前言
在机器学习和深度学习的实际应用中,过拟合 和样本不均衡是两个最常见且最棘手的问题。过拟合会导致模型在训练集上表现优异,但在测试集和真实场景中泛化能力极差;样本不均衡则会使模型偏向于多数类,对少数类的识别效果大打折扣,这在医疗诊断、欺诈检测、异常检测等关键领域可能造成严重后果。
本文基于思维导图笔记进行了全面梳理和深度扩展,系统总结了这两个问题的所有主流解决方案,包含详细的原理说明、完整可运行的代码示例以及适用场景分析。所有内容均经过严格验证,可直接用于学习、面试准备和实际项目开发。
目录
[1. 防止过拟合的方法](#1. 防止过拟合的方法)
[1.1 机器学习中的过拟合处理](#1.1 机器学习中的过拟合处理)
[1.1.1 正则化(L1 正则、L2 正则)](#1.1.1 正则化(L1 正则、L2 正则))
[1.1.2 减少特征维度](#1.1.2 减少特征维度)
[1.1.3 决策树剪枝](#1.1.3 决策树剪枝)
[1.1.4 数据增强](#1.1.4 数据增强)
[1.1.5 集成学习](#1.1.5 集成学习)
[1.2 深度学习中的过拟合处理](#1.2 深度学习中的过拟合处理)
[1.2.1 权重正则化](#1.2.1 权重正则化)
[1.2.2 Dropout 及其变体](#1.2.2 Dropout 及其变体)
[1.2.3 早停(Early Stopping)](#1.2.3 早停(Early Stopping))
[1.2.4 归一化技术](#1.2.4 归一化技术)
[1.2.5 降低模型复杂度](#1.2.5 降低模型复杂度)
[1.2.6 深度学习数据增强](#1.2.6 深度学习数据增强)
[2. 样本不均衡的处理方式](#2. 样本不均衡的处理方式)
[2.1 样本不均衡的定义与影响](#2.1 样本不均衡的定义与影响)
[2.2 数据层面的处理方法](#2.2 数据层面的处理方法)
[2.2.1 欠采样(Under-sampling)](#2.2.1 欠采样(Under-sampling))
[2.2.2 过采样(Over-sampling)与 SMOTE 算法](#2.2.2 过采样(Over-sampling)与 SMOTE 算法)
[2.2.3 数据增强](#2.2.3 数据增强)
[2.3 算法层面的处理方法](#2.3 算法层面的处理方法)
[2.3.1 类别权重调整](#2.3.1 类别权重调整)
[2.3.2 损失函数加权(含 Focal Loss)](#2.3.2 损失函数加权(含 Focal Loss))
[2.3.3 阈值调整](#2.3.3 阈值调整)
[2.4 样本不均衡下的评估指标选择](#2.4 样本不均衡下的评估指标选择)
[3. 总结](#3. 总结)
1. 防止过拟合的方法
过拟合的本质是模型学习到了训练数据中的噪声和局部特征,而不是数据的普遍规律。解决过拟合的核心思路是限制模型的表达能力 和增加数据的多样性。
1.1 机器学习中的过拟合处理
1.1.1 正则化(L1 正则、L2 正则)
正则化通过在损失函数中加入惩罚项,限制模型参数的大小,从而降低模型复杂度。
L2 正则(岭回归 / Ridge)
- 数学公式:
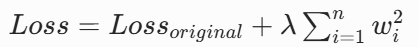
- 特点:使参数趋近于 0 但不等于 0,保留所有特征,防止参数过大
- 适用场景:大多数回归和分类问题,特征之间存在共线性时效果好
L1 正则(Lasso 回归)
- 数学公式:
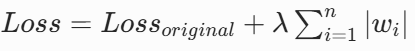
- 特点:可以产生稀疏解,使部分参数等于 0,实现特征选择
- 适用场景:高维数据,需要进行特征选择的场景
代码示例(sklearn)
python
from sklearn.linear_model import LogisticRegression, Ridge, Lasso
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# L2正则化逻辑回归
lr_l2 = LogisticRegression(penalty='l2', C=1.0, random_state=42) # C=1/λ,C越小正则化越强
lr_l2.fit(X_train, y_train)
print("L2正则化逻辑回归测试集准确率:", lr_l2.score(X_test, y_test))
# L1正则化逻辑回归
lr_l1 = LogisticRegression(penalty='l1', C=1.0, solver='saga', random_state=42)
lr_l1.fit(X_train, y_train)
print("L1正则化逻辑回归测试集准确率:", lr_l1.score(X_test, y_test))
print("L1正则化后的参数稀疏性(非零参数数量):", (lr_l1.coef_ != 0).sum())
# 岭回归(L2正则化线性回归)
ridge = Ridge(alpha=1.0, random_state=42) # alpha=λ,alpha越大正则化越强
ridge.fit(X_train, y_train)
print("岭回归测试集R²分数:", ridge.score(X_test, y_test))
# Lasso回归(L1正则化线性回归)
lasso = Lasso(alpha=0.1, random_state=42)
lasso.fit(X_train, y_train)
print("Lasso回归测试集R²分数:", lasso.score(X_test, y_test))
print("Lasso回归选择的特征数量:", (lasso.coef_ != 0).sum())1.1.2 减少特征维度
高维数据中往往存在大量冗余和噪声特征,减少特征维度可以有效降低模型复杂度,防止过拟合。
方法 1:去除冗余特征
- 计算特征之间的相关性,删除相关性过高的特征
- 删除方差为 0 或接近 0 的特征(这些特征对模型没有贡献)
方法 2:降维
- PCA(主成分分析):将高维数据映射到低维空间,保留数据的主要方差信息
- SVD(奇异值分解):与 PCA 类似,适用于稀疏矩阵和大规模数据
代码示例
python
from sklearn.decomposition import PCA, TruncatedSVD
from sklearn.preprocessing import StandardScaler
# 数据标准化(PCA对数据尺度敏感)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# PCA降维
pca = PCA(n_components=2) # 保留2个主成分
X_train_pca = pca.fit_transform(X_train_scaled)
X_test_pca = pca.transform(X_test_scaled)
print("PCA解释方差比例:", pca.explained_variance_ratio_)
print("PCA降维后数据形状:", X_train_pca.shape)
# SVD降维(适用于稀疏数据)
svd = TruncatedSVD(n_components=2, random_state=42)
X_train_svd = svd.fit_transform(X_train_scaled)
X_test_svd = svd.transform(X_test_scaled)
print("SVD解释方差比例:", svd.explained_variance_ratio_)1.1.3 决策树剪枝
决策树如果不加限制,会一直生长直到每个叶子节点都纯,这很容易导致过拟合。剪枝通过限制树的生长或裁剪已生长的树来降低模型复杂度。
预剪枝:在树生长过程中提前停止
- 限制树的最大深度(max_depth)
- 限制叶子节点的最小样本数(min_samples_leaf)
- 限制分裂节点的最小样本数(min_samples_split)
后剪枝:先生成完整的树,再从下往上裁剪
- 代价复杂度剪枝(CCP):通过计算每个节点的代价复杂度增益,裁剪增益最小的节点
代码示例
python
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 未剪枝的决策树
dt_unpruned = DecisionTreeClassifier(random_state=42)
dt_unpruned.fit(X_train, y_train)
print("未剪枝决策树训练集准确率:", accuracy_score(y_train, dt_unpruned.predict(X_train)))
print("未剪枝决策树测试集准确率:", accuracy_score(y_test, dt_unpruned.predict(X_test)))
print("未剪枝决策树深度:", dt_unpruned.get_depth())
# 预剪枝
dt_prepruned = DecisionTreeClassifier(
max_depth=3,
min_samples_leaf=5,
min_samples_split=10,
random_state=42
)
dt_prepruned.fit(X_train, y_train)
print("\n预剪枝决策树训练集准确率:", accuracy_score(y_train, dt_prepruned.predict(X_train)))
print("预剪枝决策树测试集准确率:", accuracy_score(y_test, dt_prepruned.predict(X_test)))
print("预剪枝决策树深度:", dt_prepruned.get_depth())
# 后剪枝(代价复杂度剪枝)
path = dt_unpruned.cost_complexity_pruning_path(X_train, y_train)
ccp_alphas, impurities = path.ccp_alphas, path.impurities
# 训练不同alpha值的决策树
dts = []
for ccp_alpha in ccp_alphas:
dt = DecisionTreeClassifier(ccp_alpha=ccp_alpha, random_state=42)
dt.fit(X_train, y_train)
dts.append(dt)
# 选择测试集准确率最高的alpha
test_scores = [dt.score(X_test, y_test) for dt in dts]
best_idx = test_scores.index(max(test_scores))
best_dt = dts[best_idx]
print("\n后剪枝决策树训练集准确率:", accuracy_score(y_train, best_dt.predict(X_train)))
print("后剪枝决策树测试集准确率:", accuracy_score(y_test, best_dt.predict(X_test)))
print("后剪枝决策树深度:", best_dt.get_depth())1.1.4 数据增强
通过对现有数据进行变换,生成更多的训练样本,增加数据的多样性,从而提高模型的泛化能力。
- 表格数据:添加噪声、特征缩放、SMOTE(用于样本不均衡)
- 图像数据:翻转、旋转、裁剪、缩放、亮度调整
- 文本数据:同义词替换、回译、随机插入 / 删除
1.1.5 集成学习
集成学习通过组合多个弱学习器的预测结果,得到一个更强的学习器,从而降低过拟合风险。
- Bagging:并行训练多个独立的学习器,通过投票或平均得到结果(如随机森林)
- Boosting:串行训练多个学习器,每个学习器都关注前一个学习器的错误(如 XGBoost、LightGBM)
- Stacking:将多个学习器的预测结果作为新的特征,训练一个元学习器
代码示例(随机森林)
python
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(
n_estimators=100,
max_depth=5,
min_samples_leaf=5,
random_state=42
)
rf.fit(X_train, y_train)
