📌 前言
作为大数据开发者,深入理解HDFS的底层原理至关重要。本文将从读写数据流程 、NameNode与SecondaryNameNode工作机制 、DataNode心跳与数据完整性三个核心维度,结合源码与架构图,带你彻底搞懂HDFS的设计哲学。
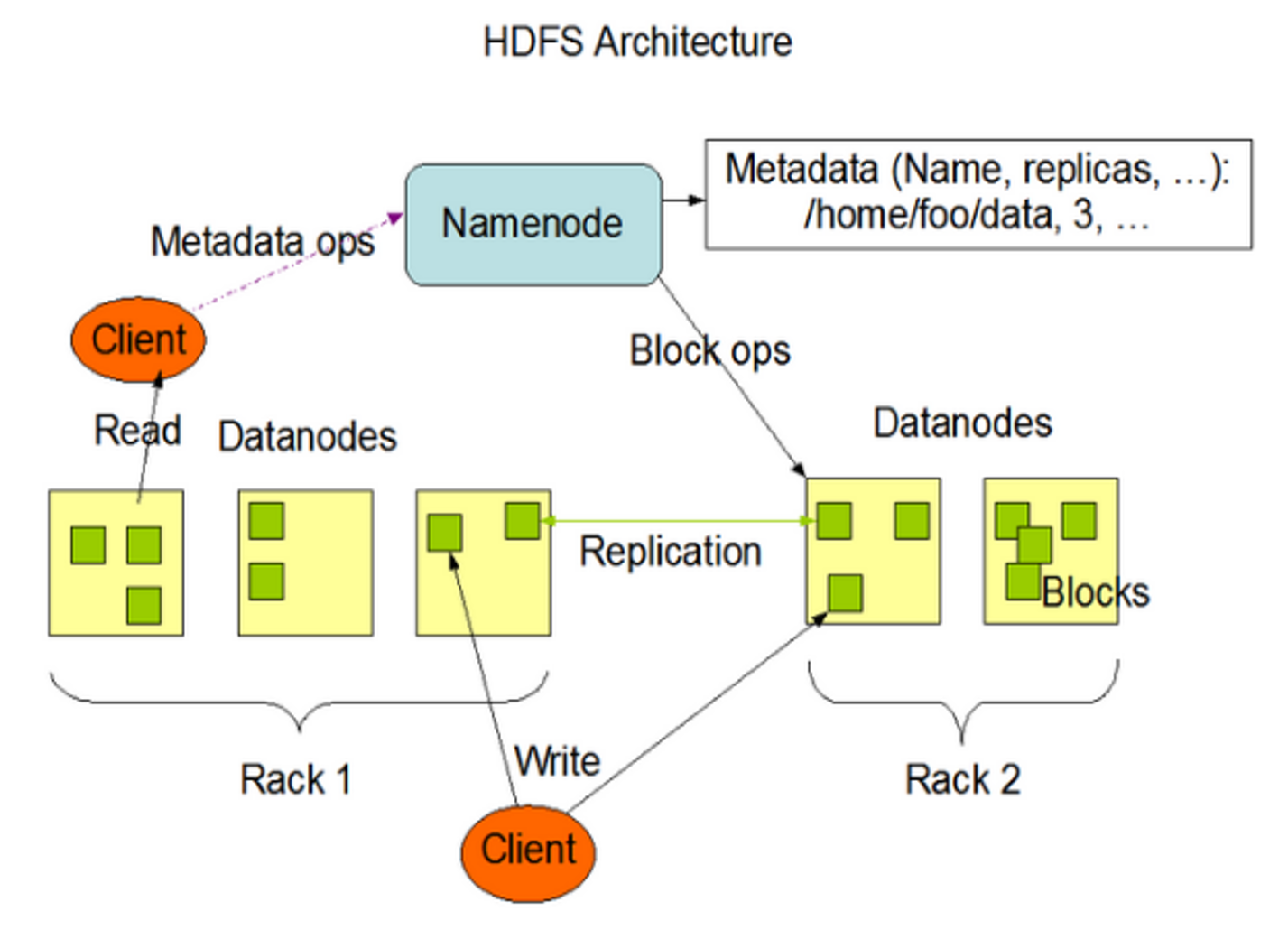
一、HDFS架构回顾
在深入原理之前,先快速回顾HDFS的核心架构:
| 组件 | 核心职责 |
|---|---|
| NameNode | 管理文件系统命名空间,维护元数据(目录树、文件属性、块位置映射) |
| DataNode | 存储实际的数据块(Block),执行数据的读写操作 |
| SecondaryNameNode | 辅助NameNode合并FsImage和Edits,不是NameNode的热备份 |
| Client | 通过NameNode获取元数据,直接与DataNode交互读写数据 |
