Bright Data Web Scraper 实战:构建 TikTok 与 LinkedIn Web Scraping 自动化 Skill(2026)
一、数据采集维护趋于困难
我上一篇文章写的是 Bright Data MCP + Dify :把采集能力接进工作流,适合想快速做可视化编排的人。但继续往前做,我很快又遇到另一个现实问题:工作流能跑,不代表交付物好复用。当需求从"一次性获取"变成"团队内反复调用、换关键词继续跑、还需导出 HTML 报告"时就需要新的方案来实现。
当我真正研究过Bright Data相关实现方式后,把 Bright Data 的 Web Scraper API能力直接封成一个可复用的 skill成为了我新的目标。用这个skill我就不用反复手写提交任务、拿 snapshot、处理重试、再把结果转成给同事看的页面。如果你也想自己先跑通一遍,建议先注册 Bright Data 账号拿试用额度:Bright Data 注册链接。
这篇文章,我不再讲 Dify,而是讲另一条更适合工程化复用的路线:直接把 Bright Data Web Scraper API包装成自动化 skill 。这次我没有把 TikTok 和 LinkedIn 放入同一个目录,而是拆成两个独立 skill:collect-tiktok-by-keyword 和 collect-linkedin-company-by-url。前者负责 TikTok 关键词采集,后者负责 LinkedIn 公司主页 URL 采集,两者都支持 snapshot 下载和 HTML 预览。
二、为什么TikTok 与 LinkedIn的获取数据较难
如果你只抓一个站点,很多问题还能靠耐心顶住;一旦你同时碰 TikTok 和 LinkedIn,维护成本就会变得不可控。
| 平台 | 典型难点 | 一旦 DIY 的后果 |
|---|---|---|
| TikTok | 签名、设备指纹、访问环境、速率控制 | 脚本经常失效,字段结构也不稳定 |
| 登录墙、行为检测、页面动态渲染 | 账号/会话容易出问题,公开页抓取也不稳定 |
更麻烦的是,真正拖慢项目的往往不是"请求发不出去",而是拿回来的数据还不能直接交付。有人要JSON,有人要CSV,还有人只想先看一眼页面效果。你最后会发现,团队最缺的不是一个临时脚本,而是一个能把"发请求、等结果、下载、预览、沉淀"合并为统一流程的自动化层。
这也是我这次没有继续写"再来一个demo"的原因。我更想交付一个目录清晰、命令明确、拿走就能跑的 skill,而不是一篇看完就关掉的教程。
三、这次的核心思路:把 Web Scraper 封成 skill
