作为后端开发,我们每天都在和 MySQL 打交道,写 SQL、用事务、做主从复制,但很少有人会去想这些最基础的问题:
- 为什么 MySQL 执行一条 UPDATE 语句,要写三个日志?一个日志不够吗?
- 数据库突然断电崩溃了,为什么重启后提交的数据不会丢失?
- 主从复制是怎么实现的?为什么从库能和主库保持数据一致?
- 为什么会出现 "主库提交成功,从库却没有这条数据" 的诡异情况?
其实这些问题的答案,都藏在 MySQL 的三大日志和两阶段提交机制里。
redo log、undo log、binlog,这三个日志是 MySQL 整个体系的基石。它们各司其职,又紧密配合,共同保证了 MySQL 的事务原子性、持久性和数据一致性。而两阶段提交,则是协调这三个日志,解决 "两个日志不一致" 致命问题的核心机制。
这篇文章,我们就从最基础的问题出发,逐个拆解每个日志的作用、特点、底层实现,再深入到两阶段提交的完整流程,最后讲清楚崩溃恢复和主从复制的底层逻辑。看完这篇,你不仅能轻松拿捏所有相关面试题,更能从底层理解 MySQL 的运行机制。
一、先搞懂:MySQL 的日志体系总览
在分别讲解每个日志之前,我们先建立一个整体认知,明确三个日志的定位和所属层级,这是避免后续概念混淆的关键:
- undo log(回滚日志) :InnoDB 引擎层专属日志,负责实现事务的原子性,用于事务回滚和 MVCC 多版本并发控制。
- redo log(重做日志) :InnoDB 引擎层专属日志,负责实现事务的持久性,用于崩溃恢复,保证提交的数据不会丢失。
- binlog(归档日志) :MySQL Server 层日志,所有存储引擎都支持,负责实现数据归档和主从复制,记录了所有修改数据的 SQL 语句。
这里必须强调:redo log 和 undo log 是 InnoDB 引擎特有的,而 binlog 是 Server 层的,和引擎无关。这是全网流传最广的误区之一,也是理解整个日志体系的基础。
二、逐个拆解:三大日志的核心原理
1. undo log:事务原子性与 MVCC 的基石
undo log 是整个事务机制的起点,没有它,事务的原子性就无从谈起。
核心作用
undo log 是逻辑日志 ,记录的是数据修改的反向操作。它的核心作用有两个:
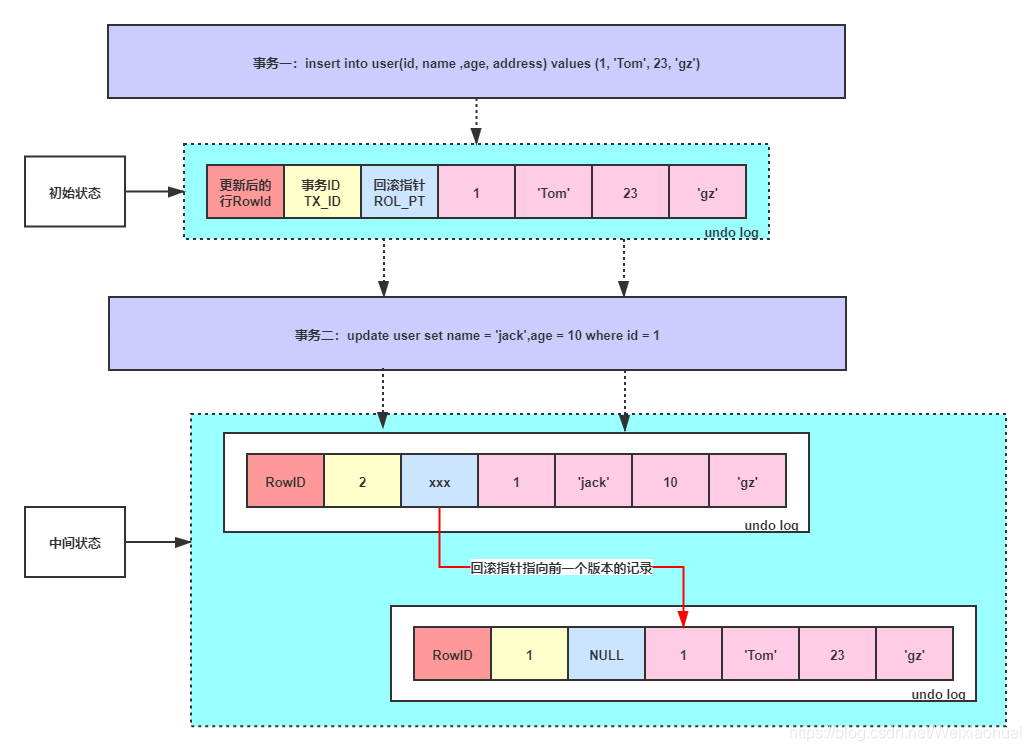
- 实现事务的原子性:当事务执行失败、主动回滚或数据库崩溃需要回滚时,执行 undo log 中的反向操作,将数据精确恢复到事务开始前的状态。
- 实现 MVCC 多版本并发控制:通过 undo log 保存数据的历史版本,让不同事务可以读取不同版本的数据,实现了读写不阻塞,大幅提升了数据库的并发性能。
工作原理
举个最简单的例子,当你执行一条转账语句:
sql
UPDATE user_account SET balance = balance - 1000 WHERE id = 1;InnoDB 会先将修改前的旧数据写入 undo log:
sql
-- 写入undo log的反向操作
UPDATE user_account SET balance = balance + 1000 WHERE id = 1;如果事务执行到一半出现异常需要回滚,InnoDB 就会执行 undo log 中的这条反向语句,将 balance 恢复为原来的值,就像这个事务从来没有执行过一样。
重要特性
- undo log 是逻辑日志,记录的是 SQL 语句级别的反向操作,不是物理页的修改,这让它可以跨页、跨表回滚。
- undo log 是追加写的,事务提交后不会立即删除,因为 MVCC 还需要用它来为其他长事务提供历史版本。
- InnoDB 有专门的 purge 线程,会在后台定期清理不再被任何事务引用的 undo log,释放磁盘空间。
2. redo log:持久性的保证,WAL 机制的核心
这是三大日志中最重要、也是最难理解的一个。要搞懂 redo log,必须先回答一个灵魂拷问:为什么需要 redo log?直接把数据刷到磁盘不行吗?
为什么需要 redo log?
我们都知道,MySQL 的数据最终是持久化在磁盘上的。但如果每次事务提交,都把修改的整页数据(InnoDB 默认页大小 16KB)刷到磁盘,会有两个致命问题:
- 随机 IO 性能极差:磁盘的随机 IO 速度只有几百次 / 秒,完全无法满足高并发业务每秒几千甚至几万次的写入需求。
- 刷盘粒度太大:哪怕只修改了 1 行 100 字节的数据,也要刷 16KB 的整页数据,浪费了大量的 IO 资源。
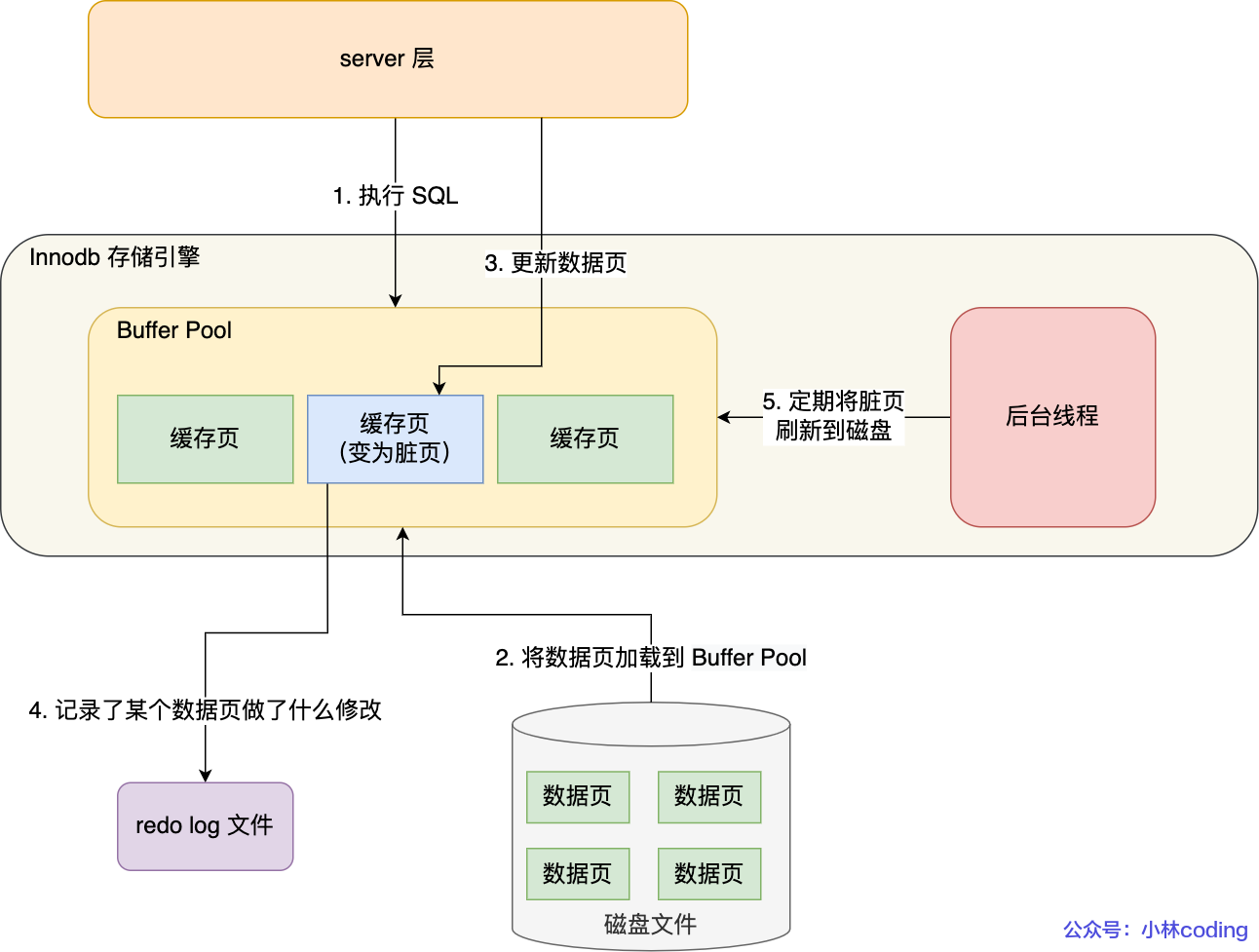
