1、协程出现的背景
咱们从一个典型场景示例开始。这个场景就是点击按钮后联网获取用户信息,然后把用户信息展示出来。如果用最直接的方式来写,应该是这样的:
fun onClick() {
val user = api.getUser() //网络连接,比较耗时,且会阻塞住线程
show(user)
}很显然,网络连接是一个比较耗时的操作,网络不好的情况下说不定需要好几秒钟才能返回结果,此时线程就会陷入阻塞状态,这期间UI无法响应,严重的话还会ANR。改进
Thread {
val user = api.getUser()
runOnUiThread {
show(user)
}
}.start()这样就好多了,把网络连接放到子线程里,阻塞由子线程去承受,收到结果后再通过runOnUiThread交给主线程去显示。但此时还是有一些问题:
(1)线程是一种比较重的系统资源,它的创建、切换、销毁等都需要较大的开销,而且系统支持的线程数量是有限的,如果网络请求并发很多,每个请求都用一条线程的话,开销实在太大了。
(2)需要用回调来处理结果。上面的这个示例还不太明显,如果场景复杂一些:先获取用户信息,获取到后用回调方式再用用户信息里的某些字段去拉取其他信息,拉取到其他信息后再......依此类推,陷入回调地狱。继续改进,大家熟悉的线程池就要上场了,如此一来,就可以复用线程了,确实可以大大减小对线程数量的需求,但是当请求很多时,还是会捉襟见肘;至于回调问题,自然可以用Future来解决,但future的get()也是阻塞线程的,总得来说线程池+Future的方案减小了对线程数量的需求,也避免了回调地狱,但仍然没有解决线程阻塞的问题 。线程一旦阻塞,就是在那什么也做不了,其实就是一种浪费资源的行为。如果此时线程可以抽身去做别的事,等结果返回了再回来处理结果,那就完美了!于是,协程(Coroutine)带着这个使命应运而生了!咱们先来看下用协程方式该怎么写:
launch { //启动协程的一种方式
val user = api.getUser()
show(user)
}上面的代码中,当协程执行到getUser()时由于网络连接是一种耗时行为,此时正在由系统层去执行网络行为,上层陷入等待(即阻塞)状态,协程会释放当前线程,保存当前场景数据,线程抽身离开去做别的事,等user返回后协程再调用线程(不一定是上一次的那条)处理结果。但是仔细观察一下就会发现,上述代码似乎并没有看出异步的机制呀,跟
fun onClick() {
val user = api.getUser() //网络连接,比较耗时,且会阻塞住线程
show(user)
}
简直一模一样啊!没错,这正是协程的亮点之一:用同步代码的编写方式(或称为样貌?)实现异步的效果。
再来一个
Thread.sleep(1000) //传统线程方式。线程啥也不做,就在那呆着,一秒钟。
delay(1000) //协程方式。逻辑暂停1秒钟,线程先去忙活别的。
总结一下 :协程的本质是为了解决为了等待而白白浪费线程的问题。协程运行在线程上。线程是操作系统调度单位,协程是程序自身的调度单位,是一种可暂停、可恢复的轻量级任务。
Kotlin 协程是 Kotlin 语言提供的一种轻量级并发编程方案,它允许你以同步的方式编写异步代码,从而简化线程阻塞、回调地狱和状态共享等问题,同时还能减小传统线程方式带来的较大开销。
2、协程的原理概述
suspend(挂起) :用来修饰函数。"挂起"的意思是函数执行到某个点时,可以主动释放当前线程,让线程去执行其他任务,等等待的条件满足(如网络返回、定时到达)后再恢复执行该函数剩下的代码。整个过程不阻塞线程。
Scope(作用域) :管理协程生命周期;为协程提供启动入口;绑定"父子关系"(父协程取消则所有子协程自动取消,子协程失败则父协程也失败,等等规则)。
Dispatcher(调度器) :决定协程运行在哪条线程上。
上下文 :一个不可变的键值对集合,包含协程运行所需的各种配置(Job、调度器、异常处理器等)。
Job :协程的"控制手柄"。可调用 cancel()、join(),父子 Job 之间形成树,父取消则子自动取消。
下面用一个简单的示例来讲解协程是怎样运行起来的
//函数被suspend修饰,用delay模拟阻塞操作
suspend fun getMessage(): String {
delay(1000) // 挂起点,会在这让出线程
return "Hello"
}
fun main() = runBlocking {
val format = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss.SSS")
// 手动创建一个作用域,配置上下文,其中调度器Dispatcher.IO是Kotlin原生调度器
val scope = CoroutineScope(Job() + Dispatchers.IO)
// 作用域为协程提供启动入口,launch是启动协程的一个方法
val job = scope.launch {
println("即将getMessage。当前时间 ${ZonedDateTime.now().format(format)}")
val msg = getMessage()
// withContext是切换上下文的一种方式,这里用来切换调度器。此处只是用来演示切换,实际不切换
// 也可以。
withContext(Dispatchers.Default) {
