文章目录
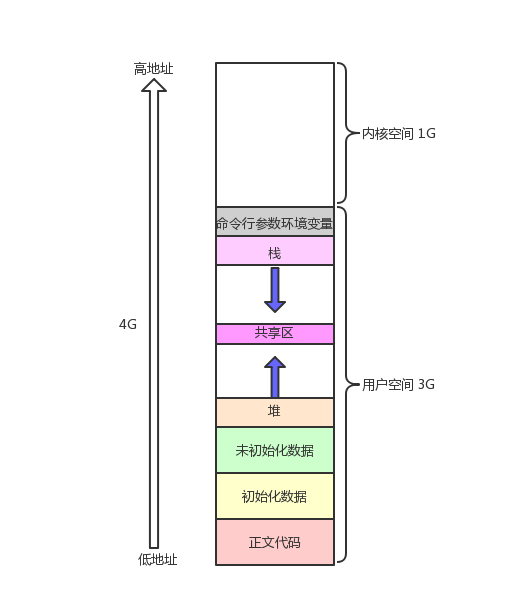
Linux进程内存布局
地址空间的范围,在32位机器上是2^32比特位,也就是0,4G。
内存布局验证
- ⭐内存布局代码验证:
cpp
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
int init=10;
int uninit;
int main()
{
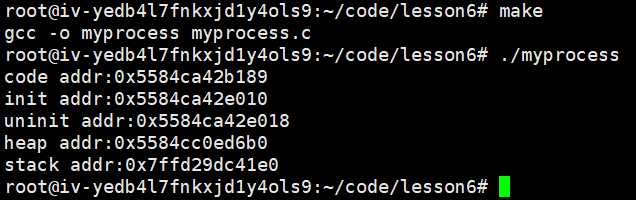
printf("code addr:%p\n",&main);
printf("init addr:%p\n",&init);
printf("uninit addr:%p\n",&uninit);
char* heap = (char* )malloc(20);
printf("heap addr:%p\n",heap);
printf("stack addr:%p\n",&heap);
return 0;
}由运行结果可知内存布局。
- 验证堆向上增长与栈向下增长:
cpp
char* heap1 = (char* )malloc(20);
char* heap2 = (char* )malloc(20);
char* heap3 = (char* )malloc(20);
char* heap4 = (char* )malloc(20);
char* heap5 = (char* )malloc(20);
printf("heap1 addr:%p\n",heap1);
printf("heap2 addr:%p\n",heap2);
printf("heap3 addr:%p\n",heap3);
printf("heap4 addr:%p\n",heap4);
printf("heap5 addr:%p\n",heap5);