为了解决这个问题,InnoDB 引入了数据库领域最经典的优化机制 ------WAL(Write-Ahead Logging,预写日志) 。它的核心思想非常简单:先写日志,再刷磁盘。
当事务提交时,InnoDB 不会立刻把内存中修改的数据页刷到磁盘,而是先把修改操作记录到 redo log 里,然后就可以告诉客户端 "事务提交成功了"。等系统空闲的时候,再由后台线程把 redo log 里的修改异步刷到磁盘上。
这样做的好处是革命性的:
- redo log 是顺序写的,磁盘的顺序 IO 速度可以达到几万次 / 秒,比随机 IO 快几个数量级。
- redo log 记录的是 "某个数据页的某个偏移量做了什么修改",粒度极小,刷盘效率极高。
核心特性
- redo log 是物理日志,记录的是数据页的物理修改,不是 SQL 语句,这让它的恢复速度极快。
- redo log 的大小是固定的,循环写入。比如配置了 4 个 1GB 的 redo log 文件,总大小就是 4GB,写满后会从头开始循环覆盖。
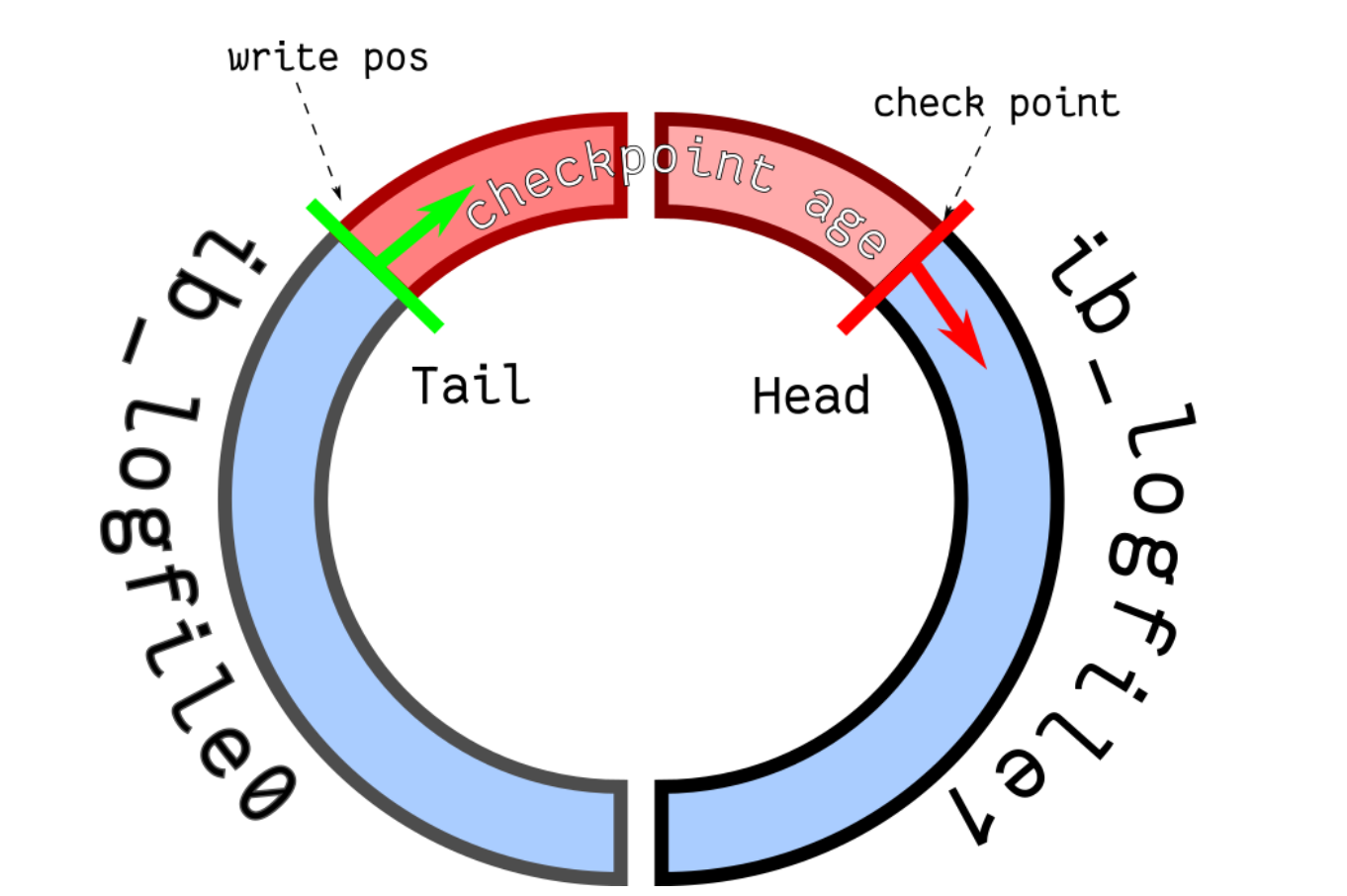
- redo log 有两个关键指针:
- write pos:当前写入的位置,不断向后移动;
- checkpoint:当前已经刷到磁盘的位置,也不断向后移动。
write pos 和 checkpoint 之间的部分,就是还没有刷到磁盘的修改。当 write pos 追上 checkpoint 时,就必须先停下来,把一部分修改刷到磁盘,腾出空间后才能继续写。
崩溃恢复
如果数据库突然断电崩溃了,内存中的数据还没来得及刷到磁盘,怎么办?