💡 关键认知:HDFS的设计遵循**"移动计算比移动数据更经济"**的原则,计算任务调度到数据所在节点执行,减少网络传输开销。
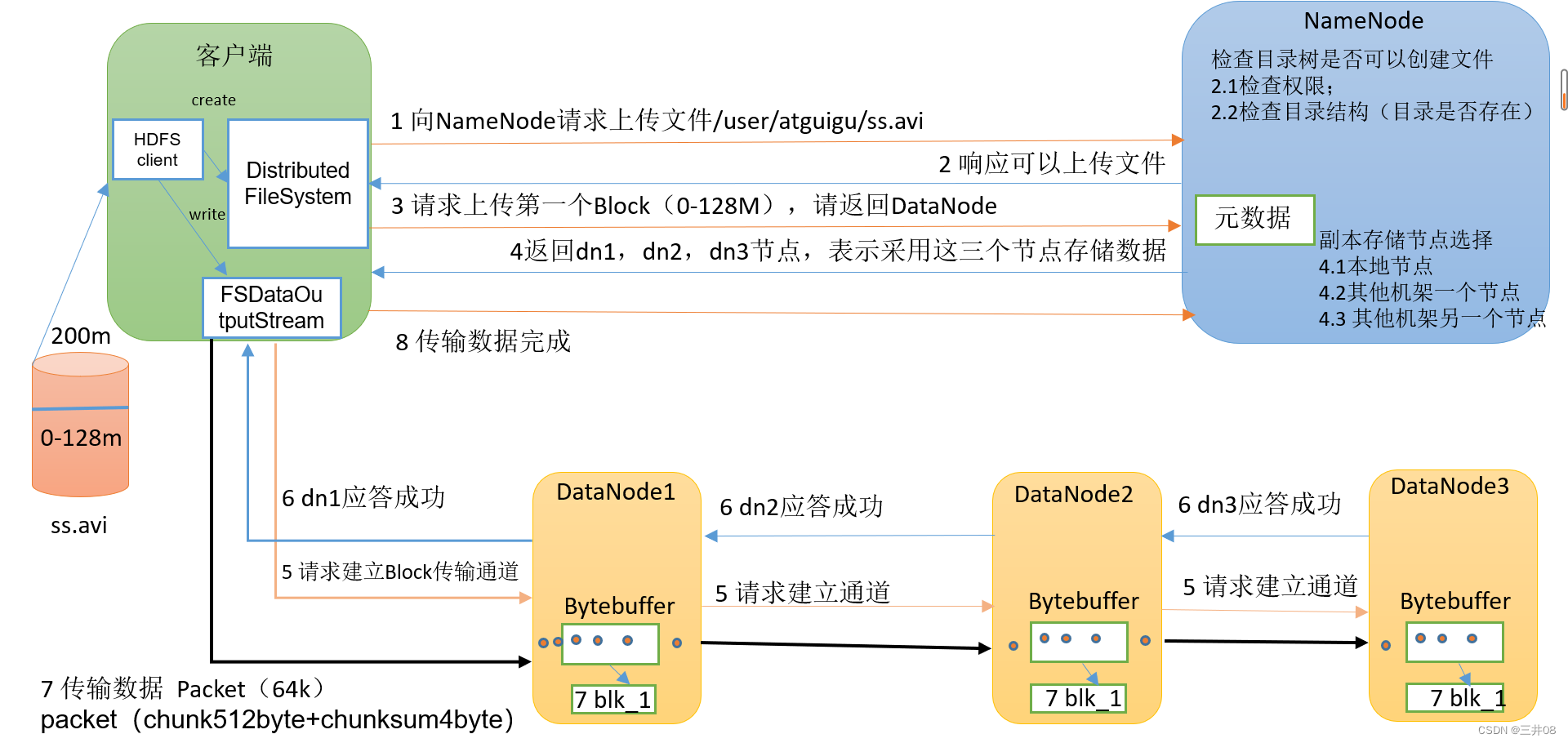
二、HDFS写数据流程(面试重点)
2.1 完整流程图解
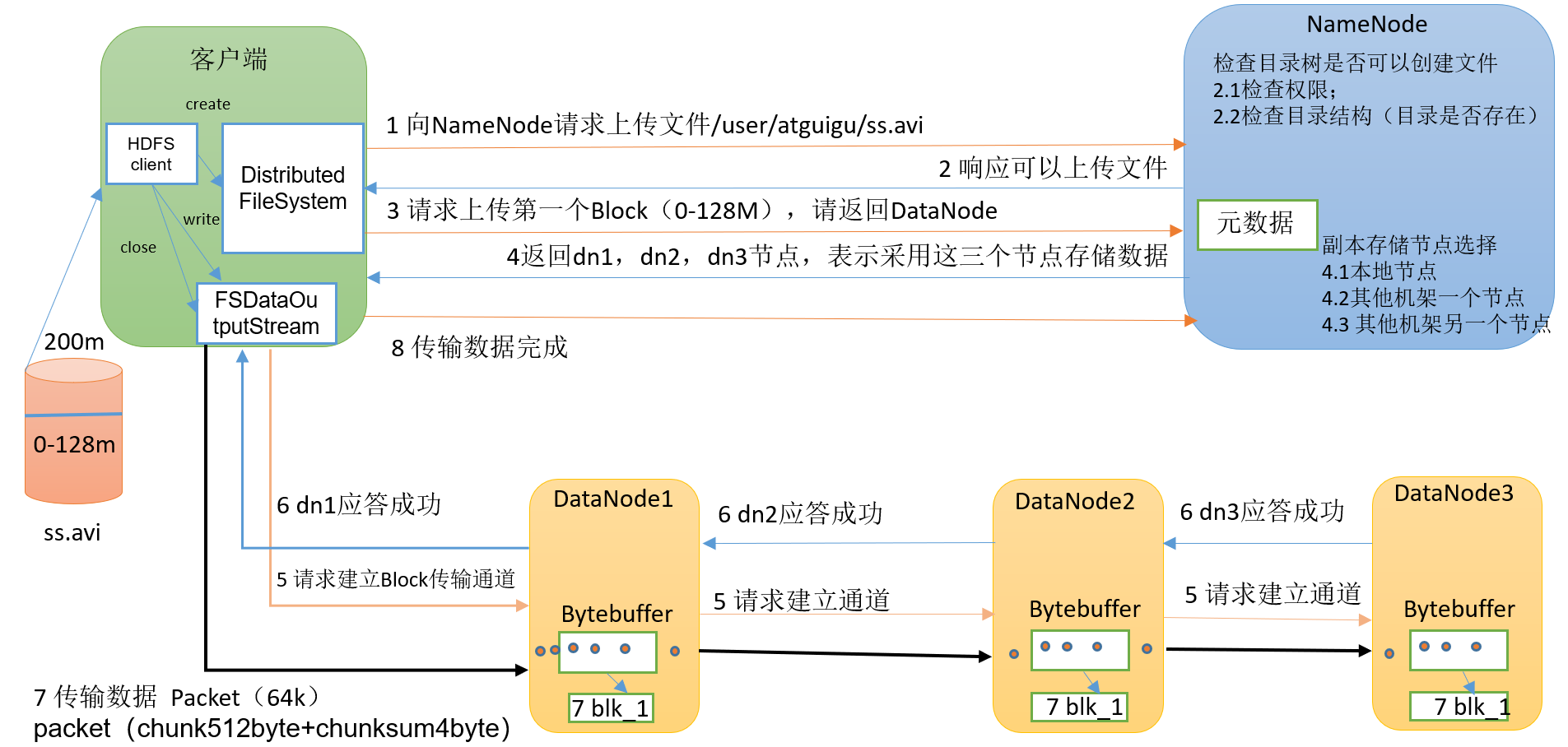
2.2 八步详细解析
| 步骤 | 操作 | 详细说明 |
|---|---|---|
| ① | 客户端请求上传 | 通过DistributedFileSystem向NameNode请求上传文件/user/atguigu/ss.avi |
| ② | NameNode校验 | 检查目标文件是否已存在、父目录是否存在,返回是否可以上传 |
| ③ | 请求Block位置 | 客户端请求第一个Block(0-128MB)上传到哪些DataNode |
| ④ | 返回DataNode列表 | NameNode返回3个DataNode节点(dn1、dn2、dn3),基于机架感知策略 |
| ⑤ | 建立传输管道 | 客户端通过FSDataOutputStream请求dn1,dn1调用dn2,dn2调用dn3,建立Pipeline |
| ⑥ | 逐级应答 | dn3→dn2→dn1逐级应答客户端,管道建立完成 |
| ⑦ | 传输数据 | 客户端以**Packet(64KB)**为单位上传,dn1收到后传给dn2,dn2传给dn3;同时dn1将Packet放入应答队列等待确认 |
| ⑧ | 循环传输 | 第一个Block完成后,客户端再次请求NameNode上传第二个Block(重复③-⑦) |
2.3 核心细节:Packet传输机制
客户端内存缓存
↓
Packet (64KB) = chunk(512B) + checksum(4B) × 128个chunk
↓
┌─────────┐ ┌─────────┐ ┌─────────┐
│ DataNode1 │──→│ DataNode2 │──→│ DataNode3 │
│ (dn1) │ │ (dn2) │ │ (dn3) │
└─────────┘ └─────────┘ └─────────┘
↑
应答队列(ACK确认机制)🔑 关键设计 :Pipeline并行传输------客户端只需发送一次数据,DataNode之间自动复制,而非客户端分别发送3份,极大减少网络带宽占用。
三、机架感知与副本存储策略
3.1 网络拓扑与节点距离计算
NameNode选择DataNode时,遵循**"就近原则"**。节点距离 = 两个节点到达最近共同祖先的距离总和。
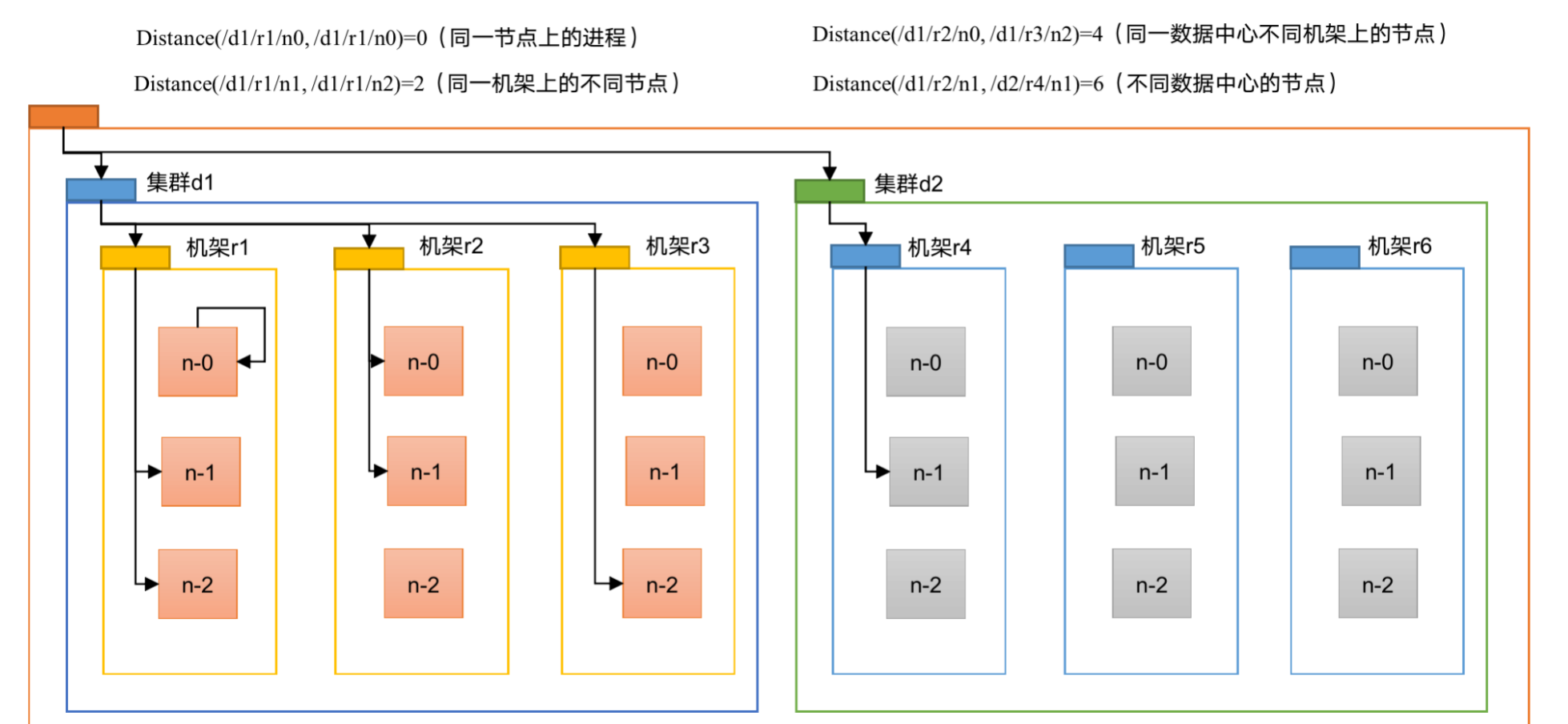
距离计算示例:
| 场景 | 路径 | 距离 |
|---|---|---|
| 同一节点上的进程 | /d1/r1/n1 → /d1/r1/n1 |
0 |
| 同一机架不同节点 | /d1/r1/n1 → /d1/r1/n2 |
2 (n1→r1→n2) |
| 同一数据中心不同机架 | /d1/r1/n1 → /d1/r2/n0 |
4 (n1→r1→d1→r2→n0) |
| 不同数据中心 | /d1/r1/n1 → /d2/r4/n0 |
6 (n1→r1→d1→root→d2→r4→n0) |
3.2 官方副本存储策略(Hadoop 3.1.3)
3副本策略详解:
| 副本 | 存储位置 | 设计意图 |
|---|---|---|
| 第1个副本 | 客户端所在节点(若客户端在集群内);否则随机选择一个节点 | 利用数据局部性,减少网络传输 |
| 第2个副本 | 与第1个副本不同机架的随机节点 | 防止机架故障导致数据丢失 |
| 第3个副本 | 与第2个副本相同机架的另一个节点 | 平衡可靠性与网络带宽 |
📌 源码验证 :在
BlockPlacementPolicyDefault类的chooseTargetInOrder方法中实现。
策略优势:
- ✅ 可靠性:3个副本分布在2个机架,机架故障不丢数据
- ✅ 写性能:只需跨1个机架传输,减少机架间写流量
- ✅ 读性能:块分布在2个机架,读取时可就近选择
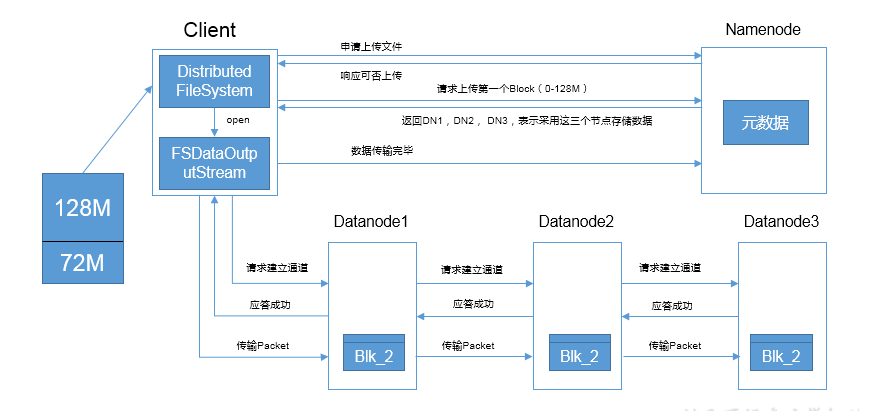
