一、背景
在生产环境下,我们搭建了Flink-k8s集群,为不同项目用户的Flink作业运行提供了实时计算资源。为了避免主机房发生不可抗力故障(断电、网络分区、硬件批量损坏)而引发状态丢失或数据不一致问题,我们需要建设Flink集群的容灾备份能力,即建设灾备机房的Flink-k8s集群、主机房Flink集群作业的状态备份同步。
在灾备机房搭建Flink-k8s集群很容易,主要是实现整个Flink集群作业状态数据的定期、可靠、高效地同步至备机房,便于容灾切换后用户的Flink作业在灾备机房仍然有可用的Checkpoint/Savepoint进行快速恢复。当前Flink作业的状态后端使用HDFS,不同用户拥有各自独立的 CP/SP 存储路径(hdfs:///flink/cp/{user}/{job_id}/、hdfs:///flink/sp/{user}/{job_id}/)。
二、状态同步方案
在技术评估阶段,我们对比了以下两种方案:
| 方案 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| DistCp 直接拷贝 | Hadoop MapReduce 分布式复制 | 实现简单 | 复制期间数据可能不一致或被清理;大量小文件性能差 |
| HDFS 快照 + DistCp | 先创建一致性快照,再增量同步 | 数据一致性强;支持增量同步 | 需要快照权限管理 |
最后基于一致性与稳定性考量,选择了HDFS 快照 + DistCp 增量同步方案。
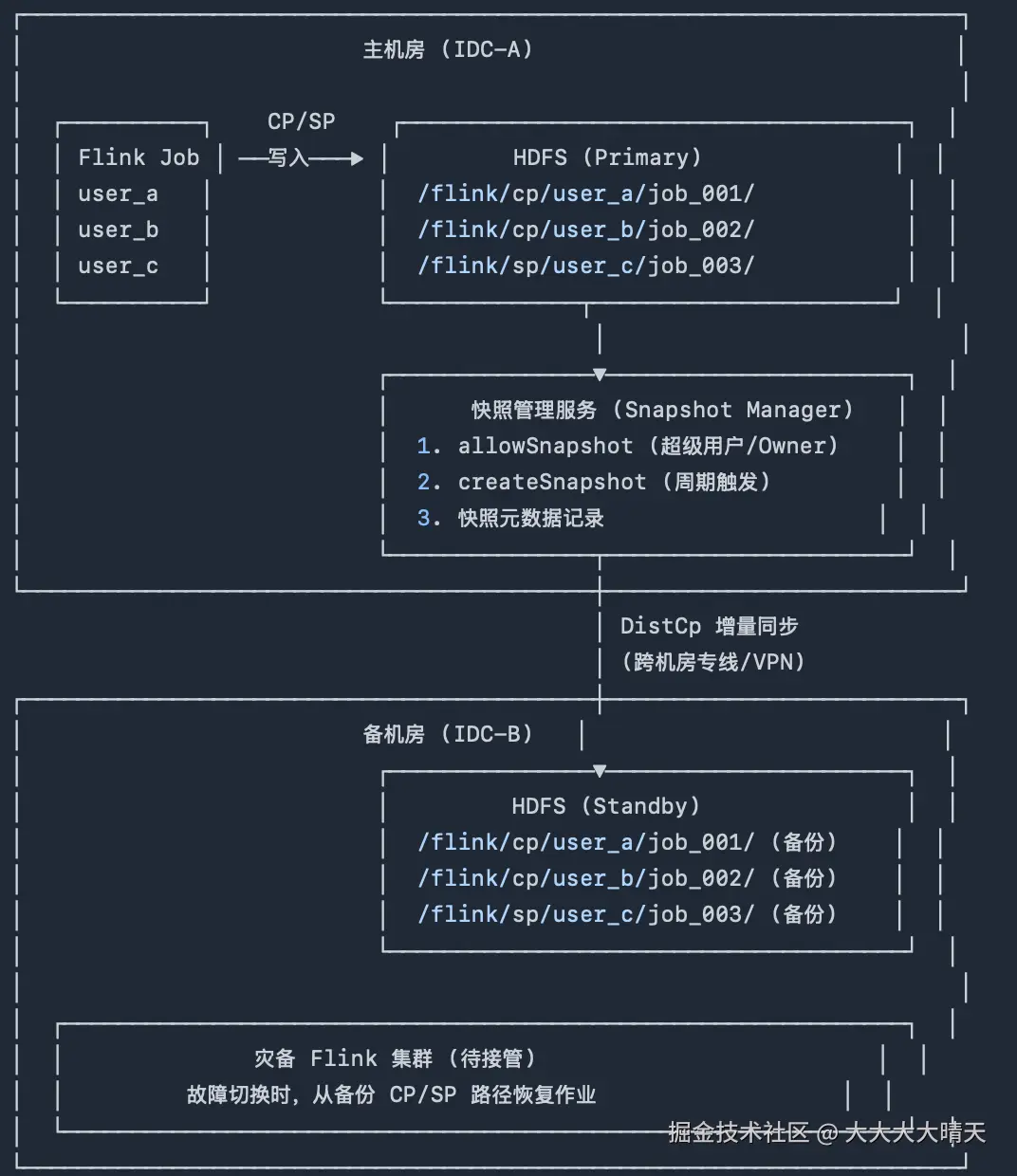
核心流程如下:
csharp
定时调度器
│
▼
[Step 1] 扫描所有用户的 CP/SP 目录清单
│
▼
[Step 2] allowSnapshot ------ 对目标目录开启快照功能(需超级用户)
│
▼
[Step 3] createSnapshot ------ 创建时间点快照(需目录 Owner 权限)
│
▼
[Step 4] DistCp 增量同步快照数据至备机房
│
▼
[Step 5] 清理过期快照(保留最近 N 个)
│
▼
[Step 6] 记录同步元数据 & 告警上报三、问题描述
在多用户平台中,我们使用一个统一的备份服务账号(如 backup_service)来执行所有用户目录的快照创建操作。测试时遭遇如下报错:
- 对他人目录执行 createSnapshot
ruby
# 当前执行用户:backup_service
# 目标目录 Owner:user_a
$ hdfs dfs -createSnapshot /flink/cp/user_a/job_001 snap_20260501
# 报错输出:
org.apache.hadoop.security.AccessControlException:
createSnapshot: Permission denied: user=backup_service,
access=EXECUTE, inode="/flink":hadoop:supergroup:drwx------- 为用户增加/flink目录递归读与执行权限后执行createSnapshot
ruby
# 当前执行用户:backup_service
# 目标目录 Owner:user_a
$ hdfs dfs -createSnapshot /flink/cp/user_a/job_001 snap_20260501
# 报错输出:
org.apache.hadoop.security.AccessControlException:
createSnapshot: Permission denied: user=backup_service is not the owner of inode=/flink/cp/user_a/job_001四、问题分析
通过查阅Hadoop源码发现,HDFS 路径遍历需要每一级父目录的execute(x)权限。用户backup_service要访问/flink/cp/user_a/job_001,必须先经过/flink目录。但/flink 的权限是drwx------,即只有 owner(hadoop) 有权限,backup_service既不是 owner 也不在supergroup组中,所以连遍历/flink的资格都没有------直接被挡在门口。
另外,createSnapshot操作还需要对目标目录/flink/cp/user_a/job_001有写权限,而且必须是目录的 Owner,但超级用户例外,完整的权限检查流程在FSDirectory.checkPermission()中执行。
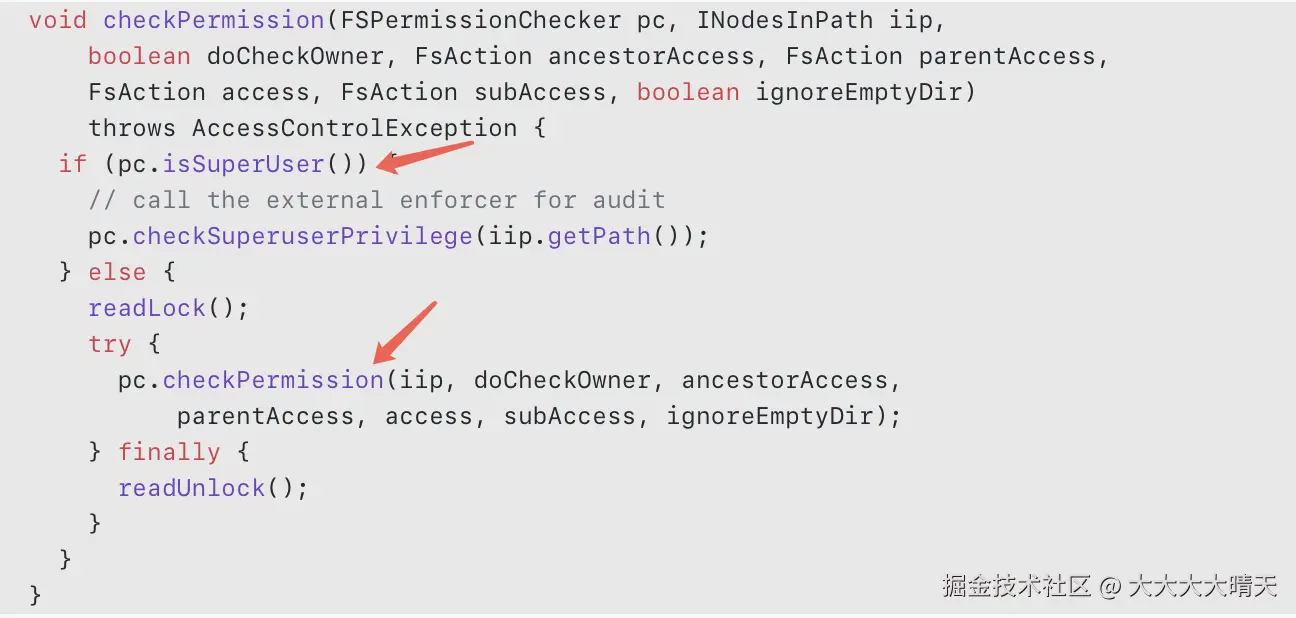
