GPU 利用率上不去?显存莫名 OOM?分布式训练卡死不动?这些问题不能靠"再加一张卡"解决,必须靠 Profiling 把瓶颈找出来。
性能调优的正确顺序是自顶向下:先在框架层看哪个算子慢,再下到系统层看 CPU/GPU 时间线,最后下到 GPU 芯片内部看微架构。每一层都有专属工具,越往下越精细,但开销也越大。错用工具------比如用 Nsight Compute 跑整个训练循环------会让程序慢上百倍,得不偿失。
下面这五件套覆盖了从框架到硬件的全栈,是我日常排查的标准武器库。
一、PyTorch Profiler:第一手排查工具
什么时候用
90% 的性能问题用 PyTorch Profiler 就能定位。典型场景:
- 不知道哪个算子最耗时
- 怀疑 DataLoader 读图太慢,导致 GPU 在空等(GPU Starvation)
- 显存峰值排查(OOM 原因)
它的优势是几乎不用改代码,套个 Context Manager 就行。
用法一:导出给 TensorBoard 看(图形化)
python
import torch
prof = torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA,
],
# 预热1步,记录2步,避免Profiler本身带来过大开销
schedule=torch.profiler.schedule(wait=1, warmup=1, active=2, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('./log/resnet_profile'),
record_shapes=True, # 记录Tensor形状
profile_memory=True, # 记录显存分配
)
prof.start()
for step, data in enumerate(dataloader):
train_step(data)
prof.step()
prof.stop()然后 tensorboard --logdir=./log/resnet_profile。
重点看三个视图:
- Trace 视图 :找
DataLoader Wait时间块。如果 GPU 时间线上有大段空白,多半是数据加载拖了后腿 - Operator 视图 :看
Self CUDA Time排行榜,谁排第一谁就是嫌疑犯 - Memory 视图:显存随时间的曲线,OOM 之前一定有异常的尖峰
用法二:直接在终端打印表格(轻量、快速)
懒得开 TensorBoard 时,直接 print 一张表更快:
python
import torch
import torchvision.models as models
model = models.resnet18().cuda()
inputs = torch.randn(16, 3, 224, 224).cuda()
# 预热,让GPU初始化完成
for _ in range(3):
model(inputs)
torch.cuda.synchronize()
with torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA,
],
record_shapes=True,
) as prof:
with torch.profiler.record_function("my_resnet_forward"):
outputs = model(inputs)
# 打印表格,sort_by可以是cuda_time_total / self_cuda_time_total / cpu_time_total
print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=10))终端输出长这样:
----------------------- ---------- ---------- ---------- ---------- ----------
Name Self CPU % Self CPU Self CUDA % Self CUDA # of Calls
----------------------- ---------- ---------- ---------- ---------- ----------
my_resnet_forward 2.50% 1.200ms 0.00% 0.000us 1
aten::conv2d 0.15% 72.000us 0.00% 0.000us 20
aten::cudnn_convolution 1.50% 720.000us 75.00% 11.400ms 20
aten::batch_norm 0.10% 48.000us 10.00% 1.520ms 20
...
----------------------- ---------- ---------- ---------- ---------- ----------
Self CPU time total: 48.000ms
Self CUDA time total: 15.200ms怎么读懂这张表
四个维度,必须分清:
Name
aten::xxx是 PyTorch 底层 C++ 算子(aten::conv2d是卷积,aten::add是加法)- 自己用
record_function("xxx")打的标签也会出现在这里Self vs Total
