目录
[问题 1:哈希值一定是 8+B 位吗?](#问题 1:哈希值一定是 8+B 位吗?)
[1. 哈希值到底多长?](#1. 哈希值到底多长?)
[2. 低 B 位为什么能定位桶?](#2. 低 B 位为什么能定位桶?)
[3. tophash 为什么只存 8 位?](#3. tophash 为什么只存 8 位?)
[4. 所以中间的那些位去哪了?](#4. 所以中间的那些位去哪了?)
[问题 2 哈希函数到底怎么工作的?](#问题 2 哈希函数到底怎么工作的?)
[1.2 哈希函数的详细过程](#1.2 哈希函数的详细过程)
[Go 的哈希函数是"内置"的,用户无法自定义](#Go 的哈希函数是"内置"的,用户无法自定义)
[1.3 hash0 到底是什么?为什么需要它?](#1.3 hash0 到底是什么?为什么需要它?)
[没有 hash0 的世界(灾难)](#没有 hash0 的世界(灾难))
[有了 hash0 的世界(安全)](#有了 hash0 的世界(安全))
[1.4 hash函数的计算流程和重要性质:](#1.4 hash函数的计算流程和重要性质:)
[2.1 结论](#2.1 结论)
[2.2 为什么是无序的?](#2.2 为什么是无序的?)
[3.1 物理层面:扩容后顺序必然被打乱](#3.1 物理层面:扩容后顺序必然被打乱)
[3.2 设计层面:强制你写健壮的代码](#3.2 设计层面:强制你写健壮的代码)
[5.1 结论](#5.1 结论)
[5.2 底层保护机制](#5.2 底层保护机制)
[5.3 那该怎么办?](#5.3 那该怎么办?)
[深入:问题 1:Map 并发安全的写标志位机制](#深入:问题 1:Map 并发安全的写标志位机制)
[1.1 图书馆的"营业中"牌子](#1.1 图书馆的"营业中"牌子)
[1.2 读操作的检测逻辑](#1.2 读操作的检测逻辑)
[1.3 写操作的"先挂牌子,再干活"逻辑](#1.3 写操作的"先挂牌子,再干活"逻辑)
[1.4 为什么"读+写"并发也不安全?](#1.4 为什么"读+写"并发也不安全?)
[深入:问题 2 扩充:h.flags |= hashWriting 到底在做什么?](#深入:问题 2 扩充:h.flags |= hashWriting 到底在做什么?)
[2.1 h.flags 是什么?](#2.1 h.flags 是什么?)
[2.2 |= 是什么?为什么能"置位"?](#2.2 |= 是什么?为什么能"置位"?)
[先定义 hashWriting](#先定义 hashWriting)
[2.3 &^= 是什么?为什么能"复位"?](#2.3 &^= 是什么?为什么能"复位"?)
[&^ 运算符的含义](#&^ 运算符的含义)
[先算 ^hashWriting(按位取反)](#先算 ^hashWriting(按位取反))
[再和 h.flags 做按位与](#再和 h.flags 做按位与)
[2.4 为什么 Go 要用位运算做标志位?](#2.4 为什么 Go 要用位运算做标志位?)
[6.1 结论](#6.1 结论)
[6.2 为什么?------哈希冲突的兜底手段](#6.2 为什么?——哈希冲突的兜底手段)
[6.3 哪些类型可以当 key?](#6.3 哪些类型可以当 key?)
[7.Map 的扩容时机是怎样的?](#7.Map 的扩容时机是怎样的?)
[条件 1:装载因子超过阈值 → 双倍扩容](#条件 1:装载因子超过阈值 → 双倍扩容)
[条件 2:溢出桶(overflow bucket)数量过多 → 等量扩容](#条件 2:溢出桶(overflow bucket)数量过多 → 等量扩容)
[深入:问题 1:为什么要设计"等量扩容"?直接双倍扩容不就行了吗?](#深入:问题 1:为什么要设计"等量扩容"?直接双倍扩容不就行了吗?)
[1.1 先理解"溢出桶过多"是什么场景](#1.1 先理解"溢出桶过多"是什么场景)
[1.2 等量扩容在干什么?](#1.2 等量扩容在干什么?)
[深入:问题 2 扩容时的"重新计算哈希"到底是什么意思?](#深入:问题 2 扩容时的"重新计算哈希"到底是什么意思?)
[2.1 同一个 key,在同一个程序运行期间,哈希值不会变](#2.1 同一个 key,在同一个程序运行期间,哈希值不会变)
[2.2 那"重新计算"到底在计算什么?](#2.2 那"重新计算"到底在计算什么?)
[8、Map 的扩容过程是怎样的?](#8、Map 的扩容过程是怎样的?)
[8.1 核心特点:渐进式扩容(Gradual)](#8.1 核心特点:渐进式扩容(Gradual))
[8.2 两种扩容的区别](#8.2 两种扩容的区别)
[深入:问题1:nevacuate 字段有什么作用](#深入:问题1:nevacuate 字段有什么作用)
[1. 为什么不是指针?](#1. 为什么不是指针?)
[2. 它表示的是什么?](#2. 它表示的是什么?)
[3. 在扩容搬迁中怎么工作?](#3. 在扩容搬迁中怎么工作?)
[4. 为什么需要 nevacuate?没有它行不行?](#4. 为什么需要 nevacuate?没有它行不行?)
[9、可以对 Map 的元素取地址吗?](#9、可以对 Map 的元素取地址吗?)
[9.1 结论](#9.1 结论)
[9.2 为什么?------扩容导致地址失效](#9.2 为什么?——扩容导致地址失效)
[10、Map 中删除一个 key,内存会释放吗?](#10、Map 中删除一个 key,内存会释放吗?)
[10.1 结论](#10.1 结论)
[10.2 底层发生了什么?](#10.2 底层发生了什么?)
[10.3 什么时候真正释放?](#10.3 什么时候真正释放?)
[11、Map 可以边遍历边删除吗?](#11、Map 可以边遍历边删除吗?)