这次我采用的结构很简单:一个 skill 目录 + 两个核心脚本 + 一个 HTML 模板 + 一份参考说明。它和上一篇 Dify 方案的区别在于:Dify 更像编排层,而这次的 skill 更像一个可复制、可打包、可交付的执行单元。
整体流程如下:
输入关键词 / 公司 URL
独立 Skill 入口
collect_tiktok_by_keyword.py / collect_linkedin_company_by_url.py
Bright Data Web Scraper API
Snapshot 下载
run-summary.json / snapshot.json
render_tiktok_html.py / render_linkedin_company_html.py
report.html
在当前仓库里,已经落地的 skill 目录是:
text
collect-tiktok-by-keyword/
├─ SKILL.md
├─ scripts/
│ ├─ collect_tiktok_by_keyword.py
│ └─ render_tiktok_html.py
├─ references/
│ └─ bright_data_tiktok_notes.md
└─ assets/
└─ report_template.html
collect-linkedin-company-by-url/
├─ SKILL.md
├─ scripts/
│ ├─ collect_linkedin_company_by_url.py
│ └─ render_linkedin_company_html.py
├─ references/
│ └─ bright_data_linkedin_company_notes.md
└─ assets/
└─ report_template.html这个结构的好处很明确:
- TikTok 和 LinkedIn 各自有独立脚本,不会因为参数、字段、数据集差异而互相污染。
- 两个 skill 的目录结构保持一致,后续维护和扩展更轻松。
references/里分别保留了 Bright Data 请求说明,便于回看请求形态和下载约定。
四、开始动手前,我准备了哪些最小条件
如果你想复现这套流程,需要准备的东西并不多:
-
Bright Data 账号 :建议直接从这里注册并领取试用额度:Bright Data 注册链接,输入折扣码leo20,可以领取20美元免费额度。
-
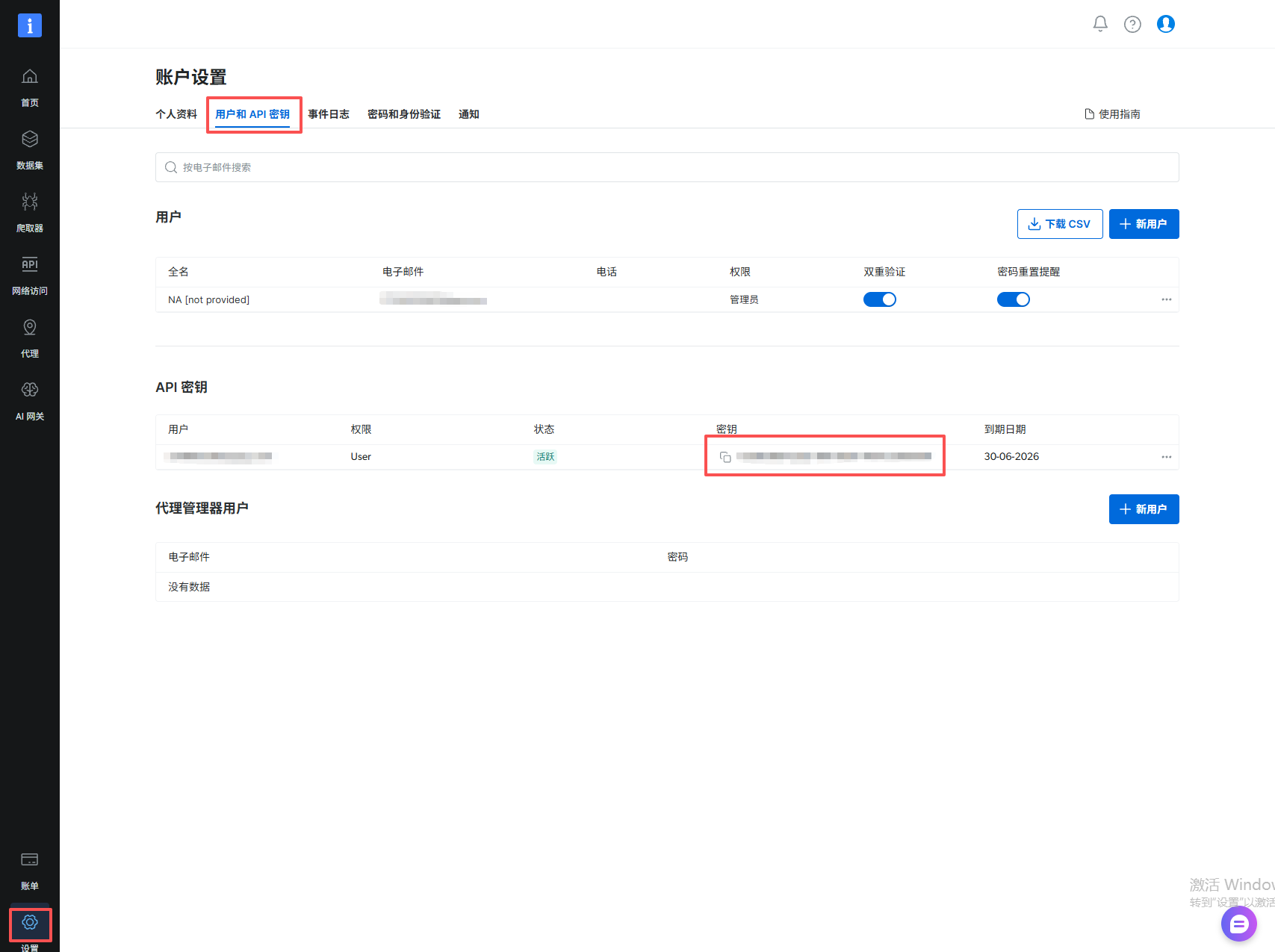
Bright Data API Token :文中统一用占位符
YOUR_BRIGHTDATA_API_KEY -
Python 环境 :本地能直接运行
