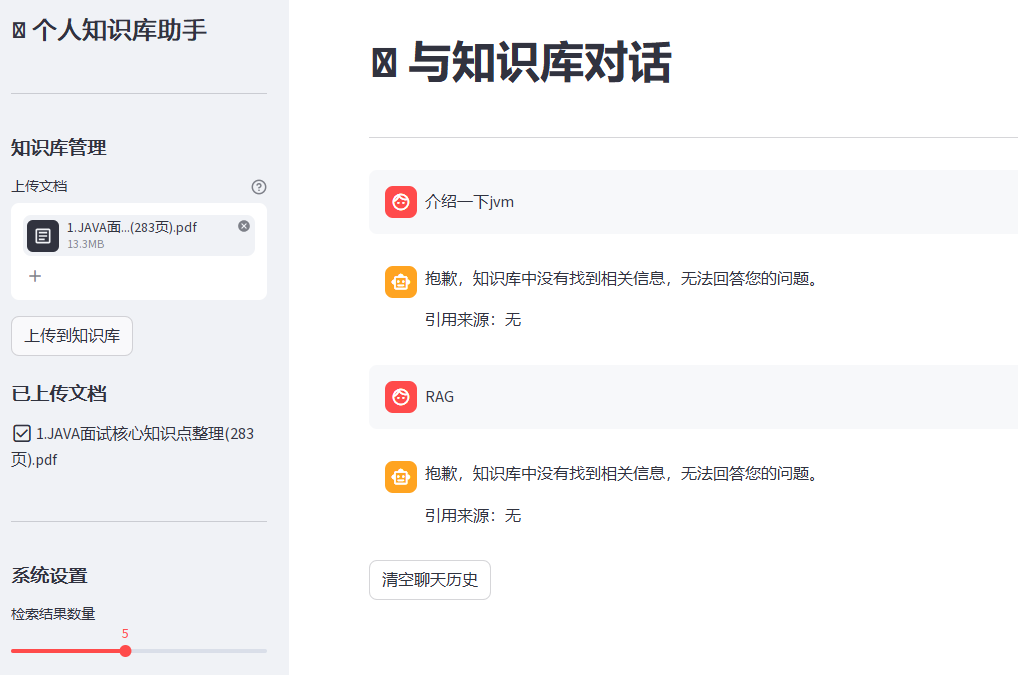
第一步:先确认问题出在哪一层
问题大概率出在 **「文档分块」或「向量库入库」** 环节。
1. 先检查分块文件 processed_chunks.jsonl
打开这个文件,看看里面有没有数据:
- 有没有 JSON 格式的分块
- 每个分块的
text字段里,有没有 "JVM"、"RAG" 相关的内容 - 分块数量是不是和你上传的 PDF 页数对应

上传的新文档 → 只在内存里生效 → 没有写入到本地文件 processed_chunks.jsonl
找到 add_documents 方法:
python
def add_documents(self, new_chunks):
"""向混合检索器中添加新文档分块"""
# 1. 添加到内存
self.chunks.extend(new_chunks)
with open("processed_chunks.jsonl", "a", encoding="utf-8") as f:
for chunk in new_chunks:
f.write(json.dumps(chunk, ensure_ascii=False) + "\n")
# 2. 添加到向量库
documents = [chunk["text"] for chunk in new_chunks]
metadatas = [chunk["metadata"] for chunk in new_chunks]
ids = [chunk["id"] for chunk in new_chunks]
self.collection.add(
documents=documents,
metadatas=metadatas,
ids=ids
)
# 3. 重建BM25(现在有这个方法了)
self.build_bm25_index()
print(f"✅ 成功添加 {len(new_chunks)} 个文档分块")重启后端,重新上传文档,可以看到 processed_chunks.jsonl文档有更新

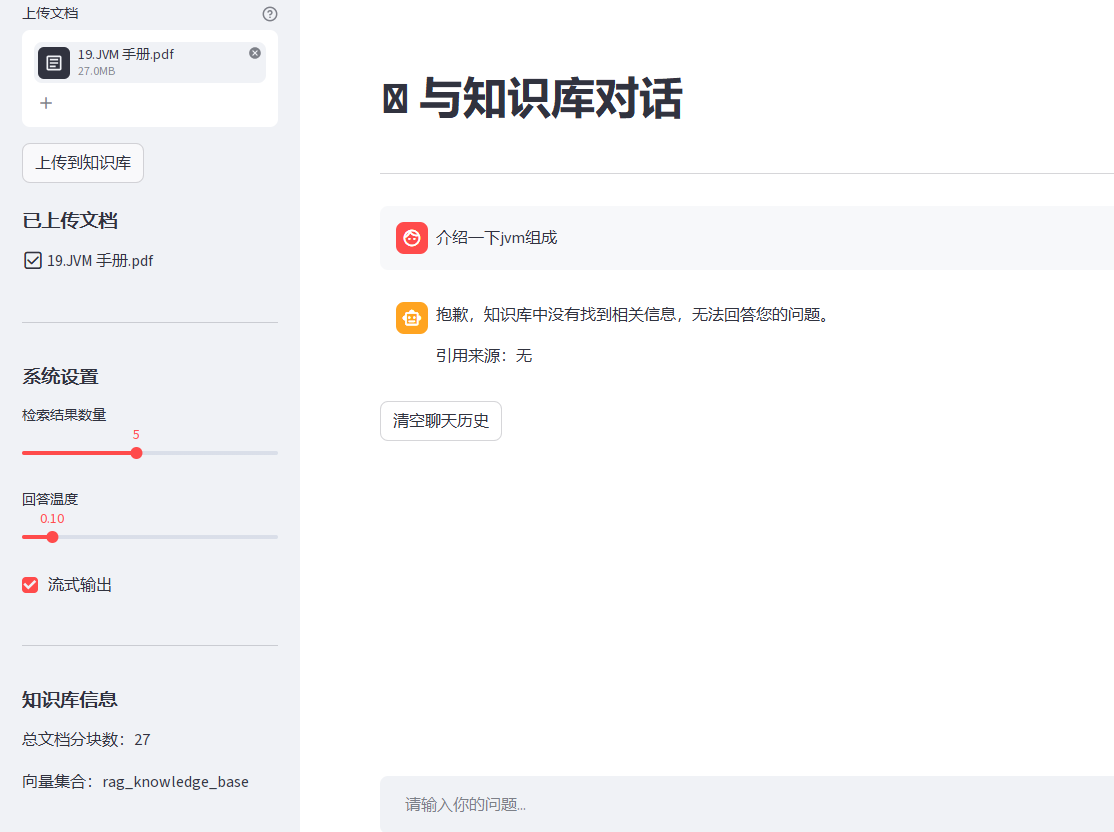
上传文档时后端打印日志,报错信息如下:
问题分析
- 写入问题已解决 :
