大家好 👋,我是 Moment,目前正在使用 Next.js、NestJS、LangChain 开发 DocFlow。这是一个面向 AI 场景的协同文档平台,集成了基于
Tiptap的富文本编辑、NestJS后端服务、实时协作与智能化工作流等核心模块。在这个项目的持续打磨过程中,我积累了不少实战经验,不只是
Tiptap的深度定制、编辑器性能优化和协同方案设计,也包括前端工程化建设、React 源码理解以及复杂项目架构实践。如果你对 AI 全栈开发、文档编辑器、前端工程化或者 React 源码相关内容感兴趣,欢迎添加我的微信
yunmz777一起交流。觉得项目还不错的话,也欢迎给 DocFlow 点个 star ⭐
在前面的章节中,我们详细讲解了 Fiber 树构造的探寻阶段(beginWork),它负责向下遍历并创建或更新 Fiber 节点。现在让我们来看 Fiber 树构造的另一个关键阶段------回溯阶段(completeWork)。
为什么需要 completeWork?
在 beginWork 阶段,React 主要处理的是 Fiber 节点的创建和 diff 算法,但它并不直接操作 DOM。这是因为 React 采用了"双缓存"机制,需要在内存中完整构建好新的 Fiber 树后,才能一次性将变更应用到页面上。completeWork 就是这个构建过程的另一半。
如果把 Fiber 树的构造比作建造一栋房子:
- beginWork 就像是规划设计,确定每个房间的布局和功能
- completeWork 就像是实际施工,建造墙壁、安装设施,并记录哪些地方需要最后的装修
回溯阶段是 Fiber 树构造循环中的第二个阶段,当 beginWork 没有返回子节点(即 next === null)时,就会进入回溯阶段。这个阶段的主要任务是:
- 创建或更新 DOM 节点(但不插入到页面)
- 处理节点的副作用(effects)
- 向上冒泡副作用队列
- 收集需要在 commit 阶段执行的操作
- 构建 DOM 树的父子关系
completeUnitOfWork 入口
在 performUnitOfWork 函数中,当 beginWork 返回 null 时,会调用 completeUnitOfWork:
ts
function performUnitOfWork(unitOfWork: Fiber): void {
const current = unitOfWork.alternate;
let next;
next = beginWork(current, unitOfWork, subtreeRenderLanes);
unitOfWork.memoizedProps = unitOfWork.pendingProps;
if (next === null) {
// 没有子节点,进入回溯阶段
completeUnitOfWork(unitOfWork);
} else {
workInProgress = next;
}
}completeUnitOfWork 流程
completeUnitOfWork 函数是回溯阶段的核心,它会从当前节点开始向上回溯,直到根节点。
ts
function completeUnitOfWork(unitOfWork: Fiber): void {
let completedWork = unitOfWork;
do {
// 获取备份节点(current)和父级 fiber
const current = completedWork.alternate;
const returnFiber = completedWork.return;
// 检查是否存在异常
if ((completedWork.flags & Incomplete) === NoFlags) {
// 正常流程:执行 completeWork
// 创建真实 DOM 对象并添加到 stateNode 属性中
let next = completeWork(current, completedWork, subtreeRenderLanes);
if (next !== null) {
// 如果返回了新的工作单元,继续处理
workInProgress = next;
return;
}
} else {