python命令即可 -
本文配套 skill :当前是仓库中的
collect-tiktok-by-keyword/和collect-linkedin-company-by-url/ -
一个明确的采集目标 :比如 TikTok 的
music、#artist,或 LinkedIn 公司主页 URL
为了避免把凭证写进代码,我建议统一用环境变量:
powershell
$env:BRIGHT_DATA_TOKEN="YOUR_BRIGHTDATA_API_KEY"填写折扣码:
Api_key位置:
五、开发 TikTok 与LinkedIn Skill 教程
以下我介绍的教程,是针对 TikTok 的,LinkedIn 的实现原理也类似。
Step 1:创建统一入口
Bright Data Web Scraper API这一层,最适合收成一个脚本入口。当前 collect_tiktok_by_keyword.py 做的事情有三步:
- 接收
--keyword、--limit、--format、--output-dir等参数 - 调用 Bright Data 数据采集接口提交任务
- 从返回结果里拿到
snapshot_id,然后继续下载结果
调用方式我已经收成了一个命令:
powershell
python .\collect-tiktok-by-keyword\scripts\collect_tiktok_by_keyword.py ^
--keyword "music" ^
--limit 20 ^
--format json ^
--output-dir ".\outputs\tiktok-music" ^
--generate-html跑完之后,目录里会得到几类文件:
submission-response.json:提交任务后的原始响应snapshot.json/snapshot.csv:真正下载回来的数据run-summary.json:本次运行摘要report.html:适合直接截图或人工核验的预览页
这一步的意义是把"散装 API 调用"变成一个稳定入口。以后不管是人工手动跑、让 agent 跑,还是接进别的自动化流程,入口都统一了。
Step 2:把 snapshot 的等待、重试和下载逻辑封死
我以前写这类脚本时,最容易偷懒的地方就是:任务提交完就结束,剩下让人自己去查 snapshot。这样短期省事,但长期下来比较折磨人。
所以这个 skill 里直接包含下载的逻辑:
- 识别
snapshot_id - 生成下载 URL
- 在结果尚未就绪时按重试策略等待
- 把最终快照落盘到输出目录
这类逻辑一旦写死在 skill 里,用户就不用再理解 Bright Data 的完整任务生命周期,只需要自然语言描述就行。
