文章目录
-
- 一、三种大模型部署格式
-
- [1.1. 选择合适的部署格式](#1.1. 选择合适的部署格式)
- 二、模型优化【重点】
-
- [2.1. **模型压缩:让大模型变小、变快**](#2.1. 模型压缩:让大模型变小、变快)
-
- [2.1.1. 模型压缩三剑客:权重量化、权重剪枝、蒸馏](#2.1.1. 模型压缩三剑客:权重量化、权重剪枝、蒸馏)
- [2.1.2. 权重量化(在原模型上降精度)](#2.1.2. 权重量化(在原模型上降精度))
- [2.1.3. 权重剪枝(在原模型上删连接)](#2.1.3. 权重剪枝(在原模型上删连接))
- [2.1.4. 知识蒸馏(训练一个全新的小模型)](#2.1.4. 知识蒸馏(训练一个全新的小模型))
一、三种大模型部署格式
三种大模型部署时用的文件格式 / 载体:ONNX、GGUF与TFLite。
真实场景应基于部署设备去选择模型:
| 格式 | 主要优势 | 典型适用场景 |
|---|---|---|
| ONNX | 跨框架兼容好,NVIDIA 硬件优化完善 | PC/GPU 服务器、边缘设备 |
| GGUF | 轻量本地推理,支持量化,CPU 推理性能好 | 通用格式:移动端(iOS/Android)、llama.cpp 普通电脑部署 |
| TFLite | 专为移动设备优化,Android 生态支持好 | Android 手机端轻量部署 |
例如 ONNX 格式的大模型
https://www.modelscope.cn/models/onnx-community/Qwen3-0.6B-ONNX
例如 TFLite 格式的大模型
https://www.modelscope.cn/models/google/gemma-1.1-2b-it-tflite
1.1. 选择合适的部署格式
iOS > Core ML (优先使用ANE)
Android > TFLite + Hexagon Delegate 或 ONNX Runtime Mobile
二、模型优化【重点】
如果部署后发现模型运行效率低、或模型太大需要进一步压缩模型。
注:选择模型时尽量选择已经蒸馏、剪枝完的模型;避免自己再进行蒸馏。
模型的进一步压缩的目标:在尽量不牺牲精度的前提下,让AI模型跑得更快、更省、更远。
2.1. 模型压缩:让大模型变小、变快
基础知识了解
最重要的概念:模型文件里装的是什么?
1. 下载的模型文件(几个 GB),里面装的是无数个数字(权重)。
没有文字、没有知识库,从头到尾就只有一大堆普通小数 ,比如 0.25、1.36、-0.78 这种。
AI 所有的聪明、会说话、懂知识,全靠这堆数字撑起来。
2. 7B=70亿参数,就是 整整70亿个这种数字
参数 = 就是一个单独的数字
7B 模型,直白说:文件里老老实实存了 70亿个独立数字。
3. 重点:每个数字,代表神经元之间「连接的重要程度」
把神经网络想成无数个节点(神经元)互相拉线连起来:
- 每两根神经元之间有一根连线
- 每一根连线,对应一个数字
这个数字多大,就代表这根连线影响力有多强 :- 数字大:这条通路很重要,信号优先走这里
- 数字小:这条通路不重要,几乎不起作用
- 负数:起到抑制、抵消的作用
简单说:一个数字 = 一根神经连线的强弱等级 。
模型学知识的过程,就是自动把这70亿个数字调到最合适的大小,固定下来存进文件。
4. 微调:调整这些数字
模型出厂自带一套默认70亿个数字,是通用能力。
微调不改变网络结构,只少量修改里面一部分数字 ,
改完之后,神经连线的强弱变了,模型就专门擅长某一件事(比如写文案、做客服、懂行业术语)。
5. 量化:压缩这些数字的精度
原本每个数字精度很高 (占用字节多,文件大、耗显存)。
量化就是:不改变数字大致大小,只降低它的精细度
比如原本是超高精度小数,改成普通精度整数,
数字还能用、模型智商几乎没变,但文件变小、跑得更快。
核心一句话总结(只记数字)
- 模型里全是海量普通数字,名字叫权重;
- 一个数字对应一条神经连线的强弱;
- 70亿参数 = 70亿个控制连线强弱的数字;
- 微调 = 改这些数字,量化 = 压缩这些数字的精细度。
大模型推理执行流程:你输入中文问题
⬇️
【第一步】分词器 Tokenizer汉字 / 词语 → 逐字 转换为整数数字编号,
示例:你好➡️对应转换成编号:1024, 2048
⬇️
【第二步】嵌入编码 Embedding将每一个数字编号,分别转换为专属语义向量(一串小数)
你 1024 → 向量 0.15, -0.27, 0.63......