println("$msg from ${Thread.currentThread().name}。 当前时间 ${ZonedDateTime.now().format(format)}")
}
}
// 通过 Job 控制协程
job.join() // 等待协程完成
scope.cancel() // 取消作用域(清理资源)
println("协程执行结束了。当前时间 ${ZonedDateTime.now().format(format)}")
}其运行结果如下

作用域 (后文会详细讲解)提供一个包含 Job 和 调度器 的 上下文 ,用它启动的协程 会被打包为可挂起的状态机,由调度器投递到指定线程池执行,遇到挂起点时让出线程,恢复时重新调度,整个过程由父子 Job 保证取消与异常传播。
runBlocking是一个顶层函数,用于连接非协程和协程世界(如在 main() 方法中测试)。它会阻塞当前线程,不推荐在非测试代码中使用。
3、协程的Scope
作用域是 Kotlin 协程的核心管理机制,本质是一个协程容器 / 生命周期边界,定义了协程的执行范围与生命周期限制。它包含一个核心属性coroutineContext(协程上下文),其中必须包含Job元素以实现结构化并发。
所有协程都必须在作用域内启动,作用域与协程形成父子层级关系,父作用域负责管理所有子协程。
Kotlin 协程原生提供了多种预定义的 CoroutineScope,它们各有侧重,核心目的就是为协程绑定一个生命周期,实现结构化并发,从而避免内存泄漏。
GlobalScope:进程级别,伴随整个应用生命周期。极少使用(如,不依赖UI的长期后台任务)。不会自动取消,极易造成内存泄漏。使用示例如下
GlobalScope.launch(Dispatchers.IO){
//执行协程任务
}viewModelScope :绑定 ViewModel 的生命周期,ViewModel 被清除时自动取消。是ViewModel的一个扩展属性 ,所以仅可在ViewModel中使用。
lifecycleScope :绑定 Activity/Fragment 的生命周期,适用于在 Activity/Fragment 中执行需与页面生命周期绑定的短时操作,宿主销毁时自动取消。是LifecycleOwner的一个扩展属性 。
MainScope() :在主线程执行,需手动管理;必须在不需要时手动调用 cancel()。可在任意地方使用,但其中的协程会在主线程上执行。
CoroutineScope() :通用的作用域工厂,可自定义 CoroutineContext。创建完全自定义的作用域。手动控制或依赖于父协程的取消。第2节给出的示例中就用到了该方法。该方法只有一个参数CoroutineScope(context: CoroutineContext): CoroutineScope,但是示例中传进的参数却是Job() + Dispatchers.IO,这是怎么回事?Job() + Dispatchers.IO并不是两个参数,而是通过协程库重载的 + 运算符,合并成了一个 CoroutineContext 对象。
coroutineScope():挂起函数,原型是 public suspend fun <R> coroutineScope(block: suspend CoroutineScope.() -> R): R,继承外部的 CoroutineContext。它用于在一个挂起函数内部创建新的协程作用域,并等待其所有子协程完成。任一子协程失败,则所有子协程和自身都会失败。
supervisorScope():类似 coroutineScope(),但子协程的失败不会影响其他子协程。管理一组相互独立的子任务,如并行加载UI模块。子协程失败不会影响父协程和其他子协程。
在 Jetpack Compose 中,可以使用 rememberCoroutineScope() 创建一个感知 Composable 生命周期的作用域,用于在点击事件等回调中安全地启动协程。
coroutineScope vs. supervisorScope:它们都是挂起函数,用于在已有的挂起上下文中创建一个新的作用域。关键在于失败的处理方式:coroutineScope 遵循"一损俱损"原则,而 supervisorScope 则遵循"各自为政"原则。
4、调度器Dispatcher
调度器是协程上下文中负责决定协程在哪个线程或线程池上执行的核心组件。Kotlin同样也提供了一些现成的调度器供使用。
Dispatchers.Default:适用于CPU 密集型任务。线程数 = CPU 核心数(至少2),所以一般线程数较少,这样也可以防止计算线程过多切换。
Dispatchers.IO :适用于IO 密集型任务,如网络、文件、数据库查询等。按需扩容,线程数上限 64(可调),与 Default 共享线程池。
Dispatchers.Main:只有一条线程,即UI 主线程。
Dispatchers.Unconfined:无固定线程,极少用,官方不推荐使用。 启动时在调用者线程,恢复时由恢复点决定。
自定义调度器:如Executors.newFixedThreadPool(4).asCoroutineDispatcher(),不过通常内置的已足够。
既然Default和IO是共用同一线程池,它们的线程数又是怎么分配的?这个线程池是谁创建的?
