目录
数据结构
Zset 有两种实现方式,分界线是 单个元素的字节数 和 元素总数。
-
如果 每个元素都不到 64 字节 ,而且 元素总数不到 128 个 ,就用 紧凑列表 listpack 存数据;
-
如果超过任意一个阈值,就用 跳表 存数据。
Zset 要实现有序,要按照分数排序。跳表本身有序,而且跳表效率高,所以用跳表是理所当然的事情。那考虑为什么在数据量小的时候用紧凑列表?
为什么数据量小的时候用紧凑列表?
在数据量小的时候,跳表的指针浪费内存,指针占用内存的比例过大,不划算。
Redis 把数据存在内存里,选择数据结构的时候要十分重视内存开销。
紧凑列表用一块连续的内存空间存储数据,节省了指针占用的内存。而且它对元素使用特殊的编码方式,不同长度的数据对应不同的编码,在很大程度上节省了内存。
为什么跳表有序而且效率高?
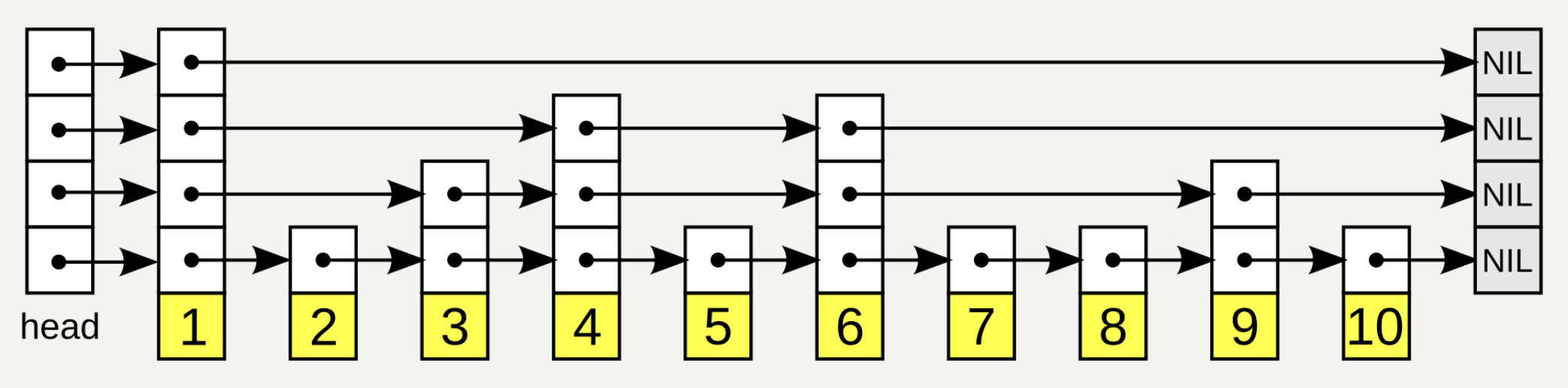
要弄懂跳表的特性,就要理解它底层的 数据结构。
-
宏观上看:一个跳表包括很多层,每一层是一条链表。
-
从上往下看:位于高层的链表,它的节点稀疏;底层链表的节点密集。
-
从左往右看:所有链表的头节点都存储在一个数组里。往后的每一个节点是一个对象,一个对象包含多个指针,每个指针指向「同一个值在不同层的节点」。
高效性 :理解了它的数据结构之后,就能明白它是通过 多层链表 去提高效率的。程序从最高层开始查找,高层链表越过更多的元素,随着范围的缩小,逐渐降低层次,减少了需要检查的元素的数量。
有序性:不论是哪一层的链表,链表中的节点都是按照升序排列的,不同层的节点共享同一个值。这意味着不论从哪一层开始查找,始终可以按顺序访问元素。
使用场景
利用 Zset 按照分数排序 的特性
-
在 游戏 中,把 玩家的得分 作为分数,可以实现 排行榜;
-
在 短视频软件 中,把 视频播放次数 、点赞数 作为分数,可以实现 推荐系统 或 排行榜;
-
如果要实现 延时队列 ,可以把 任务的执行时间 作为分数,分数是一个 时间戳 ,表示任务执行的具体时间(当前时间 + 延迟时间),用 Zset 定时取出 分数最小的元素,也就是最早执行的任务,从而实现延时队列。