写在开头
昨天在技术群里看到个老哥心态崩了。 说是去字节二面,面试官抛了个场景题:"我有 10 亿个用户手机号,请你设计一个系统,支持毫秒级查询手机尾号(后 4 位)。"
老哥一听,这也太简单了,张口就来:"在 MySQL 建个索引,或者用 LIKE '%1234' 呗。"
面试官当场就笑了:"10 亿数据,你用 LIKE?这是要全表扫描把数据库炸穿吗?就算你建了普通索引,B+ 树的最左前缀原则也不认后缀啊。再想想?"
老哥汗流浃背,支支吾吾半天:"那......上 ES?"
面试官摇头:"为了查个尾号,你让我搭一套 ES 集群?这硬件成本、维护成本,还有数据同步的延迟怎么算?杀鸡用牛刀?"
这道题其实是架构设计里典型的"照妖镜" 。它考的根本不是 SQL 语法,而是你对 "异构索引"、"分布式路由"以及"存储成本"的权衡。
今天咱们就扒开这 10 亿数据的外衣,看看怎么从架构层面把性能榨干。
一、 找死流:LIKE % / 暴力索引
很多初学者第一反应就是:SELECT * FROM users WHERE phone LIKE '%1234'。
结局:DBA 提刀赶来,你的工位可能保不住了。
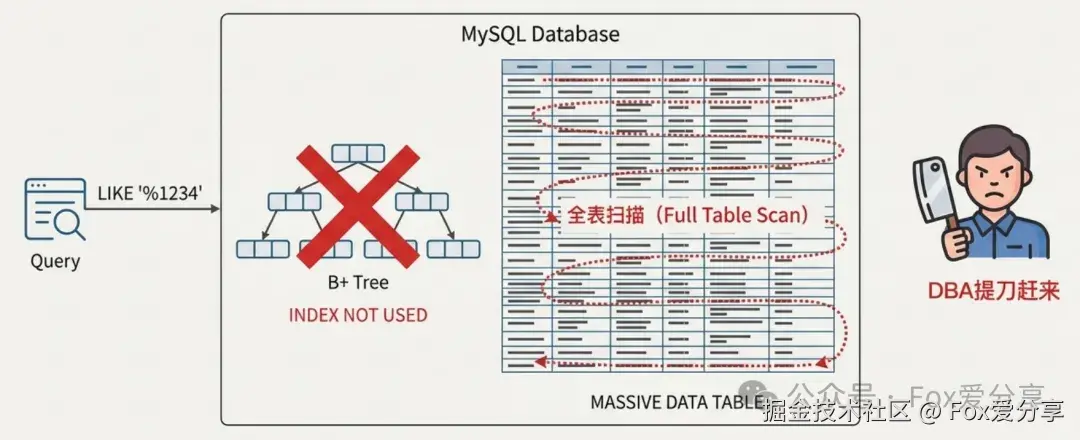