[11.1 结论](#11.1 结论)
[11.2 单协程内的行为](#11.2 单协程内的行为)
1.GO语言map的底层实现原理
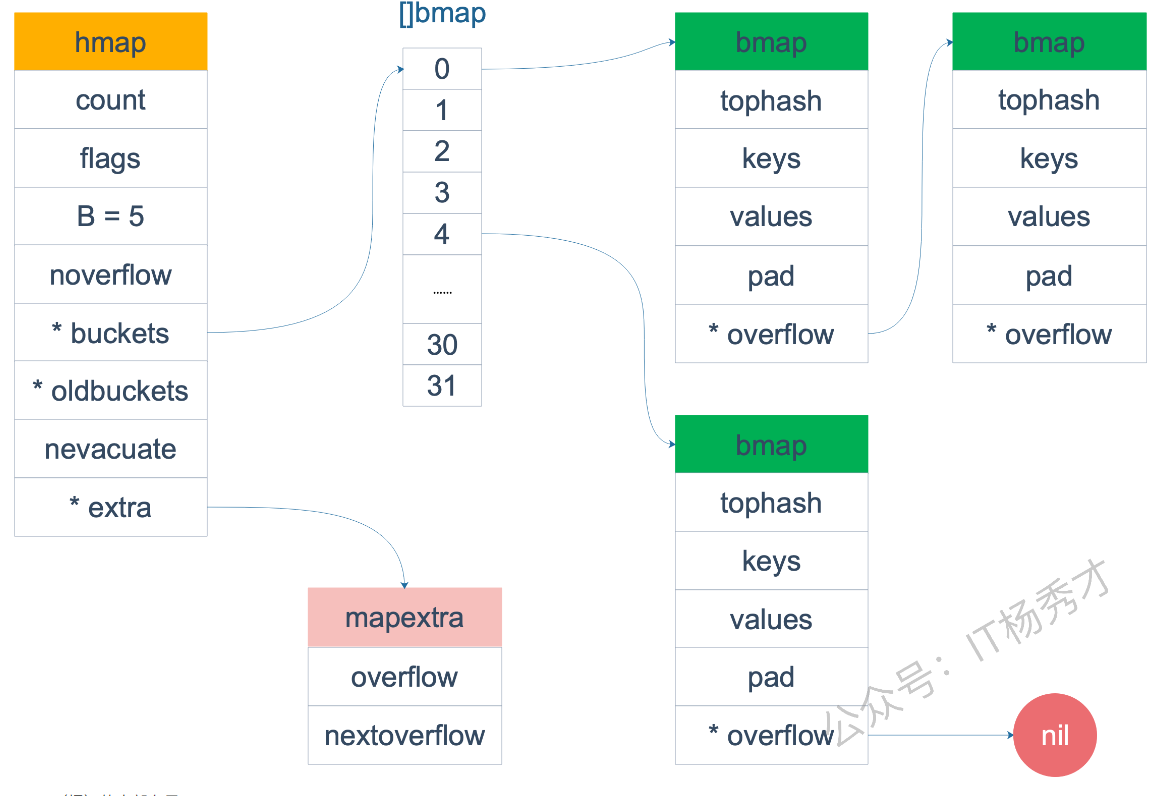
map的就是⼀个hmap的结构。Go Map的底层实现是⼀个哈希表 。它在运⾏时表现为⼀个指向hmap结构体的指针 ,hmap中记录了桶数组指针buckets、溢出桶指针以及元素个数等字段。每个桶是⼀个bmap结构体,能存储8个键值对和8个tophash,并有指向下⼀个溢出桶的指针overflow 。为了内存紧凑,bmap中采⽤的是先存8个键再存8个值的存储⽅式。
hmap 结构体定义:
type hmap struct {
count int // 当前存了多少个 key-value
flags uint8 // 状态标志位(比如是否正在扩容)
B uint8 // 桶数量的对数,桶数 = 2^B
noverflow uint16 // 溢出桶数量近似值
hash0 uint32 // 哈希种子(防止哈希攻击)
buckets unsafe.Pointer // 指向当前桶数组
oldbuckets unsafe.Pointer // 扩容时指向旧桶数组
nevacuate uintptr // 扩容进度:小于这个值的桶已搬迁完毕
extra *mapextra // 指向溢出桶等额外信息
}
bmap(桶)的内部布局:
tophash(8个高8位哈希值)
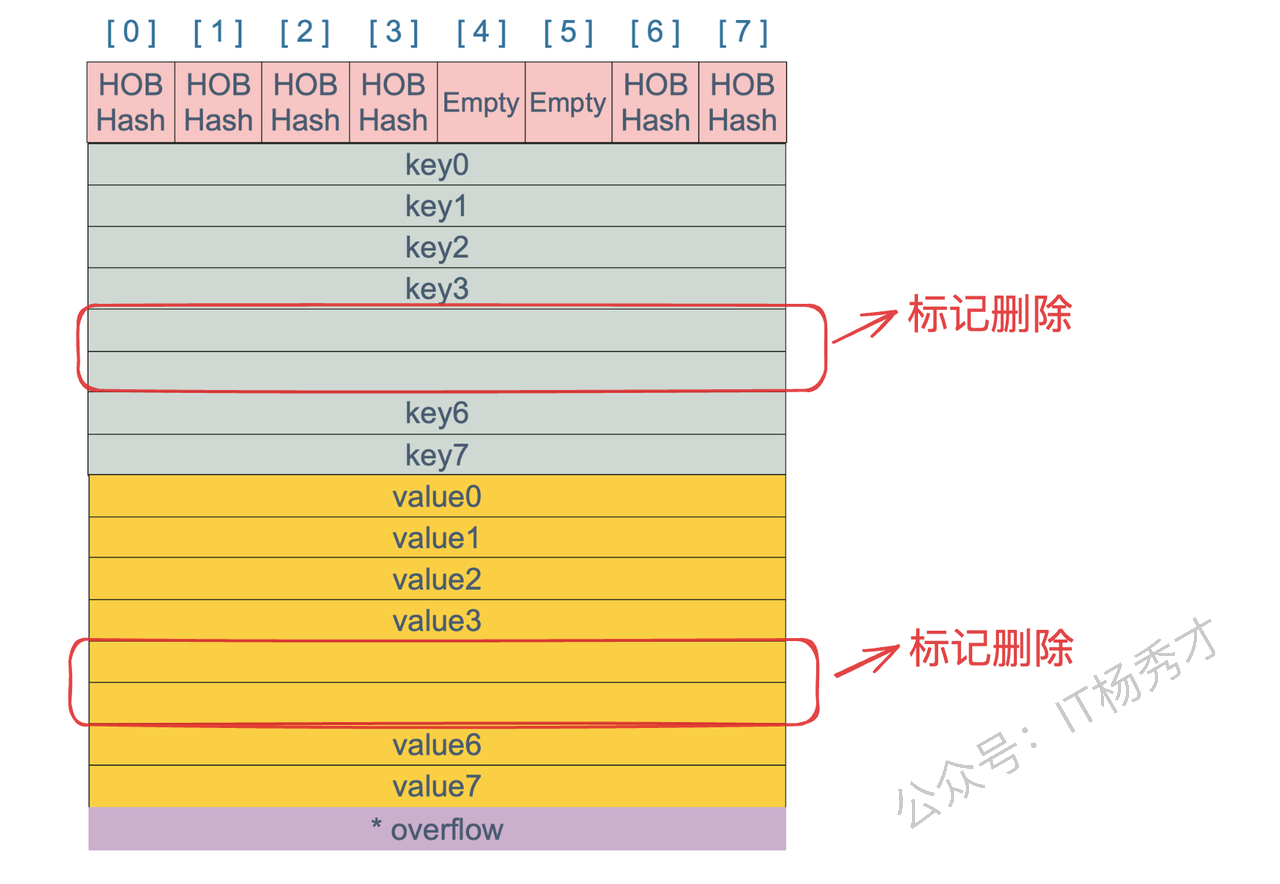
为什么先存 8 个 key 再存 8 个 value? 因为 Go 做了内存对齐 。相同类型的数据放一起,内存更紧凑,CPU 缓存命中率更高。如果 key 和 value 是 int64 类型,这种排列几乎没有内存碎片。
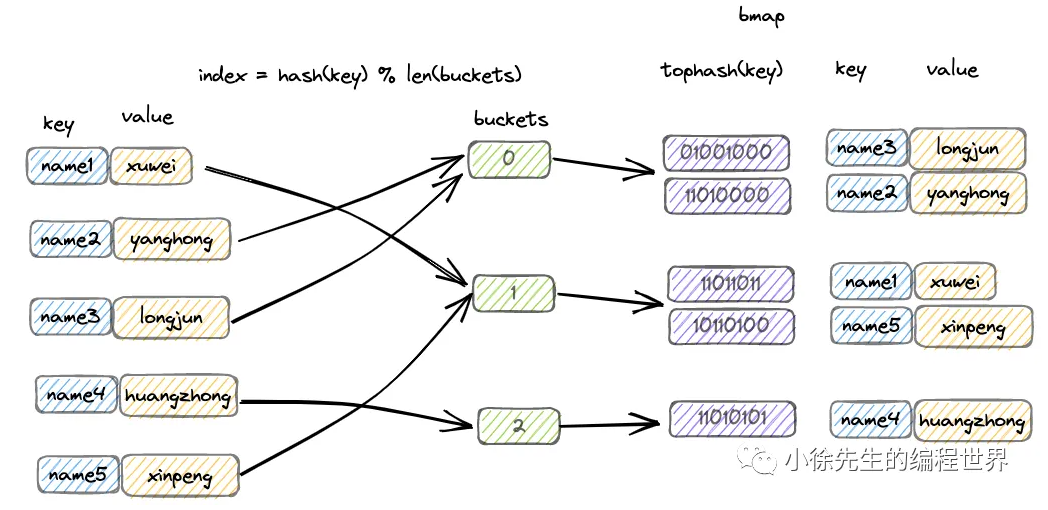
查找过程(理解底层的关键)
当你写 m["hello"] 时,Go 做了啥?
-
算哈希 :用哈希函数算出
"hello"的哈希值。 -
定位桶 :取哈希值的低
B位,决定去哪个bmap(比如B=5,桶数=32,看后 5 位)。 -
看 tophash :进桶后,先对比 8 个
tophash(哈希值的高 8 位)。如果色块对不上,直接跳过;对上了,再翻开书(对比完整 key)。 -
处理冲突 :如果 8 个位置都满了,去
overflow溢出桶继续找。 -