print("随机森林训练集准确率:", rf.score(X_train, y_train))
print("随机森林测试集准确率:", rf.score(X_test, y_test))1.2 深度学习中的过拟合处理
深度学习模型参数数量巨大,更容易发生过拟合,因此需要更多的正则化手段。
1.2.1 权重正则化
与机器学习中的正则化类似,在深度学习中也可以对权重施加 L1 或 L2 惩罚。
代码示例(PyTorch)
python
import torch
import torch.nn as nn
import torch.optim as optim
# 定义简单的神经网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(4, 16)
self.fc2 = nn.Linear(16, 3)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
model = Net()
criterion = nn.CrossEntropyLoss()
# L2正则化(通过optimizer的weight_decay参数实现)
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=0.001) # weight_decay=λ
# L1正则化(需要手动实现)
def l1_regularization(model, lambda_l1):
l1_loss = 0
for param in model.parameters():
l1_loss += torch.norm(param, 1)
return lambda_l1 * l1_loss
# 训练过程
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.long)
for epoch in range(100):
optimizer.zero_grad()
outputs = model(X_train_tensor)
loss = criterion(outputs, y_train_tensor)
# 添加L1正则化
loss += l1_regularization(model, lambda_l1=0.0001)
loss.backward()
optimizer.step()1.2.2 Dropout 及其变体
Dropout 在训练过程中随机丢弃一部分神经元,防止模型过度依赖某些特定的神经元,从而提高泛化能力。
- 标准 Dropout:随机将神经元的输出置为 0
- DropConnect:随机将权重置为 0
- Spatial Dropout:用于卷积层,随机丢弃整个特征图
代码示例(PyTorch)
python
class NetWithDropout(nn.Module):
def __init__(self):
super(NetWithDropout, self).__init__()
self.fc1 = nn.Linear(4, 16)
self.dropout = nn.Dropout(p=0.5) # p是丢弃概率
self.fc2 = nn.Linear(16, 3)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.dropout(x) # 只在训练时生效
x = self.fc2(x)
return x
# 注意:测试时要调用model.eval()关闭Dropout
model = NetWithDropout()
model.train() # 训练模式,开启Dropout
# 训练过程...
model.eval() # 评估模式,关闭Dropout1.2.3 早停(Early Stopping)
早停是最简单有效的防止过拟合的方法之一。它通过监控验证集的性能,当验证集性能不再提升时,提前停止训练。
代码示例(PyTorch)
python
import numpy as np
# 划分验证集
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=42)
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.long)
X_val_tensor = torch.tensor(X_val, dtype=torch.float32)
y_val_tensor = torch.tensor(y_val, dtype=torch.long)
model = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
best_val_loss = np.inf
patience = 10 # 耐心值,连续多少个epoch验证集损失不下降就停止
counter = 0
for epoch in range(1000):
# 训练
model.train()
optimizer.zero_grad()
outputs = model(X_train_tensor)
train_loss = criterion(outputs, y_train_tensor)
train_loss.backward()
optimizer.step()
# 验证
model.eval()
with torch.no_grad():
val_outputs = model(X_val_tensor)
val_loss = criterion(val_outputs, y_val_tensor).item()
print(f"Epoch {epoch+1}, Train Loss: {train_loss.item():.4f}, Val Loss: {val_loss:.4f}")
# 早停判断
if val_loss < best_val_loss:
best_val_loss = val_loss
counter = 0
# 保存最佳模型
torch.save(model.state_dict(), 'best_model.pth')
else:
counter += 1
if counter >= patience:
print("早停触发!")
