Redis高频面试题与跳跃表原理详解
一、缓存穿透
问题描述
缓存穿透 是指用户大量请求不存在的数据------缓存中没有,数据库中也没有。所有请求直接打到数据库,导致数据库负载过高甚至崩溃。
用户请求 → Redis缓存(无) → 数据库(无) → 数据库崩溃解决方案
1. 布隆过滤器(Bloom Filter)
使用Redis的bitmap类型,将所有合法的数据ID存入过滤器。查询前先检查布隆过滤器,如果判断数据不存在则直接返回,避免无效查询打到数据库。
bash
# 将合法ID存入bitmaps(以用户ID为例)
SETBIT bloom:user:exists 10001 1
SETBIT bloom:user:exists 10002 1
# 查询时检查
GETBIT bloom:user:exists 99999 # 返回0,说明不存在2. 缓存空值
将空值也缓存起来,并设置较短的过期时间(如30秒)。这样相同请求第二次就会从缓存返回。
bash
# 查询数据库也为空时,缓存空值
SETEX cache:user:99999 30 ""3. 延迟加载策略
查询时先检查布隆过滤器,如果过滤器判断可能存在再去查询数据库。适用于数据量可控的业务场景。
二、缓存击穿
问题描述
缓存击穿 是指某个热点key对应数据存在,但缓存过期失效,瞬间大量请求直接打数据库。就像"击穿"了缓存保护层一样。
热点key失效 → 大量并发请求 → 直接打数据库 → 数据库过载解决方案
1. 热点数据预热
在系统上线或高峰期前,将热点数据提前加载到缓存中:
bash
# 系统启动时预热热点数据
KEYS hot:* # 找出热点key
GET hot:product:1 # 提前加载到缓存2. 实时监控与续期
实时监控系统中的热点key,检测到即将过期时自动延长过期时间:
python
# 伪代码:监控热点key并自动续期
if is_hot_key(key) and ttl(key) < 60:
expire(key, 3600) # 自动延长到1小时3. 分布式互斥锁
使用Redis的SETNX命令实现分布式锁,保证只有一个线程去数据库读取数据:
python
# 伪代码:使用SETNX实现互斥锁
lock = redis.setnx('lock:product:1', '1', nx=True, ex=10)
if lock:
# 只有获取到锁的线程才去查询数据库
data = db.query('SELECT * FROM products WHERE id=1')
