
🔥草莓熊Lotso: 个人主页
❄️个人专栏: 《C++知识分享》 《Linux 入门到实践:零基础也能懂》
✨生活是默默的坚持,毅力是永久的享受!
🎬 博主简介:

文章目录
- 前言:
- [一. HTTP 服务器的整体架构](#一. HTTP 服务器的整体架构)
- [二. HTTP 请求的宏观格式](#二. HTTP 请求的宏观格式)
-
- [2.1 请求行](#2.1 请求行)
- [2.2 请求头](#2.2 请求头)
- [2.3 空行](#2.3 空行)
- [2.4 请求体](#2.4 请求体)
- [2.5 理解 HTTP 协议的四个核心问题](#2.5 理解 HTTP 协议的四个核心问题)
- [三. HTTP 响应的宏观格式](#三. HTTP 响应的宏观格式)
-
- [3.1 状态行](#3.1 状态行)
- [3.2 响应头](#3.2 响应头)
- [3.3 空行](#3.3 空行)
- [3.4 响应体](#3.4 响应体)
- [四. 实战:HTTP 协议的反序列化实现](#四. 实战:HTTP 协议的反序列化实现)
-
- [4.1 核心常量定义](#4.1 核心常量定义)
- [4.2 按行读取工具函数](#4.2 按行读取工具函数)
- [4.3 解析请求行](#4.3 解析请求行)
- [4.4 分割请求头键值对](#4.4 分割请求头键值对)
- [4.5 完整的反序列化函数](#4.5 完整的反序列化函数)
- [4.6 便捷访问接口](#4.6 便捷访问接口)
- [五. 实战:HTTP 服务器的实现(待完善)](#五. 实战:HTTP 服务器的实现(待完善))
-
- [5.1 HttpServer 类实现](#5.1 HttpServer 类实现)
- [5.2 主函数](#5.2 主函数)
- [5.3 编译运行](#5.3 编译运行)
