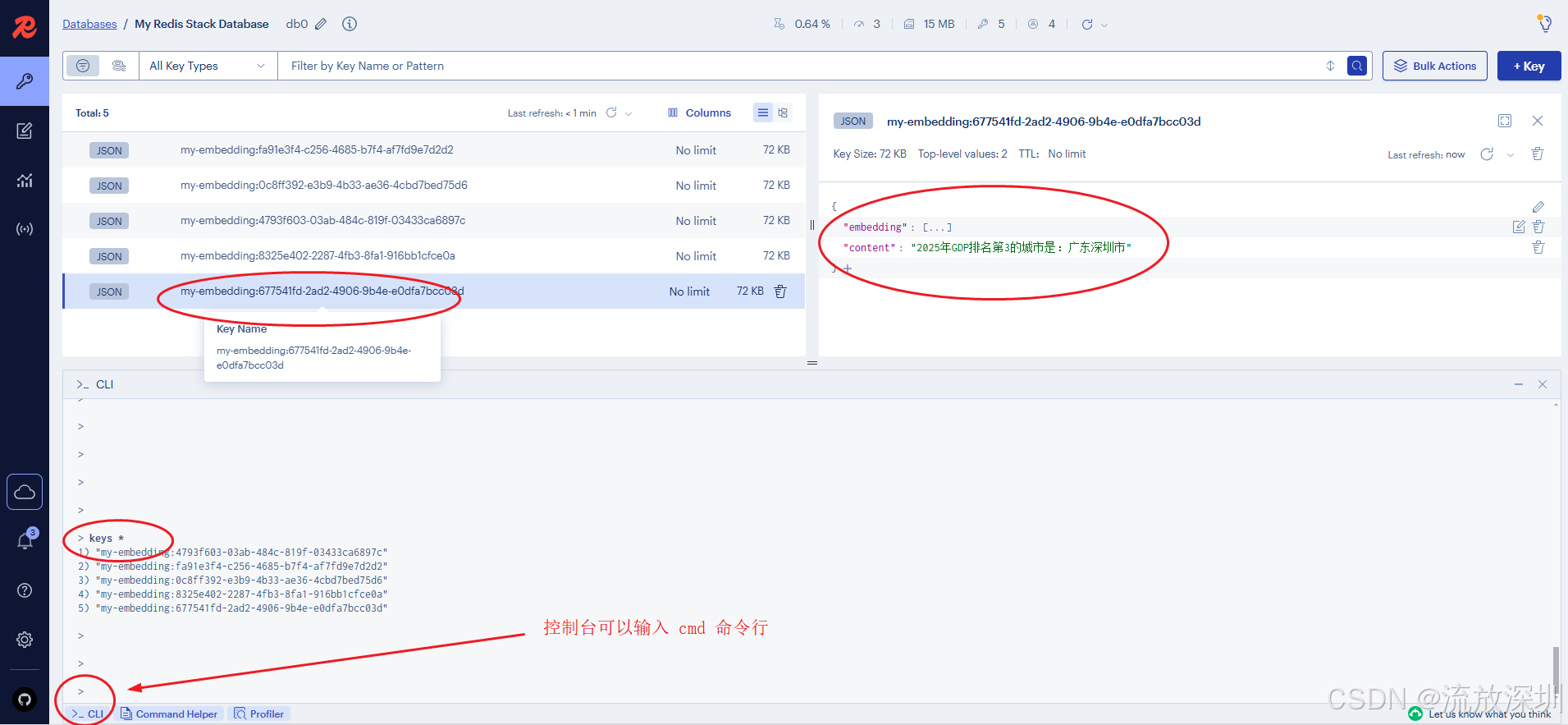
说明:
1、RedisStack 管理后台是之前提到的,在 10.4 章节提及。管理后台地址一般在 http://你部署RedisStack的虚拟机IP:8001/
2、在管理后台的底部有 CLI 命令行窗口
3、可以看到文本经过向量化存入到了 RedisStack 中。
10.5.7 从向量库查询相似度匹配
VectorController 测试类增加测试方法:
java
/**
* 获取向量存储中的所有向量
* @param msg
* @return
*/
@GetMapping("/embed/vector/get")
public List getAll(String msg) {
SearchRequest request = SearchRequest.builder()
.query(msg)//查询条件
.topK(3)//返回数量
.build();
List<Document> documentList = vectorStore.similaritySearch(request);
System.out.println("查询结果:" + documentList);
return documentList;
}测试接口:http://localhost:8080/embed/vector/get?msg=广东
测试结果:

11、RAG 检索增强
11.1 RAG 的概念和出现的背景
概念:
检索增强生成 (RAG,Retrieval Augmented Generation) 是一种使用来自私有或专有数据源的信息来辅助文本生成的技术。它将检索模型(设计用于搜索大型数据集或知识库)和生成模型(例如大型语言模型 (LLM),此类模型会使用检索到的信息生成可供阅读的文本回复)结合在一起。
通过从更多数据源添加背景信息,以及通过训练来补充 LLM 的原始知识库 ,检索增强生成能够提高搜索体验的相关性。**这能够改善大型语言模型的输出,但又无需重新训练模型。**额外信息源的范围很广,从训练 LLM 时并未用到的互联网上的新信息,到专有商业背景信息,或者属于企业的机密内部文档,都会包含在内。
RAG 对于诸如回答问题和内容生成等任务,具有极大价值,因为它能支持生成式 AI 系统使用外部信息源生成更准确且更符合语境的回答。它会实施搜索检索方法(通常是语义搜索或混合搜索)来回应用户的意图并提供更相关的结果。
RAG链路的两个阶段,包括Indexing pipeline阶段和RAG的阶段:
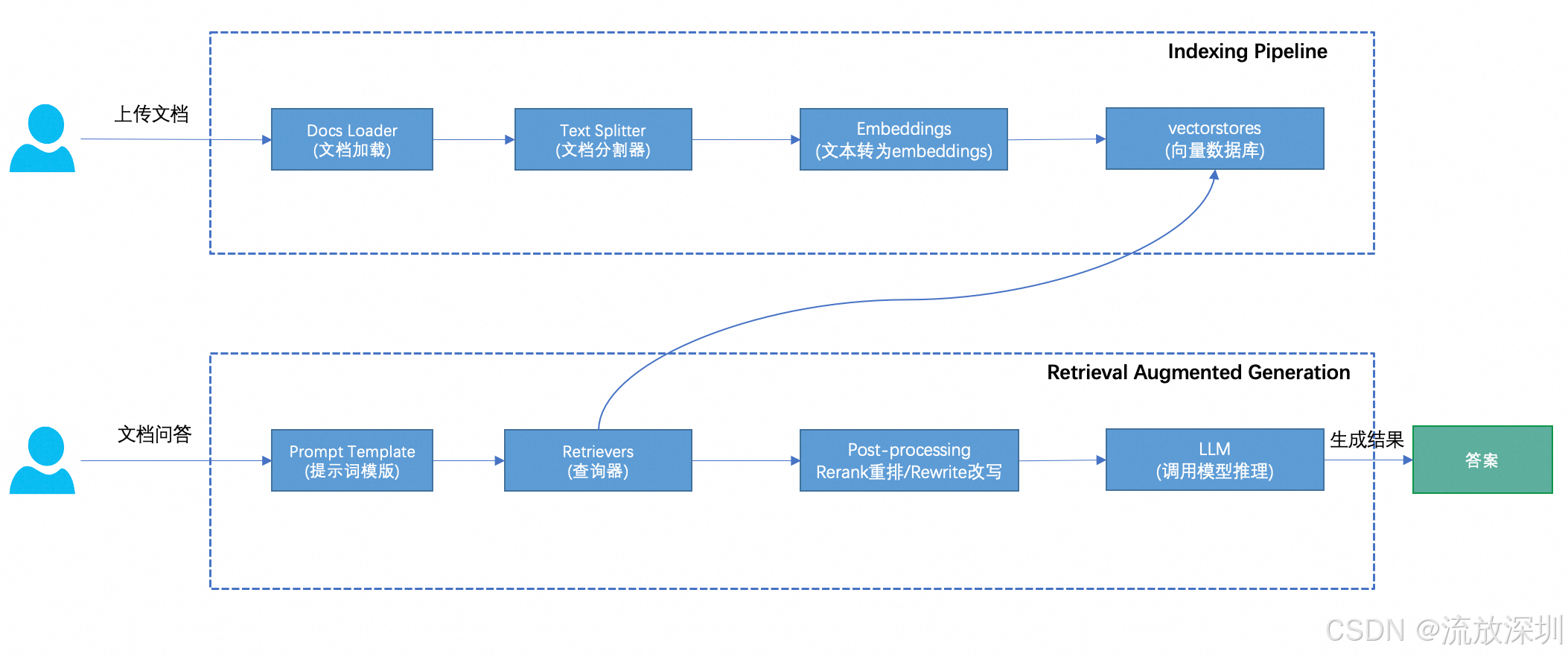
从上图可以看到, indexing pipeline的阶段主要是将结构化或者非结构化的数据或文档进行加载和解析、chunk切分、文本向量化并保存到向量数据库。 RAG的阶段主要包括将prompt文本内容转为向量、从向量数据库检索内容、对检索后的文档chunk进行重排和prompt重写、最后调用大模型进行结果的生成。
简单来说分为2个步骤:建索引、查询。
背景:
为什么需要 RAG 检索增强?因为大模型的训练,都是有时间节点的。比如某个大模型训练出来是在2025年10月,但是在2026年5月份再去问大模型某些特定领域的知识,大模型可能会不知道,就会产生"幻觉"。常见的大模型幻觉有:已读不回、已读乱回、似是而非。这就大大降低了大模型的准确率和知识覆盖率。
SpringAI 官网学习地址:https://docs.spring.io/spring-ai/reference/api/retrieval-augmented-generation.html
官网介绍的RAG:
检索增强生成(RAG)是一种技术,有助于克服大型语言模型在处理长篇内容、事实准确性和上下文感知方面的局限性。
Spring AI通过提供模块化架构来支持RAG,该架构允许您自行构建自定义RAG流程,或使用Advisor API来使用现成的RAG流程。
11.2 SpringAI 整合 RAG
整体思路:读取本地具体业务文件,通过 RedisTemplate 客户端和 VetorStore 存入 RedisStack 形成文档数据库,在用户查询具体问题时,通过 advisor 增强器查询向量数据库的结果返回给用户。
11.2.1 创建一份业务文件
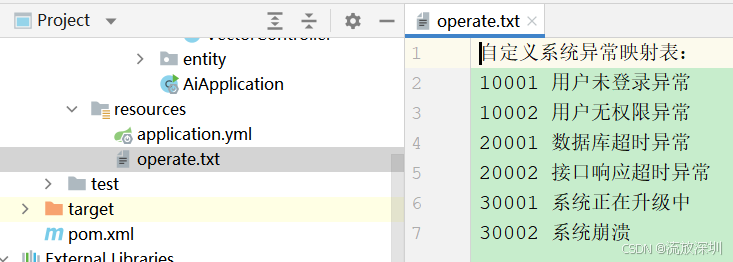
实际项目中,我们经常需要上传一些文件"投喂"给大模型,比如:公司规章制度、行业政策文件、报表文件等。接下来我们模拟一份自定义系统异常的文件,内容如下:
自定义系统异常映射表:
10001 用户未登录异常
10002 用户无权限异常
20001 数据库超时异常
20002 接口响应超时异常
30001 系统正在升级中
30002 系统崩溃
将自定义系统异常文件以 operate.txt 保存,并复制到代码的配置文件中(与 application.yml 同一级)。
11.2.2 配置 RedisTemplate
因为要整合 Redis,我们使用 RedisTemplate,创建 RedisTemplateConfig 配置类:
java
package ai.study.config;
import org.apache.commons.pool2.impl.GenericObjectPoolConfig;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisPassword;
import org.springframework.data.redis.connection.RedisStandaloneConfiguration;
import org.springframework.data.redis.connection.lettuce.LettuceClientConfiguration;
import org.springframework.data.redis.connection.lettuce.LettuceConnectionFactory;
import org.springframework.data.redis.connection.lettuce.LettucePoolingClientConfiguration;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import java.time.Duration;
/**
* @author CSDN流放深圳
* @describe RedisTemplate 配置,SpringBoot 2.0 后使用 Lettuce 客户端而非 Jedis
* @create 2026-05-02 10:01
*/
@Configuration
public class RedisTemplateConfig {
/**
* 数据库,默认 db0
*/
@Value("${spring.data.redis.database:0}")
private Integer database;
/**
* 主机
*/
@Value("${spring.data.redis.host}")
private String host;
/**
* 端口号
*/
@Value("${spring.data.redis.port:6379}")
private Integer port;
/**
* 密码
*/
@Value("${spring.data.redis.password}")
private String password;
/**
* 超时时间
*/