redis.setex('product:1', 3600, json.dumps(data))
redis.delete('lock:product:1')
else:
# 其他线程等待或返回旧数据
time.sleep(0.1)三、缓存雪崩
问题描述
缓存雪崩 是指某一时刻大量key同时过期,或者Redis服务宕机,导致大量请求同时打到数据库,造成数据库瞬间负载过高而崩溃。
同一时刻大量key过期 → 大量请求同时打数据库 → 数据库崩溃解决方案
1. 多级缓存架构(推荐)
Nginx缓存 → Redis缓存 → 数据库多级缓存分担压力,即使Redis缓存失效,Nginx缓存仍能挡住部分流量。
2. 随机过期时间
设置过期时间时加上随机值,避免大量key同时过期:
python
# 伪代码:设置随机过期时间
base_ttl = 3600 # 基础1小时
random_ttl = random.randint(0, 300) # 随机0-5分钟
expire(key, base_ttl + random_ttl)3. 分布式锁 + 服务熔断
使用分布式锁保证高并发下只有一个线程去数据库读取数据,同时实现服务熔断降级机制。
四、跳跃表(Skip List)原理
什么是跳跃表
跳跃表是一种有序的链表数据结构 ,是Redis有序集合(Sorted Set / ZSET)的底层实现之一。

跳跃表支持平均O(log N)、最坏**O(N)**的插入、删除、查找操作,是一种高效的空间换时间的数据结构。
跳跃表数据结构
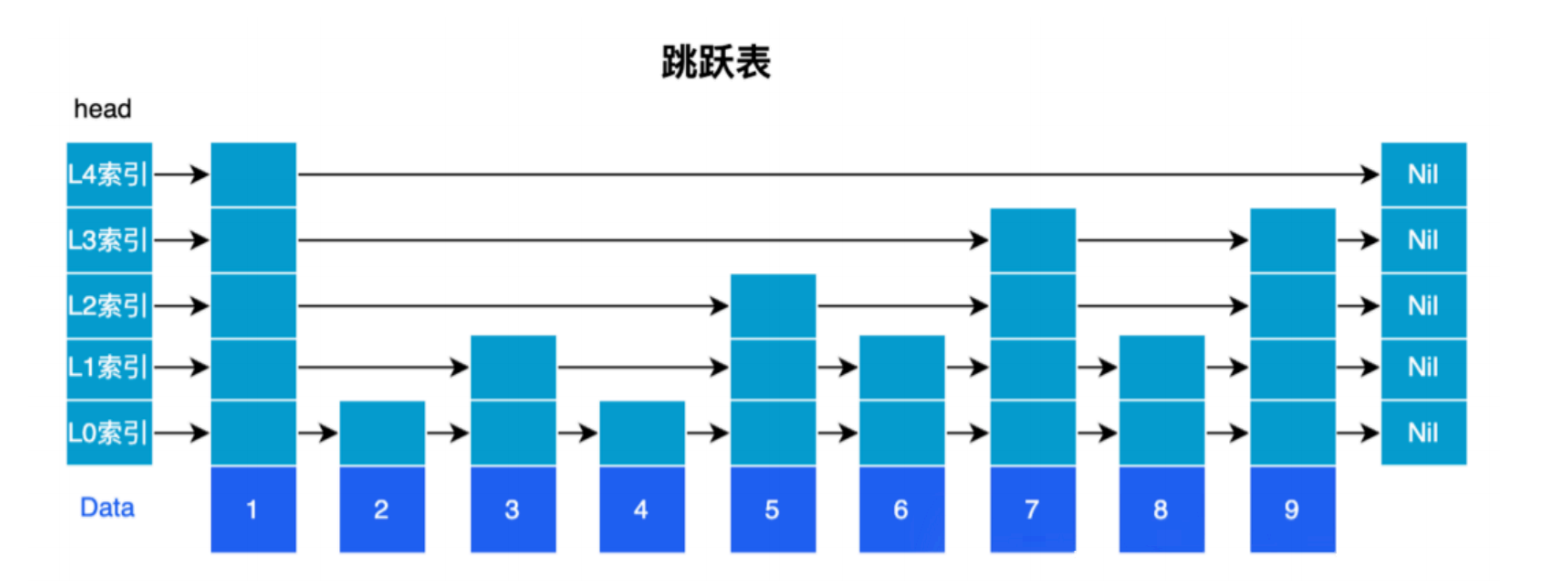
跳跃表通过维护多层级链表实现快速查找:
- 每层节点的
forward指针指向同一层的下一个节点 - 底层(0层)包含所有元素
- 上层节点是下层节点的"快速通道",用于加速遍历
简单示例
假设要在链表中查找节点3:
普通链表:需要遍历 1→2→3,经过3个节点
跳跃表:从最上层开始,1→3(跨过2),只经过2个节点
跳跃表的层数通常用随机算法决定,每一层大概是下一层的50%概率升层。
Redis中跳跃表的实现
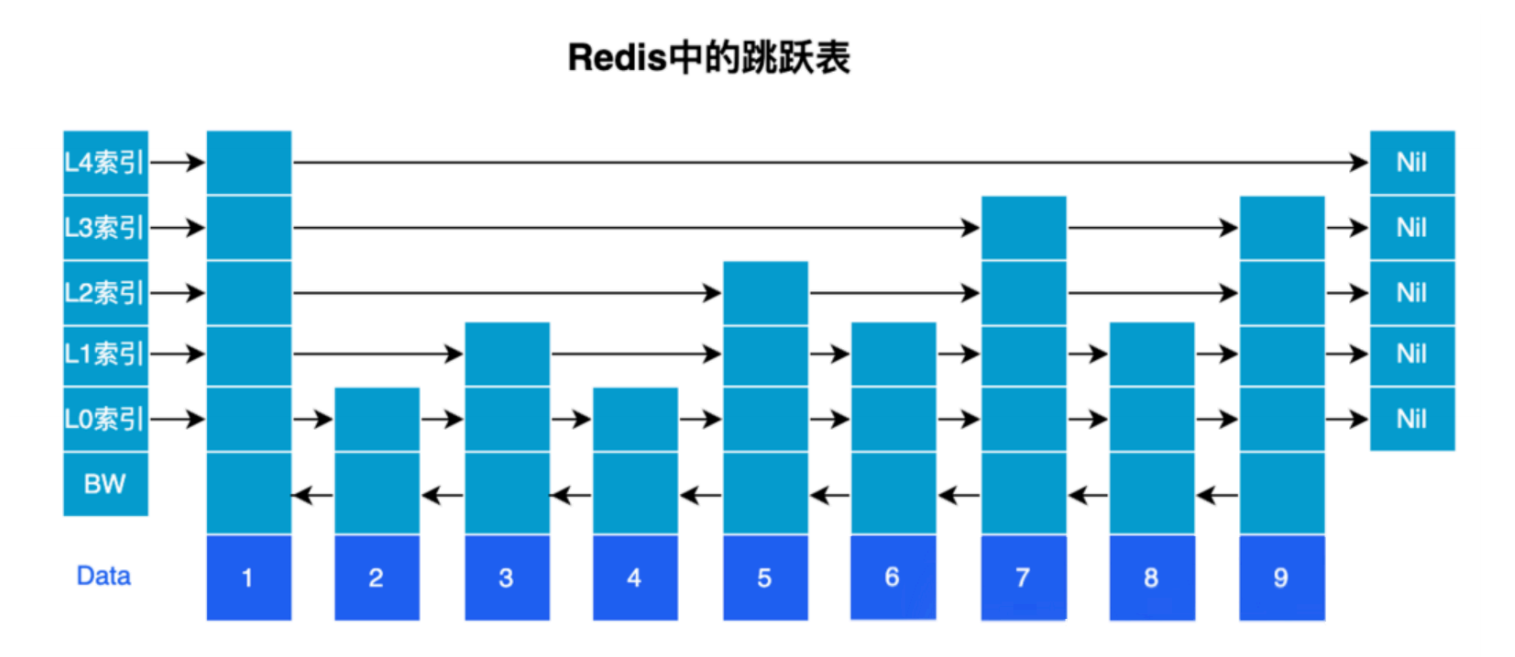
Redis跳跃表节点结构源码:
c
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele; // 元素值
double score; // 分数(排序依据)