该线程池由 kotlinx-coroutines-core 协程库自动创建。它不是 JDK 普通的 ThreadPoolExecutor,而是 Kotlin 协程库自研的全局单例调度器CoroutineScheduler。在应用启动后第一次使用协程时,就会默默创建这个全局唯一的线程池,且该线程池由应用独享,不与其他应用共享。其核心线程数是Max(2,CPU核数)。Default只能用核心线程(=CPU 核心数),核心线程固定、常驻、不回收。Default的任务满了就排队,绝对不创建新线程;而IO可以用核心线程 + 额外的临时线程(总上限默认 64),临时线程空闲久了就自动销毁。此外,Default任务优先级高于IO任务,即使核心线程全被IO任务占满了,此时来了一个Default任务,也要把核心线程优先让给Default任务,IO去用扩容的临时线程。
5、Job
Job 就是协程的 生命周期控制器 + 任务身份 + 取消开关 。每个协程天生自带一个 Job,它是 CoroutineContext 协程上下文里最重要的元素之一。作用域 CoroutineScope 内部必须持有一个Job,不明确设置的话,框架就自动给补 Job()。Job主管的4件事:
(1)标记协程生命周期状态。
(2)取消协程。
(3)父子层级绑定(结构化并发根基)。Job 天然形成树形父子关系:作用域的 Job 是父 Job;
作用域里启动的所有协程都是子 Job;父 Job取消则所有子 Job 全取消;普通 Job 下,一个 子协程崩了则父 + 所有子全跟着崩;SupervisorJob各自翻车互不影响。
(4)等待协程执行完。job.join() 挂起,等这个协程彻底结束再往下走。
6、上下文
协程上下文CoroutineContext是协程运行时携带的一组环境信息,可以简单理解为协程的运行配置。仍以launch启动一条协程为例,
launch(Dispatchers.IO) {
... //协程任务逻辑
}
为什么要传一个Dispatchers.IO呢?因为协程需要知道在哪运行。还有launch(Job())这样的用法,为什么要传一个Job()呢?因为需要有控制手柄来控制协程。等等这些配置信息放在哪呢?就在上下文(CoroutineContext) 结构里。它本质上是一个Key-Value 结构。它常见的元素有Job、Dispatcher、CoroutineName(协程名)、 ExceptionHandler(异常处理 )等,上下文就是一个所有这些元素的集合。所有这些元素合起来也就决定了协程在哪执行、属于谁管理、如何取消、如何处理异常、恢复时如何继续运行等。
7、常用API
7.1 启动协程
launch:启动一个没有返回结果的协程。原型是public fun CoroutineScope.launch(context: CoroutineContext = EmptyCoroutineContext, start: CoroutineStart = CoroutineStart.DEFAULT, block: suspend CoroutineScope.() -> Unit): Job。可见,如果前两个参数不指定的话会由默认值充当。默认的上下文即表示完全继承父作用域的所有上下文。start即启动模式。CoroutineStart.DEFAULT:协程马上执行;
LAZY(懒启动):协程创建后不执行,必须手动调用 job.start() 或 job.join() 才会运行;
ATOMIC / UNDISPATCHED:底层专用,不用管。
val job = viewModelScope .launch {
//执行任务
}
即表示,让协程马上执行,但不关心结果,返回一个job用以控制协程。
async:启动一个有返回结果的协程。其原型
public fun <T> CoroutineScope.async(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> T
): Deferred<T>。
Deferred继承自Job,但Job不携带结果,Deferred携带结果,可通过await()获取到结果。
val deferred: Deferred<Int> = scope.async {
println("执行delay前")
delay(2000)
5
}
val result = deferred.await()//这里会暂停两秒,然后打印出结果 5
println(result)runBlocking:阻塞住当前线程直到协程结束。通常仅用于测试和桥接。
