一、引言:为什么需要"透视"Kubernetes 的组件
在云原生技术栈中,Kubernetes(K8s)已经成为事实上的容器编排标准。多数人入门时,通常会用一条 kubectl apply 发布应用,然后感受到 Pod 自动运行、自动恢复的便利。但如果您不止于"会用",而是希望真正拥有排查问题、设计高可用集群的能力,就必须从"组件化"的视角理解 K8s 的内部构造------控制平面如何决策?工作节点如何运行容器?多个控制器如何协同而不冲突?etcd 又为何必须是奇数个节点?
本文将以一套高可用集群为例(基于9节点 Proxmox 虚拟化环境),系统拆解 Kubernetes 核心架构,逐一剖析**控制平面**与**工作节点**的各个组件,并通过命令行实操来验证组件状态和冗余机制。文末还提供了常用命令速查表,便于日后回顾和使用。
二、集群总体架构鸟瞰
一个生产级 Kubernetes 集群通常由以下四个逻辑部分组成:
- 控制平面(Control Plane):集群的大脑,负责全局决策、调度和事件响应,通常由 API Server、etcd、Controller Manager 和 Scheduler 共同构成。
- 工作节点(Worker Nodes):运行业务负载的机器,受控制平面管理,运行 kubelet、kube-proxy 和容器运行时。
- 持久存储:etcd 是一致性键值数据库,保存所有集群状态。
- 网络模型:Pod 之间通过扁平网络直接通信,Service 抽象出服务发现与负载均衡。
简化版示意图如下(后文会详细标注端口与协议):
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Plain Text 用户 (kubectl) │ HTTPS :6443 ▼ 负载均衡器 (HAProxy / keepalived) │ ▼ ┌─────────────────────────────┐ │ kube-apiserver (多个实例) │ └────────────┬────────────────┘ │ 唯一读写 etcd ┌────▼────┐ │ etcd │ (至少3节点, Raft) └─────────┘ ▲ ▲ │ │ │ watch │ watch ┌──┴─────────────────┴───┐ │ controller-manager │ │ scheduler │ └─────────────────────────┘ │ ▼ 工作节点 (kubelet / kube-proxy / 容器运行时) |
三、控制平面:集群决策中心
控制平面的四个核心组件各司其职,通过 kube-system 命名空间中的静态 Pod 运行(若使用 kubeadm 部署)。
|-------------------------|-------------------------------|
| 组件 | 一句话职责 |
| kube-apiserver | 集群统一 API 网关,所有操作都通过 REST 接口进行 |
| etcd | 分布式键值存储,保存全部集群数据 |
| kube-controller-manager | 多种控制器的集合,将当前状态调谐至期望状态 |
| kube-scheduler | 负责 Pod 的节点选择与绑定 |
3.1 kube-apiserver:唯一的 etcd 前门
- 功能:提供 REST API,处理来自 kubectl、控制平面组件、kubelet 及外部系统的请求。它封装了认证(Authentication)、授权(Authorization)和准入控制(Admission Control)三层安全机制。
- 通信 :默认监听 6443 端口,采用 HTTPS 双向证书认证。
- 无状态设计 :可水平扩展多个实例,前方通过负载均衡器(如 HAProxy)提供统一入口,例如 kubeapi.example.com:6443。多个 api-server 实例之间没有直接依赖。
- 与 etcd 的关系:是**唯一**能直接读写 etcd 的组件,其他组件必须经由 api-server 间接访问存储。
3.2 etcd:集群的"记忆中枢"
- 由 CoreOS 开发,基于 Raft 共识算法 的分布式 KV 存储,保存 Nodes、Pods、ConfigMaps、Secrets 以及所有运行时状态。
- 高可用要求:至少 3 个节点(且为奇数),写操作需要多数派确认(quorum = floor(N/2)+1)。例如,3 节点集群最多允许 1 台宕机;5 节点可容忍 2 台宕机。
- 端口:客户端通信 **2379**,peer 通信 **2380**。
- 性能敏感:强烈建议使用 SSD 以及低延迟网络,通常还会启用 TLS 加密。
3.3 kube-controller-manager:永不停止的调谐循环
它并非单个控制器,而是一组控制器的集合,以单一进程运行,包含:
- Node Controller:监控节点健康状态,在节点失联时触发 Pod 驱逐。
- Deployment Controller 与 **ReplicaSet Controller**:管理副本数,确保实际 Pod 数量与期望一致。