四、HDFS读数据流程
4.1 完整流程图解
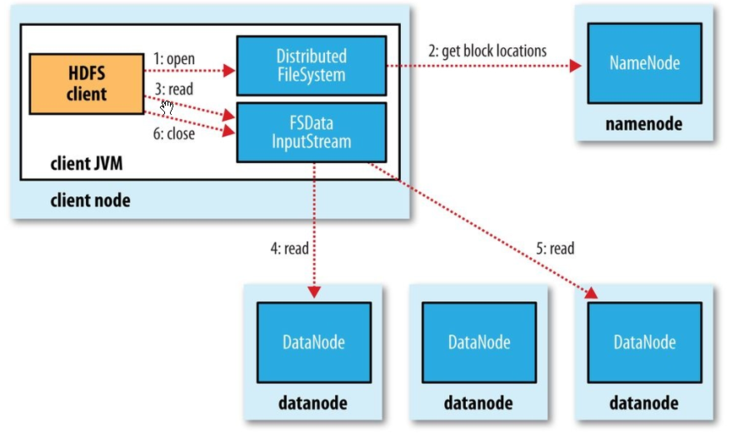
4.2 四步详细解析
| 步骤 | 操作 | 详细说明 |
|---|---|---|
| ① | 请求下载 | 客户端通过DistributedFileSystem向NameNode请求下载文件 |
| ② | 获取元数据 | NameNode查询元数据,返回文件块所在的DataNode地址列表 |
| ③ | 选择DataNode | 客户端挑选一台DataNode(就近原则 → 随机),请求读取数据 |
| ④ | 传输数据 | DataNode从磁盘读取数据,以Packet为单位传输给客户端;客户端本地缓存后写入目标文件 |
💡 就近原则:优先选择距离客户端最近的DataNode,若该节点负载过高或数据损坏,则自动切换到其他副本节点。
五、NameNode与SecondaryNameNode工作机制
5.1 核心问题:元数据如何持久化?