这是最容易搞混的一对:
Total Time:算子从开始到结束的总耗时,包含其内部调用的所有子算子时间 。比如aten::conv2d内部会调aten::convolution → aten::cudnn_convolution,它的 Total 把底层全包进去了Self Time:剔除子调用后该算子自己消耗的时间排查瓶颈时盯紧
Self Time。Total 高没意义------它可能只是个壳;Self 高才说明这一行真的慢。CPU vs CUDA
CPU列:CPU 下发指令(Launch kernel)或纯 CPU 算子的耗时CUDA列:GPU 真正在硅片上算的时间深度学习场景主要看
Self CUDA。# of Calls
调用次数。轻量级算子调用上万次,累加起来也很恐怖。比如某个 element-wise 算子单次只有 5us,但被调用 50000 次就是 250ms。
实战技巧
sort_by="self_cuda_time_total" 排序,前两三行通常就是罪魁祸首。最常见的"惊喜"包括:自定义的 Attention 实现、低效的 LayerNorm、忘了 fuse 的 element-wise 操作。
二、Nsight Systems (nsys):系统级时间线
什么时候用
PyTorch Profiler 告诉你"哪个算子慢",nsys 告诉你"整个系统在干什么"。当你怀疑:
- CPU 准备数据和 GPU 计算没重叠
- H2D(Host to Device)数据拷贝阻塞了计算
- 分布式训练里 NCCL 通信和计算没并行
就该上 nsys 了。
怎么用
不用改代码(但建议在关键代码段加 torch.cuda.nvtx.range("MyOp") 打标签,nsys 会显示出来)。
bash
# 标准用法:生成报告文件,本地用GUI打开
nsys profile -t cuda,nvtx,osrt -o my_profile python train.py
# 终端汇总用法:加 --stats=true 直接打印文本表格
nsys profile -t cuda,nvtx --stats=true python train.py终端输出(--stats=true)
跑完后 nsys 在终端打印两类核心表格:
CUDA API 统计(CPU 端发出的指令耗时):
Time (%) Total Time (ns) Num Calls Avg (ns) Name
-------- --------------- --------- ---------- --------------------
45.2% 1,250,000,000 100 12,500,000 cudaMemcpy (H2D)
30.5% 850,000,000 5000 170,000 cudaLaunchKernel
...这个例子里 H2D 拷贝占了 45%,瓶颈很清楚------数据搬运太重,要么 pin memory、要么改 DataLoader、要么用 prefetch。
CUDA Kernel 统计(GPU 端真正执行的耗时):
Time (%) Total Time (ns) Instances Avg (ns) Name
-------- --------------- --------- -------- ----------------------
60.1% 500,000,000 1000 500,000 volta_sgemm_128x64_nn
15.2% 126,000,000 2000 63,000 layer_norm_kernel
...矩阵乘法占 60% 是健康的(计算密集型任务理应如此);如果某个不起眼的 element-wise kernel 占到 30%,那就有问题。
GUI 界面看什么
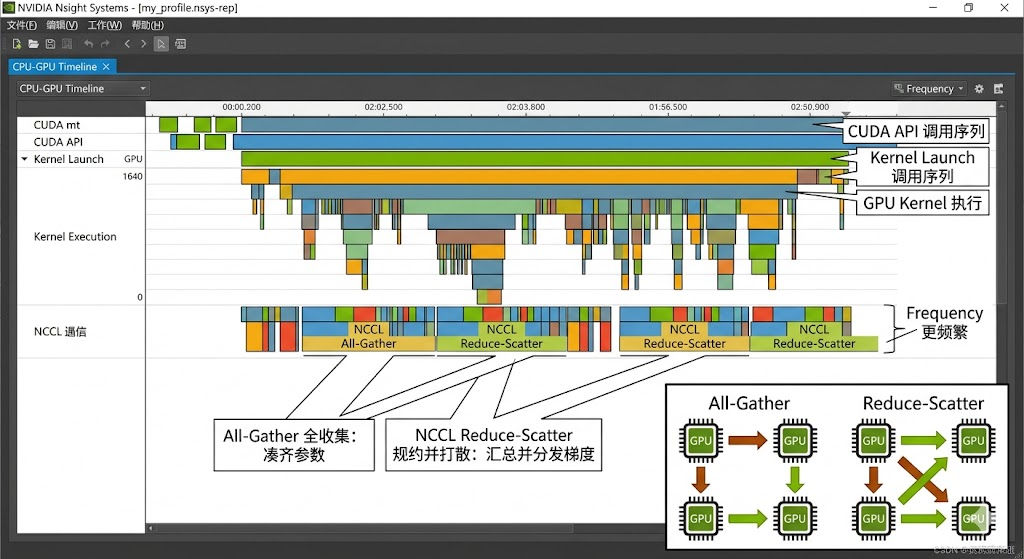
终端表格只有汇总,真正的价值在 GUI 的时间线 。把 .nsys-rep 下载到本地,用 Nsight Systems GUI 打开,会看到一张多行时间线:
- CPU 行:每个核心在做什么(数据预处理、Python 解释器、Kernel Launch)
- CUDA HW 行:GPU 实际执行的 Kernel(按 Stream 分行)
- PCIe / Memcpy 行:H2D / D2H 数据拷贝
- NVTX 行:你自己打的标签
- NCCL 行:分布式通信(AllReduce / AllGather / ReduceScatter)
排障时盯三件事:
- GPU 时间线有没有空白。空白 = GPU 在发呆,多半是 CPU 算太慢或 H2D 拷贝阻塞
- NCCL 色块和计算色块上下重不重叠。不重叠 = 通信被串行化了,扩展性会很差
- AllGather / ReduceScatter 占多大比例。FSDP / ZeRO-3 训练里,AllGather 是 GPU 在计算前临时把分片参数"借齐";ReduceScatter 是计算后把梯度规约并打散回各 GPU。这两个色块如果占据时间线一大半,说明通信成为瓶颈,要考虑梯度累积、offload、或更高带宽的互连
三、Nsight Compute (ncu):Kernel 级显微镜
什么时候用
前两步定位到某个 Kernel 慢------比如自己写的 FlashAttention 跑得不如预期------但你不知道它为什么慢:是被显存带宽卡住了?算力没喂饱?还是寄存器溢出?
