在涉及用户运营的系统中,"计算连续签到天数"和"计算 N 日留存率"是两个极其高频的业务需求。
面对这两个需求,很多开发人员的第一反应是:SQL 处理不了时间序列中的"断层"问题。于是,他们习惯于把用户的全量打卡记录拉到内存中,用 Java 里的 for 循环加上日期工具类去逐个比对天数。这不仅代码冗长,而且在大数据量下性能极差。
实际上,只要掌握了 SQL 里的日期函数并结合前面几篇文章讲过的窗口函数与行列转换,这类复杂的时间序列统计在数据库执行层就能优雅搞定。本文将直接拆解这两个经典难题的标准 SQL 写法。
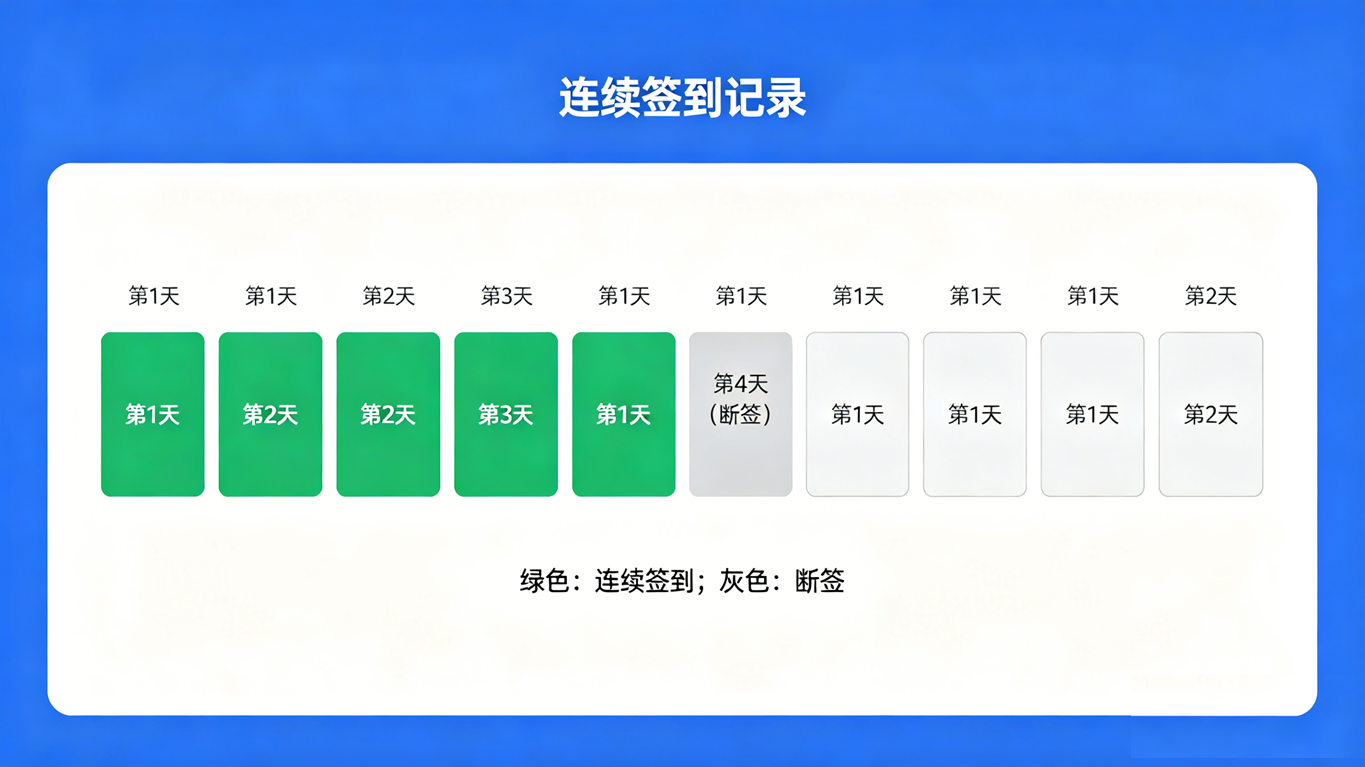
一、 终极考验 1:"连续签到"问题(孤岛问题)
需求说明: 找出 user_checkins 表中,连续签到天数大于等于 3 天的所有用户,并给出他们连续签到的起止时间。
表结构参考: user_checkins (user_id, checkin_date) (假设数据按天记录,没有时分秒)
核心难点: 时间序列是不连续的(比如 1号、2号、4号签到,3号断签了)。常规的 GROUP BY 无法将 1号和 2号分为一组,将 4号分为另一组。这在数据库领域被称为著名的"孤岛问题(Gaps and Islands)"。
巧妙解法:利用等差数列的差值恒定原理 如果在连续的日期上,减去一个连续递增的序号,得到的结果必然是同一个日期!