printf("stack1 addr:%p\n",&heap1);
printf("stack2 addr:%p\n",&heap2);
printf("stack3 addr:%p\n",&heap3);
printf("stack4 addr:%p\n",&heap4);
printf("stack5 addr:%p\n",&heap5);
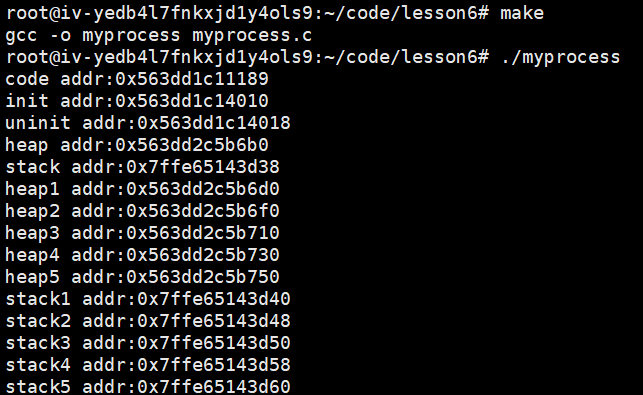
验证结果显示堆向上增长与栈向下增长
- 🔥验证命令行参数和环境变量
cpp
int main(int argc,char* argv[],char* env[])
{
for(int i = 0;argv[i];i++)
{
printf("&argv[%d]:%p \n",i,argv+i);
}
for(int i = 0;env[i];i++)
{
printf("&env[%d]:%p \n",i,env+i);
}
return 0;
}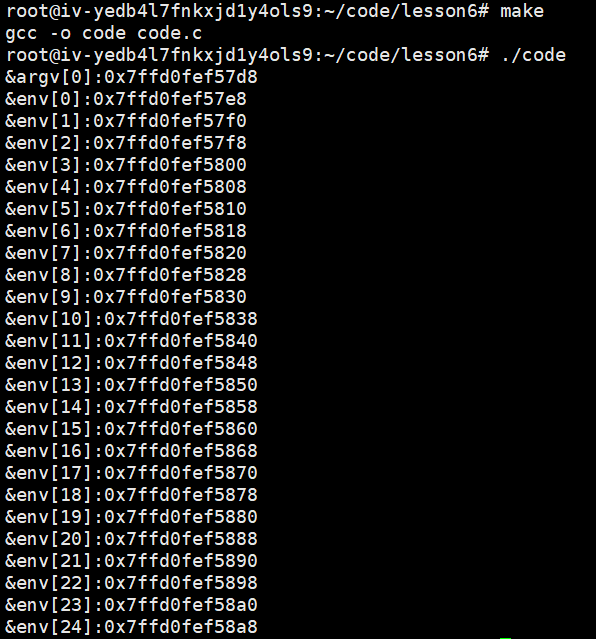
运行结果及分析:环境变量与命令行参数这两张表(不是表指向的内容),比栈区大,其中,是先有命令行参数这张表,才有环境变量这张表。
- 📌验证表的地址存放
cpp
int main(int argc,char* argv[],char* env[])
{
for(int i = 0;argv[i];i++)
{
printf("argv[%d]:%p \n",i,argv[i]);
}
for(int i = 0;env[i];i++)
{
printf("env[%d]:%p \n",i,env[i]);
}
return 0;
}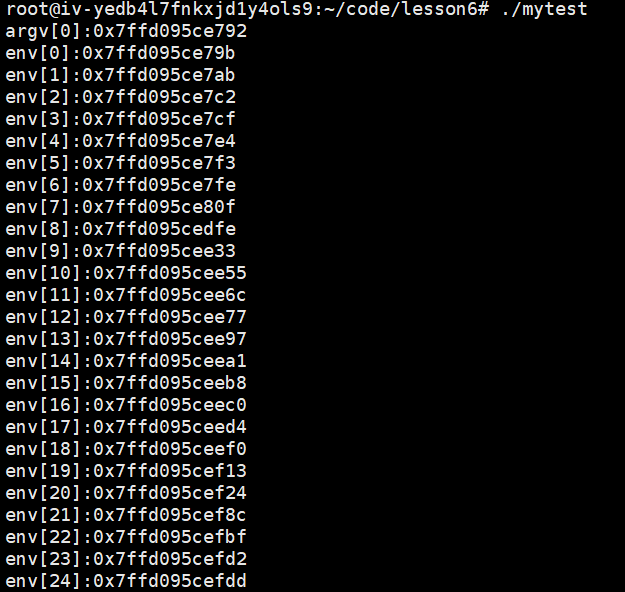
