上篇文章:Linux共享内存原理与实战:从内核到C++实现|附源码
目录
[一、System V 消息队列:带标签的数据包裹](#一、System V 消息队列:带标签的数据包裹)
[1. 深入内核:消息队列的底层数据结构](#1. 深入内核:消息队列的底层数据结构)
[2. 用户层协议设计与 msgrcv 的精准读取](#2. 用户层协议设计与 msgrcv 的精准读取)
[二、System V 信号量:临界资源的"预订机制"](#二、System V 信号量:临界资源的“预订机制”)
[1. 从"去电影院看电影"通俗理解信号量](#1. 从“去电影院看电影”通俗理解信号量)
[2. 硬核剖析:Dijkstra 原语与信号量底层理论](#2. 硬核剖析:Dijkstra 原语与信号量底层理论)
[3. System V 信号量的内核结构与繁琐 API](#3. System V 信号量的内核结构与繁琐 API)
[三、最强硬核探秘:内核如何用"多态"统一管理 IPC?](#三、最强硬核探秘:内核如何用“多态”统一管理 IPC?)
[1. 惊人的重合:基类 kern_ipc_perm](#1. 惊人的重合:基类 kern_ipc_perm)
[2. 顶层管理:全局大字典 ipc_ids 与柔性数组](#2. 顶层管理:全局大字典 ipc_ids 与柔性数组)
[3. 偷天换日:C 语言实现"多态"的神级操作](#3. 偷天换日:C 语言实现“多态”的神级操作)
[四、拓展加餐:mmap 文件映射与底层内存分配](#四、拓展加餐:mmap 文件映射与底层内存分配)
[1. 什么是 mmap?](#1. 什么是 mmap?)
[2. 硬核 API 解析](#2. 硬核 API 解析)
[3. 降维打击:用 mmap 极简模拟 malloc](#3. 降维打击:用 mmap 极简模拟 malloc)
前言:从共享内存的局限性说起
在上一篇文章中,我们深度探讨了 System V 共享内存。我们得出一个重要结论:共享内存是最快的 IPC 方式。但它存在两个明显的痛点:
-
它只能传递无差别的字节流数据,如果我们想在进程间传递带有特定类型的数据块,共享内存就显得力不从心。
-
它没有任何自带的保护机制。如果进程 A 正在写入,还没写完进程 B 就跑来读取,必然会导致读取到半截的"脏数据"。
如果说消息队列解决了"发什么类别的数据"的问题,那么信号量解决的就是"怎么安全地并发读写"的问题。
本文将带你补齐 System V IPC 的最后两块拼图,深入 Linux 内核源码,结合底层结构体揭秘操作系统是如何用 C 语言的"多态"思想统一组织 shm、msg、sem 等 IPC 资源的!并在文末带来重磅加餐:剖析 mmap 文件映射,并用其极简模拟底层的 malloc 内存分配!
一、System V 消息队列:带标签的数据包裹
如果说管道(Pipe)和共享内存是毫无感情的字节流,那么消息队列(Message Queue)则提供了一种从一个进程向另外一个进程发送带有特定"类型"的数据块的方法。由于接收者可以根据类型选择性地读取,这使得消息队列天然具备了类似"多路复用"的特性。
1. 深入内核:消息队列的底层数据结构
在 Linux 内核(/usr/include/linux/msg.h)中,操作系统为每一个消息队列维护了一个严密的数据头结构 struct msqid_ds:
struct msqid_ds {
struct ipc_perm msg_perm; /* Ownership and permissions (权限信息) */
time_t msg_stime; /* Time of last msgsnd (最后发送时间) */
time_t msg_rtime; /* Time of last msgrcv (最后接收时间) */
time_t msg_ctime; /* Time of last change (最后修改时间) */
unsigned long msg_cbytes; /* Current number of bytes in queue (当前队列字节数) */
msgqnum_t msg_qnum; /* Current number of messages in queue (当前队列消息数) */
msglen_t msg_qbytes; /* Maximum number of bytes allowed (队列允许最大字节数) */
