****论文题目:****Vehicle Detection and Tracking Based on Improved YOLOv8(基于改进 YOLOv8 的轻量化车辆检测与跟踪方法)
期刊:IEEE ACCESS
****摘要:****随着交通压力的迅速增加,对高效交通识别和跟踪系统的需求日益增长。传统方法在处理交通场景的复杂情况时存在一定的局限性,如权值大、检测精度不足等。因此,我们提出了一种基于YOLOv8n的新方法。首先在检测头上引入基于SCConv的SCC_Detect,减少冗余特征的计算;然后用对偶卷积核代替卷积核,构建轻量级深度神经网络。随后,引入Focaler-EIoU损失函数来提高精度。BotSORT跟踪器嵌入推理期,在交通场景中获得更准确、稳定的识别和跟踪结果。实验结果表明,与UA-DETRAC数据集上的yolov8n相比,该模型的参数和权重分别减少了约36.5%和25%,而成本仅为0.2%mAP@0.5。在跟踪方面,BoTSORT算法在测试视频上的MOTA、IDF1和MOTP优于DeepSORT和ByteTrack算法。提高了精度,减少了丢失航迹的数量。在流量检测和部署中具有很高的实用价值和应用前景。
基于改进 YOLOv8 的轻量化车辆检测与跟踪方法详解
一、背景与问题
截至 2023 年底,中国民用车辆保有量已达 3.3618 亿辆,较上年增加 1,714 万辆。随着城镇化的不断推进,交通管理和安全问题日益突出,对高效、准确的交通检测与跟踪系统的需求愈发迫切。
现有的交通检测系统主要依赖安装于道路上的监控摄像头,其核心是基于深度学习的目标检测模型。然而,当前方法在实际部署中面临以下几个突出问题:
1.1 模型计算量大、难以部署于嵌入式设备
主流的车辆检测模型(如 Faster R-CNN,参数量约 2395.9 万,计算量 201.1 GFLOPs,权重 309MB)虽然精度高,但计算开销极大,无法在资源受限的嵌入式设备上直接部署。即使是 YOLOv8n(8.2 GFLOPs,权重 6MB),仍存在一定的冗余计算。
1.2 样本不均衡导致的检测精度不足
在交通流检测场景中,背景像素与目标车辆像素的占比差异极大。这种正负样本严重不均衡的问题使得模型容易过拟合大量简单背景样本,而对稀疏目标车辆的检测能力不足,进而影响整体检测精度。
1.3 遮挡等复杂情况导致跟踪精度受限与目标丢失
在实际交通环境中,车辆之间相互遮挡、摄像头抖动(因风雨等外部因素)以及多目标密集场景都会给跟踪算法带来严峻挑战。传统的 DeepSORT 等跟踪算法在应对这些复杂情况时,误报(FP)和漏报(FN)较多,目标 ID 切换频繁,导致丢失目标比例(MLR)偏高。
1.4 特征冗余问题
现有的检测头(Detection Head)在处理特征图时存在大量空间与通道维度的冗余信息,这不仅浪费计算资源,还可能干扰检测精度,增加模型部署难度。
二、方法创新点
针对上述问题,本文在 YOLOv8n 基础上提出了一套完整的改进方案,涵盖检测头、主干网络、损失函数和跟踪算法四个层面。
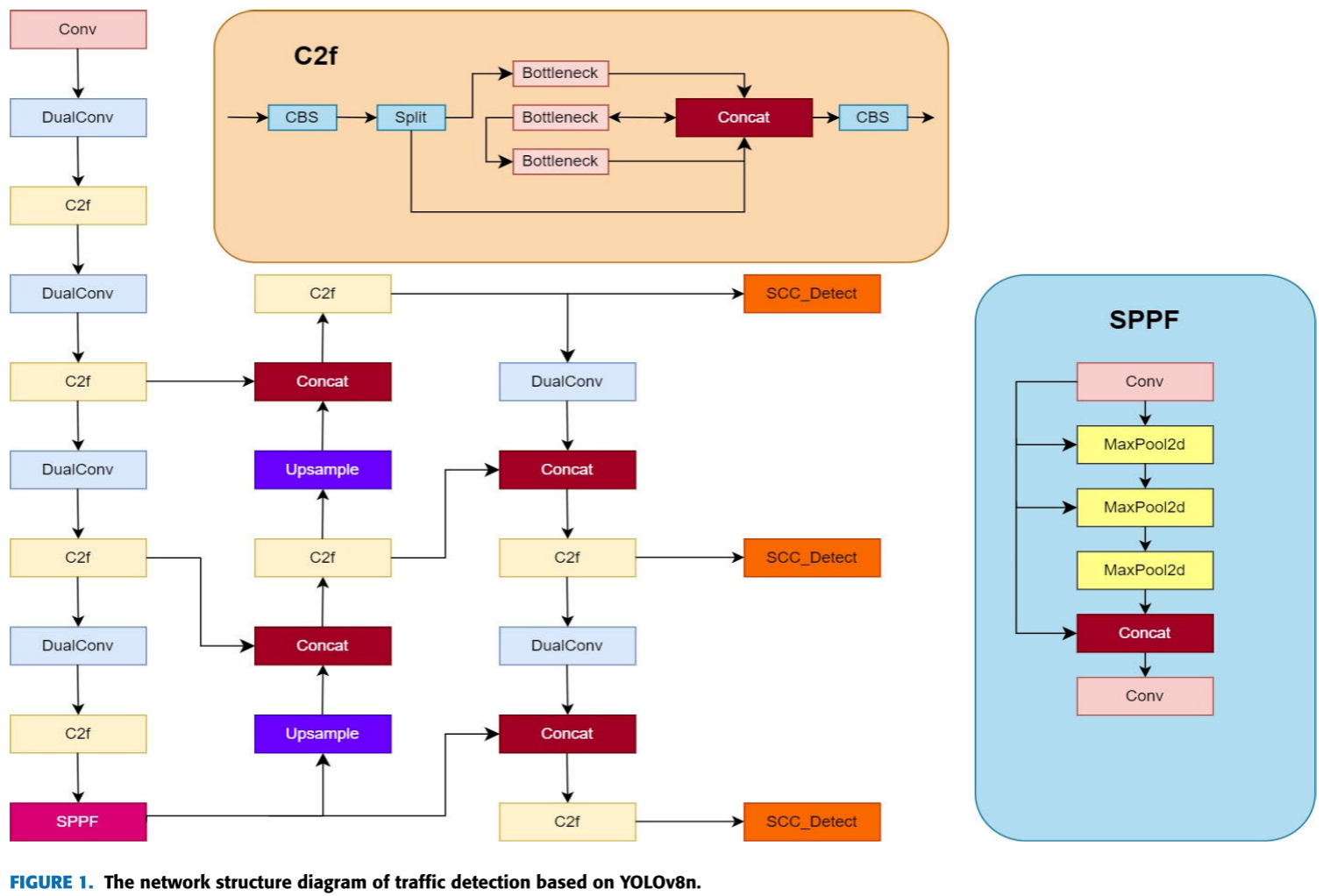
📷 【配图:图1 --- 改进 YOLOv8n 的完整网络结构图】
对应论文 Figure 1,展示 Conv → DualConv → C2f → SPPF 主干,Upsample → Concat → SCC_Detect 颈部与检测头的整体架构。
2.1 创新点一:基于 SCConv 的检测头 SCC_Detect
问题根源:原始 YOLOv8 的检测头在中间特征图中存在大量空间和通道冗余,增加了不必要的计算开销。
解决方案 :设计 SCC_Detect,以 SCConv(Spatial and Channel reconstruction Convolution)替换原始检测头。SCConv 由两个核心单元组成:
(1)SRU(空间重建单元):使用分离-重组操作处理空间冗余。
- 首先对输入特征进行组归一化(Group Normalization),得到
:
- 利用可学习参数
- 通过门控 Sigmoid 函数区分信息丰富的权重
