在AI大模型飞速普及的今天,越来越多的开发者开始投身大模型应用的开发浪潮中。但很多人在从原型demo走向生产级应用时,都会遇到一个核心难题:大模型应用的后端架构,和我们熟悉的传统Web后端架构,根本不是一回事。传统Web后端的那套"加索引、堆缓存、分库分表"的方法论,在大模型面前几乎失灵。
我在长期的技术实战和面试辅导中发现,很多开发者对大模型后端架构的理解,还停留在"调用一下OpenAI API"的层面。但真正能支撑千级、万级用户稳定使用的生产级架构,需要解决的问题远比想象中复杂。今天,我就结合自己的实战经验,从核心差异出发,一步步拆解生产级大模型应用后端架构的设计思路,全程通俗易懂,避开专业术语堆砌,让无论是新手还是有经验的开发者,都能看懂、能用得上。
先给大家抛一个核心结论:设计大模型应用后端架构,本质上就是解决LLM(大语言模型)带来的三个核心痛点:慢、贵、不确定。这三个痛点,是所有架构设计的出发点,也是区别于传统后端架构的关键。理解了这三点,后续的分层设计、组件选择、优化策略,就都有了明确的方向。
一、先搞懂:大模型后端与传统Web后端的核心差异
在设计架构之前,我们必须先理清一个问题:为什么传统Web后端的架构不能直接套用在大模型应用上?答案很简单,两者的核心瓶颈和设计目标完全不同。
传统Web后端的核心瓶颈,几乎都集中在数据库上。比如查询慢了,我们就给字段加索引;并发高了,我们就加Redis缓存;数据量大了,我们就分库分表。这套方法论经过十几年的打磨,已经非常成熟,甚至形成了固定的模板。我们设计传统后端架构,核心目标是"提升数据库性能、保证数据一致性",因为大部分请求的逻辑都是"接收请求→查数据库→返回结果",整个链路短且同步,耗时通常在几十毫秒到几百毫秒之间。
但当我们把LLM引入后端架构后,一切都变了。我们可以通过一组数据,直观感受两者的差异:
-
响应速度:普通数据库查询耗时是毫秒级,一次LLM调用动辄几秒甚至十几秒,复杂的Agent任务(比如多步工具调用、长文档分析)耗时能达到几十秒;
-
调用成本:数据库查询按次计费几乎可以忽略不计,而LLM调用是按token收费,一个活跃用户一天的对话成本,可能就从几毛钱涨到几块钱,一旦用户量上来,成本会呈指数级增长;
-
输出特性:数据库查询是确定性的,同样的SQL语句,无论执行多少次,返回的结果永远一致;但LLM的输出是不确定的,哪怕是完全相同的输入,两次调用返回的结果也可能不一样。
慢、贵、不确定,这三个问题就像三座大山,横在大模型应用后端架构设计的面前。我们后续所有的架构设计,都是为了针对性解决这三个问题,如何让响应更快,如何让成本更低,如何让输出更可控。
举个真实的例子,我之前辅导过一个团队,他们做了一个大模型问答应用,原型阶段直接调用GPT-3.5 API,简单写了个接口就上线了。初期用户量少,一切都很顺畅,但当用户量涨到1000+时,问题全来了:用户反馈等待时间太长,有时候要等10秒以上;月底对账时发现,LLM调用费用比预期高出3倍;更麻烦的是,同一个问题,不同用户得到的回答差异很大,甚至出现答非所问的情况。这就是典型的没有针对大模型的核心痛点设计架构,导致应用无法支撑生产级需求。
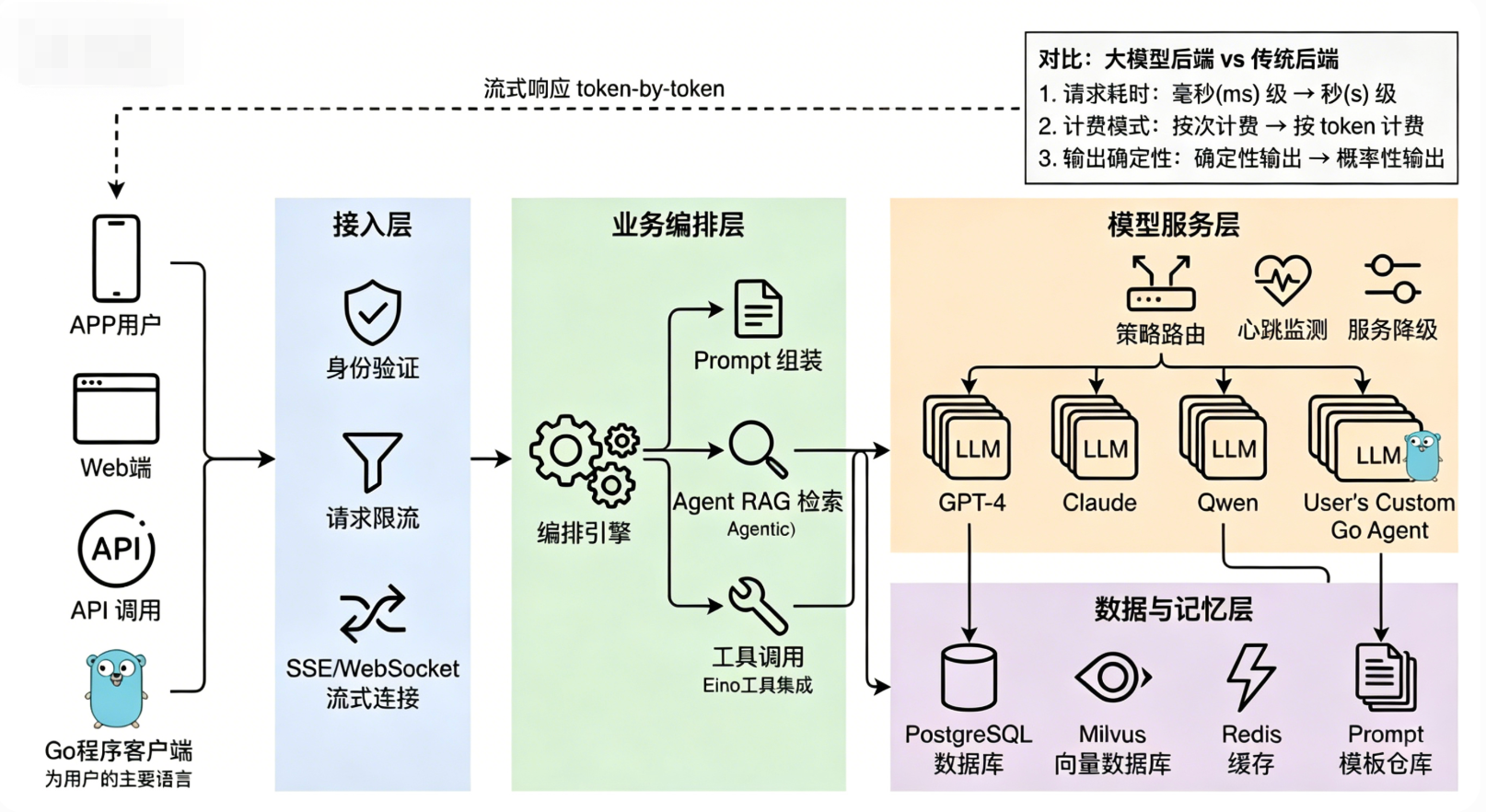
二、整体架构设计:四层架构,层层递进解决核心痛点
针对大模型的三大痛点,生产级大模型应用后端架构,从外到内通常可以分为四层:接入层、业务编排层、模型服务层、数据与记忆层。这四层的划分,看起来和传统微服务架构有点像,但每一层的设计重心、核心组件、优化方向,都和传统后端有本质区别。
很多开发者容易陷入一个误区,就是照搬传统微服务的分层思路,把接入层只做鉴权,把业务层只做简单的逻辑判断,结果导致架构无法适配LLM的特性,后期迭代起来举步维艰。正确的做法是,让每一层都针对性解决大模型的某个痛点,四层协同,形成一个完整的闭环。
下面,我们逐一拆解每一层的设计细节,包括核心职责、关键组件、实战技巧,全程结合实际项目场景,避免空谈理论。
2.1 接入层:守住入口,解决"慢"的第一道防线
接入层是用户请求进入系统的第一道大门,传统后端的接入层,核心职责是协议处理、认证鉴权、流量控制,比如校验用户token、限制接口QPS。但对于大模型应用来说,接入层还有一个更重要的职责:处理流式响应,这是解决"慢"痛点的第一道防线。
为什么流式响应如此重要?我们可以想一下,一次LLM调用需要3-10秒才能生成完整回复,如果我们还是用传统REST API的方式,让用户干等完整响应,体验会非常糟糕,很多用户会以为系统卡死了,直接关闭页面。这也是很多大模型应用原型无法落地的核心原因之一,忽略了流式响应的设计。
所以,大模型应用的接入层,必须把流式响应作为一等公民来设计,而不是事后补丁。目前行业内主流的流式实现方案有两种:SSE和WebSocket,两者各有适用场景,我们可以根据自己的业务需求选择。
SSE(Server-Sent Events),适合单向推送场景,也就是服务端向客户端逐token输出回复,比如常见的大模型对话场景。它的优势是实现简单,天然兼容HTTP协议,不需要额外的协议支持,前端只需要用普通的HTTP请求就能接收流数据,开发成本很低。
WebSocket,适合双向通信场景,比如用户在LLM生成回复的过程中,发送"停止生成""重新生成"的指令,或者需要实时交互的Agent场景。它的优势是双向通信延迟低,但实现复杂度比SSE高,需要维护长连接,还要处理连接断开、重连等问题。
这里给大家一个实战建议:如果你的应用是简单的对话场景,不需要用户实时交互,优先选择SSE;如果是复杂的Agent、多轮交互场景,再选择WebSocket。
但流式传输带来的工程复杂度,也需要我们重点关注,尤其是三个容易踩坑的点:
第一个坑,中间件兼容性问题。Nginx默认会缓冲后端响应,再一次性发给客户端,这会直接导致流式传输失效,用户还是要等完整响应才能看到内容。解决方法很简单,在Nginx配置中显式关掉proxy_buffering,配置如下:
nginx
location /api/stream {
proxy_pass http://your-backend-server;
proxy_buffering off; # 关闭缓冲,实现真正的流式传输
proxy_set_header Connection '';
proxy_http_version 1.1;
proxy_set_header Cache-Control no-cache;
}除了Nginx,很多API网关、WAF(Web应用防火墙)也有类似的缓冲问题,需要提前测试,关闭相关缓冲配置。
第二个坑,错误处理时机变化。在传统REST API中,我们可以根据处理结果返回对应的HTTP状态码,比如400表示参数错误,500表示服务器错误。但在流式场景下,HTTP 200状态码已经在发送流的初期就返回给客户端了,中间如果出现错误,无法再修改状态码,只能在流中插入错误事件,让前端捕获并处理。
比如,我们可以在流中返回JSON格式的错误信息,前端解析后停止接收流,并提示用户:
json
{
"type": "error",
"message": "模型调用超时,请重试",
"code": 504
}第三个坑,token计量问题。LLM调用是按token收费的,流式输出时,我们需要在服务端准确统计每次调用的token消耗,包括输入token和输出token,这就需要对输出流进行拦截和计数。如果计数不准确,会导致成本统计偏差,甚至出现超预算的情况。
工程上比较成熟的做法,是搭建一个流式代理网关,专门负责维护长连接、做流的中继转发、附加token统计元数据、处理超时和异常中断。把流的复杂性封装在这一层,其他层不需要关心流式传输的细节,只需要专注于自己的核心职责。这样既能降低整体架构的复杂度,也能提高可维护性。
除了流式响应,接入层的其他核心职责也不能忽视:
认证鉴权:和传统后端一样,需要校验用户的token、权限,防止未授权访问。可以使用JWT、OAuth2.0等成熟方案,结合Redis存储黑名单,实现token的过期管理和强制登出。
流量控制:大模型调用成本高、并发能力有限,接入层需要做限流、熔断、降级。比如,限制单个用户每分钟的调用次数,防止恶意请求;当后端服务压力过大时,熔断部分非核心接口,优先保证核心功能可用;当用户请求量超过阈值时,返回排队提示,避免系统崩溃。
请求校验:校验用户输入的参数是否合法,比如输入内容的长度、格式,防止恶意输入导致的系统异常。同时,在这里可以做初步的输入过滤,拦截已知的恶意请求,为后续的安全防护打下基础。
2.2 业务编排层:承上启下,解决"不确定"的核心环节
业务编排层是整个架构的核心枢纽,承上启下,一边对接接入层的用户请求,一边调用模型服务层的能力,同时还要和数据与记忆层交互。它的核心职责是理解用户意图、组装Prompt、编排多步调用逻辑,解决LLM输出"不确定"的痛点,同时优化调用链路,提升响应速度。
传统后端的业务层,通常是"接收请求→查数据库→返回结果"的同步短链路,逻辑相对简单。但大模型应用的业务层,逻辑要复杂得多,可能需要编排多轮LLM调用、工具调用、RAG检索,整个链路又长又慢,而且需要处理各种异常情况,保证输出的稳定性和准确性。
业务编排层的设计,主要围绕三个核心点展开:Prompt管理、多步任务编排、意图识别与解析。
2.2.1 Prompt管理:让LLM输出更可控
Prompt在大模型应用中的角色,相当于传统应用中的业务逻辑代码,它直接决定了应用的行为和输出质量。但很多团队在早期开发时,都会犯一个致命的错误:把Prompt硬编码在代码里,和业务逻辑混在一起。
这种做法在原型阶段没问题,简单快捷,但一旦进入生产环境,就会遇到各种麻烦。首先是迭代效率低,Prompt的调优频率远高于代码,我们可能每天都要微调措辞、补充示例, if写在代码里,每次调优都要走完整的开发、测试、发布流程,非常繁琐,严重影响迭代速度。其次是版本管理和回滚困难,Prompt改了一版后,如果效果变差想回滚,和代码绑定在一起,就会影响同次发布的其他功能,风险很高。
所以,生产环境中,我们必须搭建一个独立的Prompt管理服务,本质上就是一个带版本控制的模板仓库,支持灰度发布和快速回滚,让Prompt的迭代和代码解耦。
Prompt管理服务的核心功能,主要包括以下几点:
- 模板管理:将System Prompt、Few-shot示例等固定内容,做成模板,通过变量占位符和业务数据做动态拼装。比如,我们可以定义一个对话模板:
text
你是一个专业的{{role}},用户现在的问题是:{{user_query}}。请结合以下上下文:{{context}},给出简洁、准确的回答,不要冗余。其中,{{role}}、{{user_query}}、{{context}}都是变量,业务编排层在调用时,根据实际情况填充这些变量,生成最终的Prompt。这样既能保证Prompt的一致性,又能灵活适配不同的业务场景。
-
版本控制:每一次Prompt的修改,都生成一个新的版本,记录修改人、修改时间、修改内容。当新Prompt效果不佳时,可以快速回滚到上一个稳定版本,避免影响线上用户。
-
灰度发布:支持将新Prompt的流量逐步放大,比如先让10%的用户使用新Prompt,观察输出效果和用户反馈,没问题再逐步提升到50%、100%。这样可以降低Prompt迭代的风险,避免出现大面积的输出异常。
-
效果监控:统计不同Prompt版本的输出质量、用户满意度、token消耗等指标,为Prompt调优提供数据支撑。比如,通过对比两个版本的回答准确率,判断哪个版本的Prompt效果更好。
目前行业内有很多成熟的Prompt管理工具,比如LangFuse、PromptLayer,它们都提供了上述功能,我们可以直接集成使用,也可以根据自己的业务需求,基于数据库搭建简单的Prompt管理服务。
这里给大家一个实战技巧:Prompt的调优,要遵循"简洁、明确、具体"的原则,避免冗余的指令。很多开发者为了让LLM输出更准确,会写大量的冗余指令,结果不仅增加了token消耗,还可能导致LLM忽略核心指令,输出不符合预期。比如,不要写"请你一定要认真回答,不要敷衍,要准确、简洁,不要冗余",直接写"请给出简洁、准确的回答"即可。
2.2.2 多步任务编排:让复杂链路更高效
大模型应用中,有很多"重任务",比如基于RAG的长文档问答、多步Agent任务、批量内容生成等。这些任务的耗时通常在十几秒到几分钟不等,用传统的同步HTTP请求来承载,显然不合适,会导致用户等待时间过长,甚至出现请求超时的情况。
成熟的做法是,将这些重任务交给异步任务队列处理,业务编排层负责提交任务,后台Worker异步执行,前端通过轮询或WebSocket接收进度推送。这样既能提升用户体验,又能避免同步请求导致的系统阻塞。
在Python生态中,最常用的异步任务队列方案是Celery + Redis,其中Celery作为任务调度器,负责管理任务的提交、执行、重试,Redis作为消息代理,存储任务队列和执行状态。我们可以通过简单的代码,实现异步任务的提交和执行:
python
# 1. 定义Celery实例
from celery import Celery
app = Celery('llm_tasks', broker='redis://localhost:6379/0', backend='redis://localhost:6379/0')
# 2. 定义异步任务(比如RAG长文档问答)
@app.task(bind=True, max_retries=3)
def rag_long_doc_qa(self, doc_id, user_query):
try:
# 步骤1:从向量数据库中检索相关文档
relevant_docs = vector_db.search(user_query, top_k=5)
# 步骤2:拼装Prompt
prompt = prompt_template.render(user_query=user_query, context=relevant_docs)
# 步骤3:调用LLM生成回答
response = llm_client.generate(prompt)