@Value("${spring.data.redis.timeout}")
private Long timeout;
/**
* 超时停止时间
*/
@Value("${spring.data.redis.lettuce.shutdown-timeout}")
private Long shutDownTimeout;
//最大连接数
@Value("${spring.data.redis.lettuce.pool.max-active}")
private Integer maxActive;
//最大空闲连接
@Value("${spring.data.redis.lettuce.pool.max-idle}")
private Integer maxIdle;
//最小空闲连接
@Value("${spring.data.redis.lettuce.pool.min-idle}")
private Integer minIdle;
/**
* 构建 RedisTemplate,使用默认名字,否则其它组件引入时需要增加 @Qualifier 注解过滤
*
* @return
*/
@Bean
public RedisTemplate<String, Object> redisTemplate() {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(lettuceConnectionFactory());//设置连接工厂
//为String类型的key设置序列化器
template.setKeySerializer(new StringRedisSerializer());
//为String类型value设置通用的序列化器
template.setValueSerializer(new GenericJackson2JsonRedisSerializer());
//为Hash类型key设置序列化器
template.setHashKeySerializer(new StringRedisSerializer());
//为Hash类型value设置通用的序列化器
template.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
return template;
}
/**
* Redis连接工厂
*
* @return
*/
@Bean
public LettuceConnectionFactory lettuceConnectionFactory() {
//Redis 基本连接
RedisStandaloneConfiguration redisStandaloneConfiguration = new RedisStandaloneConfiguration();
redisStandaloneConfiguration.setDatabase(database);
redisStandaloneConfiguration.setHostName(host);
redisStandaloneConfiguration.setPort(port);
redisStandaloneConfiguration.setPassword(RedisPassword.of(password));
//lettuce 连接池配置
GenericObjectPoolConfig genericObjectPoolConfig = new GenericObjectPoolConfig();
genericObjectPoolConfig.setMaxIdle(maxIdle);
genericObjectPoolConfig.setMinIdle(minIdle);
genericObjectPoolConfig.setMaxTotal(maxActive);
LettuceClientConfiguration clientConfig = LettucePoolingClientConfiguration.builder()
.commandTimeout(Duration.ofMillis(timeout))
.shutdownTimeout(Duration.ofMillis(shutDownTimeout))
.poolConfig(genericObjectPoolConfig)
.build();
LettuceConnectionFactory factory = new LettuceConnectionFactory(redisStandaloneConfiguration, clientConfig);
return factory;
}
}11.2.3 pom.xml 添加 rag 依赖
html
<!-- SpringAI RAG https://mvnrepository.com/artifact/org.springframework.ai/spring-ai-rag -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-rag</artifactId>
<version>1.1.5</version>
<scope>compile</scope>
</dependency>11.2.4 读取系统异常文件并存入向量数据库
创建配置类 VectorDatabaseConfig ,用于将文件内容存入到向量数据库。
java
package ai.study.config;
import jakarta.annotation.PostConstruct;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
import java.nio.charset.Charset;
import java.util.List;
/**
* @author CSDN流放深圳
* @description 文件内容存入到向量数据库配置类
* @create 2026-05-02 10:17
* @since 1.0.0
*/
@Configuration
public class VectorDatabaseConfig {
@Autowired
private VectorStore vectorStore;
@Value("classpath:operate.txt")
private Resource resource;
/**
* 初始化向量数据库。程序启动时就执行
*/
@PostConstruct
public void init(){
//1。读取文件内容
TextReader textReader = new TextReader(resource);
//设置编码格式,防止乱码
textReader.setCharset(Charset.defaultCharset());
//2 将文件转为向量(开启分词)
List<Document> documentList = new TokenTextSplitter().transform(textReader.read());
//3 写入到向量数据库中
vectorStore.add(documentList);
System.out.println("向量数据库初始化完成");
}
}注意:此版本并未完善,有bug,需要优化。见 11.2.5 章节。
11.2.5 编写测试类
编写 Rag 测试类 RagController
java
package ai.study.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.api.Advisor;
import org.springframework.ai.rag.advisor.RetrievalAugmentationAdvisor;
import org.springframework.ai.rag.retrieval.search.VectorStoreDocumentRetriever;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
/**
* @author CSDN流放深圳
* @description RAG测试类
* @create 2026-04-30 10:01
* @since 1.0.0
*/
@RestController
public class RagController {
@Autowired
@Qualifier("qwen2ChatClient")
private ChatClient chatClient;
@Autowired
private VectorStore vectorStore;
/**
* rag 测试类
* @param msg
* @return
*/
@GetMapping("/rag")
public Flux<String> memoryChat(String msg) {
String systemTopic = "系统提示:你是一个系统运维工程师,按照给出的异常代码给出故障信息,匹配不到则回复找不到异常信息。";
Advisor advisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.build())
.build();
return chatClient.prompt()
.system(systemTopic)
.user(msg)
.advisors(advisor)
.stream().content();
}
}启动系统,在控制台看到向量数据库已经初始化完成。

去 RedisStack 管理后台可以查看到具体数据:
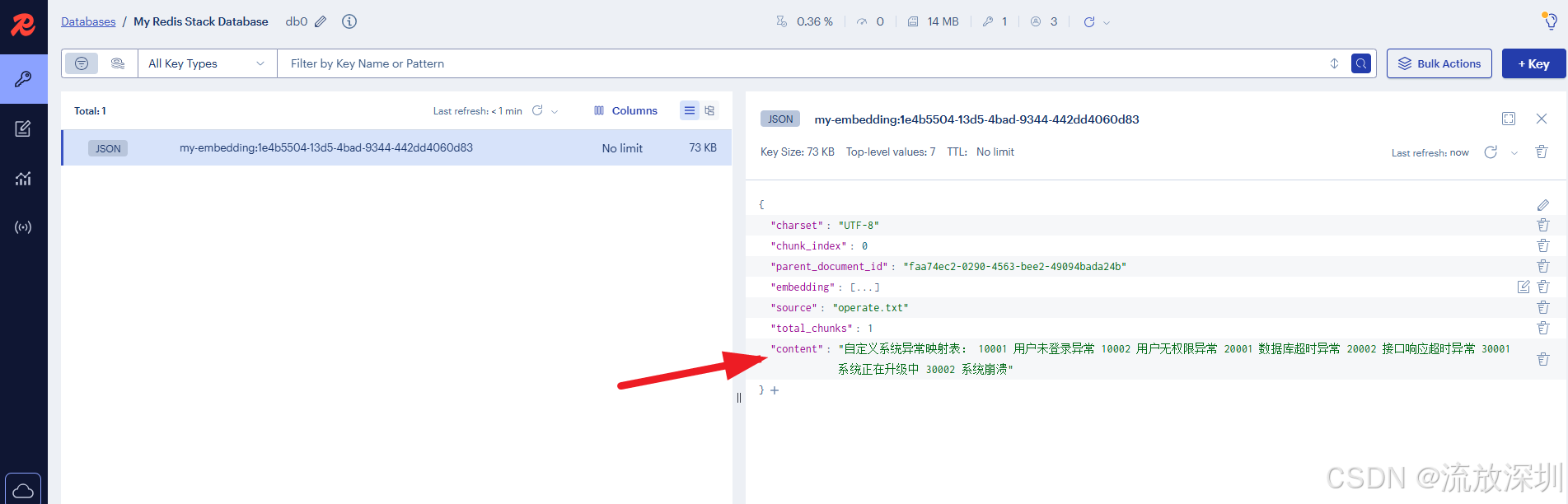
测试接口:http://localhost:8080/rag?msg=30001
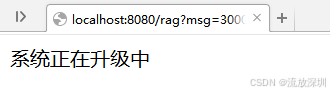
再测试接口:http://localhost:8080/rag?msg=666

测试结果符合我们的预期:当测试的错误编码在文档定义内容里,就能正确提示错误信息,否则提示找不到异常信息。
11.2.6 优化去重初始化文档到向量数据库的逻辑
我们发现一个问题:如果代码里没有去重,每次启动系统,RedisStack 就会把文件初始化进去,导致向量数据库的数据不断堆积,造成内存浪费。
因此,我们需要改造一下 VectorDatabaseConfig 中读取文件存储到向量数据库的逻辑。
1、在 pom.xml 中添加 hutool 加解密工具包:
html
<!-- hutool 工具加密解密包 -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-crypto</artifactId>
<version>5.8.43</version>
<scope>compile</scope>
</dependency>2、修改后的 VectorDatabaseConfig 配置类如下:
java
package ai.study.config;
import cn.hutool.crypto.SecureUtil;
import jakarta.annotation.PostConstruct;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
import org.springframework.data.redis.core.RedisTemplate;
import java.nio.charset.Charset;
import java.util.List;
/**
* @author CSDN流放深圳
* @description 文件内容存入到向量数据库配置类
* @create 2026-05-02 10:17
* @since 1.0.0
*/
@Configuration
public class VectorDatabaseConfig {
@Autowired
private VectorStore vectorStore;
@Value("classpath:operate.txt")
private Resource resource;
@Autowired
private RedisTemplate redisTemplate;
/**
* 初始化向量数据库。程序启动时就执行
*/
@PostConstruct
public void init() {
//1。读取文件内容
TextReader textReader = new TextReader(resource);
//设置编码格式,防止乱码
textReader.setCharset(Charset.defaultCharset());
//获取文件路径等元数据
//拿到文件路径后,常见用途是做去重校验------用文件路径生成哈希值,存入 Redis,避免同一文件被重复加载到向量数据库中。但需要注意,这种方式只能判断"是否同一个文件",无法感知文件内容的变化。如果文件内容更新但路径不变,你可以考虑用文件内容的哈希值来做判断。
String fileName = (String) textReader.getCustomMetadata().get(TextReader.SOURCE_METADATA);
//对文件路径进行md5加密
String securityFileName = SecureUtil.md5(fileName);
String redisKey = "study-operate:" + securityFileName;
//判断文件是否已经存在
Boolean flag = redisTemplate.opsForValue().setIfAbsent(redisKey, "1");
if (flag) {
//文件不存在,则写入向量数据库
List<Document> documentList = new TokenTextSplitter().transform(textReader.read());
//写入到向量数据库中
vectorStore.add(documentList);
System.out.println("向量数据库初始化完成");
} else {
System.out.println("向量数据库已经存在");
}
}
}3、把原来 RedisStack 的旧数据删除。再重启系统。看到多了一个 Redis key,用于判断该文件是否已经存在。
12、工具(Function/Tool Calling)
"工具(Tool)"或"功能调用(Function Calling)"允许大型语言模型(LLM)在必要时调用一个或多个可用的工具,这些工具通常由开发者定义。工具可以是任何东西:网页搜索、对外部 API 的调用,或特定代码的执行等。LLM 本身不能实际调用工具;相反,它们会在响应中表达调用特定工具的意图(而不是以纯文本回应)。然后,我们应用程序应该执行这个工具,并报告工具执行的结果给模型。
工具调用(也称为函数调用)是人工智能应用中的一种常见模式,它允许模型与一组应用程序编程接口(API)或工具进行交互,从而增强其功能。工具主要用于:
**信息检索。**此类工具可用于从外部源(如数据库、网络服务、文件系统或网络搜索引擎)中检索信息。其目标是增强模型的知识,使其能够回答原本无法回答的问题。因此,它们可用于检索增强生成(RAG)场景。例如,可以使用工具来检索给定位置的当前天气、检索最新新闻文章,或查询数据库以获取特定记录。
**采取行动。**此类工具可用于在软件系统中执行操作,如发送电子邮件、在数据库中创建新记录、提交表单或触发工作流。其目标是自动化那些原本需要人工干预或显式编程的任务。例如,可以使用工具为与聊天机器人交互的客户预订航班、在网页上填写表单,或在代码生成场景中基于自动化测试(TDD)实现Java类。
官网学习地址:https://docs.spring.io/spring-ai/reference/api/tools.html
12.1 未进行 ToolCalling 测试
新建一个测试类:ToolCallingController,先测试未进行 ToolCalling 的测试:
java
package ai.study.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
/**
* @author CSDN流放深圳
* @description ToolCalling测试类
* @create 2026-05-04 10:28
* @since 1.0.0
*/
@RestController
public class ToolCallingController {
@Autowired
@Qualifier("qwen2ChatClient")
private ChatClient qwen2ChatClient;
/**
* 未进行 ToolCalling 的测试
* @param msg
* @return
*/
@GetMapping("/no/toolCalling/test")
public Flux<String> toolCallingTest1(@RequestParam(name="msg", defaultValue = "深圳今天的天气如何?") String msg) {
Flux<String> result = qwen2ChatClient.prompt()
.user(msg)
.stream()
.content();
return result;
}
}测试接口:http://localhost:8080/no/toolCalling/test ,询问深圳今天的天气如何。
结果:

12.2 ToolCalling 流程设计
下图是一个泳道图,用户输入提问 ------ 调用大模型 ------ 判断是否需要调用工具 ------ 通过大模型回复用户。
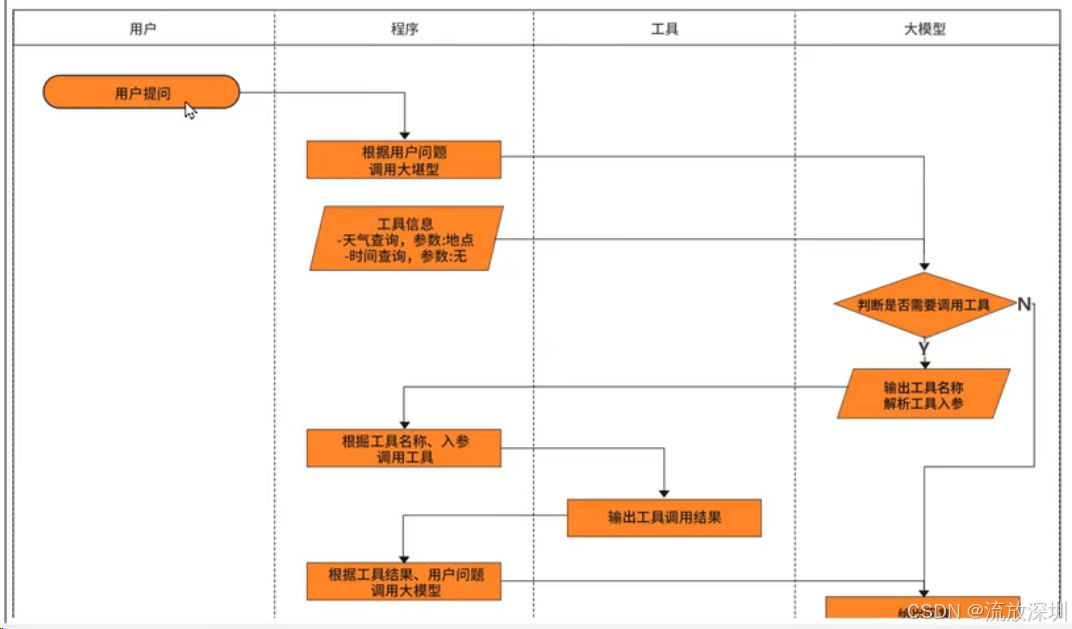
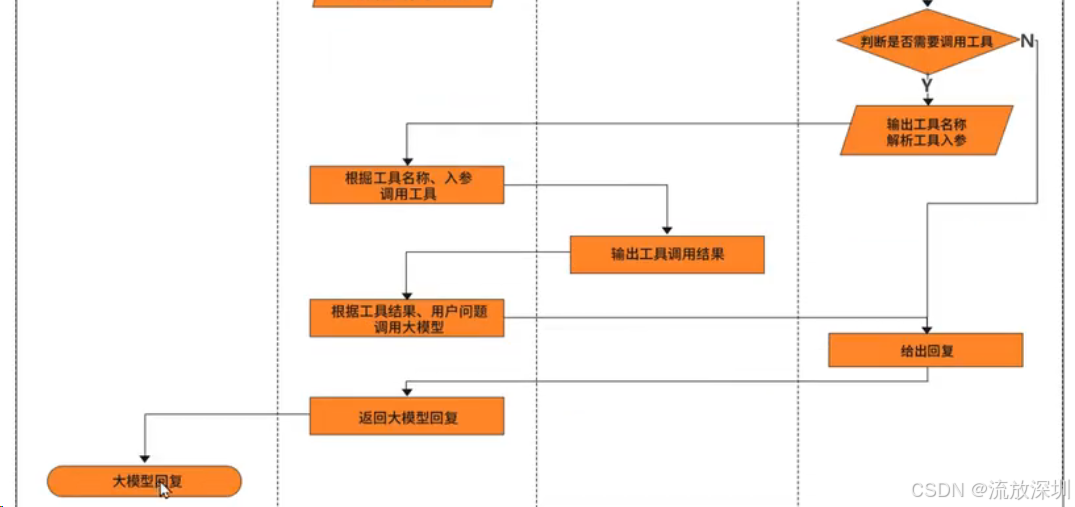
12.3 使用 ChatModel 实现 ToolCalling
新建一个获取当前时间的工具类 MyDateTimeToos,并增加注解 @Tool ,该注解有几个字段,其中最重要的是 returnDirect。表示是否需要不通过大模型就直接返回给调用者。默认为false,表示需要通过大模型进行转换。在一些场景下,需要不通过大模型转换而直接返回给调用者,比如:数据查询等。
java
package ai.study.util;
import cn.hutool.core.date.DateUtil;
import org.springframework.ai.tool.annotation.Tool;
/**
* @author CSDN流放深圳
* @description 时间工具类
* @create 2026-05-04 11:33
* @since 1.0.0
*/
public class MyDateTimeToos {
/**
* 获取当前时间
* returnDirect:表示是否需要不通过大模型就直接返回给调用者。默认为false,表示需要通过大模型进行转换。
* 在一些场景下,需要不通过大模型转换而直接返回给调用者,比如:数据查询等。
* @return
*/
@Tool(description = "获取当前时间", returnDirect = false)
public String getCurrentTime() {
return DateUtil.now();
}
}在 ToolCallingController 新增测试方法:
java
@Autowired
@Qualifier("qwen2")
private ChatModel qwen2ChatModel;
/**
* 使用ChatModel 进行 ToolCalling 测试
* @param msg
* @return
*/
@GetMapping("/chatModel/toolCalling")
public String toolCallingTest2(@RequestParam(name="msg", defaultValue = "现在是北京时间几点钟?") String msg) {
//1 工具注册到工具集合里
ToolCallback[] tools = ToolCallbacks.from(new MyDateTimeToos());
//2 将工具集配置进 ChatOptions 对象
ChatOptions options = ToolCallingChatOptions.builder()
.toolCallbacks(tools).build();
//3 构建提示词
Prompt prompt = new Prompt(msg, options);
//4 调用大模型
return qwen2ChatModel.call(prompt).getResult().getOutput().getText();
}测试接口:http://localhost:8080/chatModel/toolCalling
测试结果:
12.4 使用 ChatClient 实现 ToolCalling
在 ToolCallingController 测试类中增加 ChatClient 的测试方法,代码如下:
java
/**
* 使用ChatModel 进行 ToolCalling 测试
* @param msg
* @return
*/
@GetMapping("/chatClient/toolCalling")
public Flux<String> toolCallingTest3(@RequestParam(name="msg", defaultValue = "现在是北京时间几点钟?") String msg) {
return qwen2ChatClient
.prompt(msg)
.tools(new MyDateTimeToos())
.stream()
.content();
}测试接口:http://localhost:8080/chatClient/toolCalling
测试结果:

13、MCP
13.1 MCP 概念
模型上下文协议(Model Context Protocol,MCP) 是一种标准化协议,它使人工智能(AI)模型能够以结构化 的方式与外部工具和资源进行交互。你可以将其视为AI模型与现实世界之间的桥梁,通过一致的接口让模型能够访问数据库、应用程序编程接口(API)、文件系统和其他外部服务。该协议支持多种传输机制,以在不同环境中提供灵活性。
MCP Java SDK提供了模型上下文协议的Java实现,通过同步 和异步通信模式,实现了与AI模型和工具的标准化交互。(类似于微服务的 openFeign 微服务之间的接口调用。)
官网学习地址:https://docs.spring.io/spring-ai/reference/api/mcp/mcp-overview.html
MCP服务官网:https://mcp.so/zh
MCP 架构分为客户端和服务器(C/S架构),主要分为以下核心部分:1、MCP主机(MCP Hosts):发起请求的 AI 应用程序,比如聊天机器人、AI 驱动的 IDE 等。
2、MCP客户端(MCP Clients):在主机程序内部,与 MCP 服务器保持 1:1 的连接。
3、MCP服务器(MCP Servers):为 MCP 客户端提供上下文、工具和提示信息。
4、本地资源(Local Resources):本地计算机中可供 MCP 服务器安全访问的资源,比如文件、数据库等。
5、远程资源(Remote Resources):MCP 服务器可以连接到的远程资源,比如通过 API 提供的数据。
13.2 MCP 支持的传输协议(SSE 和 STDIO)
MCP 支持2种传输协议:SSE 和 STDIO。
SSE(Server-Sent Events):支持使用 HTTP POST,请求进行服务器到客户端流式处理,以实现客户端到服务端的通信。
STDIO(标准输入/输出):支持标准输入和输出流进行通信,主要用于本地集成、命令行工具等场景。
两者协议的对比:
|------|----------------------------|--------------------|
| 特性 | SSE | STDIO |
| 传输协议 | HTTP 长连接 | 操作系统级文件描述符 |
| 方向 | 服务器 ---> 客户端(单向推送) | 双向流(stdin、stdout) |
| 保持连接 | 长连接(Connection:keep-alive) | 不保证长时间打开,取决于进程生命周期 |
| 数据格式 | 文本流(EventStream格式) | 原始字节流 |
| 异常处理 | 可通过 HTTP 状态码或重连机制 | 进程退出或管道断裂 |
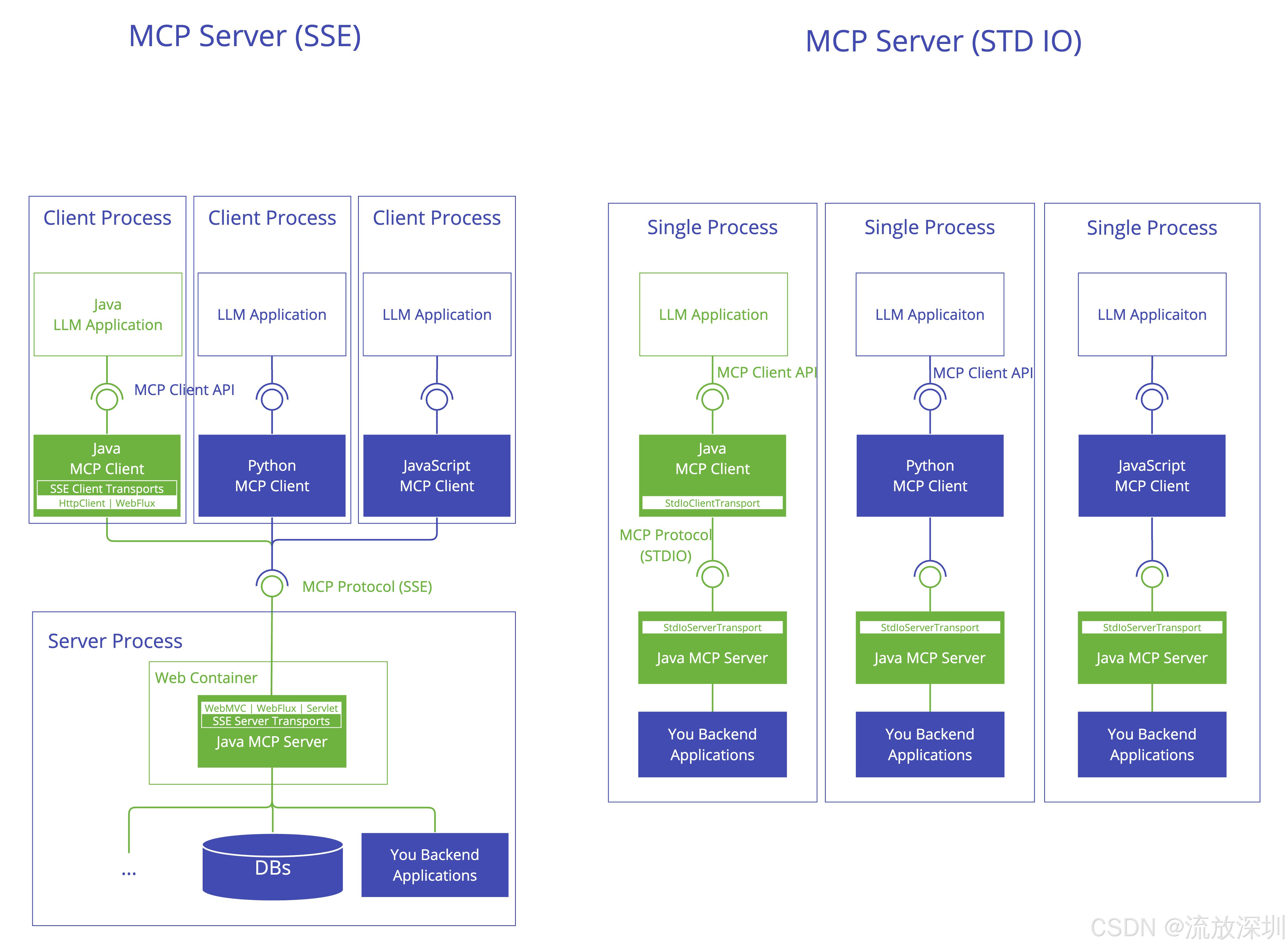
13.3 MCP 与 ToolCalling 的对比
ToolCalling:每个大模型需要为每个工具单独开发接口(FunctionCalling),导致重复造轮子。
MCP通过统一协议,让开发者只需写一次 MCP 服务端,所有兼容 MCP 协议的模型都能调用,MCP 让大模型从"被动应答"变为"主动调用工具"。
13.4 本地 MCP 服务端搭建
首先需要说明一点:我们之前的项目工程在创建 SpringBoot 项目时,在 pom.xml 引入的是
spring-boot-starter-web,如图:

SpringBoot 默认使用的是 Tomcat 服务器,通过查看源码可知,如图:
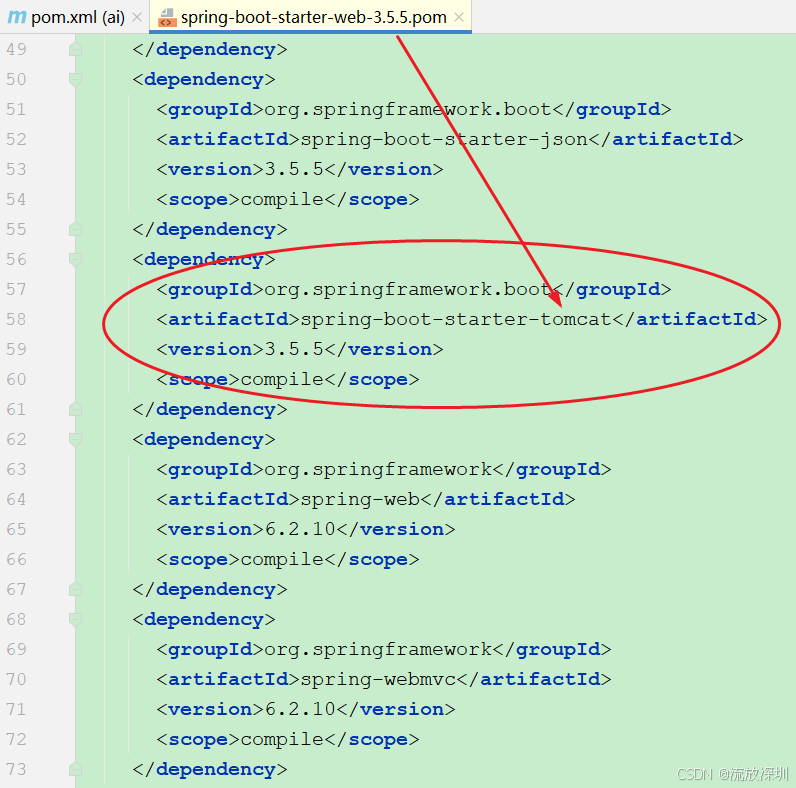
我们将要搭建的 MCP 服务端,使用的不是 Tomcat 服务器,而是可处理高并发的 Netty 服务器,而 MCP 服务器依赖的是 Netty 服务器。如果引入 spring-boot-starter-web 会产生冲突问题,因此我们引入的是 spring-boot-starter(没有 web)。
13.4.1 重新创建一个项目用于搭建 mcp 服务
新建项目:
13.4.2 pom 添加 mcp server 依赖
pom.xml 配置如下:
html
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.study</groupId>
<artifactId>mcpServer</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
</properties>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.5</version>
</parent>
<dependencies>
<!--
注意事项:spring-ai-starter-mcp-server-webflux 不能和 spring-boot-starter-web 依赖并存,否则会默认启动 Tomcat 服务器而不是 Netty 服务器,
从而导致 mcpServer 启动失败,但是程序运行是正常的,mcp客户端连接不上。
-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!-- mcp Server 依赖 https://mvnrepository.com/artifact/org.springframework.ai/spring-ai-starter-mcp-server-webflux -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webflux</artifactId>
<version>1.1.5</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
</dependency>
</dependencies>
</project>13.4.3 yml 配置
application.yml:
XML
server:
# 服务器端口号
port: 8888
servlet:
encoding:
# 设置编码格式
charset: utf-8
enabled: true
# 强制请求和响应
force: true
# mcp-Server config
spring:
ai:
mcp:
server:
name: my-mcp-server
version: 1.0.0
type: async13.4.4 创建服务类
模拟一个根据岗位查询工资的类 JobSalaryService:
java
package com.study.service;
import org.springframework.ai.tool.annotation.Tool;
import org.springframework.stereotype.Service;
import java.util.Map;
/**
* @author CSDN流放深圳
* @description 模拟一个职位对应的薪资服务类
* @create 2026-05-07 10:07
* @since 1.0.0
*/
@Service
public class JobSalaryService {
@Tool(description = "根据职位查询工资")
public String getSalary(String job) {
System.out.println("job=" + job);
Map<String, String> map = Map.of(
"CTO", "月薪100K+",
"架构师", "月薪80K+",
"总监", "月薪50K+",
"开发组长", "月薪30K+",
"程序员", "月薪20K+"
);
return map.getOrDefault(job, "sorry:未查询到对应的职位工资!");
}
}13.4.5 将服务接口暴露给外部 mcp client 调用
创建一个 McpServer 配置类 McpServerConfig:
java
package com.study.config;
import com.study.service.JobSalaryService;
import org.springframework.ai.tool.ToolCallbackProvider;
import org.springframework.ai.tool.method.MethodToolCallbackProvider;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author CSDN流放深圳
* @description McpServer 配置类
* @create 2026-05-07 10:28
* @since 1.0.0
*/
@Configuration
public class McpServerConfig {
/**
* 将工具方法暴露给外部 client 调用
* @param jobSalaryService
* @return
*/
@Bean //需要在方法上加上 @Bean 注解,Server 就能正确注册工具,Client 就能发现并使用了。这是一个很容易遗漏的小细节。
public ToolCallbackProvider jobSalaryTools(JobSalaryService jobSalaryService) {
return MethodToolCallbackProvider.builder()
.toolObjects(jobSalaryService)
.build();
}
}13.4.6 启动 mcp 服务
可以看到服务启动的是 Netty 服务器,端口号是我们设置的 8888:
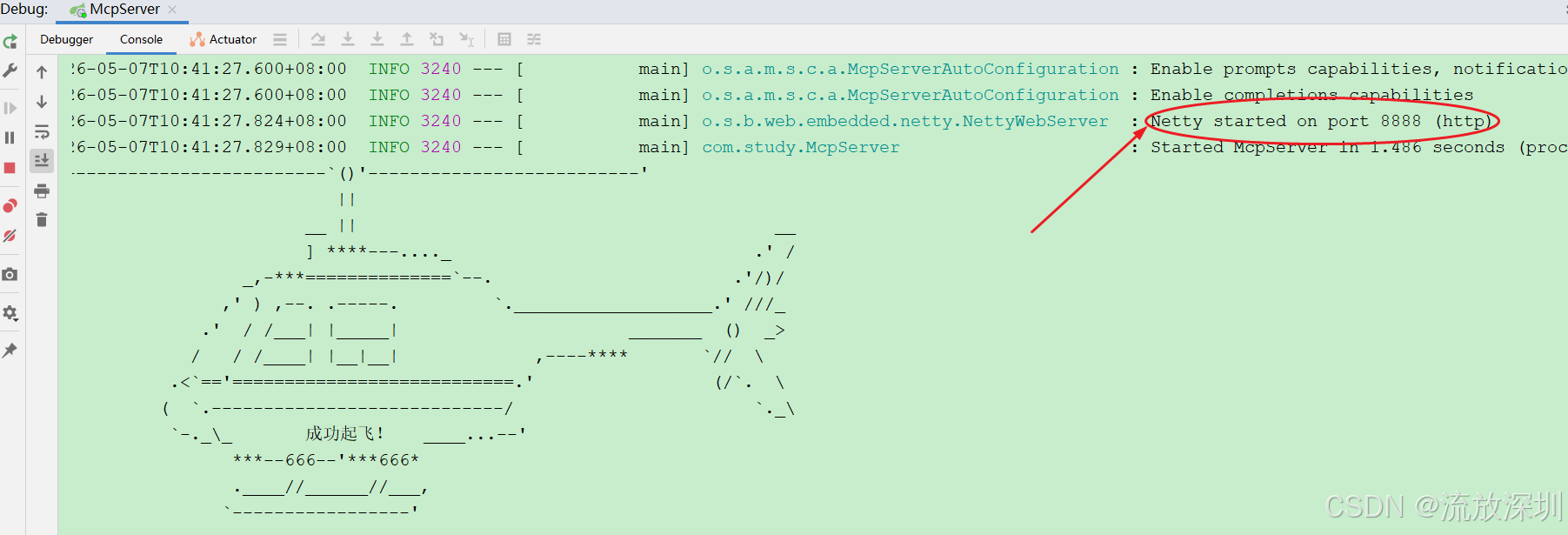
浏览器地址访问:http://127.0.0.1:8888/sse

出现以上数据即为启动成功。
13.5 本地服务端实现
在原来的 ai 项目中开发代码作为 mcp client 实现。
13.5.1 pom.xml 添加 mcp client 依赖
html
<!-- mcp Client 异步模式必须使用这个依赖:https://mvnrepository.com/artifact/org.springframework.ai/spring-ai-starter-mcp-client-webflux -->
<!-- ❌ 如果用的是这个同步版,异步模式不会生效 spring-ai-starter-mcp-client -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client-webflux</artifactId>
<version>1.1.5</version>
<scope>compile</scope>
</dependency>13.5.2 yml 配置
application.yml 增加 mcp-client 节点配置信息:
html
spring:
ai:
mcp:
client:
# 异步模式
type: async
name: my-mcp-client
# 请求超时时间
request-timeout: 20s
# 开启工具回调
toolcallback:
enabled: true
# SSE 传输协议,注意与 toolcallback 平级
sse:
connections:
# mcp-server1 的 url 地址,有多个服务器,可以配置多个 mcp-server2 以此类推
mcp-server1:
url: http://127.0.0.1:888813.5.3 配置 ChatClient 增加 mcp-client 支持
修改 ChatClientConfig 类中关于 qwen3ChatClient 的配置,增加 ToolCallbackProvider 参数作为 defaultToolCallbacks的初始化参数:
java
/**
* 创建 qwen3ChatClient
* @param chatModel
* @param toolsCallback 工具调用回调
* @return
*/
@Bean(name = "qwen3ChatClient")
public ChatClient qwen3ChatClient(@Qualifier("qwen3")ChatModel chatModel, ToolCallbackProvider toolsCallback) {
return ChatClient.builder(chatModel)
.defaultToolCallbacks(toolsCallback.getToolCallbacks()) //mcp协议,配置信息见 yml 文件
.build();
}13.5.4 启动检查代码
启动检查代码,发现服务端是否有可用的工具 Tools。创建类:McpToolChecker
java
package ai.study.config;
import jakarta.annotation.PostConstruct;
import org.springframework.ai.tool.ToolCallbackProvider;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
/**
* @author CSDN 流放深圳
* @description 启动检查代码,发现服务端是否有可用的工具 Tools
* @create 2026-05-07 15:22
* @since 1.0.0
*/
@Component
public class McpToolChecker {
@Autowired
private ToolCallbackProvider toolCallbackProvider;
@PostConstruct
public void checkTools() {
var tools = toolCallbackProvider.getToolCallbacks();
System.out.println("=== MCP 工具发现结果 ===");
System.out.println("工具数量: " + tools.length);
for (var tool : tools) {
System.out.println(" - " + tool.getToolDefinition().name());
System.out.println(" 描述: " + tool.getToolDefinition().description());
}
System.out.println("======================");
}
}13.5.5 创建 Controller 测试类
新增 McpController 测试类,引入 qwen2ChatClient(未使用 mcp)和 qwen3ChatClient(使用了 mcp):
java
package ai.study.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
/**
* @author CSDN流放深圳
* @description mcp测试类
* @create 2026-05-07 11:33
* @since 1.0.0
*/
@RestController
public class McpController {
@Autowired
@Qualifier("qwen2ChatClient")
private ChatClient qwen2ChatClient;
@Autowired
@Qualifier("qwen3ChatClient")
private ChatClient qwen3ChatClient;
/**
* 未使用 mcp 测试类
* @param msg
* @return
*/
@GetMapping("/mcp/no/test")
public Flux<String> noMcp(@RequestParam(value = "msg", defaultValue = "架构师") String msg) {
System.out.println("未使用 mcp 测试接口");
return qwen2ChatClient.prompt(msg).stream().content();
}
/**
* 使用 mcp 测试类
* @param msg
* @return
*/
@GetMapping("/mcp/use/test")
public Flux<String> useMcp(@RequestParam(value = "msg", defaultValue = "程序员") String msg) {
System.out.println("使用了 mcp 测试接口");
return qwen3ChatClient.prompt(msg).stream().content();
}
}启动服务,可以查看控制台客户端是否连接上了服务端,并且客户端发现服务端有可用的工具:

测试接口1:http://localhost:8080/mcp/no/test?msg=架构师
测试结果1(只是单纯介绍架构师的内容,没有提及工资):
测试接口2:http://localhost:8080/mcp/use/test?msg=程序员
测试结果2(使用到了 MCP 服务):
测试接口3:http://localhost:8080/mcp/use/test?msg=测试人员
测试结果3:

13.6 远程 MCP 增强(百度地图)
MCP 服务地址:https://mcp.so/zh 截止当前(2026年5月7日)收录了 20717 个 MCP 服务器。
我们这次学习以"百度地图"为案例,地址:https://mcp.so/zh/server/baidu-map/baidu-maps
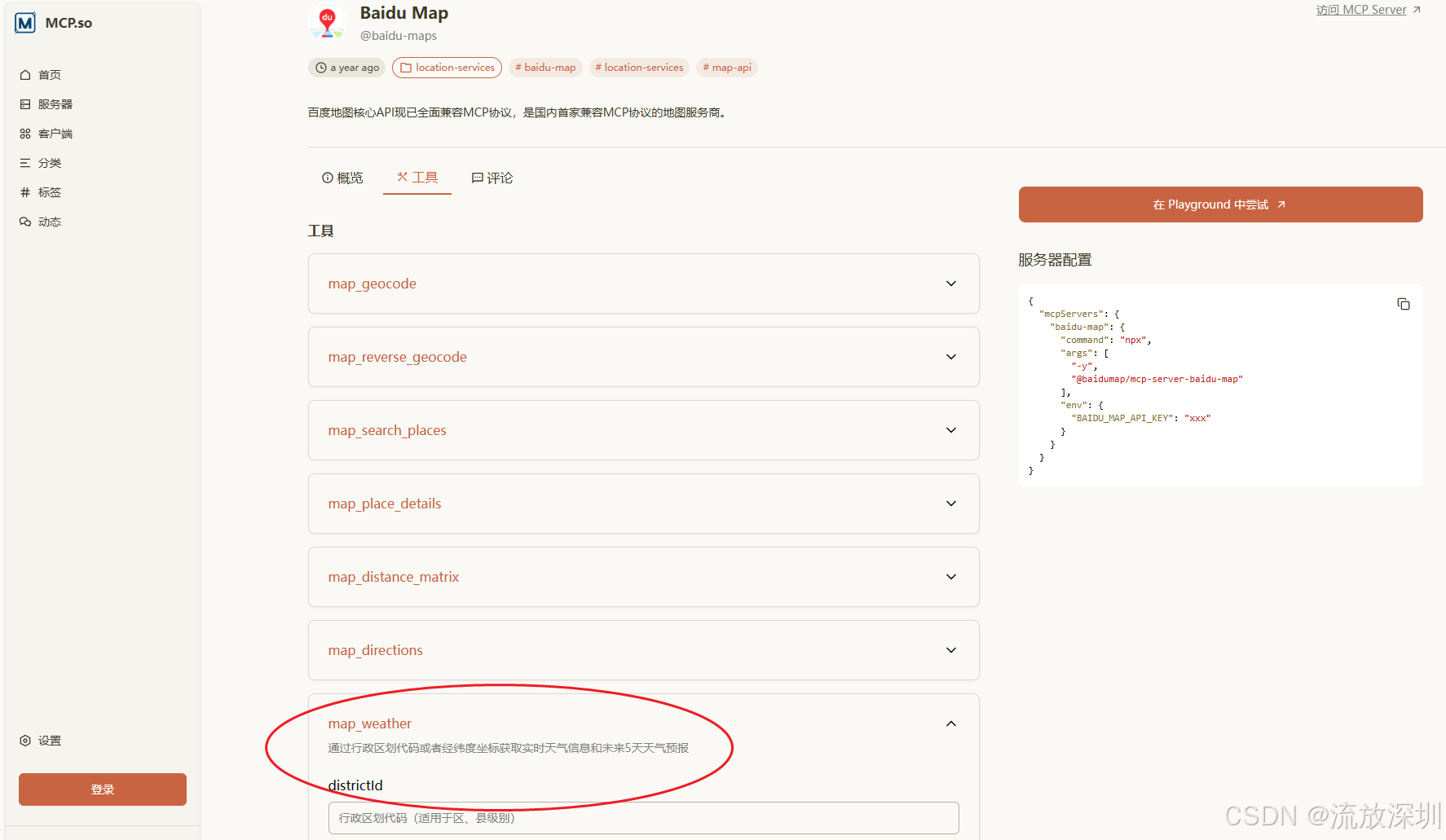
百度地图甚至还集成了查询天气的功能。
13.6.1 注册成为百度地图开发者,获取Key
百度地图开放平台地址:https://lbs.baidu.com/
点击"控制台"或者"成为开发者":
输入必要的注册信息:
人脸识别:
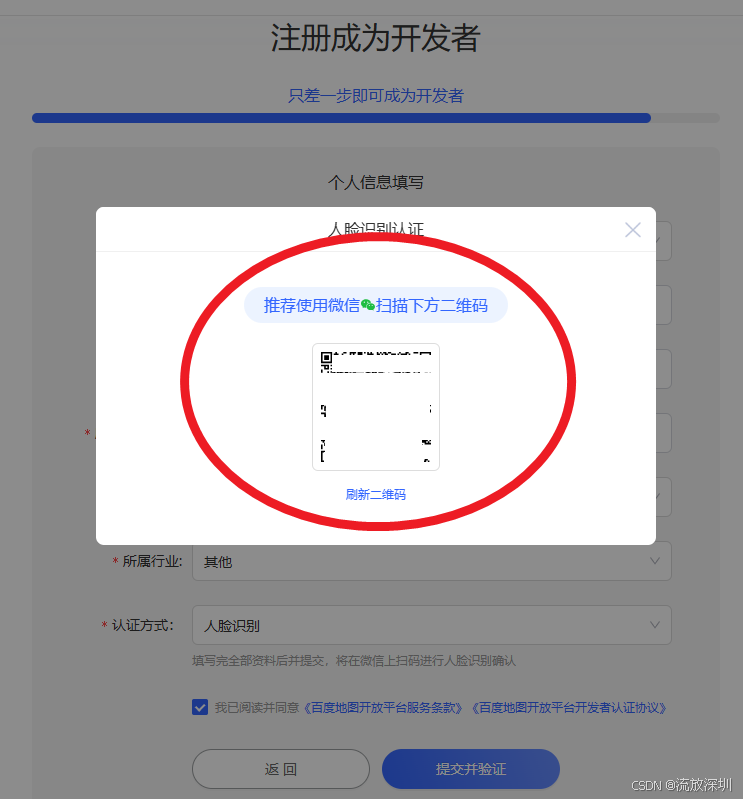
个人开发者每日限额调用次数 5 千次,每秒并发3次调用,够用了。
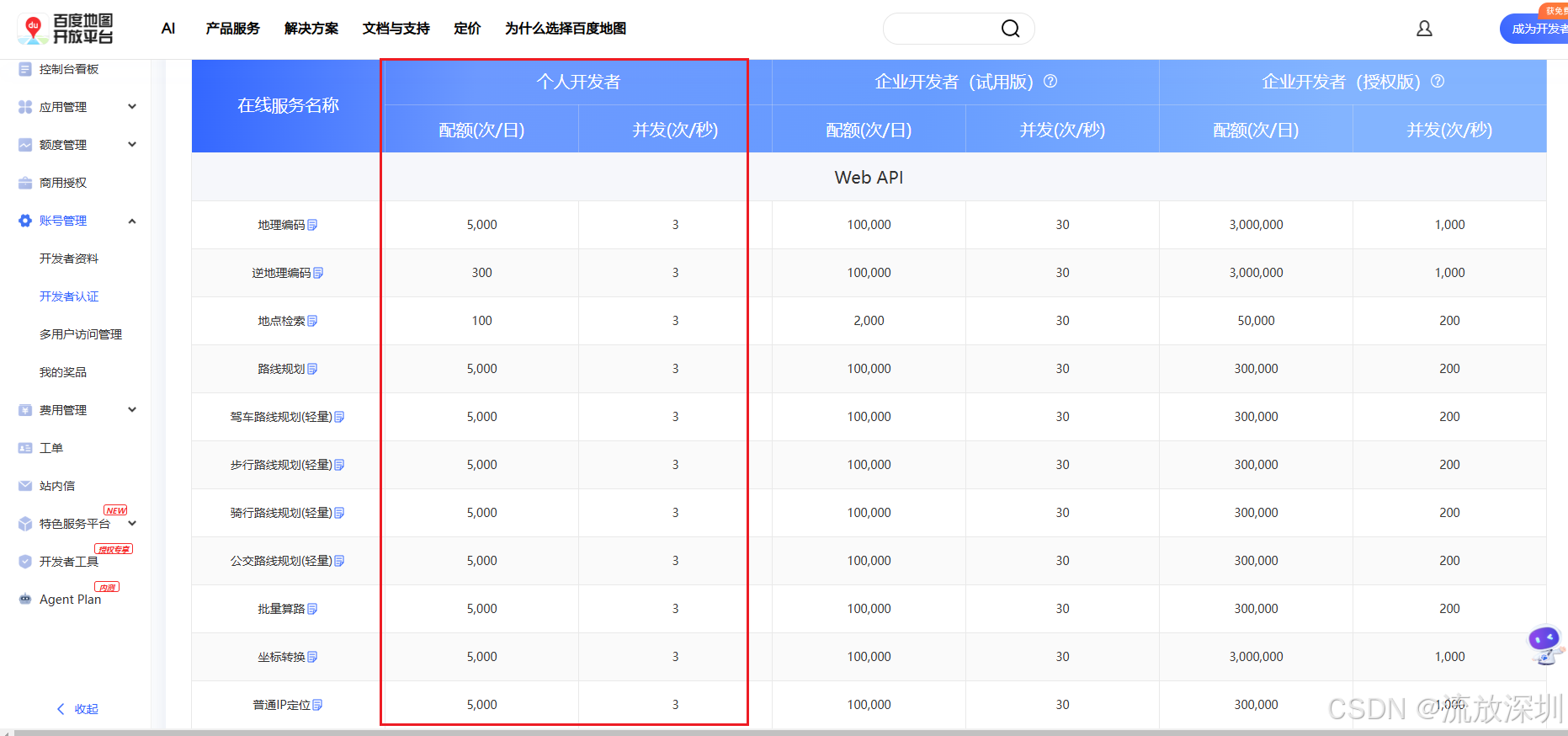
在【应用管理】-【我的应用】下面【创建应用】,IP白名单输入【0.0.0.0/0】:
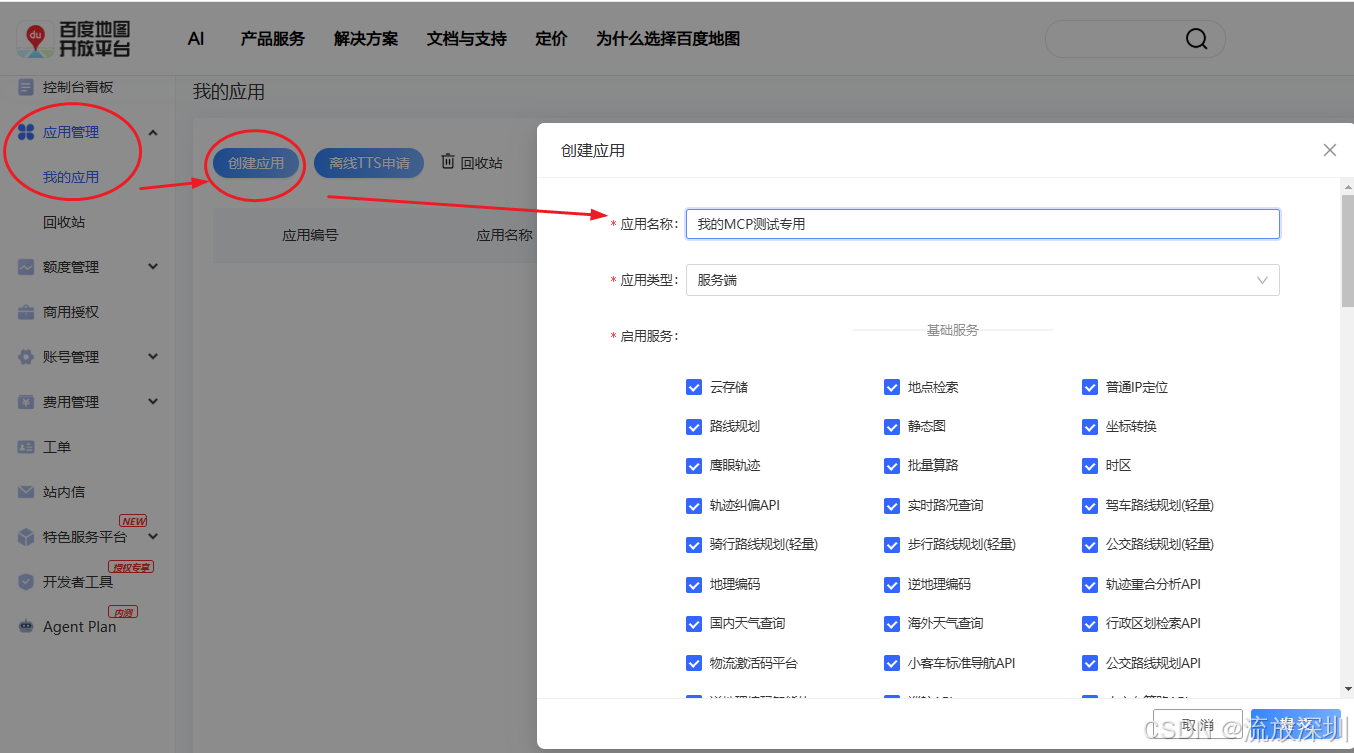
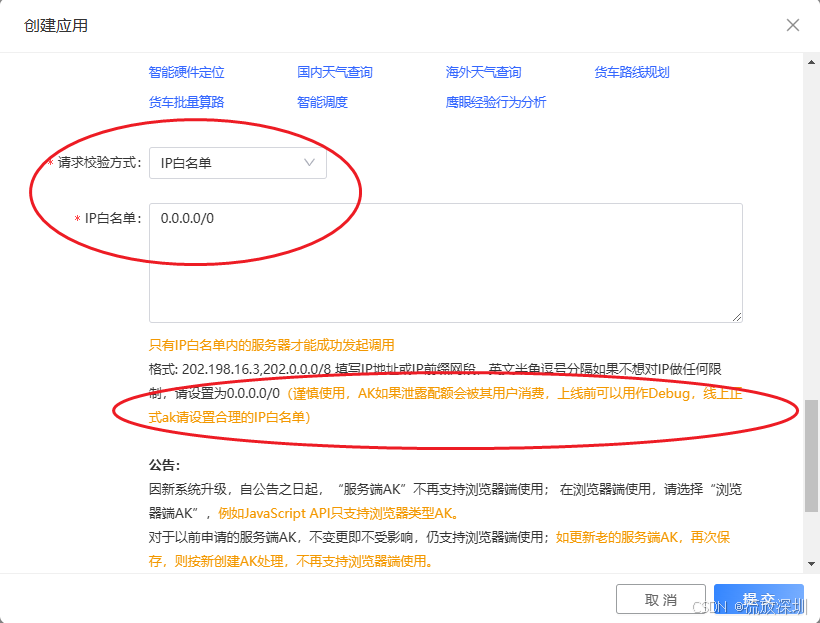
点击提交后,得到访问应用的 key(AK):
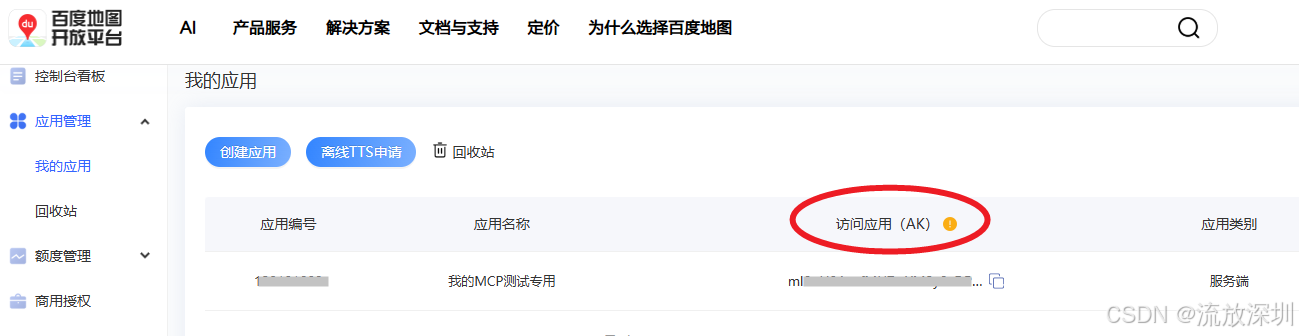
13.6.2 安装 Node.js 或者 Python 环境
原理说明:百度地图相当于 MCP 服务提供商,我们的 MPC-Client 端调用本地 MCP-Server,然后 MCP-Server 再与远程的 MCP 服务提供商保持通讯。原理图:
查看GitHub官网地址有说明:https://github.com/baidu-maps/mcp
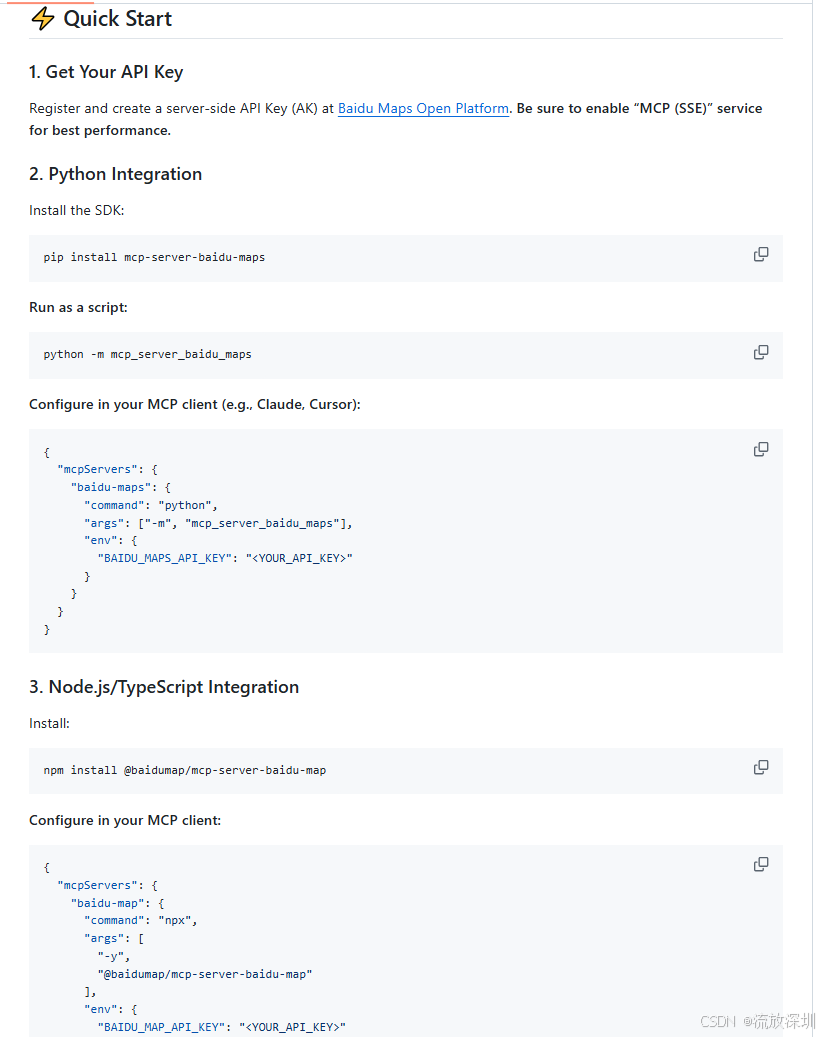
安装 Node.js 可以查看博客(第7小节):https://blog.csdn.net/BiandanLoveyou/article/details/137361246
13.6.3 在 Node.js 安装 mcp-server-baidu-map
在 cmd 命令行输入以下命令,安装 mcp-server-baidu-map
npm install @baidumap/mcp-server-baidu-map
安装结果:
说明:通过 npm install 安装后,这个包并不能独立"启动"成一个后台服务。它的工作方式是:当你配置的 AI 客户端(如 Cursor、Claude Desktop)启动时,客户端会通过 npx 命令来调用它。因此可以看到官网提供的命令行有这么一句话:command:npx
13.6.4 修改 yml 中 client 的配置
调用远程的 MCP 服务使用的是标准的协议即 stdio,因此需要注释掉之前的 sse 协议,增加 stdio 协议。修改后的 yml 配置如下:
html
spring:
ai:
mcp:
client:
# 异步模式
type: async
name: my-mcp-client
# 请求超时时间
request-timeout: 20s
# 开启工具回调
toolcallback:
enabled: true
# SSE 传输协议,注意与 toolcallback 平级
#sse:
#connections:
## mcp-server1 的 url 地址,有多个服务器,可以配置多个 mcp-server2 以此类推
#mcp-server1:
#url: http://127.0.0.1:8888
# 标准输入输出
stdio:
servers-configuration: classpath:/mcp-server.json5配置文件取名为 mcp-server.json5,需要在 resources 目录下创建该文件(如果某些编辑器不支持 json5 启动报错,则要回退到 json 格式文件,即不能有注释)。
拓展知识:
JSON5 是一种 JSON 的扩展格式,它让 JSON 文件更易于人类编写和维护。
JSON5 在标准 JSON 基础上增加了以下功能:
允许注释。
{
// 这是单行注释
"name": "百度地图",
/* 这也是
多行注释 */
"version": "1.0.0"
}键名可以不加引号
{
name: "张三", // 合法
age: 25, // 合法
"key-with-dash": true // 特殊情况仍需引号
}允许尾随逗号
{
"city": "北京",
"district": "海淀", // 末尾逗号完全合法
}支持更多数据类型
{
"十六进制": 0xFF, // 十六进制
"无穷大": Infinity, // Infinity
"NaN值": NaN, // NaN
"单引号字符串": 'hello', // 单引号
}
mcp-server.json5 内容如下(需要把你申请到的百度Key替换):
html
{
"mcpServers": {
"baidu-map": {
"command": "cmd",
"args": [
"/c",
"npx",
"-y",
"@baidumap/mcp-server-baidu-map"
],
"env": {
"BAIDU_MAP_API_KEY": "<需要把你申请到的百度Key替换>"
}
}
}
}
/*
说明:
1. mcp-server.json5 文件是 mcp-server 配置文件,用于配置 mcp-server 的运行环境。
2. mcp-server.json5 文件的格式为 JSON5,可以参考 https://github.com/json5/json5
3. mcp-server.json5 文件中的 mcpServers 属性是一个对象,对象中的 key 是 mcp-server 的名称,value 是 mcp-server 的配置。
4. cmd 是启动 Windows 命令行解释器