(2)CRU(通道重建单元):使用分割-变换-融合策略处理通道冗余。
- 将
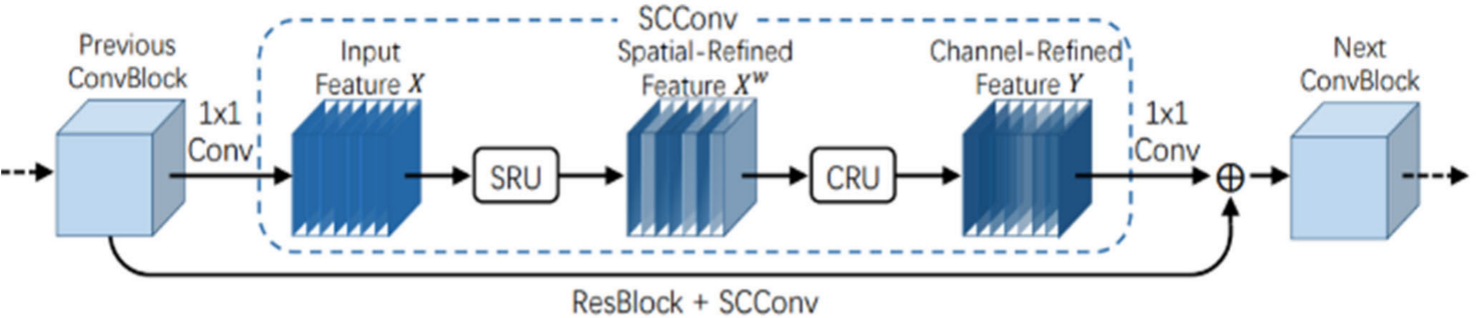
📷 【配图:图2 --- SCConv 网络架构图(含 SRU 和 CRU)】
对应论文 Figure 2,展示 Previous ConvBlock → SRU → CRU → Next ConvBlock 的完整流程。
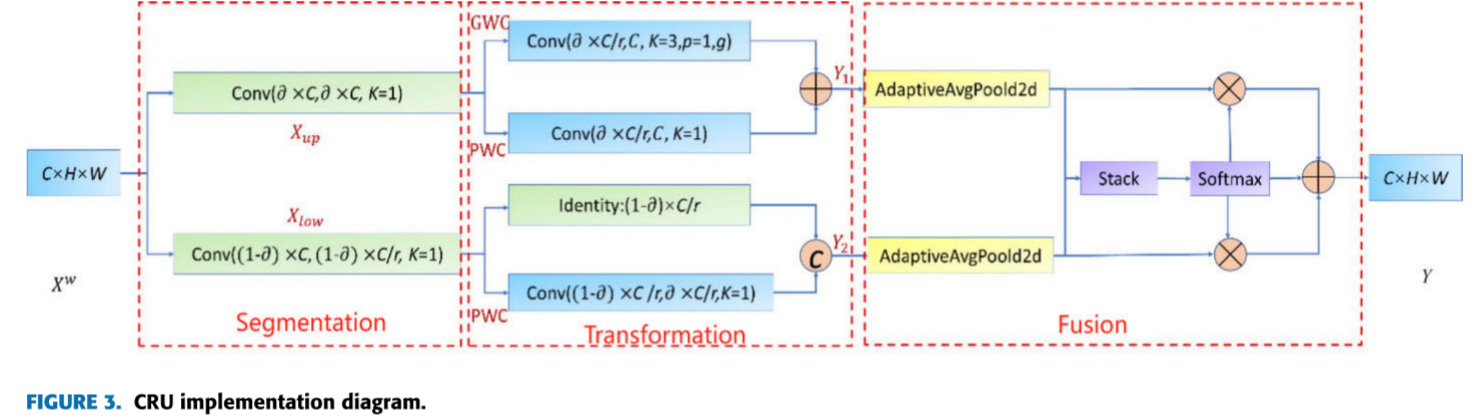
📷 【配图:图3 --- CRU 实现示意图(分割-变换-融合)】
对应论文 Figure 3,展示 GWC、PWC 的组合操作及 Softmax 融合过程。
效果(消融实验) :单独在 YOLOv8n 中加入 SCC_Detect 后,精度提升不显著,但模型计算复杂度和权重大幅下降,体现了 SCConv 在保持精度同时减少冗余的能力。
2.2 创新点二:双卷积核 DualConv 替换主干卷积
问题根源:传统卷积核计算参数量大,主干网络存在可优化空间。
解决方案 :将主干网络中的卷积核替换为 DualConv,结合 3×3 和 1×1 两种卷积核:
- 3×3 卷积负责提取空间信息;
- 1×1 卷积负责特征整合并降低参数量;
- 通过**分组卷积(Group Convolution)**技术将输入/输出特征图划分为多组,每组的卷积滤波器只处理对应的部分输入特征图,从而降低模型复杂度,同时实现跨通道信息的高效流动与整合。
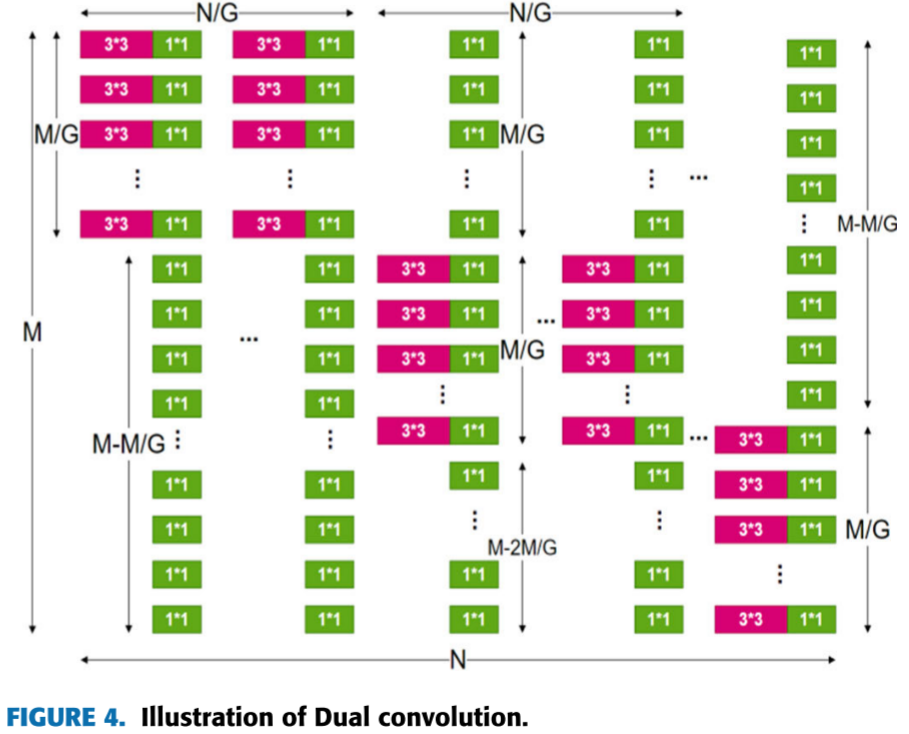
📷 【配图:图4 --- 双卷积示意图】
对应论文 Figure 4,展示 M 个通道输入、G 个分组及 3×3 和 1×1 滤波器并行处理的结构。
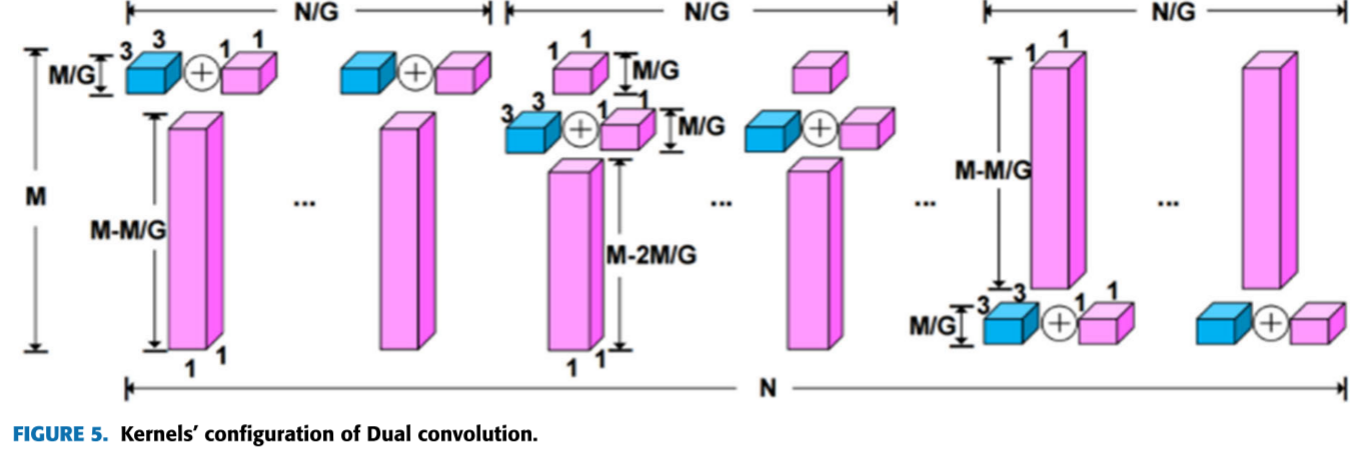
📷 【配图:图5 --- 双卷积核配置示意图】
对应论文 Figure 5,展示 N/G 分组中 3×3 与 1×1 卷积核的具体布局及 ⊕ 加法合并方式。