很简单,重启后只要读取 redo log,把 checkpoint 之后的所有修改重新执行一遍,就能把数据精确恢复到崩溃前的状态。这就是 redo log 保证事务持久性的核心原理。
3. binlog:数据归档与主从复制的核心
binlog 是 MySQL Server 层的日志,它的存在让 MySQL 具备了数据备份和主从复制的能力,是分布式数据库架构的基础。

核心作用
binlog 是逻辑日志,记录了所有修改数据的 SQL 语句(查询语句不会记录)。它的核心作用有两个:
- 数据归档与时间点恢复:可以用来做数据备份,当误删数据或数据库损坏时,可以用 binlog 将数据恢复到任意一个时间点。
- 主从复制:主库把 binlog 发送给从库,从库执行 binlog 里的 SQL 语句,就能和主库保持数据一致,实现读写分离和高可用。
binlog 的三种格式
MySQL 支持三种 binlog 格式,各有优缺点:
- STATEMENT 格式:记录原始的 SQL 语句。优点是日志体积小,缺点是在某些情况下会导致主从不一致(比如使用了 NOW ()、RAND ()、UUID () 等非确定性函数)。
- ROW 格式:记录每一行数据的修改前后的值。优点是绝对不会出现主从不一致,缺点是日志体积大(比如批量更新 10 万条数据,会记录 10 万条行修改)。这是 MySQL 5.7 及以后的默认格式。
- MIXED 格式:混合了 STATEMENT 和 ROW 格式,MySQL 会自动判断用哪种格式记录,兼顾了体积和一致性。
重要特性
- binlog 是追加写的,写完一个文件会自动创建下一个,不会覆盖之前的文件,适合长期归档。
- binlog 是 Server 层的日志,所有存储引擎都支持,而不仅仅是 InnoDB。
- binlog 默认是关闭的,需要在配置文件中手动开启,线上生产环境必须开启。
| 特性 | undo log | redo log | binlog |
|---|---|---|---|
| 所属层级 | InnoDB 引擎层 | InnoDB 引擎层 | MySQL Server 层 |
| 日志类型 | 逻辑日志 | 物理日志 | 逻辑日志 |
| 记录内容 | 数据修改的反向操作 | 数据页的物理修改 | 修改数据的 SQL 语句 |
| 核心作用 | 事务回滚、MVCC | 崩溃恢复、保证持久性 | 数据归档、主从复制 |
| 写入方式 | 追加写 | 循环写 | 追加写 |
| 事务提交时是否必须写 | 是 | 是 | 是 |
| 崩溃恢复时是否使用 | 是 | 是 | 否 |
三、核心问题:为什么需要两阶段提交?
现在我们有了两个独立的日志系统:引擎层的 redo log 和 Server 层的 binlog。这两个日志是完全独立的,各自写入各自的文件。如果没有协调机制,就会出现一个致命的问题:两个日志不一致。
我们来看一个真实的灾难场景:假设我们执行一条转账语句UPDATE user_account SET balance = 900 WHERE id = 1,事务提交时:
- 先写 redo log,写完后数据库突然断电崩溃了,binlog 还没来得及写。
- 数据库重启后,根据 redo log 恢复数据,把 balance 改成了 900。
- 但 binlog 里没有这条记录,主从复制时,从库不会执行这条更新,导致主库余额是 900,从库余额还是 1000,主从不一致。
- 如果之后用 binlog 恢复数据,也会丢失这条更新,数据彻底不一致。
反过来,如果先写 binlog,再写 redo log,也会出现类似的问题:
- 先写 binlog,写完后数据库崩溃了,redo log 还没来得及写。
- 数据库重启后,redo log 里没有这条记录,数据不会恢复,balance 还是 1000。
- 但 binlog 里有这条记录,主从复制时,从库会执行这条更新,把 balance 改成 900,主从不一致。
这就是 "两个日志不一致" 的致命问题,它会导致数据丢失、主从不一致、数据恢复错误等严重后果。为了解决这个问题,MySQL 引入了 **两阶段提交(2PC,Two-Phase Commit)**机制。
四、两阶段提交的完整流程
两阶段提交,顾名思义,就是把事务的提交过程分成两个独立的阶段:Prepare 阶段 和Commit 阶段。
我们还是以上面的 UPDATE 语句为例,完整的事务提交流程是这样的:
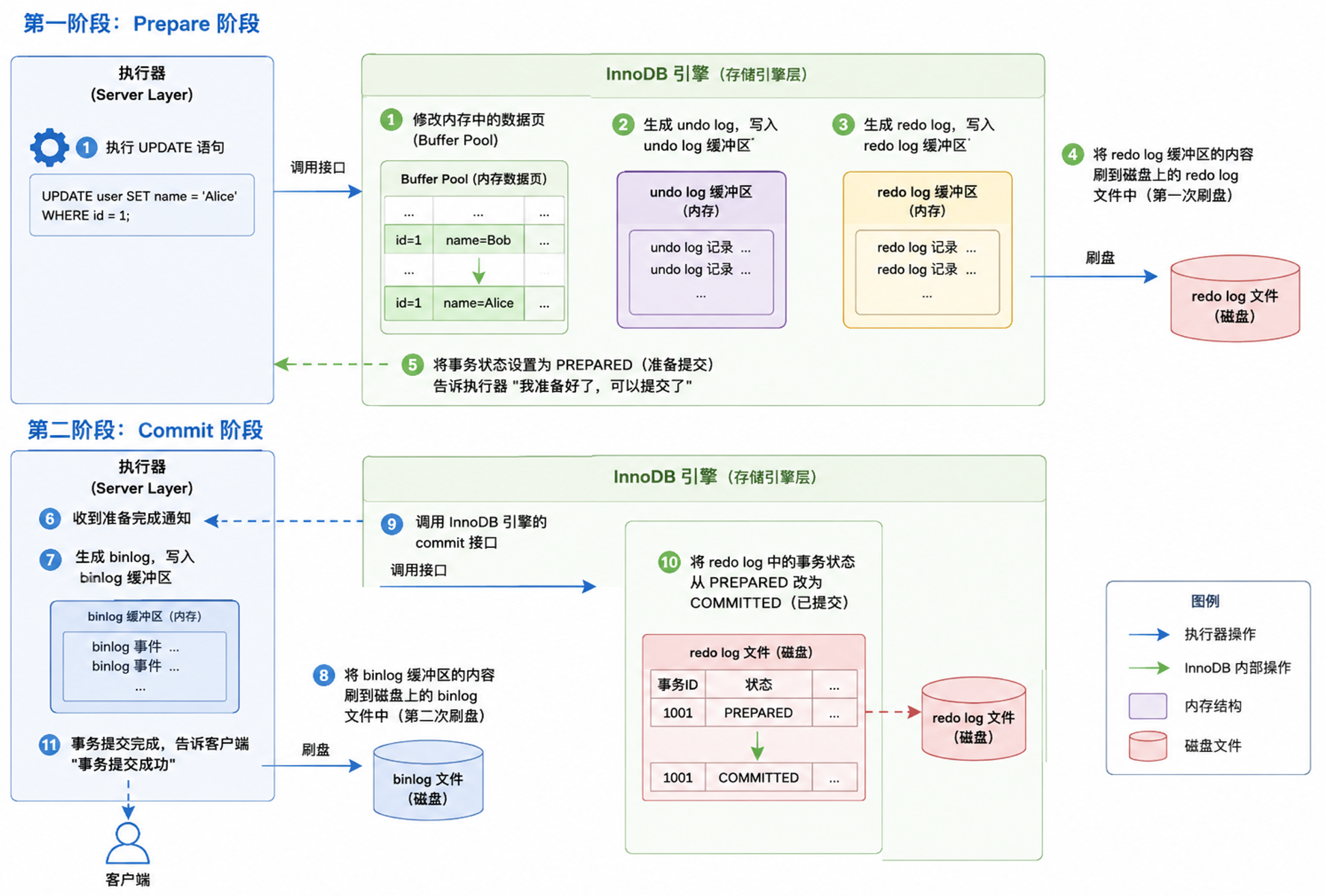
第一阶段:Prepare 阶段
- 执行器调用 InnoDB 引擎的接口,执行 UPDATE 语句,修改内存中的数据页(Buffer Pool)。
- InnoDB 生成 undo log,写入 undo log 缓冲区。
- InnoDB 生成 redo log,写入 redo log 缓冲区。
- InnoDB 将 redo log 缓冲区的内容刷到磁盘上的 redo log 文件中(这是第一次刷盘)。
- InnoDB 将事务状态设置为PREPARED(准备提交),告诉执行器 "我准备好了,可以提交了"。
第二阶段:Commit 阶段
- 执行器收到 InnoDB 的准备完成通知后,生成 binlog,写入 binlog 缓冲区。
- 执行器将 binlog 缓冲区的内容刷到磁盘上的 binlog 文件中(这是第二次刷盘)。
- 执行器调用 InnoDB 引擎的 commit 接口。
- InnoDB 将 redo log 中的事务状态从PREPARED 改为COMMITTED(已提交)。
- 事务提交完成,执行器告诉客户端 "事务提交成功"。
这里有一个非常重要的细节,也是很多人容易搞错的地方:binlog 的刷盘,发生在两个阶段之间。也就是说,只有当 redo log 已经成功刷盘,并且事务状态是 PREPARED 之后,才会写 binlog。这个顺序是保证数据一致性的关键。
五、崩溃恢复时的处理逻辑
有了两阶段提交之后,数据库崩溃了,重启后怎么处理才能保证数据一致呢?