返回结果 :找到了返回 value,没找到返回零值(所以 Go 的
m[key]永远能返回值,不会抛异常)。
问题 1:哈希值一定是 8+B 位吗?
先说结论
不是。 哈希值本身是完整的 32 位或 64 位 (取决于你的系统是 32 位还是 64 位),远不止 8+B 位。Go 只是借用了其中的两部分来工作:
-
低 B 位:决定你去哪个桶(书架)。
-
最高 8 位 :作为
tophash(书脊色块),存在桶里用于快速筛选。
详细拆解
1. 哈希值到底多长?
Go Runtime 使用的哈希算法(内部叫 memhash 或 typehash)在 64 位系统 上会生成一个 64 位 的整数,在 32 位系统 上会生成一个 32 位的整数。
完整的哈希值(64位):
├────────────────────────────────────────────────────────────────┤
│ 高 8 位 (tophash) │ 中间若干位 │ 低 B 位 (选桶) │
│ (bits 56~63) │ (被忽略) │ (bits 0~B-1) │
└────────────────────────────────────────────────────────────────┘2. 低 B 位为什么能定位桶?
因为 Go 的桶数量永远是 2 的幂次方 (2^B)。比如:
-
B=3→ 8 个桶 → 用哈希值的低 3 位(000~111)就能映射到 0~7 号桶。 -
B=5→ 32 个桶 → 用哈希值的低 5 位(00000~11111)映射到 0~31 号桶。
3. tophash 为什么只存 8 位?
因为 tophash 在源码里定义的是 uint8(8 位无符号整数),所以只取哈希值的最高 8 位(HOB, High Order Bits)。
为什么取最高位而不是最低位? 因为低 B 位已经被用来选桶了,同一个桶里的所有元素,它们的低 B 位是相同 的。如果 tophash 再存低 8 位,那同一个桶里的 tophash 也会高度雷同,失去了"快速筛选"的意义。而高 8 位是均匀分布的,能快速排除不匹配的 key。
4. 所以中间的那些位去哪了?
中间的那些位在查找过程中被忽略了。也就是说:
-
**第一步:**用低 B 位找到桶(粗略定位)。
-
**第二步:**在桶里用 tophash(高 8 位)快速排除大部分不匹配项。
-
第三步: 对剩下的少数候选者,用
==比较完整的 key(这才是最终裁决)。
问题 2 哈希函数到底怎么工作的?
