
前言
在 Spring Cloud 微服务架构中,随着业务规模增长和用户量激增,系统性能瓶颈逐渐显现。缓存作为提升系统吞吐量的关键技术,常常面临穿透、击穿、雪崩等问题;而数据库则会遭遇单库单表数据量过大导致的查询缓慢、写入延迟等挑战。本文将深入剖析缓存三大问题的解决方案,并系统讲解数据库分库分表入门知识,为 Spring Cloud 微服务性能优化提供实战指南。
一、缓存三大问题深度解析与解决方案
1.1 缓存穿透:无效请求直击数据库的 "隐形杀手"
1.1.1 问题定义与危害
缓存穿透是指查询一个不存在的数据,由于缓存中没有该数据,所有请求都会穿透到数据库,导致数据库压力剧增,甚至宕机。
典型场景:
- 恶意攻击:黑客利用不存在的用户 ID、商品 ID 进行高频查询
- 业务误操作:查询条件错误导致查询不存在的数据
- 缓存与数据库数据不一致:数据已删除但缓存未清理
危害:大量无效请求绕过缓存直接访问数据库,导致数据库连接耗尽、响应超时,影响正常业务。
1.1.2 核心解决方案(生产可用)
| 方案 | 原理 | 实现难度 | 适用场景 |
|---|---|---|---|
| 缓存空值 | 查询结果为空时,仍缓存空对象(设置较短 TTL) | 低 | 数据不存在场景较少 |
| 布隆过滤器 | 用位数组快速判断数据是否存在 | 中 | 数据量大、查询频繁的场景 |
| 参数校验 | 入口处过滤非法参数(如 ID≤0) | 低 | 所有接口通用 |
| 限流降级 | 对特定接口进行限流,保护数据库 | 中 | 高并发场景 |
1.1.3 代码实现(Spring Cloud+Redis)
方案一:缓存空值(实战代码)
java
@Service
public class ProductServiceImpl implements ProductService {
@Autowired
private ProductMapper productMapper;
@Autowired
private StringRedisTemplate redisTemplate;
private static final String CACHE_KEY_PREFIX = "product:";
private static final long NULL_VALUE_TTL = 5*60; // 空值缓存5分钟
private static final long NORMAL_VALUE_TTL = 3600; // 正常数据缓存1小时
@Override
public Product getProductById(Long id) {
// 1. 参数校验(基础防护)
if (id == null || id <= 0) {
return null;
}
String key = CACHE_KEY_PREFIX + id;
String value = redisTemplate.opsForValue().get(key);
// 2. 缓存命中
if (value != null) {
// 处理空值
if ("NULL".equals(value)) {
return null;
}
return JSON.parseObject(value, Product.class);
}
// 3. 缓存未命中,查询数据库
Product product = productMapper.selectById(id);
// 4. 处理查询结果
if (product != null) {
redisTemplate.opsForValue().set(key, JSON.toJSONString(product),
NORMAL_VALUE_TTL, TimeUnit.SECONDS);
} else {
// 缓存空值,防止穿透
redisTemplate.opsForValue().set(key, "NULL",
NULL_VALUE_TTL, TimeUnit.SECONDS);
}
return product;
}
}方案二:布隆过滤器(Guava 实现)
java
@Configuration
public class BloomFilterConfig {
// 预估数据量
private static final long EXPECTED_INSERTIONS = 1000000;
// 误判率
private static final double FALSE_POSITIVE_PROBABILITY = 0.01;