// 异常流程:执行 unwindWork 处理错误
const next = unwindWork(current, completedWork, subtreeRenderLanes);
if (next !== null) {
// 清除不必要的副作用标记
next.flags &= HostEffectMask;
workInProgress = next;
return;
}
// 向父节点冒泡异常标记
if (returnFiber !== null) {
returnFiber.flags |= Incomplete;
returnFiber.subtreeFlags = NoFlags;
returnFiber.deletions = null;
} else {
// 已经回溯到根节点,标记渲染未完成
workInProgressRootExitStatus = RootDidNotComplete;
workInProgress = null;
return;
}
}
// 检查是否有兄弟节点
const siblingFiber = completedWork.sibling;
if (siblingFiber !== null) {
// 如果有兄弟节点,处理兄弟节点
workInProgress = siblingFiber;
return;
}
// 没有兄弟节点,向上回溯到父节点
completedWork = returnFiber;
workInProgress = completedWork;
} while (completedWork !== null);
// 到达根节点,标记渲染完成
if (workInProgressRootExitStatus === RootInProgress) {
workInProgressRootExitStatus = RootCompleted;
}
}completeUnitOfWork 工作流程图如下所示:
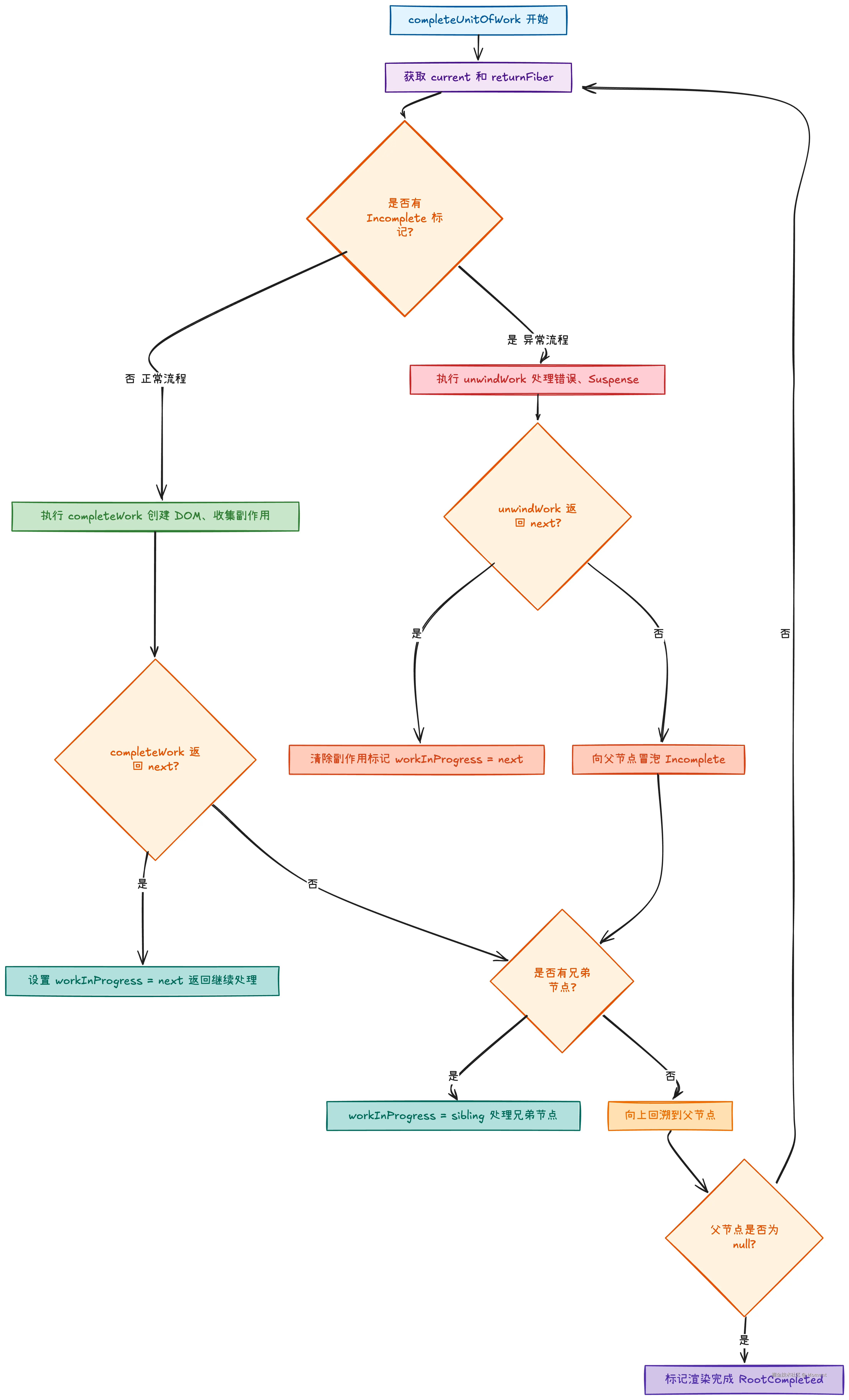
从这个流程可以看出,completeUnitOfWork 会:
- 对当前节点调用
completeWork - 如果没有返回新的工作单元,检查是否有兄弟节点
- 如果有兄弟节点,处理兄弟节点(进入
beginWork) - 如果没有兄弟节点,向上回溯到父节点,继续执行
completeWork - 重复这个过程,直到回溯到根节点
completeUnitOfWork 遍历顺序示例
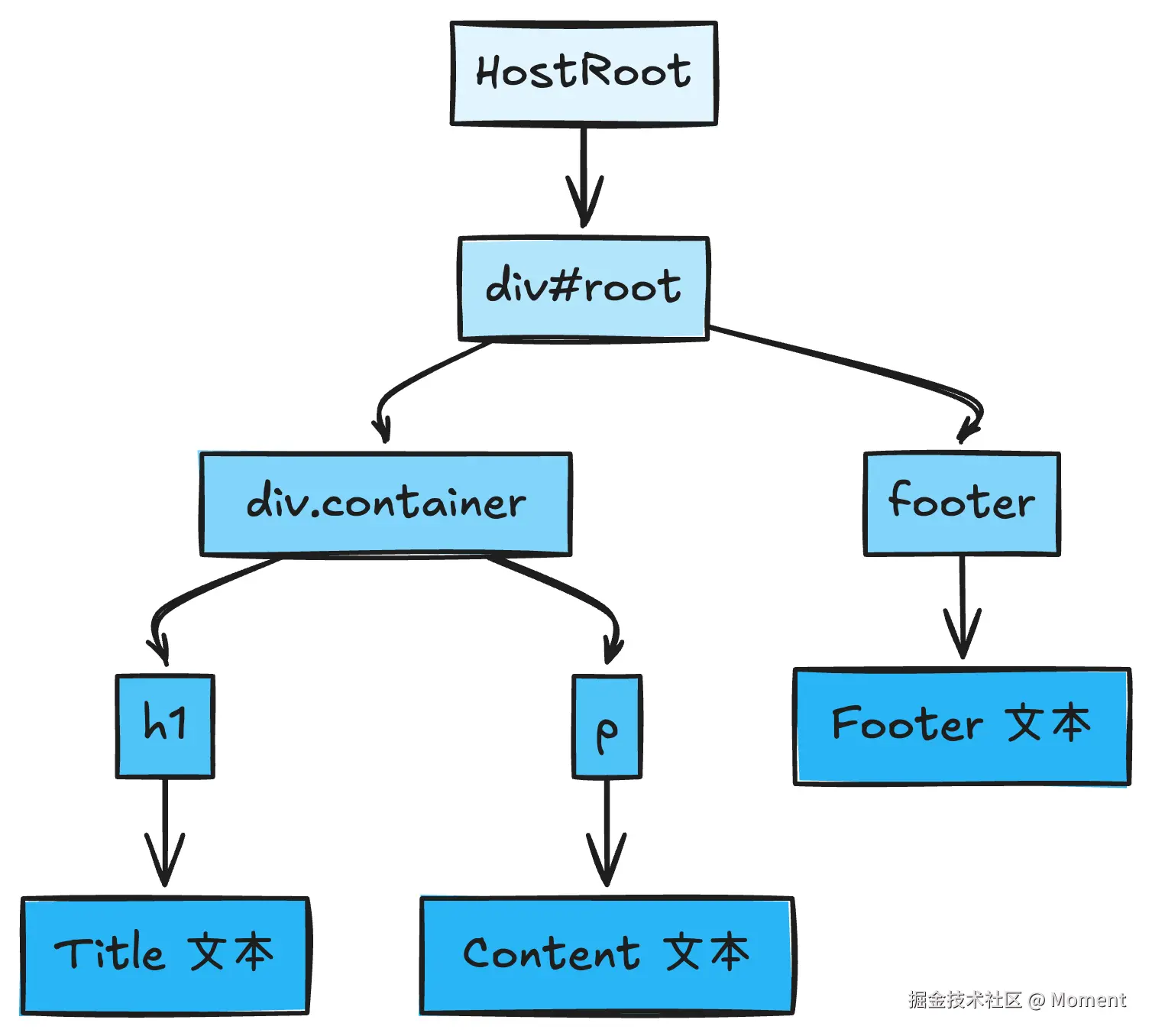
让我们通过一个具体的 Fiber 树来理解遍历顺序:
jsx
<div id="root">
<div className="container">
<h1>Title</h1>
<p>Content</p>
</div>
<footer>Footer</footer>
</div>对应的 Fiber 树结构和遍历顺序:
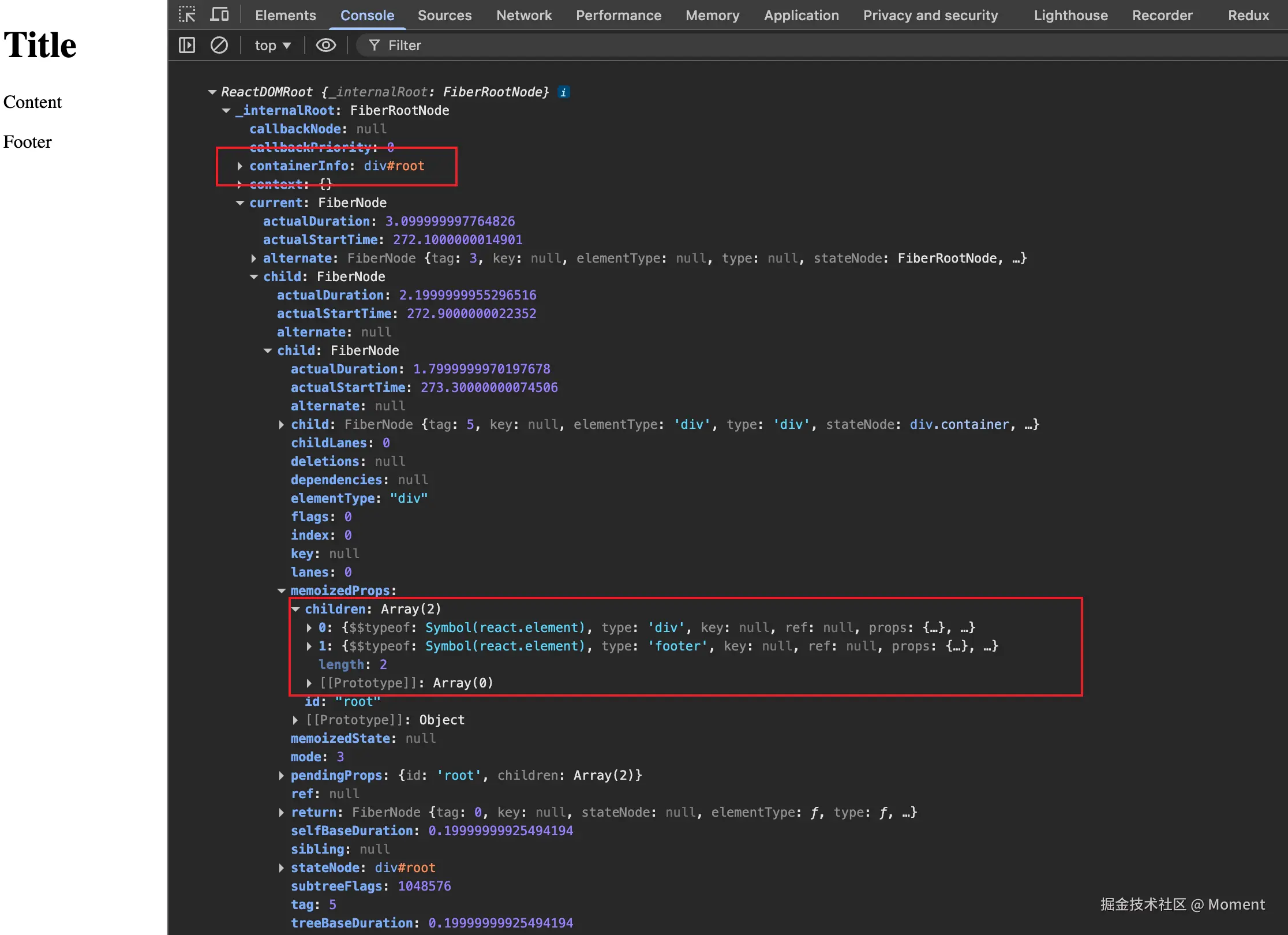
对应源码的输出如下图所示:
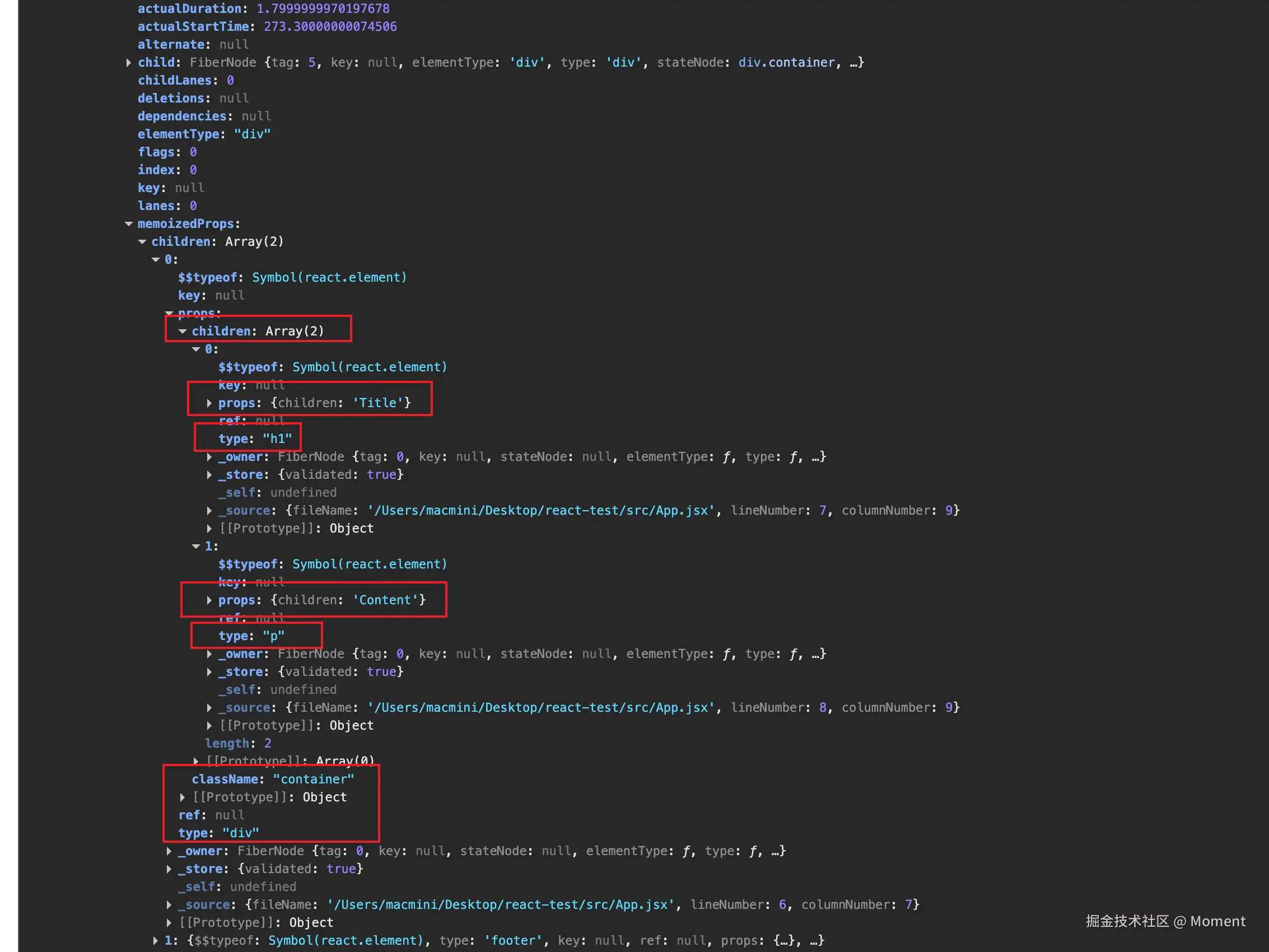
我们可以看其中一个,直接进入到 div.container,如下输出所示:
completeWork 的执行顺序:
beginWork向下遍历到最深的叶子节点"Title 文本"completeWork("Title 文本")→ 创建文本节点- 向上回溯到
h1,completeWork(h1)→ 创建h1DOM,将文本节点append进去 h1有兄弟节点p,切换到p,重新进入beginWorkbeginWork向下到"Content 文本"completeWork("Content 文本")→ 创建文本节点- 向上回溯到
p,completeWork(p)→ 创建pDOM,将文本节点append进去 p没有兄弟节点,向上回溯到div.containercompleteWork(div.container)→ 创建divDOM,将h1和pappend进去div.container有兄弟节点footer,切换到footer,重新进入beginWork- 继续处理
footer及其子节点 - 最后回溯到