- [六. 核心考点提炼](#六. 核心考点提炼)
- 结尾:
前言:
上一篇我们学习了 HTTP 协议的基础概念、URL 与 URI 的区别以及 URL 编码解码的原理。但光有理论还不够,要真正理解 HTTP,我们必须深入到协议的字节流层面,并且动手实现一个完整的 HTTP 服务器。本文将基于我们之前封装的多进程 TcpServer 网络框架,一步步拆解 HTTP 请求和响应的格式,实现 HTTP 协议的反序列化和序列化,最终写出一个可以被浏览器正常访问的 HTTP 服务器。所有代码采用分层设计,网络层、协议层、业务层完全解耦,符合工业级代码规范。
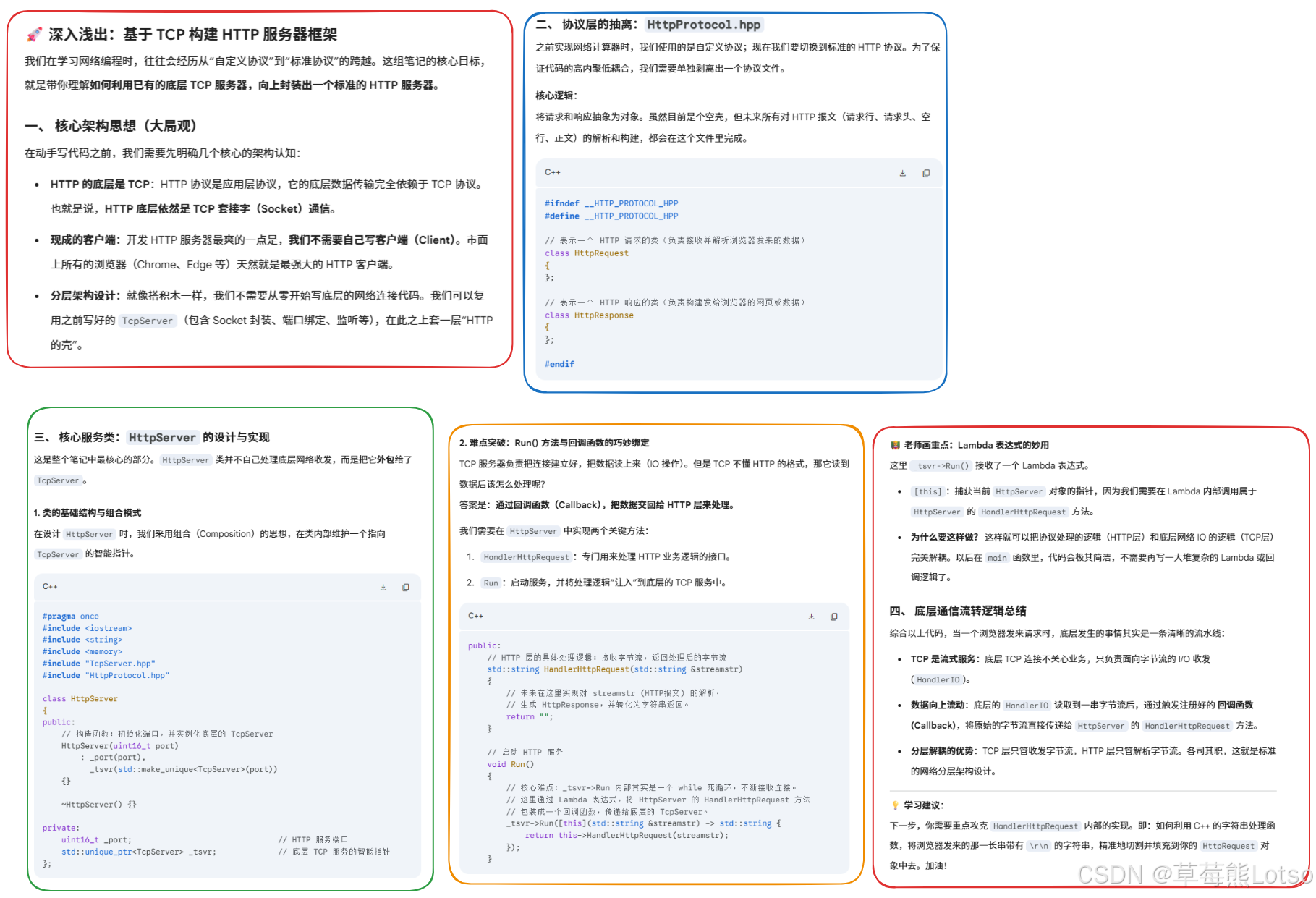
一. HTTP 服务器的整体架构
在开始写代码之前,我们先明确 HTTP 服务器的分层架构,这是写出可维护代码的关键:
bash
┌─────────────────┐
│ 业务层 │ 处理具体HTTP请求,生成业务响应
│ (HttpServer) │
├─────────────────┤
│ 协议层 │ 负责HTTP请求反序列化、响应序列化
│ (HttpProtocol) │
├─────────────────┤
│ 网络层 │ 负责TCP连接建立、数据收发、多进程处理
│ (TcpServer) │
└─────────────────┘这种分层设计的核心优势:
- 解耦:网络层只关心字节流的收发,完全不感知上层协议格式
- 可扩展:未来支持 HTTPS、WebSocket 时,只需修改或新增协议层
- 易测试:各层可以单独编译、单独测试
我们已经完成了 TcpServer 的封装,所以今天的重点就是实现协议层 和业务层。


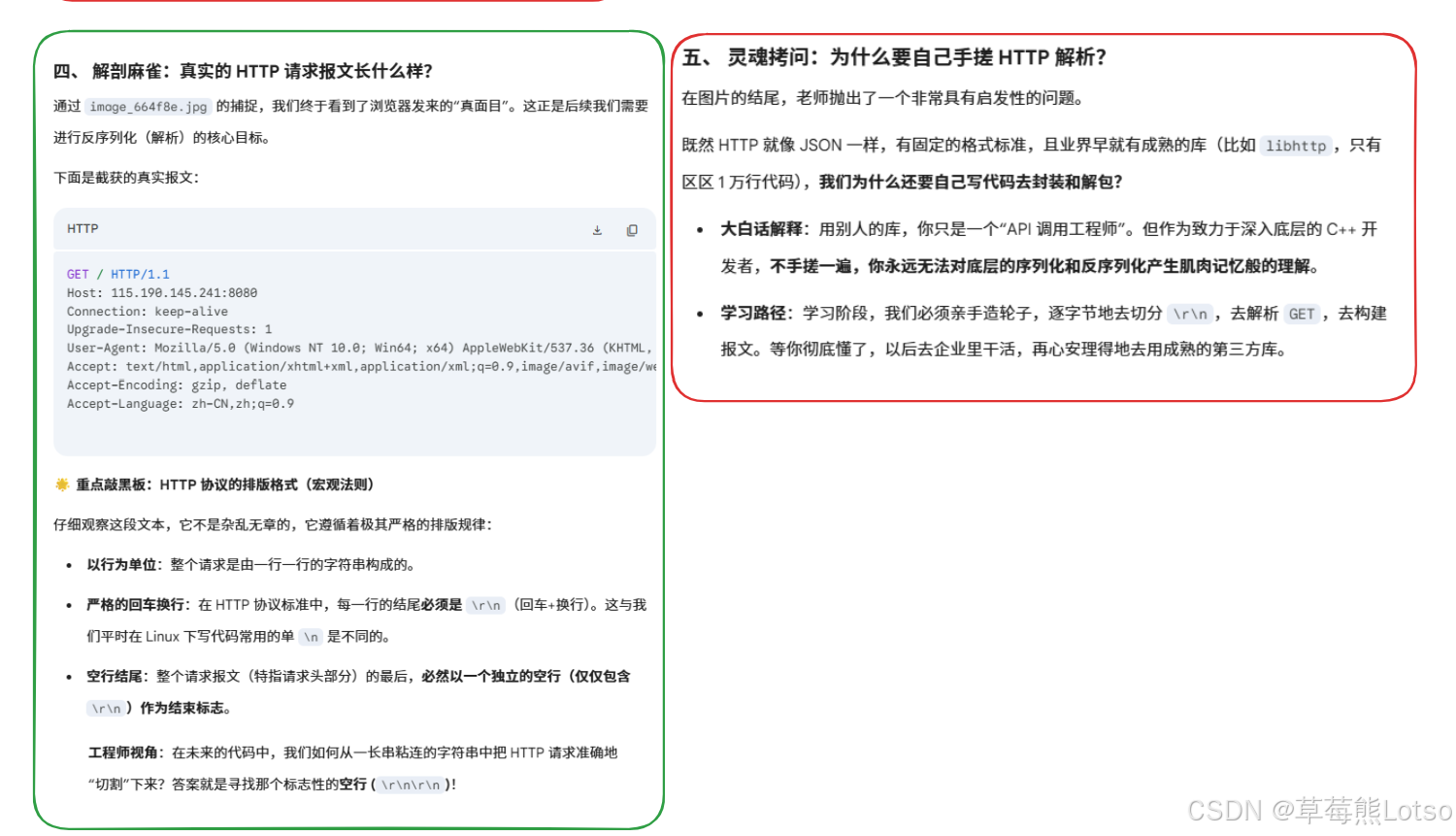

二. HTTP 请求的宏观格式