WITH
-- 步骤 1:去重。防止脏数据导致同一天有两条签到记录
DistinctCheckins AS (
SELECT DISTINCT user_id, checkin_date
FROM user_checkins
),
-- 步骤 2:为每个用户的签到日期按时间顺序打上连续的行号(1, 2, 3...)
RankedCheckins AS (
SELECT
user_id,
checkin_date,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY checkin_date) AS rn
FROM DistinctCheckins
),
-- 步骤 3:核心魔法。用签到日期减去行号的天数,得到一个"分组基准日"
GroupedCheckins AS (
SELECT
user_id,
checkin_date,
DATE_SUB(checkin_date, INTERVAL rn DAY) AS group_date
FROM RankedCheckins
)
-- 步骤 4:根据 user_id 和 分组基准日 进行常规聚合计算
SELECT
user_id,
MIN(checkin_date) AS continuous_start,
MAX(checkin_date) AS continuous_end,
COUNT(*) AS continuous_days
FROM GroupedCheckins
GROUP BY user_id, group_date
HAVING COUNT(*) >= 3;原理解析: 假设张三在 5月1日、5月2日、5月4日签到。
-
5月1日:行号 1。5月1日减 1 天 = 4月30日。
-
5月2日:行号 2。5月2日减 2 天 = 4月30日。
-
5月4日:行号 3。5月4日减 3 天 = 5月1日 。 你能清晰地看到,因为 3号断签了,行号没有断,但日期断了。减去行号后,连续的 1号和 2号得到了相同的