HostRoot
从上面的执行流程可以看出几个关键特征:
- 深度优先遍历:始终先处理最深的子节点,然后再处理父节点
- 从下往上完成:子节点的
completeWork完成后才能执行父节点的completeWork - 兄弟节点切换:当一个节点完成后,如果存在
sibling兄弟节点,会切换到兄弟节点并重新进入beginWork阶段 - DOM 构建顺序:正是这种自底向上的执行顺序,才能保证在处理父节点时,所有子节点的
DOM都已经创建好,可以直接通过appendAllChildren追加到父节点中
completeWork 函数详解
completeWork 函数是回溯阶段的核心,它根据 fiber.tag 的不同类型执行相应的处理逻辑。主要包括 FunctionComponent、ClassComponent、HostRoot、HostComponent、HostText 等类型,每种类型的处理方式各有不同。
下面的流程图展示了 completeWork 的完整执行流程,从获取 props 开始,根据不同的 fiber 类型进行分支处理,最终都会执行 bubbleProperties 冒泡副作用并返回 null:
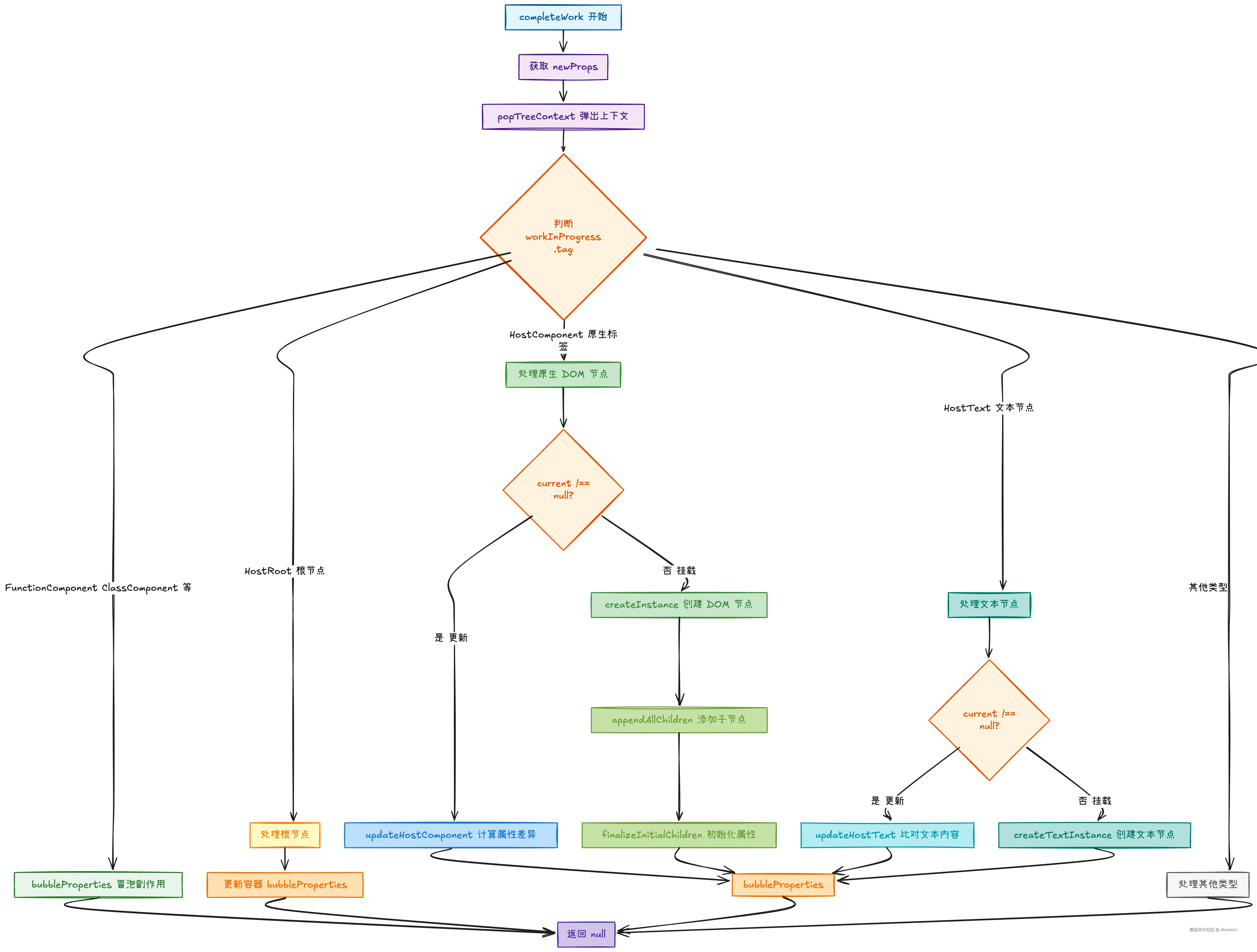
从流程图可以看出,completeWork 的核心逻辑是根据 fiber.tag 执行对应的处理函数,其中 HostComponent(原生 DOM 元素)的处理最为复杂,需要区分挂载和更新两种场景。
函数组件和类组件
对于函数组件、类组件等不需要创建 DOM 的组件,completeWork 的处理非常简单:
ts
case FunctionComponent:
case ForwardRef:
case SimpleMemoComponent:
case MemoComponent:
bubbleProperties(workInProgress);
return null;
case ClassComponent: {
const Component = workInProgress.type;
if (isLegacyContextProvider(Component)) {
popLegacyContext(workInProgress);
}
bubbleProperties(workInProgress);
return null;
}这些组件类型只需要调用 bubbleProperties 来冒泡副作用,然后返回 null。
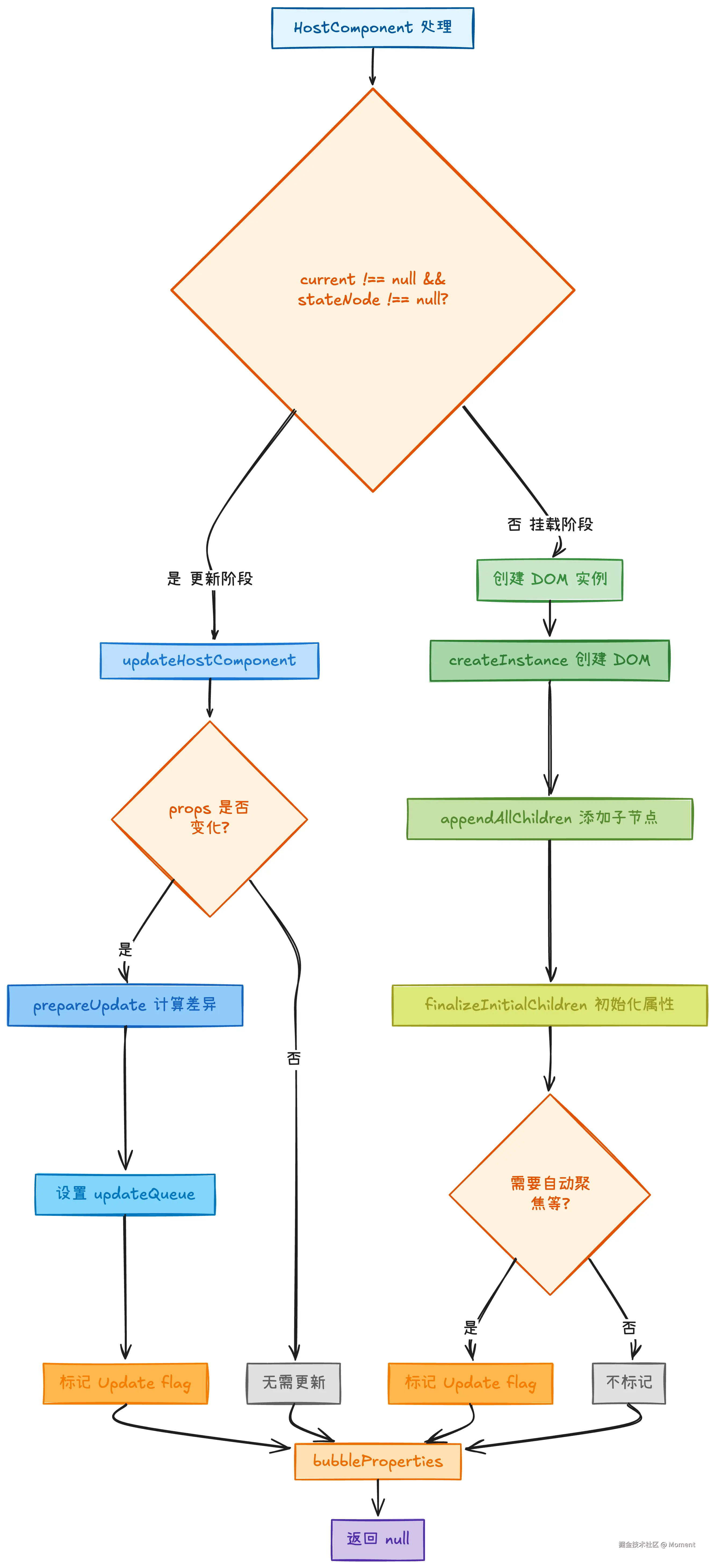
HostComponent(原生 DOM 元素)
HostComponent 是 completeWork 中最核心也是最复杂的部分,它负责处理原生 DOM 元素(如 div、span、button 等)的创建和更新。处理逻辑需要区分两种场景:
- 更新阶段(
current !== null && stateNode !== null):DOM 节点已存在,需要计算属性差异并标记更新 - 挂载阶段(
current === null或stateNode === null):需要创建新的 DOM 节点并初始化属性
下面的流程图展示了 HostComponent 的完整处理流程:
更新阶段(current !== null)
在更新阶段,DOM 节点已经存在,React 需要判断是否需要更新 DOM 属性。这个阶段的核心是调用 updateHostComponent 函数:
ts
if (current !== null && workInProgress.stateNode != null) {
// 更新阶段:DOM 节点已存在
updateHostComponent(
current,
workInProgress,
type,
newProps,
rootContainerInstance
);
// 检查 ref 是否变化
if (current.ref !== workInProgress.ref) {
markRef(workInProgress);
}
}updateHostComponent 函数会比较新旧 props,计算需要更新的属性并生成 updatePayload:
ts
updateHostComponent = function(
current: Fiber,
workInProgress: Fiber,
type: Type,
newProps: Props,
rootContainerInstance: Container,
) {
const oldProps = current.memoizedProps;
// 如果 props 引用相同,直接返回(优化)
if (oldProps === newProps) {
return;
}
const instance: Instance = workInProgress.stateNode; // 获取 DOM 实例
const currentHostContext = getHostContext();
// 核心:调用 prepareUpdate 计算属性差异
const updatePayload = prepareUpdate(
instance,
type,
oldProps,
newProps,
rootContainerInstance,
currentHostContext,
);
// 将更新信息保存到 updateQueue,commit 阶段会使用
workInProgress.updateQueue = (updatePayload: any);
// 如果有属性变动,标记 Update flag
if (updatePayload) {
markUpdate(workInProgress);
}
};让我们通过一个实际的例子来理解 updatePayload 是如何工作的:
jsx
const DemoComponent = ({ content }) => {
console.log("DemoComponent render");
return <div>{content}</div>; // HostComponent
};
const App = () => {
const [content, setContent] = useState("初始内容");
const handleClick = () => {
setContent("更新后的内容"); // 触发更新
};
return (
<div>
<h1>React 渲染演示</h1>
<DemoComponent content={content} />
<button onClick={handleClick}>更新内容</button>
</div>
);
};当点击按钮触发更新时,控制台会输出以下内容:
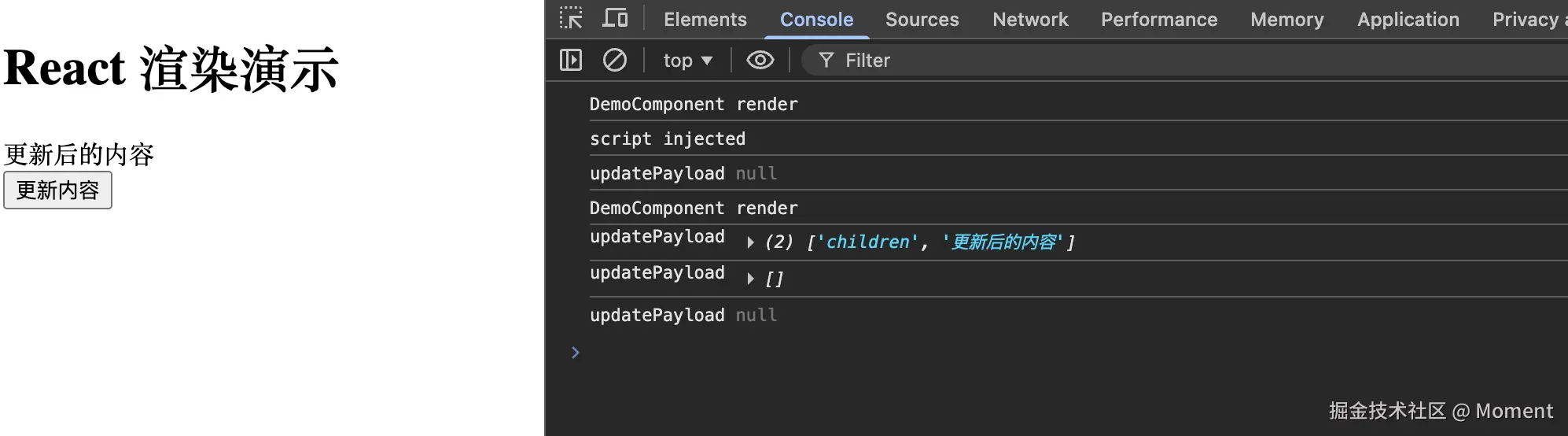
从控制台输出可以看到 updatePayload (2) ['children', '更新后的内容'] 的关键输出,它表示组件更新所需的负载:
-
第一项
children表示更新的是组件的子元素(children)。 -
第二项
'更新后的内容'表示更新后的新值,即新的 children 内容。
每次 React 检测到 props 或 state 的变化时,都会生成一个更新负载(updatePayload)。在这种情况下,updatePayload 中包含了要更新的属性名(children)和它的新值(更新后的内容)。
prepareUpdate 详解
prepareUpdate 是 DOM 属性 diff 的入口函数,它的主要作用是在开发环境进行一些校验,然后调用 diffProperties 计算具体的属性差异:
ts
export function prepareUpdate(
domElement: Instance,
type: string,
oldProps: Props,
newProps: Props,
rootContainerInstance: Container,
hostContext: HostContext
): null | Array<mixed> {
// 开发环境:验证 DOM 嵌套规则(如 <p> 内不能嵌套 <div>)
// 生产环境:这部分代码会被移除
// 核心:调用 diffProperties 计算属性差异
return diffProperties(
domElement,
type,
oldProps,
newProps,
rootContainerInstance
);
}从源码可以看出,prepareUpdate 本身很简单,真正的 diff 逻辑在 diffProperties 中。
diffProperties 完整源码解析
diffProperties 是 React DOM 属性 diff 的核心函数,它的职责是比较新旧 props 并生成 updatePayload。这个函数的实现相当复杂,包含了大量针对不同属性类型和不同 HTML 元素的特殊处理逻辑。整个函数可以分为三个主要步骤:预处理、删除属性处理、新增/变化属性处理。下面我们逐步深入解析每个步骤。
第一步:表单元素的特殊预处理
在开始 diff 之前,React 首先会根据元素类型进行预处理。表单元素(input、select、textarea)是 Web 应用中最常用的交互元素,它们有一个关键特点:需要维护内部状态(如用户输入的值)。React 需要精确控制这些状态,因此对表单元素采用了特殊的处理策略。
ts
export function diffProperties(
domElement: Element,
tag: string,
lastRawProps: Object,
nextRawProps: Object,
rootContainerElement: Element | Document | DocumentFragment
): null | Array<mixed> {
let updatePayload: null | Array<any> = null;
let lastProps: Object;
let nextProps: Object;
// 根据元素类型进行预处理
switch (tag) {
case "input":
// 处理 input 元素:将原始 props 转换为标准化的 host props
lastProps = ReactDOMInputGetHostProps(domElement, lastRawProps);
nextProps = ReactDOMInputGetHostProps(domElement, nextRawProps);
updatePayload = []; // 关键!预先初始化为空数组
break;
case "select":
// 处理 select 元素:标准化 props,处理 value/defaultValue
lastProps = ReactDOMSelectGetHostProps(domElement, lastRawProps);
nextProps = ReactDOMSelectGetHostProps(domElement, nextRawProps);
updatePayload = []; // 关键!预先初始化为空数组
break;
case "textarea":
// 处理 textarea 元素:标准化 props,处理 value/defaultValue
lastProps = ReactDOMTextareaGetHostProps(domElement, lastRawProps);
nextProps = ReactDOMTextareaGetHostProps(domElement, nextRawProps);
updatePayload = []; // 关键!预先初始化为空数组
break;
default:
// 普通元素:直接使用原始 props
lastProps = lastRawProps;
nextProps = nextRawProps;
// 特殊处理:如果新增了 onClick 事件
// 需要在非交互元素(如 div)上捕获点击事件
if (
typeof lastProps.onClick !== "function" &&
typeof nextProps.onClick === "function"
) {
trapClickOnNonInteractiveElement(domElement);
}
break;
}
// ...后续逻辑
}这段代码解释了一个在实际开发中常见的现象:当你在控制台打印 updatePayload 时,会发现表单元素即使没有属性变化,也会返回空数组 [] 而不是 null。这是为什么呢?