launch、async 这两个函数并不会因为协程任务里有耗时操作就会迟迟不返回,它们只是把协程提交出去,然后立即返回,所以不会阻塞住所在线程。可通过第2节中的launch示例结果验证这一点。runBlocking也是把协程提交出去,但是它会阻塞住线程,也就是它要等到协程全部执行完后才会返回。
7.2 挂起函数
delay():相当于Thread.sleep()的协程版。前面已有示例。
yield() :主动让出调度器,让其他协程有机会执行。与线程中的yield()类似。
withContext(context) :切换协程上下文,最常用的场景就是切换调度器,比如在一个自定义Scope里处理业务逻辑时需要读取一下文件,就可以使用该方法切换到IO调度器去读取文件。在第2节的示例代码中也已演示。
withTimeout():限时执行,超时抛出 TimeoutCancellationException。
fun main() = runBlocking {
val format = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss.SSS")
// 手动创建一个作用域,配置上下文,其中调度器Dispatcher.IO是Kotlin原生调度器
val scope = CoroutineScope(Job() + Dispatchers.IO)
val job = scope.launch {
withTimeout(1000){
println("执行delay前,当前时间 ${ZonedDateTime.now().format(format)} ")
delay(3000)
println("执行delay结束,当前时间 ${ZonedDateTime.now().format(format)} ")
}
}
job.join()
scope.cancel()
println("执行全部结束,当前时间 ${ZonedDateTime.now().format(format)} ")
}执行结果如下
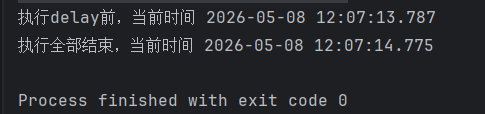
可见,第二句Log没有打印出来,这是因为使用了withTimeout(1000),即给里面的协程的执行时间只有1000ms,但是协程的执行需要3000ms,于是触发了超时,协程被取消了,实际抛出了CancellationException,但是在 Kotlin 协程中,CancellationException 及其子类(包括 TimeoutCancellationException)被视为"协程正常的结束原因",而不是"必须崩溃的致命错误",所以程序并没有崩溃。
withTimeoutOrNull() :超时返回 null 而不是抛异常。
suspendCoroutine :原型是public suspend inline fun <T> suspendCoroutine(crossinline block: (Continuation<T>) -> Unit): T。作用是把基于回调的异步 API 转换成基于协程的挂起函数,所以它的典型用途是封装老旧的回调式 API(如 Android 的 View.setOnClickListener、Callback、Future 等),让它们可以被协程以同步风格调用。关于Continuation咱们后面再讲,目前先知道它是一种表示在当前指令之后下一步需要做什么的数据结构即可,简单理解为它表示"剩余的计算",它使协程有了可以暂停再恢复执行的能力。suspendCoroutine使用示例(先大致了解下,后面详细讲解协程原理时会再介绍suspendCoroutine)
// 假设这是某个库的回调 API
fun fetchUser(id: Int, callback: (User) -> Unit) {
thread { // 模拟异步
Thread.sleep(1000)
callback(User(id, "name"))
}
}
suspend fun fetchUserSuspend(id: Int): User = suspendCoroutine { continuation ->
fetchUser(id) { user ->
continuation.resume(user) // 恢复协程并返回 user
}
}
runBlocking {
val user = fetchUserSuspend(1)
println(user) // 像同步函数一样得到结果
}7.3 作用域、协程控制、结果获取等
Job.cancel()、Job.cancelAndJoin()、Deferred.await()、CoroutineScope.cancel()等。
awaitAll(listOf(deferred1, deferred2)):等待所有 Deferred 完成,收集结果。
