JVM内存区域的划分
一个运行起来的java进程,就是一个jvm虚拟机(会申请一大块内存)
这些内存,会划分成不同的内存区域 ;
方法区(1.7之前) / 元数据区(1.8开始)
存储 类对象 , .class文件加载到内存后,就是类对象
堆
存储 代码中 new 的对象 , (堆占据最大空间)
虚拟机栈栈(重点)
存储 代码执行中, 方法之间的调用关系 (用栈把哪个方法调用哪个方法的关系,维护起来)
(和数据结构里的栈是 类似的 , 栈里 每个元素 , 称为 "栈帧" ,每个栈帧 代表一个 方法调用, 栈帧里包含: 方法的入口, 方法返回的位置, 方法的形参,方法的返回值, 局部变量...)
程序计数器
只占一个较小的空间, 里面只是 存放一个 "地址", 地址表示 下一个要执行的指令, 在内存的什么地方 ;(这些指令 都是在 方法区里, 每个方法里的指令都是 二进制的形式 存在对应的 类对象里)
刚开始调用方法时,程序计数器就在方法的入口地址,每执行一条指令,程序计数器就自动更新,指向下一条指令
虚拟机栈和程序计数器, 每个线程都会有一份,例如: jvm里有10个线程,那么就会有10个虚拟机栈和10个程序计数器(每个线程各自有一个) , 而堆和元数据区是 只有一份;
在java里, 有这种说法, 每个线程有自己私有的 栈空间 ;(这也算是对的,只局限java)
本地方法栈(不重点)
native修饰的方法,C++写的方法 ;
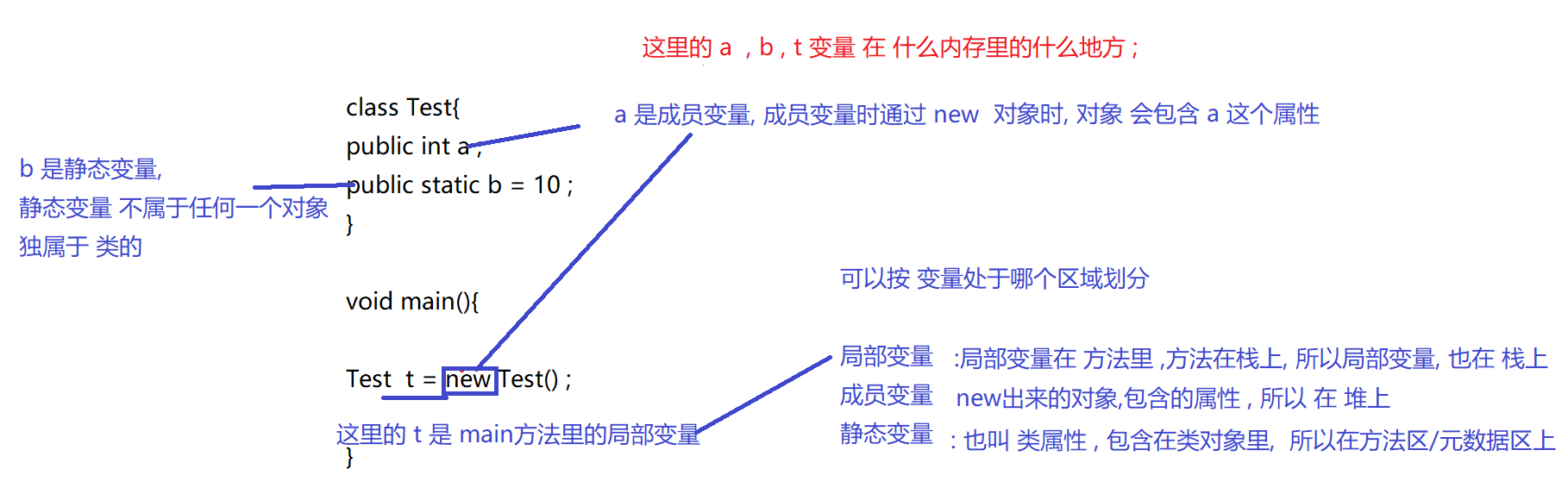
常见面试题:
给一个代码, 问 代码里的某个变量, 处于 内存里的哪个区域;
注意 : 变量处于哪个 区域 , 和 变量 是否是引用类型还是基本类型 没有关系
JVM类加载
1.类加载的基本流程
java代码会被编译成
类加载的过程,主要分为 5 个步骤: (也有3个步骤的说法,不过是5个中的3个合并成一个)
1.加载: 找到.class文件, 打开文件,读取文件内容
在代码里,一般会有某个类的 "全限定类名" ,例如: java.lang.String ,jvm会根据这个类名在指定的目录范围内 查找; 所以这里的加载, 主要做的是 找到,打开,读取 ;
2.验证: .class 文件是 一个二进制格式的文件(某个字节都有特殊的含义的),就需要验证当前读到的这个格式是否符合要求 ;
虽然.class是一个二进制文件,但里面的内容必须是严格按照格式来的,开头的几个字节是什么,中间的是什么,....这里验证,如果格式不对,就会报错;
在java官方文档里


3. 准备: 给类对象分配空间(最终目标是 构造出 类对象)
分配多少空间,就按照上面验证出来,大概需要多少空间 ; 这里只是分配内存空间,还没有初始化,此时 这里分配出来的内存空间的 数值 都是全 0 ; 所以这时候 就打印 static 的属性 得到的值 就是 : 0
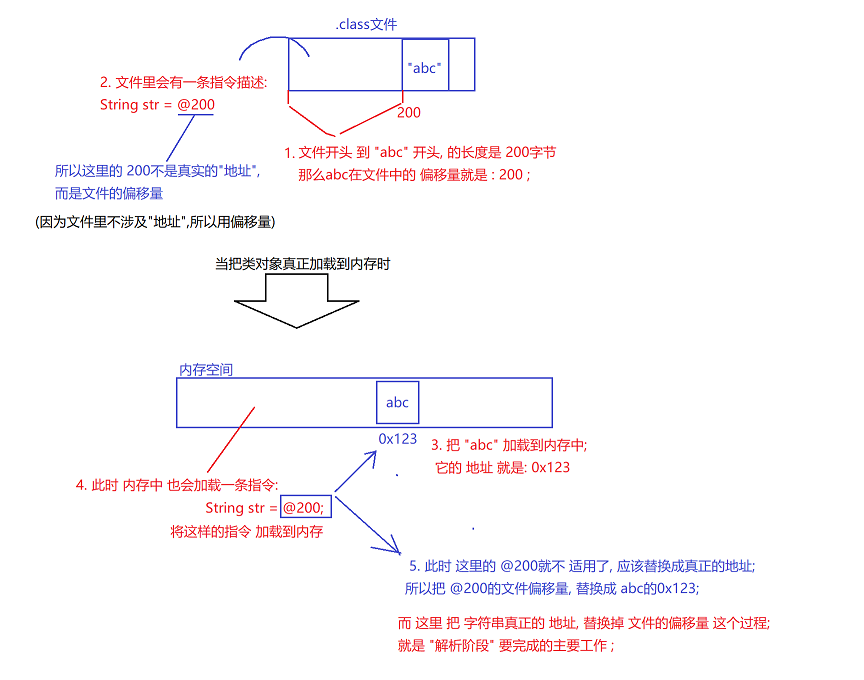
4. 解析 : 针对类对象中包含的 字符串常量进行处理 . 进行一些初始化操作 ;
java代码中用到的 "字符串常量" , 在编译后,也会进入到 .class 文件里 ;
例如: final String str = "abc" ; 这个 "abc"也会在 .class 文件里 ; 并且 str 这个引用也会在.class文件的二进制指令里 创建 ;
而这里主要就是 文件里没有"地址" 用 "偏移量"代替了 ;
"abc" 这个字符串常量, 在.class文件里的 某个特定地方 ; String str="abc" ; str这个引用,要把 "abc"的地址赋给str , 但是 此时 是在 "文件" 里 ,不涉及内存地址,没有"地址" 来赋给 str , 所以 在.class文件里, str 的初始化语句, 会设置成 "文件的偏移量" ; 可以通过 "文件偏移量" ,就能找到 字符串 "abc" 的位置 ; 例如 : str = @200 ; 字符串 "abc" 在文件 200的位置; 当这个类 被加载到内存的时候 , 再把这里的 偏移量 替换成 真正的内存地址
5.初始化 : 针对类对象进行初始化
把类对象的各项属性都设置好(就按"验证阶段"的.class文件格式 来设置好 ) ,
需要初始化好 static成员
2. 双亲委派模型
双亲委派模型 属于 "类加载" 中 第一个步骤 " 加载" 过程中的一个环节 ;
负责根据 "全限定类名" ,找到 .class文件 ; (这个过程就是 双亲委派模型)
类加载器(jvm中的一个模块, 这个模块就负责类加载的操作)
JVM中内置了 3个 类加载器 ;
1. BootStrap ClassLoader ; (爷) : 负责 jdk的 标准库 的目录
2. Extension ClassLoader ; (父) : 负责 jdk的 扩展库 的目录(扩展库是在标准库之外,做出的扩展)
3. Application ClassLoader ; (子) : 负责 当前项目的 和 第三方库目录 ;
这三个 类加载器,都有各自的 父子关系 ; 这里的父子关系 , 不是通过 extend 继承的, 而是 这些 ClassLoader 有一个 "parent"这样的属性 , 指向一个父 "类加载器" ;
(只有一个"父" , 是这里的"双亲" 属于翻译问题, 英文是:parent :双亲之一, 不好听 , 叫 "父亲委派模型" 也合适)
类加载的过程(找.class文件的过程)
1. 给定一个 全限定类名 ,例如: java.lang.String 这样的 ; 2. 从 Application ClassLoader 作为入口,开始查找的逻辑(负责当前项目和第三方库的目录) 3. Application ClassLoader 不会立刻去找,而是先将查找的任务,交给自己的父亲Extension ClassLoader ; 4. Extension ClassLoader 也不会立刻查找自己负责的目录 (负责 JDK的一些扩展库) , 而是交给 自己的父亲 BootStrap ClassLoader ; 5. BootStrap ClassLoader 也不想立即扫描自己负责的目录(负责 jdk的标准库目录) 向继续将任务交给自己的父亲,发现自己没有父亲! BootStrap ClassLoader 就自己负责扫描 : java.lang.String 在标准库里,就可以找到对应的.class文件, 就可以打开文件,读取文件...(做进一步的验证解析等过程...); 查找过程结束 如果没有找到,就把任务交给孩子来执行 ; 6. Extension ClassLoader 会负责扫描 扩展库目录,如果找到了,就继续类加载后面的操作,查找结束 ; 没有找到就 吧任务交给孩子来执行 ; 7. Application ClassLoader 会负责扫描 当前项目和第三方库的目录,找到了,就执行后面类加载的操作 ; 没有找到 ,就抛出一个 ClassNotFoundException 异常 ;
这样的过程就算

双亲委派模型 的目的
这样一套流程, 为了确保
如果自己代码写了一个 java.lang.String的类, 在jvm加载的时候,是加载的 标准库的 类, 而不会加载到 自己写的类 ;
(当然自己写的加载器,就可以打破这里的双亲委派模型, Tomcat里 也没有用这里的双亲委派模型)
JVM 中的垃圾回收机制
垃圾回收机制 (GC)
c/c++里new的对象,需要free或delete及时回收资源,但总有万一;
而 java 就给出了 垃圾回收机制GC , 让 jvm 自行判断,某个内存,是否就不在使用了.如果这个内存后面确实不在用来,jvm就会自动把这个内存回收掉 , 就不必程序员手动回收 ;
GC 的缺陷
1.系统的开销: 需要有一个或一些:特定的线程,不停的扫描内存中的所有对象,看是否能够回收(需要额外内存+CPU资源)
2.效率问题: 扫描线程不一定能 及时的 回收释放内存 (扫描有一定周期); 一旦同一时间有大量对象需要回收,对GC的负担比较大 , 甚至引起这个程序卡顿(STW问题:Stop The World)
GC 回收的对象
GC回收的目标,其实是内存中的对象, 对于java, 就是 new出来的对象 ;
栈里的局部变量,是跟着 栈帧的 生命周期走的 ;(方法执行完,销毁栈帧,释放内存)
静态变量,生命周期是整个程序,所以无需被释放 ;
真正需要GC释放的 => 堆上的 对象 ;
垃圾回收(GC)
垃圾:不在使用的对象 ;
GC 主要分 两个大步骤 : 怎么找到垃圾,怎么判断是否是垃圾 ,GC里有两个主流方案 ;
找到垃圾 (注意: 分为 java用的机制 和 Python用的机制)
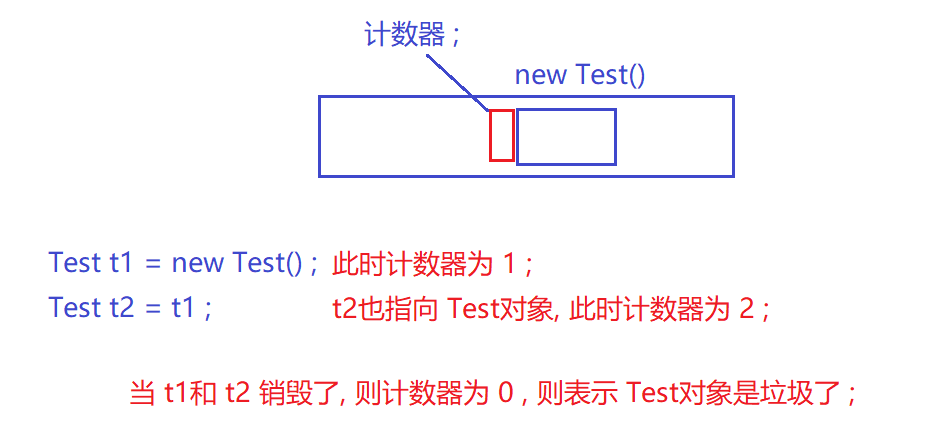
1.引用计数 (是: Python , PHP用的)
在new出来的对象,单独安排一块空间,来保存计数器; 每有一个引用指向这个对象,则计数器+1 ; 当没有引用指向这个对象了, 则计数器为 0 了, 表示 这个对象是 垃圾 ;
引用计数的缺点?(为什么java不用)
1.比较浪费内存 ;
计数器,本身要用的字节就不小,起码也要2个字节;
但如果 对象本身很小 , 这个计数器占据的空间比例就很大了 ; 有非常多的对象,但这些对象本身都比较小, 这时计数器占据的空间, 非常离谱了 ;
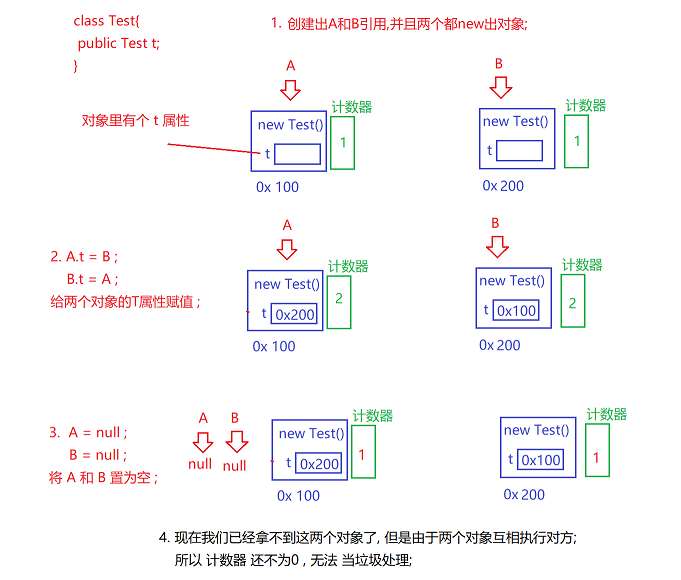
2. 存在 "循环引用"的问题 ;
类似于 "死锁" 问题一样 , A 的属性指向 B 指向的对象, B 的属性指向A指向的对象, 然后A,B 置为null, 但此时两个对象仍然不会被销毁, 因为两个对象互相执行了对方, 但我们也拿不到两个对象; 要拿到1对象, 就要通过2对象, 要想拿到2对象,就要通过1对象 ;
2. 可达性分析 (java用的)
可达性分析 : 本质是 时间 换空间的手段 ;
以 一个/一组线程, 周期性 扫描 代码里的
可达性分析 出发点有很多: 所有的局部变量,常量池中引用的对象,方法区中的静态引用类型的引用变量 ;
这里的遍历,看访问的某个对象,有多少个引用类型的成员 ;
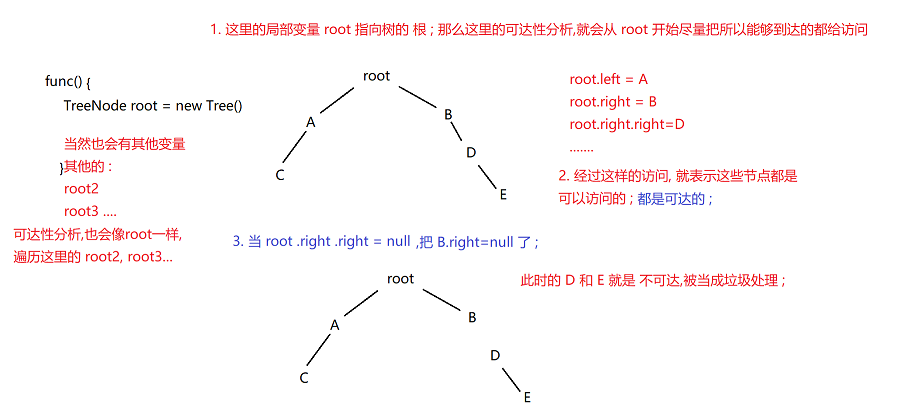
缺点:
可达性分析时 周期性的, 比较消耗系统资源,开销比较大 ;
释放垃圾 (如何回收垃圾)
回收释放垃圾, 主要有三种基本思路 ;
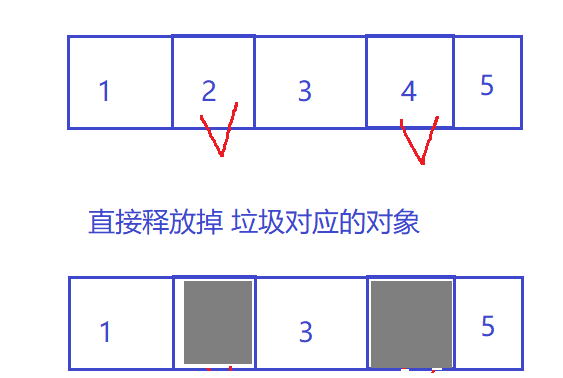
1.标记清除 (比较一般的方案)
直接将垃圾对应的对象 释放掉; 但会产生很多内存碎片
释放掉内存, 是为了让其他代码可以申请内存, (申请内存, 都是要 "连续的内存空间" ) ;
而这里假设 2 和 4 都占 1MB , 虽然有 2MB 的空间被释放 , 但由于 不连续 , 比较零零散散;
申请 空间时 , 只能 申请 <= 1MB 的空间, 我想申请2Mb的空间不行 ;
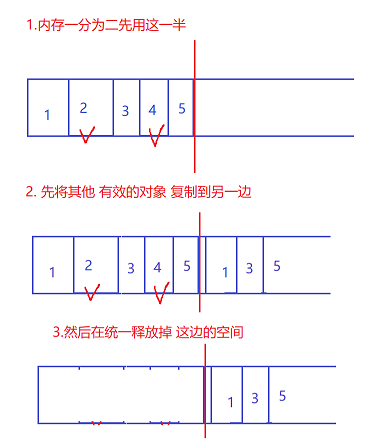
2. 复制算法
通过复制的方式,将有效的对象,归类到一起, 在统一 释放 剩下的 空间 ;(可以有效解决内存碎片的方式)
缺点:
1. 内存要浪费一半,利用率不高
2. 如果有效对象非常多 , 拷贝开销非常大 ;(如果有100个对象都有效,要拷贝100个对象)
3. 标记整理
既能解决 标记清除 内存碎片的问题 ,也能处理 复制算法 内存利用率的问题
类似于 顺序表 中 删除 元素 的搬运 操作 ;
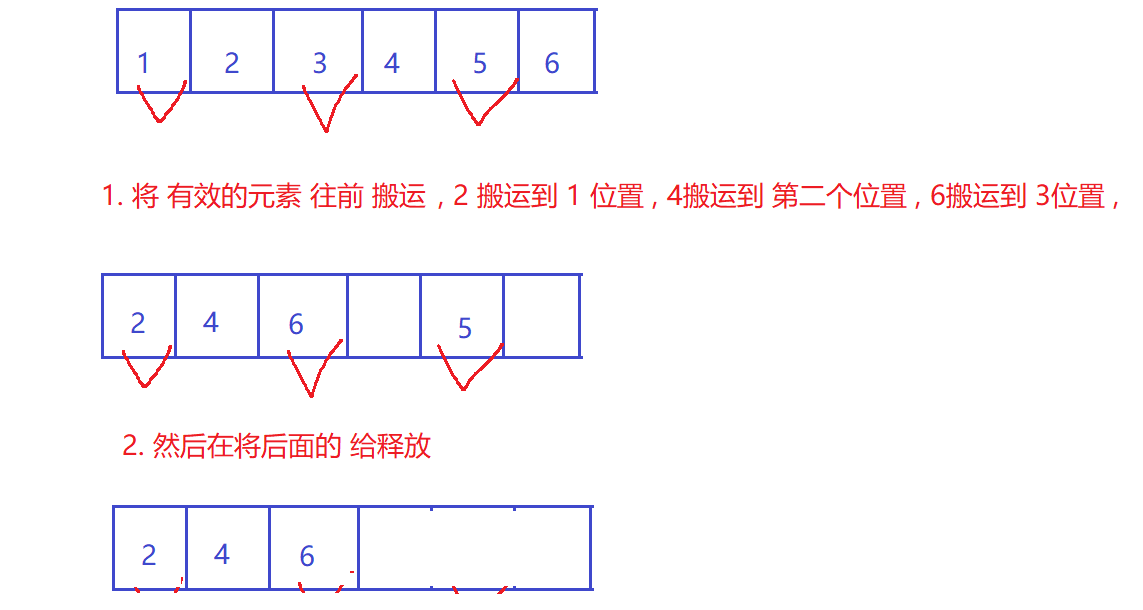
缺点: 复制搬运的开销 仍然很大 ;
JVM 采取的释放的 方案 , 是 上面3个方案的 总结合
3个方案结合, 扬长避短 ;
分代回收
分代回收 , 将 内存空间 分成主要两个 部分 : 新生代 和 老年代
新生代里有 : 伊甸区 和 幸存区 伊甸区 : 新创建的 对象, 就在 伊甸区; 幸存区: 幸存区, 是一个分成大小相同的两个部分 在第一轮扫描存活下来的对象, 就 复制算法 复制到 幸存区 ; 老年区: 对象在幸存区 GC扫描多次后,仍然存活, 就复制到老年区; 老年区里 的GC 扫描 频率 比 幸存区里 低 (降低GC开销 , 并且能在老年区的对象,本身就没有那么容易挂) 老年区里 使用 标记整理 的方法, 清除垃圾 ;
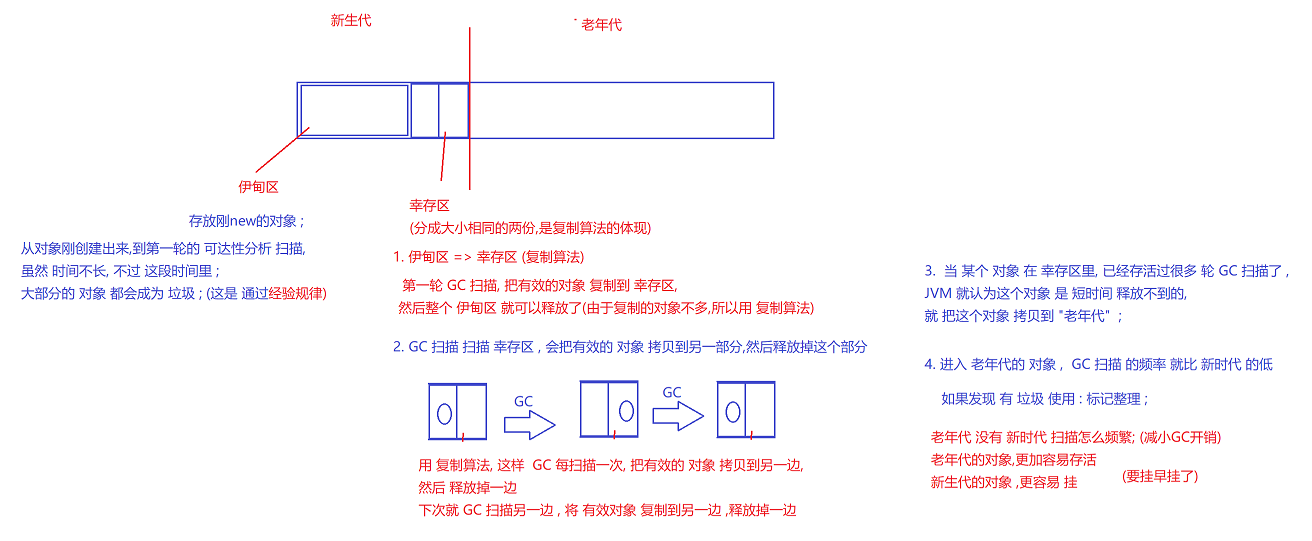
分代回收,其实在jvm垃圾回收还有优化 ;(标记清除,问题太大了,没有采用)