ncu 就是干这个的。它会告诉你这个 Kernel 在 GPU 芯片内部的真实状态。
⚠️ 重要警告
绝对不要用 ncu 跑整个训练循环。
它会对每个 Kernel 做极细粒度的硬件计数器采样,开销是 50~200 倍。我见过有人 ncu python train.py 然后程序跑了三天没动------以为是死锁,其实是 ncu 在尽职工作。
正确姿势:精准狙击
bash
# 只profile名字包含"layer_norm"的kernel,只采集1次,输出完整指标
ncu --kernel-regex 'layer_norm' -c 1 --set full -o report python test_kernel.py通常的做法是把要测的算子单独剥离出来写个 mini 脚本,不要带训练循环。
终端输出解读
ncu 的输出是一块块 Section,最关键的有三个:
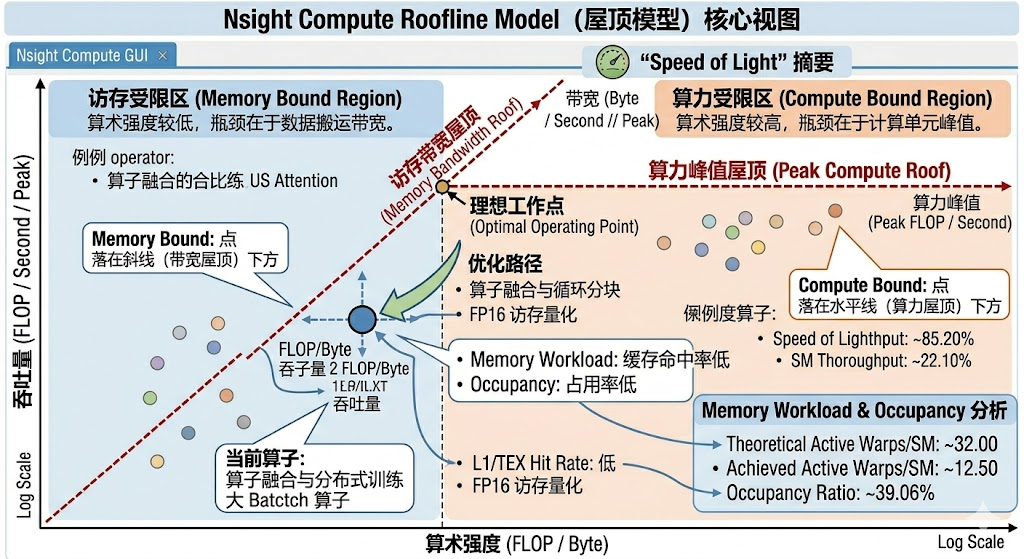
1. Speed of Light(光速模型)--- 一眼看懂瓶颈类型
Section: GPU Speed Of Light Throughput
----------------------------- ---------- ---------------
Memory Throughput % 85.20 ← 访存接近打满
Compute (SM) Throughput % 22.10 ← 算力只跑到22%
----------------------------- ---------- ---------------
WRN This kernel exhibits low compute performance and is memory bound.这种情况叫 Memory Bound:算子在等内存读取,算力单元闲着。优化方向是 fuse 算子、用更大 block 提高数据复用、或者改成 FP16 减少访存量。
反过来如果 Compute % 高、Memory % 低,就是 Compute Bound,瓶颈在算力本身,能做的不多(除非换更高效的算法)。
2. Memory Workload --- 看缓存命中率
Section: Memory Workload Analysis
----------------------------- ---------- -------
L1/TEX Hit Rate % 45.50
L2 Hit Rate % 88.20
----------------------------- ---------- -------L1 命中率低意味着同一块数据被反复从 L2 / 显存读取------典型的访存模式问题。Tile 大小、shared memory 的使用方式都会影响这个。
3. Occupancy --- 线程块配置合不合理
Section: Occupancy
----------------------------- ---------- -------
Theoretical Active Warps/SM warp 32.00
Achieved Active Warps/SM warp 12.50
Occupancy Ratio % 39.06 ← 只跑到理论值的39%
----------------------------- ---------- -------Occupancy 低有几种原因:寄存器用太多(每线程占资源多,能起的 Warp 就少)、Block 太大或太小、shared memory 用太多。GUI 里有交互式工具能告诉你减到什么程度能提升。
Roofline Model(GUI 里最直观的视图)
GUI 会画一张 Roofline 图:横轴是算术强度(FLOP / Byte),纵轴是吞吐。每个 Kernel 是图上一个点。
- 点落在斜线(带宽屋顶)下方 → Memory Bound
- 点落在水平线(算力屋顶)下方 → Compute Bound
- 点离屋顶有多远,就是优化空间有多大
四、NCCL_DEBUG=INFO:分布式通信排障
什么时候用
DDP / FSDP / ZeRO 训练突然 hang 住、超时、或者多机扩展效率差到不能看。这些问题大概率出在通信层,但报错信息往往一脸懵------这时候打开 NCCL 的调试日志就对了。
怎么用
bash
export NCCL_DEBUG=INFO
export NCCL_DEBUG_SUBSYS=INIT,GRAPH # 可选:只看初始化和图构建
torchrun --nproc_per_node=8 train.py重点看三件事
1. 网卡选择