# 步骤4:存储结果
db.save_qa_result(doc_id, user_query, response)
return response
except Exception as e:
# 任务失败时重试
self.retry(exc=e, countdown=5)
# 3. 提交任务
task_id = rag_long_doc_qa.delay(doc_id="doc_123", user_query="请解释文档中的核心观点")前端拿到task_id后,可以通过轮询接口查询任务状态,比如:
python
@app.route('/task/status/<task_id>')
def task_status(task_id):
task = rag_long_doc_qa.AsyncResult(task_id)
if task.state == 'PENDING':
return jsonify({"status": "pending", "progress": 0})
elif task.state == 'SUCCESS':
return jsonify({"status": "success", "result": task.result, "progress": 100})
elif task.state == 'FAILURE':
return jsonify({"status": "failure", "message": str(task.result), "progress": 0})除了异步任务队列,异步任务内部还需要一个编排引擎,来协调多步骤的执行。很多复杂任务,比如RAG问答流程,包含多个步骤,而且步骤之间有串行、并行的依赖关系,比如:先并行执行"查询改写"和"关键词提取",完成后再并行做"向量检索"和"关键词检索",汇总后进行Rerank(重新排序),最后送入LLM生成回答。
这种复杂的编排逻辑,用普通的代码实现,会非常繁琐,而且难以维护。这时就需要用到任务编排引擎,LangGraph就是一个非常合适的选择。它用有向图来定义编排逻辑,每个节点是一个处理步骤,边定义数据流向和条件分支,能够清晰地描述步骤之间的依赖关系,同时支持并行执行,降低任务耗时。
比如,我们可以用LangGraph定义一个简单的RAG编排流程:
python
from langgraph.graph import Graph
# 1. 定义各个处理节点
def rewrite_query(user_query):
# 步骤1:查询改写
return llm_client.generate(f"将用户查询改写为更适合检索的格式:{user_query}")
def extract_keywords(user_query):
# 步骤2:关键词提取
return llm_client.generate(f"提取用户查询的核心关键词:{user_query}")
def vector_search(rewritten_query):
# 步骤3:向量检索
return vector_db.search(rewritten_query, top_k=5)
def keyword_search(keywords):
# 步骤4:关键词检索
return keyword_db.search(keywords, top_k=3)
def rerank(results):
# 步骤5:重新排序
return rerank_model.rank(results)
def generate_answer(context, user_query):
# 步骤6:生成回答
prompt = prompt_template.render(user_query=user_query, context=context)
return llm_client.generate(prompt)
# 2. 构建有向图
graph = Graph()
# 添加节点
graph.add_node("rewrite_query", rewrite_query)
graph.add_node("extract_keywords", extract_keywords)
graph.add_node("vector_search", vector_search)
graph.add_node("keyword_search", keyword_search)
graph.add_node("rerank", rerank)
graph.add_node("generate_answer", generate_answer)
# 3. 定义边(数据流向)
# 并行执行查询改写和关键词提取
graph.add_edge("rewrite_query", "vector_search")
graph.add_edge("extract_keywords", "keyword_search")
# 检索完成后,进入重新排序
graph.add_edge("vector_search", "rerank")
graph.add_edge("keyword_search", "rerank")
# 排序完成后,生成回答
graph.add_edge("rerank", "generate_answer")
# 4. 运行流程
result = graph.invoke({"user_query": "请解释文档中的核心观点"})通过LangGraph,我们可以清晰地定义每个步骤的逻辑和依赖关系,而且能够自动处理并行执行,大大降低了复杂任务的编排难度,同时提升了任务执行效率。
2.2.3 意图识别与解析:让LLM更懂用户需求
LLM输出不确定的一个重要原因,是无法准确理解用户的真实意图。比如,用户输入"Python怎么读JSON",可能是想知道基础的读取方法,也可能是想解决读取过程中遇到的异常问题,还可能是想了解优化读取性能的技巧。如果不能准确识别用户意图,LLM的输出就可能偏离用户需求,导致用户体验变差。
业务编排层的一个核心职责,就是对用户的输入进行意图识别和解析,将模糊的用户需求,转化为明确的任务指令,再分发给对应的处理逻辑。
意图识别的实现方式,主要有两种:一种是基于规则的识别,适合意图类型较少、逻辑简单的场景;另一种是基于LLM的识别,适合意图类型多、逻辑复杂的场景。
基于规则的识别,就是通过关键词匹配、正则表达式等方式,判断用户的意图。比如,当用户输入中包含"读JSON""解析JSON"等关键词时,判断用户的意图是"JSON读取";当包含"报错""异常"等关键词时,判断用户的意图是"问题排查"。这种方式实现简单,效率高,但灵活性差,无法处理复杂的意图。
基于LLM的识别,是通过调用LLM,对用户输入进行意图分类和解析。比如,我们可以给LLM一个明确的Prompt,让它输出用户的意图和关键参数:
text
用户输入:"用Python读取JSON文件时出现报错,提示JSONDecodeError,该怎么解决?"