@Bean
public BloomFilter<Long> productIdBloomFilter() {
// 创建布隆过滤器
BloomFilter<Long> bloomFilter = BloomFilter.create(
Funnels.longFunnel(),
EXPECTED_INSERTIONS,
FALSE_POSITIVE_PROBABILITY
);
// 初始化:将所有有效商品ID加载到布隆过滤器
List<Long> validProductIds = productMapper.selectAllProductIds();
validProductIds.forEach(bloomFilter::put);
return bloomFilter;
}
}
// 在Service层使用
@Override
public Product getProductById(Long id) {
// 1. 布隆过滤器判断是否存在
if (!bloomFilter.mightContain(id)) {
log.warn("商品ID {} 不存在(布隆过滤器拦截)", id);
return null;
}
// 后续逻辑同上(缓存查询、数据库查询)
}1.1.4 方案对比与最佳实践
- 缓存空值:实现简单,但会占用缓存空间,适用于数据不存在场景较少的情况
- 布隆过滤器:空间效率高,查询速度快,但有一定误判率,适用于数据量大的场景
- 最佳实践 :布隆过滤器 + 缓存空值 + 参数校验组合使用,全方位防护缓存穿透
1.2 缓存击穿:热点数据过期的 "瞬间洪峰"
1.2.1 问题定义与危害
缓存击穿是指热点数据的缓存过期,此时大量并发请求同时访问该数据,导致所有请求都穿透到数据库,瞬间压垮数据库。
典型场景:
- 秒杀商品:热点商品缓存过期
- 热门新闻:突发新闻缓存过期
- 高频接口:核心业务接口缓存过期
危害:数据库瞬间承受巨大压力,连接数暴增,响应超时,影响正常业务。
1.2.2 核心解决方案
| 方案 | 原理 | 实现难度 | 适用场景 |
|---|---|---|---|
| 互斥锁 | 缓存失效时,只允许一个线程重建缓存 | 中 | 热点数据较少 |
| 热点 key 永不过期 | 缓存不设置 TTL,后台异步更新 | 低 | 核心热点数据 |
| 提前预热 | 缓存过期前主动更新 | 中 | 可预测的热点数据 |
1.2.3 代码实现(分布式锁方案)
java
@Service
public class ProductServiceImpl implements ProductService {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private RedissonClient redissonClient;
private static final String CACHE_KEY_PREFIX = "product:";
private static final String LOCK_KEY_PREFIX = "lock:product:";
@Override
public Product getProductById(Long id) {
// 1. 参数校验
if (id == null || id <= 0) {
return null;
}
String cacheKey = CACHE_KEY_PREFIX + id;
String lockKey = LOCK_KEY_PREFIX + id;
// 2. 尝试获取缓存
String value = redisTemplate.opsForValue().get(cacheKey);
if (value != null && !"NULL".equals(value)) {
return JSON.parseObject(value, Product.class);
}
// 3. 缓存未命中,获取分布式锁
RLock lock = redissonClient.getLock(lockKey);
try {
// 尝试获取锁,最多等待100ms,持有锁最多10秒
if (lock.tryLock(100, 10000, TimeUnit.MILLISECONDS)) {
// 4. 再次检查缓存(双重校验)
value = redisTemplate.opsForValue().get(cacheKey);