当浏览器向服务器发送请求时,它发送的本质是一个符合特定格式的连续字节流。我们先来看一个实际的 GET 请求:
bash
GET /index.html HTTP/1.1
Host: 115.190.145.241:8080
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9这个请求看起来是多行的,但所有换行都是\r\n字符。一个完整的 HTTP 请求严格由四个部分组成:
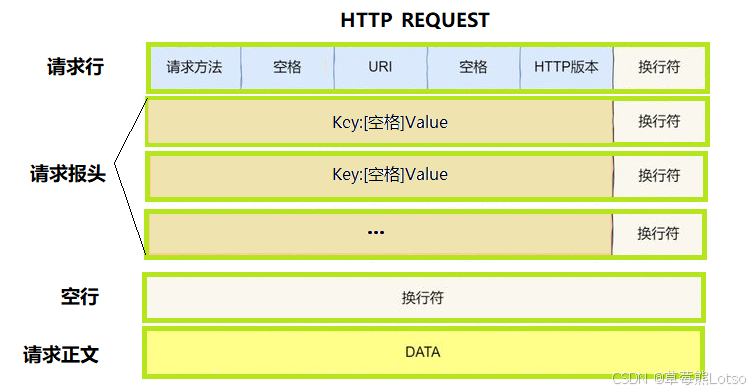
2.1 请求行
第一行是请求行,格式固定为:
bash
[请求方法] [URI] [HTTP版本]- 请求方法:表示对资源的操作类型,最常用的是 GET 和 POST
- URI :请求的资源路径,如
/index.html、/api/user/login - HTTP 版本 :客户端支持的 HTTP 版本,目前主流是
HTTP/1.1
2.2 请求头
从第二行开始到空行之前,都是请求头,格式为:
bash
[Key]: [Value]每一行是一个键值对,描述了请求的元数据,比如:
Host:请求的主机名和端口号(HTTP/1.1 必须携带)User-Agent:客户端的浏览器和操作系统信息Accept:客户端能接受的响应内容类型

2.3 空行
请求头之后必须有一个空行 (即连续的\r\n),这是 HTTP 协议中最重要的分隔符,用来明确标记请求头的结束。
2.4 请求体
空行之后的内容就是请求体,通常用于 POST 请求提交数据(如登录表单、JSON 数据)。GET 请求一般没有请求体。

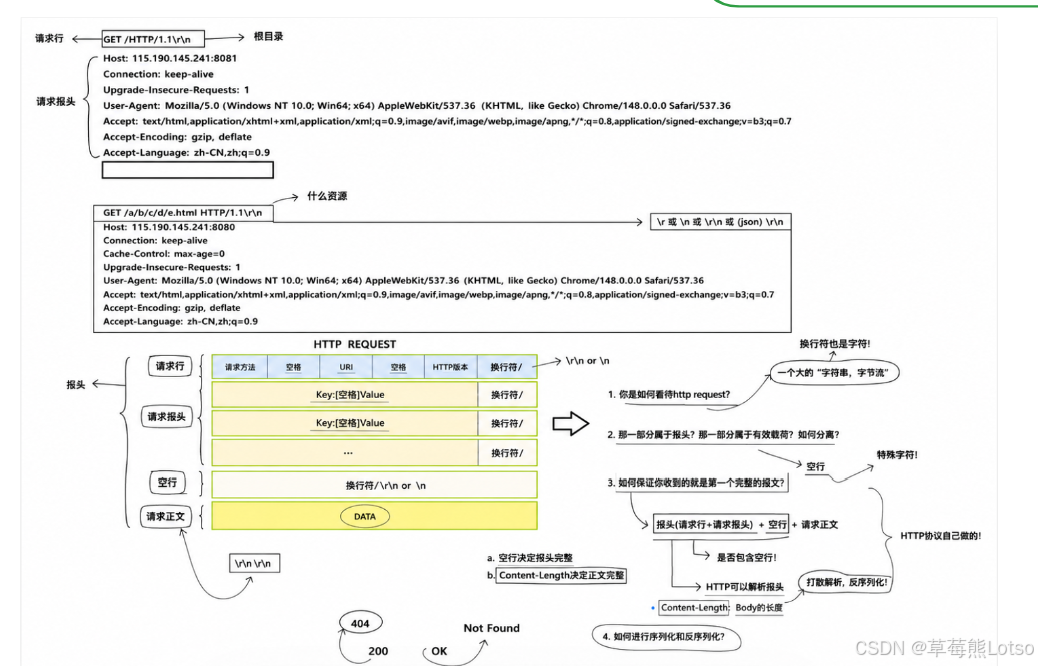
2.5 理解 HTTP 协议的四个核心问题
这四个问题是面试高频考点,也是理解所有应用层协议的通用思路:
-
如何看待 HTTP 请求?