async 批量 + awaitAll:并发执行多个独立任务。
8、协程的异常处理
前面多少也提到了一点关于协程异常的情况。这一节专门讲讲协程的异常。
(1)在普通 launch 或 async 中,如果一个子协程抛出异常(非 CancellationException),它会自动取消它的父协程以及兄弟协程(除非使用 SupervisorJob),这就很容易造成大范围取消。
fun main() = runBlocking {
val scope = CoroutineScope(Job()) // 默认 Job
val job1 = scope.launch {
delay(500)
println("job1 完成")
}
val job2 = scope.launch {
delay(100)
println("job2 delay 100ms 完成")
throw RuntimeException("job2 崩溃")
}
delay(1000) // 等待两个协程执行
println(scope.coroutineContext[Job]?.isCancelled?.let { "scope 是否活跃: ${!it}" })
}运行结果

如果不像让某条子协程异常影响到其他子协程,可使用SupervisorJob。将以上代码改为
val scope = CoroutineScope(SupervisorJob()) ,则运行结果如下

如果只想在某个局部作用域内隔离异常,不想影响外部协程,可以用 supervisorScope。
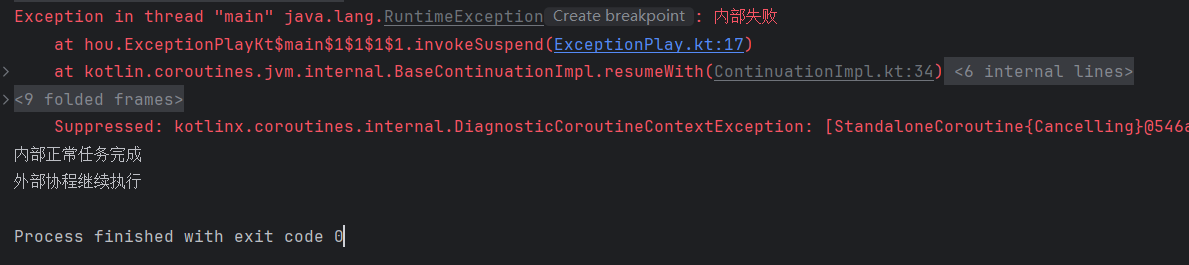
fun main() = runBlocking {
launch {
supervisorScope { // 内部子协程失败不影响外部
launch {
delay(200)
throw RuntimeException("内部失败")
}
launch {
delay(400)
println("内部正常任务完成")
}
}
println("外部协程继续执行")
}
delay(1000)
}运行结果
与Thread有uncaughtExceptionHandler类似,协程也有类似机制,不过它只能用于launch,不能用于async(因为 async 要求必须通过 await() 处理异常),它会在协程未捕获的异常发生时被调用。
val handler = CoroutineExceptionHandler { _, exception ->
println("Caught: $exception")
}
fun main() = runBlocking {
val scope = CoroutineScope(Job() + handler)//这样设置handler
scope.launch {
throw NullPointerException("NPE")
}
delay(500)
println(scope.coroutineContext[Job]?.isCancelled?.let { "scope 是否活跃: ${!it}" })
}运行结果
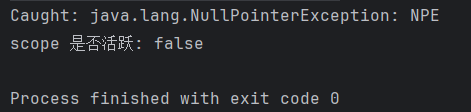
可见,CoroutineExceptionHandler 虽然能捕获异常,但是scope仍然会被取消。
(2)async 的异常隐藏。async 启动的协程,其异常不会自动抛出,而是被封装在 Deferred 中,只有在调用 await() 时才会重新抛出。如果忘记调用 await(),异常就会被"吞掉",难以发现。async的异常捕获如下
fun main() = runBlocking {
val deferred = async {
delay(200)
throw ArithmeticException("除零错误")
42
}
try {
val result = deferred.await()
println("Result: $result")
} catch (e: Exception) {
println("Caught in await: $e")
}
}执行结果
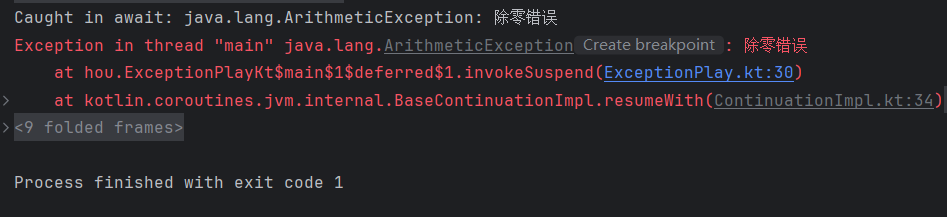
(3)默认没有全局异常处理器。在 launch 中未捕获的异常,如果没有设置 CoroutineExceptionHandler,只会打印到控制台(JVM 平台),但不会导致 JVM 退出。线上环境需要主动记录和响应。
9、协程的底层原理
9.1 协程的本质