group_date(4月30日),而 4号得到了不同的group_date。 随后,我们只需要直接GROUP BY group_date,就能把连续的日期完美聚合成一行。一行 SQL 替代了应用层几百行的循环比对逻辑。
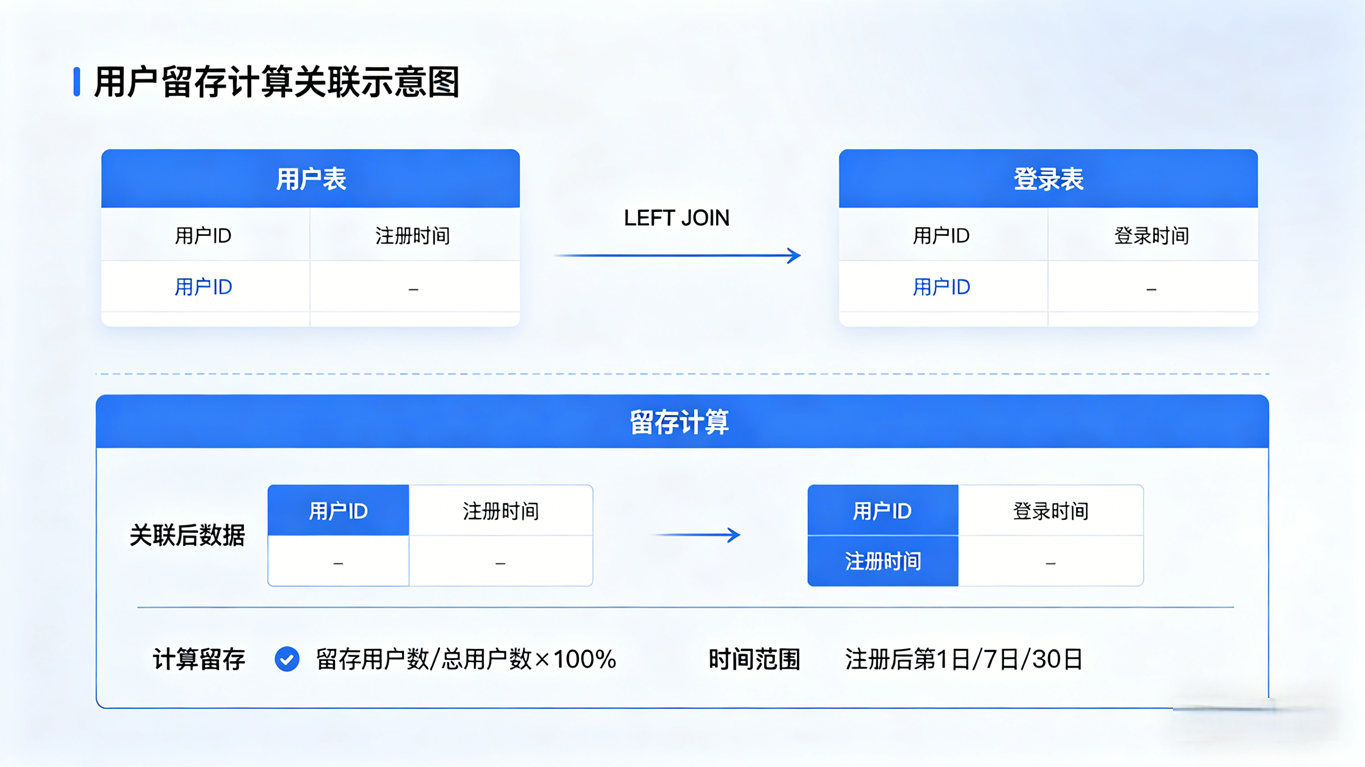
二、 终极考验 2:用户留存率报表
需求说明: 统计每天的新注册用户数,以及这些用户在注册后的第 1 天(次日)、第 3 天、第 7 天的留存情况。
表结构参考: 用户表:users (user_id, register_date) 登录流水表:user_login_log (user_id, login_date)
核心难点: 我们需要以"注册日期"为基准,将不同日期的登录记录通过日期差值"拍扁"到同一行上。这需要结合上一篇学的 CASE WHEN 知识。
优雅解法:LEFT JOIN + 日期差值 + 条件去重统计
SELECT
u.register_date,
-- 1. 统计当天的总注册人数
COUNT(DISTINCT u.user_id) AS new_users,
-- 2. 计算次日留存:注册日期与登录日期相差 1 天的用户数
COUNT(DISTINCT CASE WHEN DATEDIFF(l.login_date, u.register_date) = 1 THEN l.user_id END) AS day_1_retention,
-- 3. 计算 3 日留存:相差 3 天
COUNT(DISTINCT CASE WHEN DATEDIFF(l.login_date, u.register_date) = 3 THEN l.user_id END) AS day_3_retention,
-- 4. 计算 7 日留存:相差 7 天
COUNT(DISTINCT CASE WHEN DATEDIFF(l.login_date, u.register_date) = 7 THEN l.user_id END) AS day_7_retention
FROM users u