5、args 是启动命令行解释器的参数。/c:告诉 cmd 执行完后面的命令后关闭自身。-y: 自动确认操作(默认接受所有提示)。npx:要通过 npx 执行的 npm 包名(本次配置的是百度地图包)
6、env 是启动命令行解释器的环境变量。BAIDU_MAP_API_KEY 是访问百度开放平台 API 的密钥。
*/13.6.5 创建测试类
创建测试类 BaiduMapController:
java
package ai.study.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
/**
* @author CSDN流放深圳
* @description 百度地图测试类
* @create 2026-05-08 11:33
* @since 1.0.0
*/
@RestController
public class BaiduMapController {
@Autowired
@Qualifier("qwen2ChatClient")
private ChatClient qwen2ChatClient;
@Autowired
@Qualifier("qwen3ChatClient")
private ChatClient qwen3ChatClient;
/**
* 调用百度地图测试类
* @param msg
* @return
*/
@GetMapping("/baidumap")
public Flux<String> baidumap(@RequestParam(value = "msg", defaultValue = "查询深圳未来3天的天气情况") String msg) {
return qwen3ChatClient.prompt(msg).stream().content();
}
/**
* 没有调用百度地图 MCP 服务的测试类
* @param msg
* @return
*/
@GetMapping("/no/mcp-server/test")
public Flux<String> noMcpServer(@RequestParam(value = "msg", defaultValue = "深圳") String msg) {
return qwen2ChatClient.prompt(msg).stream().content();
}
}注意:我们之前 qwen3ChatClient 的初始化是有设置 defaultToolCallbacks 的,因此本次测试继续沿用 qwen3ChatClient。
java/** * 创建 qwen3ChatClient * @param chatModel * @param toolsCallback 工具调用回调 * @return */ @Bean(name = "qwen3ChatClient") public ChatClient qwen3ChatClient(@Qualifier("qwen3")ChatModel chatModel, ToolCallbackProvider toolsCallback) { return ChatClient.builder(chatModel) .defaultToolCallbacks(toolsCallback.getToolCallbacks()) //mcp协议,配置信息见 yml 文件 .build(); }我们在 13.5.4 章节新增的发现服务端是否有可用的工具类:McpToolChecker,在启动时可以检查百度地图 MCP-Server 有什么可用的工具。
html=== MCP 工具发现结果 === 工具数量: 10 - map_geocode 描述: 地理编码服务 - map_reverse_geocode 描述: 全球逆地理编码 - map_search_places 描述: 地点检索服务(包括城市检索、圆形区域检索、多边形区域检索) - map_place_details 描述: 地点详情检索服务 - map_distance_matrix 描述: 计算多个出发地和目的地的距离和路线用时 - map_directions 描述: 路线规划服务, 计算出发地到目的地的距离、路线用时、路线方案 - map_weather 描述: 通过行政区划代码或者经纬度坐标获取实时天气信息和未来5天天气预报 - map_ip_location 描述: 通过IP地址获取位置信息 - map_road_traffic 描述: 根据城市和道路名称查询具体道路的实时拥堵评价和拥堵路段、拥堵距离、拥堵趋势等信息 - map_poi_extract 描述: POI智能标注 ======================

我们暂时测试以下 3 种功能:
1、路线规划服务, 计算出发地到目的地的距离、路线用时、路线方案
测试接口:http://localhost:8080/baidumap?msg=帮我规划从深圳到广州的路线
测试结果:
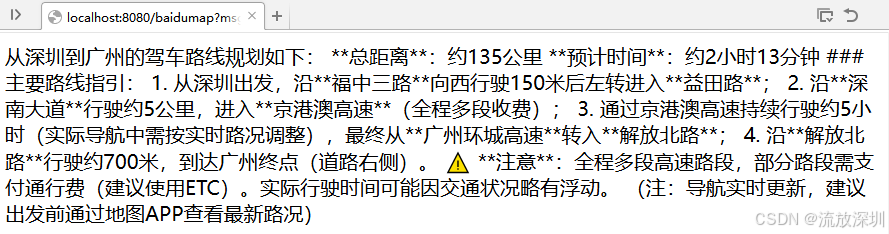
2、通过行政区划代码或者经纬度坐标获取实时天气信息和未来5天天气预报
测试接口:http://localhost:8080/baidumap?msg=帮我查询深圳未来3天的天气情况
测试结果:
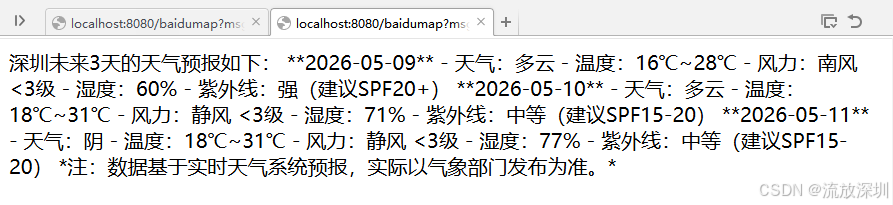
3、根据城市和道路名称查询具体道路的实时拥堵评价和拥堵路段、拥堵距离、拥堵趋势等信息
测试接口:http://localhost:8080/baidumap?msg=帮我查询深南大道最近1小时的车流量情况
测试结果:

4、测试没有使用百度 MCP 服务
测试接口:http://localhost:8080/no/mcp-server/test?msg=查询深圳明天的天气情况
测试结果(没有使用百度 MCP 服务并不能正确查询天气情况):
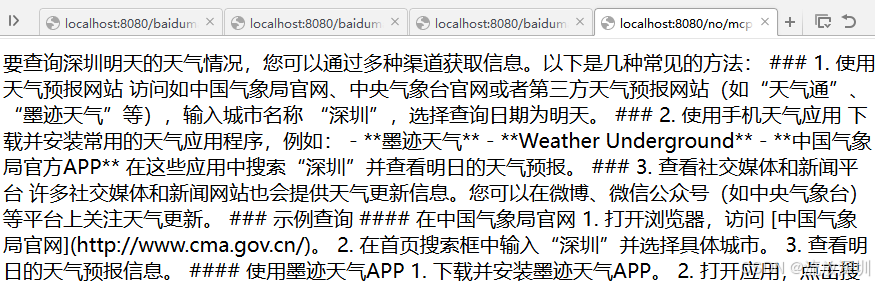
13.6.6 百度地图 MCP 原理浅谈
1、首先我们执行下载命令,表示把百度地图包下载到本地:
npm install -g @baidumap/mcp-server-baidu-map
2、那么百度地图包安装到了哪里?
一般放在:C:\Users\你的用户名\node_modules 目录下:
我们打开 @baidumap\mcp-server-baidu-map\dist 的 index.js 文件

有前端 js 基础的可以看到百度地图的 js 是如何调用百度服务的:
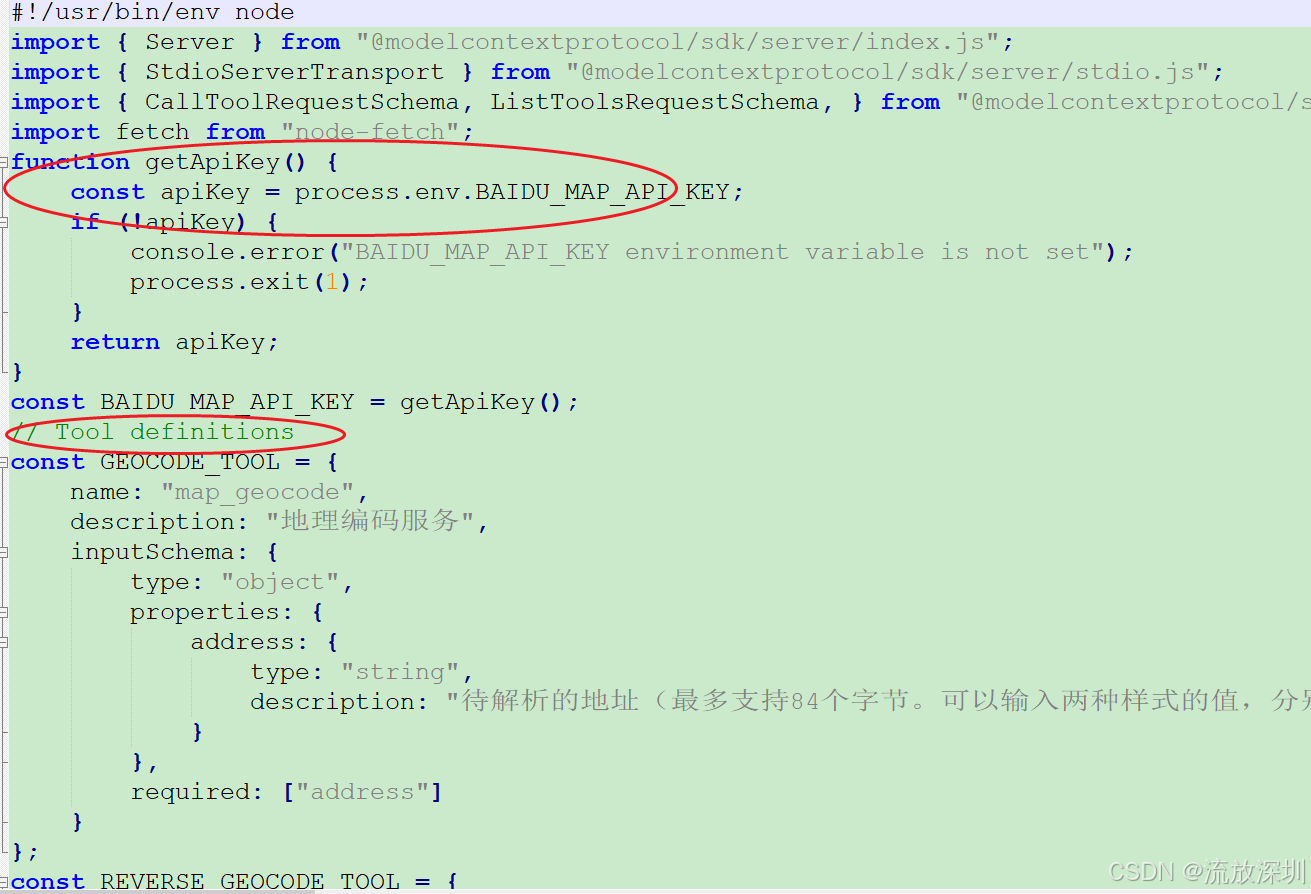
回到最初的那个图,我们本地 MCP-Client 和 Nodejs 服务,形成内部的整体服务,然后通过标准协议 Stdio 去调用百度 MCP 服务,获得具体的数据。
14、文章总结
通过本篇博客的学习,能掌握 SpringAI 对接大模型的基本知识和核心 API 。后续还将持续输出更多关于人工智能学习的博客。本篇博客8万2千多字,跟着B站尚硅谷从0开始学习:https://www.bilibili.com/video/BV1pvWGznEqh/
前后花费了近半个月,利用零碎时间边学边记录问题边写技术博客。在这个过程当中自己也得到了很多提升。CSDN 还搞了很多模式,比如:关注博主后才能继续阅读,或者付费后才能继续阅读专栏等等。我觉得在这个知识开放的时代,从各个渠道都可以获取到只是,搞付费模式除了科学研究或者技术原创,其它真没必要,也赚不到几个钱。只有我为人人、人人为我,才能惠及更多喜欢学习的人。
好了,敬请期待更多技术博客分享。