- HTTP 请求本质上就是一个大字符串 ,或者说字节流。我们看到的多行只是因为有
\r\n换行符。
- HTTP 请求本质上就是一个大字符串 ,或者说字节流。我们看到的多行只是因为有
-
如何分离报头和有效载荷?
- 空行以上是报头(请求行 + 请求头),空行以下是有效载荷(请求体)。HTTP 协议通过特殊字符分隔的方式解决了这个问题。
-
如何保证收到的是一个完整的报文?
- 报头是否完整:判断字节流中是否包含空行
- 正文是否完整 :解析请求头中的
Content-Length字段,它精确指定了请求体的字节长度
核心结论:空行决定报头完整,Content-Length 决定正文完整
- 如何进行序列化和反序列化?
- 反序列化:将网络字节流转换为内存中的结构化数据(如结构体)
- 序列化:将内存中的结构化数据转换为网络字节流

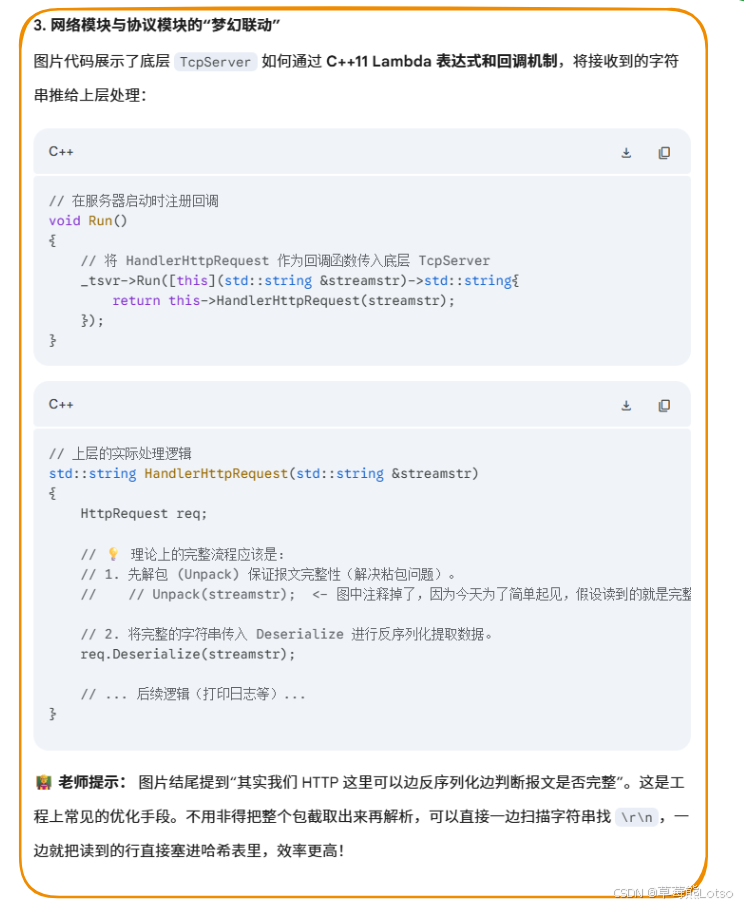
三. HTTP 响应的宏观格式
服务器收到请求后,会返回一个格式与请求非常相似的 HTTP 响应:
bash
HTTP/1.0 200 OK
Content-Length: 22
Content-Type: text/html
<h1>Hello World</h1>一个完整的 HTTP 响应同样由四个部分组成:

3.1 状态行
第一行是状态行,格式为:
bash
[HTTP版本] [状态码] [状态码描述]- HTTP 版本:服务器使用的 HTTP 版本
- 状态码:3 位数字,表示请求的处理结果
- 状态码描述:对状态码的文字说明
3.2 响应头
和请求头一样,也是键值对格式,描述了响应的元数据,比如:
Content-Length:响应体的字节长度(必须携带)Content-Type:响应体的 MIME 类型,如text/html、image/png
3.3 空行
响应头之后同样必须有一个空行,分隔响应头和响应体。
3.4 响应体
空行之后的内容就是响应体,也就是浏览器最终渲染的内容,可以是 HTML、CSS、JS、图片、视频等任何类型的数据。

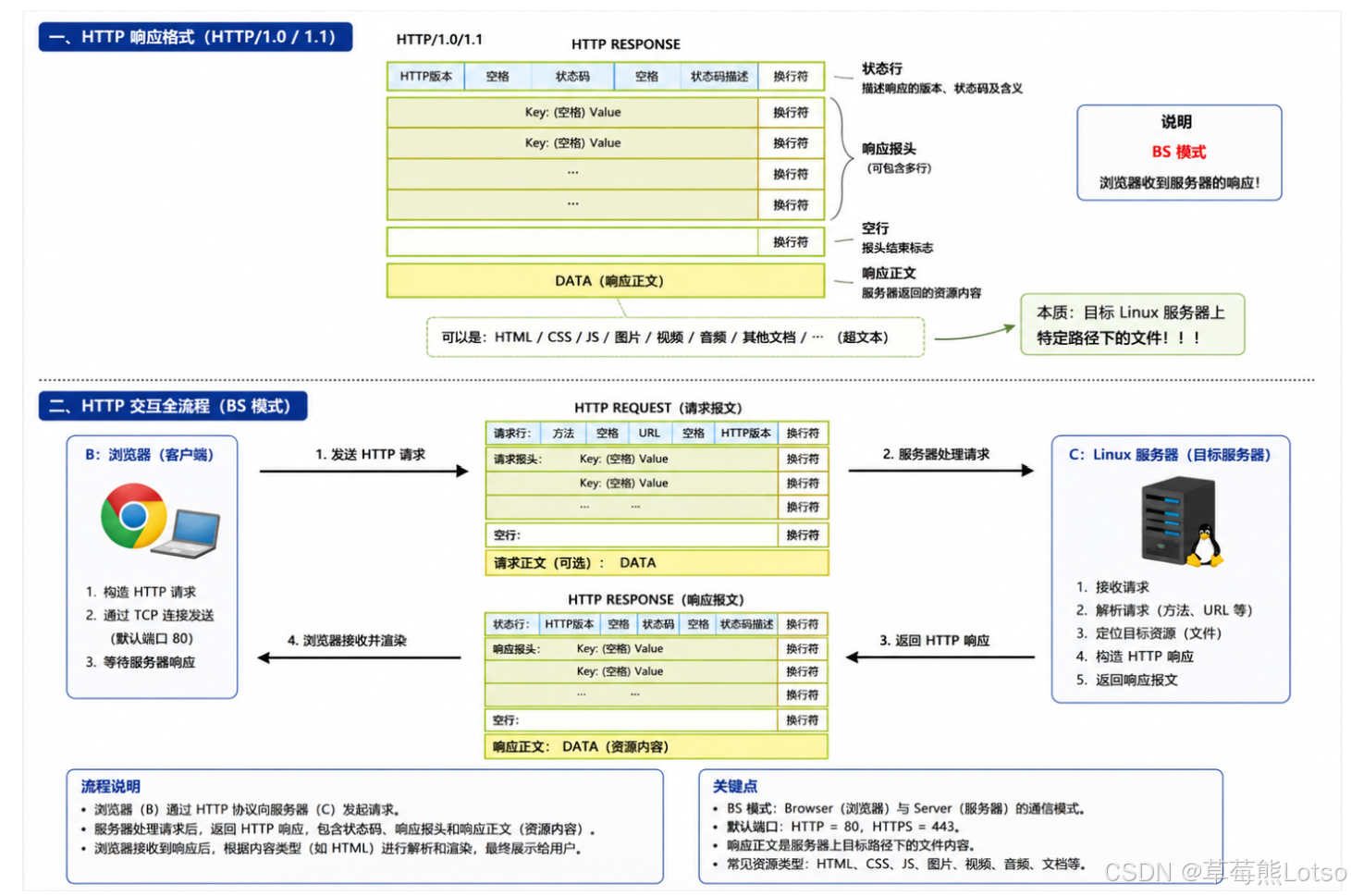
- 补充一下版本号

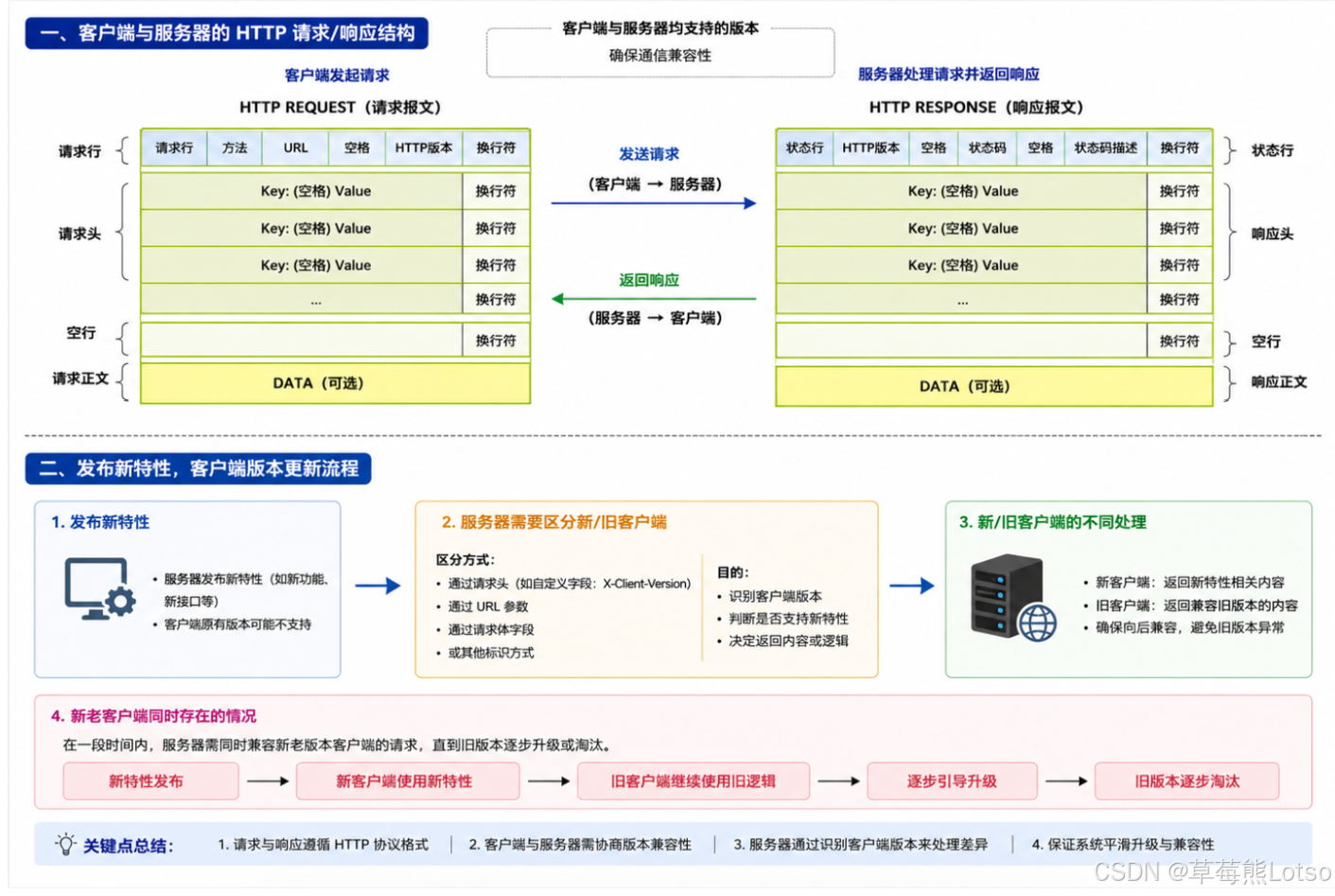
四. 实战:HTTP 协议的反序列化实现
理解了协议格式,我们现在来实现 HTTP 请求的反序列化,这是整个 HTTP 服务器中最核心的部分。所有代码都在HttpProtocol.hpp中。
4.1 核心常量定义
首先定义协议相关的全局常量:
cpp
const std::string linesep = "\r\n"; // 行分隔符
const std::string headeresp = ": "; // 请求头键值分隔符