请识别用户的意图,输出格式为JSON,包含intent(意图名称)和parameters(关键参数)。
意图可选值:json_read、json_parse_error、json_optimize、other。
关键参数包括:language(语言)、error_type(错误类型)、task(任务)。LLM会返回类似以下的结果:
json
{
"intent": "json_parse_error",
"parameters": {
"language": "Python",
"error_type": "JSONDecodeError",
"task": "读取JSON文件"
}
}业务编排层拿到这个结果后,就可以明确用户的意图是解决JSON解析错误,然后调用对应的处理逻辑,比如查询错误解决方案、生成调试代码等,从而让LLM的输出更精准,减少不确定性。
2.3 模型服务层:核心引擎,解决"慢、贵、不确定"的关键
模型服务层是整个架构中技术含量最高的一层,它直接面对LLM的"慢、贵、不确定"三大痛点,核心职责是管理和调用各种LLM,做路由、负载均衡和容错降级,同时优化模型调用效率,降低调用成本。
很多开发者在设计这一层时,会陷入一个误区:只使用一个LLM模型,比如全程调用GPT-4o。这种做法在原型阶段没问题,但在生产环境中风险很高,一旦该模型API超时、报错,整个应用就会瘫痪;而且单一模型无法兼顾所有场景,比如GPT-4o擅长复杂推理,但成本高,不适合简单的分类、提取任务。
生产环境中,模型服务层的设计,核心是"多模型协同",通过模型路由、降级策略、并发管理、性能优化,同时解决"慢、贵、不确定"三个痛点。
2.3.1 多模型路由与降级:保证可用性,降低成本
多模型路由,就是根据任务类型、复杂度、成本预算等条件,将用户请求分发到合适的LLM模型,实现"物尽其用",既保证输出质量,又降低调用成本。
比如,我们可以根据任务复杂度,将模型分为三个等级:
-
高端模型:比如GPT-4o、Claude 3 Opus,擅长复杂推理、长文档理解、多轮对话,用于核心业务场景,比如复杂的Agent任务、专业知识问答;
-
中端模型:比如GPT-3.5 Turbo、Claude 3 Sonnet,性能适中,成本中等,用于常规对话、简单推理场景;
-
低端模型:比如开源的Qwen、Llama 3,成本低,响应快,用于简单的分类、提取、格式转换等场景,比如用户输入的意图识别、关键词提取。
要实现多模型路由,就需要一个模型路由器,它的核心是维护一张"模型能力矩阵",记录每个模型的关键信息,包括上下文窗口、支持的功能(Function Calling、Vision等)、平均延迟、每千token价格、当前健康状态等。
模型能力矩阵的示例如下:
json
{
"models": [
{
"name": "gpt-4o",
"context_window": 128000,
"functions": ["function_calling", "vision"],
"avg_delay": 5000, // 平均延迟(毫秒)
"price_per_1k_tokens": 0.06, // 每千token价格(美元)
"health": "healthy" // 健康状态:healthy/unhealthy
},
{
"name": "claude-3-sonnet",
"context_window": 200000,
"functions": ["function_calling"],
"avg_delay": 4000,
"price_per_1k_tokens": 0.03,
"health": "healthy"
},
{
"name": "qwen-7b",
"context_window": 8192,
"functions": [],
"avg_delay": 1000,
"price_per_1k_tokens": 0.001,
"health": "healthy"
}
]
}路由决策的逻辑,可以基于规则,也可以基于策略:
基于规则的路由:比如"含图片的请求,只发给支持Vision功能的模型""需要Function Calling的请求,发给支持该功能的模型""简单分类任务,发给开源模型"。
基于策略的路由:比如"优先选择延迟最低的健康模型""成本超阈值时,降级到更便宜的模型""核心用户优先使用高端模型,普通用户使用中端模型"。
除了路由,降级策略也是模型服务层的核心设计,它能保证系统的可用性,避免因为单个模型故障导致整个应用瘫痪。一个典型的降级链是:GPT-4o → Claude 3 Sonnet → Qwen-7b,越往后,模型能力可能稍弱,但可用性更高、成本更低。
降级策略的实现逻辑很简单:当首选模型API超时、返回错误,或者健康状态异常时,系统自动切换到备选模型,直到找到可用的模型。如果所有模型都不可用,就返回预设的兜底回复,比如"当前系统繁忙,请稍后重试"。
这里给大家一个实战建议:在实现降级策略时,要设置合理的超时时间,比如高端模型的超时时间设置为8秒,中端模型设置为5秒,低端模型设置为3秒,避免因为等待超时导致用户体验变差。同时,要记录模型的故障日志,方便后续排查问题,优化模型选择策略。
2.3.2 并发与队列管理:提升效率,避免限流
LLM API通常有严格的Rate Limit(调用频率限制),比如OpenAI的GPT-4o,免费版的调用频率限制是每分钟30次,超出限制后,API会返回429错误。如果系统并发量大,没有做好并发管理,就会频繁出现限流错误,影响用户体验。
模型服务层的并发与队列管理,核心是解决两个问题:一是避免触发LLM API的Rate Limit,二是提高模型调用的并发能力,降低响应延迟。
针对API调用的Rate Limit,我们可以在模型服务层做请求排队和令牌桶限速。令牌桶算法的核心逻辑是:系统按照固定的速率生成令牌,每个请求需要获取一个令牌才能调用LLM API,没有令牌的请求就进入队列等待,直到有令牌可用。这样可以平稳地控制请求的发送频率,避免触发Rate Limit。
在Python中,我们可以用ratelimit库实现令牌桶限速:
python
from ratelimit import limits, sleep_and_retry
# 定义限速规则:每分钟最多调用30次
@sleep_and_retry
@limits(calls=30, period=60)
def call_llm_api(prompt):
response = llm_client.generate(prompt)
return response对于自部署的开源模型(比如Qwen、Llama 3),我们还需要做Dynamic Batching(动态批处理),来提高GPU利用率。动态批处理的核心逻辑是:将多个用户的请求合并成一个批次,一起发送给模型进行推理,减少GPU的空闲时间,提升并发处理能力。vLLM和TGI(Text Generation Inference)是目前行业内最常用的开源模型部署工具,它们都内置了Dynamic Batching功能,能够大幅提升模型的推理效率。
比如,使用vLLM部署Qwen-7b模型,只需简单的命令即可开启Dynamic Batching:
bash
vllm serve qwen/Qwen-7B-Chat --port 8000 --max-batch-size 32其中,--max-batch-size参数指定了最大批处理大小,根据GPU的显存大小进行调整,显存越大,批处理大小可以设置得越大。
另外,模型服务层还需要做负载均衡,当部署了多个模型实例(比如多个vLLM实例)时,将请求均匀地分发到各个实例,避免单个实例压力过大。可以使用Nginx、HAProxy等成熟的负载均衡工具,也可以自己实现简单的轮询、随机分发逻辑。
2.3.3 模型性能优化:解决"慢"的核心手段
LLM调用慢,是影响用户体验的核心问题之一,除了流式响应,模型服务层还可以通过多种方式优化模型性能,降低响应延迟。
第一种方式,是使用模型量化。模型量化是将模型的权重从高精度(比如FP32)转换为低精度(比如FP16、INT8),这样可以减少模型的显存占用,提高推理速度。比如,将Qwen-7b模型从FP32量化为INT8,显存占用可以减少75%,推理速度可以提升2-3倍,而且输出质量几乎没有损失。
目前,vLLM、TGI都支持模型量化,我们可以在部署模型时,指定量化方式:
bash
vllm serve qwen/Qwen-7B-Chat --port 8000 --quantize int8第二种方式,是使用KV缓存。KV缓存是大模型推理过程中的一种优化技术,它可以缓存模型推理过程中计算的Key和Value值,后续生成新token时,不需要重新计算所有的Key和Value,只需要计算新token的相关值,从而大幅提升推理速度。尤其是在长对话场景中,KV缓存的优化效果非常明显。
我们可以通过HuggingFace Transformers API,手动开启KV缓存:
python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("qwen/Qwen-7B-Chat")
model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-7B-Chat", device_map="auto")
# 开启KV缓存
inputs = tokenizer("你好", return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, use_cache=True, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))需要注意的是,KV缓存会占用一定的显存,而且缓存大小会随着对话长度的增加而增长,对于长对话场景,需要合理设置缓存的最大长度,避免显存溢出。
第三种方式,是模型选型优化。不同的模型,在不同的任务场景下,性能差异很大。比如,长文档理解场景,Claude 3的上下文窗口更大,性能更好;简单分类场景,开源的Qwen-7b响应更快,成本更低。我们需要根据具体的业务场景,选择最合适的模型,避免"大材小用",既保证性能,又降低成本。
2.4 数据与记忆层:底层支撑,保障数据安全与高效访问
数据与记忆层是整个架构的底层支撑,核心职责是负责对话历史、向量检索、用户画像、Prompt模板等数据的持久化存储,同时保障数据的安全、高效访问。传统后端的数据层,主要以关系型数据库(比如MySQL)为主,但大模型应用的数据层,需要新增一系列新的组件,来适配LLM的特性。
数据与记忆层的设计,主要围绕四个核心组件展开:关系型数据库、向量数据库、缓存系统、Prompt模板库。这四个组件协同工作,既保证数据的持久化存储,又保证数据的高效访问,同时支撑业务编排层和模型服务层的正常运行。
2.4.1 关系型数据库:存储结构化数据
关系型数据库(比如MySQL、PostgreSQL),主要用于存储结构化数据,比如用户信息、用户权限、对话历史的元数据、任务记录等。这些数据具有结构化强、需要事务支持、需要复杂查询的特点,非常适合用关系型数据库存储。
比如,对话历史的元数据,可以设计如下表结构:
sql
CREATE TABLE chat_history (
id INT PRIMARY KEY AUTO_INCREMENT,
user_id VARCHAR(64) NOT NULL, -- 用户ID
session_id VARCHAR(64) NOT NULL, -- 会话ID
prompt TEXT NOT NULL, -- 用户输入的Prompt
response TEXT NOT NULL, -- LLM的响应
token_input INT NOT NULL, -- 输入token数
token_output INT NOT NULL, -- 输出token数
model_name VARCHAR(32) NOT NULL, -- 调用的模型名称
create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, -- 创建时间
update_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);关系型数据库的优化,和传统后端类似,比如给常用字段加索引(比如user_id、session_id),提升查询速度;根据数据量,做分库分表,避免单表数据量过大导致的性能下降;开启事务,保证数据的一致性。
2.4.2 向量数据库:支撑RAG与语义检索
向量数据库是大模型应用数据层的核心组件之一,主要用于存储文档的Embedding向量,支撑RAG(检索增强生成)场景。RAG的核心逻辑是,将用户的问题转化为Embedding向量,在向量数据库中检索相关的文档,将文档内容作为上下文,拼装到Prompt中,让LLM基于相关文档生成回答,这样既能提升回答的准确性,又能避免LLM的"幻觉"问题。
传统的关系型数据库,无法高效地进行向量相似度检索,而向量数据库专门针对向量检索进行了优化,能够快速检索出与查询向量最相似的向量,检索速度比传统数据库快几个数量级。
目前行业内主流的向量数据库有:Pinecone、Milvus、Chroma、FAISS等。其中,FAISS是Facebook开源的向量检索库,适合小规模数据场景;Milvus、Chroma适合中大规模数据场景,支持分布式部署,能够支撑高并发检索;Pinecone是托管式向量数据库,无需自己部署,适合快速上线的场景。
我们可以通过简单的代码,实现向量数据库的检索功能(以Milvus为例):
python
from pymilvus import MilvusClient
# 1. 连接Milvus
client = MilvusClient("http://localhost:19530")
# 2. 创建集合(类似数据库表)
client.create_collection(
collection_name="document_embeddings",
dimension=768 # Embedding向量的维度
)
# 3. 插入文档Embedding
documents = [
{"id": 1, "embedding": [0.1, 0.2, ..., 0.768], "text": "文档1内容"},
{"id": 2, "embedding": [0.3, 0.4, ..., 0.768], "text": "文档2内容"}
]
client.insert(collection_name="document_embeddings", data=documents)
# 4. 检索相似文档
query_embedding = [0.15, 0.25, ..., 0.768] # 用户问题的Embedding
results = client.search(
collection_name="document_embeddings",
data=[query_embedding],
limit=5, # 检索前5个最相似的文档
output_fields=["text"]
)
# 5. 提取检索结果
relevant_docs = [hit["entity"]["text"] for hit in results[0]]向量数据库的优化,主要关注两个点:一是Embedding模型的选择,选择合适的Embedding模型(比如BERT、Sentence-BERT),能够提升检索的准确性;二是索引的优化,向量数据库支持多种索引类型(比如IVF_FLAT、HNSW),HNSW索引的检索速度更快,适合高并发场景,IVF_FLAT索引的检索准确性更高,适合对准确性要求高的场景。
2.4.3 缓存系统:降低延迟,减少成本
缓存在传统后端是锦上添花,但在大模型后端,是必须有的基础设施。原因很直接,LLM调用既慢又贵,如果同样的问题能从缓存中直接返回,既能将响应延迟从几秒降到几毫秒,又能节省大量的调用成本。
大模型应用的缓存系统,通常分为三层,层层递进,提升缓存命中率,降低成本:
第一层,精确匹配缓存。核心逻辑是,将用户输入的hash值作为key,LLM的响应作为value,存入Redis。当用户输入完全相同时,直接从缓存中返回响应,无需调用LLM。这种方式实现简单,延迟极低,但命中率通常很低,因为自然语言表达的多样性,同一个意思有无数种问法,比如"Python怎么读取JSON文件"和"用Python解析JSON文件的方法",虽然语义相同,但hash值完全不同,无法命中缓存。
精确匹配缓存的实现代码(以Redis为例):
python
import redis
import hashlib