NameNode的元数据存储在内存中 ,但断电会丢失。解决方案:FsImage(镜像文件)+ Edits(编辑日志)。
| 文件 | 作用 | 特点 |
|---|---|---|
| FsImage | 元数据的完整快照 | 体积大,不频繁更新 |
| Edits | 元数据变更的操作日志 | 只追加不修改,效率高 |
5.2 工作机制图解
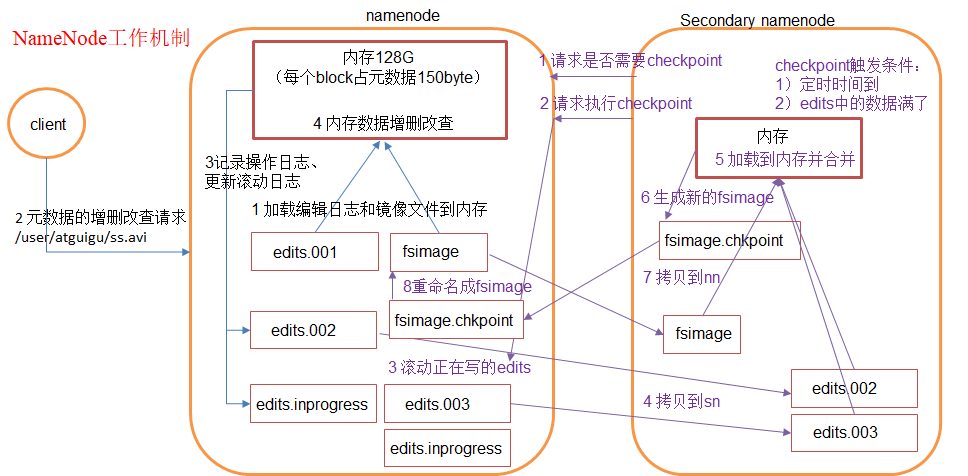
5.3 两阶段工作流程
第一阶段:NameNode启动
1. 格式化后创建FsImage和Edits文件
↓
2. 非首次启动:加载FsImage和Edits到内存
↓
3. 客户端发起增删改请求
↓
4. NameNode记录操作日志 → 更新Edits文件
↓
5. NameNode在内存中执行元数据变更第二阶段:SecondaryNameNode工作(CheckPoint)
| 步骤 | 操作 | 说明 |
|---|---|---|
| ① | 询问CheckPoint | SecondaryNameNode询问NameNode是否需要执行CheckPoint |
| ② | 请求执行 | NameNode同意,触发CheckPoint流程 |
| ③ | 滚动Edits | NameNode将正在写的edits_inprogress滚动为edits |
| ④ | 拷贝文件 | 将滚动前的edits和fsimage拷贝到SecondaryNameNode |
| ⑤ | 加载合并 | SecondaryNameNode加载到内存,合并生成新的镜像 |
| ⑥ | 生成新镜像 | 生成fsimage.chkpoint文件 |
| ⑦ | 拷贝回NameNode | 将fsimage.chkpoint拷贝到NameNode |
| ⑧ | 重命名 | NameNode将fsimage.chkpoint重命名为fsimage |
5.4 CheckPoint触发条件
xml
<!-- hdfs-default.xml -->
<!-- 条件1:每隔1小时执行一次 -->
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600s</value>
</property>
<!-- 条件2:每分钟检查操作次数,达到100万时触发 -->
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60s</value>
</property>⚠️ 重要澄清 :SecondaryNameNode不是NameNode的热备份!它只是辅助合并元数据,NameNode故障时无法自动接管。
5.5 FsImage与Edits文件解析
查看FsImage(oiv命令)
bash
hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-3.1.3/fsimage.xmlFsImage内容示例:
xml
<inode>
<id>16386</id>
<type>DIRECTORY</type>
<name>user</name>
<mtime>1512722284477</mtime>
<permission>atguigu:supergroup:rwxr-xr-x</permission>
</inode>
<inode>
<id>16389</id>
<type>FILE</type>
<name>wc.input</name>
<replication>3</replication>
<perferredBlockSize>134217728</perferredBlockSize>
<blocks>
<block>
<id>1073741825</id>
<numBytes>59</numBytes>
</block>
</blocks>
</inode>🤔 思考题 :FsImage中没有记录块对应的DataNode ,为什么?