const std::string webroot = "wwwroot"; // Web根目录,所有静态资源存放位置4.2 按行读取工具函数
HTTP 是面向行的协议,所以我们需要一个通用的按行读取函数:
cpp
int ReadOneLine(std::string &streamstr, std::string *line)
{
// 查找行分隔符的位置
auto pos = streamstr.find(linesep);
if(pos == std::string::npos)
return -1; // 没有找到完整的行
// 提取当前行
*line = streamstr.substr(0, pos);
// 从原始字节流中删除已经处理的行和分隔符
streamstr.erase(0, pos + linesep.size());
// 返回行的长度:0表示读到空行,>0表示有效行
return line->size();
}代码解读:
- 参数
streamstr是引用传递,因为我们需要在读取后修改原始字节流 - 这种设计天然解决了 TCP 的粘包问题:不完整的行会留在缓冲区中,下次收到数据后继续处理
- 返回值的设计非常巧妙,用一个整数同时表示读取结果和行的类型
4.3 解析请求行
读取到第一行后,我们需要解析出请求方法、URI 和 HTTP 版本:
cpp
void ParseLine(std::string &request_line)
{
// 使用stringstream自动按空格分割字符串
std::stringstream ss(request_line);
ss >> _method >> _uri >> _http_version;
// 拼接Web根目录,得到资源在服务器上的实际路径
_path = webroot + _uri;
}
4.4 分割请求头键值对
请求头的每一行都是Key: Value格式,我们需要一个分割函数:
cpp
void SplitString(std::string &line, std::string *key, std::string *value, const std::string sep = headeresp)
{
auto pos = line.find(sep);
if(pos == std::string::npos)
return;
*key = line.substr(0, pos);
// 跳过分隔符,注意分隔符是": "(冒号加空格)
*value = line.substr(pos + sep.size());
}4.5 完整的反序列化函数
现在我们可以实现完整的反序列化逻辑了:
cpp