数据库重启后,会扫描所有的 redo log,找到所有状态是PREPARED的事务。对于每个 PREPARED 的事务,会去 binlog 里找对应的记录:
- 如果 binlog 里有这条事务的完整记录:说明 binlog 已经成功刷盘了,那么就提交这个事务,把 redo log 里的状态改成 COMMITTED。
- 如果 binlog 里没有这条事务的记录:说明 binlog 还没来得及写,那么就回滚这个事务,执行 undo log 里的反向操作。
这样就完美解决了 "两个日志不一致" 的问题:
- 如果 redo log 写了,binlog 没写:回滚事务,两个日志都没有这条记录,一致。
- 如果 redo log 写了,binlog 也写了:提交事务,两个日志都有这条记录,一致。
- 如果 redo log 没写:事务根本没提交,什么都不用做。
无论数据库在哪个时间点崩溃,重启后都能保证 redo log 和 binlog 的一致性,从而保证数据的一致性。
六、深入思考:两阶段提交的性能优化
两阶段提交虽然解决了数据一致性问题,但也带来了性能问题:每个事务提交都需要两次刷盘(一次 redo log 刷盘,一次 binlog 刷盘),这是 MySQL 事务提交的性能瓶颈。
为了在性能和安全性之间做权衡,MySQL 提供了两个关键参数,可以调整刷盘策略:
1. innodb_flush_log_at_trx_commit
控制 redo log 的刷盘策略,有三个取值:
- 0:每秒刷一次盘,事务提交时不刷盘,只写到 redo log 缓冲区。性能最高,但崩溃会丢失 1 秒的数据。
- 1:每次事务提交都刷盘。最安全,性能最低,这是默认值。
- 2:每次事务提交都写到操作系统缓存,每秒刷一次盘。性能比 1 高,崩溃时如果操作系统没挂,不会丢数据;如果操作系统挂了,会丢失 1 秒的数据。
2. sync_binlog
控制 binlog 的刷盘策略,有三个取值:
- 0:由操作系统决定什么时候刷盘。性能最高,最不安全。
- 1:每次事务提交都刷盘。最安全,性能最低,这是 MySQL 5.7 及以后的默认值。
- N:每 N 个事务提交刷一次盘。性能和安全的折中。
这里必须强调:线上生产环境,这两个参数都必须设置为 1,这是保证数据不丢失的最低要求。只有在对性能要求极高、能接受少量数据丢失的场景(比如日志统计、非核心数据),才可以调整为其他值。
七、实战指南:三大日志与两阶段提交的线上最佳实践
- 必须开启 binlog:这是主从复制和数据恢复的基础,线上环境绝对不能关闭。
- binlog 格式使用 ROW 格式:这是 MySQL 5.7 及以后的默认格式,能保证主从数据绝对一致,避免 STATEMENT 格式带来的不一致问题。
- 合理设置 redo log 的大小:redo log 太小会导致频繁的 checkpoint,刷盘次数变多,性能下降;太大则会导致崩溃恢复时间变长。一般建议设置为 4-8GB,总大小不超过 16GB。
- 不要随便调整刷盘策略 :线上生产环境,
innodb_flush_log_at_trx_commit=1和sync_binlog=1是必须的,不要为了一点性能牺牲数据安全。 - 避免大事务:大事务会导致 redo log 和 binlog 体积过大,刷盘时间变长,还会导致主从延迟严重。大事务一定要拆分成小事务,分批提交。
- 定期备份 binlog:binlog 是数据恢复的唯一依据,一定要定期备份,保留足够长的时间(一般建议保留 7-30 天)。
- 监控 binlog 的增长速度:如果 binlog 增长过快,要排查是否有大量的批量更新操作,或者是否开启了不必要的 binlog 记录。
八、误区纠正 & 高频面试题解答
常见误区纠正
- 误区 :redo log 和 binlog 都是用来做崩溃恢复的。纠正:只有 redo log 是用来做崩溃恢复的。binlog 是用来做数据归档和主从复制的,不参与崩溃恢复。
- 误区 :两阶段提交是 InnoDB 引擎的特性。纠正:两阶段提交是 MySQL Server 层的机制,用来协调 Server 层的 binlog 和引擎层的 redo log,和引擎无关。
- 误区 :事务提交时,数据会立刻刷到磁盘。纠正:事务提交时,只有 redo log 和 binlog 会刷到磁盘,数据页会在后台由 InnoDB 的刷盘线程异步刷到磁盘。
- 误区 :undo log 在事务提交后就会被删除。纠正:undo log 在事务提交后不会立即删除,因为 MVCC 还需要用它来提供历史版本。purge 线程会在后台定期清理不再需要的 undo log。
高频面试题解答
-
问:MySQL 的三大日志分别是什么?各自的作用是什么?