💡 答案:集群启动后,DataNode会主动向NameNode上报块信息,并周期性(6小时)再次上报。动态维护比静态记录更准确。
查看Edits(oev命令)
bash
hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-3.1.3/edits.xmlEdits记录的操作类型:
OP_START_LOG_SEGMENT:日志段开始OP_ADD:添加文件OP_ALLOCATE_BLOCK_ID:分配块IDOP_SET_GENSTAMP_V2:设置时间戳OP_ADD_BLOCK:添加数据块OP_CLOSE:关闭文件
六、DataNode工作机制
6.1 数据块存储结构
每个数据块在DataNode上以两个文件存储:
- 数据文件:实际的数据内容
- 元数据文件:数据块长度、校验和(Checksum)、时间戳
6.2 心跳机制与块汇报
| 机制 | 频率 | 作用 |
|---|---|---|
| 心跳 | 每3秒一次 | 向NameNode报告存活状态,接收NameNode指令(如复制块、删除块) |
| 块汇报 | 每6小时一次 | 上报所有数据块信息,确保NameNode元数据准确 |
| 目录扫描 | 每6小时一次 | 扫描本地磁盘块信息,与内存中的块列表比对 |
关键配置:
xml
<!-- 心跳间隔 -->
<property>
<name>dfs.heartbeat.interval</name>
<value>3s</value>
</property>
<!-- 块汇报间隔(毫秒) -->
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>21600000</value> <!-- 6小时 -->
</property>
<!-- 目录扫描间隔 -->
<property>
<name>dfs.datanode.directoryscan.interval</name>
<value>21600s</value> <!-- 6小时 -->
</property>6.3 掉线时限参数
NameNode判断DataNode不可用的超时时间:
超时时间 = 2 × dfs.namenode.heartbeat.recheck-interval + 10 × dfs.heartbeat.interval
= 2 × 300000ms + 10 × 3s
= 600s + 30s
= 630s(10分30秒)
xml
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value> <!-- 毫秒 -->
</property>💡 设计意义:避免网络抖动导致误判,给DataNode足够的恢复时间。
七、数据完整性保障
7.1 校验和(Checksum)机制
场景假设:如果存储高铁信号灯数据的磁盘损坏,一直显示绿灯,后果极其严重。HDFS通过以下机制保证数据完整性:
| 步骤 | 操作 |
|---|---|
| ① | DataNode读取Block时,计算CheckSum |
| ② | 与Block创建时的CheckSum比对 |
| ③ | 不一致 → Block已损坏 → 客户端读取其他DataNode上的副本 |
| ④ | DataNode周期性验证CheckSum,发现损坏自动修复 |
7.2 常用校验算法
| 算法 | 校验码长度 | 特点 |
|---|---|---|
| CRC32 | 32位 | 速度快,HDFS默认使用 |
| MD5 | 128位 | 安全性高,但计算较慢 |
| SHA1 | 160位 | 安全性更高,用于敏感数据 |
7.3 数据完整性流程图
八、核心知识点总结
| 主题 | 核心要点 |
|---|---|
| 写数据流程 | ①请求→②校验→③获取DataNode→④建立Pipeline→⑤Packet传输→⑥ACK确认→⑦循环传输 |
| 读数据流程 | ①请求→②获取元数据→③就近选择DataNode→④Packet传输 |
| 机架感知 | 第1副本本地节点,第2副本不同机架,第3副本同机架不同节点 |
| NameNode机制 | 内存元数据 + FsImage快照 + Edits日志,SecondaryNameNode辅助合并 |
| CheckPoint | 每小时或100万次操作触发,合并FsImage和Edits |
| DataNode心跳 | 每3秒心跳,每6小时块汇报,10分30秒超时判定 |
| 数据完整性 | CRC32校验和,损坏自动切换副本,周期验证自动修复 |
面试高频考点
-
HDFS为什么不适合存储小文件?
- NameNode内存中每个文件/目录的元数据约150字节,小文件过多会耗尽NameNode内存
- 寻址时间超过读取时间,效率低下
-
SecondaryNameNode是NameNode的备份吗?
- 不是! 它只是辅助合并FsImage和Edits,无法替代NameNode
- 生产环境应使用HA(High Availability)架构,部署Active/Standby双NameNode
-
HDFS如何保证数据不丢失?
- 多副本冗余(默认3副本)
- 机架感知策略分散存储
- Checksum校验和自动检测损坏
- 心跳机制及时发现故障节点
-
客户端上传文件时,某DataNode挂掉怎么办?
- Pipeline中的DataNode故障,客户端会收到ACK失败通知
- 客户端向NameNode报告,NameNode标记该节点为故障
- 客户端重新建立Pipeline,继续传输剩余数据