- ServiceAccount & Token Controller:为命名空间创建默认 ServiceAccount 和 Token。
- 其他控制器:Job、CronJob、Namespace、EndpointSlice 等。
控制器内部逻辑遵循经典的"观察→分析差异→调谐"模式:通过 watch api-server 获取期望状态和当前状态,如有偏差则执行操作趋近期望。
高可用:多个实例通过资源锁(Lease)实现**领袖选举**,只有当前的 leader 执行调谐,其余 standby。
3.4 kube-scheduler:为 Pod 寻找最优节点
- 监听 api-server 中 nodeName 为空的 Pod,负责为其选择节点。
- 调度过程分为三个阶段:
- 过滤(Filtering):剔除不满足条件的节点(资源不足、污点不匹配等);
- 打分(Scoring):对剩余节点按策略计分(如 LeastRequestedPriority、BalancedResourceAllocation);
- 绑定(Binding) :将 Pod 的 nodeName 更新为选中节点,写回 api-server。
- 支持扩展:可通过**调度框架**注入自定义插件,或实现自定义调度器。
- 高可用同样依赖领袖选举,仅 leader 执行调度。
四、工作节点组件:业务容器的真正执行者
每个工作节点上运行三类核心组件:
|-------------------|-------------------------------|
| 组件 | 职责 |
| kubelet | 节点代理,负责 Pod 生命周期、与容器运行时交互 |
| kube-proxy | 维护节点上的网络规则,实现 Service 流量转发 |
| Container Runtime | 真正运行容器的软件,通过 CRI 与 kubelet 集成 |
4.1 kubelet:节点的"监工"
- 由 systemd 管理(systemctl status kubelet),以守护进程形式运行。
- 核心工作流:
- 向 api-server 注册 Node 对象,持续上报节点状态(心跳);
- 监听分配至本节点的 PodSpec,通过 CRI 接口通知容器运行时创建/停止容器;
- 执行用户定义的探针(Liveness、Readiness、Startup),并根据结果重启或标记 Pod 状态;
- 与 api-server 通信,提供只读 metrics 端口(10250)。
- kubelet 并不直接与 etcd 通信,所有集群信息均通过 api-server 获取和上报。
4.2 kube-proxy:Service 的实现基石
- 运行在每个节点,watch api-server 中 Service 和 EndpointSlice 的变化,动态更新本机的网络规则,确保访问 Service ClusterIP 或 NodePort 的流量能正确负载均衡到后端 Pod。
- 支持三种代理模式:
- userspace(已弃用)
- iptables(默认,大规模集群规则过多时性能下降)
- IPVS(高性能,支持多种负载均衡算法,推荐用于生产环境)
- kube-proxy 独立于 kubelet 运行,两者没有直接依赖。
4.3 容器运行时与 CRI:可插拔的标准化接口
为了让 kubelet 与具体的容器运行解耦,Kubernetes 定义了 **CRI(Container Runtime Interface)**------一组 gRPC 接口,包含 RuntimeService(管理 Pod 与容器生命周期)和 ImageService(管理镜像)。只要实现了 CRI,运行时就能被 Kubernetes 使用。
常见的 CRI 实现:
- containerd:源于 Docker,现为 CNCF 毕业项目,轻量高效,已成为事实标准。
- CRI-O:专门为 Kubernetes 打造,恪守 CRI 标准。
- Docker Engine:历史上 K8s 通过 dockershim 与 Docker 对接,但 dockershim 已在 v1.24 被移除,官方推荐使用 containerd 或 CRI-O 作为运行时。
containerd 与 Docker 的关系对比
Docker 是一个完整的容器管理平台(CLI、构建、镜像仓库等),底层也会调用 containerd;而 containerd 则专注于容器运行时管理,并提供原生 CRI 插件,因此在 Kubernetes 中更轻量、更高效。
为了方便跨运行时调试,社区提供了 crictl 工具,它直接与 CRI 端点交互,可以列出 Pod、容器和镜像,例如:
|---------------------------------------------------------------------------------------------------|
| Bash sudo crictl pods # 显示所有 Pod(含 pause 容器) sudo crictl ps -a # 显示所有容器 sudo crictl images # 显示镜像 |
通过 crictl,我们看到的容器已经以 Pod 维度组织------每个 Pod 至少包含一个 **pause 容器**,它负责维持网络命名空间,业务容器加入其中共享网络。