pid_t msg_lspid; /* PID of last msgsnd (最后发送的进程PID) */
pid_t msg_lrpid; /* PID of last msgrcv (最后接收的进程PID) */
};消息队列的本质是一个内核级的双向链表 。当我们调用发送函数时,内核并非简单地拷贝字节,而是将我们的数据封装成一个 struct msg_msg 结构体,并将其挂载到链表(q_messages)上:
// 内核真实的双向链表节点:记录单个消息
struct msg_msg {
struct list_head m_list; // 包含 *next 和 *prev,双向链表指针
long m_type; // 消息类型
size_t m_ts; // 消息正文大小
// ... 后面紧接着的实际上是消息正文 (sg_msgseg)
};2. 用户层协议设计与 msgrcv 的精准读取
我们在用户层写代码时,必须定义一个特定的"数据包协议"结构体(注意:必须以 long 类型的 mtype 开头):
struct msgbuf {
long mtype; /* 必须大于0的消息类型 */
char mtext[1024]; /* 消息正文,大小可以自定义 */
};核心系统调用:
-
msgget:获取消息队列 ID。 -
msgctl(msqid, IPC_RMID, NULL):操作msqid_ds,如删除队列。 -
msgsnd(msqid, &msg, sizeof(msg.mtext), 0):将用户空间的msgbuf拷贝到内核链表。 -
msgrcv(msqid, &msg, sizeof(msg.mtext), msgtyp, 0):接收消息。
msgrcv 的 msgtyp 参数设计得非常硬核:
-
msgtyp == 0:直接读取队列的第一条信息(FIFO 模式)。 -
msgtyp > 0:精准打击!返回队列中第一条类型等于msgtyp的消息。 -
msgtyp < 0:优先级调度!返回队列中类型小于或等于msgtyp绝对值的消息中,类型最小的那一条。
二、System V 信号量:临界资源的"预订机制"
解决了数据类型传递的问题,我们要面对更棘手的并发安全问题。试想一下,共享内存没有任何保护,进程 A 正在写,进程 B 跑来读,岂不是乱套了?为了保护这种临界资源,我们需要引入信号量。
补充概念:
(多进程要通信,先要让多个进程看到同一份资源,对于资源,如果我们提供的是一块内存块,那他就相当于共享内存;如果提供的是一个队列,那他就相当于消息队列;如果提供的是一个文件,那就相当于管道)
不同进程看到了同一个资源 -> 新的问题也就从这里展开,比如并发访问出现错误。
并发编程,概念铺垫:
- 多个执行流(流程),能看到的同一份公共资源:共享资源。
- 被保护起来的共享资源叫做临界资源。
- 保护的方式常见:互斥与同步
- 任何时刻,只允许一个执行流访问资源,叫做互斥
- 多个执行流,访问临界资源的时候,具有一定的顺序性,叫做同步
- 系统中某些资源一次只允许一个进程使用,称这样的资源为临界资源或互斥资源(互斥与同步+共享 = 临界资源)
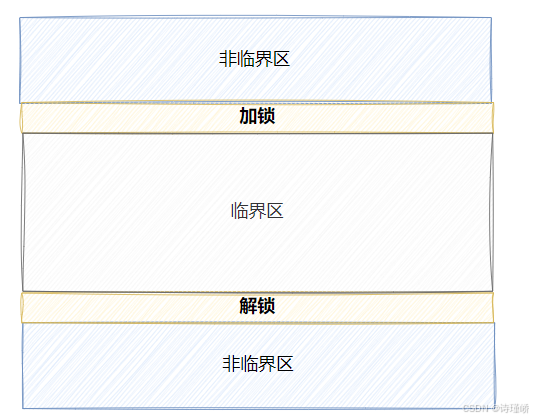
- 在进程中涉及到互斥资源的程序段叫做临界区。写的代码 = 访问临界资源的代码(临界区)+不访问临界资源的代码(非临界区)
- 所谓的对共享资源进行保护,本质是对访问共享资源的代码进行保护
1. 从"去电影院看电影"通俗理解信号量
为了不一开始就陷入冷冰冰的代码中,我们先来想一个生活中的场景:去电影院看电影。
电影院的放映厅就是一个【共享资源】。你是怎么保证你走进去看电影时,一定有属于你的座位呢? 答案是:因为你买到了票。
"买票"的本质,就是对座位资源的一种预订机制 。只要你买到了票,放映厅里面必然有一个位置是留给你的。对于整个放映厅而言,座位数是有限的,这个总票数,就可以看作是一个信号量(Semaphore)。
-
当你买票成功,票数减少(计数器
--),这叫 P 操作(申请资源)。 -
如果票数为 0 了,后续想买票的人只能排队等候(进程阻塞挂起)。
-
当电影散场,人群退场,座位空了出来,票数增加(计数器
++),这叫 V 操作(释放资源)。
如果这是一个超级 VIP 影厅,里面只有一个座位 ,这意味着总票数(信号量)的初始值为 1。这就形成了所谓的互斥锁(二元信号量)------同时只能有一个人(进程)进去!
