提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 在Linux系统中使用split和awk
- 总结
前言
日常工作中不免会遇到大文件的csv、日志文件log或者其他txt,但是用wps、文本编辑器打开发现超出行数内容显示范围,导致只显示了一部分内容,于是想着看有什么方法可以快速拆分这些大文件,一开始是想把这些文件导入到oracle数据库的,但是发现如果文件内容不太规范的话导入某些行会报错,最终实践下来发现还是把文件传到linux系统用split或者awk拆分快。
在Linux系统中使用split和awk
一、split
先确认你的文件换行符是'\r\'还是'\n'
bash
head -c 500 PB.csv | od -c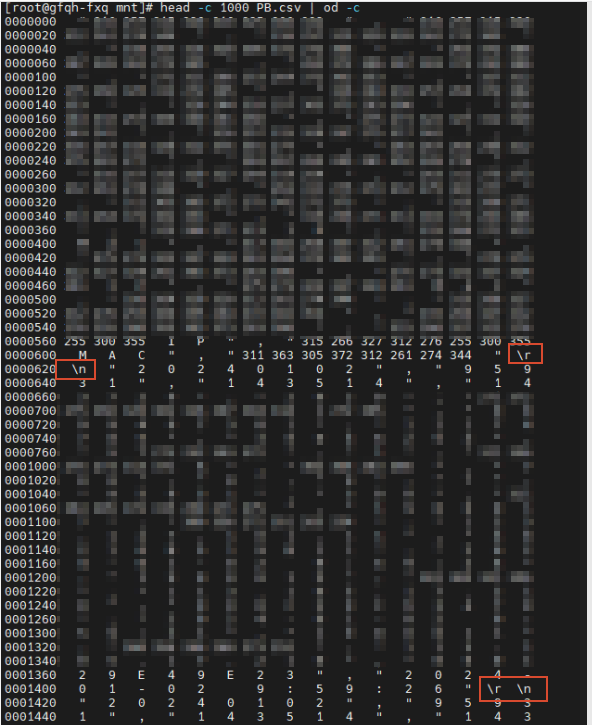
文件中有看到 \n(换行符),也有 \r(回车符)。如果没有换行符 \n,只有回车符\r,整个文件可能是一个用 \r 作为行分隔符的文件(老 Mac 风格)
split命令---文件中有看到 \n(换行符)
split命令用于将大文件分割成多个小文件,便于处理或传输。默认按行数分割,也可按大小或自定义规则。
基本语法:
bash
split [选项] 输入文件 [输出文件前缀]常用选项:
-l 行数:按指定行数分割-b 大小:按文件大小分割(如-b 10M)-d:使用数字后缀而非字母-a 长度:设置后缀长度
示例:
(1)将大文件 PB.csv 按每 1000 行拆分成多个 CSV 文件,输出文件前缀为 output_,并自动添加 .csv 后缀,但是这样直接行数拆分的话只有第一个文件有标题
示例:
bash
# 按每1000行分割文件
split -l 1000 PB.csv output_ --additional-suffix=.csv如果拆分后所有文件都要有标题:使用 split 的 --filter 选项
--filter 允许对每个输出文件执行自定义命令,我们可以将标题行与当前分片内容合并写入最终文件
bash
# 1. 提取标题行(保存为临时文件)
head -n 1 PB.csv > header.csv
# 2. 跳过标题行,按 1000 行拆分,并通过 filter 合并标题
tail -n +2 PB.csv | split -l 1000 - output_ --additional-suffix=.csv --filter='cat header.csv - > $FILE'
# 3. 清理临时文件
rm header.csvsplit命令---文件中没有换行符 \n,只有回车符\r
如果 CSV 文件中没有换行符 \n,只有回车符 \r,那么直接使用 split -l 1000 将无法正确识别行,因为 split 默认以 \n 作为行分隔符(换行符)。这时候就需要将回车符 \r转换为 \n
(1)直接拆分,只有第一个文件有标题
bash
tr '\r' '\n' < ronghang.csv | split -l 1000000 - output_ --additional-suffix=.csv(2)如果拆分后所有文件都要有标题:使用 split 的 --filter 选项
bash
# 1. 提取标题行(注意原文件以 \r 结尾)
head -n 1 PB.csv | tr '\r' '\n' > header.csv
# 2. 将整个文件的 \r 转为 \n,跳过标题行,按 1000 行拆分并添加标题
tail -n +2 PB.csv | tr '\r' '\n' | \
split -l 1000 - output_ --additional-suffix=.csv \
--filter='cat header.csv - > $FILE'
# 3. 清理临时文件
rm header.csv二、awk命令
awk是一种强大的文本处理工具,支持模式扫描和语言处理,常用于数据提取、报表生成等。
基本结构:
bash
awk '模式 {动作}' 输入文件常用功能:
- 按列处理:
$1表示第一列 - 内置变量:NR(行号)、NF(当前行列数)
- 数学运算:直接在动作中计算
- 条件判断:支持if/else等逻辑
示例:
bash
# 打印文件第一列和第三列
awk '{print $1,$3}' data.txt
# 过滤第二列大于100的行
awk '$2 > 100 {print $0}' records.txt
# 计算列总和
awk '{sum += $1} END {print sum}' numbers.txt
# 使用分隔符(默认空格)
awk -F',' '{print $2}' csv_file.csv组合使用案例,拆分大文件
将大日志文件按每月分割拆分处理:
bash
# 1. 预创建文件并写入标题(可选,防止某个月没数据导致文件不存在)
# 注意:这里假设你的年份范围是 2024-2026
head -n 1 PB.csv | while read line; do
for year in 2024 2025 2026; do
for month in 01 02 03 04 05 06 07 08 09 10 11 12; do
echo "$line" > "${year}_${month}.csv"
done
done
done
# 2. 使用 awk 处理数据
awk '
NR==1 { next } # 跳过标题行
{
# 获取第一列并清洗
raw_date = $1;
gsub(/"/, "", raw_date);
# 提取年月 (假设格式 yyyymmdd)
year = substr(raw_date, 1, 4);
month = substr(raw_date, 5, 2);
# 校验年份和月份
if (year ~ /^[0-9]{4}$/ && month ~ /^[0-9]{2}$/) {
# 直接拼接文件名:例如 2024_04.csv
file = year"_"month".csv";
print >> file;
close(file);
}
}' PB.csv按每季度拆分
bash
# 1. 提取并保存CSV文件的标题行到每个可能生成的季度文件中
head -n 1 PB.csv | while read line; do
for year in 2024 2025 2026; do # 根据你的数据年份范围修改
for q in 1 2 3 4; do
echo "$line" > "${year}_Q${q}.csv"
done
done
done
# 2. 使用awk处理所有数据行,并追加(>>)到对应的文件中
awk -F',' 'NR > 1 {
# 去除第一列的双引号和回车符
gsub(/["\r]/, "", $1);
year = substr($1, 1, 4);
month = substr($1, 5, 2);
# 确保月份是有效数字
if (month ~ /^[0-9]+$/) {
q = int((month - 1) / 3) + 1;
file = year "_Q" q ".csv";
# 关键:使用 >> 进行追加,而不是 > 覆盖
print >> file;
close(file);
}
}' PB.csv注意事项:
- split生成的文件默认以xaa/xab命名,可用
--additional-suffix指定后缀 - awk支持正则表达式和复杂逻辑,可编写多行脚本
- 处理CSV时注意用
-F指定分隔符 - 大数据量时建议先用split分割再处理
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了split、awk拆分大文件的使用,更多用法请查找相关资料学习。