五、高可用架构的核心机制
生产环境的高可用控制平面需要考虑 etcd 拓扑、API Server 负载均衡以及组件领袖选举。
- 拓扑选择:
- 堆叠 etcd(本实验推荐):每个控制平面节点同时运行 api-server 和 etcd,架构简单、管理便利。
- 外部 etcd:api-server 与 etcd 独立部署在不同节点,耦合度更低,但运维复杂度升高。
- API Server 的负载均衡:所有控制平面节点前必须放置 LB(如 HAProxy + keepalived 或云 LB),kubectl 和所有组件通过统一 DNS 名称和 6443 端口访问。即使某个 api-server 挂掉,流量也会被转移到健康实例。
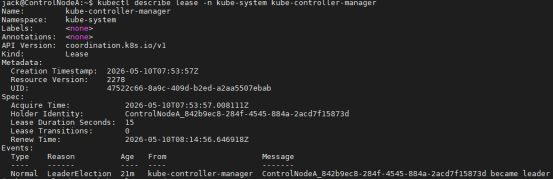
- Controller Manager 和 Scheduler 的领袖选举 :这两个组件默认开启 --leader-elect,它们会竞争写入同一个 Lease 对象(或旧版的 Endpoint),获取锁的实例成为 leader 开始工作。可使用以下命令查看:
|-----------------------------------------------------------------------------------------------------|
| Bash kubectl get lease -n kube-system kubectl describe lease -n kube-system kube-controller-manager |
输出的 holderIdentity 即标识当前 leader。
- etcd 的 Quorum 机制:任何写操作必须得到集群多数成员确认。以 3 节点为例,容忍 1 台故障;若 2 台宕机,集群将变为只读,无法写入新状态。因此维护 etcd 的健康尤为重要。
六、动手实践:深入验证组件状态与冗余
下面我们借助一个已部署的高可用集群(本例环境为9节点 Proxmox VE,节点运行 Ubuntu 22.04,3 个控制平面 + 若干工作节点)来进行实地验证。
6.1 观察控制平面组件
控制平面的四大组件都以静态 Pod 形式运行在 kube-system 命名空间:
|--------------------------------------------------------------------------------------------------|
| Bash kubectl get pods -n kube-system -o wide | grep -E 'etcd|apiserver|controller|scheduler' |
示例输出可以看到类似 etcd-master1, kube-apiserver-master1, kube-controller-manager-master1, kube-scheduler-master1 的条目,并且 -o wide 能显示它们所在的节点。
查看某个组件的日志,例如实时观察 api-server 的请求:
|---------------------------------------------------------------------------|
| Bash kubectl logs -n kube-system kube-apiserver-controlnodea --tail=20 -f |
日志中会包含认证、审计等信息,是排查问题的第一手资料。

6.2 检查工作节点服务与容器运行时
登录任意工作节点,确认 kubelet 和容器运行时(示例使用 containerd)处于运行状态:
|-----------------------------------------------------------|
| Bash systemctl status kubelet systemctl status containerd |

查看 kubelet 的配置,确认其 CRI 端点:
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Bash sudo cat /var/lib/kubelet/config.yaml | grep containerRuntimeEndpoint # 输出通常为: unix:///run/containerd/containerd.sock  为什么 containerRuntimeEndpoint: "" 是空的? 这是正常现象! kubelet 在使用 containerd 时: 要么配置文件指定 要么自动发现默认路径(unix:///run/containerd/containerd.sock) 空的不影响!系统会自动用默认地址! |
为什么 containerRuntimeEndpoint: "" 是空的? 这是正常现象! kubelet 在使用 containerd 时: 要么配置文件指定 要么自动发现默认路径(unix:///run/containerd/containerd.sock) 空的不影响!系统会自动用默认地址! |