redis_client = redis.Redis(host="localhost", port=6379, db=0)
def get_cached_response(user_query):
# 计算用户输入的hash值
query_hash = hashlib.md5(user_query.encode("utf-8")).hexdigest()
# 从缓存中获取响应
cached_response = redis_client.get(query_hash)
if cached_response:
return cached_response.decode("utf-8")
return None
def set_cached_response(user_query, response, expire=3600):
# 计算用户输入的hash值
query_hash = hashlib.md5(user_query.encode("utf-8")).hexdigest()
# 存入缓存,设置过期时间(1小时)
redis_client.setex(query_hash, expire, response)第二层,语义缓存。这是更实用的缓存方式,核心思路是,将用户输入转化为Embedding向量,在缓存中做向量相似度检索,当相似度超过预设阈值(比如0.85)时,直接返回缓存中的响应。这种方式能够解决自然语言表达多样性的问题,缓存命中率远高于精确匹配缓存。
GPTCache是专门做语义缓存的开源方案,我们可以直接集成使用,它支持多种Embedding模型和向量数据库,能够快速实现语义缓存功能:
python
from gptcache import Cache
from gptcache.adapter import openai
from gptcache.embedding import SentenceEmbedding
from gptcache.storage import RedisStorage
# 初始化缓存
embedding = SentenceEmbedding("all-MiniLM-L6-v2")
storage = RedisStorage(redis_client=redis_client)
cache = Cache(embedding=embedding, storage=storage)
# 开启缓存
openai.ChatCompletion.create = cache.cache_embedding(openai.ChatCompletion.create)
# 调用LLM,自动触发缓存
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Python怎么读取JSON文件"}]
)语义缓存的关键,是相似度阈值的调优,需要根据业务场景进行调整。阈值设太高,缓存命中率低,无法起到节省成本的作用;阈值设太低,可能返回不太相关的响应,影响用户体验。通常,阈值设置在0.8-0.9之间,效果比较好。
第三层,Prompt模板缓存。在实际项目中,System Prompt和Few-shot示例通常是固定的,每次请求都带上这些固定前缀,会浪费大量的token,增加调用成本。OpenAI的Prompt Caching和Anthropic的Cache Control机制,就是针对这个场景设计的。
Prompt模板缓存的核心逻辑是,将Prompt的固定前缀缓存在模型服务端,后续请求只需传递增量部分(比如用户的具体问题),模型服务端将固定前缀和增量部分拼接,生成完整的Prompt。这样既减少了网络传输量,又降低了token费用,缓存命中的token价格通常是原价的10%-25%。
比如,使用OpenAI的Prompt Caching,只需在调用API时,指定缓存控制参数:
python
import openai
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "你是一个专业的Python开发工程师,擅长解答Python相关问题。", "cache_control": {"type": "ephemeral"}},
{"role": "user", "content": "Python怎么读取JSON文件"}
]
)其中,cache_control参数指定了System Prompt的缓存类型,ephemeral表示临时缓存,模型服务端会缓存这个System Prompt,后续相同的System Prompt请求,只需传递用户的问题即可。
2.4.4 Prompt模板库:与业务编排层协同
Prompt模板库,本质上是一个持久化的模板存储系统,和业务编排层的Prompt管理服务协同工作,负责存储所有的Prompt模板、版本信息、灰度发布配置等。它可以基于关系型数据库或文档数据库(比如MongoDB)实现,核心是保证Prompt模板的持久化、可查询、可管理。
比如,使用MongoDB存储Prompt模板,可以设计如下文档结构:
json
{
"_id": "template_123",
"name": "python_qa_template",
"content": "你是一个专业的{{role}},用户现在的问题是:{{user_query}}。请结合以下上下文:{{context}},给出简洁、准确的回答。",
"variables": ["role", "user_query", "context"],
"version": "v1.0",
"gray_rate": 10, // 灰度发布比例(10%)
"status": "active", // 状态:active/inactive
"create_time": "2024-05-01T10:00:00Z",
"update_time": "2024-05-02T15:30:00Z"
}Prompt模板库的核心功能,是支持模板的增删改查、版本管理、灰度发布配置,业务编排层在需要拼装Prompt时,从模板库中获取对应的模板,填充变量,生成最终的Prompt。这样既能保证Prompt模板的统一管理,又能实现模板的快速迭代和回滚。
三、架构优化:可观测性与成本管控,让架构更稳定、更经济
很多开发者在设计大模型应用后端架构时,只关注功能实现,忽略了可观测性和成本管控,导致应用上线后,出现问题无法快速排查,成本失控。生产级架构,不仅要能正常运行,还要能被监控、被管理,同时控制成本,这样才能长期稳定运行。
下面,我们就来拆解可观测性和成本管控的设计思路,这也是面试中非常加分的知识点。
3.1 可观测性:全方位监控,快速排查问题
大模型应用的可观测性需求,比传统后端复杂得多。传统后端主要关心QPS、延迟、错误率这些指标,但大模型后端,除了这些,还需要追踪每次LLM调用的token消耗、Prompt的完整内容和模型的完整输出、缓存命中率、模型路由命中分布等。
一个完善的可观测性体系,通常包含三个维度:链路追踪、实时监控、日志审计。这三个维度协同工作,全方位监控系统的运行状态,快速排查问题。
3.1.1 链路追踪(Tracing):追踪请求全链路
链路追踪的核心,是记录每个请求从接入到返回的完整调用链,尤其是LLM调用链路,包括哪个模型、什么Prompt、返回了什么、耗时多久、花了多少token。这样,当出现问题时,我们可以快速定位到问题所在的环节,比如是接入层的流式传输有问题,还是模型服务层的调用超时,或是业务编排层的逻辑有漏洞。
传统的链路追踪工具(比如Jaeger、Zipkin),虽然也能追踪调用链,但无法很好地适配LLM调用的特性。目前,行业内有很多LLM原生的链路追踪工具,比如LangSmith、LangFuse,它们专门针对大模型应用设计,能够自动追踪LLM调用、Prompt内容、token消耗、工具调用流程等关键信息,甚至支持Prompt回放、输出对比,帮助我们快速定位问题。
实战中,我们可以将链路追踪工具与业务代码深度集成,给每个请求分配一个唯一的trace_id,贯穿接入层、业务编排层、模型服务层、数据与记忆层,记录每个环节的耗时、输入输出、异常信息。比如,当用户反馈"回答异常"时,我们可以通过trace_id,快速查到对应的Prompt内容、调用的模型、检索的文档、token消耗等信息,判断是Prompt设计问题、模型输出异常,还是检索结果不准确。