if (value != null && !"NULL".equals(value)) {
return JSON.parseObject(value, Product.class);
}
// 5. 重建缓存
Product product = productMapper.selectById(id);
if (product != null) {
redisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(product),
3600, TimeUnit.SECONDS);
} else {
redisTemplate.opsForValue().set(cacheKey, "NULL",
300, TimeUnit.SECONDS);
}
return product;
} else {
// 6. 获取锁失败,返回旧数据或降级处理
if (value != null && "NULL".equals(value)) {
return null;
}
// 降级:返回默认数据或提示
return getDefaultProduct();
}
} catch (InterruptedException e) {
log.error("获取分布式锁失败", e);
Thread.currentThread().interrupt();
return null;
} finally {
// 7. 释放锁
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
}1.2.4 最佳实践
- 核心热点数据:采用 "热点 key 永不过期 + 后台异步更新" 方案
- 一般热点数据:采用 "互斥锁 + 双重校验" 方案
- 缓存更新策略:结合业务场景选择合适的更新时机,避免集中过期
1.3 缓存雪崩:缓存集体失效的 "系统性灾难"
1.3.1 问题定义与危害
缓存雪崩是指大量缓存同时过期 或缓存服务宕机,导致所有请求都穿透到数据库,造成数据库灾难性故障。
典型场景:
- 缓存服务器宕机(如 Redis 集群故障)
- 大量缓存设置相同 TTL,同时过期
- 缓存更新策略不当,导致批量缓存失效
危害:数据库瞬间承受所有流量,连接数耗尽,系统崩溃,影响范围广。
1.3.2 核心解决方案
| 方案 | 原理 | 实现难度 | 适用场景 |
|---|---|---|---|
| TTL 加随机偏移量 | 缓存 TTL 设置随机值,避免同时过期 | 低 | 所有缓存场景 |
| 多级缓存 | 本地缓存 + 分布式缓存,降低缓存失效影响 | 中 | 核心业务 |
| 缓存集群 | 搭建高可用缓存集群,避免单点故障 | 高 | 企业级应用 |
| 限流降级 | 对数据库进行限流,保护核心业务 | 中 | 高并发场景 |
1.3.3 架构设计(多级缓存 + TTL 随机化)
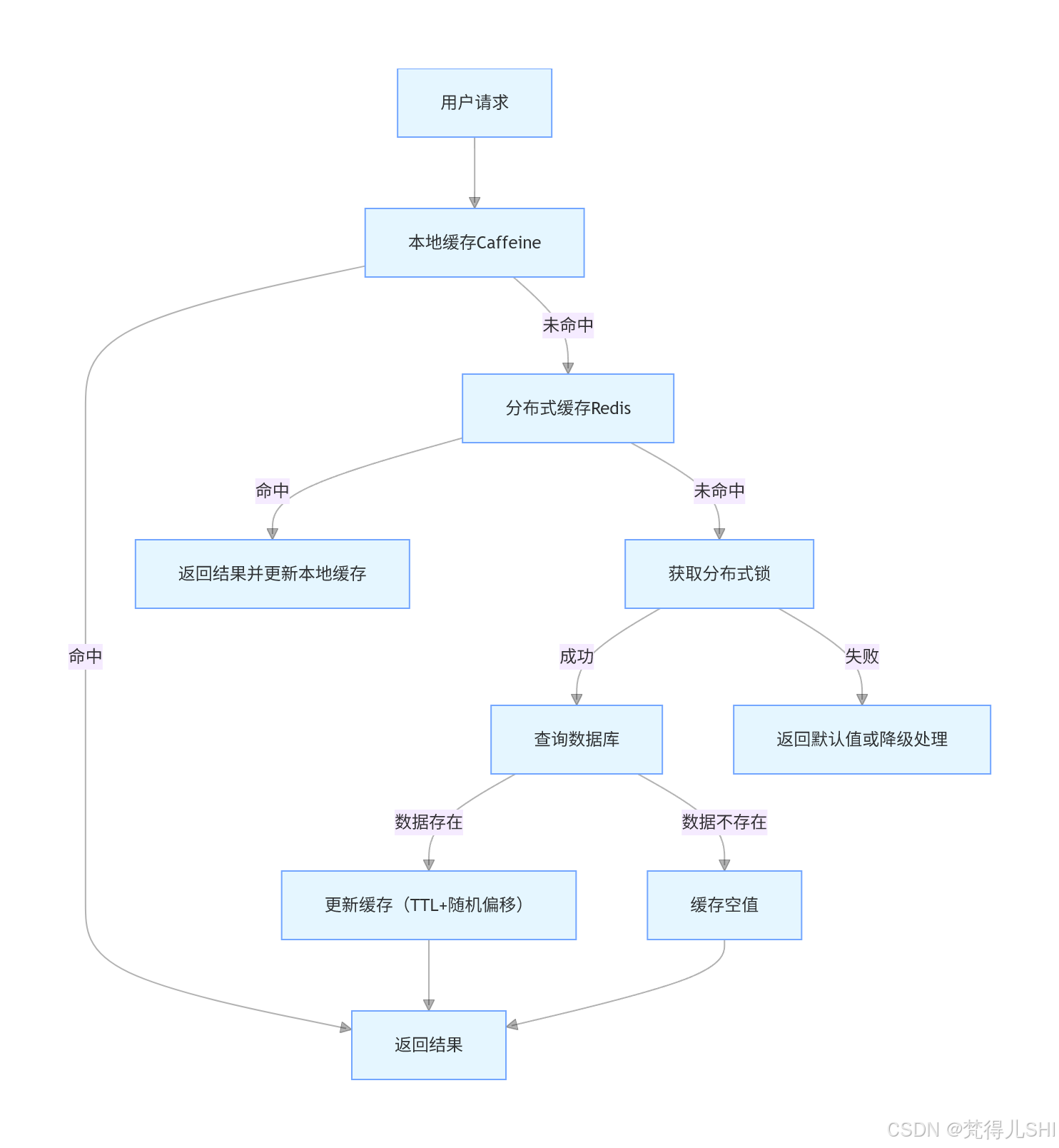
1.3.4 代码实现(TTL 随机化)
java
/**
* 生成带随机偏移的TTL
* @param baseTTL 基础过期时间(秒)
* @param offset 偏移量(秒)
* @return 最终TTL
*/
private long getRandomTTL(long baseTTL, long offset) {
Random random = new Random();
return baseTTL + random.nextInt((int) offset);
}
// 使用示例
long ttl = getRandomTTL(3600, 600); // 基础1小时,偏移0-10分钟
redisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(product),
ttl, TimeUnit.SECONDS);1.3.5 缓存高可用架构建议
- Redis 集群:采用主从 + 哨兵模式,确保缓存服务高可用
- 多级缓存:本地缓存(Caffeine)+ 分布式缓存(Redis),降低缓存失效影响
- 熔断降级:使用 Sentinel 或 Resilience4j,缓存服务故障时快速降级
- 监控告警:实时监控缓存命中率、过期率、宕机情况,及时预警
1.4 缓存问题总结与最佳实践
| 问题 | 核心解决方案 | 关键注意事项 |
|---|---|---|