1.2 哈希函数的详细过程
Go 的哈希函数是"内置"的,用户无法自定义
你写 m["hello"] 时,Go 编译器会根据 key 的类型,自动选择对应的哈希函数:
| Key 类型 | 使用的哈希算法 |
|---|---|
string |
runtime.memhash(基于 xxhash/ahash 的变体) |
int / uint |
直接拿数值本身,或做位混合 |
float |
特殊处理 NaN 等情况后哈希 |
struct |
逐字段哈希后混合 |
pointer |
指针地址做哈希 |
关键点:
-
这些哈希函数是 runtime 层硬编码 的,用户不能自定义。
-
不像 Java 的
hashCode()可以由类覆盖,Go 的 map key 类型如果内置不支持哈希,直接编译报错。
哈希计算的两步混合
Go 的哈希不是简单地对 key 内容算一次哈希,而是两步混合:
最终哈希值 = HashAlgorithm(key内容, hash0)具体过程(以 string 为例):
-
读取字符串的每个字节内容。
-
用特定的哈希算法(如 memhash)把字节流搅乱成一个大整数。
-
关键一步 :把这个大整数和
hmap.hash0(种子)做**异或(XOR)**或加法混合。
// 伪代码,示意 runtime 的行为
hash := memhash(keyBytes, h.hash0) // 把 key 内容和种子一起喂给哈希函数1.3 hash0 到底是什么?为什么需要它?
hash0 是 uint32 类型的随机种子,每个 map 实例在创建时,Runtime 会用随机数填充它。
没有 hash0 的世界(灾难)
假设没有种子,哈希函数是纯确定性的:
-
"hello"的哈希值永远是0x12345678。 -
攻击者可以分析你的哈希算法,然后构造 10000 个不同的字符串,它们的哈希值低 B 位完全相同。
-
这 10000 个 key 会全部挤进同一个桶,溢出桶连成一条长蛇。
-
你的 map 从 O(1) 直接退化成 O(N),CPU 被打满,这就是哈希碰撞攻击(Hash DoS)。
有了 hash0 的世界(安全)
-
每次程序启动,
hash0都是随机生成的。 -
同样的
"hello",在这次运行中哈希值是0x12345678,下次运行可能就是0xABCDEF00。 -
攻击者无法预测种子,也就无法构造针对性的碰撞 key。
-
同一个 map 实例内 ,
hash0是固定的,所以同一个 key 的哈希值是稳定的,查找才能成功。
1.4 hash函数的计算流程和重要性质:
以一组 key-value 对写入 map 的流程为例进行简述:
(1)通过哈希方法取得 key 的 hash 值;
(2)hash 值对桶数组长度取模,确定其所属的桶;
(3)在桶中插入 key-value 对.
hash 的性质,保证了相同的 key 必然产生相同的 hash 值,因此能映射到相同的桶中,通过桶内遍历的方式锁定对应的 key-value 对.
因此,只要在宏观流程上,控制每个桶中 key-value 对的数量,就能保证 map 的几项操作都限制为常数级别的时间复杂度.
hash 译作散列,是一种将任意长度的输入压缩到某一固定长度的输出摘要的过程,由于这种转换属于压缩映射 ,输入空间远大于输出空间,因此不同输入可能会映射成相同的输出结果. 此外,hash在压缩过程中会存在部分信息的遗失,因此这种映射关系具有不可逆的特质.
(1)hash 的可重入性:相同的 key,必然产生相同的 hash 值;
(2)hash 的离散性:只要两个 key 不相同,不论其相似度的高低,产生的 hash 值会在整个输出域内均匀地离散化;
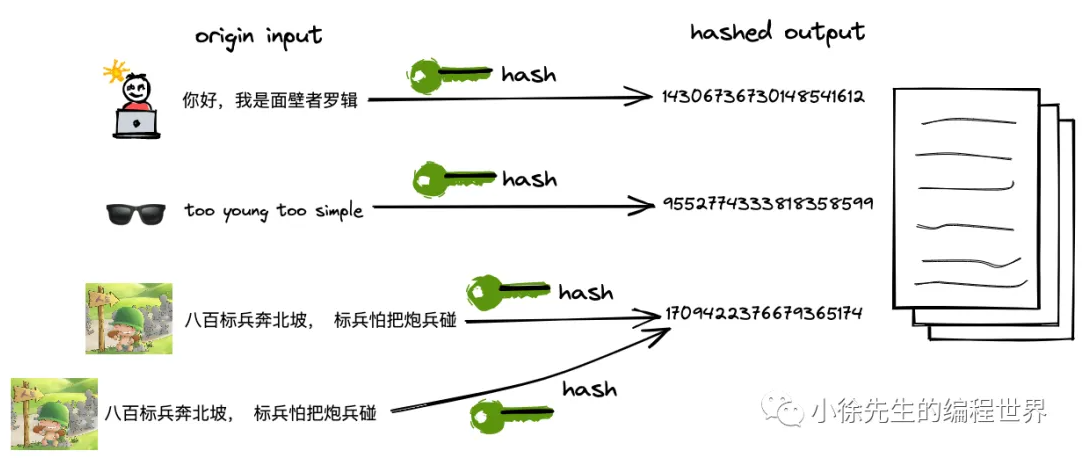
(3)hash 的单向性:企图通过 hash 值反向映射回 key 是无迹可寻的.
2.Go语⾔Map的遍历是有序的还是⽆序的?
2.1 结论
完全随机,每次遍历顺序都不一样。
2.2 为什么是无序的?
Go 语言里 Map 的遍历是故意设计成随机的:
-
每次
for range map时,Runtime 会生成一个随机数作为起始桶号。 -
即使在同一个桶内,也会从随机偏移位置开始遍历。
所以,你连续运行两次同样的代码,打印出的 key 顺序大概率不同。
3.map的遍历为什么设计成无序?
这是 Go 团队的一个刻意为之的设计,有两个层面的原因:
3.1 物理层面:扩容后顺序必然被打乱
Map 扩容时,桶数量会变(通常是翻倍)。原来在同一个桶里的 key,扩容后可能会被重新哈希到完全不同的新桶。原来在桶 3 的 key,可能去了桶 7;原来在桶 4 的,可能原地不动。
既然扩容必然导致顺序剧变,那强行维护有序就是自找麻烦,性能开销巨大。
3.2 设计层面:强制你写健壮的代码
Go 团队不希望开发者写出这种脆弱代码:
// 错误示范:依赖遍历顺序
for k, v := range m {
if k == "first" { ... } // 指望某个key先出现
}通过在遍历引入随机性,Go 从根本上杜绝了程序员依赖特定遍历顺序的可能性,逼你写出不依赖顺序的健壮逻辑。这是 Go 语言"务实哲学"的典型体现。
4.map如何实现顺序读取呢?
如果业务上确实需要按 key 排序后遍历,最规范的做法是:
package main
import (
"fmt"
"sort"
)
func main() {
m := map[int]int{
3: 200, 4: 200, 1: 100, 8: 800, 5: 500, 2: 200,
}
// 1. 把所有 key 拿出来
keyList := make([]int, 0, len(m))
for key := range m {
keyList = append(keyList, key)
}
// 2. 排序
sort.Ints(keyList)
// 3. 按顺序访问 map
for _, key := range keyList {
fmt.Println(key, m[key])
}
}核心思路:Map 本身无序,但 Slice 可以排序。用 Slice 当"导航员",指挥 Map 按顺序输出。
5.map是否并发安全?
5.1 结论
绝对不是!Map 不是线程安全的。并发读写同一个 map 会导致 panic。
5.2 底层保护机制
Go 的 map 在操作时会检测写标志位(hashWriting):
-
如果有 goroutine 正在写,另一个 goroutine 又来写/读,Runtime 会直接抛出:
fatal error: concurrent map writes -
即使是"读+写"并发,也是不安全的(Go 1.6 之后读检测更严格)。
5.3 那该怎么办?
如果需要并发使用,有三个选择:
-
sync.RWMutex:最常用,给 map 加读写锁。 -
sync.Map:Go 官方提供的并发安全 map,适合读多写少、key 类型固定等特定场景。 -
Channel 串行化:把对 map 的操作都发给一个专门 goroutine 处理(CSP 思想)。
深入:问题 1:Map 并发安全的写标志位机制
1.1 图书馆的"营业中"牌子
hmap 结构体里有一个 flags uint8 字段,相当于图书馆门口挂的状态牌子:
-
其中有一个位叫
hashWriting(写标志位)。 -
牌子翻过来(置位 = 1):表示"正在装修,禁止入内"。
-
牌子翻过去(复位 = 0):表示"正常营业"。
1.2 读操作的检测逻辑
当你执行 v := m["key"] 或 for range m 时,Go 会先瞄一眼牌子:
if h.flags & hashWriting != 0 {
throw("concurrent map read and write") // 直接 panic
}翻译: 如果发现有 goroutine 正在写(牌子翻过来了),读操作直接 panic,不给你任何侥幸机会。
1.3 写操作的"先挂牌子,再干活"逻辑
当你执行 m["key"] = value 或 delete(m, "key") 时,Go 会:
-
先检查牌子:看看有没有其他人在写(防止两个写的并发)。
-
翻牌子 :
h.flags |= hashWriting(把写标志位置位)。 -
开始干活:修改桶里的数据、搬迁、扩容等。
-
干完活再把牌子翻回去 :
h.flags &^= hashWriting(复位)。
"赋值和删除函数在检测完写标志是复位之后,先将写标志位置位,才会进行之后的操作。"
1.4 为什么"读+写"并发也不安全?
这是最关键的设计细节。你可能想:"我只是读,别人在写,我读我的不就行了吗?"
不行,因为 map 的读操作没有加锁保护,而写操作可能让内存处于"半成品"状态。
具体有以下几种危险情况:
| 危险场景 | 会发生什么 |
|---|---|
| 写了一半的 key-value | 写 goroutine 刚写完 key,还没写 value,读 goroutine 就读到了未初始化的 value |
| 扩容搬迁中 | 写 goroutine 正在把旧桶数据搬到新桶,读 goroutine 可能去旧桶找,发现数据不见了;或去新桶找,数据还没搬过来 |
| 桶内数据移动 | 插入新元素可能导致桶内已有元素的位置调整,读 goroutine 可能读到错误的槽位 |
Go 1.6 之前,Runtime 对"读+写"的检测比较宽松,有时候能跑但会读到脏数据。Go 1.6 之后,读操作也会严格检测 hashWriting 标志,一旦发现有人在写,立刻 panic。
深入:问题 2 扩充:h.flags |= hashWriting 到底在做什么?
这是**位运算(Bitwise Operation)**的应用,是理解 Go Runtime 并发检测的关键。
2.1 h.flags 是什么?
h.flags 是 uint8 类型,只占 1 个字节(8 个比特位)。Go 把这 8 个位拆开,每个位代表一个独立的状态标志:
h.flags 的 8 个比特位:
┌──┬──┬──┬──┬──┬──┬──┬──┐
│b7│b6│b5│b4│b3│b2│b1│b0│
└──┴──┴──┴──┴──┴──┴──┴──┘
↑
hashWriting 通常占其中一位,比如 b22.2 |= 是什么?为什么能"置位"?
|= 是按位或赋值 操作,等价于 h.flags = h.flags | hashWriting。
先定义 hashWriting
在 Go runtime 源码里,hashWriting 是一个常量,通常定义为:
const hashWriting = 1 << 2 // 二进制:00000100(第 2 位为 1,其余为 0)按位或的真值表
| A | B | A | B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
特性:和 1 进行或运算,结果一定是 1;和 0 进行或运算,结果保持原样。
所以 h.flags |= hashWriting 的精确含义:
把
h.flags中代表"正在写入"的那个比特位,强行设为 1 ,同时不影响其他任何标志位。
2.3 &^= 是什么?为什么能"复位"?
&^= 是 Go 里特有的按位清除(AND NOT)赋值 ,等价于 h.flags = h.flags &^ hashWriting。
&^ 运算符的含义
a &^ b = a & (^b),即:a 和 b 的反码进行按位与。
先算 ^hashWriting(按位取反)
hashWriting: 00000100
^hashWriting: 11111011 (第 2 位变 0,其他位变 1)再和 h.flags 做按位与
| A | B | A & B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
特性:和 0 进行与运算,结果一定是 0;和 1 进行与运算,结果保持原样。
所以 h.flags &^= hashWriting 的精确含义:
把
h.flags中代表"正在写入"的那个比特位,强行清零 ,同时不影响其他任何标志位。
2.4 为什么 Go 要用位运算做标志位?
一个字节能塞 8 个标志,极省内存 。如果每个标志都用一个 bool,在 64 位系统上可能占 8 个字节(内存对齐后),而且 CPU 缓存命中率低。位运算在 CPU 层面是单指令操作,速度极快。
6.map的key一定要是可比较类型吗?为什么?