好 2048 → 向量 0.22, 0.51, -0.33......
⬇️
【第三步】进入模型权重计算输入向量 和 模型内几十亿权重数字做矩阵运算
⬇️
【第四步】自动激活相关权重和问题语义相关的权重 → 自动激活、参与主导计算
无关的权重 → 抑制弱化、不参与主导
⬇️
【第五步】预测下一字概率依靠激活的权重运算,逐个算出后续汉字的概率
⬇️
【第六步】分词器解码转文字概率数字 → 反向翻译还原为中文汉字
⬇️
输出 AI 最终回答
**接下来先继续了解概念:**什么是神经网络、什么是权重?**
1. 先认识一下:什么是神经网络?
简单说,神经网络就是一张由"圆圈"和"连线"组成的网:
- 圆圈 = 神经元(可以想象成一个小计算器)
- 连线 = 连接(神经元之间的通道)
它的工作方式: 给你看一张猫的图片,信息从左边进入,依次流过每一层的**"神经元"和它们之间的"连接"**,一层接一层,直到最右边输出结果------"这是猫"。
🍎 打个比方: 就像一条工厂流水线。原料(图片)从入口进入,经过一道道工序(神经元层),每道工序的工人之间用手递材料(连接),最后产品(判断结果)从出口出来。
"学习"是什么意思:就是不断调整每条"连线"上的数字,让最终输出越来越准。这些数字就是下面要讲的权重。
2. 什么叫"权重"(Weight)?
这个名字来自一个非常生活化的类比:
想象你要决定"今晚吃什么"。
- 朋友说"火锅好吃"(权重 = 0.7 ------ 很重要)
- 你说"太辣了"(权重 = 0.3 ------ 不太重要)
- 最后你说"今天太累"(权重 = 0.1 ------ 基本忽略)
每个因素都有一个重要性程度 ,或者叫**"加权值"。数值越大,这个因素在最终决策中的"分量越重"**。
在神经网络里完全一样:
- 输入A → 乘以 权重0.9 → 对结果影响很大(权重高)
- 输入B → 乘以 权重0.1 → 对结果影响很小(权重低)
所以这些可调的数字,就叫做权重 ------因为它们决定了每个输入信号的 "分量"。
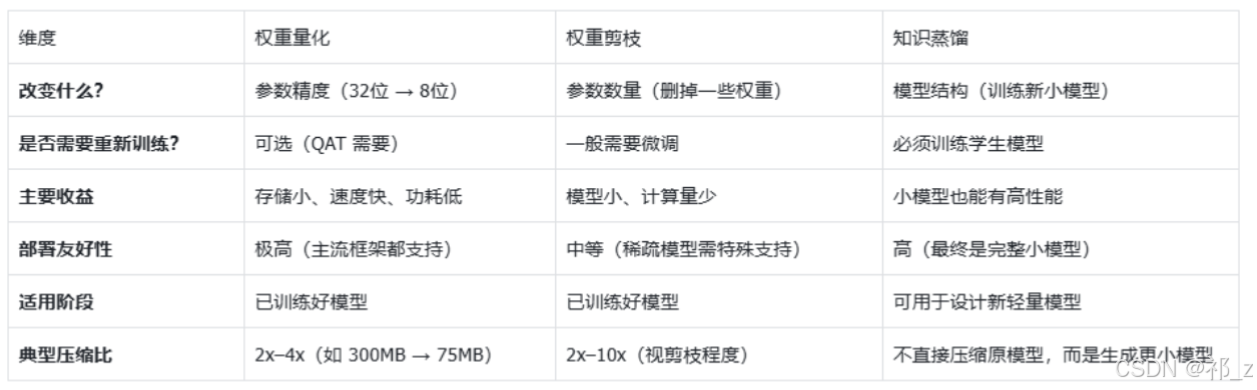
2.1.1. 模型压缩三剑客:权重量化、权重剪枝、蒸馏
1. 权重量化 (Quantization)【类比有一把毫米级精度的尺子,实际用不到这么大的精度,权重量化就是把精度调低】
2. 权重剪枝 (Pruning)【剪掉可有可无的连接(例如剪掉权重值小于0.01的连接),类比剪掉多余的树枝,操作简单一行代码搞定】
3. 知识蒸馏 (Knowledge Distillation)【大模型当老师教小模型,只学"解题思路"不背"全部细节"。例如用整本百科全书(大模型)的考试要点,训练一本小手册(小模型)达到同等考试水平】
在实际工业应用中,这三者经常组合使用:
- 先用知识蒸馏训练一个小模型(学生);
- 再对这个学生模型做剪枝(去掉不重要的连接);
- 最后做量化(降低数值精度)。
三种模型优化比较:
2.1.2. 权重量化(在原模型上降精度)
参考来源: https://cloud.tencent.com/developer/article/2546431
在部署推理时量化(只在加载到显存/内存的那一刻才转成 INT8),不改变原模型文件。
python
# 案例:将 FP32 转为 INT8/INT4 等低位精度,加载到内存/显存中。
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# 8-bit 量化配置
quantization_config = BitsAndBytesConfig(
load_in_8bit=True, # 加载时将 FP32/FP16 权重转为 INT8,减少约一半显存
)
# 模型 ID(Qwen 最小开源模型,约 0.6B 参数)
model_id = "Qwen/Qwen3-0.6B"