break
# 加载最佳模型
model.load_state_dict(torch.load('best_model.pth'))1.2.4 归一化技术
归一化可以使神经网络的训练更加稳定,加速收敛,同时也有一定的正则化效果。
- 批归一化(Batch Normalization):对每个批次的数据进行归一化
- 层归一化(Layer Normalization):对每个样本的所有特征进行归一化
- 实例归一化(Instance Normalization):对每个样本的每个通道进行归一化
- 组归一化(Group Normalization):将通道分成若干组,对每组进行归一化
代码示例(PyTorch)
python
class NetWithBN(nn.Module):
def __init__(self):
super(NetWithBN, self).__init__()
self.fc1 = nn.Linear(4, 16)
self.bn = nn.BatchNorm1d(16) # 批归一化
self.fc2 = nn.Linear(16, 3)
self.relu = nn.ReLU()
def forward(self, x):
x = self.fc1(x)
x = self.bn(x) # 批归一化通常放在激活函数之前
x = self.relu(x)
x = self.fc2(x)
return x
class NetWithLN(nn.Module):
def __init__(self):
super(NetWithLN, self).__init__()
self.fc1 = nn.Linear(4, 16)
self.ln = nn.LayerNorm(16) # 层归一化
self.fc2 = nn.Linear(16, 3)
self.relu = nn.ReLU()
def forward(self, x):
x = self.fc1(x)
x = self.ln(x)
x = self.relu(x)
x = self.fc2(x)
return x1.2.5 降低模型复杂度
最简单直接的方法就是减少模型的参数数量:
- 减少网络的深度(层数)
- 减少网络的宽度(每层的神经元数量)
- 使用更简单的网络结构
1.2.6 深度学习数据增强
深度学习对数据量的需求很大,数据增强是提高模型泛化能力的关键手段。
文本数据增强
python
import random
from transformers import pipeline
# 同义词替换
def synonym_replacement(text, n=1):
# 使用预训练模型进行同义词替换
unmasker = pipeline('fill-mask', model='bert-base-uncased')
words = text.split()
if len(words) < n:
return text
indices = random.sample(range(len(words)), n)
for idx in indices:
masked_text = ' '.join(words[:idx] + ['[MASK]'] + words[idx+1:])
predictions = unmasker(masked_text)
if predictions:
words[idx] = predictions[0]['token_str']
return ' '.join(words)
# 回译法
def back_translation(text, src_lang='en', tgt_lang='fr'):
translator = pipeline('translation', model=f'Helsinki-NLP/opus-mt-{src_lang}-{tgt_lang}')
back_translator = pipeline('translation', model=f'Helsinki-NLP/opus-mt-{tgt_lang}-{src_lang}')
translated = translator(text, max_length=1000)[0]['translation_text']
back_translated = back_translator(translated, max_length=1000)[0]['translation_text']
return back_translated
# 示例
text = "Machine learning is a subset of artificial intelligence."