-- 使用 LEFT JOIN,保证即使某天注册的用户没人再登录,该注册日期的行依然存在
LEFT JOIN user_login_log l
ON u.user_id = l.user_id
-- 优化点:只关联注册之后的登录记录,减少无关的数据比对
AND l.login_date >= u.register_date
GROUP BY u.register_date
ORDER BY u.register_date DESC;原理解析与工程细节:
-
DATEDIFF函数: 这是计算两个日期相差天数的绝对利器。通过比较登录日和注册日,我们把复杂的日期序列转化为了简单的整数(1, 3, 7)。 -
COUNT(DISTINCT ...)的必要性: 同一个用户可能在次日登录了 5 次,user_login_log表会有 5 条记录。如果不加DISTINCT,这个用户的次日留存会被计算为 5 个人。结合CASE WHEN只在满足天数差时返回user_id,完美实现了按天维度的精准去重。
三、 总结与架构建议
这两个案例展示了 SQL 在处理数据逻辑时极其硬核的一面。
-
连续问题(孤岛): 记住"日期 减去 行号 = 分组基准"这个公式,它是处理所有连续状态(连续跌停、连续活跃、连续下单)的标准解法。
-
留存问题(漏斗): 善用 左连接主表 +
DATEDIFF+CASE WHEN行转列。
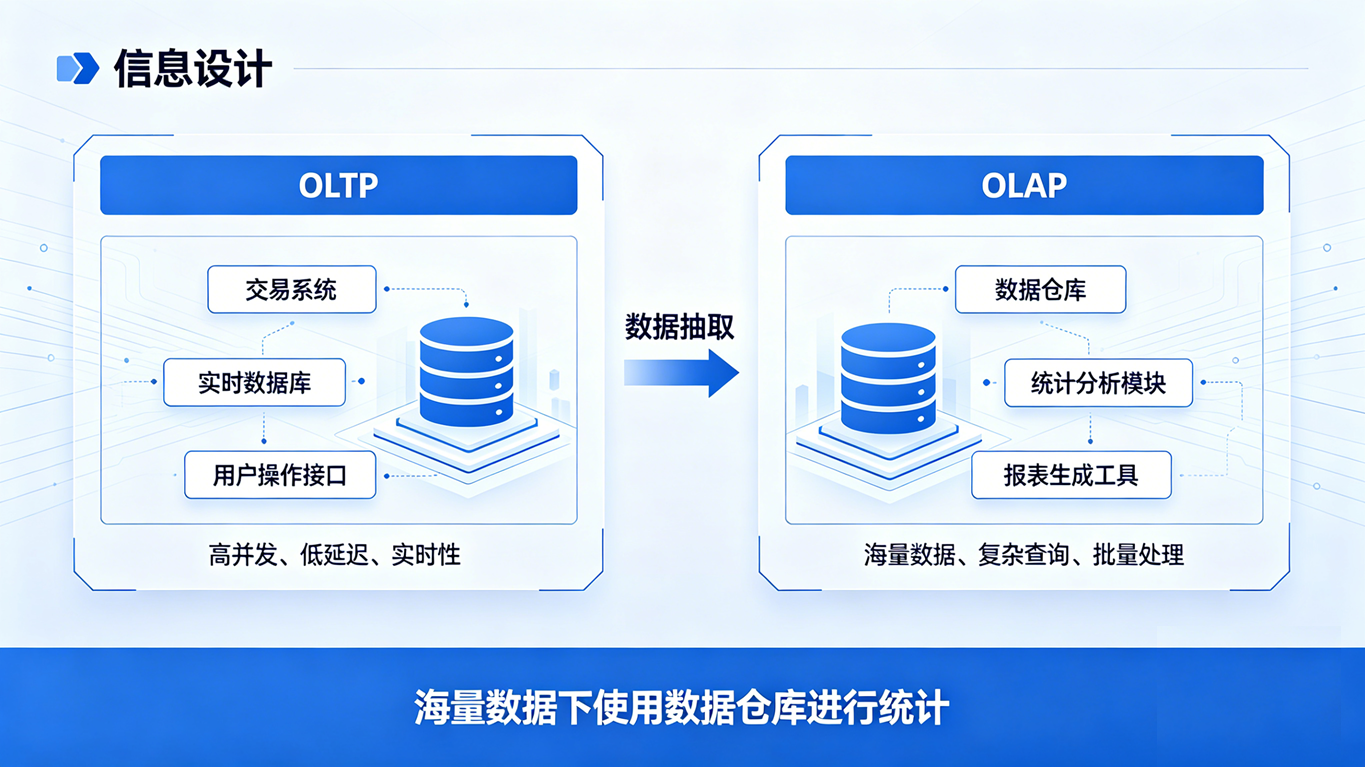
架构边界提示: 虽然这种写法很优雅,但必须明确:关系型数据库(如 MySQL、PostgreSQL)主要应对的是业务事务(OLTP)。 如果你的 user_login_log 表每天有上千万条新增记录,直接在 MySQL 上执行包含 COUNT(DISTINCT) 和复杂时间计算的 SQL,依然会导致全表扫描和内存临时表爆满。 在真实的大型互联网公司架构中,面对海量用户的留存与漏斗分析,这段标准的 SQL 逻辑依然有效,但执行环境应该迁移到专门的列式数据仓库(如 ClickHouse、Doris)中进行。