结果分析:无论是表还是表指向的项目,都在栈上部的.
- 验证静态变量在内存分布中的位置:
这里就不验证了,直接得出结论:静态变量是存放在初始化数据与未初始化数据之间的。静态变量默认是会被初始化的,哪怕用户定义出来没有赋值,编译器也会初始化。例如int 类型的静态变量,会被编译器初始化为0;
接下来看一段代码:
cpp
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
int g_val = 1000;
int main()
{
pid_t id = fork();
if(id==0)
{
//子进程
while(1)
{
printf("child pid:%d ppid:%d g_val=%d &g_val:%p\n",getpid(),getppid(),g_val,&g_val);
sleep(1);
}
}
//父进程
else{
while(1)
{
printf("father pid:%d ppid:%d g_val=%d &g_val:%p\n",getpid(),getppid(),g_val,&g_val);
sleep(1);
}
}
return 0;
}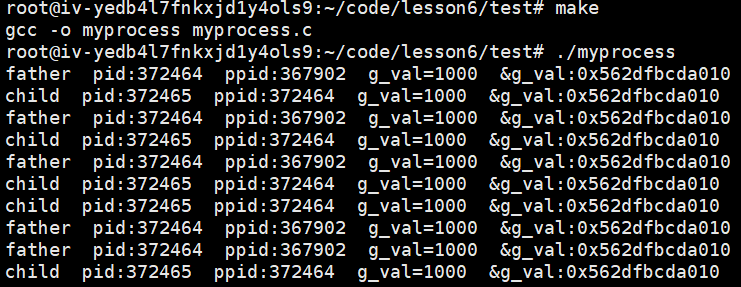
运行结果:符合我们预期的,数据本来就是父子进程共享的,除非要写入,进程之间时具有独立性的,写入的时候需要写时拷贝。
📌现象解释
- 1.地址一样却值不一样,所以这个地址肯定不是物理地址。
- 2.如果是物理地址,绝对不可能在一个地址中存放的内容不一样。
这个地址叫做虚拟地址/线性地址。
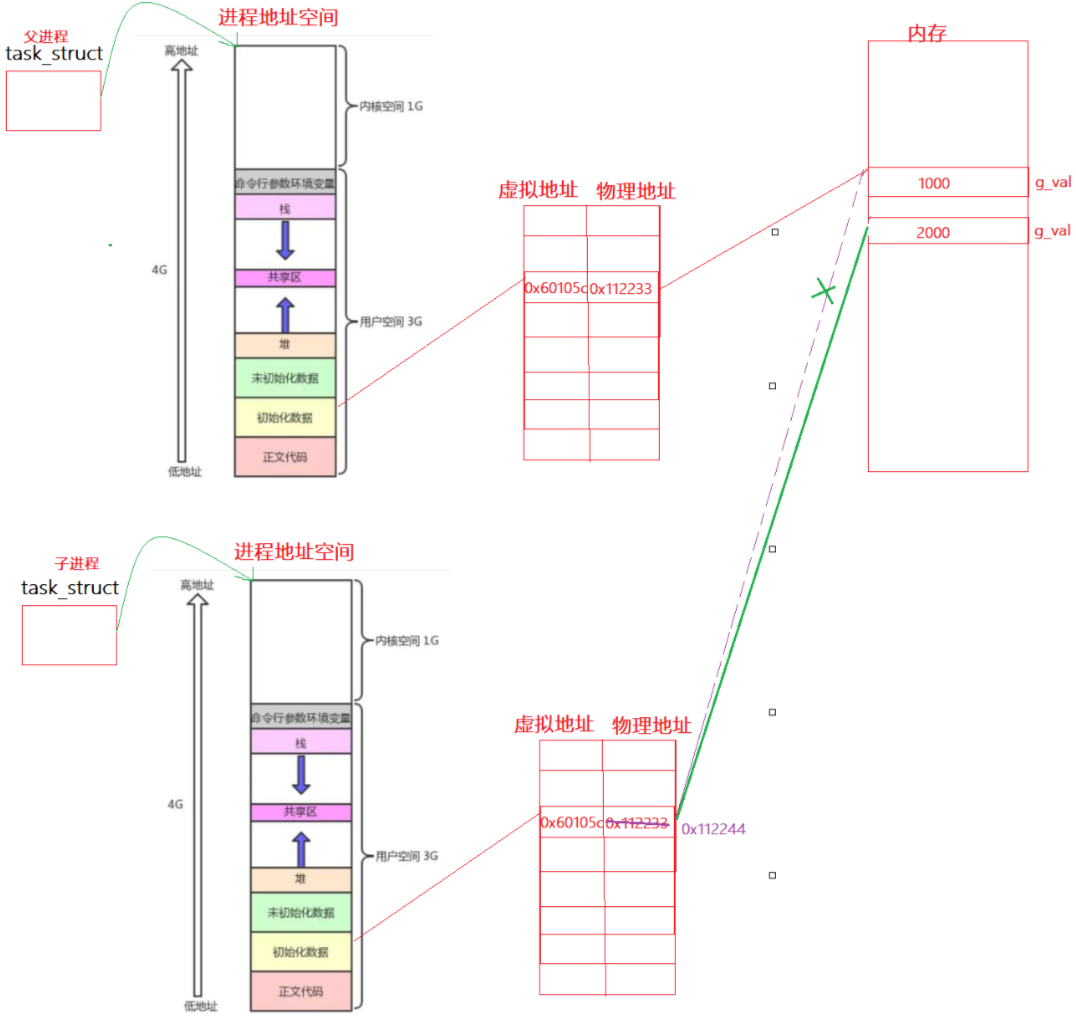
结论:我们平时用到的语言的地址全部都不是物理地址,是虚拟地址。所以下面这个图的空间排布的情况不是物理内存,它叫做进程地址空间。