配置 crictl 并查看 Pod 和容器:
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Bash crictl config runtime-endpoint unix:///run/containerd/containerd.sock crictl config image-endpoint unix:///run/containerd/containerd.sock sudo crictl pods # 包含 pause 容器 sudo crictl ps -a # 所有容器 sudo crictl ps --name kube-system # 筛选系统容器 |
通过 crictl 的输出可以直观理解每个 Pod 至少绑定一个 pause 容器,再挂载业务容器,由此理解 Pod 内共享命名空间的原理。

|-----------------------------------------------------------------------------------------------------------------------|
| 提示:如果运行时为 Docker,您仍可使用传统的 docker ps,但不会看到 Pod 级别的抽象。这正是 CRI 带来的标准化价值------无论底层是 containerd、CRI-O 还是其他运行时,crictl 体验一致。 |
6.3 分析高可用与领袖选举
获取当前 controller-manager 和 scheduler 的 leader:
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Bash # 新式 Lease 方式 kubectl get lease -n kube-system kubectl describe lease -n kube-system kube-controller-manager # 兼容旧版的 Endpoint 方式 kubectl get endpoints -n kube-system kube-controller-manager -o yaml | grep -A5 control-plane.alpha.kubernetes.io/leader |
以上命令会标明当前哪个节点是 leader。接下来模拟故障:
- 在虚拟化管理器中暂停一个控制平面节点(或直接 systemctl stop kubelet 并停掉 etcd)。
- 在外部 LB 或其他正常节点上执行:
|----------------------------------------------------------------|
| Bash kubectl get nodes kubectl get pods -n kube-system -o wide |
观察被停止的节点最终变为 NotReady,该节点上的组件 Pod 会进入 Terminating 状态。
- 验证集群 API 仍然可用:kubectl get pods -A 应正常返回(只要多数派 etcd 存活)。
- etcd 多数派测试 :3 节点 etcd 集群,关闭 1 台,读写正常;再关闭 1 台,执行 kubectl get pods 将报错------因为 etcd 失去 quorum,进入只读状态。
此实验能够非常直观地证明 etcd 的容错机制和 Leader 选举的自动切换。
6.4 绘制架构图
在理解上述所有组件及其交互后,强烈建议您用工具(Draw.io、Visio、ProcessOn 等)绘制一张完整的 Kubernetes 核心架构图。图中需包含:
- 控制平面区:etcd 集群、kube-apiserver、controller-manager、scheduler;
- 工作节点区:kubelet、kube-proxy、容器运行时,以及 Pod 内的 pause 容器和业务容器;
- 外部实体:kubectl 客户端、LB、HTTPS 端口 6443;
- 标注通信协议(HTTPS、gRPC over Unix socket)及关键端口(6443、2379/2380、10250 等),并描述各组件的核心功能。
绘图的过程就是一次知识梳理,能有效避免"黑盒化"认知。
七、总结
通过本文的架构解读和动手验证,您应该已经获得以下能力:
- 清晰划分控制平面(api-server、etcd、controller-manager、scheduler)和工作节点(kubelet、kube-proxy、CRI运行时)的职责;
- 理解 etcd Raft quorum、API Server 的无状态扩展、控制器的调谐循环以及 kubelet 通过 CRI 管理容器的完整流程;
- 能够用 kubectl、crictl 查看组件状态和容器运行时细节,并模拟高可用故障验证冗余;
- 具备组件化思维,能够绘制并讲解 Kubernetes 的请求调用链路。
本文为"搭建DevOps企业级仿真实验环境"系列的一部分,所有内容均基于实际硬件环境(32核64线程 / 128G内存 / 6T硬盘)编写,力求贴近真实企业部署场景。
欢迎各位 DevOps、SRE 爱好者,在评论区留言交流探讨,互相学习。