在权限检查过程中,系统会调用checkOwner()来验证用户是否为目录所有者:

问题总结:多租户场景下,各用户拥有各自 CP/SP 目录的 Owner 权限,统一备份服务账号(backup_service)既不是相关目录的 Owner,也不具备 HDFS 超级用户权限,导致 createSnapshot 操作的 checkOwner() 校验失败。
五、解决方案
- 方案一:变更目录 Owner(chown 方案)-- 将所有 CP/SP 目录的 Owner 统一变更为备份服务账号。
- 方案二:备份服务使用超级用户身份(Superuser 方案)-- 赋予备份服务账号 HDFS 超级用户权限,直接绕过 Owner 检查。
- 方案三:代理用户机制(Proxy User / Impersonation)-- 利用 Hadoop 的 代理用户(Proxy User) 机制,允许备份服务账号以各业务用户的身份执行操作,既保留业务用户的目录 Owner 权限,又无需赋予备份账号超级用户权限。
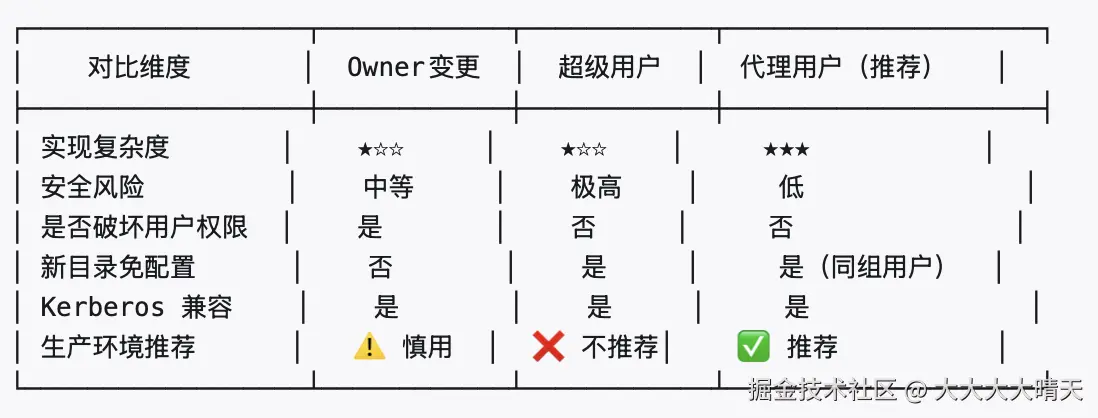
基于用户权限与安全风险考虑,我们选择了代理用户的方案进行实施,需要在core-site.xml中配置代理权限,并在客户端程序中使用代理用户机制创建快照:
xml
<!-- 允许 backup_svc 代理哪些用户 -->
<property>
<name>hadoop.proxyuser.backup_svc.users</name>
<value>user_a,user_b,user_c</value>
</property>
<!-- 允许 backup_svc 从哪些主机发起代理请求 -->
<property>
<name>hadoop.proxyuser.backup_svc.hosts</name>
<value>backup-node01.example.com</value>
</property>
<!-- 允许 backup_svc 代理哪些组(可与 users 配合使用) -->
<property>
<name>hadoop.proxyuser.backup_svc.groups</name>
<value>business_group</value>
</property>