效果(消融实验) :YOLOv8n + DualConv 组合使 mAP@0.5-0.95 相比 YOLOv8n 提升 1.5% (90.8% → 92.3%),同时权重从 6MB 降至 5.5MB ,GFLOPs 从 8.2 降至 7.6。
2.3 创新点三:Focaler-EIoU 损失函数
问题根源:YOLOv8 使用的 CIoU 损失函数在交通检测场景中,因背景与目标车辆像素比例差异极大,容易导致正负样本不均衡,模型过拟合大量简单背景,忽视稀疏车辆目标。
解决方案 :引入 Focaler-EIoU 损失函数,通过动态调整权重的方式缓解样本不均衡问题。
首先,EIoU 在 CIoU 基础上重新定义形状损失,分别对宽度差和高度差进行约束:
其中 和
分别为同时包围预测框和真实框的最小外接框的宽和高。
然后,Focaler-IoU 通过重新定义 IoU 的关注范围,仅对中等难度样本给予训练权重,
最终,Focaler-EIoU 损失定义为:
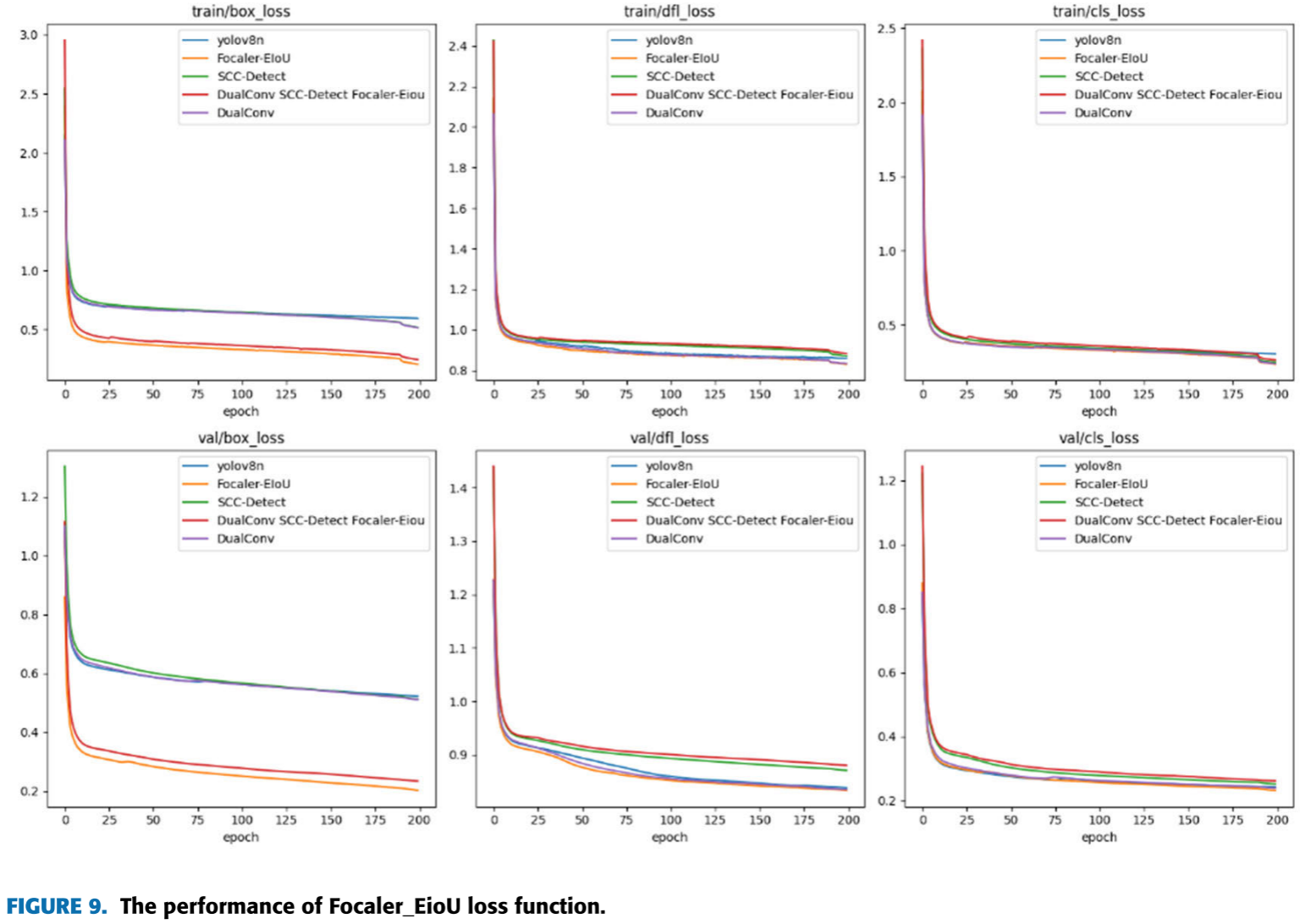
📷 【配图:图9 --- Focaler_EIoU 损失函数训练曲线】
对应论文 Figure 9,展示 train/box_loss、train/dfl_loss、train/cls_loss 及 val 各损失在 200 epochs 内的收敛对比。
效果(消融实验) :使用 Focaler_EIoU 后,mAP@0.5-0.95 相比 YOLOv8n 提升 1.7%(90.8% → 92.5%),且损失函数收敛速度更快,边框损失(box_loss)、分布特征损失(dfl_loss)和分类损失(cls_loss)均更为有效。
2.4 创新点四:BoTSORT 多目标跟踪算法
问题根源:DeepSORT 等传统跟踪算法在复杂交通场景(遮挡、摄像头抖动、多目标密集)下误报、漏报多,目标丢失率高。
解决方案 :引入 BoTSORT(Robust Associations Multi-Pedestrian Tracking 的改进版),作为 ByteTrack 的进一步优化版本,主要包含以下核心机制:
(1)重新定义卡尔曼滤波(KF)状态向量
BoTSORT 改变了 SORT 的 7 元组状态向量,不再预测宽高比,而是直接估计边框的宽度和高度,提升了对车辆形变的适应性。
(2)摄像头运动补偿(CMC)
针对室外摄像头因风雨抖动导致边框位置变化、引发跟踪失效的问题,BoTSORT 引入全局运动补偿(GMC),基于 OpenCV 的仿射变换算法进行视频稳定,并通过以下方程完成摄像头运动校正:
其中 为摄像头运动补偿前后的 KF 预测状态向量。
(3)IoU + ReID 融合机制
BoTSORT 将车辆外观信息与运动轨迹结合,通过余弦相似度计算 和 IoU 距离
进行融合匹配,只有当余弦相似度高时才接受 IoU 匹配:
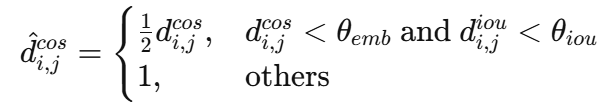
(4)跟踪流程
BoTSORT 通过低置信度阈值将检测结果分为高置信度和低置信度两类,高置信度检测先与预测轨迹匹配,低置信度检测再与未匹配轨迹关联;连续未匹配的轨迹标记为丢失并在超过阈值时删除。
三、实验设置
- 数据集:UA-DETRAC(北京/天津拍摄,共 82,050 张图像,8,250 辆车,1.21 百万标注框,含夜间、晴天、雨天及三级遮挡,四类车辆:轿车、公共汽车、卡车、其他)
- 数据集划分:训练集与验证集比例 9:1,UA-DETRAC 自带测试集
- 训练参数:batch size 32,训练 200 epochs,输入尺寸 640×640,初始学习率 0.01,权重衰减系数 0.0005,动量 0.937,优化器 SGD
- BoTSORT 参数:track_high_thresh 0.8,track_low_thresh 0.5,new_track_thresh 0.6
- 硬件环境:Intel Core i5-13600KF CPU @ 3.50GHz,NVIDIA RTX 4070 Ti 12GB
- 软件环境:Windows 11,PyTorch 2.2.1,Python 3.9.6,CUDA 12.1