| 穿透 | 布隆过滤器 + 缓存空值 + 参数校验 | 空值 TTL 不宜过长,布隆过滤器需定期更新 |
| 击穿 | 互斥锁 + 热点 key 永不过期 | 锁超时时间合理设置,避免死锁 |
| 雪崩 | TTL 随机化 + 多级缓存 + 集群 | 缓存集群高可用,熔断降级机制完善 |
二、数据库分库分表入门指南
2.1 分库分表核心概念
2.1.1 什么是分库分表
分库分表是将单一数据库中的数据分散存储到多个数据库或表中的技术方案,核心思想是 "分而治之",解决数据库性能瓶颈问题。
- 分库:将表按业务或数据量拆分到不同数据库中
- 分表:将单张表的数据按规则拆分到多张表中
2.1.2 垂直拆分与水平拆分
| 拆分方式 | 定义 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 垂直分库 | 按业务模块拆分数据库 | 业务解耦,减轻单库压力 | 跨库事务复杂 | 业务模块清晰,独立性强 |
| 垂直分表 | 按字段拆分表 | 解决表字段过多问题 | 关联查询复杂 | 表字段过多,访问频率差异大 |
| 水平分库 | 按数据规则拆分数据库 | 分散存储和访问压力 | 路由复杂 | 单库数据量过大 |
| 水平分表 | 按数据规则拆分表 | 解决单表数据量过大 | 跨表查询复杂 | 单表数据量超千万 |
垂直分表示例:用户表拆分为:
- user_basic(基础信息:id、name、age)
- user_detail(详细信息:id、address、email、phone)
水平分表示例:订单表按用户 ID 取模拆分:
- order_0、order_1、...、order_15(16 张表)
2.2 分库分表核心策略
2.2.1 分片键选择
分片键是分库分表的核心,选择原则:
- 均匀分布:数据均匀分布到各个分片
- 查询友好:查询条件中频繁使用该字段
- 稳定不变:分片键值不应轻易改变
常见分片键:
- 用户 ID:适用于用户中心、订单系统
- 时间:适用于日志、报表系统
- 地理区域:适用于地域分布的业务
2.2.2 分片策略实现
-
哈希取模(最常用)
java// 按用户ID取模分表 int tableIndex = userId % 16; String tableName = "order_" + tableIndex; -
范围分片
java// 按订单创建时间分表 if (createTime < "2023-01-01") { tableName = "order_2022"; } else if (createTime < "2024-01-01") { tableName = "order_2023"; } -
一致性哈希解决哈希取模扩容时数据迁移量大的问题,适用于动态扩容场景。
2.3 分库分表实现方式
2.3.1 应用层分片(硬编码)
在应用代码中根据分片规则决定访问哪个库 / 表,优点是灵活可控,缺点是代码侵入性强。
示例代码:
java
@Service
public class OrderServiceImpl implements OrderService {
@Autowired
private List<OrderMapper> orderMappers; // 多个数据源的Mapper
private static final int TABLE_COUNT = 16;
@Override
public Order getOrderById(Long orderId, Long userId) {
// 计算分片索引
int tableIndex = userId % TABLE_COUNT;
int dbIndex = tableIndex % 2; // 分2个库
// 选择对应的Mapper
OrderMapper orderMapper = orderMappers.get(dbIndex);
// 设置表名
orderMapper.setTableName("order_" + tableIndex);
return orderMapper.selectById(orderId);
}
}2.3.2 中间件分片(推荐)
使用成熟的分库分表中间件,如 ShardingSphere、MyCat 等,优点是无侵入、功能完善。
ShardingSphere 快速入门
- 引入依赖
XML
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.3.2</version>