原因在于表单元素需要特殊的更新处理机制。React 对表单元素采用了"总是触发更新"的策略,即使 props 没有变化,也要返回一个空数组,确保在 commit 阶段能够执行必要的同步操作(比如将 React 的 state 同步到 DOM 元素的 value 属性)。这种设计保证了受控组件的正确性,避免了用户输入和 React state 之间的不一致。
ReactDOMInputGetHostProps 等函数会对 props 进行标准化处理,比如将 value 和 defaultValue 转换为内部使用的格式,处理 checked 属性等。这些处理函数会过滤掉一些 React 特有的 props(如 defaultValue),只保留需要设置到 DOM 上的属性。
第二步:处理被删除的属性
完成预处理后,diffProperties 开始第一轮遍历:遍历旧的 props 对象,找出那些在新 props 中不存在的属性。这些属性在更新后应该被删除。React 需要将这些删除操作记录到 updatePayload 中,以便在 commit 阶段从 DOM 元素上移除这些属性。
需要注意的是,不同类型的属性有不同的删除策略。比如样式属性需要将每个样式值设为空字符串,而普通属性则直接设为 null。事件属性的删除更特殊,因为 React 使用事件委托,所以不需要在 DOM 元素上操作,只需要确保 commit 阶段能够更新 Fiber 节点的 props 指针。
ts
// 第一轮遍历:遍历旧 props,找出被删除的属性
for (propKey in lastProps) {
// 跳过以下情况:
// 1. 新 props 中仍然存在这个属性(说明没有被删除)
// 2. 不是自有属性(继承的属性)
// 3. 值为 null 或 undefined(已经是空值)
if (
nextProps.hasOwnProperty(propKey) ||
!lastProps.hasOwnProperty(propKey) ||
lastProps[propKey] == null
) {
continue;
}
// 找到了一个被删除的属性,根据属性类型进行不同处理
if (propKey === "style") {
// 样式属性被删除:需要将所有样式子属性设为空字符串
// 不能直接移除 style 属性,而是清空每个样式值
const lastStyle = lastProps[propKey];
for (styleName in lastStyle) {
if (lastStyle.hasOwnProperty(styleName)) {
styleUpdates = styleUpdates || {};
styleUpdates[styleName] = ""; // 清空样式,如 color: ""
}
}
} else if (propKey === "dangerouslySetInnerHTML" || propKey === "children") {
// innerHTML 和 children 的删除不在这里处理
// 由 React 的文本清除机制统一处理,避免重复操作
} else if (
propKey === "suppressContentEditableWarning" ||
propKey === "suppressHydrationWarning"
) {
// React 内部使用的属性,不需要设置到 DOM 上
// 这些属性只在 React 内部使用,用于控制警告行为
} else if (propKey === "autoFocus") {
// autoFocus 属性在更新时不起作用
// autoFocus 只在元素首次挂载时有效,更新时即使删除也不需要处理
} else if (registrationNameDependencies.hasOwnProperty(propKey)) {
// 这是一个事件属性(如 onClick、onChange)被删除了
// 由于 React 使用事件委托,事件监听器在根容器上
// 所以不需要从 DOM 元素上移除监听器
// 但需要确保 updatePayload 不为 null,触发 commit 更新 props 指针
if (!updatePayload) {
updatePayload = [];
}
} else {
// 其他普通属性被删除:添加到 updatePayload
// 格式:[propKey, null],null 表示删除这个属性
(updatePayload = updatePayload || []).push(propKey, null);
}
}这段代码展示了 React 对不同类型属性的精细化处理。比如,样式属性的删除不是简单地移除 style 属性,而是将每个具体的样式值(如 color、fontSize)设为空字符串。这是因为在某些情况下,元素可能继承了父元素的样式,直接删除 style 属性可能导致样式显示不符合预期。
事件属性的处理更能体现 React 事件系统的设计思想。当一个事件属性被删除时,React 不需要从 DOM 元素上移除监听器(因为根本没有在元素上添加监听器),只需要确保返回一个非 null 的 updatePayload,让 commit 阶段更新 Fiber 节点的 memoizedProps,这样事件触发时就能找到正确的处理函数(或者不再调用已删除的处理函数)。
第三步:处理新增或变化的属性
完成删除属性的处理后,diffProperties 进入第二轮遍历:遍历新的 props 对象,找出新增的属性或值发生变化的属性。这是 diff 算法的核心部分,React 需要精确识别哪些属性发生了变化,并将这些变化记录到 updatePayload 中。
这一步的处理逻辑比第一步更复杂,因为不同类型的属性有不同的比较和更新策略。特别是样式属性,React 会进行细粒度的 diff,只记录发生变化的具体样式值,而不是整个 style 对象。这种优化可以减少不必要的 DOM 操作,提高性能。
ts
// 第二轮遍历:遍历新 props,找出新增或变化的属性
for (propKey in nextProps) {
const nextProp = nextProps[propKey]; // 新值
const lastProp = lastProps != null ? lastProps[propKey] : undefined; // 旧值
// 跳过以下情况:
// 1. 不是自有属性(继承的属性)
// 2. 值完全相同(引用相等或基本类型值相等)
// 3. 新旧值都为 null 或 undefined
if (
!nextProps.hasOwnProperty(propKey) ||
nextProp === lastProp ||
(nextProp == null && lastProp == null)
) {
continue;
}
// 找到了一个新增或变化的属性,根据属性类型进行不同处理
if (propKey === 'style') {
// 样式属性:需要进行细粒度的 diff
if (lastProp) {
// 之前有样式,需要对比新旧样式对象
// 第一步:找出被删除的样式属性
for (styleName in lastProp) {
if (
lastProp.hasOwnProperty(styleName) &&
(!nextProp || !nextProp.hasOwnProperty(styleName))
) {
// 这个样式属性在新 style 中不存在了,需要清空
styleUpdates = styleUpdates || {};
styleUpdates[styleName] = '';
}
}
// 第二步:找出新增或变化的样式属性
for (styleName in nextProp) {
if (
nextProp.hasOwnProperty(styleName) &&
lastProp[styleName] !== nextProp[styleName]
) {
// 这个样式属性是新增的,或者值发生了变化
styleUpdates = styleUpdates || {};
styleUpdates[styleName] = nextProp[styleName];
}
}
} else {
// 之前没有样式,现在添加样式,直接使用新的 style 对象
styleUpdates = nextProp;
}
} else if (propKey === 'dangerouslySetInnerHTML') {
// innerHTML 属性:用于设置元素的 HTML 内容
const nextHtml = nextProp ? nextProp.__html : undefined;
const lastHtml = lastProp ? lastProp.__html : undefined;
// 只有当 HTML 内容确实发生变化时才添加到 updatePayload
if (nextHtml != null && lastHtml !== nextHtml) {
(updatePayload = updatePayload || []).push(propKey, nextHtml);
}
} else if (propKey === 'children') {
// children 属性:React 只在这里处理文本子节点
// 如果 children 是 React 元素数组,会在 Fiber 树中处理,不会走这里
if (typeof nextProp === 'string' || typeof nextProp === 'number') {
// 文本子节点:添加到 updatePayload
// 转换为字符串确保类型一致
(updatePayload = updatePayload || []).push(propKey, '' + nextProp);
}
} else if (
propKey === 'suppressContentEditableWarning' ||
propKey === 'suppressHydrationWarning'
) {
// React 内部使用的属性,用于控制警告信息
// 不需要设置到 DOM 上,直接跳过
} else if (registrationNameDependencies.hasOwnProperty(propKey)) {
// 这是一个事件属性(如 onClick、onChange、onScroll 等)
if (nextProp != null) {
// 特殊处理:某些事件(如 scroll)不使用事件委托
// 需要直接在元素上监听,因为这些事件不冒泡
if (propKey === 'onScroll') {