# 以 8-bit 精度加载模型
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config, # 使用上面定义的 8-bit 配置
device_map="auto" # 自动分配到可用的 GPU/CPU
)
# 加载对应的分词器
tokenizer = AutoTokenizer.from_pretrained(model_id)如果 Hugging Face 下载慢,可以换成 ModelScope 魔塔的加载方式:
python
from modelscope import AutoModelForCausalLM, AutoTokenizer
from transformers import BitsAndBytesConfig
# 8-bit 量化配置
quantization_config = BitsAndBytesConfig(
load_in_8bit=True, # 加载时转为 INT8 精度
)
# 模型 ID(ModelScope 路径)
model_id = "qwen/Qwen3-0.6B"
# 以 8-bit 精度加载模型
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config, # 8-bit 量化
device_map="auto" # 自动分配设备
)
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_id)2.1.3. 权重剪枝(在原模型上删连接)
直接修改原模型的权重矩阵,生成新模型文件。
删除不重要的权重连接以减小模型规模。可用 torch.nn.utils.prune 实现。
python
import torch
import torch.nn.utils.prune as prune
from transformers import AutoModelForCausalLM
# 1. 加载需要裁剪的模型(Qwen 最小开源模型)
model_id = "Qwen/Qwen3-0.6B"
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float32, # 剪枝需要 fp32 精度
device_map="auto"
)
# 2. 开始剪枝(对第一层 Transformer 的注意力输出投影做 30% 随机剪枝)
prune.random_unstructured(
model.model.layers[0].self_attn.o_proj, # Qwen3 的层名
name="weight", # 裁剪权重
amount=0.3 # 裁剪30%
)
# 3. 验证稀疏度
sparsity = (
model.model.layers[0].self_attn.o_proj.weight == 0
).float().mean()
print(f"稀疏度: {sparsity:.2%}")
# 4. 固化剪枝结果并保存
prune.remove(model.model.layers[0].self_attn.o_proj, "weight")
model.save_pretrained("./qwen0.6b-pruned")2.1.4. 知识蒸馏(训练一个全新的小模型)
训练一个全新的小模型,模仿大模型的行为。
python
# 简化伪代码
teacher_logits = teacher(input_ids).logits # 老师:大模型
student_logits = student(input_ids).logits # 学生:小模型
# 本质是让学生模仿老师的"思考方式"(输出概率),而非仅背答案
# 💡 实际使用时建议加入温度参数 T 软化分布,学习效果更好
loss = nn.KLDivLoss()(
F.log_softmax(student_logits), # 学生侧:log-概率
F.softmax(teacher_logits) # 老师侧:概率分布
)