6.1 结论
必须可比较! 也就是说,key 的类型必须支持 == 和 != 操作。
6.2 为什么?------哈希冲突的兜底手段
Map 定位 key 的过程分两步:
-
哈希定位桶 :通过哈希值快速找到对应的
bmap。 -
精确匹配 key :因为不同 key 的哈希值可能相同 (哈希冲突),这时候必须逐个用
==比较桶里的 key,才能确认"是不是你要找的那本书"。
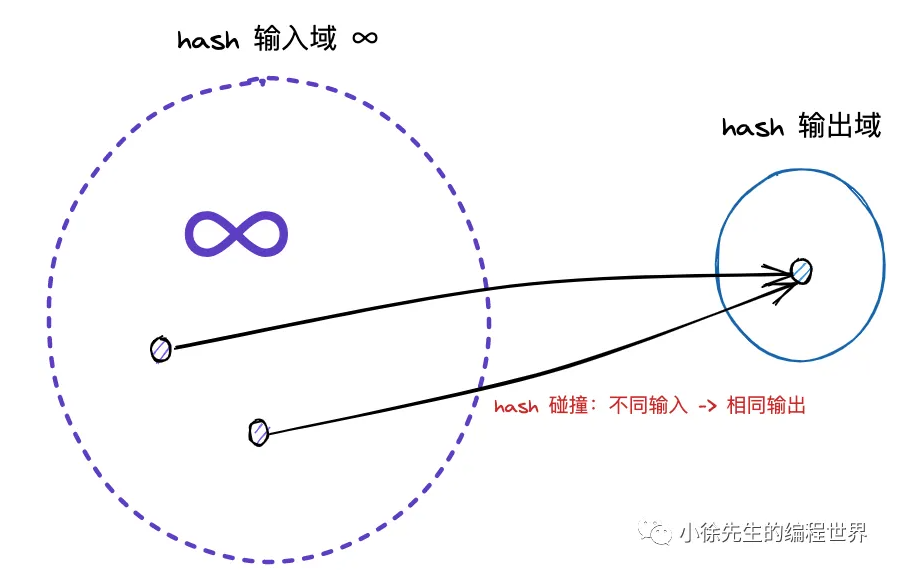
hash 冲突:由于输入域(key)无穷大,输出域(hash 值)有限,因此必然存在不同 key 映射到相同 hash 值的情况,称之为 hash 冲突.
如果 key 类型不可比较(比如 slice、map、function),第二步就无法进行,Runtime 会直接编译报错或运行时崩溃。
6.3 哪些类型可以当 key?
-
✅ 基本类型:
int,string,bool,float,complex -
✅ 指针类型
-
✅ 数组(元素可比较)
-
✅ 结构体(所有字段都可比较)
-
❌ Slice、Map、Function、Channel(不可比较)
7.Map 的扩容时机是怎样的?
向 map 插入新 key 时,Runtime 会检测两个条件,满足其一就触发扩容:
条件 1:装载因子超过阈值 → 双倍扩容
-
装载因子 = 元素个数 / 桶数量。
-
Go 源码里定义的阈值是 6.5。
-
这意味着平均每个桶(含溢出桶)存了 6.5 个元素以上,就太拥挤了。
-
动作 :桶数量翻倍(
B+1,即2^(B+1)),把所有旧数据重新哈希到新桶。
条件 2:溢出桶(overflow bucket)数量过多 → 等量扩容
有时候元素不多,但某些桶因为哈希不均匀,挂了一大堆溢出桶(像书架旁接了一长串临时书架)。这时候装载因子可能没超 6.5,但查找效率下降了。
判定标准:
-
当
B < 15(桶总数 < 2^15 ≈ 3.2万),如果 overflow 桶数量 超过 2^B(超过常规桶数量)。 -
当
B >= 15(桶总数 >= 2^15),如果 overflow 桶数量 超过 2^15。
动作 :桶数量不变 ,但把所有数据重新排列一遍,让数据更紧密,清理掉过多的溢出桶。这叫等量扩容。
深入:问题 1:为什么要设计"等量扩容"?直接双倍扩容不就行了吗?
1.1 先理解"溢出桶过多"是什么场景
这是触发等量扩容的条件 2。咱们用图书馆比喻:
正常情况:
-
图书馆有 128 个书架(
B=7,2^7=128)。 -
总共 1000 本书。
-
平均每个书架放 7~8 本书,偶尔旁边接 1 个临时书架(overflow),很正常。
异常情况(溢出桶过多):
-
还是 128 个书架,1000 本书。
-
但因为某些书的编号(哈希值)特别"扎堆",50 本书都挤在 3 号书架。
-
3 号书架只能放 8 本,剩下的 42 本只能一串接一串地挂在临时书架上。
3号书架: [8本] ──► overflow ──► overflow ──► overflow ──► ...这时候你要找一本落在 3 号书架的书,得沿着这条长链表逐个翻,查找效率从 O(1) 退化到接近 O(N)。
关键来了: 这时候装载因子是多少?
-
1000 / 128 ≈ 7.8,还没超过 6.5 吗?等等,6.5 是阈值,7.8 已经超过 6.5 了,应该会触发双倍扩容。 -
但如果总数不是 1000,而是 500 本 呢?
500/128 ≈ 3.9,远小于 6.5,不会触发双倍扩容。 -
但这 500 本里有 200 本挤在 3 号书架,挂了几十个溢出桶,查找极慢!
这就是条件 2 存在的意义:元素总数不多,但分布极度不均匀,导致某些桶的溢出链过长。
1.2 等量扩容在干什么?
"等量" = 桶数量不变(还是 128 个),但把所有书重新整理一遍。
具体过程:
-
遍历所有旧桶(包括溢出桶)。
-
对每个 key 重新计算哈希(注意:桶数没变,所以低 B 位理论上不变,但 Go 会用新的内存布局)。
-
尝试把溢出桶里的书塞回主桶的空位。
-
如果主桶确实满了,再合理分配溢出桶,让链表变短。
效果:
-
原来 3 号书架挂了 20 个溢出桶,整理后可能只剩 2 个。
-
查询时沿着链表走的步数大大减少。
-
内存没有翻倍增长,非常节约。
生活比喻:
你家书架有 5 层,总共只放了 30 本书,但因为你随手乱扔,第一层塞了 20 本,堆得旁边地上都是(溢出桶)。这时候你有两个选择:
买个大书架(双倍扩容):能解决,但占地方、花钱,而且大部分层还是空的。
重新整理(等量扩容):把第一层的书匀到其他层,地上的收回来,书架还是原来的书架,但整洁多了。
Go 选择两者兼备:装载因子高了(整体拥挤)就加盖楼层(双倍扩容);只是局部乱(溢出桶多)就重新整理(等量扩容)。
深入:问题 2 扩容时的"重新计算哈希"到底是什么意思?