struct zskiplistNode *backward; // 前驱指针(双向遍历)
struct zskiplistLevel {
struct zskiplistNode *forward; // 每层的前进指针
unsigned long span; // 跨度(用于计算排名)
} level[];
} zskiplistNode;Redis跳跃表的特点:
| 特性 | 说明 |
|---|---|
| 快速查找 | 利用层级结构,O(log N)时间复杂度 |
| 范围查找 | O(log N)查找特定范围内的节点 |
| 双向遍历 | 每个节点都有前驱指针,支持正序/逆序遍历 |
跳跃表 vs 其他数据结构
| 数据结构 | 查找复杂度 | 是否支持范围查询 | 实现复杂度 |
|---|---|---|---|
| 跳跃表 | O(log N) | ✅ 支持 | 简单 |
| 平衡树(AVL) | O(log N) | ✅ 支持 | 复杂(需旋转) |
| 哈希表 | O(1) | ❌ 不支持 | 简单 |
| 普通链表 | O(N) | ❌ 不支持 | 最简单 |
对比总结:
- vs 平衡树:实现更简单,不需要旋转操作,但时间复杂度相同
- vs 哈希表:支持范围查询和有序输出,虽然查找稍慢但功能更全面
- vs 链表:查找效率从O(N)提升到O(log N),空间换时间
Redis跳跃表应用场景
1. 有序集合(Sorted Set / ZSET)
ZSET是Redis支持的一种数据结构,可以存储一个元素并附带分数,通过分数排序。ZADD、ZRANGE等操作的底层就是用跳跃表实现的。
bash
# ZSET示例:排行榜
ZADD leaderboard 100 "player1"
ZADD leaderboard 200 "player2"
ZADD leaderboard 150 "player3"
# 按分数范围获取排名
ZRANGEBYSCORE leaderboard 100 2002. Redis集群节点管理
Redis集群中使用跳跃表存储节点信息和槽(slot)信息,实现高效的范围操作。
跳跃表优缺点总结
优点
- 插入/删除/查找时间复杂度 O(log N),性能高效
- 实现比平衡树简单,无需复杂的旋转操作
- 支持范围查询和有序输出
- 内存效率较高
缺点
- 空间复杂度 O(N),每个元素需要存储多层级指针
- 层级随机性可能导致最坏情况,但概率很低