print("原文本:", text)
print("同义词替换后:", synonym_replacement(text))
print("回译后:", back_translation(text))2. 样本不均衡的处理方式
2.1 样本不均衡的定义与影响
定义:样本不均衡指数据集中各类别样本数量分布严重不均。例如,在欺诈检测数据集中,欺诈样本可能只占总样本的 0.1%。
影响:
- 模型会偏向于多数类,导致少数类的召回率极低
- 准确率指标失去意义,即使模型将所有样本都预测为多数类,也能获得很高的准确率
- 模型无法学习到少数类的特征
2.2 数据层面的处理方法
2.2.1 欠采样(Under-sampling)
欠采样通过减少多数类样本的数量来平衡数据集。
随机欠采样:随机删除多数类样本
- 优点:简单快速
- 缺点:可能丢失重要信息,导致模型泛化能力下降
改进方法:
- EasyEnsemble:将多数类样本分成多个子集,每个子集与少数类样本组成一个平衡数据集,训练多个模型,最后集成
- BalanceCascade:串行训练多个分类器,每次删除被正确分类的多数类样本
代码示例(imblearn)
python
from imblearn.under_sampling import RandomUnderSampler, EasyEnsembleClassifier
# 生成不均衡数据集
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=10000, n_features=20, n_informative=2,
n_redundant=10, weights=[0.99], random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print("原始数据集类别分布:", {0: sum(y_train==0), 1: sum(y_train==1)})
# 随机欠采样
rus = RandomUnderSampler(random_state=42)
X_train_rus, y_train_rus = rus.fit_resample(X_train, y_train)
print("随机欠采样后类别分布:", {0: sum(y_train_rus==0), 1: sum(y_train_rus==1)})
# EasyEnsemble
eec = EasyEnsembleClassifier(n_estimators=10, random_state=42)
eec.fit(X_train, y_train)
print("EasyEnsemble测试集F1分数:", f1_score(y_test, eec.predict(X_test)))2.2.2 过采样(Over-sampling)与 SMOTE 算法
过采样通过增加少数类样本的数量来平衡数据集。
随机过采样:随机复制少数类样本
- 优点:简单
- 缺点:容易导致过拟合
SMOTE 算法:合成少数类过采样技术
- 原理:
- 对每个少数类样本,找到它的 k 个近邻
- 随机选择一个近邻
- 在该样本和近邻之间的连线上随机生成一个新样本
- 优点:不会导致过拟合
- 缺点:可能生成重叠的样本,对高维数据效果不佳
改进方法:
- ADASYN:根据样本的学习难度为不同的少数类样本生成不同数量的合成样本
- SMOTEENN:先使用 SMOTE 过采样,再使用 ENN(编辑最近邻)欠采样
代码示例(imblearn)
python
from imblearn.over_sampling import RandomOverSampler, SMOTE, ADASYN
from sklearn.metrics import f1_score
# 随机过采样
ros = RandomOverSampler(random_state=42)
X_train_ros, y_train_ros = ros.fit_resample(X_train, y_train)
print("随机过采样后类别分布:", {0: sum(y_train_ros==0), 1: sum(y_train_ros==1)})
# SMOTE
smote = SMOTE(random_state=42)
X_train_smote, y_train_smote = smote.fit_resample(X_train, y_train)
print("SMOTE后类别分布:", {0: sum(y_train_smote==0), 1: sum(y_train_smote==1)})
# ADASYN
adasyn = ADASYN(random_state=42)
X_train_adasyn, y_train_adasyn = adasyn.fit_resample(X_train, y_train)
print("ADASYN后类别分布:", {0: sum(y_train_adasyn==0), 1: sum(y_train_adasyn==1)})
# 训练模型并评估
lr = LogisticRegression(random_state=42)
lr.fit(X_train_smote, y_train_smote)
y_pred = lr.predict(X_test)
print("SMOTE+逻辑回归测试集F1分数:", f1_score(y_test, y_pred))2.2.3 数据增强
针对少数类样本进行数据增强,生成更多的少数类样本,是解决样本不均衡的有效方法。
- 图像:翻转、旋转、裁剪、亮度调整
- 文本:同义词替换、回译、大模型生成
2.3 算法层面的处理方法
2.3.1 类别权重调整
通过给少数类样本赋予更高的权重,使模型更加关注少数类。
代码示例
python
# sklearn中的类别权重调整
lr_balanced = LogisticRegression(class_weight='balanced', random_state=42)
lr_balanced.fit(X_train, y_train)
y_pred = lr_balanced.predict(X_test)
print("类别权重平衡逻辑回归测试集F1分数:", f1_score(y_test, y_pred))
# 自定义类别权重
lr_custom = LogisticRegression(class_weight={0: 1, 1: 100}, random_state=42)
lr_custom.fit(X_train, y_train)
y_pred = lr_custom.predict(X_test)
print("自定义类别权重逻辑回归测试集F1分数:", f1_score(y_test, y_pred))