2.1 同一个 key,在同一个程序运行期间,哈希值不会变
绝对不变。 因为:
-
哈希函数是固定的。
-
hash0在 map 创建时就固定了。 -
同样的 key 内容,喂给同样的算法和同样的种子,输出永远相同。
所以,"重新计算哈希"不等于"哈希值会变",也不等于"换了哈希算法"。
2.2 那"重新计算"到底在计算什么?
双倍扩容时的"重新计算"
当 B 变成 B+1,桶数量从 2^B 变成 2^(B+1)。
此时:
-
原来用低 B 位决定桶号。
-
现在需要用低 (B+1) 位决定桶号。
同一个哈希值,多看了一位,桶号就可能变了!
假设哈希值的低 4 位是:...1101
当 B=3(8个桶):
取低 3 位:101 → 桶号 5
当 B=4(16个桶):
取低 4 位:1101 → 桶号 13所以双倍扩容时的"重新哈希",本质上是用同一个哈希值,但多取一位来重新决定新桶位置 。数据本身(key-value)没有变,哈希值也没有变,只是桶的划分粒度变细了。
等量扩容时的"重新计算"
"重新计算哈希"其实表述上容易引起误解。更准确的说法是**"重新整理/重新安置"**。
因为:
-
B没变,桶数量没变。 -
同一个 key 的低 B 位没变,所以它应该去的桶号理论上不变。
那为什么要"重新算"?实际上 Runtime 做的是:
-
创建新的
buckets(大小相同)。 -
遍历旧桶,把每个有效的 key-value 重新 hash 定位到新桶。
-
由于桶数量没变,key 应该落在和旧桶相同编号的新桶里。
-
但! 因为旧桶可能有大量
Empty槽位(delete 留下的)和冗长的 overflow 链,而新桶是全新的、空的,重新插入时数据会紧密排列,溢出桶数量大幅减少。
这个过程不是"哈希值变了",而是"用不变的哈希值,在新的内存布局里找更合适的位置"。
生活比喻:
你有一个 128 格的收纳箱,用了几年里面塞得乱七八糟,很多格子空了但旁边挂了一堆外挂袋子(overflow)。等量扩容就是:买了一个一模一样大的新收纳箱,把所有东西掏出来,重新整齐地码进去。东西还是那些东西(key 没变,哈希值没变),但新箱子码得整整齐齐,外挂袋子基本不需要了。
8、Map 的扩容过程是怎样的?
这是 Go Map 设计的精髓之一,也是它高性能的原因。
8.1 核心特点:渐进式扩容(Gradual)
很多语言的哈希表扩容是"Stop The World"式的:暂停一切操作,一次性把所有数据搬到新空间。这会导致瞬间卡顿。
Go 的扩容是渐进式的:
-
分配新空间 :创建新的
buckets数组(翻倍或等量)。 -
标记扩容状态 :
hmap.flags打上扩容标记,oldbuckets指向旧数组。 -
日常操作"顺便"搬迁 :之后每次你对 map 进行 insert、delete、update 时,Runtime 会"顺手"搬迁 1~2 个旧桶的数据到新桶。
-
全部搬完 :当
nevacuate进度走到末尾,旧桶全部搬迁完毕,oldbuckets被释放,扩容结束。
8.2 两种扩容的区别
| 类型 | 新桶数量 | 数据搬迁方式 | 目的 |
|---|---|---|---|
| 双倍扩容 | 原来的 2 倍 | 旧数据重新计算哈希,分散到新桶 | 降低装载因子,解决拥挤 |
| 等量扩容 | 和原来相同 | 数据重新排列,填到更紧凑的位置 | 减少溢出桶,提高空间利用率 |
小白理解:
-
双倍扩容 = 图书馆书太多,加盖一层楼,把书分散过去。
-
等量扩容 = 书不多,但放得乱,重新整理书架,把空位填满,去掉旁边的临时书架。
深入:问题1:nevacuate 字段有什么作用
nevacuate 不是指针 ,它的类型是 uintptr。虽然名字看起来和指针有关,但本质上它是一个无符号整数 (可以理解为"一个能存地址的数字"),在 map 的渐进式扩容中充当进度计数器。
1. 为什么不是指针?
在 Go 的 runtime 包里,和内存地址相关的类型有三种:
| 类型 | 本质 | 特点 |
|---|---|---|
unsafe.Pointer |
真指针 | 可以解引用,受 GC 跟踪 |
uintptr |
整数 | 只存地址的数值,不能解引用,GC 不把它当指针 |
*T |
类型化指针 | 普通指针,如 *int |
nevacuate 被设计成 uintptr 而不是指针,是因为 Go 只需要用它存一个桶的序号(索引) ,而不是指向某块内存。它存的是一个整数进度值。
2. 它表示的是什么?
nevacuate 表示的是渐进式扩容的搬迁进度。
具体含义:
所有编号小于
nevacuate的旧桶(oldbuckets),都已经完成了数据搬迁;大于等于nevacuate的旧桶,可能还没搬。
3. 在扩容搬迁中怎么工作?
Go 的 map 扩容是渐进式(Gradual) 的,不会一次性搬完。nevacuate 就是用来记录"搬到哪了"的标尺。
工作机制
// hmap 结构体里的相关字段
type hmap struct {
buckets unsafe.Pointer // 新桶数组(新图书馆)
oldbuckets unsafe.Pointer // 旧桶数组(旧图书馆)
nevacuate uintptr // 搬迁进度:小于它的旧桶已搬完
}-
扩容触发 :创建新桶数组,
oldbuckets指向旧数组,buckets指向新数组。 -
日常"顺便"搬迁 :之后你每次对 map 执行
insert、delete、update或lookup时,Go 会顺手检查:-
如果访问的 key 落在还没搬的旧桶里,就现场把它搬到新桶对应位置。
-
然后再额外多搬1~2 个 以
nevacuate为起点的旧桶(推进进度)。
-
-
推进进度 :每搬完一个旧桶,
nevacuate就 +1。 -
搬迁完成 :当
nevacuate == 旧桶总数(即2^B)时,说明所有旧书架都搬完了。此时oldbuckets会被置为nil,交给 GC 回收。
源码层面的逻辑(伪代码)
// 每次访问 map 时,会调用类似这样的逻辑
func mapaccess(h *hmap, key string) {
// 1. 如果正在扩容,先"顺便"搬一点
if h.growing() {
growWork(h, bucketIndex) // 搬当前桶 + 推进 nevacuate
}
// 2. 正常查找...