</dependency>- 配置分库分表规则
bash
spring:
shardingsphere:
datasource:
names: ds0,ds1
ds0:
url: jdbc:mysql://localhost:3306/order_db_0?useSSL=false
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
ds1:
url: jdbc:mysql://localhost:3306/order_db_1?useSSL=false
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
rules:
sharding:
tables:
t_order:
actual-data-nodes: ds${0..1}.t_order_${0..7}
table-strategy:
standard:
sharding-column: user_id
sharding-algorithm-name: t_order_table
database-strategy:
standard:
sharding-column: user_id
sharding-algorithm-name: t_order_ds
sharding-algorithms:
t_order_table:
type: MOD
props:
sharding-count: 8
t_order_ds:
type: MOD
props:
sharding-count: 2
props:
sql-show: true- 使用示例
java
@Mapper
public interface OrderMapper extends BaseMapper<Order> {
// 无需关心分库分表,直接操作逻辑表
List<Order> selectByUserId(Long userId);
}2.4 分库分表关键挑战与解决方案
2.4.1 跨库事务问题
解决方案:
- 最终一致性:使用消息队列(如 RabbitMQ、Kafka)实现异步确保
- 分布式事务:使用 Seata 等分布式事务框架
- 本地消息表:通过本地事务 + 定时任务实现跨库事务
2.4.2 跨库查询问题
解决方案:
- 应用层聚合:查询多个分片后在应用层聚合结果
- 全局表:将字典表、配置表等公共数据存储在所有分片
- 联邦查询:使用 ShardingSphere 的联邦查询功能
2.4.3 扩容问题
解决方案:
- 预分片:提前规划足够的分片数量
- 一致性哈希:减少数据迁移量
- 在线扩容:使用 ShardingSphere 的弹性伸缩功能
2.5 分库分表最佳实践
- 先垂直后水平:先按业务垂直拆分,再考虑水平拆分
- 分片键选择:优先选择查询频繁、分布均匀的字段
- 避免过度拆分:拆分粒度适中,避免管理复杂
- 数据迁移:使用专业工具(如 ShardingSphere Migration)确保数据一致性
- 监控运维:实时监控分片数据分布、查询性能,及时调整策略
三、Spring Cloud 性能优化综合实践
3.1 缓存与分库分表结合架构

3.2 核心优化策略总结
-
缓存优化
- 采用 "布隆过滤器 + 缓存空值" 解决穿透问题
- 采用 "互斥锁 + 热点 key 永不过期" 解决击穿问题
- 采用 "TTL 随机化 + 多级缓存 + 集群" 解决雪崩问题
- 监控缓存命中率、过期率,及时调整策略
-
数据库优化
- 先垂直拆分,再水平拆分
- 选择合适的分片键,确保数据均匀分布
- 使用成熟中间件(如 ShardingSphere)降低开发复杂度
- 解决跨库事务、跨库查询等关键问题
-
综合优化
- 缓存与分库分表结合,最大化提升系统性能
- 配合限流、熔断、降级等手段,确保系统稳定性
- 建立完善的监控体系,及时发现并解决性能瓶颈
四、总结与展望
本文深入剖析了 Spring Cloud 微服务中缓存穿透、击穿、雪崩三大问题的解决方案,并系统讲解了数据库分库分表入门知识。在实际应用中,需根据业务场景选择合适的优化策略,缓存与分库分表结合使用,才能最大化提升系统性能。
随着云原生技术发展,Spring Cloud 性能优化将朝着自动化、智能化方向发展,如基于 AI 的缓存策略调整、自适应分库分表等。持续关注技术发展,不断优化系统架构,是每个 Spring Cloud 开发者的必修课。