processed_chunks.jsonl里已经有了19.JVM 手册.pdf的分块数据,说明上传功能已经正常工作。 - 新问题:PDF 解析器报错 :
MuPDF error说明你当前使用的 PDF 解析库损坏或版本不兼容,导致部分 PDF 解析失败,文本乱码(看你截图里的text字段,有大量重复的JVMJVMJava,这就是解析失败的乱码)。 - 检索不到的原因:因为解析出来的文本是乱码,向量模型无法匹配你的查询,所以一直返回 "没有找到相关信息"。
首先,替换别的文档试试。

解决。
第二步:分块文档中存在,但是仍然查不到

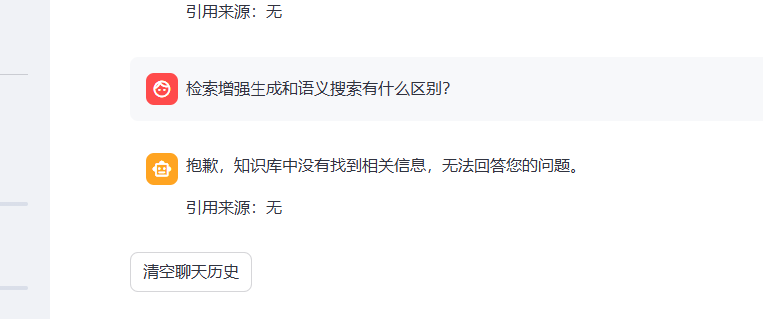
问题出在混合检索的得分过滤 :hybrid_search函数中,对语义检索和 BM25 的得分进行了加权融合,但如果:
- 语义相似度得分太低(比如低于 0.5)
- BM25 的得分也不高
- 融合后的结果被过滤掉了
就会出现 "明明有文本,但检索结果为空" 的情况
步骤 1:降低检索过滤门槛,强制返回所有 Top-K 结果
打开 rag_core.py,找到调用hybrid_search的地方,改成只用语义检索,并取消过滤:
python
def query(self, question, top_k=5, stream=False, max_context_tokens=12000):
processed_question = self._preprocess_query(question)
if not processed_question:
return "请输入有效的问题。"
# 关键:改成只用语义检索,并且强制返回所有结果,不做过滤
retrieved_docs = self.retriever.semantic_search(
query=processed_question,
top_k=top_k
)
# 强制打印检索结果,方便调试
print(f"🔍 检索到的文档数量:{len(retrieved_docs)}")
for i, doc in enumerate(retrieved_docs):
print(f" [{i}] 得分:{doc['score']:.4f} | 文本:{doc['text'][:50]}...")