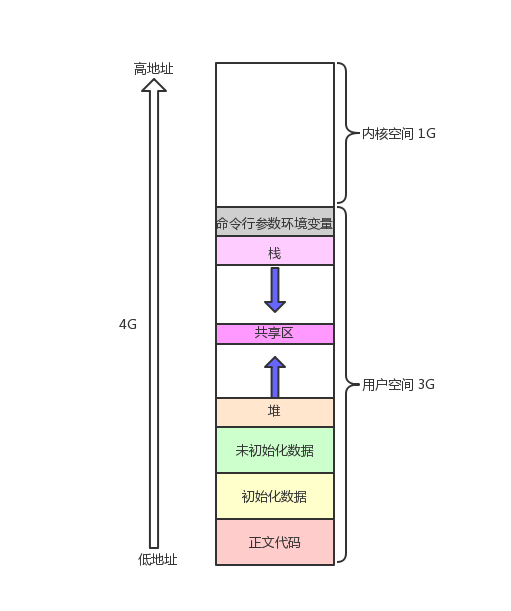
进程地址空间
每一个进程都有一个task_struct(PCB),PCB里面有该进程的进程地址空间,进程地址空间和内存之间是用一张表(叫做页表:里面存放的是虚拟地址与物理地址)建立关系的,如下图,页表对应一个映射关系,是虚拟地址与物理地址之间的关系。根据虚拟地址可以找到对应的物理地址。下面的结构都是操作系统内部在维护的
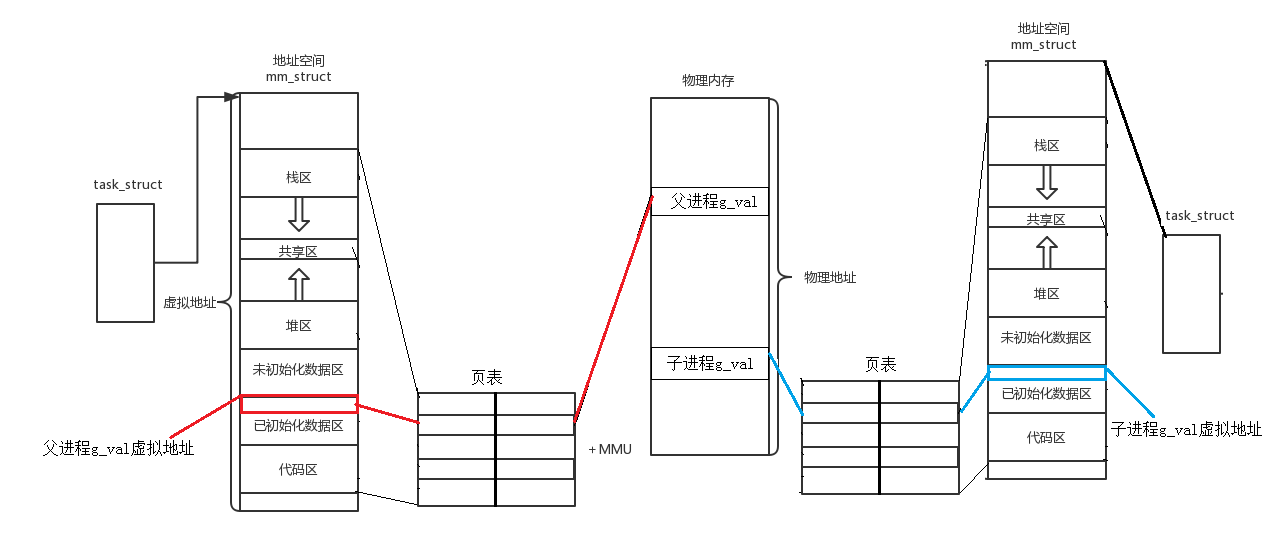
- 说明:上面的图表明同一个变量,地址相同,其实是虚拟地址相同,内容不同其实是被映射到了不同的物理地址!
📌其中,父进程创建子进程后,子进程也会有一个这样的结构,也会有进程地址空间,页表,并且父进程PCB的大部分属性都会被子进程继承下来,页表也会被继承下来(类似浅拷贝),这时父子进程都指向同一个物理内存。以上面的示例分析:当子进程尝试对g_val进行修改时,操作系统会在内存中重新开一个空间,将修改后的值放在这个空间里,再改变页表中g_val的虚拟地址对应的物理地址,注意:改的是物理地址,虚拟地址没有改变,所以上面示例的结果打印出来的地址(虚拟地址)没有改变。
📌为什么要有页表
- 在进程看来,有了页表,可以将物理内存从无徐变为有序,因为页表是有序的。让进程以统一的视角,看待内存;
- 将进程管理和内存管解耦合,进程管理与内存管理互不干扰。
地址空间+页表是保护内存安全的重要手段(拦截非法:例如:野指针,越界问题)。
写时拷贝
- 为什么需要写时拷贝?
答:进程之间要做到独立性。 - 创建子进程的时候,为什么不直接将父进程的代码和数据拷贝一份给子进程呢?
答:因为子进程并不是会对父进程的所有数据都要进行写入操作,如果fork()创建子进程的时候,直接拷贝一份代码和数据,会降低fork()的效率。 - 为什么是要拷贝呢,只开空间不拷贝行不行?