答:三大日志是 undo log、redo log 和 binlog。undo log 用于事务回滚和 MVCC;redo log 用于崩溃恢复,保证事务的持久性;binlog 用于数据归档和主从复制。
-
问:redo log 和 binlog 有什么区别?
答:redo log 是 InnoDB 引擎层的物理日志,循环写,用于崩溃恢复;binlog 是 Server 层的逻辑日志,追加写,用于数据归档和主从复制。
-
问:为什么需要两阶段提交?
答:因为 MySQL 有两个独立的日志系统:引擎层的 redo log 和 Server 层的 binlog。如果没有两阶段提交,会出现两个日志不一致的问题,导致崩溃恢复和主从复制时数据不一致。
-
问:两阶段提交的完整流程是什么?
答:分为 Prepare 阶段和 Commit 阶段。Prepare 阶段:InnoDB 写 redo log 并刷盘,将事务状态设为 PREPARED;Commit 阶段:执行器写 binlog 并刷盘,然后调用 InnoDB 的 commit 接口,将 redo log 中的事务状态改为 COMMITTED。
-
问:数据库崩溃后,重启时怎么恢复数据?
答:扫描 redo log,找到所有 PREPARED 状态的事务。如果 binlog 里有对应的完整记录,就提交事务;如果没有,就回滚事务。
-
问:什么是 WAL 机制?有什么好处?
答:WAL 是预写日志机制,先写日志再刷磁盘。好处是将随机 IO 变成了顺序 IO,大幅提升了数据库的写入性能,同时保证了事务的持久性。
-
问:为什么 binlog 不能用来做崩溃恢复?
答:因为 binlog 是逻辑日志,记录的是 SQL 语句,没有记录数据页的物理修改,无法用来恢复内存中的数据页。而且 binlog 是追加写的,没有 checkpoint 机制,无法知道哪些修改已经刷到磁盘了。
九、总结
写到这里,相信你已经彻底搞懂了 MySQL 的三大日志和两阶段提交机制。
我们回头看整个设计,其实核心只有一个:在保证数据一致性的前提下,尽可能提升数据库的写入性能。
undo log 解决了事务原子性的问题,让事务可以安全回滚;redo log 通过 WAL 机制,将随机 IO 变成了顺序 IO,解决了写入性能和持久性的矛盾;binlog 解决了数据归档和主从复制的问题,让 MySQL 可以支撑分布式架构。而两阶段提交,则完美协调了 redo log 和 binlog 这两个独立的日志系统,解决了它们之间的数据不一致问题。
这四个机制相互配合,共同构成了 MySQL 数据一致性的基石。理解了它们,你就理解了 MySQL 事务的底层逻辑,理解了崩溃恢复和主从复制的原理,也就能从底层排查和解决线上的各种数据库问题。
技术学习的尽头,从来不是死记硬背语法和 API,而是搞懂底层的设计逻辑。当你能从 "数据一致性" 的视角看懂 MySQL 的日志设计,你就跨过了 MySQL 从进阶到精通的那道门槛。