因此信号量的本质就是对临界资源的一种预定机制。
2. 硬核剖析:Dijkstra 原语与信号量底层理论
这个精妙的机制由计算机科学家 Dijkstra(迪杰斯特拉)提出。在操作系统底层,信号量不仅仅是一个简单的整型变量,它还带有一条进程等待队列。
我们可以用以下伪代码来硬核解剖信号量的本质结构:
struct semaphore {
int value; // 资源计数器
pointer_PCB queue; // 进程等待队列 (存放处于阻塞状态的进程 PCB)
};value 值的深刻含义:
-
S > 0:表示当前可用资源的个数。 -
S == 0:表示无可用资源,且暂无等待进程。 -
S < 0:表示无可用资源,且|S|(绝对值)代表当前等待队列中阻塞挂起的进程个数!
P/V 原语的原子操作:
// P操作 (Passeren - 申请资源)
P(s) {
s.value--; // 申请一个资源
if (s.value < 0) {
// 资源不足,将当前进程状态置为等待状态
// 将该进程插入到相应的等待队列 s.queue 末尾
}
}
// V操作 (Verhogen - 释放资源)
V(s) {
s.value++; // 归还一个资源
if (s.value <= 0) { // 注意!如果加1后仍 <= 0,说明原本是负数,即有人在排队!
// 唤醒相应等待队列 s.queue 中的一个进程
// 将其改变为就绪态,投入 OS 就绪队列
}
}信号量就是一段属性数据和代码的集合。
细节:
- 为了保证不同进程访问的是同一个信号量,我们将信号量技术归类到IPC范畴。
- 信号量本身也是共享资源,为了保证信号量自身的安全,需要将P,V操作设计为自身安全的,也就是原子状态(指一件事要么不做,要做就一定做完)
- 所有进程访问公共资源(shm),都要先申请信号量,绝对不能让部分进程直接访问。
- 我们是通过将临界区保护起来的方式去保护临界资源的。
- 要想知道访问共享资源哪一部分,是通过我们程序员自己维护的
3. System V 信号量的内核结构与繁琐 API
在 Linux 中,System V 信号量并不是单个存在的,而是以"信号量集合(Set)"的形式存在的。对应内核中定义了 struct semid_ds:
struct semid_ds {
struct ipc_perm sem_perm; /* Ownership and permissions (权限信息) */
time_t sem_otime; /* Last semop time (最后执行 PV 操作的时间) */
time_t sem_ctime; /* Last change time (最后修改时间) */
unsigned long sem_nsems; /* No. of semaphores in set (集合中信号量的个数!) */
};操作信号量需要使用三个极其繁琐的系统调用,这也是为什么实际开发中常需要用到建造者模式(Builder Pattern)去封装它的原因:
① 申请集合:semget
int semget(key_t key, int nsems, int semflg);这里的 nsems 就是你要申请的信号量集合里有几个信号量。
② 初始化/控制集合:semctl
int semctl(int semid, int semnum, int cmd, ...);大坑预警 :信号量的申请和初始化是分开 的。初始化时,我们需要用到第四个可变参数 union semun。最坑的是,系统标准库通常不提供这个联合体,需要程序员自己在代码里显式定义!
union semun {
int val; /* 用于 SETVAL 命令,设置某个信号量的初始值 */
struct semid_ds *buf; /* 用于 IPC_STAT 提取属性,或 IPC_SET 修改属性 */
unsigned short *array; /* 用于 GETALL, SETALL */
struct seminfo *__buf;
};要给第一个信号量(下标0)设置初始值为1(做互斥锁),你需要: union semun un; un.val = 1; semctl(semid, 0, SETVAL, un);
③ 执行 P/V 操作:semop
int semop(int semid, struct sembuf *sops, size_t nsops);你需要向内核传递 struct sembuf 结构体:
struct sembuf {
unsigned short sem_num; /* 要操作的是集合中的第几个信号量 (下标) */
short sem_op; /* -1 代表P操作, 1 代表V操作 */
short sem_flg; /* 标志位,强烈建议设为 SEM_UNDO */
};硬核细节 :SEM_UNDO 是神来之笔。如果进程申请了锁(P操作),还没来得及释放(V操作)就意外崩溃了,会导致所有等待的进程死锁。加上 SEM_UNDO,操作系统会在内核记录这笔账,当进程异常退出时,自动撤销它对信号量所做的改变!