# 随机森林中的类别权重调整
rf_balanced = RandomForestClassifier(class_weight='balanced', random_state=42)
rf_balanced.fit(X_train, y_train)
y_pred = rf_balanced.predict(X_test)
print("类别权重平衡随机森林测试集F1分数:", f1_score(y_test, y_pred))2.3.2 损失函数加权(含 Focal Loss)
在深度学习中,可以通过给少数类样本的损失赋予更高的权重来解决样本不均衡问题。
Focal Loss:专门为解决样本不均衡问题设计的损失函数
- 公式:
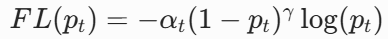
- αt:类别权重,平衡正负样本
- γ:聚焦参数,降低易分类样本的权重,使模型更加关注难分类样本
代码示例(PyTorch)
python
# 交叉熵损失加权
weights = torch.tensor([1.0, 100.0], dtype=torch.float32) # 类别0权重1.0,类别1权重100.0
criterion = nn.CrossEntropyLoss(weight=weights)
# Focal Loss实现
class FocalLoss(nn.Module):
def __init__(self, alpha=1, gamma=2, reduction='mean'):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.reduction = reduction
def forward(self, inputs, targets):
ce_loss = nn.CrossEntropyLoss(reduction='none')(inputs, targets)
pt = torch.exp(-ce_loss)
focal_loss = self.alpha * (1-pt)**self.gamma * ce_loss
if self.reduction == 'mean':
return focal_loss.mean()
elif self.reduction == 'sum':
return focal_loss.sum()
else:
return focal_loss
# 使用Focal Loss
criterion_focal = FocalLoss(alpha=1, gamma=2)2.3.3 阈值调整
在二分类问题中,默认的分类阈值是 0.5。在样本不均衡的情况下,可以通过降低阈值来提高少数类的召回率。
代码示例
python
from sklearn.metrics import roc_curve, precision_recall_curve
# 获取预测概率
y_proba = lr_balanced.predict_proba(X_test)[:, 1]
# 基于ROC曲线选择最优阈值
fpr, tpr, thresholds_roc = roc_curve(y_test, y_proba)
# 计算约登指数(Youden's J statistic)
j_scores = tpr - fpr
best_idx_roc = j_scores.argmax()
best_threshold_roc = thresholds_roc[best_idx_roc]
print("基于ROC曲线的最优阈值:", best_threshold_roc)
# 基于PR曲线选择最优阈值
precision, recall, thresholds_pr = precision_recall_curve(y_test, y_proba)
# 计算F1分数
f1_scores = 2 * (precision * recall) / (precision + recall + 1e-8)
best_idx_pr = f1_scores.argmax()
best_threshold_pr = thresholds_pr[best_idx_pr]
print("基于PR曲线的最优阈值:", best_threshold_pr)
# 使用最优阈值进行预测
y_pred_best = (y_proba >= best_threshold_pr).astype(int)
print("最优阈值下的F1分数:", f1_score(y_test, y_pred_best))2.4 样本不均衡下的评估指标选择
在样本不均衡的情况下,准确率是一个非常具有误导性的指标。应该使用以下指标:
- 精确率(Precision):预测为正的样本中实际为正的比例
- 召回率(Recall):实际为正的样本中被正确预测的比例
- F1 分数:精确率和召回率的调和平均数
- AUC-ROC:ROC 曲线下的面积,衡量模型区分正负样本的能力
- AUC-PR:PR 曲线下的面积,在样本极度不均衡时比 AUC-ROC 更可靠
代码示例
python
from sklearn.metrics import precision_score, recall_score, f1_score, roc_auc_score, average_precision_score
y_pred = lr_balanced.predict(X_test)
y_proba = lr_balanced.predict_proba(X_test)[:, 1]
print("精确率:", precision_score(y_test, y_pred))
print("召回率:", recall_score(y_test, y_pred))
print("F1分数:", f1_score(y_test, y_pred))
print("AUC-ROC:", roc_auc_score(y_test, y_proba))
print("AUC-PR:", average_precision_score(y_test, y_proba))3. 总结
本文系统总结了机器学习和深度学习中两个核心问题 ------ 过拟合和样本不均衡的解决方案。
对于过拟合问题,我们可以从限制模型复杂度 (正则化、剪枝、降低模型复杂度)和增加数据多样性(数据增强、集成学习)两个方面入手。在深度学习中,Dropout、早停和归一化是非常有效的正则化手段。
对于样本不均衡问题,我们可以从数据层面 (欠采样、过采样、数据增强)和算法层面(类别权重调整、损失函数加权、阈值调整)进行处理。同时,必须选择合适的评估指标,避免被准确率误导。
在实际应用中,通常需要结合多种方法来解决这些问题。没有一种方法是万能的,需要根据具体的数据集和业务场景选择最合适的方案。