另外,链路追踪的核心是"细粒度",但也要避免过度追踪导致的性能损耗。我们可以针对性地追踪关键链路,比如LLM调用、RAG检索、多步任务编排等核心环节,而对于简单的参数校验、缓存查询等环节,可以适当简化追踪粒度,平衡可观测性和系统性能。
3.1.2 实时监控(Monitoring):实时感知系统状态
实时监控是可观测性体系的核心,它能帮助我们实时感知系统的运行状态,提前发现潜在问题,避免故障扩大。大模型应用的实时监控,需要覆盖"系统指标、业务指标、模型指标"三个维度,缺一不可。
第一个维度,系统指标,主要监控服务器、中间件的运行状态,和传统后端类似,包括CPU利用率、内存占用、GPU利用率(自部署模型场景)、网络带宽、数据库QPS、缓存命中率等。其中,GPU利用率是自部署开源模型的核心监控指标,一旦GPU利用率过高(比如超过80%),会导致模型推理延迟大幅增加,需要及时扩容;如果GPU利用率过低,说明资源浪费,需要优化批处理大小或缩减资源。
第二个维度,业务指标,主要监控与用户体验、业务运行相关的指标,比如请求QPS、平均响应时间、错误率、用户会话数、活跃用户数等。其中,错误率需要细分类型,比如接入层的限流错误、模型服务层的调用超时错误、RAG检索的无结果错误等,不同类型的错误对应不同的处理策略。比如,限流错误增多,说明用户请求量超出预期,需要调整限流阈值或扩容;模型调用超时错误增多,说明模型服务层压力过大,需要优化模型性能或增加降级策略。
第三个维度,模型指标,这是大模型应用特有的监控指标,也是最容易被忽略的,主要包括token消耗(输入token、输出token、总token)、模型调用成功率、模型路由分布、Prompt命中率、输出质量评分等。这些指标直接反映模型服务的运行状态和成本消耗,比如token消耗突然激增,可能是Prompt冗余、恶意请求或模型选型不当导致的,需要及时排查;模型调用成功率下降,可能是模型API故障或降级策略触发,需要及时检查模型健康状态。
实战中,我们可以使用Prometheus + Grafana搭建实时监控平台,通过自定义指标采集器,采集上述三类指标,制作可视化仪表盘,设置告警阈值。比如,当模型调用超时率超过5%、GPU利用率超过85%、token消耗单日超出预算10%时,自动触发告警(短信、邮件、企业微信等),让开发人员第一时间介入处理。
3.1.3 日志审计(Logging):追溯问题根源
日志审计是可观测性体系的兜底保障,它能记录系统运行的所有细节,当链路追踪和实时监控无法定位问题时,通过日志可以追溯问题根源。大模型应用的日志,需要区分不同层级,做到"结构化、可检索、可分析",避免无意义的日志堆砌。
我们可以将日志分为四个层级,分别对应架构的四层,每个层级的日志重点不同:
-
接入层日志:主要记录用户请求的基本信息,比如请求IP、用户ID、请求路径、请求参数、响应状态码、流式传输状态、限流/鉴权结果等,用于排查用户请求无法正常接入的问题;
-
业务编排层日志:主要记录意图识别结果、Prompt拼装内容、多步任务编排流程、任务状态( pending/success/failure )、异常信息等,用于排查业务逻辑漏洞、Prompt设计问题;
-
模型服务层日志:主要记录模型调用信息,比如调用的模型名称、输入输出token数、调用耗时、响应内容(脱敏处理)、模型降级触发情况、限流情况等,用于排查模型调用异常、成本异常;
-
数据与记忆层日志:主要记录数据库查询、向量检索、缓存操作、Prompt模板读取等信息,比如检索结果、缓存命中情况、数据库操作耗时等,用于排查数据存储、检索相关的问题。
需要注意的是,日志中不能包含敏感信息,比如用户的隐私数据、完整的Prompt和响应内容(可做脱敏处理,比如替换关键信息为***),避免数据泄露。同时,日志需要结构化存储(比如JSON格式),方便后续通过ELK(Elasticsearch + Logstash + Kibana)等工具进行检索和分析,比如通过用户ID查询该用户的所有请求日志,通过模型名称查询某类模型的调用情况。
3.2 成本管控:让架构更经济,避免成本失控
大模型应用的成本,主要集中在LLM调用(API费用或自部署的硬件成本),这也是区别于传统后端的核心成本点。很多团队在应用上线后,都会遇到"成本超预算"的问题,比如原本预计每月1万元的API费用,实际消耗达到3万元,核心原因就是没有做好成本管控。
成本管控的核心思路是"开源节流":"节流"是减少不必要的LLM调用,降低单位请求的token消耗;"开源"是优化模型选型、提升资源利用率,降低单位token的成本。下面,我们从四个维度拆解成本管控的实战技巧,每一个都能直接落地,帮助你快速降低成本。
3.2.1 减少无效调用:避免"白花钱"
无效调用是成本浪费的主要原因之一,比如用户重复发送相同的请求、恶意请求(比如频繁发送无意义内容)、前端误触发请求等,这些调用不仅浪费token,还会增加系统压力。我们可以通过三个方式减少无效调用:
第一,完善缓存体系,这是最直接、最有效的方式。通过前文提到的"精确匹配缓存+语义缓存+Prompt模板缓存"三层缓存,将重复请求、语义相似请求拦截在缓存层,无需调用LLM,既能降低成本,又能提升响应速度。实战中,建议将语义缓存的相似度阈值设置在0.85左右,兼顾缓存命中率和输出质量,同时给缓存设置合理的过期时间(比如热门请求1小时,冷门请求10分钟),避免缓存占用过多内存。
第二,增加请求过滤机制。在接入层对用户请求进行过滤,拦截恶意请求、无意义请求(比如纯符号、空白内容)、重复请求(比如10秒内同一用户发送相同请求)。比如,通过关键词匹配、正则表达式,拦截"测试""123"等无意义请求;通过Redis记录用户最近10秒的请求,避免重复调用。
第三,优化前端交互逻辑。比如,前端添加"发送确认"按钮,避免用户误触发送;当用户在LLM生成回复的过程中关闭页面,前端及时通知后端停止模型调用,避免生成无效的响应,浪费token。
3.2.2 优化token消耗:降低单位请求成本
LLM调用是按token收费的,输入token和输出token都会计费,因此,优化token消耗,就能直接降低单位请求的成本。主要有三个优化方向:
第一,精简Prompt,避免冗余。前文提到,Prompt的调优要遵循"简洁、明确、具体"的原则,去掉冗余的指令,比如不要写"请你一定要认真回答,不要敷衍,要准确、简洁",直接写"请给出简洁、准确的回答"。同时,System Prompt只保留核心角色和指令,Few-shot示例按需添加,避免过多示例导致输入token激增。
第二,控制输出token长度。根据业务场景,给LLM的输出设置合理的最大token限制,比如常规对话场景,设置max_new_tokens=100-200,避免LLM输出冗余内容,浪费token。同时,在Prompt中明确要求"输出控制在XX字以内",进一步约束输出长度。
第三,优化对话历史管理。多轮对话场景中,不需要将所有历史对话都传入LLM,只需传入与当前问题相关的历史内容,比如只保留最近3-5轮对话,或者通过摘要的方式,将历史对话浓缩为一段简短的上下文,减少输入token消耗。比如,用户进行多轮对话时,后端自动将历史对话摘要为"用户之前询问了Python读取JSON的方法,现在想了解异常处理",再传入LLM。
3.2.3 优化模型选型:选对模型,降低单位token成本
不同模型的单位token成本差异很大,比如GPT-4o每千token0.06美元,而开源的Qwen-7b每千token仅0.001美元,差异达到60倍。因此,优化模型选型,根据任务场景选择合适的模型,是降低成本的核心手段。
实战中,我们可以按照"任务复杂度分层选型",结合模型能力矩阵,实现"物尽其用":
-
简单任务(意图识别、关键词提取、格式转换):优先使用开源模型(Qwen-7b、Llama 3),自部署后成本极低,而且响应速度快,完全能满足需求;
-
常规任务(常规对话、简单推理、基础问答):使用中端模型(GPT-3.5 Turbo、Claude 3 Sonnet),平衡成本和输出质量,比高端模型成本低50%以上;
-
核心任务(复杂推理、长文档理解、专业知识问答):使用高端模型(GPT-4o、Claude 3 Opus),确保输出质量,同时通过降级策略,在模型不可用时切换到中端模型,兼顾可用性和成本。