四、实验结果
4.1 与 YOLOv8n 原始模型对比
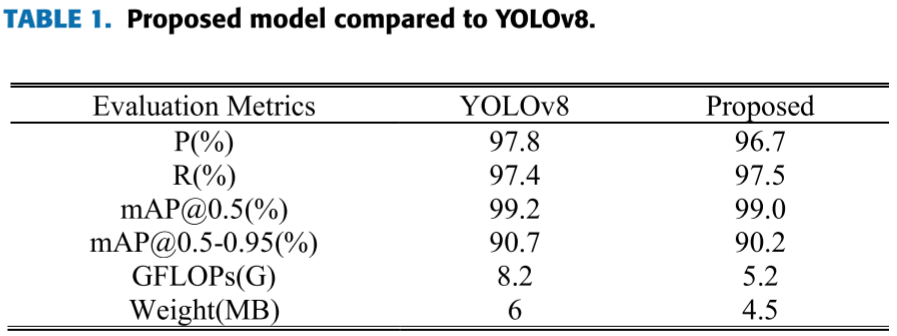
📋 【配表:表1 --- 改进模型与 YOLOv8n 的直接对比】
对应论文 Table 1,包含 P (%)、R (%)、mAP@0.5 (%)、mAP@0.5-0.95 (%)、GFLOPs(G)、Weight(MB) 六项指标。
以仅 0.2% 的 mAP@0.5 代价,换取了参数量降低 36.5%、权重降低 25% 的轻量化收益。
4.2 与主流模型的对比实验
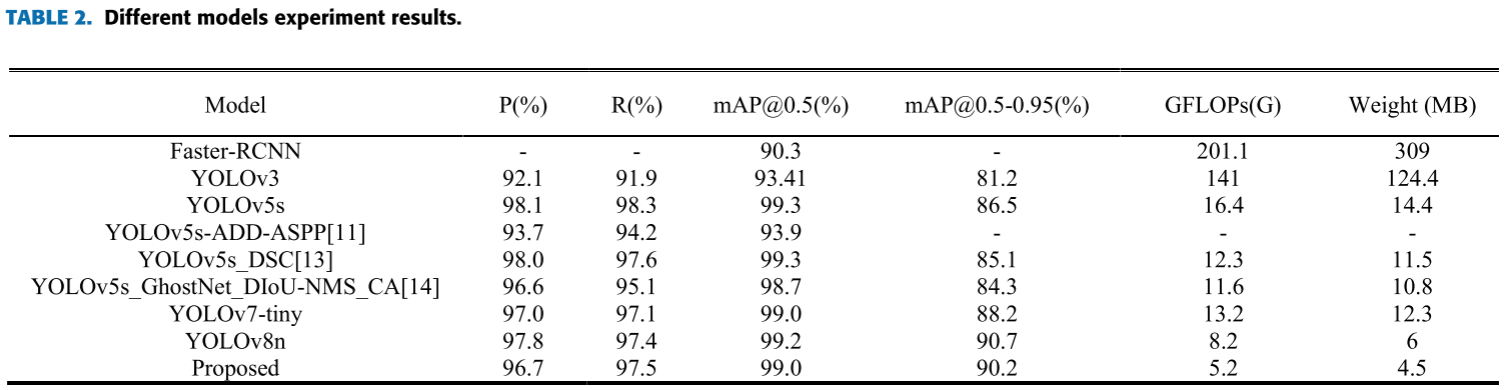
📋 【配表:表2 --- 不同模型在 UA-DETRAC 数据集上的实验结果对比】
对应论文 Table 2,包含 Faster-RCNN、YOLOv3、YOLOv5s、YOLOv5s-ADD-ASPP、YOLOv5s_DSC、YOLOv5s_GhostNet_DIoU-NMS_CA、YOLOv7-tiny、YOLOv8n 及本文模型,含 P (%)、R (%)、mAP@0.5 (%)、mAP@0.5-0.95 (%)、GFLOPs(G)、Weight(MB)。
核心结论:
- 与 Faster R-CNN(GFLOPs 201.1G,Weight 309MB)相比,本文模型以极低计算成本实现精度的全面超越(mAP@0.5:99.0% vs. 90.3%)。
- 与 YOLOv5s_DSC 相比,参数降低 4.1 GFLOPs ,权重降低 7MB ,mAP@0.5-0.95 提升 5.1%。
- 与文献14的 GhostNet 方法相比,计算量进一步降低 6.4 GFLOPs。
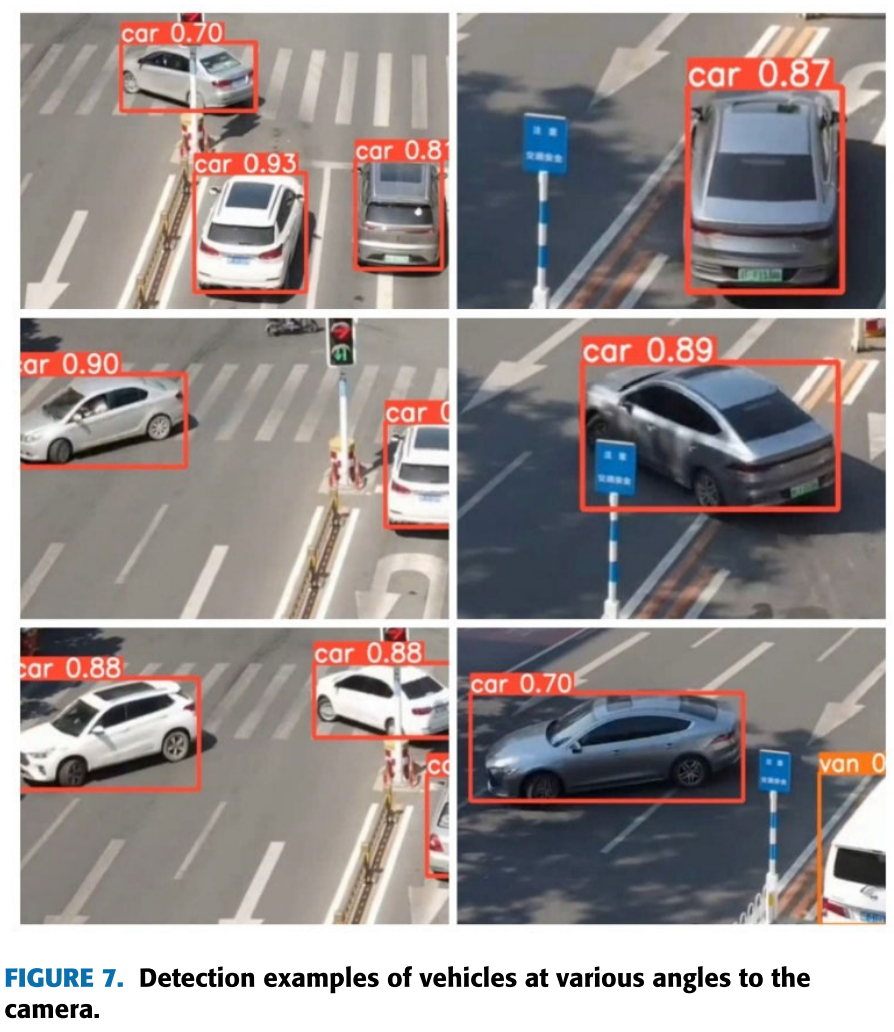

📷 【配图:图7 --- 模型对各角度车辆的检测效果示例】
对应论文 Figure 7,展示俯视/侧视/斜视等不同摄像角度下的车辆检测效果。📷 【配图:图8 --- YOLOv8 与本文模型在测试集上的检测结果对比】
