我们接着上文来讲:
2. 数据预处理
先贴出代码部分:
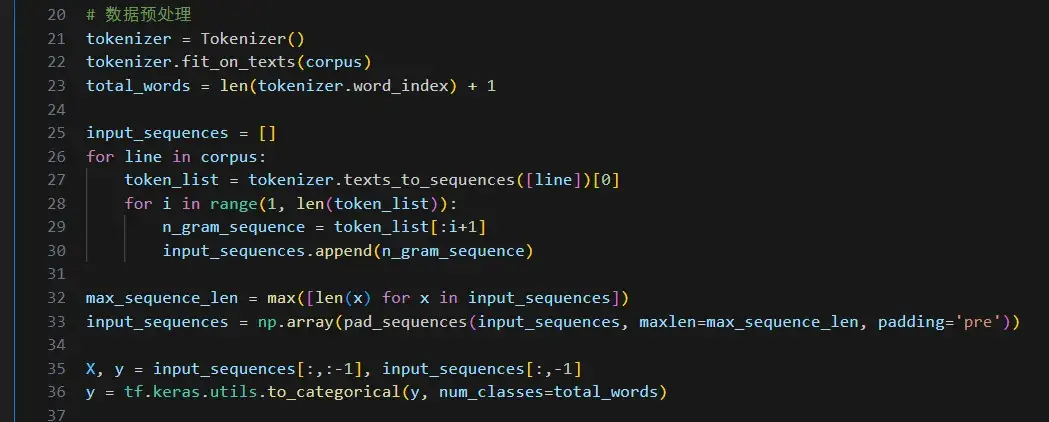
之所以这么写是因为在这一步中,使用 Tokenizer 类来对文本进行标记化处理,将每个单词转换为一个唯一的整数标识。
然后,根据标记化后的文本创建了输入序列 X 和目标序列 y,其中 X 包含了每个序列的前 n-1 个单词,而 y 包含了每个序列的最后一个单词,并将其转换为 one-hot 编码的形式。

3. 模型的构建和训练
当文本数据处理好后,就可以构建模型了,相关代码如下:
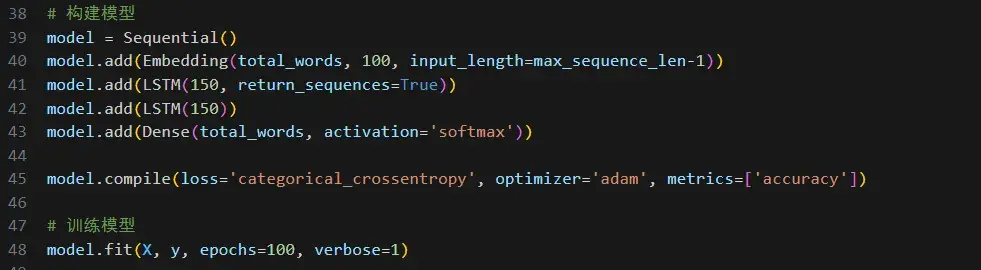
在这一步中,我们构建了一个 基于 LSTM 的神经网络模型。
该模型包含了一个 Embedding 层用于将整数标识的单词转换为密集向量表示,两个 LSTM 层用于学习文本序列的时间依赖关系,以及一个 Dense 层用于输出下一个预测的单词。接着使用了交叉熵损失函数和 Adam 优化器进行模型的编译,并使用训练数据对模型进行了训练。
当然,上面的模型相关参数是可以修改的,我这里只是为了讲解设置了很简单的参数,你可以后面把他们修改成你想要的参数值。