目录
[10.3 动态链接与动态库的加载](#10.3 动态链接与动态库的加载)
[10.3.1 进程如何看待动态库](#10.3.1 进程如何看待动态库)
[10.3.2 进程间如何共享库的](#10.3.2 进程间如何共享库的)
[10.3.3 动态链接](#10.3.3 动态链接)
[10.3.3.1 概要](#10.3.3.1 概要)
[10.3.3.2 我们的可执行程序被编译器动了手脚](#10.3.3.2 我们的可执行程序被编译器动了手脚)
[10.3.3.3 动态库中的相对地址](#10.3.3.3 动态库中的相对地址)
[10.3.3.4 我们的程序,怎么和库具体映射起来的](#10.3.3.4 我们的程序,怎么和库具体映射起来的)
[10.3.3.5 我们的程序,怎么进行库函数调用](#10.3.3.5 我们的程序,怎么进行库函数调用)
[10.3.3.6 全局偏移量表GOT(global offset table)](#10.3.3.6 全局偏移量表GOT(global offset table))
[10.3.3.7 库间依赖(简单说明)](#10.3.3.7 库间依赖(简单说明))
[10.3.4 总结](#10.3.4 总结)
10.3 动态链接与动态库的加载
10.3.1 进程如何看待动态库
为什么之前不谈,进程是如何看待静态库的??
因为静态库就是将 .o 打了个包,程序一旦运行时,就跟静态库没有关联了,运行时就变为进程,在进程的视角中看不到所谓的静态库,也不需要看到,静态库的代码已经融合到自己形成的可执行程序了。所以不用研究进程和静态库之间的关系。
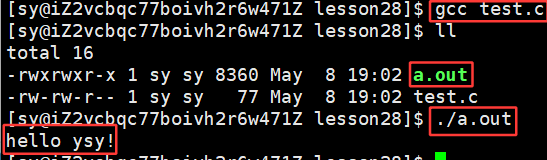
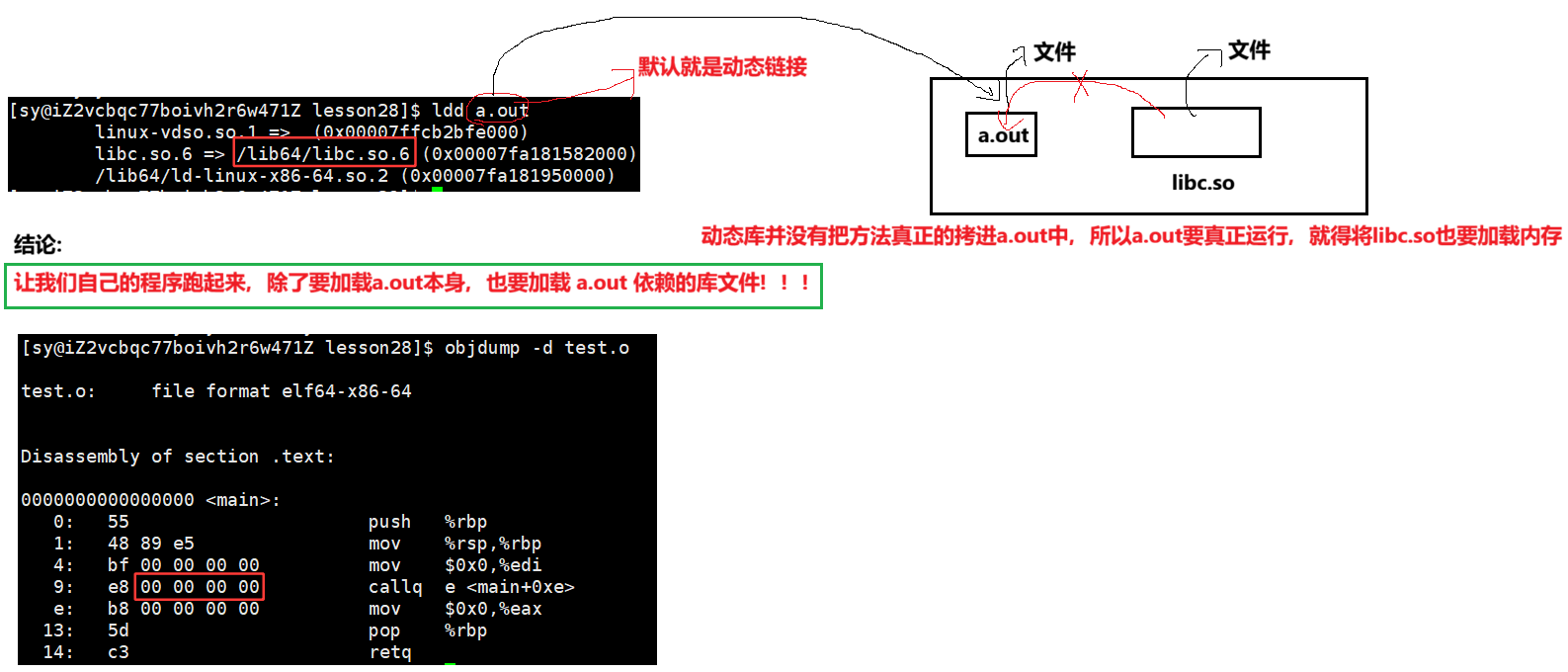
进程如何看待动态库的?