为什么? MySQL 的 B+ 树索引是严谨的"从左到右"排序。你查后缀(尾号),完全违背了 "最左前缀原则" 。这时候索引就是个摆设,数据库被迫全表扫描。 10 亿数据,哪怕全是 SSD,扫一遍也得几十分钟。毫秒级?梦里啥都有。
二、 入门流:反转大法好
稍微有点经验的兄弟会想到: "既然索引不支持从右往左查,那我就把数据倒过来存。"
骚操作 : 存手机号时,顺手存一个反转字符串。比如 13800138000 存成 00083100831。 查尾号 1234,就变成了查 reversed_phone LIKE '4321%'。
效果: 这就完美符合了"最左前缀",索引生效了,查询确实快了。
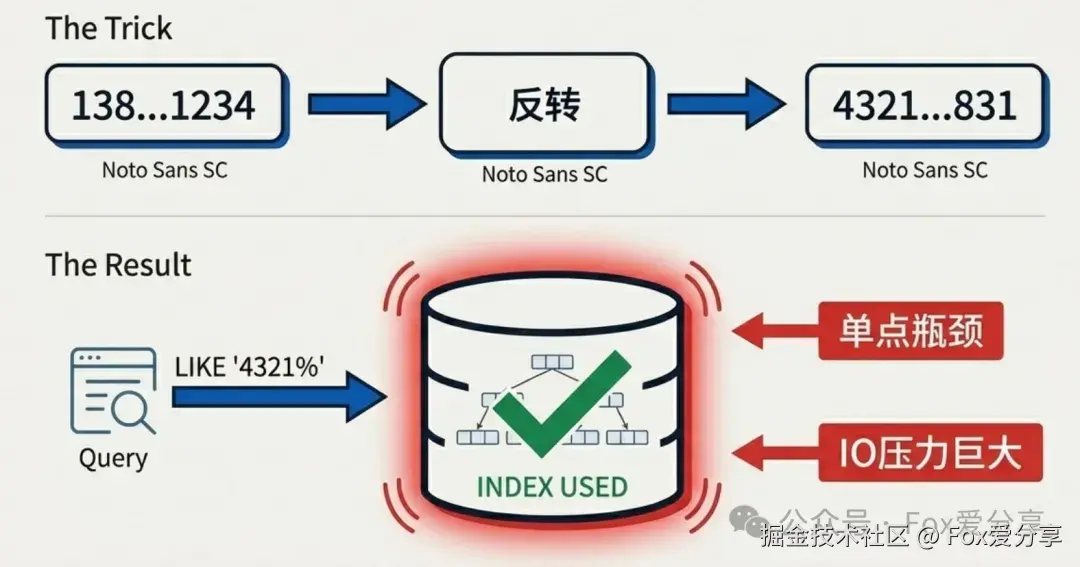
但在 10 亿数据面前,这招还是不够看: 单表 10 亿,光索引文件都得几十上百 G。B+ 树层高一变高,IO 还是瓶颈。而且,你这一台数据库能扛多少并发?
三、 进阶流:分库分表 + 异构索引(P7 必杀技)
到了这个量级,分库分表 是必须的。但这里有个巨坑。
通常我们分库分表是按 User_ID 分的。 如果你要查"尾号 1234",你根本不知道这些人在哪个库里。 这就导致了分布式系统最忌讳的 "广播查询(Scatter-Gather)" ------ 你得向所有分片库同时发起查询,然后聚合结果。这会让数据库连接池瞬间爆炸。
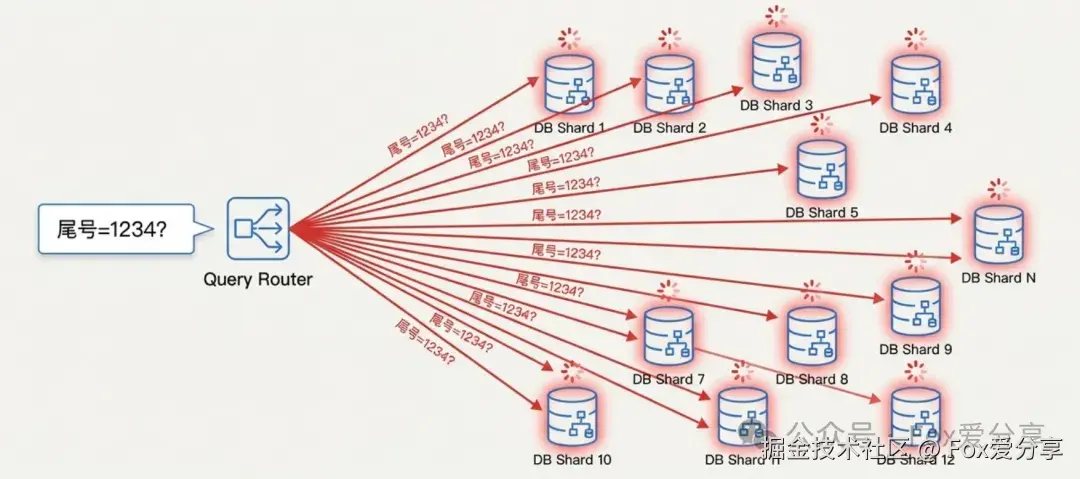
怎么破?建立"异构索引表"
别动主表(主表还是按 ID 分),我们单独建一套 映射表 ,只存 phone_suffix 和 user_id。
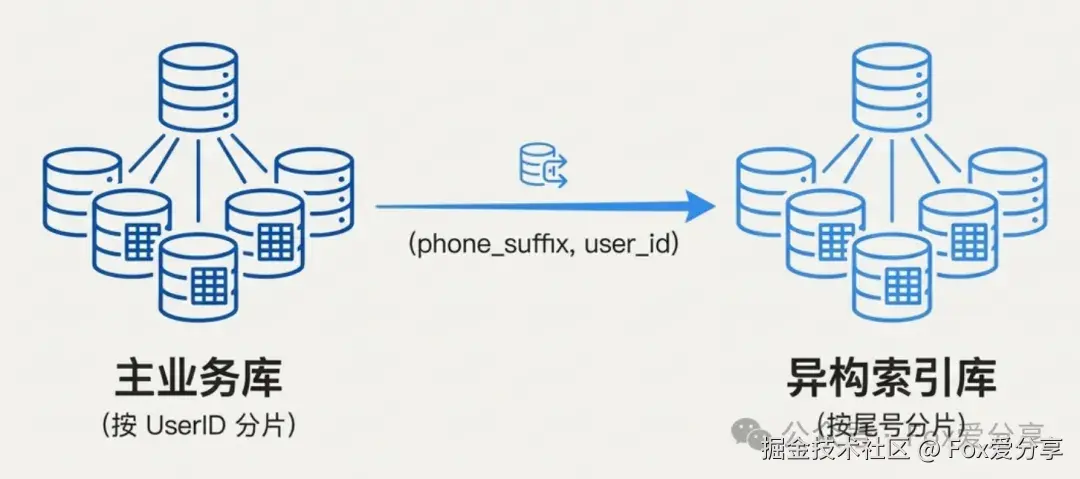
1. 怎么分片?(重点) 千万别傻乎乎地用 Hash。 手机尾号(0000-9999)本身就是数字,分布极度均匀! 建议直接切 1000 张表 。路由算法 :table_index = suffix % 1000。
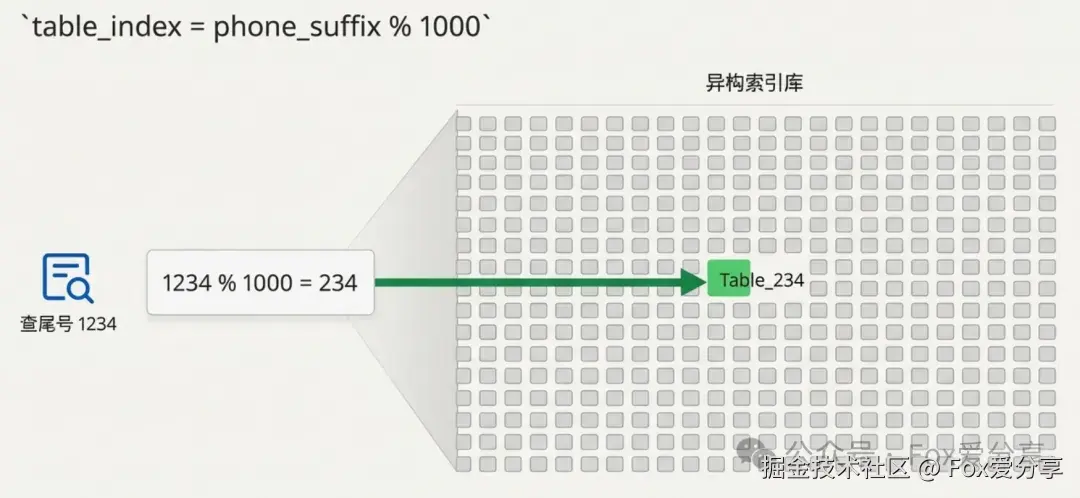
效果炸裂 : 你要查尾号 1234?1234 % 1000 = 234。 请求直接打到 第 234 号表。精准定位,根本不需要去骚扰其他 999 张表。哪怕数据量再大,单表也就 100 万行,MySQL 跑起来跟玩一样。
2. 隐藏的雷区(很多人挂在这) 面试官这时候通常会冷笑一下:"查尾号 1234,会返回多少条数据?"
咱们算笔账:10 亿用户,尾号只有 1 万种组合。10亿 / 1万 = 10万。 平均每个尾号对应 10 万个用户!
如果你代码里写个 SELECT *,一次返回 10 万条数据,你的应用服务器内存直接 OOM,带宽瞬间打满。
解法: 必须强制 分页(Limit) 。 告诉面试官:"业务上我们只展示'最新注册'的 20 个用户,SQL 强制加上 ORDER BY user_id DESC LIMIT 20。想看更多的?不支持,或者加钱上分析型数据库。"
四、 兜底流:Redis 怎么用?
这时候肯定有人说:"加个 Redis 缓存啊!"
避坑指南 : 千万别提 布隆过滤器! 尾号只有 0000-9999,这 1 万个尾号肯定都存在。布隆过滤器是防空的,这里全是满的,用了个寂寞。
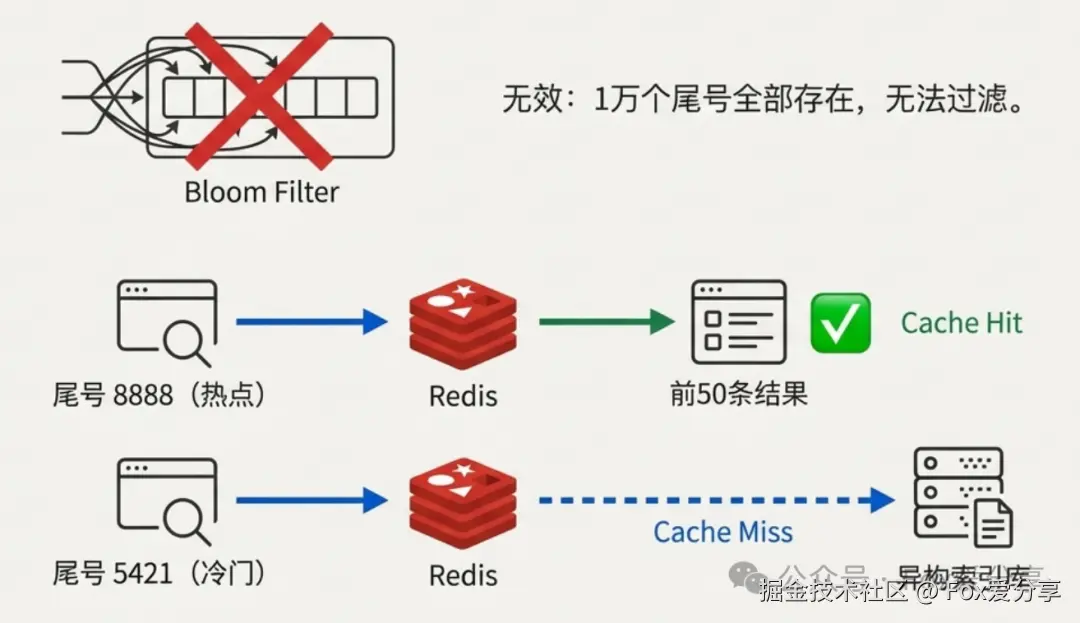
正确的 Redis 姿势 : 只缓存 "首页" 。 把尾号 8888 这种热点数据的 前 50 条 user_id 扔进 Redis(List 或 ZSet)。 99% 的用户就是看个热闹,Redis 挡住这部分流量就够了。真正想深度翻页的,让他去查异构表,反正量也不大。
总结(建议背诵)
下次面试再问这个,直接用这就话降维打击:
"面试官,这个问题的本质是 海量数据的非分片键查询。
我不会搞昂贵的 ES,而是采用 '异构索引表 + 覆盖索引' 的方案。 建立一张独立的索引表,利用手机尾号天然的离散性,直接 取模路由 到 1000 张分表中,避免了全库广播扫描。 同时,为了防止单次查询数据量过大打爆内存,我会严格限制 分页查询 。 对于热点尾号,利用 Redis 缓存 首页数据 进行兜底。 这是一套成本最低、性能最高、且完全可落地的架构方案。"
写在最后
所谓的架构设计,从来不是堆砌组件。 能用 MySQL 解决的,绝不上 ES;能用取模解决的,绝不上 Hash。把复杂留给自己,把简单留给机器,这才是高手的境界。
兄弟们,如果产品经理非要让你支持"模糊搜索任意中间 4 位"(比如 %1234%),除了提桶跑路,你还有什么招? 评论区聊聊。
觉得有用的兄弟,点个赞,收藏起来,万一下次面试就用上了呢!
关注公众号【Fox爱分享】,只讲那些书上不写的实战坑。