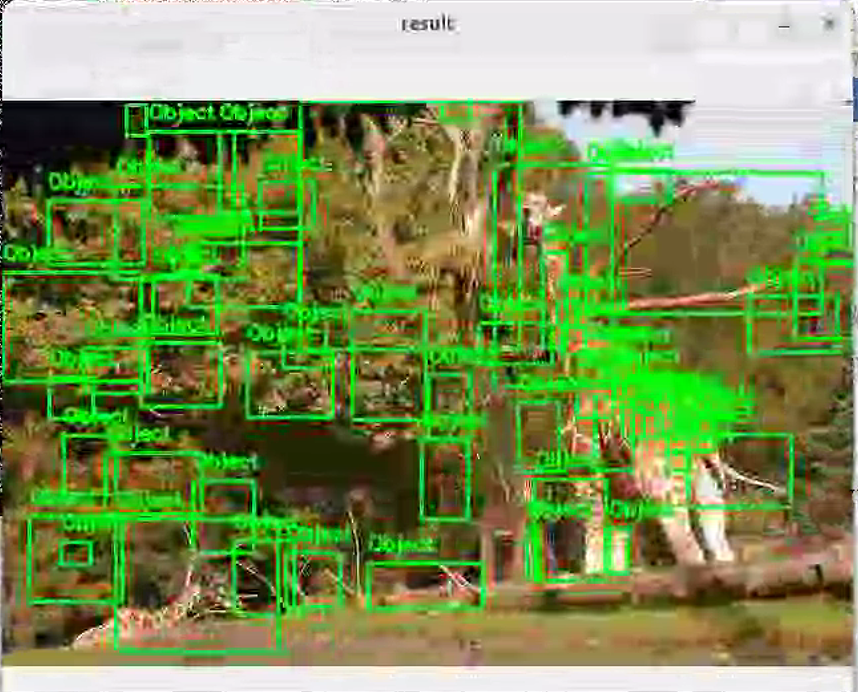
电脑自动找到物体,并且给每个物体画一个矩形检测框,和人脸识别、YOLO 检测的逻辑一模一样!
一、先上代码
python
import cv2
import numpy as np
# 1. 读取图片
img = cv2.imread("test.jpg")
# 2. 预处理(灰度+模糊+Canny边缘)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (5, 5), 0)
canny = cv2.Canny(blur, 50, 150)
# 3. 寻找轮廓
contours, _ = cv2.findContours(canny, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 4. 遍历每一个轮廓,给每个物体画框(核心!)
for cnt in contours:
# 过滤掉太小的噪点(面积<100的忽略)
area = cv2.contourArea(cnt)
if area > 100:
# 获取物体的 左上角x,y + 宽度w + 高度h
x, y, w, h = cv2.boundingRect(cnt)
# 画矩形检测框(绿色,粗细2)
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 标上文字:物体
cv2.putText(img, "Object", (x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0,255,0), 2)
# 5. 显示结果
cv2.imshow("Canny", canny)
cv2.imshow("最终检测效果", img)
cv2.waitKey(0)
cv2.destroyAllWindows()二、知识点
- 过滤噪点
python
area = cv2.contourArea(cnt)
if area > 100:- 计算物体面积
- 太小的直接忽略,避免乱框杂点
- 你可以改成
200、500更严格
- 获取物体坐标(最重要)
python
x, y, w, h = cv2.boundingRect(cnt)x, y:物体左上角坐标w:宽度h:高度所有目标检测都是靠这 4 个数字定位!
- 画检测框
python
cv2.rectangle(img, (x, y), (x+w, y+h), (0,255,0), 2)这就是人脸识别、车牌识别里框出目标的代码!
三、运行效果