协程本质上是一套用户态的轻量级并发框架,是一种 编译器 + 状态机(State Machine)+ Continuation(续体)+ 调度器(Dispatcher) 的组合。从开发角度来看,协程就是一种可挂起的函数。再来强调一下,suspend(挂起):可以暂停,之后又可以恢复而继续执行。可挂起,这是协程函数与普通函数最本质的区别,普通函数虽然从CPU调度的微观角度来看确实是在间歇性执行,但这是线程级别的暂停,需要保存的现场数据更多,开销更大,协程是应用层面函数级别的主动暂停,需要保存的数据更少,开销更小,协程恢复时也不会涉及线程栈。
Kotlin从语言层面(API)提供对协程的支持,源代码经过编译器编译后,就产生了状态机,也就是说,在Kotlin API 的源码里有接口续体Continuation、抽象类调度器CoroutineDispatcher,但没有一个叫StateMachine的类或接口,状态机是工程源码经过编译器的编译后而产生的一个类。协程状态机+续体+调度器的组合是Kotlin API 和 编译器搭配才产生出来的,咱们在工程里写的代码只是这种组合产生前还未加工的原材料。
9.2 Continuation
到了该详细讲解Continuation 的时候了,翻译为 续体,它的作用就是把函数剩余的执行逻辑,当成一个对象传来传去,也就是记录函数当前已执行的情况以及下一步要执行什么。它是协程最核心的基石。去看一下它的源码就会发现特别简单,全部源码就是如下这样
@SinceKotlin("1.3")
public interface Continuation<in T> {
/**
* The context of the coroutine that corresponds to this continuation.
*/
public val context: CoroutineContext
/**
* Resumes the execution of the corresponding coroutine passing a successful or failed [result] as the
* return value of the last suspension point.
*/
public fun resumeWith(result: Result<T>)
}看起来就是这样简单,一个协程上下文,一个resumeWith()函数。咱们知道协程是可以挂起的,也是可以恢复(继续执行)的,挂起是因为有异步操作或其他需要暂停的需求,需要等待返回了结果才能恢复,这里的resumeWith()其实就是恢复执行时要调用到的地方,里面的result就是等待而返回的结果,比如,协程要读取文件数据,到了IO的时候就需要等待系统底层给返回结果,所以协程被挂起,等系统底层返回了结果------比如一行字符串,此时的result其实就是这行字符串被封装后的数据,协程将要调用resumeWith(result)来恢复执行;如果恰好恢复执行就是协程的最后一步了,那么这个result也就是这个协程最终的结果了。
9.3 状态机
简单来说,每个挂起函数都会被编译成一个有限状态自动机,每一个挂起点 (即可能挂起的调用点)对应状态机中的一个状态,而协程的恢复(resume)本质上就是在状态机中从一个状态流转到下一个状态。这种机制与状态模式有些类似。如下这段代码
编译后的伪代码大致会是这个样子
fun example(continuation: Continuation<Unit>): Any? {
// 创建一个状态机对象
val sm = continuation as? StateMachine ?: StateMachine(continuation)
when (sm.label) {
0 -> { // 0表示初始状态
sm.label = 1
println("start")
val result = delay(1000, sm) // 传递continuation
if (result == COROUTINE_SUSPENDED) return COROUTINE_SUSPENDED
}
1 -> {
sm.label = 2
println("middle")
val result = delay(500, sm)
if (result == COROUTINE_SUSPENDED) return COROUTINE_SUSPENDED
}
2 -> {
println("end")
return Unit
}
}
return Unit
}我将另开一篇博客 Kotlin协程的运行原理 用一个示例专门讲解一下协程到底是怎样运行的
状态机是一种机制,无论是API层面还是编译器转换后的代码里都没有状态机这种类
深度思考:为什么不用纯API的方式,也就是全部都在API层面进行转换,而是采用API+编译器转换的方式?