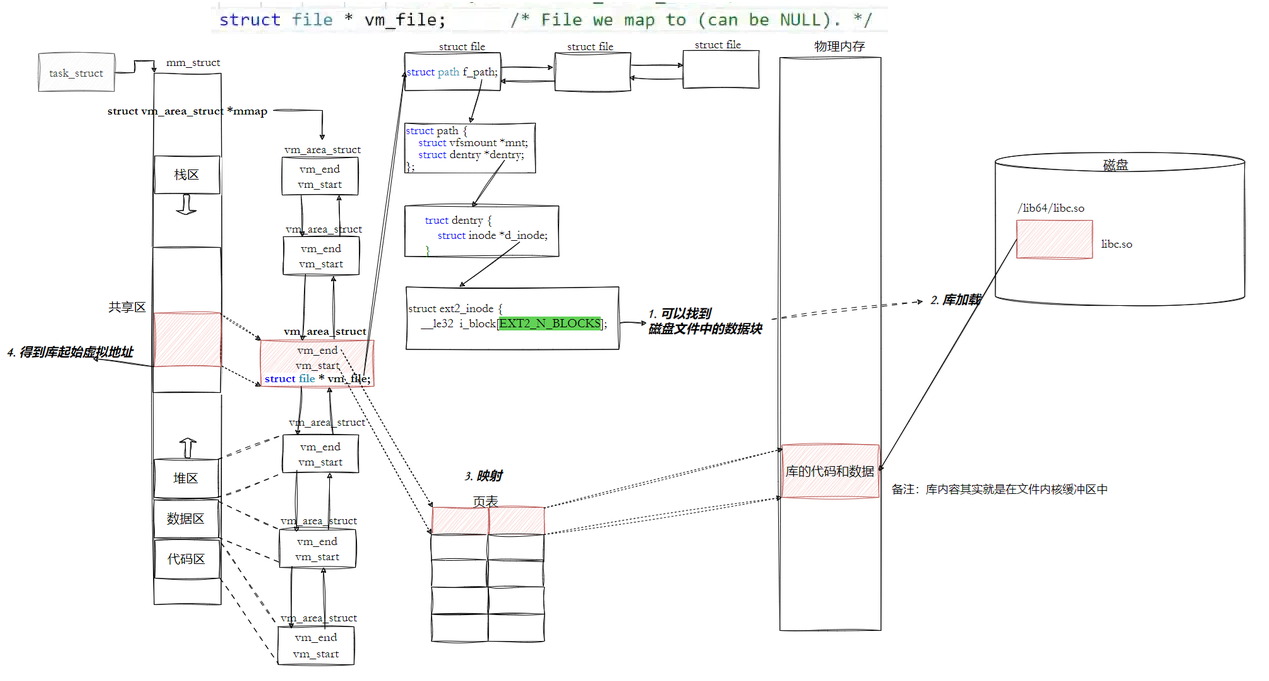
图片:
库也是ELF的,也是有自己的虚拟地址,库加载时有对应的物理地址,进程A如何看到动态库呢?本质上是在进程A的共享区(堆栈之间的共享区),把我们的动态库映射到堆栈之间。所以,进程A想看到动态库的步骤:1.将动态库加载到内存中 2. 构建映射 3. 映射到共享区中
宏观上的理解(先忽略细节)
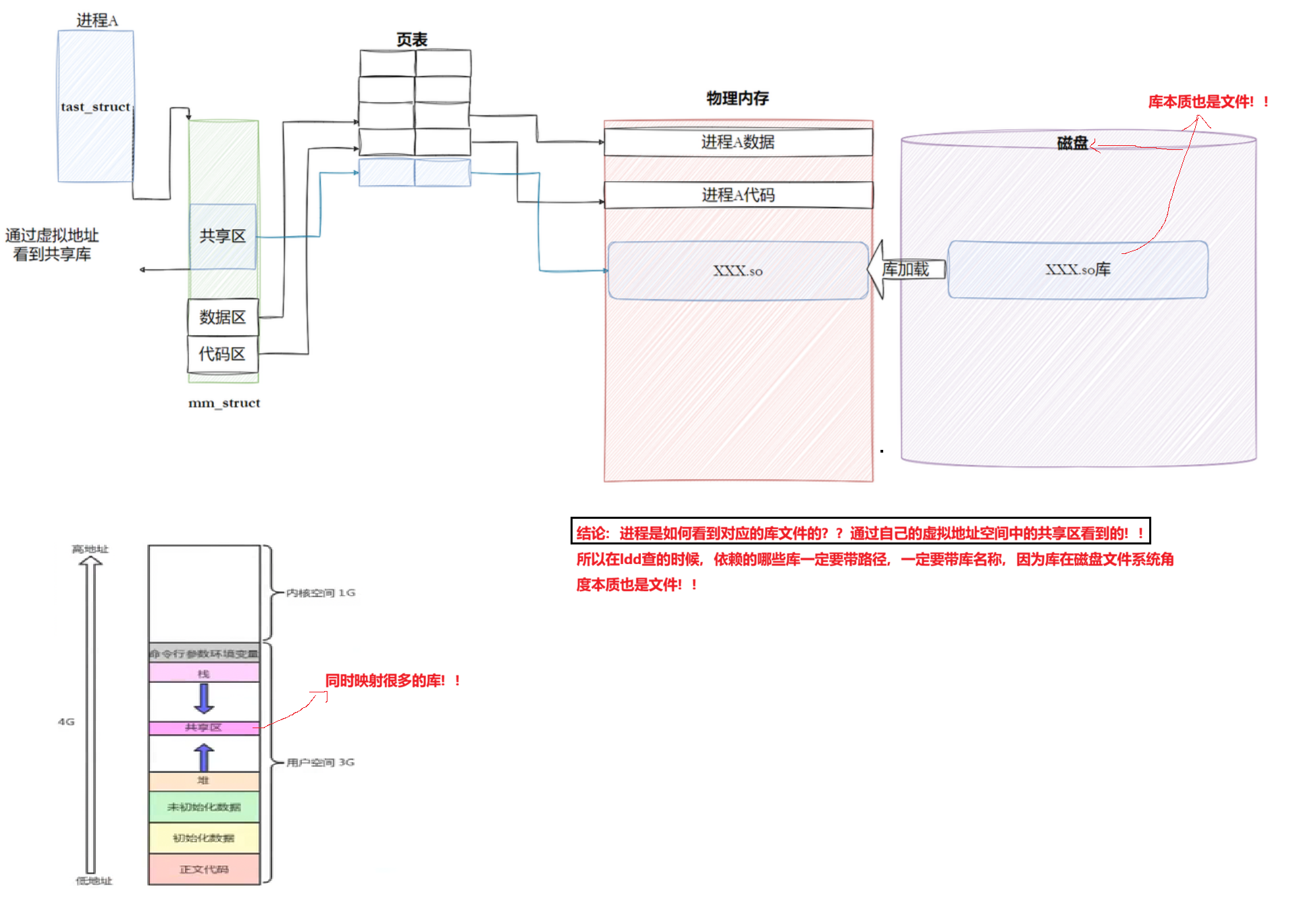
10.3.2 进程间如何共享库的
ls、top、whoami 多个进程依赖C标准库,将多个命令同时运行,多个命令同时运行就变成进程了,是如何做到多进程看到对应的库呢?