void Deserialize(std::string &streamstr)
{
// 1. 读取并解析请求行
std::string request_line;
int n = ReadOneLine(streamstr, &request_line);
ParseLine(request_line);
// 2. 循环读取并解析请求头
do
{
std::string line;
n = ReadOneLine(streamstr, &line);
if(n > 0)
{
std::string key, value;
SplitString(line, &key, &value);
if(!key.empty() && !value.empty())
{
_request_headerkv[key] = value;
}
}
else if(n == 0)
{
// 读到空行,请求头解析结束
_blankline = "\r\n";
break;
}
else
{
LOG(LogLevel::DEBUG) << "ReadOneLine error";
break;
}
}while (n > 0);
// 3. 读取请求体(如果有)
if(_request_headerkv.count("Content-Length"))
{
int len = std::stoi(_request_headerkv["Content-Length"]);
// 前面已经删除了所有请求头,剩下的就是请求体
_body = streamstr.substr(0, len);
}
// 打印调试信息
PrintDebug();
}代码解读:
- 整个反序列化过程就是按行读取、逐行解析的过程
- 读到空行时,立即停止解析请求头
- 如果存在
Content-Length字段,说明有请求体,我们从剩余字节流中读取指定长度的内容
4.6 便捷访问接口
为了方便业务层访问请求数据,我们重载了[]运算符:
cpp
std::string operator[](const std::string& key) const
{
if(key == "method") return _method;
else if(key == "uri") return _uri;
else if(key == "httpversion") return _http_version;
else if(key == "body") return _body;
else if(key == "path") return _path;
else
{
auto iter = _request_headerkv.find(key);
if(iter != _request_headerkv.end())