另外,对于自部署的开源模型,我们可以通过模型量化(INT8/FP16)、动态批处理等方式,提高GPU利用率,降低硬件成本。比如,将Qwen-7b量化为INT8后,GPU显存占用减少75%,可以部署在更廉价的GPU上,同时推理速度提升2-3倍,间接降低单位请求的硬件成本。
3.2.4 成本监控与复盘:及时发现成本异常
成本管控不是一劳永逸的,需要持续监控和复盘,才能及时发现成本异常,优化管控策略。我们可以从两个方面入手:
第一,建立成本监控体系。通过Prometheus + Grafana采集token消耗、模型调用次数、各模型的成本占比等指标,制作成本仪表盘,实时监控每日、每周、每月的成本消耗,设置成本告警阈值。比如,当单日token消耗超出预算10%时,自动触发告警,排查是否存在恶意请求、Prompt冗余等问题。
第二,定期成本复盘。每周、每月对成本消耗进行复盘,分析成本构成(比如哪个模型的调用成本最高、哪个业务场景的token消耗最多),找出成本浪费的环节,优化管控策略。比如,发现意图识别任务的token消耗占比过高,可优化Prompt或切换为更廉价的开源模型;发现某类用户的token消耗异常,可排查是否存在恶意请求。
3.3 架构容错与容灾:让架构更稳定,抵御突发故障
生产级架构,不仅要解决"慢、贵、不确定"的核心痛点,还要能抵御突发故障,比如模型API宕机、服务器故障、网络中断等,确保系统持续可用。大模型应用的容错与容灾设计,主要围绕"降级、熔断、冗余、备份"四个核心思路展开,覆盖架构的每一层。
3.3.1 降级策略:故障时"保核心、弃非核心"
降级策略的核心是"当系统出现故障时,放弃非核心功能,优先保证核心功能可用",避免故障扩散导致整个系统瘫痪。大模型应用的降级,主要分为三个层面:
-
模型层面降级:这是最核心的降级,前文在模型服务层已经提到,建立模型降级链(高端模型→中端模型→低端模型→兜底回复),当首选模型不可用时,自动切换到备选模型,直到找到可用的模型;如果所有模型都不可用,返回预设的兜底回复(比如"当前系统繁忙,请稍后重试"),避免用户看到错误页面。
-
功能层面降级:当系统压力过大(比如QPS超出阈值)或部分组件故障时,放弃非核心功能,优先保证核心功能可用。比如,关闭批量内容生成、长文档分析等非核心功能,只保留常规对话功能;关闭语义缓存,只保留精确匹配缓存,减少系统压力。
-
数据层面降级:当向量数据库、关系型数据库出现故障时,启用本地缓存或静态数据,临时支撑系统运行。比如,向量数据库宕机时,暂时使用本地预存的文档片段,作为RAG检索的上下文,避免检索功能完全不可用;数据库宕机时,暂时不存储对话历史,只保证实时对话功能可用,待数据库恢复后,再同步数据。
3.3.2 熔断策略:避免"雪崩效应"
当某个组件(比如模型API、向量数据库)出现频繁故障时,如果持续向该组件发送请求,会导致故障扩散,引发"雪崩效应",比如模型API超时,导致业务编排层线程阻塞,进而导致接入层请求堆积,最终整个系统瘫痪。熔断策略的核心是"当组件故障频率超过阈值时,暂时停止向该组件发送请求,等待组件恢复"。
实战中,我们可以使用Resilience4j、Sentinel等熔断工具,给模型调用、数据库查询、向量检索等关键接口设置熔断规则,比如"1分钟内调用失败次数超过10次,触发熔断,熔断时间为30秒"。在熔断期间,系统不再向该组件发送请求,直接返回降级结果,避免故障扩散;熔断时间结束后,系统尝试发送少量请求,检测组件是否恢复,若恢复则正常调用,若未恢复则继续熔断。
3.3.3 冗余部署:避免"单点故障"
单点故障是系统不稳定的主要原因之一,比如单个服务器宕机、单个模型实例故障、单个数据库节点故障,都会导致系统部分功能不可用。冗余部署的核心是"给关键组件部署多个实例,当某个实例故障时,其他实例可以无缝接管"。
主要包括三个层面的冗余部署:
-
服务器冗余:将接入层、业务编排层、模型服务层部署在多个服务器(或容器)上,通过Nginx、Kubernetes等工具实现负载均衡,当某个服务器宕机时,其他服务器可以接管请求,避免服务中断。
-
模型服务冗余:对于自部署的开源模型,部署多个模型实例(比如多个vLLM实例),通过负载均衡工具分发请求,当某个实例故障时,其他实例可以正常提供服务;对于第三方API模型,同时接入多个模型服务商(比如同时接入OpenAI和Anthropic),当其中一个服务商的API宕机时,切换到另一个服务商。
-
数据冗余:对关系型数据库、向量数据库进行主从复制、分布式部署,比如MySQL主从复制,主库负责写入数据,从库负责读取数据,当主库故障时,从库可以切换为主库,恢复数据读写;向量数据库采用分布式部署,多个节点存储相同的数据,当某个节点故障时,其他节点可以正常提供检索服务。
3.3.4 数据备份与恢复:避免数据丢失
数据是系统的核心资产,比如用户对话历史、Prompt模板、向量数据等,一旦数据丢失,会导致用户体验下降、业务中断,甚至造成不可逆的损失。数据备份与恢复的核心是"定期备份数据,确保数据可恢复"。
实战中,我们可以按照"不同数据类型,不同备份策略"的原则,制定备份计划:
-
结构化数据(用户信息、对话历史元数据、Prompt模板):采用"每日全量备份 + 实时增量备份"的方式,备份到异地服务器或云存储(比如阿里云OSS、AWS S3),备份文件保留30天,确保数据可以回滚到任意时间点。
-
向量数据:由于向量数据量大,全量备份成本高,可以采用"每周全量备份 + 每日增量备份"的方式,同时利用向量数据库的快照功能,快速备份和恢复数据。
-
缓存数据:缓存数据(Redis)采用持久化机制(RDB + AOF),RDB用于全量备份,AOF用于实时增量备份,确保缓存数据在Redis宕机后,能够快速恢复,避免缓存雪崩。
同时,需要定期进行数据恢复测试,比如每月随机抽取一次备份文件,测试数据恢复的成功率和恢复时间,确保备份数据可用,避免出现"备份了但无法恢复"的问题。
四、实战总结:生产级架构的核心原则与落地建议
看到这里,相信你已经对生产级大模型应用后端架构有了完整的理解。最后,我们总结一下核心原则和落地建议,帮助你快速将架构设计落地到实际项目中,避开常见的坑。
4.1 核心原则:围绕"慢、贵、不确定"展开
所有架构设计的决策,都要围绕大模型的三大痛点展开:
-
解决"慢":接入层做流式响应,模型服务层做性能优化(量化、KV缓存、动态批处理),业务编排层做异步任务编排,数据层做缓存优化;
-
解决"贵":减少无效调用,优化token消耗,分层选型模型,建立成本监控体系;
-
解决"不确定":业务编排层做Prompt管理、意图识别,模型服务层做多模型协同、降级策略,数据层做RAG检索,提升输出的稳定性和准确性。
4.2 落地建议:从简单到复杂,逐步迭代
不要一开始就追求"完美架构",可以按照"原型→最小可用版本→生产级版本"的步骤,逐步迭代优化,降低落地难度:
-
原型阶段:重点实现核心功能,比如简单的LLM调用、基础对话,无需考虑复杂的分层、缓存、监控,快速验证业务可行性;
-
最小可用版本(MVP):搭建基础的四层架构,实现接入层的流式响应、鉴权限流,业务编排层的Prompt管理、简单任务编排,模型服务层的单模型调用,数据层的基础存储,确保系统能支撑小规模用户(100-1000人)稳定使用;
-
生产级版本:逐步优化架构,添加多模型协同、缓存体系、可观测性、成本管控、容错容灾等功能,提升系统的稳定性、可扩展性和经济性,支撑千级、万级用户使用。
4.3 常见坑提醒:避开这些误区,少走弯路
结合实战经验,总结几个常见的架构设计误区,帮你少走弯路:
-
照搬传统微服务架构:忽略大模型的"慢、贵、不确定"痛点,把接入层只做鉴权,业务层只做简单逻辑,导致系统无法适配LLM特性,后期迭代困难;
-
Prompt硬编码:将Prompt和业务代码混在一起,导致Prompt迭代效率低、版本管理困难,无法快速调优;
-
单一模型依赖:只使用一个LLM模型,没有降级策略,一旦模型API宕机,整个系统瘫痪;
-
忽略成本管控:只关注功能实现,不监控token消耗,导致成本超预算;
-
缺乏可观测性:没有链路追踪、实时监控、日志审计,出现问题无法快速排查,故障扩大。
最后,生产级大模型应用后端架构,没有"唯一标准答案",需要根据你的业务场景、用户规模、成本预算,灵活调整架构设计。比如,小规模用户、低成本预算的场景,可以简化架构,使用托管式模型和托管式数据库,降低开发和运维成本;大规模用户、高可用性要求的场景,需要完善分层架构、冗余部署、容错容灾,确保系统稳定运行。