三、最强硬核探秘:内核如何用"多态"统一管理 IPC?
前面我们学完了 System V 的"三剑客":共享内存(shm)、消息队列(msg)、信号量(sem)。细心的你会发现,它们在用户层的 API 出奇地一致(都是 get、ctl),但它们的功能却天差地别。
操作系统底层究竟是如何统一组织和管理这三种截然不同的资源的? 接下来,我们直接翻开 Linux 内核源码(参考内核版本 2.6.x 源码),剥开宏观外衣,直击本质!
1. 惊人的重合:基类 kern_ipc_perm
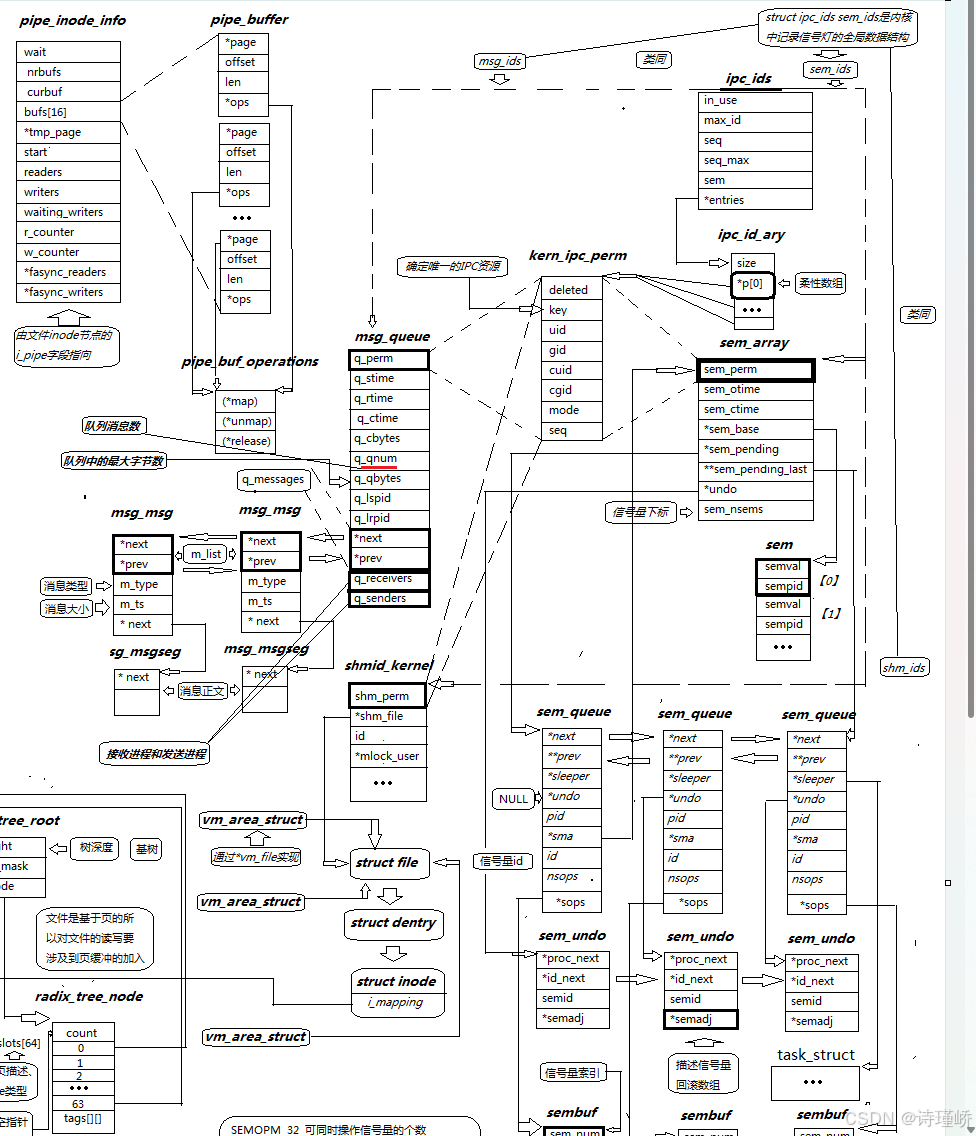
我们在用户态看到的 shmid_ds、msqid_ds、semid_ds 只是给用户看的接口结构体,在内核深处,真正描述这三个对象的结构体分别是 shmid_kernel、msg_queue 和 sem_array。
来看这三段硬核源码:
// 1. 共享内存的内核结构
struct shmid_kernel {
struct kern_ipc_perm shm_perm; // 🌟 注意:它是第一个成员!
struct file *shm_file;
int id;
unsigned long shm_nattch;
// ...