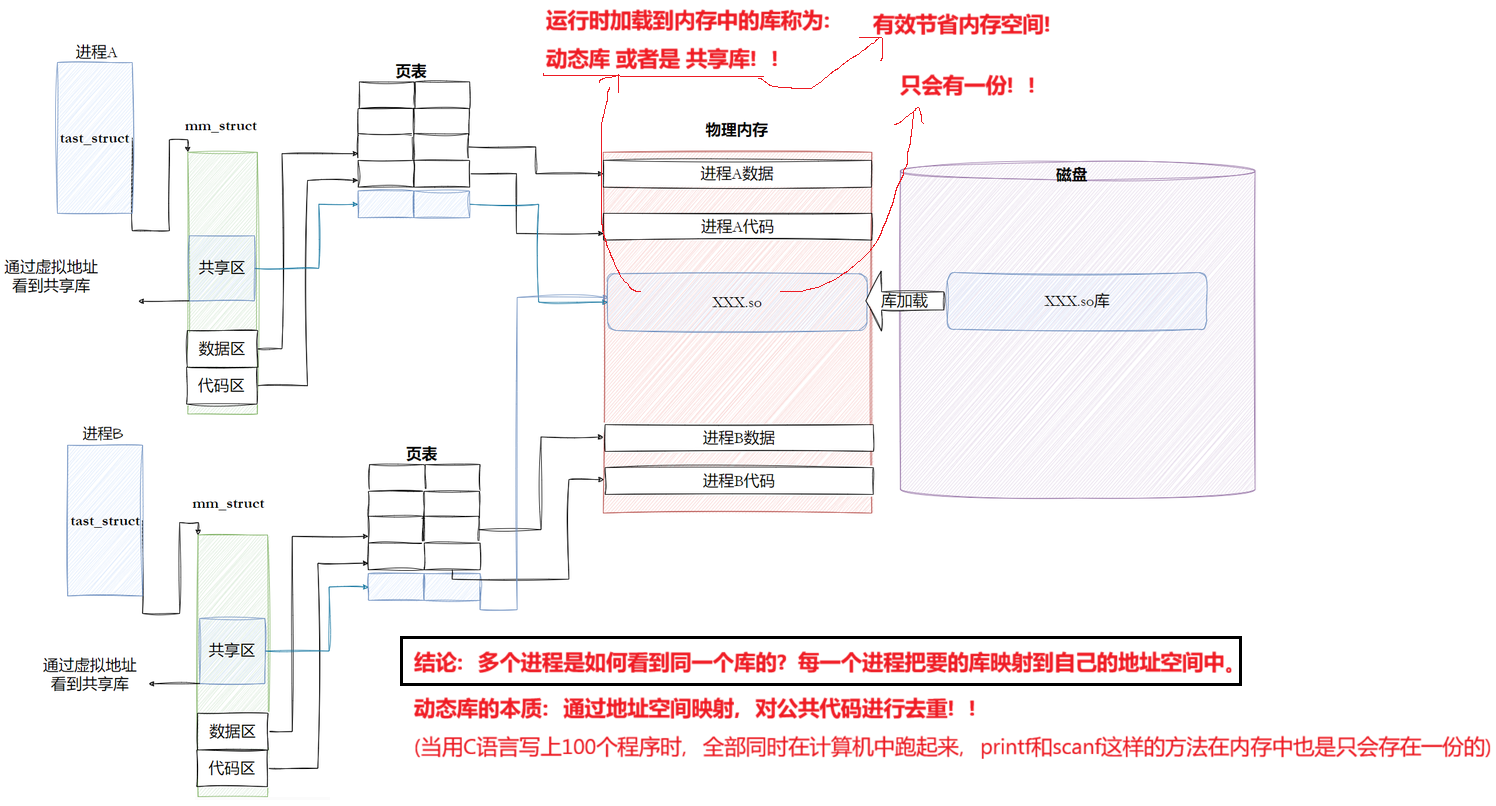
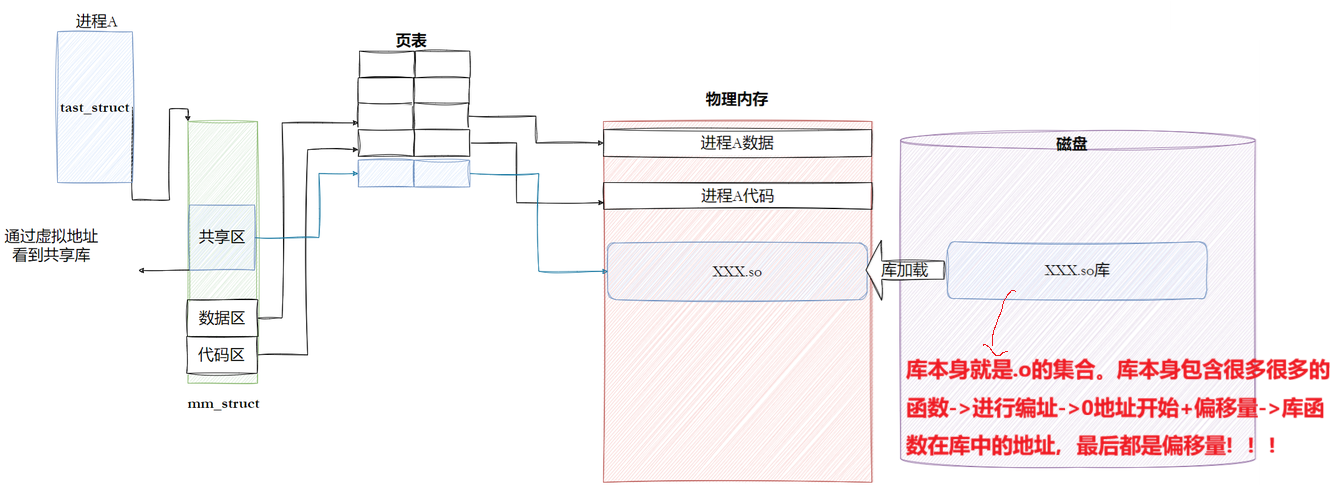
对上图中的红色字的解释:
10.3.3 动态链接
10.3.3.1 概要
动态链接其实远比静态链接要常⽤得多。⽐如我们查看下 hello 这个可执行程序依赖的动态库,会发现它就⽤到了⼀个c动态链接库:

这⾥的 libc.so 是C语⾔的运⾏时库,⾥⾯提供了常⽤的标准输⼊输出⽂件字符串处理等等这些功能。
那为什么编译器默认不使⽤静态链接呢?静态链接会将编译产⽣的所有目标⽂件,连同⽤到的各种库,合并形成⼀个独⽴的可执行⽂件,它不需要额外的依赖就可以运行。照理来说应该更加⽅便才对是吧?
**静态链接最⼤的问题在于生成的文件体积大,并且相当耗费内存资源。**随着软件复杂度的提升,我们的操作系统也越来越臃肿,不同的软件就有可能都包含了相同的功能和代码,显然会浪费⼤量的硬盘
空间。
这个时候,动态链接的优势就体现出来了,我们可以将需要共享的代码单独提取出来,保存成⼀个独⽴的动态链接库,等到程序运⾏的时候再将它们加载到内存,这样不但可以节省空间,因为同⼀个模块在内存中只需要保留⼀份副本,可以被不同的进程所共享。
动态链接到底是如何⼯作的??
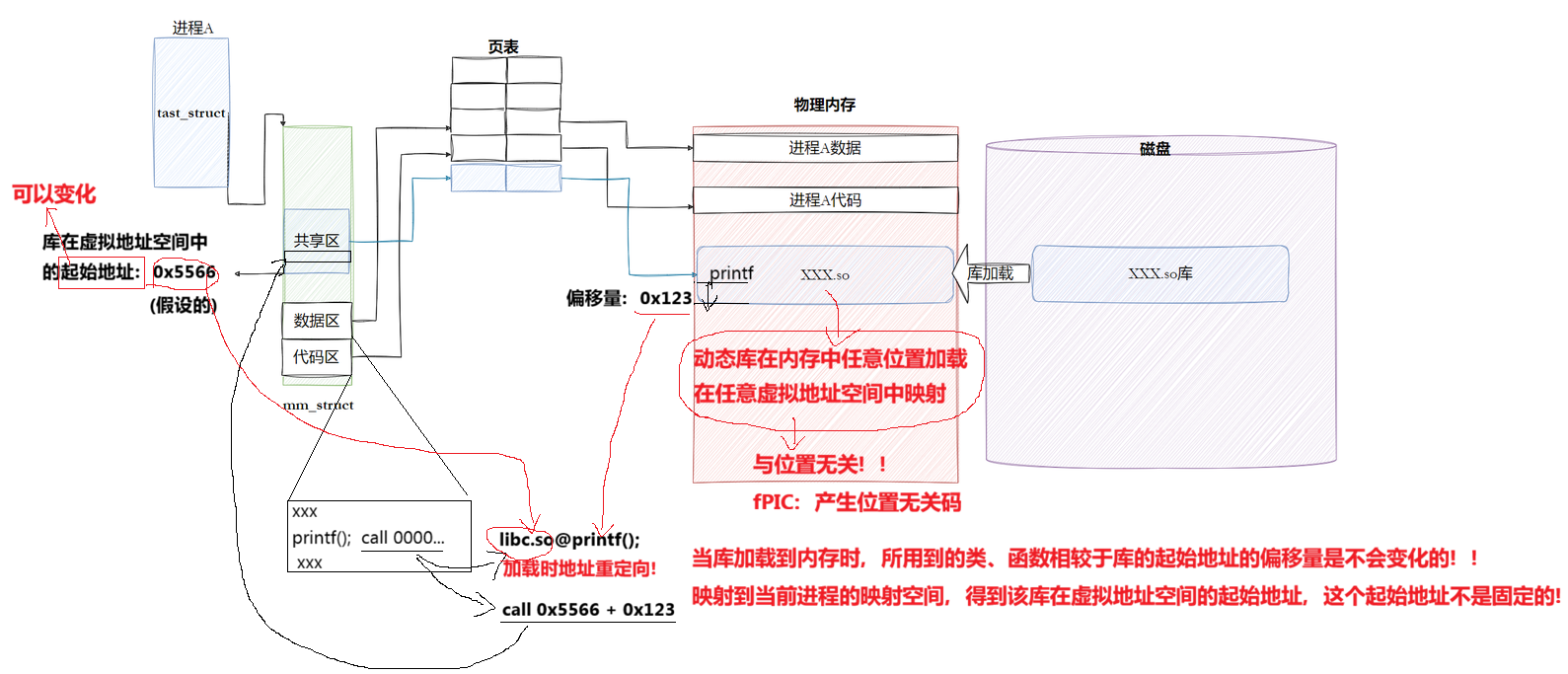
⾸先要交代⼀个结论,**动态链接实际上将链接的整个过程推迟到了程序加载的时候。**比如我们去运行⼀个程序,操作系统会⾸先将程序的数据代码连同它⽤到的⼀系列动态库先加载到内存,其中每个动态库的加载地址都是不固定的,操作系统会根据当前地址空间的使⽤情况为它们动态分配⼀段内存。