Step 3:给数据加一个"可展示层",别让结果只停留在 JSON
真实团队协作里,总有人不想先看 JSON,只想先看效果。
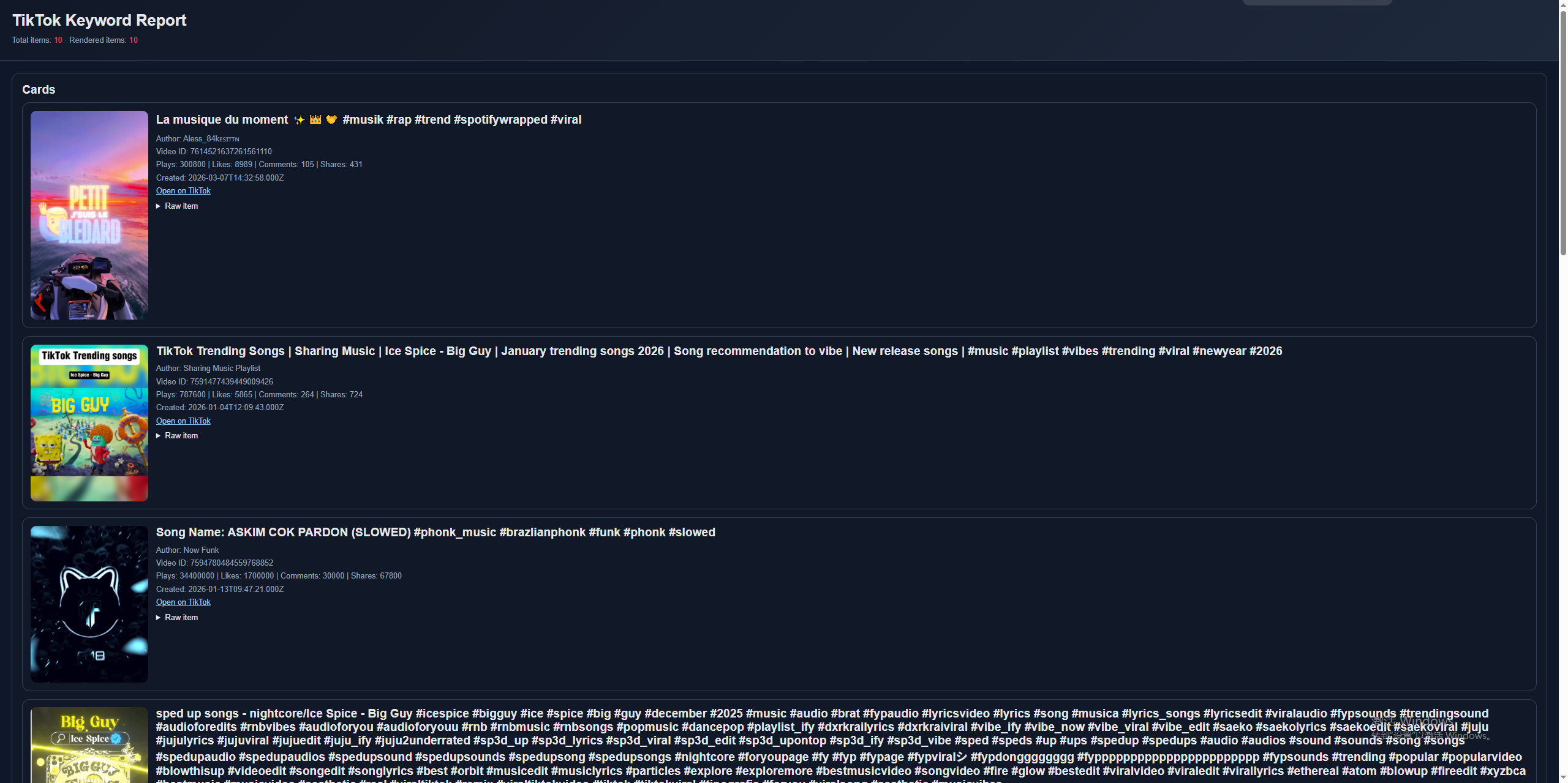
当前渲染器会从 snapshot 中优先提取这些字段:
- 内容标题:
desc/description - 作者:
author.unique_id/author.nickname - 互动指标:
statistics.digg_count、comment_count、share_count、play_count - 链接与封面:
share_url、video.cover.url_list.0
最后生成一个独立的 report.html。这非常适合做三件事:
- 自己先快速验收数据是否合理
- 给业务同事做第一次预览
- 直接截一张真实输出图放进文章或 README
Step 4:TikTok skill 结果演示
这里只展示 TikTok skill 的结果演示,LinkedIn skill 的结果演示类似。
可以直接输入:
json
用 collect-tiktok-by-keyword skill 采集 TikTok 数据:关键词 music,限制 10 条,下载 json 格式,同时生成 report.html 方便我查看结果。当 TikTok skill 跑完后,输出目录里通常会看到这几类文件:
submission-response.jsonsnapshot.jsonrun-summary.jsonreport.html
运行结果:
json数据:
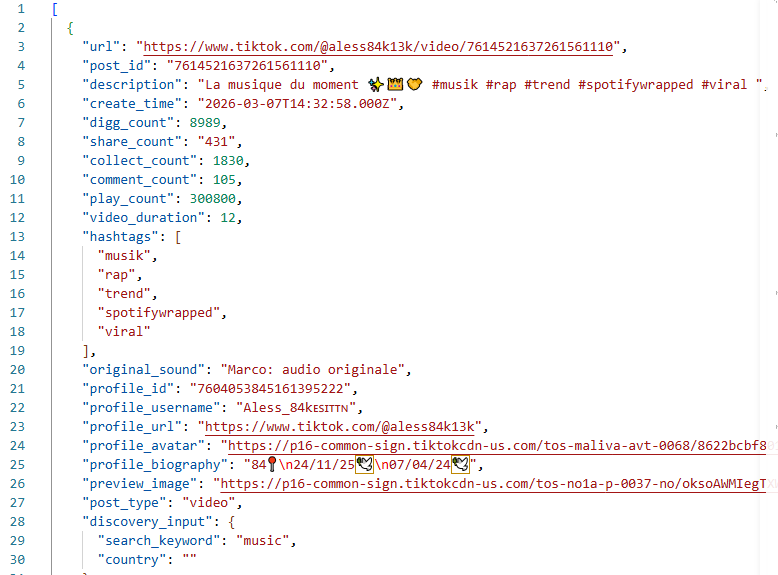
最终显示的html样式:
六、skill结构与使用教程
- GitHub Repo:linkedin-github链接,
tiktok-github链接 - Skill 目录:
collect-tiktok-by-keyword/、collect-linkedin-company-by-url/
使用非常简单只有三步:
- 放置或安装 ebay-product-search skill
- 配置
BRIGHT_DATA_TOKEN=YOUR_BRIGHTDATA_API_KEY - 用自然语言触发 skill,生成导出文件和 HTML 价格报告
文件列表如下:
| 文件 | 作用 |
|---|---|
SKILL.md |
Skill 的使用说明与触发场景 |
scripts/collect_tiktok_by_keyword.py |
提交任务、获取 snapshot、下载结果 |
scripts/render_tiktok_html.py |