答:因为子进程不一定是对这个数据直接进行覆盖式的写入,可以只是对该数据进行局部修改或则是基于之前的值进行操作。
📌如何做到写时拷贝
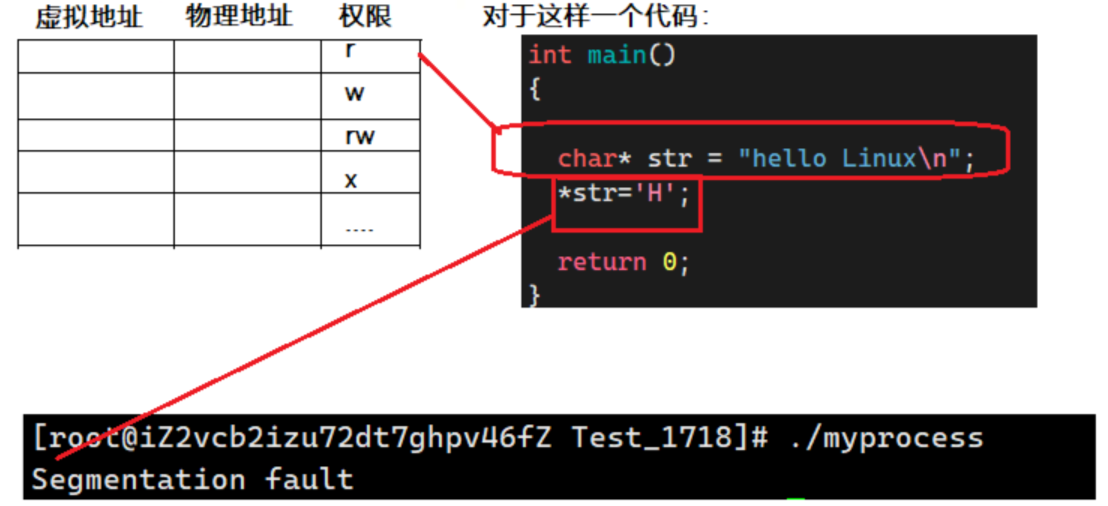
页表,不只是有虚拟地址与物理地址的转换的,还可以带很多选项的,如下图(介绍其中一个:权限):
下图代码字符串"hello Linux"是具有常属性的,不能被修改,当我们尝试去修改的时候,会报错(运行报错)。
是因为在页表有权限,虚拟地址映射到物理地址的时候,会做权限审核,如下图所示,当只有可读权限,没有修改的权限的时候,尝试去修改,就会报错。
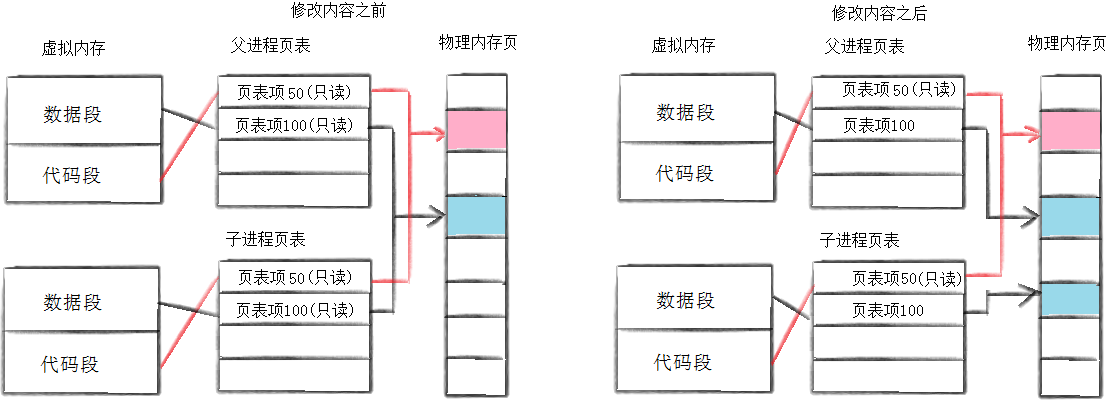
🐧写时拷贝的一些细节
当要进行写时拷贝的时候,会将父子进程页表里大部分内容的映射权限设置为只读权限,当父子进程任何一方要去进行尝试写入的时候,操作系统会进行判断,如果是数据段,对数据进行写入时合理的,就会引发缺页中断 ,操作系统会将权限改为读写,然后写时拷贝后,再把页表对应的条目改为读写。