当动态库被加载到内存以后,⼀旦它的内存地址被确定,我们就可以去修正动态库中的那些函数跳转地址了。
10.3.3.2 我们的可执行程序被编译器动了手脚
在C/C++程序中,当程序开始执⾏时,它⾸先并不会直接跳转到 main 函数。实际上,程序的人口点是 _start ,这是⼀个由C运⾏时库(通常是glibc)或链接器(如ld)提供的特殊函数。
在 _start 函数中,会执行⼀系列初始化操作,这些操作包括:
-
设置堆栈:为程序创建⼀个初始的堆栈环境。
-
初始化数据段:将程序的数据段(如全局变量和静态变量)从初始化数据段复制到相应的内存位置,并清零未初始化的数据段。
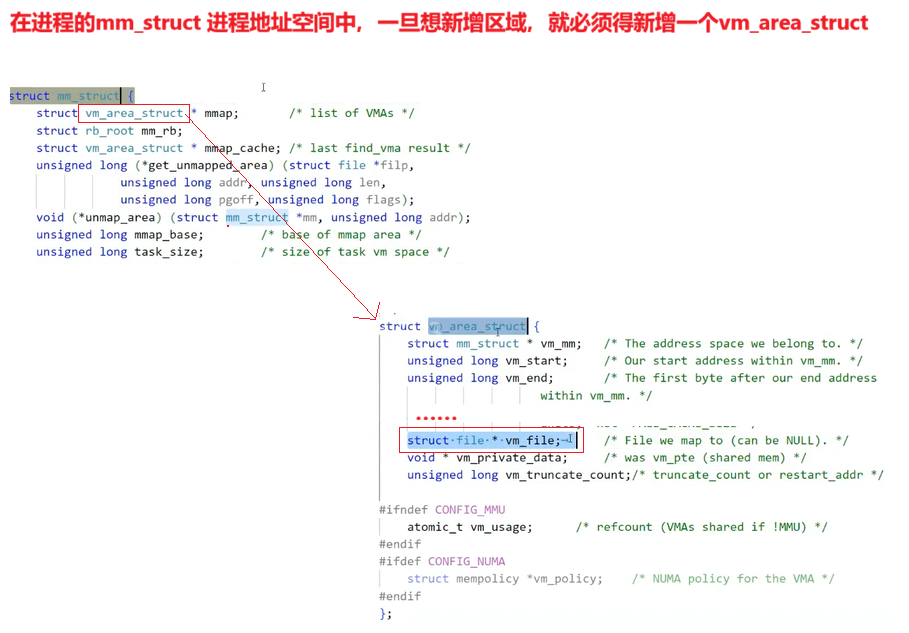
3. 动态链接:这是关键的一步, _start 函数会调用动态链接器的代码来解析和加载程序所依赖的动态库(shared libraries)。动态链接器会处理所有的符号解析和重定位,确保程序中的函数调用和变量访问能够正确地映射到动态库中的实际地址。

10.3.3.3 动态库中的相对地址
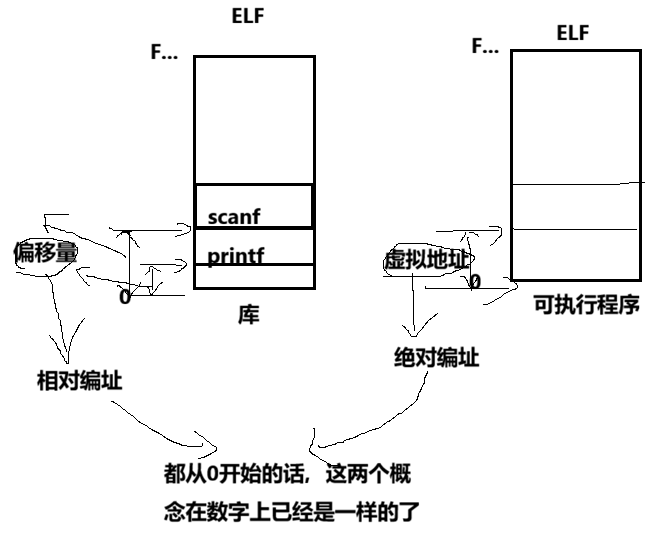
动态库为了随时进行加载,为了支持并映射到任意进程的任意位置,对动态库中的方法,统一编址,采用相对编址的方案进行编址的(其实可执行程序也一样,都要遵守平坦模式,只不过exe是直接加载的。)
命令:
bash