};
// 2. 消息队列的内核结构
struct msg_queue {
struct kern_ipc_perm q_perm; // 🌟 注意:它也是第一个成员!
time_t q_stime;
time_t q_rtime;
// ...
};
// 3. 信号量集合的内核结构
struct sem_array {
struct kern_ipc_perm sem_perm; // 🌟 注意:它还是第一个成员!
time_t sem_otime;
time_t sem_ctime;
// ...
};你发现了什么?它们结构体的第一个成员,完完全全一模一样,都是 struct kern_ipc_perm! 那么,这个 kern_ipc_perm 究竟装了什么?
struct kern_ipc_perm {
spinlock_t lock; // 自旋锁,保护该IPC对象
int deleted; // 删除标记
key_t key; // 我们非常熟悉的 key 值!
uid_t uid; // 拥有者用户ID
gid_t gid; // 拥有者组ID
mode_t mode; // 权限 (比如 0666)
unsigned long seq; // 序列号
};不难看出,kern_ipc_perm 提取了所有 IPC 资源共有的"公共属性"。这在面向对象编程中叫什么?这叫基类(Base Class) !而那三个具体的结构体,就是派生类(Derived Class)。
2. 顶层管理:全局大字典 ipc_ids 与柔性数组
既然有了"基类",内核是如何把系统中创建的成百上千个 IPC 资源统一管理起来的呢?
在内核中,存在一个全局的管理者结构 struct ipc_ids,这里面藏着 IPC 资源管理的核心灵魂------指针数组 struct ipc_id_ary:
struct ipc_ids {
int in_use;
int max_id;
unsigned short seq;
// ...
struct ipc_id_ary *entries; // 指向资源数组的指针
};
struct ipc_id_ary {
int size;
struct kern_ipc_perm *p[0]; // 🌟 柔性数组,C语言神兵利器!
};操作系统把所有创建出来的共享内存、消息队列、信号量,统统把它们内部的第一个成员 kern_ipc_perm 的地址 ,存入了这张 p[] 数组表中!
为了让你更直观地看懂底层的内存布局和指针关系,我为你绘制了下面这张内核 IPC 资源管理链表与数组的拓扑图:
[ 全局 IPC 管理结构 ]
struct ipc_ids
+-------------------+
| int in_use; |
| int max_id; |
| ... |
| entries * --------|----.
+-------------------+ |
|
V
[ IPC 资源指针数组 ]
struct ipc_id_ary
+-----------------------+
| int size; |
|-----------------------|
.------| p[0] (kern_ipc_perm*) | <-- 下标 index = 0 (例如 shmid = 0)
| |-----------------------|
| .---| p[1] (kern_ipc_perm*) | <-- 下标 index = 1 (例如 msgid = 1)
| | |-----------------------|
| | .-| p[2] (kern_ipc_perm*) | <-- 下标 index = 2 (例如 semid = 2)
| | | +-----------------------+
| | |
| | `---------------------------------------------------.
| | |
| `-------------------------------. |
V V V
[ 派生类:共享内存 (shm) ] [ 派生类:消息队列 (msg) ] [ 派生类:信号量 (sem) ]
struct shmid_kernel struct msg_queue struct sem_array
+=====================+ +=====================+ +=====================+
| 基类 kern_ipc_perm | | 基类 kern_ipc_perm | | 基类 kern_ipc_perm |
| (首地址偏移量为 0) | | (首地址偏移量为 0) | | (首地址偏移量为 0) |
+---------------------+ +---------------------+ +---------------------+
| struct file *shm_.. | | time_t q_stime; | | time_t sem_otime; |
| int id; | | time_t q_rtime; | | time_t sem_ctime; |
| ... | | ... | | unsigned long ... |
+=====================+ +=====================+ +=====================+这张 p 数组里存放的是什么?全部都是 struct kern_ipc_perm * 类型的基类指针! 当进程创建一个新的共享内存/消息队列/信号量时,操作系统会在物理内存中 malloc 出对应的完整子类结构体(比如 shmid_kernel),然后把这块内存的起始地址,强制转换为 kern_ipc_perm * 基类指针,塞进 p 数组里!
3. 偷天换日:C 语言实现"多态"的神级操作
你可能会问:数组里只存了 kern_ipc_perm * 基类指针,那操作系统需要去操作某个共享内存特有的属性(比如释放 shm_file)时,该怎么找回原来的派生类呢?