return iter->second;
}
return "";
}这样,业务层就可以像访问数组一样方便地获取请求数据:
cpp
std::string method = req["method"];
std::string path = req["path"];
std::string ua = req["User-Agent"];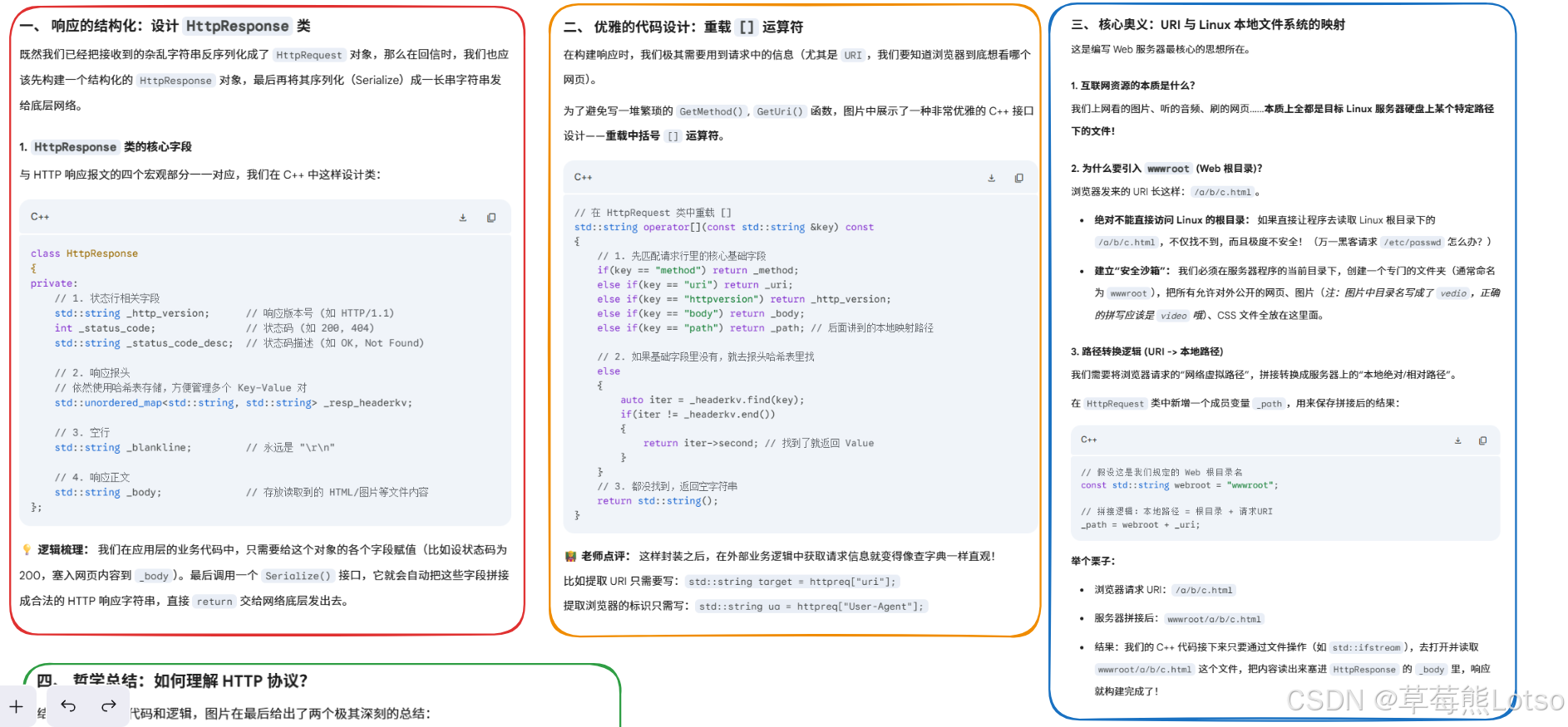

五. 实战:HTTP 服务器的实现(待完善)
有了协议层的支持,我们的 HTTP 服务器就变得异常简单了。
5.1 HttpServer 类实现
cpp
class HttpServer
{
public:
HttpServer(uint16_t port)
: _port(port)
, _tsvr(std::make_unique<TcpServer>(port))
{}
// HTTP请求处理回调函数
std::string HandlerHttpRequest(std::string &streamstr)
{
// 1. 反序列化HTTP请求
HttpRequest httpreq;
httpreq.Deserialize(streamstr);
// 2. 构建HTTP响应
std::string status_line = "HTTP/1.0 200 OK\r\n";
std::string body = "<h1>Hello World! This is my HTTP server.</h1>";
std::string content_length = "Content-Length: " + std::to_string(body.size()) + "\r\n";
std::string blank_line = "\r\n";
// 3. 序列化响应并返回
return status_line + content_length + blank_line + body;
}
// 启动服务器
void Run()
{
_tsvr->Run([this](std::string &streamstr){
return this->HandlerHttpRequest(streamstr);
});
}
~HttpServer() = default;
private:
uint16_t _port;
std::unique_ptr<TcpServer> _tsvr;
};代码解读:
HttpServer内部持有一个TcpServer对象,负责底层网络通信HandlerHttpRequest是核心回调函数,TcpServer 收到完整数据后会调用这个函数- 我们先反序列化请求,然后构建一个简单的 HTML 响应,返回给客户端