}
// 渐进搬迁
func growWork(h *hmap, bucket uintptr) {
// 把当前访问的旧桶搬到新桶
evacuate(h, bucket)
// 再搬一个以 nevacuate 为指针的旧桶,推进总进度
if h.nevacuate < oldBucketCount {
evacuate(h, h.nevacuate)
h.nevacuate++
}
}4. 为什么需要 nevacuate?没有它行不行?
没有它,Go 就不知道哪些旧桶已经搬完了,每次查找都要去旧桶和新桶两边翻,效率低且逻辑混乱。
有了 nevacuate 后,Runtime 可以做一个快速判断:
-
如果某个旧桶的编号
< nevacuate,直接跳过,因为它已经空了/无效了。 -
查找时只需要关注
≥ nevacuate的旧桶,大大减少搜索范围。
9、可以对 Map 的元素取地址吗?
9.1 结论
不可以!编译直接报错。
m := make(map[string]int)
fmt.Println(&m["qcrao"]) // 编译错误:cannot take the address of m["qcrao"]9.2 为什么?------扩容导致地址失效
如果允许你取 &m["key"],你拿到了一个指向 value 的指针。但下一秒 map 可能因为插入新元素而扩容 ,数据整体搬迁到新内存地址。你手里那个指针就变成了悬垂指针(Dangling Pointer),指向一片已经被回收或重新分配的内存------这是内存安全的大忌。
Go 语言为了绝对内存安全,干脆禁止对 map 元素取地址。
10、Map 中删除一个 key,内存会释放吗?
10.1 结论
不会立刻释放,也不会缩容!
10.2 底层发生了什么?
当你执行 delete(m, key) 时:
-
Runtime 找到对应的 key。
-
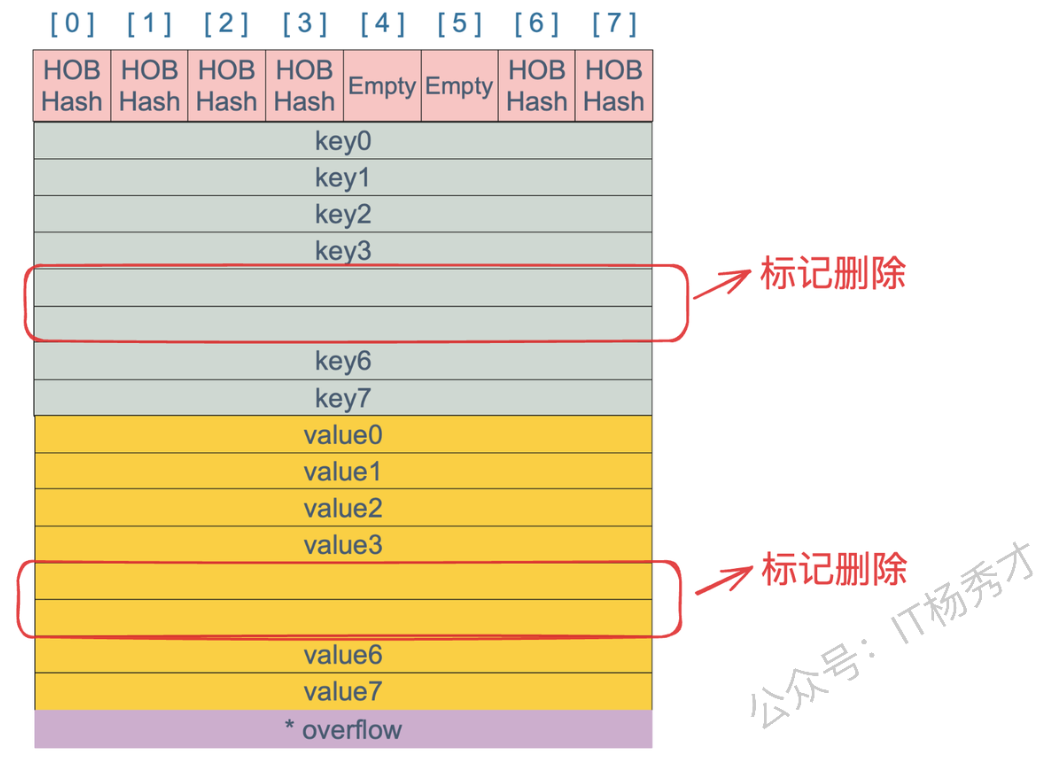
把该位置的
tophash标记为Empty(空状态)。 -
key 和 value 的内存空间被标记为"空闲",可以被后续的 GC 回收内容。
-
但是!
buckets数组本身的大小不会缩小。即使你把 map 里的 100万个 key 全删了,那些桶(书架)依然占着内存。
10.3 什么时候真正释放?
只有当整个 map 变量不再被任何变量引用 ,GC 才会把整个 hmap 及其 buckets 数组一起回收。
实际开发注意: 如果你有一个长期存活的全局 map,频繁增删大量数据,内存可能只涨不跌。如果确实需要"缩容",唯一的办法是定期重建 map(把有效数据拷贝到一个新 map,让旧 map 被 GC)。
11、Map 可以边遍历边删除吗?
11.1 结论
-
同一个 goroutine 内:可以边遍历边删除,不会 panic。
-
多个 goroutine 并发:会 panic(并发不安全)。
11.2 单协程内的行为
在同一个 goroutine 里:
for k := range m {
delete(m, k) // 不会 panic
}这不会触发并发检测,因为读写发生在同一个执行流里。但遍历结果不确定:
-
如果你删的 key 在当前遍历位置"前面",它已经遍历过了,没事。
-
如果在"后面",那遍历时可能看到也可能看不到,取决于底层桶的遍历顺序。
最佳实践: 如果需要在遍历中删除,通常没问题;但如果需要遍历中修改(增删)并保证逻辑正确,建议先收集要删的 key,遍历结束后再统一删除。