listenToNonDelegatedEvent('scroll', domElement);
}
// 对于其他事件,React 会在根容器上统一处理(事件委托)
}
// 关键!即使事件处理函数引用相同,只要进入了这个分支
// 且 lastProp !== nextProp,就需要返回空数组触发 commit
// 这确保了 Fiber 节点的 memoizedProps 能够得到更新
if (!updatePayload && lastProp !== nextProp) {
updatePayload = [];
}
} else {
// 其他普通属性(className、id、title、data-* 等)
// 直接添加到 updatePayload,格式:[propKey, nextProp]
(updatePayload = updatePayload || []).push(propKey, nextProp);
}
}
// 最后,如果有样式更新,将样式添加到 updatePayload
// 注意:style 是作为一个整体添加的,包含所有变化的样式属性
if (styleUpdates) {
(updatePayload = updatePayload || []).push('style', styleUpdates);
}
// 返回最终的 updatePayload
// 可能是 null(无变化)、[](空数组,触发 commit 但无实质更新)
// 或包含实际更新内容的数组
return updatePayload;
}这段代码中最值得注意的是样式属性的处理。React 对 style 进行了细粒度的 diff,而不是简单地比较整个 style 对象。这意味着如果你只改变了 color,React 只会更新 color 这一个样式属性,而不会重新设置所有样式。这种优化在样式复杂的应用中能显著提升性能。
例如,从 style={{ color: 'red', fontSize: '14px' }} 变为 style={{ color: 'blue', fontSize: '14px' }},styleUpdates 只会是 { color: 'blue' },而不是整个新 style 对象。这样在 commit 阶段只需要执行 element.style.color = 'blue',避免了重复设置 fontSize。
另一个关键点是事件属性的处理。当你在控制台看到 updatePayload 为空数组 [] 时,很可能就是因为事件属性发生了变化(或者是表单元素)。虽然空数组不包含任何需要更新的 DOM 属性,但它的存在会触发 commit 阶段,确保 Fiber 节点的 memoizedProps 得到更新,这对事件系统的正确运行至关重要。
diffProperties 的返回值总结
经过上面三个步骤的处理,diffProperties 最终会返回一个值,这个值有三种可能的形态,每种形态都代表了不同的更新状态。理解这三种返回值对于理解 React 的更新机制至关重要。
下面的表格总结了三种返回值的含义和典型场景:
| 返回值 | 含义 | 典型场景 | 后续处理 |
|---|---|---|---|
null |
没有任何属性变化 | 普通元素的 props 完全相同 | 不标记 Update flag,commit 阶段跳过 |
[] |
需要触发 commit,但无实质属性更新 | 1. 表单元素(input/select/textarea) 2. 事件属性发生变化 3. 某些特殊情况 |
标记 Update flag,但 commit 阶段不修改 DOM |
['key', value, ...] |
有实质的属性变化 | 普通属性、文本内容、样式等发生变化 | 标记 Update flag,commit 阶段应用到 DOM |
现在我们可以深入理解为什么事件属性变化只返回空数组了。这背后的原因与 React 的事件系统设计密切相关:
React 的事件系统采用事件委托(Event Delegation)机制。这意味着事件监听器并不是注册在每个单独的 DOM 元素上,而是统一注册在根容器(通常是 #root)上。当事件发生时,事件会冒泡到根容器,React 的事件系统会捕获这个事件,然后通过 Fiber 树找到对应的元素和它的事件处理函数。
当事件属性变化时,React 不需要在 DOM 元素上添加或移除监听器,因为所有监听器始终挂载在根容器上,DOM 元素本身没有事件监听器需要更新。然而,React 仍然需要更新 Fiber 节点的 props 指针,将 memoizedProps 指向新的 props 对象,以确保事件触发时能够找到最新的事件处理函数。因此,React 返回空数组 [] 以触发 commit 阶段。空数组会触发 markUpdate,标记 Update flag,接着在 commit 阶段执行 commitUpdate 更新 fiber.memoizedProps,但不会遍历 updatePayload 修改 DOM,因为此时的 updatePayload 为空数组。
挂载阶段(current === null)
在挂载阶段,DOM 节点还不存在,需要从零开始创建。这个阶段包含四个关键步骤:创建 DOM → 追加子节点 → 初始化属性 → 保存引用。
ts
else {
// 挂载阶段:首次渲染,需要创建新的 DOM 节点
const currentHostContext = getHostContext();
// 步骤 1:创建 DOM 实例(如 document.createElement('div'))
const instance = createInstance(
type, // 元素类型,如 'div'、'span'
newProps, // 属性对象
rootContainerInstance, // 根容器
currentHostContext, // 上下文信息
workInProgress, // 当前 fiber
);
// 步骤 2:将所有子节点的 DOM 追加到当前 DOM 中
// 此时子节点的 completeWork 已经完成,DOM 已创建
appendAllChildren(instance, workInProgress, false, false);
// 步骤 3:保存 DOM 实例到 fiber.stateNode
// 这样在 commit 阶段可以通过 fiber.stateNode 访问到 DOM
workInProgress.stateNode = instance;
// 步骤 4:初始化 DOM 属性和事件监听
if (
finalizeInitialChildren(
instance,
type,
newProps,
rootContainerInstance,
currentHostContext,
)
) {
// 返回 true 表示需要自动聚焦(autoFocus),标记 Update flag
markUpdate(workInProgress);
}
}这里的不同函数代表了不同的流程:
-
createInstance:创建真实的 DOM 节点,但还未插入到页面中 -
appendAllChildren:构建 DOM 树结构,将子节点 DOM 追加到父节点 -
stateNode:保存 DOM 引用,是 fiber 和 DOM 的桥梁 -
finalizeInitialChildren:设置属性、绑定事件,返回是否需要自动聚焦
finalizeInitialChildren 详解
finalizeInitialChildren 负责初始化 DOM 元素的属性和事件监听器,是挂载阶段的最后一步:
ts
export function finalizeInitialChildren(
domElement: Instance, // DOM 元素
type: string, // 元素类型,如 'div'、'input'
props: Props, // 属性对象
rootContainerInstance: Container, // 根容器
hostContext: HostContext // 上下文
): boolean {
// 核心:设置所有初始属性(样式、事件、普通属性等)
setInitialProperties(domElement, type, props, rootContainerInstance);
// 返回值:是否需要自动聚焦
// 如果返回 true,会在 completeWork 中标记 Update flag
// 然后在 commit 阶段调用 domElement.focus()
return shouldAutoFocusHostComponent(type, props);
}从源码可以看出,finalizeInitialChildren 非常简洁,主要工作委托给了 setInitialProperties。
setInitialProperties 完整源码解析
setInitialProperties 是挂载阶段设置 DOM 属性的核心函数。这个函数比我们想象的复杂得多,它不仅处理常见的表单元素(input、select、textarea),还特殊处理了很多 HTML5 的媒体元素和其他特殊元素。
整个函数可以分为三个阶段:预处理(根据元素类型进行特殊初始化)、统一属性设置(调用 setInitialDOMProperties)、后处理(特定元素的后续操作)。下面我们详细解析每个阶段。
第一阶段:元素类型预处理与非委托事件注册
在这个阶段,React 会根据元素类型进行不同的初始化操作。特别重要的是,某些事件(如媒体元素的播放事件、滚动事件等)不能使用事件委托机制,需要直接在元素上监听,这些事件被称为"非委托事件"。
ts
export function setInitialProperties(
domElement: Element,
tag: string,
rawProps: Object,
rootContainerElement: Element | Document | DocumentFragment
): void {
const isCustomComponentTag = isCustomComponent(tag, rawProps);
let props: Object;
// 根据元素类型进行预处理
switch (tag) {
case "dialog":
// dialog 元素:监听 cancel 和 close 事件(不冒泡,需要直接监听)
listenToNonDelegatedEvent("cancel", domElement);
listenToNonDelegatedEvent("close", domElement);
props = rawProps;
break;
case "iframe":
case "object":