#Centos下查看任意一个库的反汇编
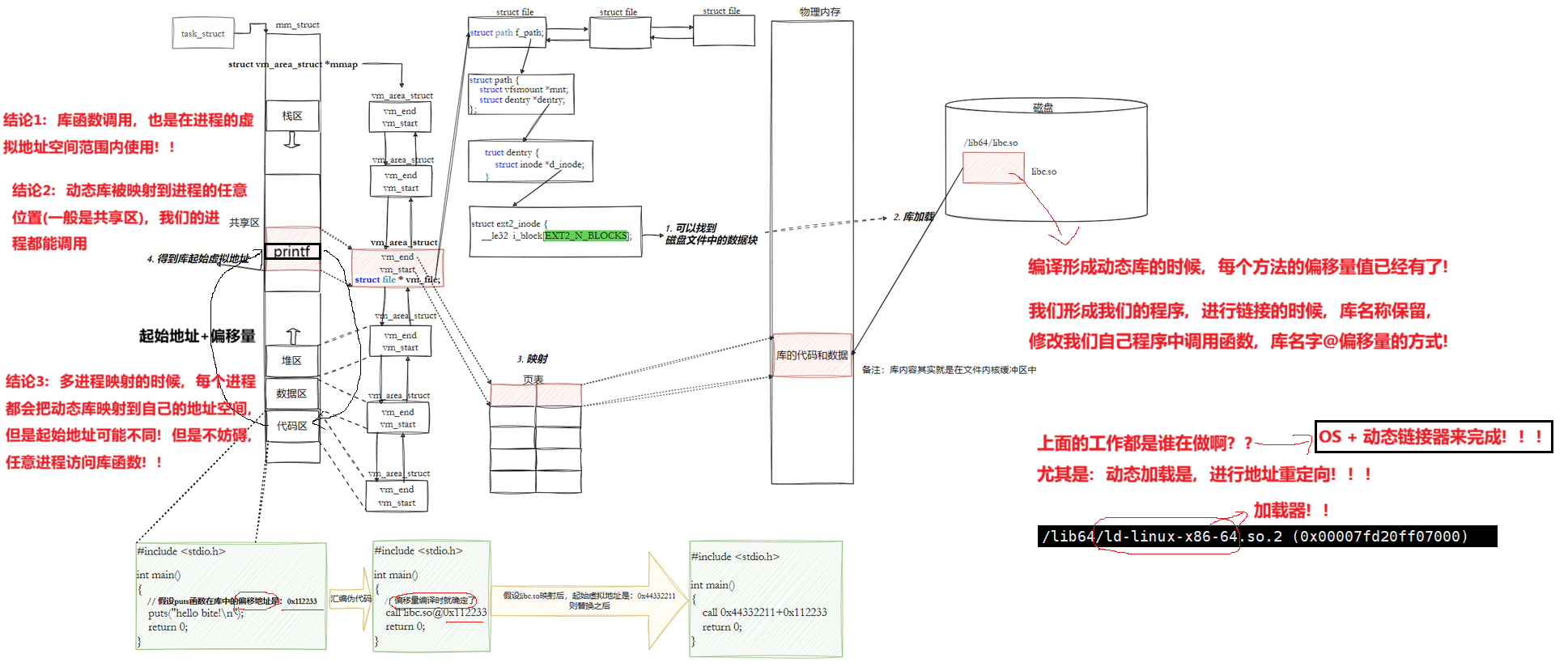
objdump -S /lib64/libc-2.17.so | less10.3.3.4 我们的程序,怎么和库具体映射起来的
10.3.3.5 我们的程序,怎么进行库函数调用
注意:
- 库已经被我们映射到了当前进程的地址空间中
- 库的虚拟起始地址我们也已经知道了
- 库中每⼀个方法的偏移量地址我们也知道
- 所有:访问库中任意方法,只需要知道库的起始虚拟地址+方法偏移量即可定位库中的方法
- 而且:整个调用过程,是从代码区跳转到共享区,调用完毕在返回到代码区,整个过程完全在进程地址空间中进行的.
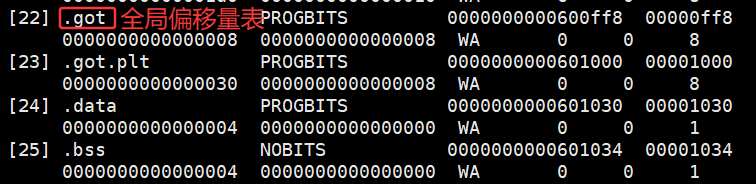
10.3.3.6 全局偏移量表GOT(global offset table)
注意:
- 也就是说,我们的程序运行之前,先把所有库加载并映射,所有库的起始虚拟地址都应该提前知道
- 然后对我们加载到内存中的程序的库函数调⽤进⾏地址修改,在内存中⼆次完成地址设置 (这个叫做加载地址重定位)
- 修改的是代码区?不是说代码区在进程中是只读的吗?怎么修改?能修改吗?

所以:动态链接采用的做法是在 .data (可执⾏程序或者库⾃⼰)中专门预留一片区域⽤来存放函数的跳转地址,它也被叫做全局偏移表GOT,表中每⼀项都是本运行模块要引用的⼀个全局变量或函数
的地址。
- 因为.data区域是可读写的,所以可以⽀持动态进⾏修改