生成 HTML 预览页 |
references/bright_data_tiktok_notes.md |
Bright Data 请求结构与输出建议 |
assets/report_template.html |
HTML 模板 |
LinkedIn skill 也遵循同样的结构,只是脚本换成:
scripts/collect_linkedin_company_by_url.pyscripts/render_linkedin_company_html.pyreferences/bright_data_linkedin_company_notes.md
如果你也想尝试,可以立即使用Bright Data 注册链接进行测试。
七、算一笔更真实的账:贵的不是调用费,贵的是时间
如果只盯着接口价格,那么我们很容易低估 DIY 抓取的总成本。真正昂贵的,往往是这些隐性支出:
- 写完还要维护的脚本
- 平台更新后重新排障的时间
- 抓取失败导致的数据中断
- 团队内没人敢接手那堆"只有作者本人看得懂"的代码
我会更倾向用下面这张表去和团队沟通:
| 方案 | 前期投入 | 月均维护 | 适合场景 |
|---|---|---|---|
| 自建脚本直连平台 | 1-3 周起步,而且平台越多越贵 | 高,且不稳定 | 一次性实验 |
| Bright Data Web Scraper API+ 自动化 Skill | 半天到 1 天能成型 | 低,可沉淀 | 团队复用、持续交付 |
Bright Data 这种方案真正有价值的地方,不只是"能抓到",而是把原本最难维护的部分外包给了成熟基础设施。你自己只需要关心输入、输出、字段映射和交付方式。
Bright Data 采用按成功采集付费的定价模式------失败的请求不计费。对比DIY 方案(35% 成功率)与skill(99%+成功率)的场景,实际有效成本差距远比表格上的数字显著。
八、总结
如果说上一篇文章解决的是"怎么把 Bright Data 接进 AI 工作流",那这篇文章解决的就是另一件更落地的事:怎么把一段能跑的流程,整理成别人也能下载、执行、复用、二次扩展的工程资产。
这次我把交付物落成了两个独立 skill:collect-tiktok-by-keyword 和 collect-linkedin-company-by-url。它们不仅会发请求,还负责下载 snapshot、输出运行摘要,并且给你一个可直接打开的 HTML 结果页。
如果你想快速复现,可以注册 Bright Data 注册链接 ,用这个链接注册再输入折扣码可以有20美金的试用,折扣码是leo20。三分钟即可快速获取TikTok与LinkedIn数据。