5.2 主函数
cpp
int main(int argc, char *argv[])
{
if (argc != 2)
{
std::cout << "Usage: " << argv[0] << " <port>" << std::endl;
exit(1);
}
// 启用控制台日志输出
ENABLE_CONSOLE_LOG_STRATEGY();
uint16_t port = std::stoi(argv[1]);
auto hsvr = std::make_unique<HttpServer>(port);
hsvr->Run();
return 0;
}5.3 编译运行
现在我们可以编译并运行我们的 HTTP 服务器了:
cpp
# 编译(需要C++17支持)
g++ -o httpserver Main.cpp -std=c++17 -lpthread
# 运行
./httpserver 8080然后在浏览器中输入http://你的服务器IP:8080,就能看到我们返回的 "Hello World" 页面了。同时,服务器终端会打印出完整的 HTTP 请求内容,包括请求行、所有请求头和空行。
六. 核心考点提炼
本文我们深入学习了 HTTP 协议的核心格式,并实现了一个模块化的 HTTP 服务器。以下是面试中最常考的核心知识点:
- HTTP 请求 / 响应的标准格式:必须能准确说出四个组成部分
- 报文完整性判断:空行决定报头完整,Content-Length 决定正文完整
- TCP 粘包问题的解决:HTTP 协议通过按行读取和 Content-Length 字段天然解决了粘包问题
- 序列化与反序列化:应用层协议的核心就是实现字节流和结构化数据的相互转换常见状态码:200 (成功)、404 (资源不存在)、403 (禁止访问)、500 (服务器内部错误)
- Web 根目录的作用:所有静态资源都放在 Web 根目录下,防止目录遍历攻击
结尾:
html
🍓 我是草莓熊 Lotso!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!结语:到这里,我们已经实现了一个最基础但功能完整的 HTTP 服务器,它可以接收浏览器的请求并返回响应。但这只是一个开始,一个工业级的 HTTP 服务器还需要支持 GET/POST 方法、静态资源自动返回、404 错误页面、Cookie 和 Session 等功能。下一篇我们将继续完善这个 HTTP 服务器,实现静态资源的自动加载,让它能够真正地作为一个 Web 服务器使用。如果你觉得本文对你有帮助,欢迎点赞、收藏、关注!有任何问题也可以在评论区留言交流。
✨把这些内容吃透超牛的!放松下吧✨ ʕ˘ᴥ˘ʔ づきらど
