上海交大人AI研究院联手 Sand.ai 开源了超强音视频大模型 daVinci-MagiHuman。
单张H100显卡2秒就能生成5秒256P人物音视频。最让人惊艳的是AI的微表情生成能力,挑眉、抿唇、眼角的细微牵动都自然到和真人无异,人类评测胜率超80%。

开源地址:https://github.com/GAIR-NLP/daVinci-MagiHuman
现在的AI音视频生成赛道,早就不是拼单纯的画面生成能力了,能做出贴合情绪的人物微表情、实现音画精准同步,才是真正的硬实力。
而daVinci-MagiHuman专为人物音视频生成打造的AI模型,把逼真二字真的做到了极致。
不仅能精准还原挑眉、撇嘴、浅笑这些细腻的微表情,让人物的情绪表达更生动,还能实现微表情和语音的完美联动。
说开心时眼角会自然弯起,讲严肃内容时嘴角会轻轻抿紧,就连肢体动作的幅度、节奏都和真人的行为逻辑高度契合。
同时还支持普通话、粤语、英语、日语、韩语、德语、法语等多语种语音生成,跨语言的人物音视频创作直接一步到位。
咱们直接看下案例效果吧。仔细看这个妹子说话时的眨眼、嘴巴联动,话语停顿等几乎和人类差不多,笑的时候也很自然,日剧味可太冲了~
,时长00:37
而这个小哥说话时的语气、眼神、动作也特别到位,毫无违和感。
,时长00:19
这款模型能做出这么惊艳的微表情和逼真效果,核心在于它颠覆了传统的多流架构,采用 150 亿参数的 40 层单流Transformer 作为核心骨干网络,把文本、视频、音频三种不同信息全都转换成统一的token序列,只用自注意力机制就完成了所有特征的处理和融合。
咱们打个比方,传统多流架构就像是给不同的食材准备了不同的灶台和厨具,还要专门找个师傅来把做好的菜拼在一起,步骤多还容易出问题。
而单流架构就是一个万能灶台,所有食材都在这个灶台上处理,还能自然融合出味道,不仅省了设备,还少了中间拼接的麻烦。从根源上保证了人物表情、动作和语音的协调性,微表情的自然度也就水到渠成。
当然这套单流架构能落地,还靠四个特别贴心的设计细节,每一个都踩在了架构优化的点子上。
首先是三明治架构布局,40 层 Transformer 的开头和结尾各 4 层专门处理不同模态的特征,能精准捕捉文本里的情绪细节、音频里的语调变化、视频里的面部特征。
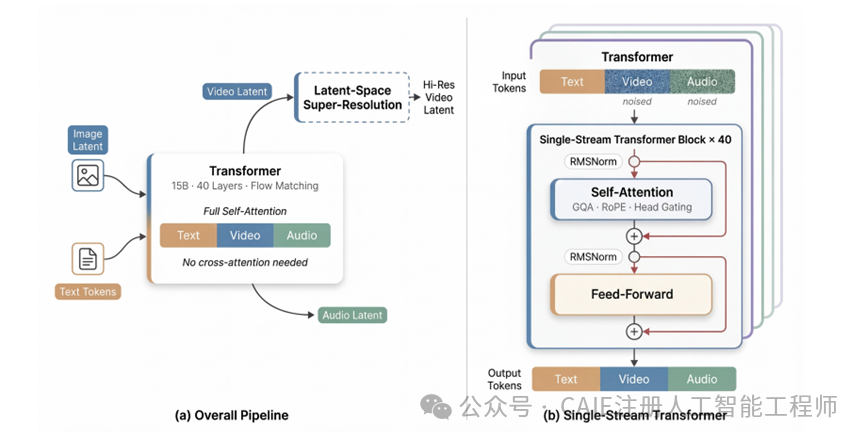
中间 32 层则用共享参数做深度融合,让情绪、微表情、语音三者完美联动,不会出现 "说着开心的话,脸上却是平淡表情" 的违和感。
其次是无时间步去噪机制,去掉了传统扩散模型专门处理时间信息的模块,直接从带噪声的音视频数据里推断去噪状态。
让人物的微表情变化更连贯,从浅笑到大笑的过渡、从皱眉到舒展的过程,都和真人的表情变化节奏一致,不会出现卡顿、跳帧的生硬感。
还有注意力头级门控设计,给每个注意力头加了可调节的门控,让模型能自主聚焦到微表情的关键特征上。
比如眼角的褶皱、嘴角的弧度、眉峰的高度,这些细微的面部变化都能被精准捕捉和还原,同时还能保证训练时的数值稳定,几乎不增加额外的计算开销。
最后是统一条件处理,把去噪音视频数据、参考的文本情绪、甚至参考图片里的面部特征,都映射到同一个特征空间处理,不用为不同的生成需求设计专门模块。
不管是根据文本生成带微表情的人物视频,还是参考图片还原人物的表情动作,都能轻松搞定,通用性拉满的同时,还能保证微表情的还原度和自然度。
光有逼真的效果还不够,推理效率拉满,才能真正落地商用,而 daVinci-MagiHuman 在速度上的表现,同样让人惊喜。
研究团队把单流骨干网络和模型蒸馏、潜空间超分辨率、Turbo VAE 解码器、全图编译四大技术深度融合,让单张 H100 显卡就能实现秒级生成。
不管是离线做内容创作,还是在线做低延迟的智能数字人交互,都能完美适配,这也是它能成为业内新王炸的重要原因。
在主流测试中daVinci-MagiHuman也相当能打。在客观的质量评测上,视频质量用的是VerseBench基准和VideoScore2指标,从视觉质量、文本对齐、物理一致性三个维度打分,音频质量用TalkVid-Bench基准,用词错误率来衡量语音的可懂度,这个数值越低,说明语音越清晰。
针对中日韩这些语言,还专门做了字符级的计算,避免了分词带来的误差。
实测数据里,这款模型的视觉质量得分4.80,文本对齐得分4.18,都是三款模型里的最高分,比Ovi 1.1和LTX 2.3都要高,说明生成的画面质量更好,和输入的文本描述贴合度也更高。

而主观的人类偏好测试,结果更是一边倒。团队找了10名专业的评估人员,做了2000组随机的对比测试,其中1000组和Ovi 1.1比,1000组和LTX 2.3比,评估人员根据音视频的整体质量、同步性、自然度三个维度选自己更喜欢的结果。
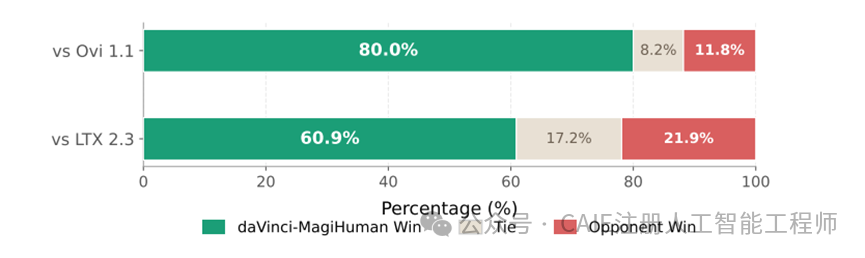
和Ovi 1.1对比的时候,这款模型的胜率直接达到了80%,只有11.8%的情况大家更喜欢Ovi 1.1,平局只有8.2%。
就算是和实力更强的LTX 2.3对比,胜率也有60.9%,对手胜率只有21.9%。
这个结果能直接说明,从人的主观感受来看,这款模型生成的内容更符合大家的审美,音画同步性更好,人物的动作和语音也更自然,这对音视频生成模型来说,是最核心的评价标准。
原文: