
一、存储引擎
一、MySQL 体系结构
MySQL采用分层插件式架构,核心分为4层,存储引擎是整个架构的核心,决定了数据的存储、读取、事务、锁等核心能力。
|-----|--------------------------------|--------------------------------------------------|----------------------------------|
| 层级 | 核心组件 | 核心作用 | 和存储引擎的关系 |
| 连接层 | 客户端连接器、连接池 | 负责客户端连接接入、身份认证、线程复用、连接数限制、内存校验 | 所有SQL请求的入口,和引擎无直接交互,只负责连接管理 |
| 服务层 | SQL接口、解析器、查询优化器、缓存 | 核心SQL处理层:负责SQL语法解析、权限校验、生成执行计划、存储过程/视图/触发器等跨引擎功能 | 生成执行计划后,调用存储引擎的接口读写数据,不关心底层存储实现 |
| 引擎层 | 可插拔存储引擎(InnoDB/MyISAM/Memory等) | 数据存储与提取的底层实现:负责数据落盘、索引管理、事务、锁、崩溃恢复等核心能力 | 是SQL执行的最终执行者,不同引擎的执行逻辑、性能、特性完全不同 |
| 存储层 | 系统文件、数据/索引/日志文件 | 负责将数据、索引、事务日志持久化到磁盘文件系统 | 存储引擎最终将数据写入该层的磁盘文件 |
二、存储引擎简介
1. 核心定义
存储引擎 是MySQL中负责数据存储、索引建立、数据 增删改查 的底层技术实现,也被称为「表类型」。
和其他数据库(Oracle、PostgreSQL)最大的区别是:MySQL的存储引擎是基于表生效,而非基于数据库,支持同一个库中不同的表使用不同的存储引擎,实现业务能力的灵活适配。
2. 基础操作示例

示例1:创建表时指定存储引擎
sql
-- 1. 业务核心表,指定InnoDB引擎(MySQL5.5+默认,可省略不写)
CREATE TABLE tb_user (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '主键ID',
name VARCHAR(50) NOT NULL COMMENT '用户名',
age INT COMMENT '年龄',
profession VARCHAR(50) COMMENT '职业'
) ENGINE = INNODB DEFAULT CHARSET = utf8mb4 COMMENT '用户核心表';
-- 2. 只读历史归档表,指定MyISAM引擎
CREATE TABLE tb_user_history_2024 (
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
create_time DATETIME
) ENGINE = MYISAM DEFAULT CHARSET = utf8mb4 COMMENT '2024年用户历史归档表';
-- 3. 临时缓存表,指定Memory引擎
CREATE TABLE tb_temp_online_user (
user_id INT PRIMARY KEY,
login_time DATETIME NOT NULL
) ENGINE = MEMORY DEFAULT CHARSET = utf8mb4 COMMENT '用户在线状态临时表';示例2:查看存储引擎相关信息
sql
-- 查看当前MySQL支持的所有存储引擎
SHOW ENGINES;
-- 查看当前数据库的默认存储引擎
SHOW VARIABLES LIKE 'default_storage_engine';
-- 查看指定表的存储引擎
SHOW CREATE TABLE tb_user;
-- 查看当前库所有表的引擎信息
SELECT TABLE_NAME, ENGINE FROM information_schema.TABLES WHERE TABLE_SCHEMA = DATABASE();三、核心存储引擎特点
重点讲解3个主流引擎,覆盖99%的业务场景,同时补充底层结构细节,衔接之前的索引优化知识。
1. InnoDB(MySQL 5.5+ 默认引擎,业务首选)
核心定位
兼顾高可靠性和高性能的事务型通用引擎,是企业级开发的默认选择。
核心特点
-
事务支持:严格遵循ACID模型,支持事务提交、回滚、崩溃安全恢复,保证数据不丢失。
-
锁机制:行级锁,仅锁定修改的行,不锁全表,支持高并发读写。
-
外键 约束:支持FOREIGN KEY外键,保证数据的参照完整性。
-
索引结构:采用聚簇索引,主键索引和数据存储在一起,之前学习的覆盖索引、联合索引优化,均基于InnoDB的B+树索引结构实现。
文件结构
每张InnoDB表对应一个 xxx.ibd 独立表空间文件,存储表结构、数据、索引,由参数 innodb_file_per_table 控制(默认开启)。
逻辑存储结构(从大到小)
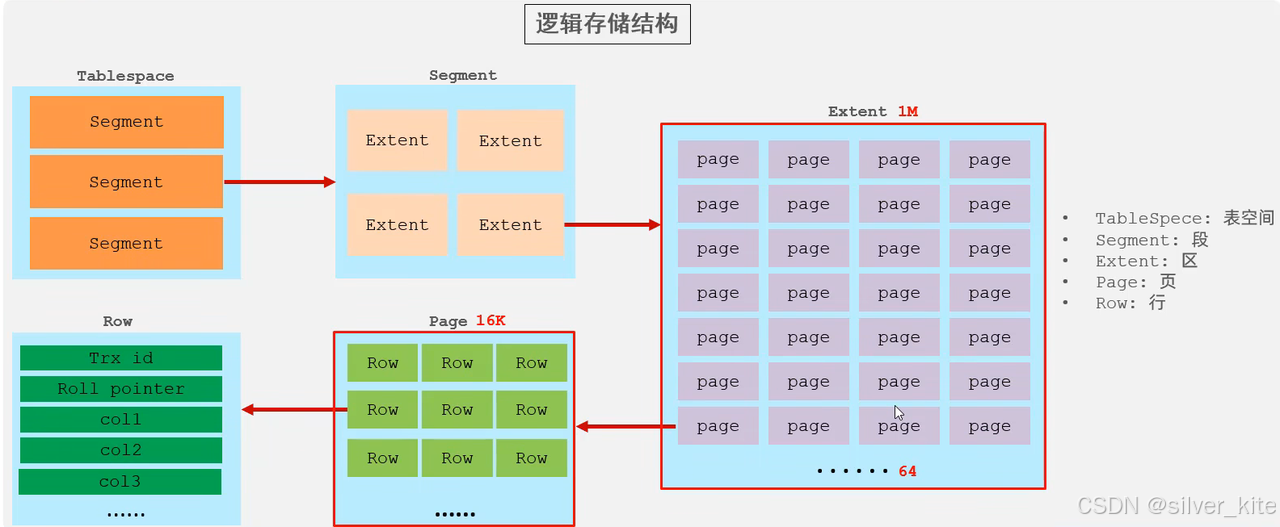
表空间(Tablespace) → 段(Segment) → 区(Extent) → 页(Page) → 行(Row)
-
表空间:最高层,对应磁盘上的ibd文件,分为系统表空间、独立表空间等。
-
段:分为数据段、索引段、回滚段,数据段对应聚簇索引的叶子节点,索引段对应二级索引。
-
区:固定大小1M,包含64个连续的16K页,保证磁盘IO的连续性,减少随机IO。
-
页:InnoDB磁盘IO的最小单位,默认16K,B+树的一个节点就是一个页,一行行数据存储在页中。
-
行:表中的单条记录,包含自定义字段+InnoDB隐藏字段(事务ID、回滚指针等)。
2. MyISAM(MySQL早期默认引擎,现已基本淘汰)
核心定位
非事务型读密集引擎,仅适用于极少数特殊场景。
核心特点
-
不支持事务、不支持外键、不支持崩溃恢复,数据安全性极差。
-
锁机制:表级锁,修改任意一行都会锁定全表,并发能力几乎为0。
-
优势:占用磁盘空间小,只读场景下访问速度快(现代MySQL版本中已被InnoDB反超)。
文件结构
每张MyISAM表对应3个磁盘文件:
-
xxx.sdi:表结构信息文件 -
xxx.MYD:数据文件(MYData) -
xxx.MYI:索引文件(MYIndex)
数据和索引完全分离存储,无法实现覆盖索引免回表的优化。
3. Memory(内存引擎)
核心定位
数据全量存储在内存中的临时引擎,仅适用于临时缓存场景。
核心特点
-
数据全量存放在内存中,磁盘仅存储表结构,访问速度极快,MySQL 重启 /断电后数据完全丢失。
-
锁机制:表级锁,并发能力弱。
-
索引支持:默认使用Hash索引,也支持B+树索引。
-
限制:表大小受内存限制,无法存储超大表。
文件结构
仅对应一个 xxx.sdi 表结构文件,无数据持久化文件。
三大引擎核心特性对比表
| 核心特性 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 事务安全 | 支持 | 不支持 | 不支持 |
| 锁机制 | 行级锁 | 表级锁 | 表级锁 |
| B+树索引 | 支持 | 支持 | 支持 |
| Hash索引 | 不支持 | 不支持 | 支持(默认) |
| 全文索引 | 5.6+ 支持 | 支持 | 不支持 |
| 外键约束 | 支持 | 不支持 | 不支持 |
| 数据持久化 | 磁盘持久化 | 磁盘持久化 | 不持久化,内存存储 |
| 崩溃数据安全 | 支持崩溃恢复 | 不支持 | 完全丢失 |
| 并发能力 | 极高 | 极低 | 低 |
四、存储引擎选择
核心原则:没有最好的引擎,只有最适合业务场景的引擎,无特殊需求优先默认InnoDB,避免不必要的兼容问题。
1. InnoDB 适用场景(99%业务首选)
-
业务需要事务支持(订单、支付、金融、用户核心数据等场景)
-
有高频的更新、删除操作,需要行锁保证高并发能力
-
对数据可靠性有强要求,需要崩溃恢复能力
-
需要外键约束保证数据的参照完整性
-
示例场景:电商订单表、用户信息表、支付流水表、库存表等所有核心业务表。
2. MyISAM 适用场景(现已极少使用)
-
业务以只读和插入为主,几乎无更新、删除操作
-
不需要事务、不需要高并发,对数据可靠性要求极低
-
示例场景:静态历史数据归档表、只读的系统配置字典表(现代场景完全可以用InnoDB替代)。
3. Memory 适用场景
-
临时数据存储,可接受数据丢失,重启后可快速重建
-
高频访问的热点小数据缓存、报表计算的中间临时表
-
示例场景:用户在线状态临时表、活动实时排名临时表、SQL查询的内部临时表。
进阶避坑提醒
-
不要在同一个事务中混用不同存储引擎的表,非事务引擎无法回滚,会直接破坏事务的ACID特性。
-
不要用Memory引擎存储核心业务数据,MySQL重启/服务器断电会直接丢失全部数据。
-
不要轻信「MyISAM比InnoDB读得快」的老旧说法,现代MySQL版本中,InnoDB的缓冲池可同时缓存数据和索引,读性能远超仅能缓存索引的MyISAM。
二、索引
一、索引概述
1.1 核心定义与本质
索引(index)是帮助 MySQL 高效获取数据的有序数据结构。数据库系统在业务数据之外,额外维护了一套满足特定查找算法的数据结构,该结构通过指针指向真实数据,从而实现高级查找算法,大幅降低数据检索的成本。
核心本质:用空间换时间,通过额外的磁盘空间、数据维护成本,换取查询效率的指数级提升。
1.2 索引的核心作用:避免全表扫描
索引的核心价值,是把低效的全表扫描,转为高效的索引查找,对应示例SQL:
sql
select * from user where age = 45;-
无索引场景:MySQL只能执行全表扫描,从第一行开始逐行比对age字段,直到找到所有符合条件的记录。数据量越大,扫描行数越多,磁盘IO成本越高,性能越差。
-
有索引场景:MySQL会基于age字段的有序索引结构,通过二分查找快速定位到age=45的记录,仅需少数几次磁盘IO即可完成查询,性能提升可达上千倍。
1.3 索引的优缺点
| 核心优势 | 核心劣势 |
|---|---|
| 1. 大幅提升数据检索效率,减少磁盘IO次数,是索引最核心的价值 | 1. 空间成本:索引需要占用额外的磁盘空间,索引总大小甚至可能超过数据本身 |
2. 利用索引的有序性,直接避免额外排序操作,降低CPU消耗(可避免Using temporary、Using filesort) |
2. 维护成本:INSERT/UPDATE/DELETE操作时,需要同步维护索引结构保证有序性,索引越多,写操作性能损耗越大 |
| 3. 将随机IO转为顺序IO,大幅提升磁盘读写效率 | 3. 优化成本:过多索引会增加查询优化器的选择成本,可能导致执行计划选错索引 |
1.4 索引与存储引擎的关系
MySQL的索引在存储引擎层实现,而非服务层,因此不同存储引擎支持的索引类型、结构、实现逻辑完全不同,这也是索引和表类型强绑定的核心原因。
主流存储引擎的索引支持情况如下:
|-----------------|------------------------|--------|------------|
| 索引类型 | InnoDB(默认引擎) | MyISAM | Memory |
| B+Tree索引 | 支持(默认、核心索引结构) | 支持 | 支持 |
| Hash索引 | 不支持(仅系统自适应Hash,无法手动创建) | 不支持 | 支持(默认索引类型) |
| R-Tree(空间索引) | 不支持 | 支持 | 不支持 |
| Full-text(全文索引) | 5.6版本之后支持 | 支持 | 不支持 |
日常业务开发中,99%的场景都是基于InnoDB引擎的B+Tree索引,这也是后续所有索引优化的核心基础。
实操示例:索引基础操作
sql
-- 1. 创建表时同时创建索引
CREATE TABLE tb_user (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '主键ID',
name VARCHAR(50) NOT NULL COMMENT '用户名',
age INT COMMENT '年龄',
profession VARCHAR(50) COMMENT '职业',
-- 普通单列索引
INDEX idx_user_age (age),
-- 联合索引(对应之前学习的最左前缀原则)
INDEX idx_user_pro_age (profession, age)
) ENGINE = INNODB DEFAULT CHARSET = utf8mb4 COMMENT '用户表';
-- 2. 查看表的所有索引
SHOW INDEX FROM tb_user;
-- 3. 给已存在的表添加索引
CREATE INDEX idx_user_name ON tb_user(name);
-- 4. 删除索引
DROP INDEX idx_user_name ON tb_user;二、索引结构
数据库查询的最大性能瓶颈是磁盘 IO (磁盘IO耗时是内存操作的上万倍),因此索引结构的设计核心目标是:尽量减少磁盘IO次数,也就是降低树的高度。
下面我们从演进逻辑,讲清楚为什么MySQL最终选择B+Tree作为默认索引结构。
2.1 为什么二叉树/红黑树不适合MySQL
二叉树
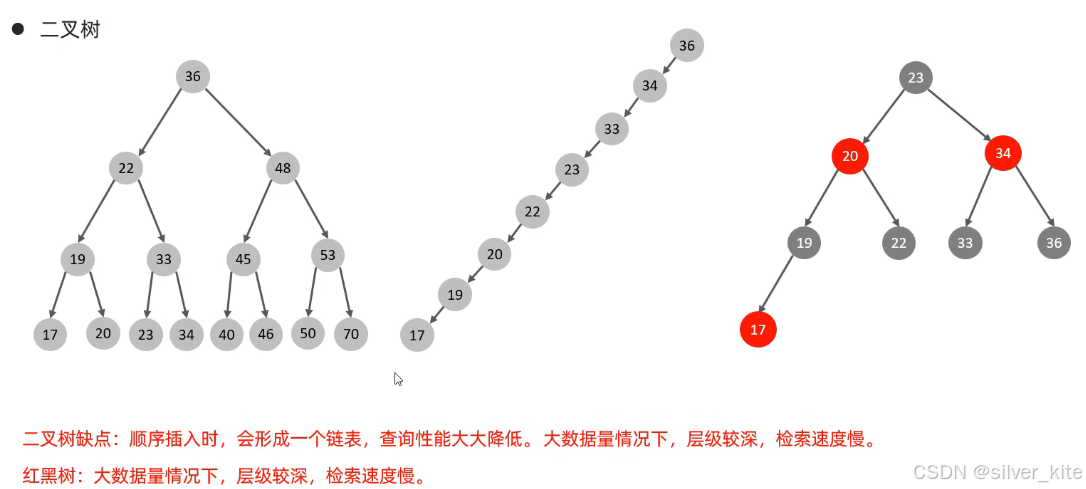
红黑树(平衡二叉树)
在二叉树基础上,通过自旋、变色保证树的平衡,解决了链表退化问题。
核心缺陷:
依然是二叉树结构,每个节点最多2个子节点,大数据量下树的高度依然很高,无法解决磁盘IO过多的核心问题,因此不适合作为MySQL的索引结构。
2.2 B-Tree(多路平衡查找树):特点与局限
为了解决树的高度问题,B-Tree(多路平衡查找树)被设计出来,核心是多路结构:一个节点可以存储多个key和多个子节点指针,大幅降低树的高度。
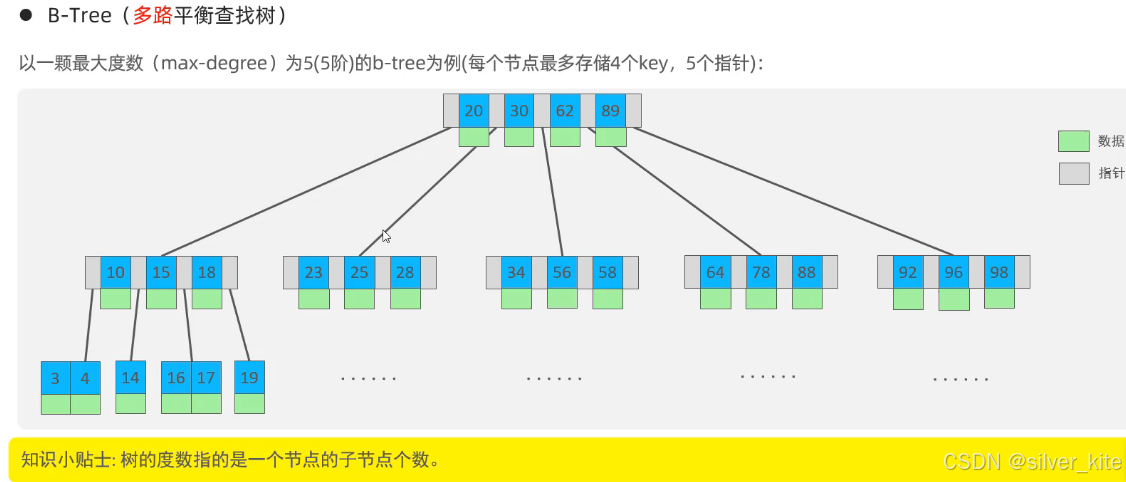
以5阶B-Tree为例:每个节点最多存储4个key、5个子节点指针,所有节点都存储key、数据、指针,整棵树全局有序。
核心特点
-
多路结构大幅降低树高:100阶B-Tree存储100万条数据,高度仅为3层,仅需3次磁盘IO即可完成查询。
-
所有节点都存储索引key和对应的数据,整棵树有序,支持二分查找。
核心局限(不适合MySQL的原因)
-
非叶子节点也存储数据:InnoDB中每个节点对应一个16K的页,非叶子节点存储数据会导致每个节点能存的key数量大幅减少,树的高度会增加,IO次数变多。
-
范围查询效率极低:范围查询需要频繁回溯父节点,带来大量额外IO。
-
排序查询需要频繁回溯,无法利用有序性做连续扫描。
2.3 B+Tree:MySQL默认的索引结构
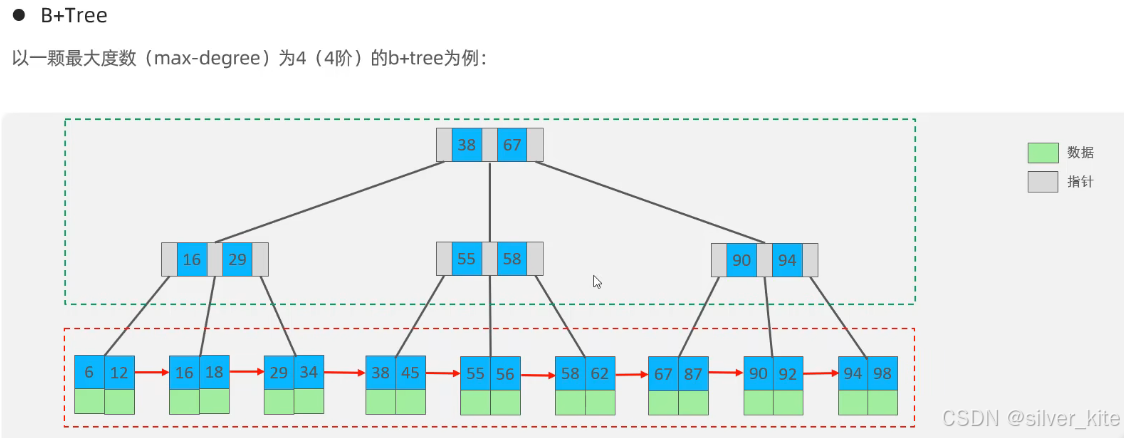
B+Tree是B-Tree的优化版,完美解决了B-Tree的缺陷,是InnoDB引擎默认的索引结构。
经典B+Tree核心特点
-
非 叶子节点 仅存储key和指针,不存储数据:所有数据只存储在叶子节点。
- 核心优势:非叶子节点能存储的key数量大幅提升,千万级数据的树高仅为3-4层,查询仅需3-4次磁盘IO,性能极高。
-
查询性能稳定:所有数据都在叶子节点,无论查询哪个key,都必须从根节点走到叶子节点,每次查询的IO次数一致,性能稳定可控。
-
叶子节点 有序串联:所有叶子节点按key从小到大排序,相邻节点通过单向链表关联,解决了B-Tree范围查询需要回溯的问题。
2.4 MySQL对B+Tree的核心优化
MySQL在经典B+Tree的基础上,做了关键优化:将 叶子节点 的 单向链表 ,升级为双向 循环链表,在叶子节点上增加了向前、向后的双向指针。
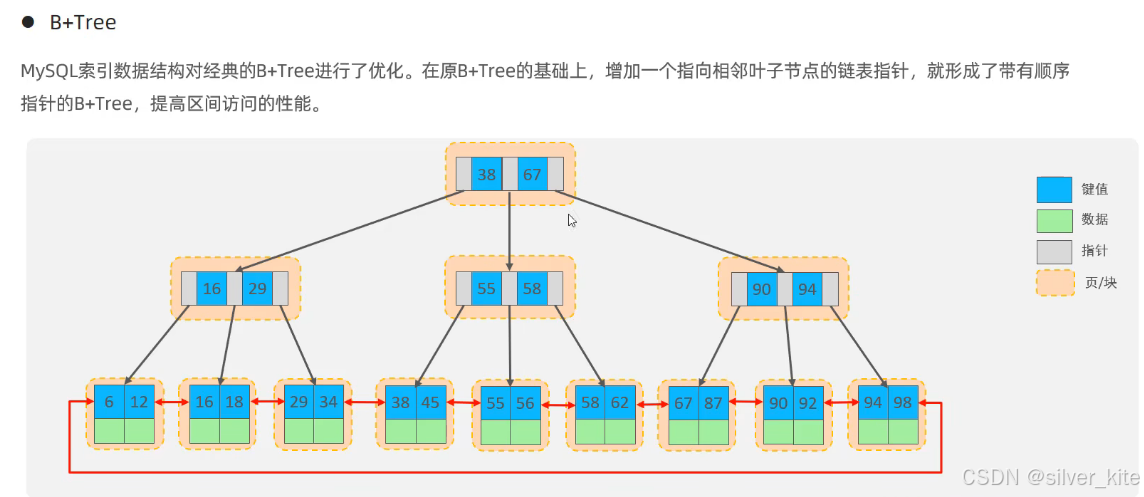
这个优化的核心价值:
-
范围查询性能拉满 :比如
age between 20 and 30,只需定位到age=20的叶子节点,即可顺着双向链表向后扫描,无需回溯父节点,无额外IO。 -
完美适配排序场景 :正序(asc)、倒序(desc)排序都可直接通过双向链表实现,无需额外排序,这也是联合索引能避免
Using temporary的底层原因。 -
全表扫描 效率高:只需遍历叶子节点的双向链表,无需遍历整棵树。
为什么B+Tree是MySQL最适合的索引结构?
树高低、IO少、查询性能稳定,天生适配范围、排序、分组查询,是所有SQL优化的底层基础。
进阶示例:验证索引的优化效果
sql
-- 1. 无索引查询,查看执行计划(全表扫描 type: ALL)
EXPLAIN SELECT * FROM tb_user WHERE age = 25;
-- 2. 创建age字段索引
CREATE INDEX idx_user_age ON tb_user(age);
-- 3. 再次查看执行计划(走索引 type: ref)
EXPLAIN SELECT * FROM tb_user WHERE age = 25;
-- 4. 范围查询,利用B+Tree双向链表优化
EXPLAIN SELECT * FROM tb_user WHERE age BETWEEN 20 AND 30 ORDER BY age;2.5Hash
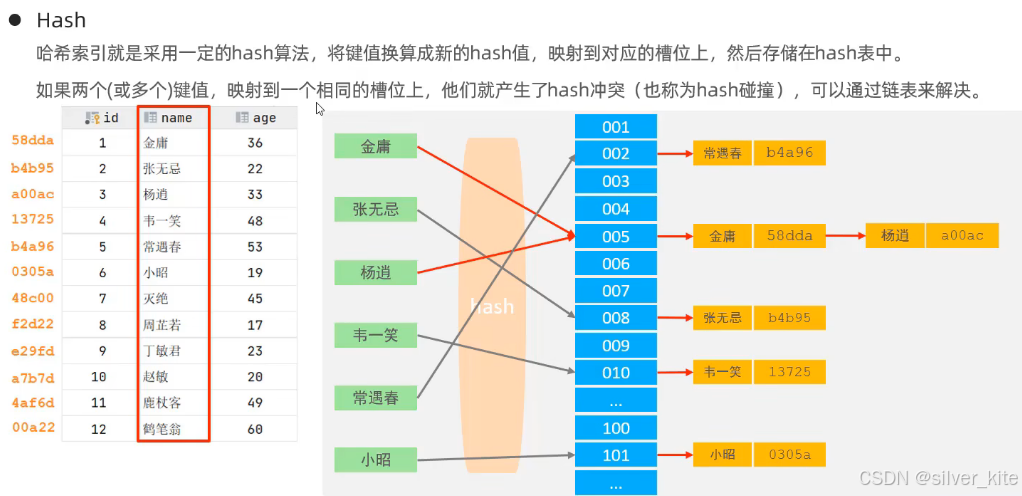
1.Hash索引的底层原理
Hash索引底层基于哈希表 ( 散列表 **)**实现,核心逻辑如下:
-
对索引列的字段值,通过固定的Hash算法计算出对应的Hash值(散列值);
-
将Hash值映射到哈希表对应的槽位(bucket)上;
-
槽位中存储「索引字段值 + 对应行数据的指针」;
-
若多个字段值计算出相同的Hash值(Hash冲突/Hash碰撞),则通过链表 法解决,在同一个槽位上串联多个数据项。
举个例子:对name字段建立Hash索引,当查询name='Arm'时,MySQL会对'Arm'计算Hash值,直接定位到对应的槽位,无需遍历树结构,一步找到数据。
2. Hash索引的核心特点
|-----------------------------------------------------------|--------------------------------------------------------------------------|
| 核心优势 | 核心劣势 |
| 等值查询(=、in)性能极高,无Hash冲突时仅需一次IO,时间复杂度O(1),理想情况下性能优于B+Tree索引 | 仅支持等值匹配,完全不支持范围查询(between、>、<、>=、<=),因为Hash值是无序的,无法通过Hash值判断大小范围 |
| | 无法利用索引完成排序操作,Hash值的大小和原字段值的大小无任何关联,无法利用Hash索引实现order by排序 |
| | 不支持模糊查询(like)、最左前缀匹配原则,无法实现部分匹配查询 |
| | Hash冲突严重时(大量重复值),需要遍历链表比对,查询性能会大幅下降 |
3. MySQL中Hash索引的支持情况
-
Memory引擎:默认支持Hash索引,也是Memory引擎的首选索引类型,适用于内存临时表的等值查询场景。
-
InnoDB引擎 :不支持手动创建Hash索引,但提供了**自适应Hash索引(Adaptive Hash Index)**功能。
-
原理:InnoDB会自动监控热点B+Tree索引的查询,如果发现频繁的等值查询能通过Hash索引优化,会在内存中自动为热点页构建Hash索引,全程无需人工干预,是内部优化机制。
-
限制:自适应Hash索引依然仅支持等值查询,不支持范围、排序等操作。
-
-
MyISAM 引擎:不支持Hash索引。
4. 为什么InnoDB默认选择B+Tree,而非Hash索引?
-
业务场景适配性:业务中绝大多数查询都是范围查询、排序、分组查询,Hash索引完全不支持这些场景,而B+Tree的叶子节点双向链表天生适配范围、排序操作。
-
IO 效率与树高:B+Tree的多路结构让千万级数据的树高仅为3-4层,仅需3-4次IO即可完成查询,性能稳定;而Hash索引在有冲突时需要遍历链表,且无法优化范围查询的IO。
-
数据存储效率:B-Tree的非叶子节点存储数据,导致单页能存储的键值少,树高增加;而B+Tree非叶子节点仅存键值和指针,单页能存储上千个键值,大幅降低树高,减少IO次数。
三、索引分类
MySQL的索引可以从功能维度 和InnoDB存储形式维度两大维度进行完整分类,其中InnoDB的聚集/二级索引分类是核心中的核心,直接决定了SQL的查询性能。
3.1 按功能维度分类
这是最基础的索引分类,对应创建索引时的语法关键字,共分为4大类:
| 分类 | 核心含义 | 核心特点 | 语法关键字 | 实操示例 |
|---|---|---|---|---|
| 主键索引 | 针对表的主键字段创建的索引,也叫聚簇索引 | 1. 表创建主键时,MySQL会自动创建主键索引,无需手动创建; 2. 一张表有且仅有一个主键索引;3. 索引列不允许为NULL,不允许重复 | PRIMARY | sql CREATE TABLE tb_user ( id INT PRIMARY KEY AUTO_INCREMENT COMMENT '主键ID' ); |
| 唯一索引 | 针对需要避免重复值的字段创建的索引,保证字段值在表中唯一 | 1. 一张表可以创建多个唯一索引 2. 索引列值必须唯一,但允许为NULL(可以有多个NULL); 3. 插入/更新时会校验唯一性,重复值会报错 | UNIQUE | sql -- 创建唯一索引 CREATE UNIQUE INDEX idx_user_phone ON tb_user(phone); |
| 常规索引(普通索引) | 最基础的索引,仅用于快速定位特定数据,无唯一性约束 | 1. 一张表可以创建多个常规索引,是业务中最常用的索引类型; 2. 无唯一性约束,允许重复值、NULL值; 3. 仅用于提升查询效率,无额外约束 | INDEX / KEY | sql -- 创建常规索引 CREATE INDEX idx_user_age ON tb_user(age); |
| 全文索引 | 针对长文本字段(varchar/text)创建的索引,用于关键词全文检索 | 1. 底层是倒排索引,和ES、Lucene核心原理一致; 2. 解决like '%xxx%'前缀模糊查询无法走索引的问题; 3. 一张表可以创建多个全文索引,仅支持文本类型字段 |
FULLTEXT | sql -- 创建全文索引 CREATE FULLTEXT INDEX idx_user_content ON tb_article(content); |
3.2 按InnoDB存储形式分类(核心重点)
在InnoDB存储引擎中,根据索引的存储形式和数据关联方式,索引分为聚集索引 ( Clustered Index ) 和二级索引(Secondary Index,也叫辅助索引/ 非聚集索引 **)**两大类,这是InnoDB索引最核心的设计。
3.2.1 聚集索引
核心定义
聚集索引是将索引结构和完整的行数据存储在一起的索引,B+Tree的叶子节点直接存储了整行的完整数据,一张表有且仅有一个聚集索引。
聚集索引的选取规则(优先级从高到低)
-
如果表定义了主键 ( PRIMARY KEY ),主键索引就是这张表的聚集索引;
-
如果表没有定义主键,会使用第一个非空的唯一索引(UNIQUE NOT NULL **)**作为聚集索引;
-
如果表既没有主键,也没有合适的唯一索引,InnoDB会自动生成一个6字节的隐藏
rowid,作为默认的隐藏聚集索引。
核心建议:业务中所有InnoDB表必须显式创建主键,且优先使用自增INT/BIGINT主键,保证聚集索引的有序性,避免页分裂带来的性能损耗。
核心特点
-
叶子节点存储完整行数据,通过主键查询时,直接在聚集索引中就能拿到整行数据,无需额外查询,性能极高;
-
数据的物理存储顺序和聚集索引的排序顺序一致,有序的主键插入会让数据顺序写入磁盘,随机IO转为顺序IO,性能拉满。
3.2.2 二级索引(辅助索引)
核心定义
二级索引是将索引和行数据分开存储 的索引,B+Tree的叶子节点不存储完整行数据,仅存储对应的 主键 值。一张表可以创建多个二级索引,我们手动创建的唯一索引、常规索引、联合索引,都属于二级索引。
核心特点
-
叶子节点仅存储主键值,而非完整行数据,索引文件体积远小于聚集索引,节省磁盘空间;
-
通过二级索引查询时,通常需要两步操作:先通过二级索引找到对应的主键值,再通过主键值到聚集索引中查找完整行数据,这个过程叫做回表查询。
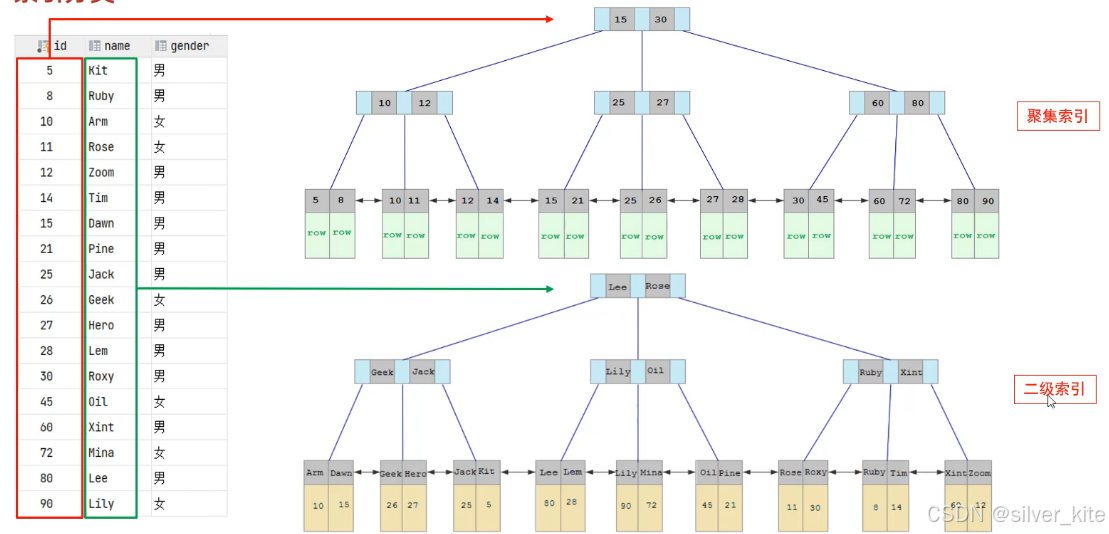
2.2.3 回表查询详解(面试高频)
核心定义
回表查询,就是先通过二级索引定位到主键值,再拿着主键值到聚集索引中查询完整行数据的过程,需要两次B+Tree查询,性能低于直接走聚集索引的查询。
执行流程:
-
先走
name字段的二级索引,在B+Tree中找到name='Arm'对应的叶子节点,拿到主键值id=10; -
拿着主键值
id=10,走聚集索引的B+Tree,找到对应的叶子节点,拿到整行的完整数据; -
整个过程需要两次B+Tree查询,这就是回表查询。
高频面试题解答
问题:以下两条SQL,哪个执行效率高?为什么?
select * from user where id = 10;(id为主键)
select * from user where name = 'Arm';(name有二级索引)
答案:第一条SQL执行效率远高于第二条。
原因:
-
第一条SQL直接走聚集索引,一次B+Tree查询就能直接拿到完整行数据,无需回表;
-
第二条SQL先走二级索引拿到主键值,再走聚集索引回表查询完整数据,需要两次B+Tree查询,额外的IO操作导致性能更低。
四、索引语法
MySQL索引的核心操作分为创建、查看、删除三类,所有操作均基于表级别生效,语法适配普通索引、唯一索引、全文索引、联合索引等所有索引类型,是索引优化的基础操作。
4.1 创建索引
通用语法
sql
CREATE [UNIQUE | FULLTEXT] INDEX index_name ON table_name (index_col_name [长度], ...);语法参数详解
|------------------|-------|---------------------------------------------------------------------|
| 参数 | 可选/必填 | 核心说明 |
| UNIQUE | 可选 | 声明创建唯一索引,保证索引列的值全局唯一,允许存在多个NULL值 |
| FULLTEXT | 可选 | 声明创建全文索引,仅支持TEXT/VARCHAR长文本字段,用于关键词模糊检索 |
| index_name | 必填 | 索引名称,建议遵循命名规范:idx_表名_字段名,联合索引用字段缩写拼接,保证库内唯一 |
| table_name | 必填 | 要创建索引的目标表名 |
| index_col_name | 必填 | 要创建索引的字段,多个字段用逗号分隔即为联合索引,字段顺序直接决定最左前缀匹配规则;字符串字段可指定索引前缀长度,减少索引体积 |
实操场景示例
场景1:建表时同步创建索引
建表时直接定义索引,可避免数据量大后创建索引的性能损耗,对应之前的索引分类:
sql
CREATE TABLE tb_user (
id BIGINT PRIMARY KEY AUTO_INCREMENT COMMENT '主键ID(主键索引,自动创建)',
name VARCHAR(50) NOT NULL COMMENT '姓名',
phone CHAR(11) NOT NULL COMMENT '手机号',
profession VARCHAR(50) COMMENT '职业',
age TINYINT COMMENT '年龄',
status TINYINT DEFAULT 1 COMMENT '状态',
email VARCHAR(100) COMMENT '邮箱',
-- 普通索引:name字段值可重复
INDEX idx_user_name (name),
-- 唯一索引:phone字段非空且唯一
UNIQUE INDEX idx_user_phone (phone),
-- 联合索引:profession、age、status,遵循最左前缀原则
INDEX idx_user_pro_age_sta (profession, age, status),
-- 普通索引:email字段提升查询效率
INDEX idx_user_email (email)
) ENGINE = INNODB DEFAULT CHARSET = utf8mb4 COMMENT '用户表';场景2:已存在的表创建索引
sql
-- 需求1:name字段值可能重复,创建普通索引
CREATE INDEX idx_user_name ON tb_user(name);
-- 需求2:phone字段非空且唯一,创建唯一索引
CREATE UNIQUE INDEX idx_user_phone ON tb_user(phone);
-- 需求3:为profession、age、status创建联合索引
CREATE INDEX idx_user_pro_age_sta ON tb_user(profession, age, status);
-- 需求4:为email建立索引提升查询效率
CREATE INDEX idx_user_email ON tb_user(email);4.2 查看索引
用于查看表中已创建的所有索引的详细信息,包括索引类型、关联字段、是否唯一、索引长度等,是索引排查的核心命令。
语法
sql
SHOW INDEX FROM table_name;实操示例
sql
-- 查看tb_user表的所有索引
SHOW INDEX FROM tb_user;核心结果说明
执行后可获取关键信息:
-
Key_name:索引名称,主键索引固定为PRIMARY -
Column_name:索引关联的字段名 -
Non_unique:是否允许重复值,0=唯一索引,1=普通索引 -
Seq_in_index:字段在联合索引中的顺序,从1开始,对应最左前缀原则 -
Index_type:索引类型,InnoDB默认为BTREE(B+Tree)
4.3 删除索引
用于删除无用、冗余的索引,减少写操作的性能损耗和磁盘空间占用。
通用语法
sql
DROP INDEX index_name ON table_name;实操示例
sql
-- 删除tb_user表中的idx_user_email索引
DROP INDEX idx_user_email ON tb_user;
-- 特殊:删除主键索引(一张表仅有一个主键索引)
ALTER TABLE tb_user DROP PRIMARY KEY;注意事项
-
删除索引前需确认无业务SQL依赖该索引,避免引发全表扫描导致线上故障
-
大表删除索引需在低峰期操作,避免影响数据库性能
-
唯一索引无法通过删除解决重复值问题,需先清理表中的重复数据
五、SQL性能分析
SQL优化的核心原则是先定位瓶颈,再针对性优化,MySQL提供了从全局到单条SQL的全链路性能分析工具,可精准定位慢SQL、性能损耗点,是索引优化的前提。
5.1 SQL执行频率分析
用于查看数据库全局的增删改查(INSERT/UPDATE/DELETE/SELECT)执行频次,判断数据库的读写压力模型,是宏观性能分析的第一步。
核心语法
sql
-- 查看全局SQL执行频次(MySQL启动以来的累计值)
SHOW GLOBAL STATUS LIKE 'Com_______';
-- 查看当前会话的SQL执行频次
SHOW SESSION STATUS LIKE 'Com_______';核心说明
-
GLOBAL:查看MySQL服务启动以来的全局累计执行次数,用于分析整体业务模型 -
SESSION:查看当前数据库连接的会话执行次数,用于测试单条/一组SQL的执行情况 -
关键结果字段:
-
Com_select:SELECT语句累计执行次数,反映读压力 -
Com_insert:INSERT语句累计执行次数 -
Com_update:UPDATE语句累计执行次数 -
Com_delete:DELETE语句累计执行次数
-
分析逻辑
-
如果
Com_select占比极高,说明数据库是读多写少模型,核心优化方向是索引优化、查询缓存、读写分离 -
如果增删改操作占比高,说明是写多读少模型,核心优化方向是索引精简、事务优化、批量写入优化
5.2 慢查询日志
慢查询日志是MySQL内置的日志功能,会记录所有执行时间超过指定阈值的SQL语句,是定位线上慢SQL的核心工具。
核心特点
-
默认关闭,需手动修改配置文件开启
-
可自定义慢SQL的时间阈值,默认阈值为10秒,生产环境通常设置为1-2秒
-
仅记录执行完成的SQL,未执行完成的长SQL不会记录
配置方式
需修改MySQL的配置文件(Linux为/etc/my.cnf,Windows为my.ini),添加以下配置:
sql
# 开启慢查询日志开关 1=开启 0=关闭
slow_query_log = 1
# 慢SQL时间阈值,单位:秒,执行时间超过2秒的SQL会被记录
long_query_time = 2
# 慢查询日志文件存储路径
slow_query_log_file = /var/lib/mysql/localhost-slow.log配置完成后,重启MySQL服务生效:
sql
# Linux重启命令
systemctl restart mysqld使用方式
-
开启后,所有超过
long_query_time阈值的SQL都会自动写入日志文件 -
通过查看日志文件,定位高频、长耗时的慢SQL,针对性做索引优化、SQL改写
-
生产环境建议长期开启,作为线上SQL性能监控的核心手段
5.3 profile详情分析
profile工具可以精准查看单条SQL执行时,每个阶段的耗时、CPU占用等细节,可定位SQL到底慢在哪个环节(如IO、排序、锁等待、优化器解析等),是微观性能分析的核心工具。
基础操作
1. 查看是否支持profile功能
sql
SELECT @@have_profiling;结果为YES表示支持,NO表示不支持,主流MySQL版本均支持。
2. 开启profile功能
默认关闭,需在当前会话手动开启,仅对当前会话生效:
sql
-- 开启profile,1=开启 0=关闭
SET profiling = 1;3. 查看SQL执行耗时概览
执行业务SQL后,通过以下命令查看所有SQL的执行耗时:
sql
-- 查看当前会话所有SQL的执行耗时、query_id
SHOW PROFILES;结果会返回每条SQL的Query_ID、执行时长、SQL语句,可快速定位耗时最高的SQL。
4. 查看指定SQL的全阶段耗时详情
通过Query_ID查看单条SQL每个执行阶段的耗时,定位瓶颈:
sql
-- 查看query_id为1的SQL,每个执行阶段的耗时
SHOW PROFILE FOR QUERY 1;
-- 进阶:同时查看CPU占用情况,精准定位CPU瓶颈
SHOW PROFILE CPU FOR QUERY 1;核心分析场景
通过profile可定位常见的性能瓶颈:
-
Sending data:数据读取、传输耗时高,通常是全表扫描、无索引导致 -
Creating sort index:排序耗时高,通常是ORDER BY字段无索引,引发Using filesort -
Creating tmp table:创建临时表耗时高,通常是GROUP BY字段无索引,引发Using temporary
5.4 explain执行计划(核心重点)
explain(或desc)是SQL优化最核心的工具,可获取MySQL优化器生成的SQL执行计划,查看SQL是否走索引、走哪个索引、是否回表、是否全表扫描、表连接顺序等核心信息,是索引优化的必备工具。
通用语法
直接在SELECT查询语句前添加EXPLAIN关键字即可:
sql
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件 [GROUP BY 字段 ORDER BY 字段];
-- 简写方式,效果完全一致
DESC SELECT 字段列表 FROM 表名 WHERE 条件;实操示例
sql
-- 查看主键查询的执行计划
EXPLAIN SELECT * FROM tb_user WHERE id = 1;
-- 查看二级索引查询的执行计划
EXPLAIN SELECT * FROM tb_user WHERE name = '张三';
-- 查看联合索引查询的执行计划
EXPLAIN SELECT * FROM tb_user WHERE profession = '软件工程' AND age = 25;执行计划核心字段详解
执行计划返回12个字段,核心高频字段如下,按重要优先级排序:
|-----------------|-------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 字段名 | 核心含义 | 重点分析规则 |
| id | SELECT查询的序列号,标识SQL中表的执行顺序 | 1. id相同,执行顺序从上到下; 2. id不同,id值越大,越先执行(子查询优先执行) |
| select_type | SELECT查询的类型 | 常见取值:SIMPLE:简单查询,无表连接、无子查询PRIMARY:主查询(外层查询) SUBQUERY:子查询 UNION:UNION中的后续查询 |
| type | 索引访问类型,反映 SQL 性能的核心指标 ,性能从好到坏排序:NULL > system > const > eq_ref > ref > range > index > all | 核心优化目标: 1. 至少达到range级别,最优为ref级别; 2. 避免出现index(全索引扫描)、all(全表扫描)常见取值说明: const:主键/唯一索引等值查询,性能最优 ref:普通索引等值匹配,高频优化目标<br>- range:索引范围查询(between、>、<、in等) all:全表扫描,必须优化 |
| possible_keys | 本次查询中,可能用到的索引(候选索引) | 仅为优化器的候选列表,不代表实际会使用 |
| key | 本次查询中,实际使用的索引 | 核心判断项: 1. 为NULL表示未使用索引,大概率全表扫描 2. 需和possible_keys对比,判断优化器是否选择了正确的索引 |
| key_len | 索引中使用的字节数,是索引字段的最大可能长度 | 1. 不损失精度的前提下,长度越短越好 2. 可通过该值判断联合索引中,实际用到了哪些字段(对应最左前缀原则) |
| rows | MySQL认为执行查询必须扫描的行数 | InnoDB中为估算值,值越小越好,全表扫描时会显示表的总行数 |
| filtered | 返回结果行数占扫描行数的百分比 | 值越大越好,100.00为最优;值越小说明扫描了大量无效行,需优化索引 |
| Extra | 额外信息,SQL 优化的核心判断项,可直接定位SQL的问题 | 高频关键值: Using index:使用了覆盖索引,无需回表,性能最优Using where:通过索引过滤后,还需在服务层过滤数据 Using temporary:使用了临时表,通常是GROUP BY无索引,必须优化 Using filesort:使用了文件排序,ORDER BY字段无索引,必须优化 Using index condition:使用了索引条件下推(ICP)优化 |
核心优化判断规则
-
必须避免
type字段出现all(全表扫描) -
必须避免
Extra字段出现Using temporary、Using filesort -
最优状态:
type为ref/const,Extra为Using index(覆盖索引,无回表)
5.6索引语法与性能分析实操闭环
完整的SQL优化流程如下,可直接套用:
-
通过慢查询日志定位线上耗时高的慢SQL
-
通过explain执行计划查看SQL的索引使用情况,定位问题(是否全表扫描、是否有临时表/文件排序)
-
通过profile详情定位SQL的具体耗时瓶颈
-
针对性创建/优化索引,改写SQL
-
再次通过explain验证优化效果,形成闭环
六.索引使用
6.1 索引效率验证
在大表场景下,索引对查询性能的提升效果极为显著,可通过以下步骤直观验证:
sql
-- 1. 无索引时执行查询(全表扫描)
SELECT * FROM tb_sku WHERE sn = '100000003145001';
-- 2. 为sn字段创建普通索引
CREATE INDEX idx_sku_sn ON tb_sku(sn);
-- 3. 再次执行相同查询(索引扫描)
SELECT * FROM tb_sku WHERE sn = '100000003145001';现象说明:
-
无索引时,查询需遍历全表数据,耗时通常在数秒至数十秒级别;
-
创建索引后,查询通过 B+Tree 直接定位数据,耗时可降至毫秒级,性能提升可达数百倍。
6.2 索引失效场景
6.2.1 最左前缀法则(联合索引核心规则)
规则定义 :联合索引遵循 "最左前缀匹配" 原则,查询必须从索引的最左列开始,且不能跳过中间列;若跳过某一列,该列右侧的所有索引列将失效。
示例 :假设联合索引为 idx_user_pro_age_sta(profession, age, status)
sql
-- 场景1:完全匹配(三列都用到索引)
EXPLAIN SELECT * FROM tb_user WHERE profession = '软件工程' AND age = 31 AND status = '0';
-- 场景2:用到前两列(status列索引失效)
EXPLAIN SELECT * FROM tb_user WHERE profession = '软件工程' AND age = 31;
-- 场景3:仅用到第一列(age、status列索引失效)
EXPLAIN SELECT * FROM tb_user WHERE profession = '软件工程';
-- 场景4:跳过最左列(profession列未使用,索引完全失效)
EXPLAIN SELECT * FROM tb_user WHERE age = 31 AND status = '0';
-- 场景5:完全不使用最左列(索引完全失效,全表扫描)
EXPLAIN SELECT * FROM tb_user WHERE status = '0';优化建议 :联合索引的字段顺序需遵循 "等值条件优先、范围条件靠后" 的原则,将高频等值查询字段放在左侧。
6.2.2 范围查询导致索引失效
规则定义 :联合索引中,若某一列使用了>/</BETWEEN等范围查询,该列右侧的所有索引列将失效。
示例:
sql
-- 场景1:age使用范围查询,status列索引失效
EXPLAIN SELECT * FROM tb_user WHERE profession = '软件工程' AND age > 30 AND status = '0';
-- 场景2:age使用>=/<=(边界范围),status列索引同样失效
EXPLAIN SELECT * FROM tb_user WHERE profession = '软件工程' AND age >= 30 AND status = '0';优化建议 :将范围查询字段放在联合索引的最后一列 ,避免影响后续字段的索引使用;若业务允许,优先使用>=/<=替代>/<,减少范围扫描的行数。
6.2.3 索引列运算 / 函数操作导致失效
规则定义 :对索引列进行运算(如加减乘除)或函数操作(如SUBSTRING/DATE_FORMAT),会导致索引失效,MySQL 将转为全表扫描。
示例:
sql
-- 场景:对phone字段使用SUBSTRING函数,索引失效
EXPLAIN SELECT * FROM tb_user WHERE SUBSTRING(phone, 10, 2) = '15';优化建议:
-
将运算 / 函数操作移到查询条件的右侧,避免作用于索引列;
-
对于字符串截取场景,优先使用前缀索引替代函数操作;
-
高版本 MySQL 支持函数索引,可直接为运算后的字段创建索引。
6.2.4 字符串字段不加引号导致索引失效
规则定义:字符串类型字段(如 VARCHAR/CHAR)查询时,若值未加引号,MySQL 会自动进行类型转换,导致索引失效。
示例:
sql
-- 场景1:status字段为字符串类型,不加引号,索引失效
EXPLAIN SELECT * FROM tb_user WHERE profession = '软件工程' AND age = 31 AND status = 0;
-- 场景2:phone字段为字符串类型,不加引号,索引失效
EXPLAIN SELECT * FROM tb_user WHERE phone = 17799990015;原理说明 :字符串与数字比较时,MySQL 会将字符串转换为数字进行比较,导致索引列的类型被隐式转换,无法匹配索引中的字符串值。优化建议:字符串字段的查询值必须加单引号,即使值是纯数字。
6.2.5 模糊查询(LIKE)导致索引失效
规则定义:
-
尾部模糊匹配(
LIKE '前缀%'):索引有效; -
头部模糊匹配(
LIKE '%后缀'/LIKE '%中间%'):索引失效,转为全表扫描。
示例:
sql
-- 场景1:尾部模糊匹配,索引有效
EXPLAIN SELECT * FROM tb_user WHERE profession LIKE '软件%';
-- 场景2:头部模糊匹配,索引失效
EXPLAIN SELECT * FROM tb_user WHERE profession LIKE '%工程';
-- 场景3:前后都模糊匹配,索引失效
EXPLAIN SELECT * FROM tb_user WHERE profession LIKE '%工%';优化建议:
-
优先使用前缀索引(如
CREATE INDEX idx_profession ON tb_user(profession(4))); -
高频模糊查询场景,建议使用全文索引(
FULLTEXT)替代普通索引; -
核心业务场景可引入 ES 等搜索引擎实现全文检索。
6.2.6 数据分布影响(MySQL 优化器放弃索引)
规则定义:当查询条件匹配的数据量超过表中总行数的约 20% 时,MySQL 优化器会评估使用索引的随机 IO 成本高于全表扫描的顺序 IO 成本,因此会放弃使用索引,直接进行全表扫描。
示例:
sql
-- 场景1:匹配数据量少,使用索引
SELECT * FROM tb_user WHERE phone >= '17799990005';
-- 场景2:匹配数据量超过20%,MySQL放弃索引,全表扫描
SELECT * FROM tb_user WHERE phone >= '17799990015';优化建议:
-
避免在低基数字段(如性别、状态)上创建索引,此类字段的查询几乎必然触发全表扫描;
-
对于大表的范围查询,可通过
FORCE INDEX强制使用索引,但需评估性能影响; -
定期分析表数据分布,避免索引因数据倾斜失效。
6.3 SQL 索引提示(人工干预优化器)
当 MySQL 优化器选择的索引不符合预期时,可通过索引提示强制指定索引,适用于复杂查询或优化器误判场景。
核心语法
sql
-- 1. USE INDEX:建议MySQL使用指定索引(优化器仍可能选择其他索引)
EXPLAIN SELECT * FROM tb_user USE INDEX(idx_user_pro) WHERE profession = '软件工程';
-- 2. IGNORE INDEX:忽略指定索引(让优化器不使用该索引)
EXPLAIN SELECT * FROM tb_user IGNORE INDEX(idx_user_pro) WHERE profession = '软件工程';
-- 3. FORCE INDEX:强制MySQL使用指定索引(优先级最高)
EXPLAIN SELECT * FROM tb_user FORCE INDEX(idx_user_pro) WHERE profession = '软件工程'使用场景:
-
优化器误判,选择了低效索引时;
-
多索引场景下,需人工干预指定最优索引;
-
临时验证不同索引的性能差异。
6.4 覆盖索引(性能天花板优化)
定义
覆盖索引是指查询所需的所有列,都能在索引中直接获取,无需回表查询聚集索引,避免了额外的 IO 操作,是 InnoDB 中性能最优的索引使用方式。
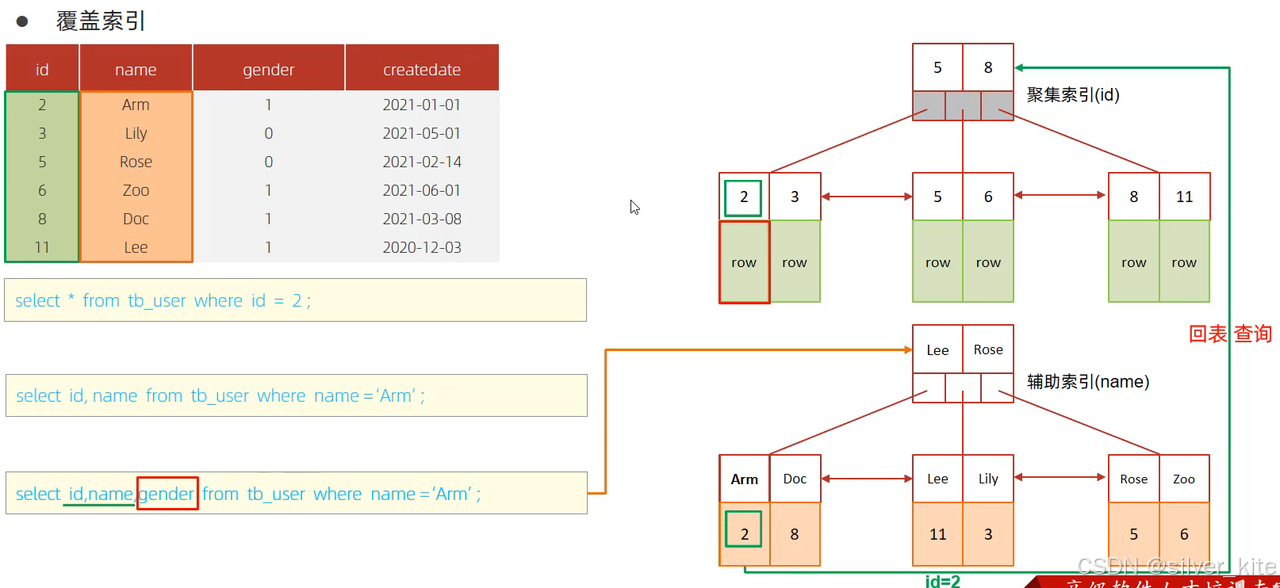
原理示例
以联合索引 idx_user_pro_age_sta(profession, age, status) 为例:
sql
-- 场景1:使用覆盖索引,无需回表(Extra显示Using index)
EXPLAIN SELECT id, profession FROM tb_user WHERE profession = '软件工程' AND age = 31 AND status = '0';
-- 场景2:索引列+主键,同样是覆盖索引(InnoDB二级索引默认包含主键)
EXPLAIN SELECT id, profession, age, status FROM tb_user WHERE profession = '软件工程' AND age = 31 AND status = '0';
-- 场景3:查询包含非索引列,需要回表(Extra无Using index)
EXPLAIN SELECT id, profession, age, status, name FROM tb_user WHERE profession = '软件工程' AND age = 31 AND status = '0';
-- 场景4:SELECT * 查询,必然回表,无法使用覆盖索引
EXPLAIN SELECT * FROM tb_user WHERE profession = '软件工程' AND age = 31 AND status = '0';关键判断(Extra 字段):
-
Using index:使用了覆盖索引,无需回表,性能最优; -
Using index condition:使用了索引,但需要回表查询完整数据; -
无上述标识:未使用索引或仅使用了部分索引,需全表扫描或大量回表。
优化建议
-
避免使用
SELECT *,仅查询业务所需的列; -
高频查询场景,创建包含所有查询列的联合索引,实现覆盖索引;
-
二级索引默认包含主键,因此查询主键列无需额外回表。
6.5 高频真题:单条 SQL 的最优索引设计
题目背景
一张用户表 tb_user,包含字段 id, username, password, status,数据量较大,需对以下 SQL 进行优化:
sql
SELECT id, username, password FROM tb_user WHERE username = 'silverkite';最优方案设计
方案 1:普通单列索引(username)
sql
CREATE INDEX idx_tb_user_username ON tb_user(username);执行逻辑:
-
通过
idx_tb_user_username索引定位到username='itcast'对应的主键id; -
再通过
id回表查询聚集索引,获取username和password字段的值; -
存在额外的回表 IO 操作,性能中等。
方案 2:覆盖联合索引(最优方案)
sql
CREATE INDEX idx_tb_user_uname_pwd ON tb_user(username, password);执行逻辑(无回表,性能天花板):
-
联合索引
(username, password)中,已包含查询所需的所有字段:-
WHERE条件匹配username; -
SELECT需要的id(二级索引默认包含主键)、username、password全部在索引中;
-
-
MySQL 可直接通过索引完成数据读取,无需回表查询聚集索引,Extra 字段显示
Using index; -
无额外 IO 操作,性能最优,是该场景下的唯一最优解。
6.6 前缀索引优化(长字符串字段索引方案)
适用场景
当字段为VARCHAR/TEXT等长字符串类型时,直接创建全字段索引会导致索引体积过大,查询时 IO 成本高,可通过前缀索引仅对字符串的前 N 个字符创建索引,大幅节省索引空间并提升查询效率。
核心语法
sql
-- 为table_name表的column字段,取前n个字符创建前缀索引
CREATE INDEX idx_xxx ON table_name(column(n));前缀长度选择方法(核心:高选择性)
前缀长度的选择需保证索引的高选择性(即不重复值占比越高,索引效率越高),计算方式如下:
sql
-- 1. 全字段索引的选择性(最优为1,即唯一索引)
SELECT COUNT(DISTINCT email) / COUNT(*) FROM tb_user;
-- 2. 计算取前5个字符的选择性,对比全字段选择性,越接近越好
SELECT COUNT(DISTINCT SUBSTRING(email, 1, 5)) / COUNT(*) FROM tb_user;
-- 3. 当选择性接近全字段时,即可确定前缀长度(如n=5)
CREATE INDEX idx_tb_user_email ON tb_user(email(5));前缀索引查询流程示例
以SELECT * FROM tb_user WHERE email = '``lvbu666@163.com``';为例:
-
辅助索引
email(5)存储的是字符串前 5 个字符,如lvbu6; -
通过前缀索引定位到匹配的
email前缀,获取对应的主键id; -
回表查询聚集索引,校验完整的
email值是否匹配; -
若匹配成功,则返回数据。
优缺点与适用场景
|----------------|----------------------|------------------------------|
| 优点 | 缺点 | 适用场景 |
| 大幅降低索引体积,减少 IO | 无法使用覆盖索引,查询时需回表校验完整值 | 长字符串字段(如邮箱、URL),无法使用全字段索引的场景 |
| 提升索引创建与查询效率 | 若前缀选择性低,仍可能导致大量回表 | 高频前缀查询场景(如邮箱前缀、手机号前缀) |
6.7 单列索引 vs 联合索引:多条件查询选型
核心结论
在多条件查询场景中,优先使用 联合索引 ,而非多个单列索引,可避免 MySQL 优化器误判,同时实现覆盖索引优化。
场景对比
场景 1:多个单列索引
sql
-- 单列索引1
CREATE INDEX idx_tb_user_phone ON tb_user(phone);
-- 单列索引2
CREATE INDEX idx_tb_user_name ON tb_user(name);
-- 多条件查询
EXPLAIN SELECT id, phone, name FROM tb_user WHERE phone = '17799990010' AND name = '韩信';执行结果分析:
-
possible_keys中同时存在两个索引,但key仅选择了idx_tb_user_phone; -
MySQL 优化器会评估两个索引的效率,选择成本更低的索引(如
phone索引的基数更高); -
未被选择的索引完全失效,仅使用单个索引过滤,需在服务层额外过滤
name条件,效率低。
场景 2:联合索引(最优方案)
sql
-- 创建phone和name的联合索引
CREATE UNIQUE INDEX idx_tb_user_phone_name ON tb_user(phone, name);
-- 相同查询
EXPLAIN SELECT id, phone, name FROM tb_user WHERE phone = '17799990010' AND name = '韩信';执行结果分析:
-
直接使用联合索引
idx_tb_user_phone_name,同时匹配phone和name两个条件; -
索引中已包含
phone、name和主键id,若查询字段仅包含这三个,可实现覆盖索引,无需回表; -
避免了优化器的索引选择问题,性能稳定且高效。
选型决策树
-
多条件等值查询:优先创建联合索引,字段顺序遵循 "高频等值条件在前,范围条件在后";
-
单条件查询:创建单列索引即可;
-
多个单条件查询:避免创建多个单列索引,优先考虑覆盖索引或联合索引,减少索引数量,降低写操作的维护成本。
索引优化核心避坑清单
|--------|-------------|-------------------|
| 优化场景 | 错误做法 | 正确做法 |
| 多条件查询 | 创建多个单列索引 | 创建联合索引 |
| 长字符串字段 | 创建全字段索引 | 创建前缀索引,优先保证高选择性 |
| 高频查询 | 使用SELECT * | 仅查询业务字段,使用覆盖索引 |
| 联合索引 | 跳过最左列 | 调整查询条件,匹配最左前缀 |
| 模糊查询 | LIKE '%前缀' | 使用LIKE '前缀%'或前缀索引 |
七.索引设计原则
索引设计是SQL性能优化的根源性工作,优秀的索引设计可从源头避免慢SQL、全表扫描、回表查询等性能问题,而非事后补救。以下7条核心设计原则,覆盖业务开发全场景与面试高频考点,完全承接前文的索引原理、使用规则与优化实践。
7.1 原则一:优先为数据量大、查询频繁的表建立索引
核心逻辑
索引的核心价值是解决大数据量下的查询性能问题,需精准匹配场景,避免无效索引:
-
收益场景:表数据量≥10万行,且有高频业务查询,索引带来的查询性能提升,远大于索引维护的成本;
-
无效场景:仅几千行的小表(如系统配置表、数据字典表),全表扫描的成本极低,建索引反而会增加额外的维护开销,无实际性能收益。
实操避坑
-
不要为极少查询的冷数据归档表创建大量索引,仅需为归档筛选字段建少量索引即可;
-
不要为全量小表盲目建索引,优先通过业务逻辑优化替代索引。
7.2 原则二:优先为WHERE、ORDER BY、GROUP BY操作的字段建立索引
索引的核心价值是过滤数据、利用有序性避免额外排序,这三类操作是索引最核心的落地场景,直接决定SQL的性能上限。
分场景拆解
1.WHERE 查询条件字段
是索引最基础的使用场景,通过索引快速过滤数据,避免全表扫描,是所有索引设计的基础。
2.ORDER BY 排序字段
利用B+Tree索引天生的有序性,直接通过索引获取有序数据,避免MySQL生成临时文件做额外排序(执行计划Extra出现Using filesort),大幅降低CPU消耗。
3.GROUP BY 分组字段
分组操作的底层需要先对数据排序,再做聚合计算,索引可避免分组时创建临时表(执行计划Extra出现Using temporary),是分组查询优化的核心手段。
实操建议
多字段组合查询场景,优先创建联合索引,字段顺序遵循:WHERE 等值查询字段 → GROUP BY 分组字段 → ORDER BY 排序字段,可实现索引全流程覆盖,无额外排序、无临时表、无回表。
7.3 原则三:优先选择区分度(基数)高的列作为索引,优先唯一索引
核心定义
区分度(也叫选择性)= 字段不重复值的数量 / 表总行数,比值越接近1,区分度越高,索引的过滤效率越强。
-
唯一索引:区分度=1,是性能最优的索引,一次索引查找即可精准定位数据,无额外过滤开销;
-
低基数字段:如性别(男/女)、状态(0/1),区分度极低,索引过滤后仍需扫描大量数据,MySQL优化器大概率会放弃索引,直接全表扫描。
实操规范
1.建索引前先计算字段区分度,优先为区分度≥0.3的字段建索引:
sql
-- 计算字段区分度,越接近1越好
SELECT COUNT(DISTINCT 字段名) / COUNT(*) FROM 表名;2.业务中保证唯一性的字段(如手机号、身份证号、订单号),必须创建唯一索引,既保证数据唯一性,又获得最优查询性能;
3.低基数字段禁止单独建索引,可通过联合索引(和高区分度字段组合)实现优化。
7.4 原则四:长字符串字段,优先建立前缀索引
核心逻辑
当字段为VARCHAR(255)、TEXT等长字符串类型时,直接创建全字段索引会导致索引体积过大,磁盘IO成本极高;前缀索引仅对字符串的前N个字符创建索引,可大幅节省索引空间,提升索引查询效率。
实操规范
1.前缀长度选择核心:保证前缀的选择性接近全字段的选择性,平衡索引体积与过滤效率;
sql
-- 1. 全字段选择性
SELECT COUNT(DISTINCT email) / COUNT(*) FROM tb_user;
-- 2. 测试前10个字符的选择性,接近全字段即可确定前缀长度
SELECT COUNT(DISTINCT SUBSTRING(email, 1, 10)) / COUNT(*) FROM tb_user;
-- 3. 创建前缀索引
CREATE INDEX idx_user_email ON tb_user(email(10));2.适用场景:邮箱、URL、长文本标题等长字符串字段的等值查询;
3.避坑提醒:前缀索引无法实现覆盖索引,因为索引中仅存储了字段前缀,无完整值,查询时必须回表校验完整数据。
7.5 原则五:优先使用联合索引,减少单列索引
核心优势
-
降低维护成本:多个单列索引在数据增删改时,需要同步维护多个B+Tree结构;联合索引仅需维护一个索引结构,大幅降低写操作的性能损耗;
-
更容易实现 覆盖索引 :联合索引可包含查询所需的所有字段,直接实现
Using index,避免回表查询,是性能优化的核心手段; -
避免 优化器 误判:多条件查询时,多个单列索引仅会被优化器选择一个最优的,其余索引完全失效;联合索引可同时匹配多个查询条件,过滤效率更高。
设计规范
-
联合索引字段顺序严格遵循最左前缀法则 ,同时满足:高频等值查询字段在前、范围查询字段在后;
-
避免冗余索引:已存在联合索引
(a,b,c),则无需再创建(a)、(a,b)这类前缀子集索引,避免冗余开销; -
单表优先通过3-5个联合索引覆盖全量业务查询,而非创建十几个单列索引。
7.6 原则六:严格控制索引数量,索引不是越多越好
核心代价
索引的本质是「空间换时间」,过量索引会带来双重成本:
-
空间成本:每个索引都需要独立的磁盘存储空间,大表的索引总体积甚至会超过业务数据本身;
-
性能成本 :执行
INSERT/UPDATE/DELETE时,需要同步维护所有相关索引的B+Tree结构,保证有序性,索引越多,写操作耗时越长,数据库并发性能越差; -
优化成本:过多索引会增加MySQL查询优化器的选择成本,可能导致优化器选错索引,反而降低查询性能。
实操规范
-
单表索引数量严格控制在5个以内,核心业务表不超过8个;
-
定期清理无用索引:通过MySQL性能_schema监控索引使用频次,删除长期未被查询使用的冗余索引;
-
禁止为每个字段单独创建单列索引,优先通过联合索引覆盖多场景查询。
7.7 原则七:索引列优先设置NOT NULL约束
核心逻辑
-
优化器 判断更高效 :MySQL优化器处理
NULL值时,需要增加额外的空值判断逻辑,无法高效利用索引;明确NOT NULL的字段,优化器可更精准地生成执行计划; -
索引统计更准确 :
NULL值会影响索引的基数统计,导致优化器对查询成本的评估出现偏差,可能选错执行计划; -
存储成本更低 :InnoDB中,
NULL值需要额外的存储空间标记空值,NOT NULL字段可减少索引的存储体积,提升IO效率。
实操规范
-
建表时,所有索引列必须设置
NOT NULL约束,并搭配合理的默认值:字符串类型默认空字符串'',数字类型默认0; -
禁止用
NULL作为业务有效值,比如用0/1表示状态,而非用NULL表示「未设置」; -
若业务字段确实存在空值场景,可通过特殊值(如
-1、空字符串)替代NULL,保证索引列的NOT NULL约束。
索引设计
-
筛选目标表:锁定数据量大、查询频繁的核心业务表,小表/冷表不做过度设计;
-
提取关键字段 :梳理业务中高频使用的
WHERE过滤、ORDER BY排序、GROUP BY分组字段; -
评估字段质量:优先选择区分度高的字段,过滤低基数字段,长字符串字段设计前缀索引;
-
设计索引结构:优先创建联合索引,字段顺序匹配最左前缀法则,尽可能实现覆盖索引;
-
控制索引规模:单表索引不超过5个,删除冗余、无用索引;
-
完善字段约束 :所有索引列设置
NOT NULL约束与默认值,优化优化器执行计划。
三、SQL优化
一、插入数据优化(Insert 优化)
插入性能的核心瓶颈是磁盘 IO 与事务提交开销,通过以下 4 种方式可大幅提升批量插入效率:
1.1 批量插入(单语句多值插入)
优化逻辑
将多条数据合并为一条INSERT语句执行,减少客户端与数据库的交互次数,降低网络 IO 与 SQL 解析开销。
示例 SQL
sql
-- 低效方式:单条插入,多次交互
INSERT INTO tb_test VALUES(1, 'Tom');
INSERT INTO tb_test VALUES(2, 'Cat');
INSERT INTO tb_test VALUES(3, 'Jerry');
-- 高效方式:批量插入,单次交互
INSERT INTO tb_test VALUES(1, 'Tom'), (2, 'Cat'), (3, 'Jerry');实操规范
-
单条批量插入建议控制在100-1000 条数据,避免单条 SQL 过大导致解析超时或日志膨胀;
-
批量插入的数据需提前校验合法性,避免单条失败导致整批回滚。
1.2 手动提交事务(事务包裹批量插入)
优化逻辑
InnoDB 默认每条 SQL 都会自动提交事务(autocommit=1),频繁提交事务会产生大量 Redo 日志刷盘操作,通过手动开启事务,将多条插入包裹在一个事务中,仅需一次提交刷盘,大幅减少 IO 次数。
示例 SQL
sql
-- 开启事务
START TRANSACTION;
-- 批量插入数据
INSERT INTO tb_test VALUES(1, 'Tom'), (2, 'Cat'), (3, 'Jerry');
INSERT INTO tb_test VALUES(4, 'Tom'), (5, 'Cat'), (6, 'Jerry');
INSERT INTO tb_test VALUES(7, 'Tom'), (8, 'Cat'), (9, 'Jerry');
-- 统一提交事务,仅一次刷盘
COMMIT;实操规范
-
事务中插入数据量建议控制在1 万条以内,避免事务过大导致锁表、日志膨胀或崩溃恢复时间过长;
-
异常场景需配合
ROLLBACK回滚,保证数据一致性。
1.3 主键顺序插入(避免页分裂)
优化逻辑
InnoDB 中数据按主键顺序存储在 B+Tree 索引中,顺序插入时数据会追加到当前页的末尾,不会触发页分裂;乱序插入可能导致数据插入到已写满的页中,触发页分裂操作,带来额外的 IO 开销。
对比示例
sql
-- 乱序主键(低效,易触发页分裂):8, 1, 9, 21, 88, 2, 4, 15, 89, 5, 7, 3
-- 顺序主键(高效,无额外页分裂):1, 2, 3, 4, 5, 7, 8, 9, 15, 21, 88, 89底层原理:页分裂与页合并
1.页分裂 :当插入数据的主键值需要写入已写满的页时,InnoDB 会将当前页的数据分裂为两个页,移动数据并调整 B+Tree 结构,是插入性能的主要瓶颈之一;
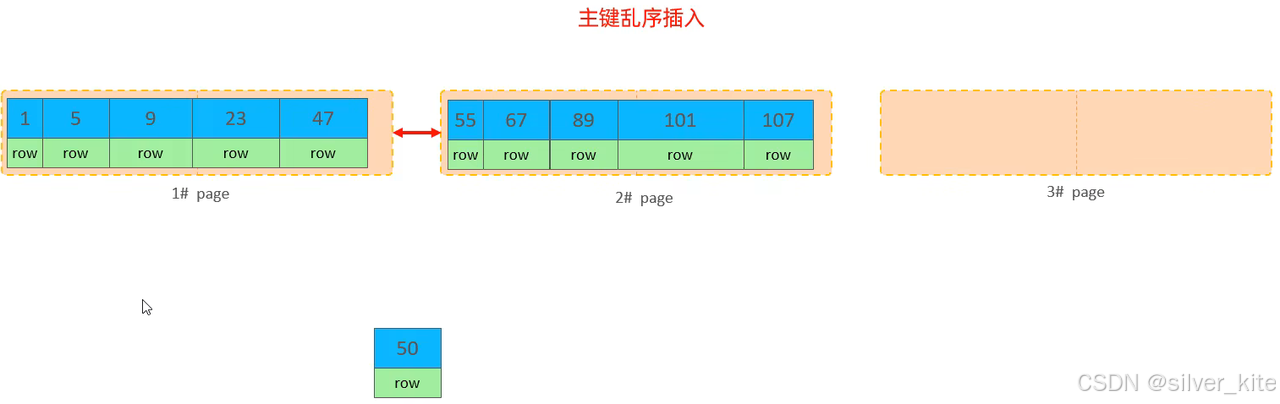

插入50,会落在1#page区域,但1#page空间不足,就会进行页分裂,先将1中一半数据放进3#page页中,再将50放入3页,然后调整页指针。
2.页合并 :当删除数据后,页中剩余数据低于MERGE_THRESHOLD(默认 50%)时,InnoDB 会尝试将相邻的页合并,减少碎片空间,优化存储效率。
1.4 大批量数据导入(LOAD DATA INFILE)
适用场景
一次性导入百万级以上的大批量数据,使用INSERT语句效率极低,推荐使用 MySQL 提供的LOAD DATA指令,直接从本地文件加载数据,跳过 SQL 解析阶段,性能提升可达数十倍。
操作步骤
1.客户端连接时开启本地文件加载权限:
sql
mysql --local-infile -u root -p2.全局开启本地文件导入开关:
sql
SET GLOBAL local_infile = 1;3.执行LOAD DATA指令导入数据:
sql
LOAD DATA LOCAL INFILE '/root/sql1.log'
INTO TABLE tb_user
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';注意事项
-
导入文件需提前按主键排序,避免导入过程中触发页分裂;
-
导入过程建议关闭索引,导入完成后再重建索引,减少导入过程中的索引维护开销。
二、主键优化(核心设计原则)
主键是 InnoDB 数据存储与索引的核心,主键设计直接影响数据插入、查询与更新的性能,需遵循以下 4 大核心原则:
2.1 降低主键长度(短主键优先)
优化逻辑
InnoDB 二级索引(辅助索引)中会包含主键值,主键越短,二级索引的体积越小,占用的磁盘空间越少,查询时 IO 效率越高。
实操建议
-
优先使用
INT/BIGINT类型的自增主键,避免使用长字符串(如 UUID、身份证号)作为主键; -
业务中无需暴露的主键,可使用无业务含义的自增 ID,避免主键长度过长。
2.2 优先使用自增主键(AUTO_INCREMENT)
优化逻辑
自增主键保证数据按顺序插入,数据会追加到当前页的末尾,不会触发页分裂操作,插入性能最优;乱序主键(如 UUID、随机 ID)会频繁触发页分裂,导致插入性能下降,同时产生大量存储碎片。
底层存储原理:索引组织表(IOT)
InnoDB 中表数据是根据主键顺序组织存放的,这种存储方式称为索引组织表(Index Organized Table, IOT),数据按主键顺序存储在 B+Tree 的叶子节点中,顺序插入可保持叶子节点的有序性与连续性,避免碎片产生。
实操规范
-
业务表主键统一使用
AUTO_INCREMENT自增主键,数据类型优先选择BIGINT UNSIGNED(范围更大,避免溢出); -
分布式场景需生成全局有序 ID 时,可使用雪花算法(保证时间戳部分有序),避免纯随机 UUID。
2.3 避免使用 UUID 或自然主键
优化逻辑
-
UUID:随机生成的 UUID 是乱序的,会导致频繁的页分裂,同时字符串类型的 UUID 长度较长,会增大二级索引的体积;
-
自然 主键(如身份证号、手机号):存在业务变更风险,且长度较长,无法保证插入顺序,同时可能因业务需求修改主键,导致数据与索引的整体调整,成本极高。
对比示例
|---------------|--------------------------|-----------------------------|
| 主键类型 | 优点 | 缺点 |
| 自增 INT/BIGINT | 顺序插入,无页分裂;主键短,索引体积小;性能最优 | 需单独维护,无业务含义 |
| UUID | 全局唯一,无需提前生成 | 乱序插入,频繁页分裂;长度长,索引体积大 |
| 自然主键(身份证号) | 无需额外字段,直接复用业务字段 | 长度长,索引体积大;存在业务变更风险;无法保证顺序插入 |
2.4 避免修改主键值
优化逻辑
主键是 InnoDB 数据存储的核心标识,修改主键值会导致:
-
数据行需要在 B+Tree 中移动位置,触发页分裂或页合并操作;
-
所有二级索引中存储的主键值都需要同步更新,维护成本极高,甚至可能导致索引失效。
实操规范
-
业务设计中,主键必须是无业务含义的字段,不参与任何业务逻辑,避免因业务变更修改主键;
-
若需修改业务标识字段(如手机号),直接更新对应字段即可,无需修改主键。
插入与主键优化总结
|-------|--------------------|---------------------|
| 场景 | 错误做法 | 正确做法 |
| 批量插入 | 逐条插入,频繁提交事务 | 批量插入 + 事务包裹 |
| 大批量导入 | 使用 INSERT 循环插入 | 使用 LOAD DATA INFILE |
| 主键设计 | 使用 UUID / 身份证号作为主键 | 使用自增 BIGINT 主键 |
| 主键插入 | 乱序插入 | 按主键顺序插入 |
| 主键修改 | 因业务需求修改主键值 | 主键无业务含义,永不修改 |
三、ORDER by 优化
排序操作是SQL性能的高频瓶颈,核心问题是避免Using filesort(文件排序),优先通过索引实现有序数据读取。
3.1 核心概念:两种排序方式
1.Using filesort:
非索引排序,通过全表扫描读取数据,在sort_buffer中完成排序操作,所有不通过索引直接返回有序结果的排序都属于文件排序,性能较差。
2.Using index:
利用有序索引直接扫描返回有序数据,无需额外排序,操作效率高,是排序优化的目标。
3.2 单字段/多字段排序优化
1. 无索引时的排序(低效)
sql
-- 无索引,触发Using filesort
explain select id,age,phone from tb_user order by age , phone;2. 创建联合索引优化(高效)
sql
-- 创建age、phone的联合索引,实现Using index
create index idx_user_age_phone_aa on tb_user(age,phone);
-- 升序排序:索引有序,无需额外排序
explain select id,age,phone from tb_user order by age , phone;
-- 同方向降序排序:索引支持,无需额外排序
explain select id,age,phone from tb_user order by age desc , phone desc;3. 升降序混合排序优化
当排序字段为一个升序、一个降序时,需创建匹配顺序的索引:
sql
-- 创建age升序、phone降序的索引
create index idx_user_age_phone_ad on tb_user(age asc ,phone desc);
-- 匹配索引顺序,实现Using index
explain select id,age,phone from tb_user order by age asc , phone desc;3.3 ORDER BY 优化核心原则
-
按排序字段创建合适的索引,多字段排序遵循最左前缀法则;
-
尽量使用 覆盖索引,避免回表操作;
-
多字段排序方向需与索引定义的方向匹配,避免混合升降序;
-
若无法避免
Using filesort,可适当增大排序缓冲区sort_buffer_size(默认256KB),提升排序性能。
四、GROUP BY 优化
分组操作的核心瓶颈是临时表创建与排序,可通过索引优化避免Using temporary。
4.1 索引优化原理
分组操作底层依赖数据有序性,索引的有序性可直接用于分组聚合,无需额外创建临时表。
4.2 实操示例
sql
-- 删除旧索引
drop index idx_user_pro_age_sta on tb_user;
-- 无索引分组,触发Using temporary
explain select profession , count(*) from tb_user group by profession ;
-- 创建(profession, age, status)联合索引
create index idx_user_pro_age_sta on tb_user(profession , age , status);
-- 匹配最左前缀,实现Using index,无临时表
explain select profession , count(*) from tb_user group by profession ;
explain select profession , count(*) from tb_user group by profession, age;
-- 带过滤条件的分组:where profession='软件工程' group by age
explain select age,count(*) from tb_user where profession = '软件工程' group by age;4.3 GROUP BY 优化核心原则
-
分组字段遵循最左前缀法则,优先创建包含分组字段的联合索引;
-
索引中包含查询所需的所有字段,实现覆盖索引;
-
过滤条件(
WHERE)字段需在分组字段之前,保证索引有序性; -
避免在低基数字段上进行分组,减少临时表创建的概率。
五、LIMIT 分页优化
大数据量下的分页查询(如limit 2000000,10)性能极差,需通过覆盖索引+子查询优化。
5.1 问题根源
limit m,n的执行逻辑是先读取前m+n条记录,再丢弃前m条,返回后n条,当m很大时,会产生大量无效IO。
5.2 优化方案:覆盖索引+子查询
sql
-- 低效方式:直接分页查询,全表扫描排序
select * from tb_sku limit 2000000,10;
-- 高效方式:先通过覆盖索引获取id,再关联查询完整数据
explain select * from tb_sku t ,
(select id from tb_sku order by id limit 2000000,10) a
where t.id = a.id;5.3 优化核心原则
-
利用主键或唯一索引的有序性,通过子查询快速定位分页数据的ID;
-
避免
select *,仅在子查询中获取主键ID,减少数据读取量; -
对于超大分页,可通过
WHERE id > ? LIMIT n的方式优化,前提是主键连续有序。
六、COUNT 优化
COUNT操作的性能差异主要由存储引擎与使用方式决定,需根据业务场景选择最优方案。
6.1 存储引擎差异
-
MyISAM :直接将表总行数存储在磁盘中,
count(*)可直接返回结果,效率极高; -
InnoDB :不存储总行数,执行
count(*)时需遍历数据行进行计数,性能受数据量影响较大。
6.2 COUNT 用法效率对比
| 用法 | 执行逻辑 | 效率排序 |
|---|---|---|
COUNT(字段) |
遍历表,读取字段值并判断是否为NULL,不为NULL则计数 | 最低 |
COUNT(主键) |
遍历表,读取主键值(非NULL)并计数 | 较低 |
COUNT(1) |
遍历表,不读取字段值,直接按行计数 | 高 |
COUNT(*) |
优化处理,不读取字段值,直接按行计数 | 最高 |
结论 :优先使用COUNT(*),效率最优。
6.3 优化核心原则
-
优先使用
COUNT(*),避免使用COUNT(字段); -
高频统计场景可通过缓存(如Redis)或统计表预存计数结果;
-
带条件的计数查询,需为过滤条件创建索引,减少扫描行数。
七、UPDATE 优化
UPDATE操作的核心风险是行锁升级为表锁,导致并发性能下降,需通过索引保证行锁的有效性。
7.1 核心原理
InnoDB的行锁是针对索引加锁,而非针对记录加锁。若更新条件字段没有索引或索引失效,行锁会升级为表锁,严重影响并发性能。
7.2 实操示例
sql
-- 高效更新:主键索引条件,行锁,仅锁定id=1的记录
update student set no = '2000100100' where id = 1;
-- 低效更新:无索引的name字段,索引失效,行锁升级为表锁
update student set no = '2000100105' where name = '韦一笑';7.3 UPDATE 优化核心原则
-
更新条件字段必须有有效索引,避免索引失效导致表锁;
-
优先使用主键或唯一索引作为更新条件,保证行锁粒度最小;
-
避免批量更新无索引的条件字段,减少表锁的概率;
-
大表更新时,分批执行,避免长时间持有锁。
补充:SQL优化通用避坑清单
|------------|----------------------------|--------------------------|
| 场景 | 错误做法 | 正确做法 |
| ORDER BY | 混合升降序排序,无索引 | 创建匹配顺序的联合索引,使用覆盖索引 |
| GROUP BY | 无索引分组,触发临时表 | 创建包含分组字段的联合索引,遵循最左前缀 |
| LIMIT 分页 | 直接使用limit m,n,超大分页 | 覆盖索引+子查询定位ID,再关联查询 |
| COUNT | 使用COUNT(字段),InnoDB直接全表计数 | 使用COUNT(*),高频统计用缓存/预存表 |
| UPDATE | 无索引条件更新,行锁升级为表锁 | 使用主键/唯一索引作为更新条件,保证索引有效 |
四、视图、存储过程、触发器
一、视图
一、视图基础概念
1. 什么是视图?
视图是虚拟存在的表,它本身不存储真实数据,只保存了查询的SQL逻辑,数据在使用视图时动态从基表中生成。
-
本质:视图是
SELECT查询的封装,相当于给复杂查询起了个"别名"。 -
特点:
-
不占用实际存储空间,仅保存SQL定义;
-
视图的数据完全依赖基表,基表数据变化时,视图数据也会同步变化;
-
支持像普通表一样进行查询、修改(部分场景)操作。
-
二、视图的基础操作
1. 创建视图
sql
-- 语法格式
CREATE [OR REPLACE] VIEW 视图名称[(列名列表)]
AS SELECT语句
[WITH [CASCADED | LOCAL] CHECK OPTION];
-- 示例:创建视图,查询学生表中id<=20的数据
CREATE VIEW v_student_20
AS SELECT id, name FROM student WHERE id <= 20;-
OR REPLACE:如果视图已存在,则替换原有定义; -
WITH CHECK OPTION:视图更新/插入数据时,必须满足视图的查询条件,否则会报错。
2. 查询视图
sql
-- 查看视图的创建语句
SHOW CREATE VIEW v_student_20;
-- 查询视图数据(和普通表用法一致)
SELECT * FROM v_student_20 WHERE name LIKE '张%';3. 修改视图
sql
-- 方式一:CREATE OR REPLACE VIEW(推荐)
CREATE OR REPLACE VIEW v_student_20
AS SELECT id, name, age FROM student WHERE id <= 20;
-- 方式二:ALTER VIEW
ALTER VIEW v_student_20
AS SELECT id, name, age FROM student WHERE id <= 20;4. 删除视图
sql
-- 语法格式
DROP VIEW [IF EXISTS] 视图名称 [,视图名称] ...;
-- 示例
DROP VIEW IF EXISTS v_student_20;三、视图的检查选项(WITH CHECK OPTION)
当使用WITH CHECK OPTION创建视图时,MySQL会在视图的INSERT/UPDATE/DELETE操作中,检查数据是否符合视图的定义条件,不符合则拒绝执行。
对于多层嵌套视图,MySQL提供两种检查规则:
1. CASCADED(默认):级联检查
-
规则:检查当前视图和所有上层依赖视图的条件,只要有一层视图条件不满足,就会报错。
-
示例:
sql-- 基表student -- 视图v1:id <= 20,带CASCADED检查 CREATE VIEW v1 AS SELECT id,name FROM student WHERE id <= 20 WITH CASCADED CHECK OPTION; -- 视图v2:基于v1,id >= 10,带CASCADED检查 CREATE VIEW v2 AS SELECT id,name FROM v1 WHERE id >= 10 WITH CASCADED CHECK OPTION; -- 视图v3:基于v2,id <= 15,无检查 CREATE VIEW v3 AS SELECT id,name FROM v2 WHERE id <= 15; -- 尝试向v3插入id=21的数据:会触发检查,不符合v1的id<=20条件,插入失败 INSERT INTO v3(id,name) VALUES(21,'test');2.
LOCAL:仅检查当前视图 -
规则:只检查当前视图的条件,不检查上层依赖视图的条件(但上层视图带
CASCADED检查时,仍会触发级联检查)。 -
示例:
sql-- 基表student -- 视图v1:id <= 15,无检查 CREATE VIEW v1 AS SELECT id,name FROM student WHERE id <= 15; -- 视图v2:基于v1,id >= 10,带LOCAL检查 CREATE VIEW v2 AS SELECT id,name FROM v1 WHERE id >= 10 WITH LOCAL CHECK OPTION; -- 尝试向v2插入id=16的数据:满足v2的id>=10条件,但不满足v1的id<=15条件,插入失败(因为数据无法被v1查询到,视图数据不生效) INSERT INTO v2(id,name) VALUES(16,'test');
四、视图的更新规则
视图的更新(INSERT/UPDATE/DELETE)并非都能执行,核心前提是:视图中的行与基表中的行存在一对一的映射关系。
1. 不可更新的场景
如果视图定义中包含以下任意一项,则该视图无法更新:
-
包含聚合函数或窗口函数:
SUM()、MIN()、MAX()、COUNT()、ROW_NUMBER()等; -
包含
DISTINCT去重; -
包含
GROUP BY分组; -
包含
HAVING过滤; -
包含
UNION或UNION ALL; -
基于多个基表的连接查询(非单表视图);
-
视图的列是基表列的计算结果(如
age+1)。
2. 可更新的场景
-
单表视图,无聚合、分组、去重等操作;
-
视图列与基表列一一对应,无计算列;
-
若使用
WITH CHECK OPTION,更新/插入的数据必须满足视图的查询条件。
五、视图的核心作用
1. 简化操作(Simple)
-
封装复杂查询:将常用的多表连接、条件过滤查询定义为视图,后续直接查询视图即可,无需重复编写SQL;
-
示例:把
JOIN + WHERE + GROUP BY的复杂报表查询封装为视图,业务人员直接查询视图即可获取数据。
2. 安全控制(Security)
-
实现行级/列级权限控制:数据库无法直接对特定行/列授权,但可以通过视图实现;
-
示例:创建视图仅包含用户的非敏感字段(如隐藏手机号、身份证号),并仅展示当前用户的数据,给业务人员授予视图的查询权限,避免敏感数据泄露。
3. 数据独立(Data Independence)
-
屏蔽基表结构变化:基表的字段名、字段顺序调整时,只需修改视图定义,上层业务代码无需修改;
-
示例:基表
student的name字段重命名为stu_name,只需修改视图的SELECT stu_name AS name,上层查询视图的业务代码无需改动。
六、视图的优缺点与使用建议
优点
-
简化复杂查询,提升开发效率;
-
实现数据权限控制,保障数据安全;
-
解耦基表与上层业务,降低维护成本。
缺点
-
视图本身不优化查询,执行视图时仍会执行基表的查询逻辑,复杂视图可能存在性能问题;
-
多层嵌套视图会增加查询的复杂度,调试困难;
-
视图更新限制多,不适合频繁修改基表数据的场景。
使用建议
-
优先用视图封装只读 查询(如报表、统计),避免用于写操作;
-
避免多层嵌套视图,建议不超过2层;
-
复杂查询优先直接编写SQL,视图仅用于简化高频、固定的查询场景。
二、存储过程
一、存储过程基础概念
1. 什么是存储过程?
存储过程是一组预编译并存储在数据库中的 SQL 语句集合,相当于数据库层面的"函数"。调用时只需传入参数即可执行封装好的逻辑,无需重复编写SQL。
-
核心思想:SQL语句的封装与复用;
-
优势:减少应用与数据库的网络交互、提升数据处理效率、简化开发操作。
二、存储过程基础操作
1. 创建存储过程
语法格式
sql
-- 命令行中需先修改结束符(避免和默认;冲突)
DELIMITER //
CREATE PROCEDURE 存储过程名称([参数列表])
BEGIN
-- 存储过程内的SQL逻辑
END //
DELIMITER ; -- 恢复默认结束符示例:无参数存储过程
sql
-- 示例:查询用户表的总数
DELIMITER //
CREATE PROCEDURE sp_get_user_count()
BEGIN
SELECT COUNT(*) AS user_total FROM tb_user;
END //
DELIMITER ;2. 调用存储过程
语法格式
sql
CALL 存储过程名称([参数]);示例:调用上面创建的存储过程
sql
CALL sp_get_user_count();3. 查看存储过程
sql
-- 1. 查看指定数据库的所有存储过程信息
SELECT * FROM INFORMATION_SCHEMA.ROUTINES WHERE ROUTINE_SCHEMA = 'test_db';
-- 2. 查看单个存储过程的创建语句
SHOW CREATE PROCEDURE sp_get_user_count;4. 删除存储过程
语法格式
sql
DROP PROCEDURE [IF EXISTS] 存储过程名称;示例
sql
DROP PROCEDURE IF EXISTS sp_get_user_count;三、存储过程的参数类型
存储过程支持3种参数类型,满足输入、输出、双向交互需求:
|---------|-----------------|--------|
| 参数类型 | 含义 | 备注 |
| IN | 输入参数,调用时传入值 | 默认类型 |
| OUT | 输出参数,用于返回结果 | 需用变量接收 |
| INOUT | 既可以作为输入,也可以作为输出 | 双向参数 |
示例1:带 IN 输入参数的存储过程
sql
-- 示例:根据用户id查询用户信息
DELIMITER //
CREATE PROCEDURE sp_get_user_by_id(IN p_user_id INT)
BEGIN
SELECT * FROM tb_user WHERE id = p_user_id;
END //
DELIMITER ;
-- 调用
CALL sp_get_user_by_id(1);示例2:带 OUT 输出参数的存储过程
sql
-- 示例:查询用户总数,并通过输出参数返回
DELIMITER //
CREATE PROCEDURE sp_get_user_count_out(OUT p_total INT)
BEGIN
SELECT COUNT(*) INTO p_total FROM tb_user;
END //
DELIMITER ;
-- 调用:用用户变量接收返回值
CALL sp_get_user_count_out(@user_count);
SELECT @user_count AS user_total;示例3:带 INOUT 双向参数的存储过程
sql
-- 示例:传入一个数字,将其乘以2后返回
DELIMITER //
CREATE PROCEDURE sp_double_num(INOUT p_num INT)
BEGIN
SET p_num = p_num * 2;
END //
DELIMITER ;
-- 调用
SET @num = 10;
CALL sp_double_num(@num);
SELECT @num AS doubled_num; -- 结果为20四、存储过程中的变量
MySQL存储过程中包含三类变量:系统变量、用户定义变量、局部变量。
1. 系统变量
MySQL服务器提供的内置变量,分为全局变量(GLOBAL)和会话变量(SESSION)。
查看系统变量
sql
-- 查看所有会话变量
SHOW SESSION VARIABLES;
-- 模糊查找变量(如查看排序缓冲区大小)
SHOW VARIABLES LIKE 'sort_buffer_size';
-- 查看指定变量的值
SELECT @@global.sort_buffer_size; -- 全局变量
SELECT @@session.sort_buffer_size; -- 会话变量设置系统变量
sql
-- 设置会话级变量(仅当前会话生效)
SET SESSION sort_buffer_size = 1024*1024; -- 1MB
-- 设置全局变量(重启后失效,需修改配置文件永久生效)
SET GLOBAL sort_buffer_size = 2*1024*1024; -- 2MB2. 用户定义变量
用户自定义的会话级变量,无需提前声明,直接用@变量名使用,作用域为当前会话。
赋值与使用
sql
-- 方式1:SET赋值
SET @user_name = 'zhangsan';
SET @age := 18; -- := 也可赋值
-- 方式2:SELECT INTO赋值
SELECT name, age INTO @user_name, @user_age FROM tb_user WHERE id = 1;
-- 使用变量
SELECT * FROM tb_user WHERE name = @user_name;3. 局部变量
存储过程内的局部变量,需用DECLARE声明,作用域为BEGIN...END块内。
声明与赋值
sql
DELIMITER //
CREATE PROCEDURE sp_local_var_demo()
BEGIN
-- 声明局部变量,指定类型和默认值
DECLARE v_total INT DEFAULT 0;
DECLARE v_name VARCHAR(20);
-- 赋值
SELECT COUNT(*) INTO v_total FROM tb_user;
SET v_name = 'local_test';
-- 使用变量
SELECT v_total, v_name;
END //
DELIMITER ;
CALL sp_local_var_demo();五、存储过程中的流程控制
1. IF条件语句
语法格式
sql
IF 条件1 THEN
-- 条件1成立时执行
ELSEIF 条件2 THEN
-- 条件2成立时执行(可选)
ELSE
-- 所有条件不成立时执行(可选)
END IF;示例:根据用户数量判断用户规模
sql
DELIMITER //
CREATE PROCEDURE sp_user_scale()
BEGIN
DECLARE v_count INT DEFAULT 0;
DECLARE v_scale VARCHAR(20);
SELECT COUNT(*) INTO v_count FROM tb_user;
IF v_count > 1000 THEN
SET v_scale = '大规模用户';
ELSEIF v_count > 100 THEN
SET v_scale = '中规模用户';
ELSE
SET v_scale = '小规模用户';
END IF;
SELECT v_count, v_scale;
END //
DELIMITER ;
CALL sp_user_scale();2. CASE条件语句
支持两种语法格式,适合多分支条件判断。
语法格式1:匹配固定值
sql
CASE case_value
WHEN when_value1 THEN statement_list1
WHEN when_value2 THEN statement_list2
ELSE statement_list
END CASE;语法格式2:匹配条件表达式
sql
CASE
WHEN search_condition1 THEN statement_list1
WHEN search_condition2 THEN statement_list2
ELSE statement_list
END CASE;示例:根据用户等级返回描述
sql
DELIMITER //
CREATE PROCEDURE sp_user_level_desc(IN p_level INT, OUT p_desc VARCHAR(20))
BEGIN
CASE p_level
WHEN 1 THEN SET p_desc = '普通用户';
WHEN 2 THEN SET p_desc = 'VIP用户';
WHEN 3 THEN SET p_desc = 'SVIP用户';
ELSE SET p_desc = '未知等级';
END CASE;
END //
DELIMITER ;
-- 调用
CALL sp_user_level_desc(2, @level_desc);
SELECT @level_desc; -- 结果为VIP用户六、存储过程中的循环语句
MySQL 存储过程支持 3 种循环:WHILE、REPEAT、LOOP,适用于不同场景的批量数据处理。
1. WHILE 循环(先判断,后执行)
语法格式
sql
WHILE 条件 DO
-- 循环体SQL逻辑
END WHILE;示例:批量插入 10 条测试用户数据
sql
DELIMITER //
CREATE PROCEDURE sp_batch_insert_user()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 10 DO
INSERT INTO tb_user (name, age) VALUES (CONCAT('test_', i), 18 + i);
SET i = i + 1; -- 必须更新计数器,否则会死循环
END WHILE;
END //
DELIMITER ;
-- 调用执行
CALL sp_batch_insert_user();2. REPEAT 循环(先执行,后判断)
语法格式
sql
REPEAT
-- 循环体SQL逻辑
UNTIL 条件 -- 条件满足时退出循环
END REPEAT;示例:批量插入 10 条测试用户数据(REPEAT 实现)
sql
DELIMITER //
CREATE PROCEDURE sp_repeat_insert_user()
BEGIN
DECLARE i INT DEFAULT 1;
REPEAT
INSERT INTO tb_user (name, age) VALUES (CONCAT('repeat_', i), 20 + i);
SET i = i + 1;
UNTIL i > 10 -- i>10时退出循环
END REPEAT;
END //
DELIMITER ;
-- 调用执行
CALL sp_repeat_insert_user();3. LOOP 循环(无条件循环,需手动退出)
语法格式
sql
[begin_label:] LOOP
-- 循环体SQL逻辑
-- 需用LEAVE手动退出循环,否则会死循环
END LOOP [end_label];-
LEAVE label:退出指定标签的循环; -
ITERATE label:跳过当前循环,直接进入下一次循环。
示例:LOOP 循环实现批量插入,含跳过逻辑
sql
DELIMITER //
CREATE PROCEDURE sp_loop_insert_user()
BEGIN
DECLARE i INT DEFAULT 1;
loop_label: LOOP -- 定义循环标签
IF i > 10 THEN
LEAVE loop_label; -- 条件满足时退出循环
END IF;
-- 跳过偶数次插入,只插入奇数
IF i % 2 = 0 THEN
SET i = i + 1;
ITERATE loop_label; -- 跳过当前循环,直接下一次
END IF;
INSERT INTO tb_user (name, age) VALUES (CONCAT('loop_', i), 25 + i);
SET i = i + 1;
END LOOP loop_label;
END //
DELIMITER ;
-- 调用执行
CALL sp_loop_insert_user();七、游标(CURSOR):遍历结果集
游标用于存储查询结果集,可在存储过程中逐行处理数据,适合批量数据处理场景。
游标使用步骤
-
声明 游标:绑定查询语句;
-
打开 游标:执行查询,获取结果集;
-
获取数据:逐行读取结果集数据到变量;
-
关闭 游标:释放资源。
语法格式
sql
-- 1. 声明游标
DECLARE 游标名称 CURSOR FOR 查询语句;
-- 2. 打开游标
OPEN 游标名称;
-- 3. 获取数据
FETCH 游标名称 INTO 变量1, 变量2...;
-- 4. 关闭游标
CLOSE 游标名称;八、条件处理程序(异常处理)
条件处理程序(Handler)用于捕获存储过程执行中的异常,并定义处理逻辑,避免程序因异常中断。
语法格式
sql
DECLARE handler_action HANDLER FOR condition_value [, condition_value] ... statement;-
handler_action:-
CONTINUE:捕获异常后继续执行后续代码; -
EXIT:捕获异常后终止当前存储过程;
-
-
condition_value:异常条件,支持:-
SQLSTATE 'xxxx':指定 SQL 状态码(如02000表示 NOT FOUND); -
SQLWARNING:捕获所有以01开头的警告; -
NOT FOUND:捕获所有以02开头的未找到数据异常; -
SQLEXCEPTION:捕获所有其他 SQL 异常。
-
示例:捕获异常并记录日志
sql
-- 先创建日志表
CREATE TABLE IF NOT EXISTS proc_log (
id INT AUTO_INCREMENT PRIMARY KEY,
error_msg VARCHAR(200),
create_time DATETIME DEFAULT CURRENT_TIMESTAMP
);
DELIMITER //
CREATE PROCEDURE sp_exception_demo()
BEGIN
-- 声明异常处理:捕获异常后继续执行,并记录日志
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION
INSERT INTO proc_log (error_msg) VALUES ('执行存储过程时发生异常');
-- 可能出错的SQL:插入重复主键数据
INSERT INTO tb_user (id, name) VALUES (1, 'test_user');
SELECT '执行完成' AS result;
END //
DELIMITER ;
-- 调用执行(若id=1已存在,会触发异常,但程序会继续执行并记录日志)
CALL sp_exception_demo();
-- 查看日志
SELECT * FROM proc_log;九、存储过程完整实战示例:批量处理用户数据
综合使用变量、循环、游标、异常处理,实现一个完整的批量数据处理存储过程:
sql
DELIMITER //
CREATE PROCEDURE sp_user_batch_process(IN p_start_id INT, IN p_end_id INT)
BEGIN
-- 1. 声明变量
DECLARE v_id INT;
DECLARE v_age INT;
DECLARE done INT DEFAULT FALSE;
DECLARE update_count INT DEFAULT 0;
-- 2. 声明游标和异常处理
DECLARE user_cursor CURSOR FOR
SELECT id, age FROM tb_user WHERE id BETWEEN p_start_id AND p_end_id;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
DECLARE EXIT HANDLER FOR SQLEXCEPTION
INSERT INTO proc_log (error_msg) VALUES (CONCAT('批量处理用户数据异常,范围:', p_start_id, '-', p_end_id));
-- 3. 打开游标,遍历处理
OPEN user_cursor;
user_loop: LOOP
FETCH user_cursor INTO v_id, v_age;
IF done THEN
LEAVE user_loop;
END IF;
-- 业务逻辑:年龄>30的用户,标记为VIP
IF v_age > 30 THEN
UPDATE tb_user SET is_vip = 1 WHERE id = v_id;
SET update_count = update_count + 1;
END IF;
END LOOP;
CLOSE user_cursor;
-- 4. 返回处理结果
SELECT CONCAT('批量处理完成,共更新', update_count, '条数据') AS result;
END //
DELIMITER ;
-- 调用:处理id 1-100的用户数据
CALL sp_user_batch_process(1, 100);十、存储过程使用注意事项
-
循环控制 :
WHILE/REPEAT/LOOP循环中必须有计数器更新或退出条件,否则会导致死循环; -
游标 资源 :使用完游标后必须
CLOSE,否则会占用数据库资源; -
异常处理:批量数据处理时建议添加异常处理,避免单条数据异常导致整个批量任务中断;
-
性能问题:存储过程内避免大事务、长循环,防止锁表或影响数据库性能;
-
调试建议:MySQL 存储过程调试困难,复杂逻辑建议分步测试,先验证单条 SQL 再封装。
三、存储函数
1. 核心概念
存储函数是有返回值的存储过程 ,它的参数只能是 IN 类型,且必须通过 RETURN 语句返回一个结果。
它可以像普通内置函数一样,直接在 SELECT 语句中调用。
2. 语法格式
sql
CREATE FUNCTION 存储函数名称([参数列表])
RETURNS type [characteristic ...]
BEGIN
-- SQL语句
RETURN ...; -- 必须有RETURN语句
END;关键字说明
-
RETURNS type:指定函数的返回值类型(如INT,VARCHAR,DECIMAL等)。 -
characteristic:特性说明,用于优化和约束函数行为:-
DETERMINISTIC:相同输入参数总是产生相同结果(纯函数)。 -
NO SQL:函数体内不包含任何SQL语句。 -
READS SQL DATA:函数体内只包含读数据的语句,不包含写数据的语句。
-
3. 基础示例
示例1:无参数的存储函数
sql
-- 示例:获取当前系统日期
DELIMITER //
CREATE FUNCTION fn_get_current_date()
RETURNS DATE
NO SQL
BEGIN
RETURN CURDATE();
END //
DELIMITER ;
-- 调用
SELECT fn_get_current_date();示例2:带参数的存储函数
sql
-- 示例:根据用户ID查询用户年龄
DELIMITER //
CREATE FUNCTION fn_get_user_age(p_user_id INT)
RETURNS INT
READS SQL DATA
BEGIN
DECLARE v_age INT;
SELECT age INTO v_age FROM tb_user WHERE id = p_user_id;
RETURN v_age;
END //
DELIMITER ;
-- 调用
SELECT fn_get_user_age(1);4. 与存储过程的核心区别
|----------|---------------------------------|-------------------|
| 对比项 | 存储过程(PROCEDURE) | 存储函数(FUNCTION) |
| 返回值 | 可以无返回值,也可通过 OUT/INOUT 参数返回多个值 | 必须有且仅有一个返回值 |
| 参数类型 | 支持 IN/OUT/INOUT | 仅支持 IN |
| 调用方式 | 使用 CALL 语句调用 | 可直接在 SELECT 中调用 |
| 适用场景 | 批量数据处理、复杂事务、多步操作 | 计算、查询单个值、可复用的业务规则 |
5. 使用注意事项
-
必须有返回值 :存储函数必须包含
RETURN语句,否则会报错。 -
参数限制 :函数参数默认是
IN类型,不能显式指定OUT或INOUT。 -
数据修改限制 :为了保证可在
SELECT中安全调用,存储函数内不建议 执行INSERT/UPDATE/DELETE等写操作,否则可能导致数据不一致。 -
权限要求 :创建存储函数需要
CREATE ROUTINE权限,调用时需要EXECUTE权限。
四、触发器
1. 核心概念
触发器是与表 关联的数据库对象,它会在 INSERT/UPDATE/DELETE 操作执行之前或之后,自动触发并执行预定义的SQL语句集合。
-
作用:在数据库端确保数据完整性、记录操作日志、数据校验、级联更新等。
-
特点:
-
仅支持行级触发(FOR EACH ROW),每操作一行触发一次;
-
使用
OLD和NEW关键字引用数据:
-
|----------|--------------|-------------|
| 触发器类型 | NEW(新数据) | OLD(旧数据) |
| INSERT | 表示将要/已新增的数据 | 无 |
| UPDATE | 表示将要/已修改后的数据 | 表示修改前的数据 |
| DELETE | 无 | 表示将要/已删除的数据 |
2. 语法格式
创建触发器
sql
CREATE TRIGGER trigger_name
BEFORE/AFTER INSERT/UPDATE/DELETE
ON tbl_name FOR EACH ROW -- 行级触发器
BEGIN
trigger_stmt; -- 触发时执行的SQL
END;查看触发器
sql
SHOW TRIGGERS;删除触发器
sql
DROP TRIGGER [IF EXISTS] [schema_name.]trigger_name;3. 实战示例:数据变更日志触发器
我们通过触发器实现 tb_user 表的增/改/删操作日志记录,将日志写入 user_logs 表。
步骤1:创建日志表
sql
CREATE TABLE user_logs(
id INT(11) NOT NULL AUTO_INCREMENT,
operation VARCHAR(20) NOT NULL COMMENT '操作类型, insert/update/delete',
operate_time DATETIME NOT NULL COMMENT '操作时间',
operate_id INT(11) NOT NULL COMMENT '操作的ID',
operate_params VARCHAR(500) COMMENT '操作参数',
PRIMARY KEY(`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;步骤2:创建INSERT触发器(记录新增日志)
sql
DELIMITER //
CREATE TRIGGER tb_user_insert_trigger
AFTER INSERT ON tb_user FOR EACH ROW
BEGIN
INSERT INTO user_logs(operation, operate_time, operate_id, operate_params)
VALUES(
'insert',
NOW(),
NEW.id,
CONCAT('新增数据:id=', NEW.id, ', name=', NEW.name, ', phone=', NEW.phone)
);
END //
DELIMITER ;步骤3:创建UPDATE触发器(记录修改日志)
sql
DELIMITER //
CREATE TRIGGER tb_user_update_trigger
AFTER UPDATE ON tb_user FOR EACH ROW
BEGIN
INSERT INTO user_logs(operation, operate_time, operate_id, operate_params)
VALUES(
'update',
NOW(),
NEW.id,
CONCAT('修改前:id=', OLD.id, ', name=', OLD.name, ' | 修改后:id=', NEW.id, ', name=', NEW.name)
);
END //
DELIMITER ;步骤4:创建DELETE触发器(记录删除日志)
sql
DELIMITER //
CREATE TRIGGER tb_user_delete_trigger
AFTER DELETE ON tb_user FOR EACH ROW
BEGIN
INSERT INTO user_logs(operation, operate_time, operate_id, operate_params)
VALUES(
'delete',
NOW(),
OLD.id,
CONCAT('删除数据:id=', OLD.id, ', name=', OLD.name, ', phone=', OLD.phone)
);
END //
DELIMITER ;测试触发器
sql
-- 1. 新增用户(触发insert触发器)
INSERT INTO tb_user(id, name, phone) VALUES(26, '张三', '18809091212');
-- 2. 修改用户(触发update触发器)
UPDATE tb_user SET name = '张三三' WHERE id = 26;
-- 3. 删除用户(触发delete触发器)
DELETE FROM tb_user WHERE id = 26;
-- 查看日志
SELECT * FROM user_logs;4. 使用注意事项
-
触发时机 :
BEFORE触发器可以修改NEW数据,也可以用于数据校验;AFTER触发器不能修改数据,适合做日志记录、级联操作。 -
OLD/NEW关键字:-
INSERT触发器中,只有NEW可用; -
DELETE触发器中,只有OLD可用; -
UPDATE触发器中,OLD和NEW都可用。
-
-
性能影响:触发器是行级触发,批量操作时会逐行触发,可能影响性能;复杂逻辑建议放在应用层。
-
循环触发风险:避免在触发器中对同一张表执行增删改操作,否则可能导致死循环。
5. 常见应用场景
-
数据审计:记录表中数据的所有变更操作(如用户日志、订单日志);
-
数据校验 :
BEFORE INSERT/UPDATE触发器中校验数据合法性(如年龄不能为负、手机号格式); -
级联 更新:主表数据修改/删除时,自动同步更新关联表数据;
-
数据同步:实时将一张表的数据同步到另一张表(如业务表到统计表)。
存储过程、存储函数、触发器尽量不要用,阿里范式不允许
开发中为什么尽量不用存储过程、存储函数、触发器(面试必背 + 通俗易懂整理)
一、统一核心原因总览
-
业务逻辑侵入数据库 ,把代码写在数据库里,违背前后端/应用层控制业务的设计思想。
-
调试难、维护难、排错极麻烦。
-
可移植性 极差,换数据库基本全要重写。
-
占用数据库性能,把计算、逻辑压力丢给DB,容易拖垮库。
-
版本管理困难,无法像代码一样Git版本控制、回滚。
-
分布式 、 微服务架构 下完全不适用。
二、存储过程 为什么不用
1. 业务逻辑下沉到数据库
业务逻辑本该写在 Java/PHP/Go 后端,存储过程把大量逻辑写死在DB里,业务分散、逻辑混乱,新人接手看不懂。
2. 调试极其困难
没有断点调试、没有日志跟踪,出问题只能靠猜、靠打印SQL,复杂流程排错成本极高。
3. 版本控制难
存储过程存在数据库里,不能Git管理,无法做版本迭代、快速回滚,上线、灰度都很麻烦。
4. 可移植性差
MySQL、Oracle、SQL Server 存储过程语法完全不一样,一旦换数据库,全部重写。
5. 加重数据库压力
复杂循环、计算、业务判断都在DB执行,DB本应只做存储和简单查询,不适合承载业务计算逻辑,容易造成CPU、连接数打满。
6. 微服务分布式不兼容
微服务提倡业务在服务层、数据只在DB,存储过程无法跨服务调用,也不方便做分布式事务、限流、熔断。
7. 并发与锁风险
存储过程里多SQL默认在一个事务,容易长事务、锁等待、死锁,线上隐患大。
三、存储函数 为什么不用
-
不能写复杂业务,功能有限,不如后端函数灵活。
-
无法做复杂逻辑、循环、外部调用。
-
在SQL中调用容易被滥用 ,嵌套在查询里会隐形增加查询开销,优化器难以预估成本。
-
同样难调试、难版本管理、难迁移。
-
禁止在函数里做增删改,容易引发主从延迟、数据不一致。
一句话:能用后端代码实现的计算,绝不写存储函数。
四、触发器 为什么坚决少用/不用
1. 隐式执行,逻辑"隐身"
触发器是自动偷偷执行 ,开发者写 insert/update/delete 时完全感知不到还有额外逻辑在跑,出了问题根本想不到是触发器导致的。
2. 排错极难
数据莫名其妙变了、莫名多了日志、莫名被修改,排查半天最后发现是触发器偷偷触发,隐蔽性太强,坑很多。
3. 性能损耗大
触发器是行级触发,批量插入1万条,就触发1万次,严重拖慢批量操作性能。
4. 容易触发循环嵌套死循环
A表触发器改B表,B表触发器又改A表,连环触发、死循环、锁表,线上事故高危。
5. 主从同步容易出问题
触发器在主库执行,从库复制可能重复触发,导致数据重复、不一致。
6. 不利于数据迁移和分库分表
分表、分库、数据迁移时,触发器逻辑容易被遗漏,导致数据行为不一致。
五、什么时候勉强可以用(仅老旧项目)
只有以下极少数场景可容忍:
-
老旧单体项目无法改造;
-
纯数据统计、报表固化逻辑;
-
仅做简单日志记录、数据校验,逻辑极简不复杂。
新项目、微服务、 分布式 项目:一律禁止使用。
六、面试极简背诵版
-
存储过程:业务下沉、难调试、难版本控制、不可移植、压垮数据库、微服务不适用。
-
存储函数:功能受限、隐藏开销、无法复杂业务、难维护。
-
触发器:隐式执行逻辑隐蔽、排错难、批量性能差、易循环触发、主从数据不一致。
-
统一原则:业务逻辑放应用层,数据库只负责存数据、查数据。
五、锁
一、锁的核心概念
锁是计算机协调多个进程/线程并发访问同一资源的机制。
在数据库中,除了CPU、内存、I/O等计算资源的争用,数据本身也是一种多用户共享资源。锁的核心目标是:
-
保证并发访问下的数据一致性、有效性;
-
锁冲突是影响数据库并发性能的关键因素。
二、MySQL锁的粒度分类
MySQL的锁按粒度从大到小分为三类:
|---------|-----------|-----------------|
| 锁类型 | 作用范围 | 特点 |
| 全局锁 | 锁定整个数据库实例 | 粒度最大,影响范围最广 |
| 表级锁 | 锁定整张表 | 粒度中等,不区分行,影响整张表 |
| 行级锁 | 锁定单条数据行 | 粒度最小,仅影响被操作的行 |
三、全局锁(Global Lock)
1. 介绍
全局锁会对整个数据库实例加锁,加锁后实例进入只读 状态,以下操作都会被阻塞:
-
DML写语句(
INSERT/UPDATE/DELETE) -
DDL语句(
CREATE/ALTER/DROP TABLE) -
已更新事务的提交语句
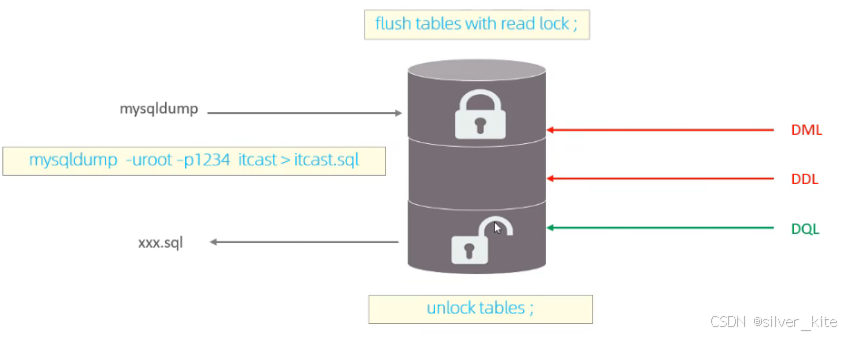
2. 典型场景:全库逻辑备份
当你执行 mysqldump 全库备份时,如果不加特殊参数,就会触发全局锁。
-
目的:获取一致性视图,保证备份数据的完整性;
-
问题:备份期间如果有业务写入,会导致备份前后数据不一致(如订单表备份到一半,库存表又被更新)。
3. 核心命令
sql
-- 加全局读锁(只读锁)
FLUSH TABLES WITH READ LOCK;
-- 释放全局锁
UNLOCK TABLES;4. 操作演示
sql
# 备份命令(传统方式,会加全局锁)
mysqldump -uroot -p1234 itcast > itcast.sql-
加锁后:
SELECT查询可以正常执行,INSERT/UPDATE/DELETE会被阻塞; -
解锁后:写入操作恢复执行。
5. 全局锁的问题与优化
问题
-
主库备份:备份期间无法执行更新操作,业务基本停摆;
-
从库备份:备份期间从库无法同步主库的binlog,导致主从延迟。
优化方案:InnoDB 不加锁备份
在 InnoDB 引擎中,使用 --single-transaction 参数实现不加锁的一致性备份:
sql
mysqldump --single-transaction -uroot -p123456 itcast > itcast.sql原理:利用 InnoDB 的事务隔离级别,在一个事务内完成一致性快照备份,全程不影响业务写入。
四、表级锁
一、表级锁概述
表级锁是MySQL中粒度最大的锁,每次操作直接锁定整张表:
-
优点:实现简单,无死锁;
-
缺点:锁冲突概率高,并发度最低;
-
适用引擎:MyISAM、InnoDB、BDB等。
表级锁主要分为三类:
-
表锁(显式表共享/排他锁)
-
元数据锁(MDL)
-
意向锁(InnoDB 自动维护)
二、表锁(显式表级锁)
1. 分类与兼容性
|-------------------|-------------------------|-----------------|
| 类型 | 加锁方式 | 兼容性说明 |
| 表共享读锁(Read Lock) | LOCK TABLES 表名 READ; | 不阻塞其他客户端的读,但阻塞写 |
| 表独占写锁(Write Lock) | LOCK TABLES 表名 WRITE; | 既阻塞其他客户端的读,也阻塞写 |
2. 核心语法
sql
-- 1. 加表锁
LOCK TABLES 表名 READ; -- 加共享读锁
LOCK TABLES 表名 WRITE; -- 加独占写锁
-- 2. 释放锁
UNLOCK TABLES; -- 手动释放
-- 客户端断开连接时,也会自动释放锁3. 工作机制图解
-
读锁 :其他客户端可以执行
SELECT,但INSERT/UPDATE/DELETE会被阻塞; -
写锁 :其他客户端的
SELECT和写操作都会被阻塞,只有持有锁的会话能读写。
三、元数据锁(MDL)
1. 核心概念
元数据锁(Meta Data Lock,MDL)是MySQL 5.5+自动维护的锁,无需显式使用,在访问表时自动加锁:
-
作用:维护表元数据的一致性,防止DML与DDL冲突;
-
核心规则:表上有活动事务时,不允许执行元数据写操作(如ALTER TABLE)。
2. 锁类型与对应SQL
|--------------------------------------------------|-------------------------------------------|-----------------------|
| 对应SQL | 锁类型 | 说明 |
| LOCK TABLES ... READ/WRITE | SHARED_READ_ONLY/SHARED_NO_READ_WRITE | 显式表锁 |
| SELECT / SELECT ... LOCK IN SHARE MODE | SHARED_READ | 与读/写兼容,与EXCLUSIVE互斥 |
| INSERT/UPDATE/DELETE / SELECT ... FOR UPDATE | SHARED_WRITE | 与读/写兼容,与EXCLUSIVE互斥 |
| ALTER TABLE ... | EXCLUSIVE | 与所有其他MDL锁互斥 |
3. 查看元数据锁
sql
SELECT object_type,object_schema,object_name,lock_type,lock_duration
FROM performance_schema.metadata_locks;四、意向锁(InnoDB 特有)
1. 核心作用
为了解决行锁与表锁的冲突检查效率问题,InnoDB引入了意向锁:
-
当事务给某行加锁时,会先在表上加对应的意向锁;
-
后续表锁请求只需检查表级意向锁,无需遍历所有行锁,大幅提升检查效率。
2. 意向锁分类与兼容性
|-----------|--------------------------------------------------|-----------------------|
| 锁类型 | 触发场景 | 兼容性说明 |
| 意向共享锁(IS) | SELECT ... LOCK IN SHARE MODE | 与表共享读锁兼容,与表独占写锁互斥 |
| 意向排他锁(IX) | INSERT/UPDATE/DELETE / SELECT ... FOR UPDATE | 与表共享读锁、写锁都互斥;意向锁之间不互斥 |
3. 查看意向锁与行锁
sql
SELECT object_schema,object_name,index_name,lock_type,lock_mode,lock_data
FROM performance_schema.data_locks;五、表级锁总结
-
表锁:手动加锁,读锁共享、写锁独占,并发度低;
-
MDL 锁:系统自动维护,防止DML与DDL冲突,是线上DDL阻塞的常见原因;
-
意向锁:InnoDB自动维护,用于优化表锁与行锁的冲突检查,不影响业务并发。
五、行级锁
1.行级锁概述
行级锁是 InnoDB 引擎独有的锁机制,每次操作仅锁定对应的行数据:
-
优点:粒度最小,锁冲突概率最低,并发度最高;
-
核心实现:行锁是对索引项加锁,而非直接对记录加锁;
-
三大类型:行锁(Record Lock)、间隙锁(Gap Lock)、临键锁(Next-Key Lock)。
2.行锁(Record Lock)
1. 分类与兼容性
行锁分为共享锁(S锁)和排他锁(X锁),兼容性如下:
|----------------------|------|------|
| 当前锁类型 | 请求S锁 | 请求X锁 |
| S( 共享锁 ) | 兼容 | 冲突 |
| X(排他锁) | 冲突 | 冲突 |
2. 触发场景与SQL示例
|---------------------------------|--------|------------|
| SQL语句 | 锁类型 | 说明 |
| INSERT / UPDATE / DELETE | 排他锁(X) | 自动加锁 |
| SELECT ... LOCK IN SHARE MODE | 共享锁(S) | 手动加锁 |
| SELECT ... FOR UPDATE | 排他锁(X) | 手动加锁 |
| 普通SELECT | 不加锁 | MVCC快照读,无锁 |
3. 示例1:共享锁(S锁)
sql
-- 事务A
BEGIN;
SELECT * FROM tb_user WHERE id = 1 LOCK IN SHARE MODE; -- 加S锁
-- 事务B
BEGIN;
SELECT * FROM tb_user WHERE id = 1 LOCK IN SHARE MODE; -- 可以加S锁(兼容)
UPDATE tb_user SET name = 'test' WHERE id = 1; -- 加X锁,被阻塞(冲突)4. 示例2:排他锁(X锁)
sql
-- 事务A
BEGIN;
UPDATE tb_user SET name = 'test' WHERE id = 1; -- 自动加X锁
-- 事务B
BEGIN;
SELECT * FROM tb_user WHERE id = 1 FOR UPDATE; -- 加X锁,被阻塞(冲突)
SELECT * FROM tb_user WHERE id = 1 LOCK IN SHARE MODE; -- 加S锁,被阻塞(冲突)5. 关键注意点
-
无索引会升级为表锁:不通过索引条件检索数据时,InnoDB会对表中所有记录加锁,相当于表锁;
-
唯一索引等值匹配会优化为行锁:对唯一索引的存在记录进行等值查询,仅锁定该记录。
3.间隙锁(Gap Lock)
1. 核心概念
间隙锁锁定索引记录的间隙(不含记录本身),目的是防止其他事务在该间隙插入数据,从而避免幻读,仅在RR隔离级别下生效。
2. 触发场景与示例
**示例1:**不存在记录的等值查询(唯一索引)
sql
-- 表中id为10、20、30,无id=15的记录
BEGIN;
SELECT * FROM tb_user WHERE id = 15 FOR UPDATE;
-- 触发间隙锁,锁定(10,20)之间的间隙,防止插入id=15的数据**示例2:**普通索引等值查询的边界场景
sql
-- 表中age为18、20、22,查询age=25(不存在)
BEGIN;
SELECT * FROM tb_user WHERE age = 25 FOR UPDATE;
-- 触发间隙锁,锁定(22, +∞)之间的间隙3. 关键注意点
-
间隙锁的唯一目的是防止其他事务插入间隙数据;
-
间隙锁可以共存,不同事务对同一间隙加间隙锁不会互相阻塞。
4.临键锁(Next-Key Lock)
1. 核心概念
临键锁是行锁 + 间隙锁的组合,同时锁定数据记录及其前面的间隙,是InnoDB在RR隔离级别下默认的锁机制,用于彻底防止幻读。
2. 触发场景与示例
**示例1:**范围查询(唯一索引)
sql
-- 表中id为10、20、30、40
BEGIN;
SELECT * FROM tb_user WHERE id > 20 AND id < 30 FOR UPDATE;
-- 触发临键锁,锁定:
-- 行锁:id=30(不满足条件的第一个值)
-- 间隙锁:(20,30)和(30,40)之间的间隙**示例2:**普通索引的范围查询
sql
-- 表中age为18、20、22、25
BEGIN;
SELECT * FROM tb_user WHERE age >= 20 FOR UPDATE;
-- 触发临键锁,锁定:
-- 行锁:age=20、22、25
-- 间隙锁:(18,20)、(20,22)、(22,25)、(25, +∞)3. 锁的优化规则
-
唯一索引等值匹配存在记录:优化为行锁;
-
唯一索引等值匹配不存在记录:优化为间隙锁;
-
普通索引等值查询边界不满足:临键锁退化为间隙锁;
-
范围查询(唯一/普通索引):默认使用临键锁。
5.查看锁信息
通过以下SQL可以查看意向锁、行锁、间隙锁的情况:
sql
SELECT object_schema,object_name,index_name,lock_type,lock_mode,lock_data
FROM performance_schema.data_locks;6.行级锁总结
|--------------------|--------------------|--------|
| 锁类型 | 作用 | 隔离级别 |
| 行锁(Record Lock) | 锁定单条记录,防止其他事务修改/删除 | RC/RR |
| 间隙锁(Gap Lock) | 锁定索引间隙,防止插入新数据 | RR |
| 临键锁(Next-Key Lock) | 行锁+间隙锁组合,彻底防止幻读 | RR(默认) |
六、死锁(产生原因+解决办法)
1.死锁概念
死锁 :两个或多个事务,互相持有对方需要的锁,又都不释放自己的锁,无限等待,谁也执行不下去。
InnoDB 会自动检测死锁,主动回滚代价更小的一个事务,让另一个正常执行。
2.死锁产生的四个必要条件(面试必背)
-
互斥 条件:锁同一资源不能同时占用;
-
请求保持:事务已持有锁,还去申请新锁;
-
不可剥夺:锁不能被强行抢走,只能自己释放;
-
循环等待 :事务间形成循环等待锁的环路。
四个条件同时满足,必然死锁。
3.死锁产生典型场景 + 完整示例
场景1:两个事务加锁顺序相反(最常见)
表 tb_user 有主键 id。
事务A
sql
BEGIN;
UPDATE tb_user SET name='a' WHERE id=1; -- 持有id=1行锁
UPDATE tb_user SET name='b' WHERE id=2; -- 等待事务B的id=2锁事务B
sql
BEGIN;
UPDATE tb_user SET name='b' WHERE id=2; -- 持有id=2行锁
UPDATE tb_user SET name='a' WHERE id=1; -- 等待事务A的id=1锁形成循环等待 → 直接 死锁。
场景2:索引失效,行锁升级为表锁引发死锁
字段无索引,更新变成表级排他锁,互相阻塞产生死锁。
事务A
sql
BEGIN;
UPDATE tb_user SET age=20 WHERE name='张三'; -- name无索引,锁整张表事务B
sql
BEGIN;
UPDATE tb_user SET age=25 WHERE name='李四'; -- 同样无索引,也锁整张表互相等待对方表锁,形成死锁。
场景3:RR隔离级别下 间隙锁 + 行锁 互相等待
普通索引范围查询产生临键锁/间隙锁,间隙之间互相占用,引发死锁。
4.如何查看死锁日志
sql
-- 查看最近一次死锁详情
SHOW ENGINE INNODB STATUS;在输出信息中找到 LATEST DETECTED DEADLOCK,可看到:
-
哪两个事务
-
各自持有什么锁、等待什么锁
-
最终回滚了哪个事务
5.死锁解决与规避方案
1. 统一SQL加锁顺序(最有效)
所有业务事务,必须按相同顺序访问表、访问行。
示例:
永远先操作 id=1,再操作 id=2,所有服务都遵守,从根源打破循环等待。
2. 避免事务过大、事务过长
-
事务里不要放无关业务逻辑;
-
尽量小事务、快提交,持有锁时间越短,死锁概率越低。
3. 确保条件字段有索引
更新/删除条件一定要走索引 ,避免行锁升级为表锁,大幅减少锁范围和冲突。
4. 业务层面加重试机制
捕获死锁异常后,间隔短暂时间自动重试,线上常用方案。
5. 尽量不用范围查询 FOR UPDATE
范围查询容易触发临键锁、间隙锁,锁范围放大,极易诱发死锁;
能用等值查询就不用范围。
6. 调低隔离级别(可选)
把隔离级别从 RR 降到 RC:
-
取消间隙锁、临键锁;
-
大幅减少死锁;
-
代价:可能出现幻读,业务能接受就可以用。
7. 避免同一事务重复加锁、交叉更新
不要在一个事务内多次更新同一张表不同行,减少锁竞争。
6.极简背诵
-
死锁四个条件:互斥 、请求保持、不可剥夺、循环等待。
-
最常见原因:事务加锁顺序不一致、无索引升级表锁、间隙锁冲突。
-
解决办法:
-
统一访问顺序;
-
小事务快提交;
-
保证索引有效;
-
业务增加重试;
-
必要时降级为RC隔离级别。
-
六、InnoDB引擎
一、逻辑存储结构
1.整体层级关系
InnoDB 的数据是按表空间 ( Tablespace **)→ 段(Segment)→ 区(Extent)→ 页(Page)→ 行(Row)**的层级组织。
2.各层级详解

3.层级关系与MVCC关联
-
数据组织:B+树索引的叶子节点就是数据段,由多个区组成,每个区包含64个页,每个页存储多行数据;
-
MVCC 支持 :行中的
trx_id和roll_pointer,配合回滚段的 undo log,实现了事务的一致性视图和多版本读取。
4.面试速记
-
层级顺序:表空间 → 段 → 区 → 页 → 行;
-
核心参数:区1MB、页16KB,1个区=64个页;
-
关键隐藏列 :
trx_id(事务ID)、roll_pointer(旧版本指针),用于MVCC; -
段的分类:数据段(叶子节点)、索引段(非叶子节点)、回滚段(undo log)。
二、架构篇
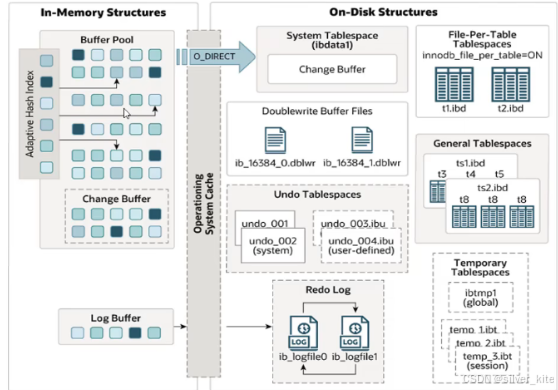
1.整体架构概览
InnoDB 架构分为三大核心部分:
-
内存 结构(In-Memory Structures):缓存数据、索引和日志,减少磁盘IO
-
磁盘结构(On-Disk Structures):持久化存储数据、日志和系统信息
-
后台线程(Background Threads):异步处理脏页刷新、日志同步、资源回收等任务
2.内存结构详解
1. Buffer Pool(缓冲池)

-
核心作用:主内存中缓存磁盘数据页的区域,是 InnoDB 性能的核心
-
工作机制:
-
增删改查优先操作缓冲池数据,减少磁盘IO
-
缓冲池无数据时,从磁盘加载并缓存
-
脏页按一定频率异步刷新到磁盘
-
-
页类型:
-
free page:空闲未使用的页 -
clean page:已使用且数据未修改的页 -
dirty page:已使用且数据已修改,与磁盘数据不一致的页
-
2. Change Buffer(更改缓冲区)
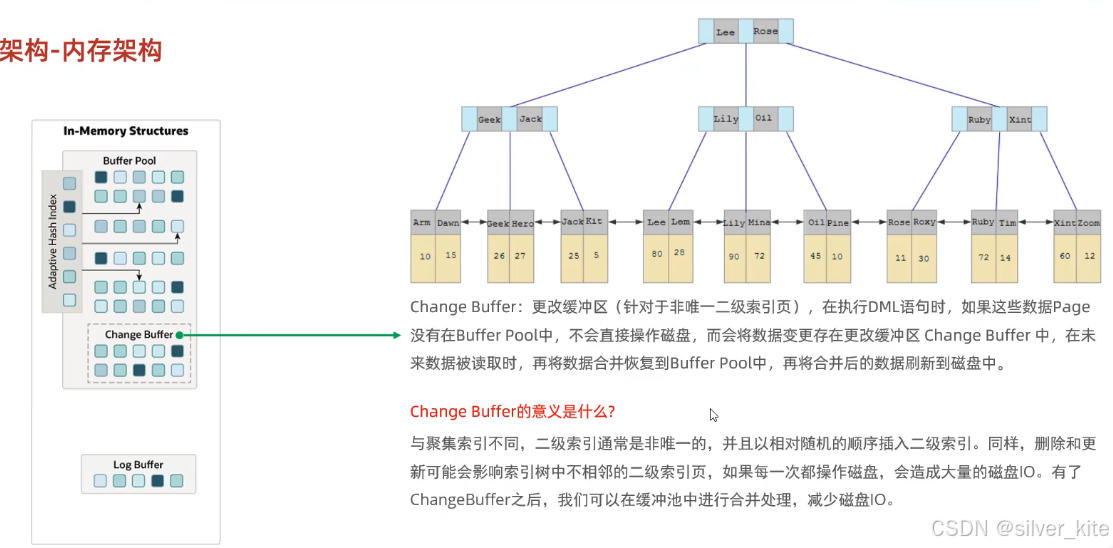
-
作用对象 :仅针对非唯一二级索引页
-
工作机制:DML操作时,若索引页不在缓冲池中,不直接操作磁盘,而是先存到Change Buffer;后续数据被读取时,再合并到缓冲池并刷新磁盘
-
核心意义:减少二级索引的随机磁盘IO,大幅提升写入性能
3. Adaptive Hash Index(自适应哈希索引)

-
作用:优化缓冲池数据的查询速度
-
机制:InnoDB自动监控索引页查询,当哈希索引能提升性能时,自动建立哈希索引,无需人工干预
-
控制参数 :
adaptive_hash_index(默认开启)
4. Log Buffer(日志缓冲区)

3.磁盘结构详解
1. 表空间(Tablespaces)

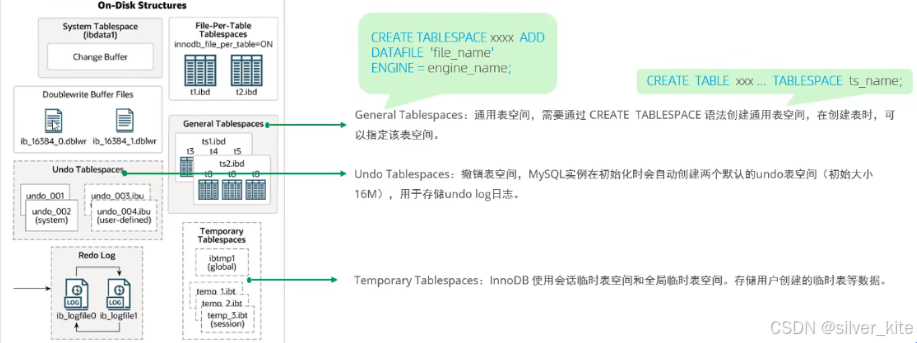
|-----------------------------------------------------|--------------------------------|----------------------------------------|
| 类型 | 作用 | 关键文件/参数 |
| 系统 表空间 (System Tablespace ) | 存储Change Buffer、数据字典、undo log等 | ibdata1,参数innodb_data_file_path |
| 独立 表空间 (File-Per-Table) | 每个表单独存储数据和索引,默认开启 | xxx.ibd,参数innodb_file_per_table=ON |
| 通用 表空间 (General Tablespaces ) | 自定义表空间,可指定多个表 | 需用CREATE TABLESPACE创建 |
| 撤销 表空间 (Undo Tablespaces ) | 存储undo log,支持事务回滚和MVCC | 默认两个16MB的文件undo_001/undo_002 |
| 临时 表空间 (Temporary Tablespaces ) | 存储临时表数据 | 全局ibtmp1和会话临时文件 |
2. Doublewrite Buffer Files(双写缓冲区)
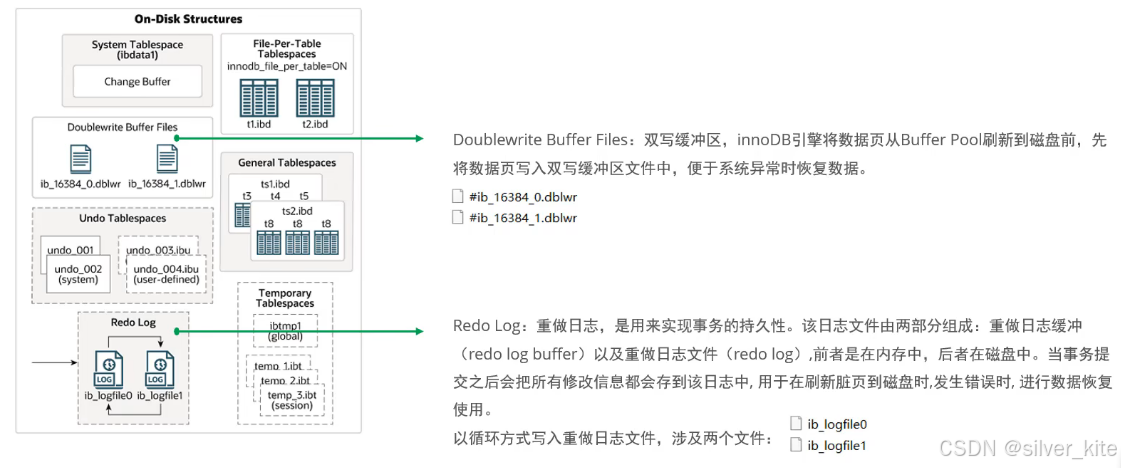
3. Redo Log(重做日志)
-
作用:实现事务持久性,崩溃恢复时重放修改
-
机制:事务提交后将修改写入redo log,脏页异步刷盘,刷盘失败时可通过redo log恢复
-
关键文件 :
ib_logfile0、ib_logfile1,以循环方式写入
4.后台线程
|-------------------------|---------------------------------------------|--------------------------|
| 线程类型 | 核心职责 | 说明 |
| Master Thread | 核心调度,异步刷新脏页、合并Change Buffer、回收undo页 | InnoDB主线程 |
| IO Thread | 处理AIO请求的回调,包括Read/Write/Log/Insert Buffer线程 | 默认配置:读4个、写4个、日志1个、插入缓冲1个 |
| Purge Thread | 回收已提交事务的undo log,释放空间 | 提升事务回滚和MVCC性能 |
| Page Cleaner Thread | 协助Master Thread刷新脏页,减轻主线程压力 | 减少主线程阻塞,提升并发性能 |
5.架构关键总结
-
内存 优先:所有读写优先操作缓冲池,日志暂存缓冲区,再异步刷盘
-
Change Buffer优化:非唯一二级索引写入性能的关键
-
Redo Log 保障:事务持久性的核心,崩溃恢复的基础
-
后台线程分工:脏页刷新、日志同步、资源回收全异步处理,不阻塞用户请求
三、事务原理
1.事务基础概念
事务是一组不可分割的操作集合,作为一个整体向系统提交或撤销请求:
-
要么全部操作同时成功 ,要么全部同时失败;
-
是数据库保证数据一致性的核心机制。
2.事务四大特性(ACID)
|--------------------------------|------------------------------|------------------|
| 特性 | 含义 | 实现机制 |
| 原子性(Atomicity) | 事务是最小操作单元,不可分割,要么全成、要么全败 | undo log(回滚日志) |
| 一致性( Consistency ) | 事务执行前后,数据必须保持一致状态(如转账前后总额不变) | 业务规则 + ACID共同保障 |
| 隔离性(Isolation) | 事务在不受外部并发操作影响的独立环境中运行 | 锁 + MVCC |
| 持久性(Durability) | 事务提交后,对数据的修改永久生效,不丢失 | redo log(重做日志) |
3.Redo Log(重做日志):实现持久性
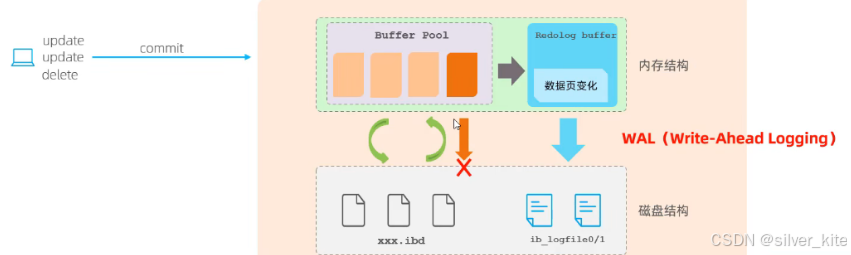
1. 核心作用
记录事务提交时数据页的物理修改,用于崩溃恢复,保障事务持久性。
2. 工作机制(WAL 预写日志)
-
WAL 原则:事务提交前,先写redo log,再异步刷脏页到磁盘;
-
结构分为两部分:
-
内存中:
redo log buffer(日志缓冲区) -
磁盘中:
ib_logfile0/ib_logfile1(重做日志文件,循环写入)
-
-
流程:事务提交 → 修改写入redo log buffer → 刷盘到redo log文件 → 脏页后续异步刷入数据文件;若刷盘失败,可通过redo log恢复数据。
4.Undo Log(回滚日志):实现原子性
1. 核心作用
记录数据修改前的状态,提供事务回滚 和MVCC 多版本并发控制。
2. 关键特点
-
属于逻辑日志 :不是物理页修改,而是反向操作记录(如
delete对应insert,update对应反向update); -
回滚时,可通过undo log中的反向操作恢复数据;
-
事务提交后不会立即删除undo log,因为可能还用于MVCC;
-
存储在回滚段(
rollback segment)中,每个回滚段包含1024个undo log段。
四、MVCC
1.MVCC基础概念
MVCC(Multi-Version Concurrency Control,多版本并发控制),是 InnoDB 实现读写不阻塞的核心机制:
-
维护数据的多个版本,使读写操作互不冲突;
-
快照读(普通SELECT)不加锁,大幅提升并发性能;
-
核心依赖:隐藏字段 + undo log版本链 + ReadView。
2.两种读模式
1. 当前读
读取记录的最新版本,并对记录加锁,保证其他事务无法修改。
-
触发场景:
-
SELECT ... LOCK IN SHARE MODE(共享锁) -
SELECT ... FOR UPDATE(排他锁) -
INSERT / UPDATE / DELETE(自动加排他锁)
-
2. 快照读
读取记录的可见版本(可能是历史数据),不加锁,是非阻塞读。
-
触发场景:普通
SELECT(无锁); -
不同隔离级别生成快照时机不同:
-
READ COMMITTED:每次SELECT都生成新快照; -
REPEATABLE READ:事务中第一次SELECT生成快照,后续复用; -
SERIALIZABLE:快照读退化为当前读。
-
3.MVCC实现三大支柱
1. 记录中的隐藏字段
每个InnoDB记录都包含三个隐藏字段:
|---------------|----------------------------|
| 字段名 | 作用 |
| DB_TRX_ID | 最近修改该记录的事务ID |
| DB_ROLL_PTR | 回滚指针,指向该记录的上一个版本(undo log) |
| DB_ROW_ID | 隐藏主键,无主键时自动生成 |
2. undo log版本链
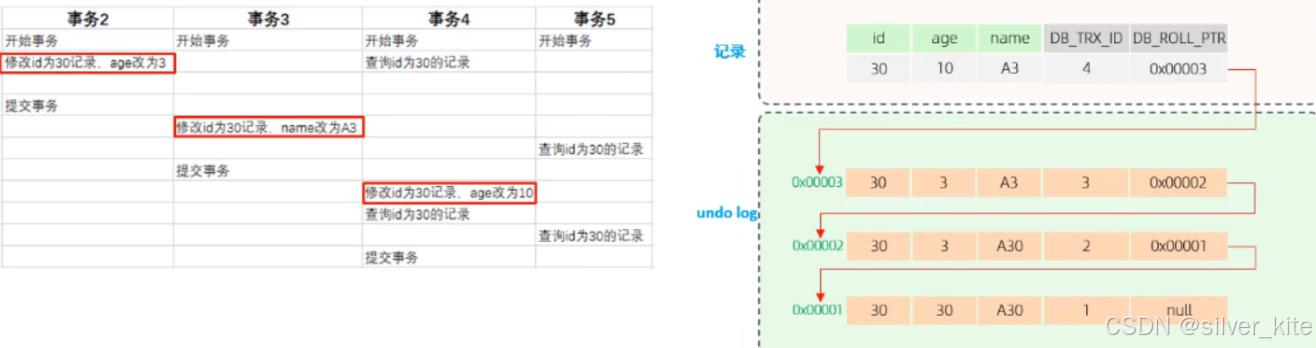
-
每次修改记录时,会生成旧版本数据,存入undo log;
-
通过
DB_ROLL_PTR将多个版本串联成一条版本链,链表头是最新版本,尾部是最早版本; -
事务提交后,undo log不会立即删除(因为快照读可能还需要),只有当没有任何事务引用该版本时,才会被Purge线程回收。
3. ReadView(读视图)
ReadView是快照读判断版本可见性的依据,记录当前系统中活跃的事务(未提交)ID集合,包含四个核心字段:
|------------------|---------------------|
| 字段 | 含义 |
| m_ids | 当前活跃事务ID集合 |
| min_trx_id | 最小活跃事务ID |
| max_trx_id | 预分配事务ID(当前最大事务ID+1) |
| creator_trx_id | 创建该ReadView的事务ID |
4.版本可见性判断规则
读取记录时,需遍历版本链,直到找到符合以下条件的版本:
-
trx_id == creator_trx_id:数据由当前事务修改,可见; -
trx_id < min_trx_id:事务已提交,可见; -
trx_id > max_trx_id:事务在ReadView生成后开启,不可见; -
min_trx_id <= trx_id <= max_trx_id:需判断trx_id是否在m_ids中:-
不在集合中:事务已提交,可见;
-
在集合中:事务未提交,不可见。
-
5.RC与RR隔离级别下的ReadView差异
|-------------------|--------------------------|-----------------------------------|
| 隔离级别 | ReadView生成时机 | 效果 |
| READ COMMITTED | 每次快照读都生成新的ReadView | 每次查询都能看到其他事务已提交的修改,解决不可重复读 |
| REPEATABLE READ | 事务中第一次快照读生成ReadView,后续复用 | 整个事务期间复用同一个ReadView,保证可重复读,同时避免幻读 |
6.MVCC总结
-
核心目的:实现读写不阻塞,提升并发性能;
-
三大支柱:隐藏字段记录事务ID、undo log维护版本链、ReadView判断版本可见性;
-
隔离级别差异:ReadView生成时机不同,决定了RC和RR的可见性规则差异。
七、MySQL管理
一、MySQL自带系统数据库
安装MySQL后,会自动创建4个系统数据库,作用如下:
|----------------------|-------------------------------------------------|
| 数据库 | 核心作用 |
| mysql | 存储MySQL服务器运行的关键信息:用户账号、权限配置、时区设置、主从复制状态等 |
| information_schema | 提供访问数据库元数据的接口,包含数据库、表、字段类型、索引、权限等信息 |
| performance_schema | 底层性能监控数据库,收集服务器运行状态参数,用于性能分析与调优 |
| sys | 基于performance_schema构建的视图集合,简化DBA进行性能诊断和调优的操作 |
二、MySQL常用客户端工具
1. mysql:核心客户端连接工具
用于连接MySQL服务器、执行SQL语句。
-
基础语法 :
mysql [options] [database] -
常用选项:
-
-u/--user=name:指定登录用户名 -
-p/--password[=name]:指定登录密码(交互输入更安全) -
-h/--host=name:指定服务器IP或域名 -
-P/--port=port:指定连接端口(默认3306) -
-e/--execute=name:执行SQL语句并直接退出(适合批处理脚本)
-
-
示例:
sql# 连接数据库并执行查询后退出 mysql -uroot -p123456 db01 -e "SELECT * FROM stu;"
2. mysqladmin:服务器管理工具
用于执行服务器配置检查、状态监控、数据库管理等操作。
-
基础语法 :
mysqladmin [options] command -
常用功能:创建/删除数据库、修改密码、刷新权限、查看服务器状态、关闭服务器等
-
示例:
sql# 删除test01数据库 mysqladmin -uroot -p123456 drop 'test01'; # 查看MySQL版本信息 mysqladmin -uroot -p123456 version;
3. mysqlbinlog:二进制日志管理工具
用于解析二进制日志文件,查看数据修改记录,支持按时间、位置过滤日志。
-
基础语法 :
mysqlbinlog [options] log-files1 log-files2 ... -
常用选项:
-
-d/--database=name:仅显示指定数据库的操作日志 -
-o/--offset=#:忽略日志开头的前N条命令 -
-r/--result-file=name:将解析后的日志输出到指定文件 -
--start-datetime/--stop-datetime:按时间范围过滤日志 -
--start-position/--stop-position:按日志位置过滤日志
-
4. mysqlshow:数据库对象查看工具
快速查询数据库、表、字段、索引等元数据信息。
-
基础语法 :
mysqlshow [options] [db_name [table_name [col_name]]] -
常用选项:
-
--count:显示数据库/表的统计信息(表数量、记录数等) -
-i:显示指定数据库或表的状态信息
-
-
示例:
sql# 查询test库中每个表的字段数和行数 mysqlshow -uroot -p2143 test --count;
5. mysqldump:数据库备份与迁移工具
用于备份数据库,生成包含建表语句和数据插入语句的SQL文件,支持跨数据库迁移。
-
基础语法:
sql# 备份单个数据库 mysqldump [options] db_name [tables] # 备份多个数据库 mysqldump [options] --database/-B db1 [db2 db3...] # 备份所有数据库 mysqldump [options] --all-databases/-A
-
常用选项:
-
--add-drop-database:在创建数据库前添加DROP DATABASE语句 -
--add-drop-table:在创建表前添加DROP TABLE语句(默认开启) -
-n/--no-create-db:不包含数据库创建语句 -
-t/--no-create-info:不包含表创建语句 -
-d/--no-data:仅备份表结构,不包含数据 -
-T/--tab=name:分别生成.sql(表结构)和.txt(数据)文件
-
6. mysqlimport / source:数据导入工具
-
mysqlimport:用于导入mysqldump -T导出的文本数据文件。-
语法:
mysqlimport [options] db_name textfile1 [textfile2...] -
示例:
mysqlimport -uroot -p2143 test /tmp/city.txt
-
-
source:MySQL客户端内的命令,用于导入SQL文件。- 语法:
source /root/xxxx.sql
- 语法:
三、工具使用核心场景速记
|------------------------|---------------------|
| 工具 | 核心场景 |
| mysql | 连接数据库、执行SQL脚本、批处理查询 |
| mysqladmin | 服务器状态监控、权限刷新、数据库管理 |
| mysqlbinlog | 日志解析、数据恢复、主从复制排查 |
| mysqldump | 数据库备份、跨环境数据迁移 |
| mysqlimport/source | 数据批量导入、SQL脚本执行 |