状态需要知道用到的数据在哪里、执行到哪一步了、下一步又该到哪里,需要知道代码的结构,但是这些无法在API层面统计出来,例如
suspend fun foo() {
val x = 10
delay(1000)
println(x)
}
这个函数如果在API层面该怎么包装成状态呢?是不是需要分析里面逻辑的步骤------第一步有一个变量,第二步暂停,第三步打印,但是分解步骤这个操作该由谁去做呢?API层面做不到!但是编译器可以做到,编译器在编译阶段就可以以全局的上帝视角观察到里面的所有分支和步骤,梳理出里面的层级关系,产生所有可能的状态。
10、协程适用的场景和不适用的场景
适用的场景
(1)IO密集型场景。网络请求、数据库查询、文件读写等。这些场合需要等待的时间较长,非常适合协程发挥作用。
(2)并发任务组合的场景,尤其是需要统一管理任务的场景,因为作用域可对这些任务统一管理。比如,同时请求多个接口、并行加载页面模块、聚合多个 API 结果等。
(3)Android UI生命周期相关的任务。可以用viewModelScope、lifecycleScope实现声明周期管理。
不适用的场景
(1)不要用不适合的调度器。例如CPU密集型任务不要用IO调度器,因为IO调度器可能会触发出很多线程,线程过多了反倒会因为线程切换导致计算更慢,这类任务应该用Default调度器。
(2)对实时性要求极高的场合,因为协程有调度开销,不过这种场合一般很少见。
11、协程与Java虚拟线程的比较
关于虚拟线程请见我的另一篇博客 Java的虚拟线程
两者都是为了解决高并发的问题,都是为了解决线程阻塞的问题,都是用更轻量级的执行单元来代替重量级的线程,都是用户态的解决方案。虚拟线程仍旧像传统线程一样使用了栈,已经深入到了JVM层面,而协程则更纯粹,不涉及栈,它是在纯应用层面实现的,只是在编译的时候由编译器做了一些转换才达到了纯应用层的效果。从这一点来说,协程对CPU的利用率更高一点、对内存的消耗更少一点。
Java为了支持虚拟线程,语言层面、API层面和JVM 都做了适配;Kotlin为了支持协程,语言层面、API层面和编译器层面都做了适配。
总体来看,虚拟线程在Java生态圈里更适用,比如服务端的开发上,而协程显然是在Kotlin的生态圈更适用,比如Android开发上。
既然Kotlin最终也是要运行在JVM上,而协程又有那么大的用途,为什么Java没有协程机制呢?
Kotlin的协程机制有个问题,就是调用suspend函数的函数也必须是suspend的!为什么会这样?因为,如果内部的suspend函数是外部函数的一部分,如果外部函数不许suspend,作为它其中一部分的内部函数自然也不可以suspend。Java发展多年,自己的API和大量第三方框架的API都是不支持suspend,如果采用Kotlin的协程方式自然就无法和它们兼容(比如在第三方框架的方法里无法调用suspend函数),即使采用一些CompletableFuture、ListenableFuture类的方案来适配也无法做到完全兼容,但是虚拟线程却没有这个限制。为了与旧代码的兼容性,Kotlin的协程方案无法在Java上实施。另外,Java发展已多年,生态庞大,任何新特性的加入都要考虑其影响和兼容性,还有新特性给从业者带来的学习成本、维护成本,综合考量,Java迟迟未添加协程,最终采用了虚拟线程这种机制上比协程稍差一些,但兼容性更好的方案。
既然这样,那Kotlin的协程岂不跟大量的Java框架有兼容性问题了?在这些框架的API里调用Kotlin的suspend函数岂不很麻烦,比如要先创建作用域什么的?
没错,确实是这样,所以才会有CompletableFuture、ListenableFuture这些接口应运而生。好消息是,大量的框架正在适配协程。