对应论文 Figure 8(a 原始图 / b YOLOv8n 检测结果 / c 本文模型检测结果),可见本文模型漏检更少。
4.3 各改进模块消融实验

📋 【配表:表3 --- 各改进模块的消融对比实验结果】
对应论文 Table 3,包含 YOLOv8n、+DualConv、+SCC_Detect、+Focaler_EIoU、完整模型(Proposed)五组,含 P (%)、R (%)、mAP@0.5 (%)、mAP@0.5-0.95 (%)、GFLOPS(G)、Weight(MB)。
4.4 跟踪算法对比实验
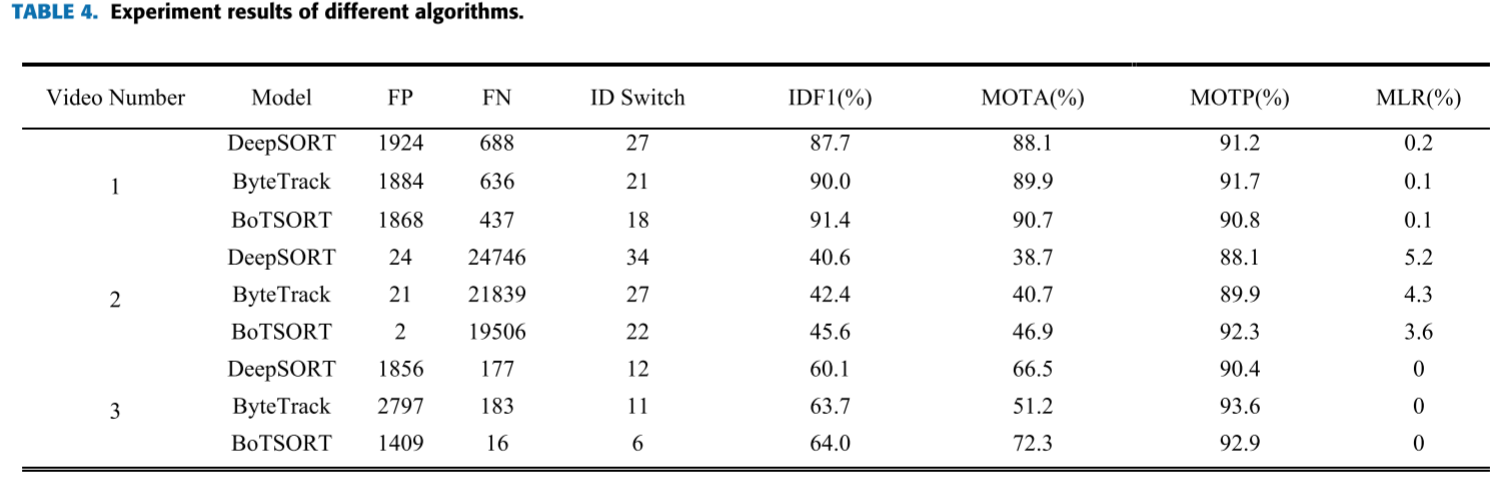
📋 【配表:表4 --- DeepSORT / ByteTrack / BoTSORT 在三段视频上的跟踪结果对比】
对应论文 Table 4,包含三段视频(Video 1/2/3),各视频包含三种算法,指标:FP、FN、ID Switch、IDF1 (%)、MOTA (%)、MOTP (%)、MLR (%)。

📷 【配图:图10 --- DeepSORT、ByteTrack、BoTSORT 跟踪效果示例图】
对应论文 Figure 10,圈出遮挡区域,对比三种算法在遮挡场景下的漏检差异。
核心结论(以 Video 1 为例):
| 算法 | FP | FN | ID Switch | IDF1 (%) | MOTA (%) | MOTP (%) | MLR (%) |
|---|---|---|---|---|---|---|---|
| DeepSORT | 1924 | 688 | 27 | 87.7 | 88.1 | 91.2 | 0.2 |
| ByteTrack | 1884 | 636 | 21 | 90.0 | 89.9 | 91.7 | 0.1 |
| BoTSORT | 1868 | 437 | 18 | 91.4 | 90.7 | 90.8 | 0.1 |