这里利用了 C 语言几何学上的一个硬核事实:结构体第一个成员的内存地址,完完全全等于整个结构体对象的起始内存地址!
场景重现: 当我们在用户态调用删除共享内存的命令 shmctl(shmid, IPC_RMID, NULL) 时,底层发生了怎样曼妙的化学反应?
-
内核拿着你传进来的用户层
shmid,经过特定的位运算,算出了这个资源在内核大数组中的下标index。 -
内核访问
p[index],提取出里面的基类指针struct kern_ipc_perm *。 -
内核知道这是一个共享内存操作,于是直接祭出强制类型转换:
struct shmid_kernel *shm = (struct shmid_kernel *)p[index]; -
瞬间!原本指向内部第一个成员的指针,就被"偷天换日"地还原成了指向整个
shmid_kernel对象的完整指针! -
接着,内核就可以为所欲为地调用
shm->shm_file去释放底层的物理资源了。
如果是操作消息队列呢?强转成 (struct msg_queue *)p[index] 即可。
💡 终极总结: 在没有任何
class、virtual关键字的纯 C 语言时代,Linux 内核黑客们硬生生地通过**"首成员地址对齐"的内存布局特性,结合 "指针数组 + 强制类型转换",实现了令人拍案叫绝的面向对象继承与多态**。 这种"先描述、再组织"的顶层架构思维,不仅极大减少了代码冗余,更为后世留下了不朽的代码典范!
四、拓展加餐:mmap 文件映射与底层内存分配
在进程间通信中,位于进程地址空间(栈和堆之间)的共享区 发挥了巨大作用。这不得不提另一个操作共享区的高级利器------mmap (Memory Mapped Files)。
1. 什么是 mmap?
mmap 允许我们将一个文件的内容,直接映射到进程的虚拟地址空间中。 它的威力在于"零拷贝": 进程可以像访问普通内存(数组)一样直接读写文件内容,内核会在后台透明地将修改同步到磁盘文件中。彻底省去了传统的 read/write 带来的内核态与用户态数据拷贝开销。
2. 硬核 API 解析
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);-
length:映射字节数。底层必定向物理页大小(通常 4KB,即 4096 Bytes)对齐向上取整。 -
prot:保护属性,如PROT_READ | PROT_WRITE。 -
flags(至关重要):-
MAP_SHARED:修改会反映到底层文件中,其他映射此文件的进程可见。 -
MAP_PRIVATE:私有写时拷贝(Copy-On-Write)。修改不会反映到底层文件。 -
MAP_ANONYMOUS:匿名映射。不关联任何文件(fd传 -1),直接向系统要一块纯粹的物理内存!
-
3. 降维打击:用 mmap 极简模拟 malloc
平时我们用的 malloc 在申请小块内存时调用 brk 扩展堆;但在申请大块内存 时,底层调用的正是 mmap! 利用 MAP_ANONYMOUS | MAP_PRIVATE 组合,我们可以让操作系统凭空在共享区分配一块内存:
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <unistd.h>
// 极简版 my_malloc
void* my_malloc(size_t size) {
// 匿名映射,私有内存,不需要 fd (传 -1)
void* ptr = mmap(NULL, size, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (ptr == MAP_FAILED) {
perror("mmap");
exit(EXIT_FAILURE);
}
return ptr;
}
// 极简版 my_free
void my_free(void* ptr, size_t size) {
if (munmap(ptr, size) == -1) {
perror("munmap");
exit(EXIT_FAILURE);
}
}
int main() {
size_t size = 1024; // 申请 1KB 内存
char* ptr = (char*)my_malloc(size);
printf("Allocated memory at address: %p\n", ptr);
my_free(ptr, size);
return 0;
}如果你使用 GDB 运行这段代码,输入 info proc mapping,你会硬核地看到:由 my_malloc 申请出的内存,明确落在了共享映射区(地址介于堆和栈之间),并且其大小被严格按 4KB (0x1000) 进行了对齐!
结语
从基础的共享内存 ,到带有路由类型的消息队列 ,再到保护资源的信号量原语 ,我们全面击穿了 System V IPC 机制。深入内核底层,我们惊叹于 Linux 使用 C 语言 ipc_id_ary 数组与 kern_ipc_perm 结构体实现底层"多态"的架构艺术。最后,我们用 mmap 揭开了文件映射和 malloc 内存分配的终极面纱。
希望这篇极度硬核的剖析,能让你对操作系统的设计之美有一次醍醐灌顶的体悟!