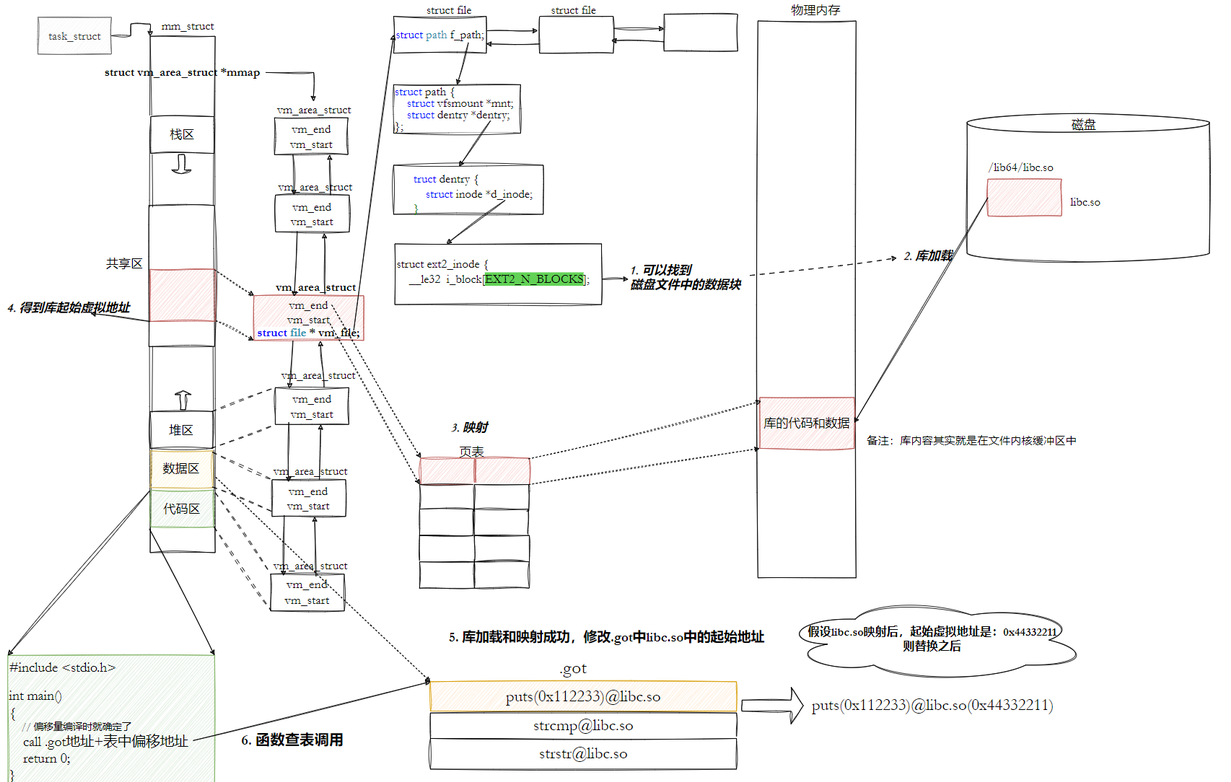
- 由于代码段只读,我们不能直接修改代码段。但有了GOT表,代码便可以被所有进程共享。但在不同进程的地址空间中,各动态库的绝对地址、相对位置都不同。反映到GOT表上,就是每个进程的每个动态库都有独立的GOT表,所以进程间不能共享GOT表。
- 在单个.so下,由于GOT表与 .text 的相对位置是固定的,我们完全可以利用CPU的相对寻址来找到GOT表。
- 在调用函数的时候会⾸先查表,然后根据表中的地址来进⾏跳转,这些地址在动态库加载的时候会被修改为真正的地址。
- 这种⽅式实现的动态链接就被叫做 PIC 地址⽆关代码 。换句话说,我们的动态库不需要做任何修改,被加载到任意内存地址都能够正常运⾏,并且能够被所有进程共享,这也是为什么之前我们给编译器指定-fPIC参数的原因,PIC=相对编址+GOT。

bash
$ objdump -S a.out
...
0000000000001050 <puts@plt>:
1050: f3 0f 1e fa endbr64
1054: f2 ff 25 75 2f 00 00 bnd jmpq *0x2f75(%rip) #
3fd0 <puts@GLIBC_2.2.5>
...
...
0000000000001149 <main>:
1149: f3 0f 1e fa endbr64
114d: 55 push %rbp
114e: 48 89 e5 mov %rsp,%rbp
1151: 48 8d 3d ac 0e 00 00 lea 0xeac(%rip),%rdi