- Video 2(夜间拥堵场景):三种算法 FN 均较高(19,000+),因夜间车辆密集导致拥堵,跟踪难度大幅增加。但 BoTSORT 的 FN 仍为最低(19,506 vs. DeepSORT 的 24,746),MOTA(46.9%)和 IDF1(45.6%)均优于其他两种算法。
- Video 3:BoTSORT 实现 0% 的 MLR(完全不丢失目标),MOTA 达到 72.3%,显著优于 DeepSORT(66.5%)和 ByteTrack(51.2%)。
BoTSORT 性能优势的核心来源在于其 CMC 模块:在摄像头抖动条件下有效减少车辆跟踪的预测偏差,提升户外车辆跟踪的精度,并在拥堵场景中保持较高的识别与跟踪精度。
五、总结与展望
主要贡献回顾
本文提出了一套完整的轻量级车辆检测与跟踪改进方案,在 UA-DETRAC 数据集上以 0.2% 的 mAP@0.5 代价,换取了以下收益:
- SCC_Detect(SCConv 检测头):通过 SRU + CRU 双重机制,减少空间与通道冗余,在保持精度同时大幅降低计算开销。
- DualConv(双卷积核主干) :结合 3×3 与 1×1 卷积的分组卷积,在保持特征表达能力的同时,权重降低至 4.5MB (-25%),GFLOPs 降至 5.2G(-36.5%)。
- Focaler-EIoU 损失函数 :动态调整样本权重,有效缓解正负样本不均衡,提升 mAP@0.5-0.95 达 1.7%,且收敛速度更快。
- BoTSORT 跟踪器:通过 CMC + IoU-ReID 融合机制,在 IDF1、MOTA 等多项跟踪指标上全面优于 DeepSORT 和 ByteTrack,尤其在遮挡和摄像头抖动场景下表现突出。
现存不足与未来方向
- 本文方法在 mAP@0.5 上相比 YOLOv8n 仍略有损失(-0.2%),在精度与轻量化之间的权衡还有进一步优化空间。
- Video 2 夜间拥堵场景下,三种跟踪算法的 FN 均偏高,说明夜间密集遮挡场景依然是当前跟踪算法的难点。
- 未来将持续探索更优算法以进一步改善交通监控效果,并将方法推广至更多复杂场景和应用领域。