日志会有这种行:
NCCL INFO NET/IB : Using [0]mlx5_0:1/IB如果看到 mlx5_xxx 是 InfiniBand,速度正确。如果看到 eth0 或更糟的 docker0,那就是走错网卡了------多机训练性能直接腰斩。常见的修法是显式指定 NCCL_SOCKET_IFNAME=eth1 或 NCCL_IB_HCA=mlx5。
2. 连接方式(单机内 GPU 之间)
text
NCCL INFO Channel 00 : 0[3000] -> 1[4000] via P2P/IPC
NCCL INFO Channel 00 : 0[3000] -> 4[7000] via SYSNVL/P2P/IPC走 NVLink 或 NVSwitch,最快PHB走 PCIe Host Bridge,差一档SYS跨 NUMA 走 CPU 内存,最慢
A100 / H100 服务器理论上 GPU 之间应该全是 NVL,如果出现 SYS 说明拓扑或绑核出了问题。
3. 拓扑构建
text
NCCL INFO Trees [0] 1/-1/-1->0->-1
NCCL INFO Channel 00/02 : Ring : 0 -> 1 -> 2 -> 3 -> 0NCCL 会构建 Ring 或 Tree 拓扑做 AllReduce。这块日志卡住或反复重试,多半是 GPU 之间不通,要去查 IB 网络或 GPU Fabric Manager。
五、nvidia-smi topo / dmon:硬件层监控
最后这套是基本功,训练前先做体检,训练中做轻量监控。
nvidia-smi topo -m:查看 GPU 拓扑
bash
nvidia-smi topo -m输出一张矩阵:
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7
GPU0 X NV12 NV12 NV12 NV12 NV12 NV12 NV12
GPU1 NV12 X NV12 NV12 NV12 NV12 NV12 NV12
GPU2 NV12 NV12 X NV12 NV12 NV12 NV12 NV12
...字符含义:
NV#:NVLink 直连,数字越大带宽越高(A100 是 NV12,H100 是 NV18)PIX/PXB/PHB:走 PCIe 不同层级,依次变慢NODE/SYS:跨 NUMA 节点,最慢
部署多卡训练前先看一遍。如果两张卡之间是 SYS,那把它们放进同一个 process group 就是性能灾难。
nvidia-smi dmon:实时监控
bash
nvidia-smi dmon -s ucm -d 1-s ucm = Utilization + Compute + Memory,-d 1 = 每秒采样。
输出像这样:
# gpu sm mem enc dec mclk pclk
# Idx % % % % MHz MHz
0 30 90 0 0 1593 1410
1 95 45 0 0 1593 1410GPU0 的 sm 才 30%,但 mem 跑到 90%------典型的访存密集特征,算力被显存带宽拖住。这种 Kernel 拿去 ncu 分析多半会确认 Memory Bound。
GPU1 的 sm 95% / mem 45% 是计算密集的健康状态。
完整排查工作流
把这五件套串起来,遇到性能问题的标准流程是:
nvidia-smi dmon先看一眼 --- sm 利用率多少?是不是有卡在睡觉?- PyTorch Profiler 跑一轮 --- 找 Self CUDA Time 排行榜的 Top 3
- 怀疑数据加载或通信?上 nsys --- 看 GPU 时间线有没有空白、NCCL 有没有重叠
- 某个 Kernel 死活优化不动?上 ncu --- Roofline 看是 Memory Bound 还是 Compute Bound
- 分布式训练 hang 住?开 NCCL_DEBUG=INFO --- 检查网卡、连接方式、拓扑
工具的开销是金字塔:上面便宜下面贵。能在第 2 步解决的问题不要拖到第 4 步------绝大多数训练性能问题,PyTorch Profiler + nsys 这一组合就够用了。真正需要下到 ncu 的场景是写自定义 CUDA Kernel 或榨取理论峰值,那是另一个层级的工作。
至于 NCCL 和拓扑相关的------这些问题往往不是性能问题而是"能不能跑起来"的问题,等到训练 hang 了再开始查就晚了,所以首次部署时先 topo -m 看一眼、单机多卡和多机各跑一次 NCCL_DEBUG,是值得的预防性投入。