# 2004 <_IO_stdin_used+0x4>
1158: e8 f3 fe ff ff callq 1050 <puts@plt>
...10.3.3.7 库间依赖(简单说明)
注意:
- 不仅仅可执行程序会调用库
- 库也会调用其他库!!(不管是什么库,不管是什么可执行程序,也是ELF格式的,也有一个数据节 .GOT,库本身也有自己的GOT表,GOT表建立的是它调用的其它库的方法的偏移量+他所依赖的库的地址。) 库之间是有依赖的,如何做到库和库之间相互调用也是与地址无关的呢?
- 库中也有.GOT,和可执行一样!(当此进程有10个库的时候,10个库的起始虚拟地址是不一样的,绝对不重叠!)这也就是为什么大家都是ELF格式!
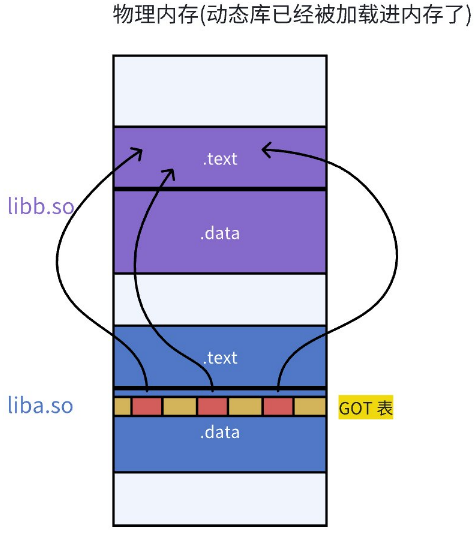
- 由于GOT表中的映射地址会在运行时去修改,我们可以通过gdb调试去观察GOT表的地址变化。在这⾥我们只用知道原理即可,有兴趣的同学可以参考:使用gdb调试GOT
由于动态链接在程序加载的时候需要对⼤量函数进行重定位,这⼀步显然是非常耗时的。为了进⼀步降低开销,我们的操作系统还做了⼀些其他的优化,比如延时绑定,或者也叫PLT(过程连接表(Procedure Linkage Table))。与其在程序⼀开始就对所有函数进行重定位,不如将这个过程推迟到函数第⼀次被调⽤的时候,因为绝⼤多数动态库中的函数可能在程序运行期间⼀次都不会被使用到。(延迟绑定可以提高加载时的效率)
思路是:GOT中的跳转地址默认会指向⼀段辅助代码,它也被叫做桩代码/stup。在我们第⼀次调用函数的时候,这段代码会负责查询真正函数的跳转地址,并且去更新GOT表。于是我们再次调用函数的时候,就会直接跳转到动态库中真正的函数实现。
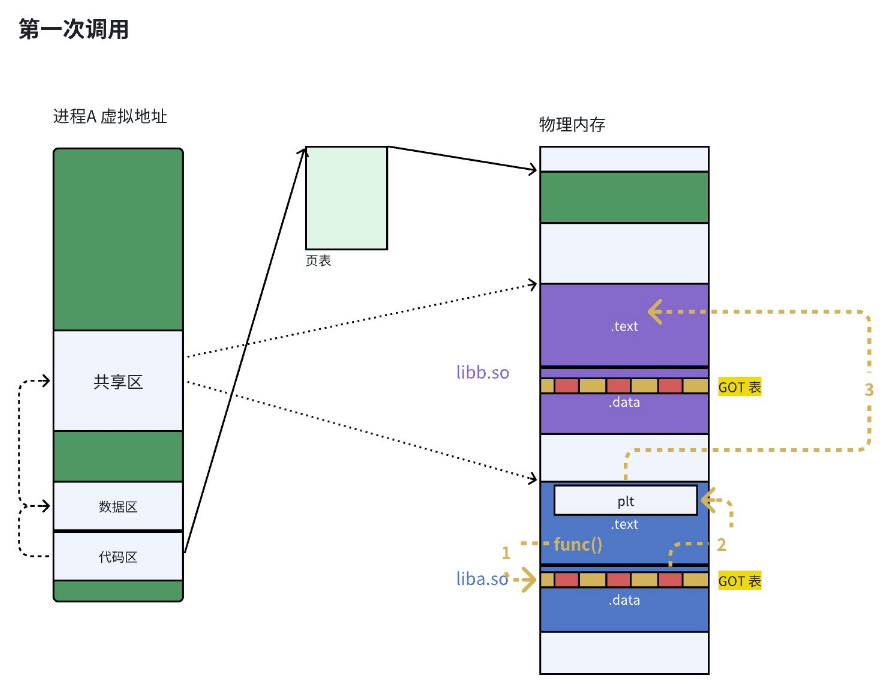
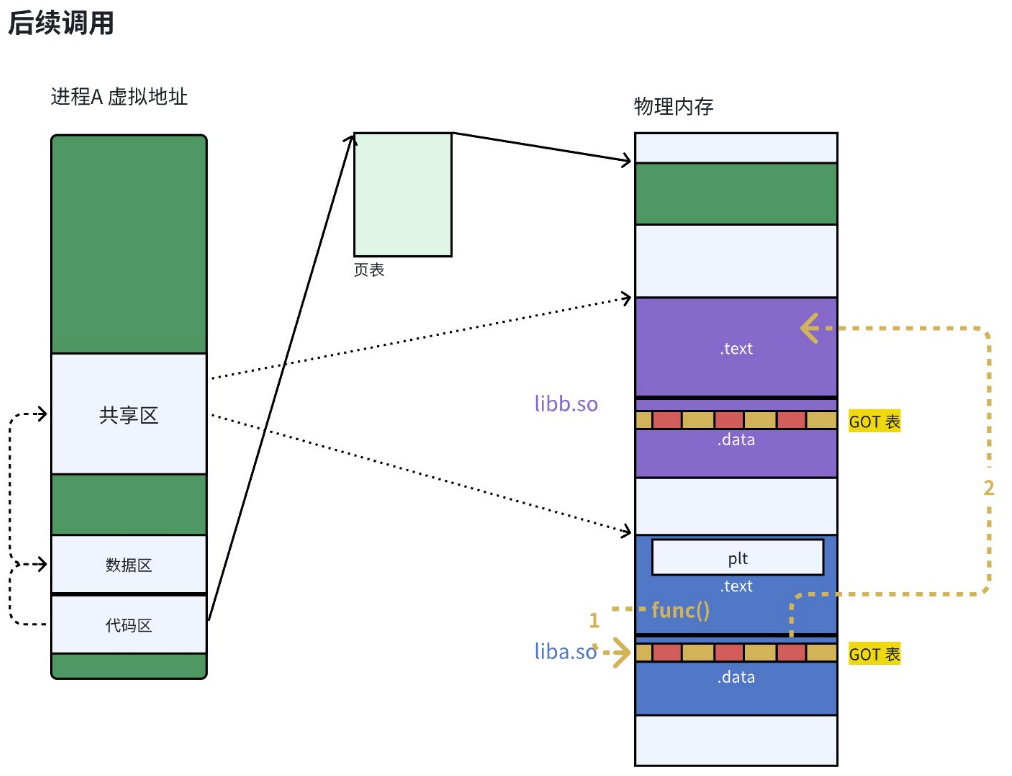
总而言之,动态链接实际上将链接的整个过程,⽐如符号查询、地址的重定位从编译时推迟到了程序的运行时,它虽然牺牲了⼀定的性能和程序加载时间,但绝对是物有所值的。因为动态链接能够更有效的利用磁盘空间和内存资源,以极大方便了代码的更新和维护,更关键的是,它实现了⼆进制级别的代码复用。
解析依赖关系的时候,就是加载并完善互相之间的GOT表的过程。
10.3.4 总结
- 静态链接的出现,提高了程序的模块化水平。对于⼀个大的项目,不同的人可以独⽴地测试和开发自己的模块。通过静态链接,⽣成最终的可执行文件。
- 我们知道静态链接会将编译产⽣的所有⽬标⽂件,和⽤到的各种库合并成⼀个独⽴的可执行文件,其中我们会去修正模块间函数的跳转地址,也被叫做编译重定位(也叫做静态重定位)。
- 而动态链接实际上将链接的整个过程推迟到了程序加载的时候。⽐如我们去运⾏⼀个程序,操作系统会⾸先将程序的数据代码连同它⽤到的⼀系列动态库先加载到内存,其中每个动态库的加载地址都是不固定的,但是⽆论加载到什么地⽅,都要映射到进程对应的地址空间,然后通过.GOT方式进行调用运行重定位,也叫做动态地址重定位)。