本篇文章说的总线实际分为2种,CPU总线和总线矩阵;其中CPU总线是属于内核的(内核定死的),总线矩阵是每个芯片产商(如STM32/GD32)自己定的:
1.CPU总线
CPU出来有三根总线,分别为I-Code,D-Code和System 总线:
- I-Code,指令总线,专用于取指令,所以直连flash,没有经过总线矩阵,以达到极致的取指效率(不需要总线仲裁和绕路)
- D-Code,数据总线,专用于取数据,这里的数据主要就是指变量和栈,另外也负责了和私有外设(如NVIC,SCB,Systick,ITM,MPU)寄存器之间的通信;所以其也没有连接到总线矩阵上,而是连接到了自己专有的数据总线复用器上,该数据总线复用器再连接SRAM和私有外设
- System 总线,系统总线,他能访问外设和SRAM,实际上主要是用于访问外设,少部分情况会访问SRAM,如当程序指令存储在SRAM里时,由于-Code不能访问SRAM,所以需要通过系统总线来访问
2.总线矩阵
总线矩阵是不属于内核的,是每个产商自己定的,其连接了所有存储器和需要读写数据的对象,如SRAM、flash、外设寄存器、CPU总线和DMA等等,它的核心作用就是作为一个交通枢纽和指挥官,负责处理所有数据传输请求,如当有多个数据传输请求时,更具优先级先给某个传输分配带宽,因此通过总线矩阵取数据,会有个总线仲裁的时间开销和绕路的开销。
3.函数存在flash和SRAM里,哪个会更快
常规应该都会认为把函数放在SRAM里会更快,因为SRAM的读写速度比flash快很多(0等待),而flash通常需要5个时钟周期;但实际情况是大部分成熟的MCU(如STM32)都会有**Flash预取和缓存(ART Accelerator)功能,就是会提前把后续指令读到缓冲区,这样只要程序逻辑不会有太多的跳转,基本上都能被预取给命中,从而实现0等待;**然而存在SRAM里的话就不可避免的增加了绕路和总线仲裁的开销。所以一般来说放在flash里会更快。
4.STM32F1和F4的预取缓冲区的差别
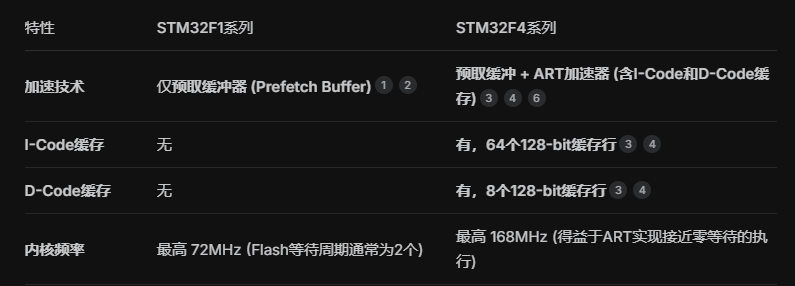

简单来说就是F1的预取缓冲区没有学习能力,只是简单的一次性读取4条指令到缓冲区,如果程序一旦发生跳转那读进去的就作废了,需要重新读取并造成读取等待。
5.关于DMA数据传输
DMA全称直接内存访问器,主要是用于内存和外设之间的数据传输的,有些情况也会用于内存和内存之间搬运数据;其作为一个通信单元挂在总线矩阵上,当有内存和外设之间的数据传输需要时,DMA会直接向总线矩阵发起传输请求并在获得总线带宽时完成传输,而不需要CPU通过系统总线读到内核再传输到SRAM,极大的节省了CPU资源。