# 即使得分低,也不直接返回"无相关信息",而是继续处理
if not retrieved_docs:
return "抱歉,知识库中没有找到相关信息,无法回答您的问题。"
# 后续上下文处理代码不变...步骤 2:修复 BGE 模型离线加载问题
之前的 BGE 模型是离线加载的,很可能因为路径或版本问题,导致向量生成失败,所有文本的向量都变成了随机值,相似度极低。
-
临时改成在线模式,把
hybrid_retriever.py开头的环境变量注释掉:# os.environ["HF_HUB_OFFLINE"] = "1" # os.environ["TRANSFORMERS_OFFLINE"] = "1" -
重启后端,让它自动下载 BGE 模型,生成正确的向量。
-
再问问题,看控制台打印的
score是否都大于 0.5。
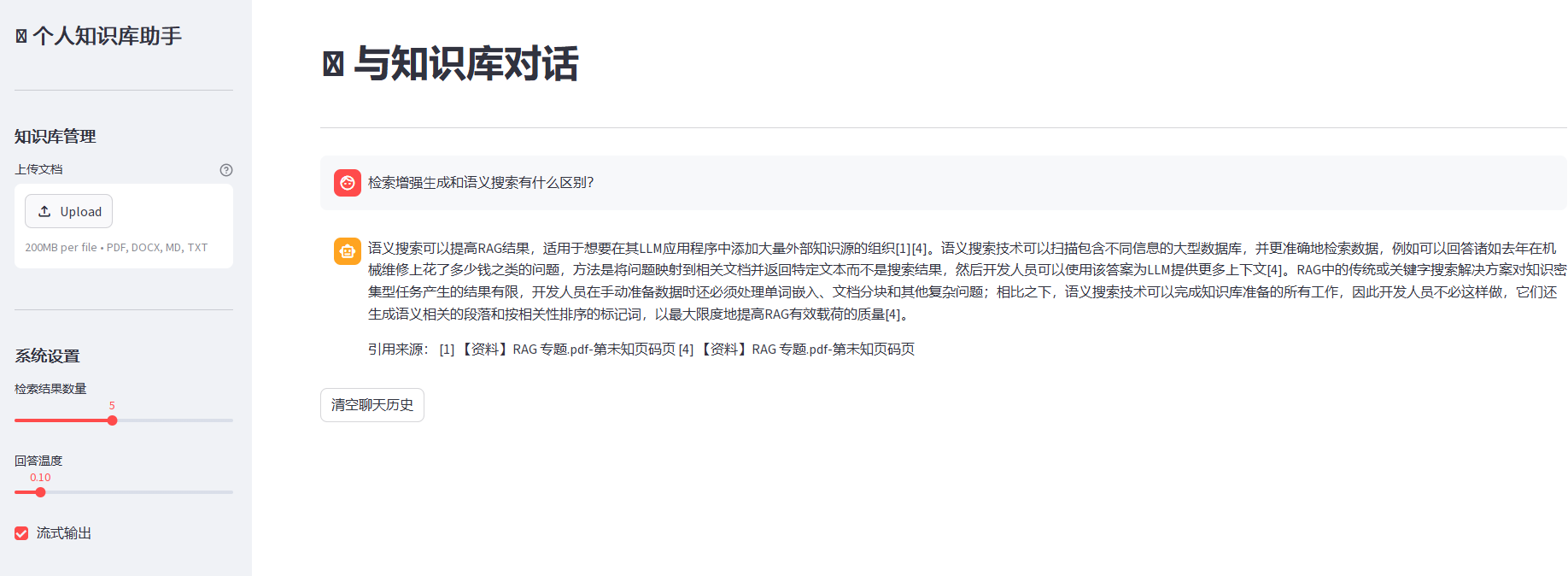
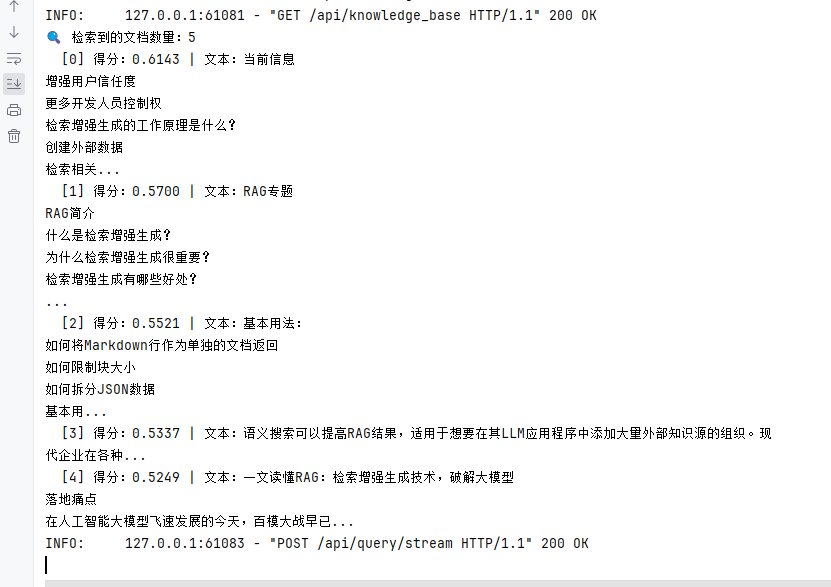
OK。