case "embed":
// 嵌入式内容:监听 load 事件(确保模拟冒泡监听器能触发)
listenToNonDelegatedEvent("load", domElement);
props = rawProps;
break;
case "video":
case "audio":
// 媒体元素:监听所有媒体相关事件(这些事件不冒泡)
// 包括:play、pause、ended、timeupdate 等
for (let i = 0; i < mediaEventTypes.length; i++) {
listenToNonDelegatedEvent(mediaEventTypes[i], domElement);
}
props = rawProps;
break;
case "source":
// source 元素:监听 error 事件
listenToNonDelegatedEvent("error", domElement);
props = rawProps;
break;
case "img":
case "image":
case "link":
// 资源加载元素:监听 error 和 load 事件
listenToNonDelegatedEvent("error", domElement);
listenToNonDelegatedEvent("load", domElement);
props = rawProps;
break;
case "details":
// details 元素:监听 toggle 事件(展开/折叠)
listenToNonDelegatedEvent("toggle", domElement);
props = rawProps;
break;
case "input":
// input 元素:最复杂的处理
// 1. 初始化 wrapper state(判断受控/非受控)
ReactDOMInputInitWrapperState(domElement, rawProps);
// 2. 获取标准化后的 props
props = ReactDOMInputGetHostProps(domElement, rawProps);
// 3. 监听 invalid 事件(表单验证失败时触发)
listenToNonDelegatedEvent("invalid", domElement);
break;
case "option":
// option 元素:验证 props 的有效性
ReactDOMOptionValidateProps(domElement, rawProps);
props = rawProps;
break;
case "select":
// select 元素:处理选中状态
ReactDOMSelectInitWrapperState(domElement, rawProps);
props = ReactDOMSelectGetHostProps(domElement, rawProps);
listenToNonDelegatedEvent("invalid", domElement);
break;
case "textarea":
// textarea 元素:处理 value
ReactDOMTextareaInitWrapperState(domElement, rawProps);
props = ReactDOMTextareaGetHostProps(domElement, rawProps);
listenToNonDelegatedEvent("invalid", domElement);
break;
default:
// 普通元素:直接使用原始 props
props = rawProps;
}
// 验证 props 的有效性(开发环境)
assertValidProps(tag, props);
// 统一设置所有 DOM 属性
setInitialDOMProperties(
tag,
domElement,
rootContainerElement,
props,
isCustomComponentTag
);
// 第三阶段:特定元素的后处理
switch (tag) {
case "input":
// 追踪 input 元素(用于某些内部优化)
track(domElement);
// 后处理:设置 value 和 checked,同步状态
ReactDOMInputPostMountWrapper(domElement, rawProps, false);
break;
case "textarea":
track(domElement);
// 后处理:设置 textarea 的 value
ReactDOMTextareaPostMountWrapper(domElement, rawProps);
break;
case "option":
// 后处理:设置 option 的 selected
ReactDOMOptionPostMountWrapper(domElement, rawProps);
break;
case "select":
// 后处理:设置 select 的选中项
ReactDOMSelectPostMountWrapper(domElement, rawProps);
break;
default:
// 普通元素:如果有 onClick,确保在非交互元素上也能触发
if (typeof props.onClick === "function") {
trapClickOnNonInteractiveElement(domElement);
}
break;
}
}从这段完整的源码可以看出,React 对 HTML 元素的处理非常精细。这里有两个特别重要的函数值得深入解析:trapClickOnNonInteractiveElement 和 ReactDOMInputPostMountWrapper(在代码中表现为 postMountWrapper)。
ReactDOMInputPostMountWrapper 完整源码解析
postMountWrapper 是 input 元素挂载后处理的核心函数,它负责同步 input 元素的 value 和 checked 状态。这个函数看起来复杂,但每一行代码都有其存在的意义,主要是为了处理各种边界情况和浏览器兼容性问题。
第一部分:value 和 defaultValue 的处理
ts
export function postMountWrapper(
element: Element,
props: Object,
isHydrating: boolean,
) {
const node = ((element: any): InputWithWrapperState);
// 只有当 props 中有 value 或 defaultValue 时才处理
if (props.hasOwnProperty('value') || props.hasOwnProperty('defaultValue')) {
const type = props.type;
const isButton = type === 'submit' || type === 'reset';
// 特殊处理:submit/reset 按钮
// 避免设置 value 属性,因为会覆盖浏览器提供的默认值
// 参考:https://github.com/facebook/react/issues/12872
if (isButton && (props.value === undefined || props.value === null)) {
return;
}
// 获取初始值(在 InitWrapperState 中保存的)
const initialValue = toString(node._wrapperState.initialValue);
// 非 SSR hydration 时才设置值
if (!isHydrating) {
if (disableInputAttributeSyncing) {
// 实验性特性:不同步 value 属性
const value = getToStringValue(props.value);
// 当不同步 value 属性时,value 属性直接指向 React prop
// 只有当它存在时才赋值
if (value != null) {
// 按钮始终赋值,这样可以清空按钮文本(赋空字符串)
// 对于其他 input,只有当值不同时才重新赋值
// 这避免了 Firefox (~60.0.1) 过早地将必填输入标记为无效
if (isButton || value !== node.value) {
node.value = toString(value);
}
}
} else {
// 标准模式:同步 value 属性
// 使用 wrapperState._initialValue,它的优先级是:
// 1. React 的 value prop(如果存在)
// 2. React 的 defaultValue prop(如果存在)
// 3. 空字符串
if (initialValue !== node.value) {
node.value = initialValue;
}
}
}
// 处理 defaultValue
if (disableInputAttributeSyncing) {
// 实验性特性:从 defaultValue prop 直接赋值
const defaultValue = getToStringValue(props.defaultValue);
if (defaultValue != null) {
node.defaultValue = toString(defaultValue);
}
} else {
// 标准模式:defaultValue 和 value 同步
node.defaultValue = initialValue;
}
}
// ... checked 处理部分
}这部分代码处理了 input 元素的值同步,需要处理多个复杂的场景。下面逐一解析每个关键场景:
场景一:submit/reset 按钮的默认文本保护
这是针对 GitHub issue #12872 的修复。浏览器会为 submit 和 reset 按钮提供默认的本地化文本(如英文的 "Submit"、"Reset",中文的 "提交"、"重置")。如果 React 设置了 value 为 undefined 或 null,会覆盖这些有用的默认文本,导致按钮显示为空。
问题场景:
jsx
// 问题代码:按钮会显示为空白
function Form() {
const [submitText, setSubmitText] = useState(undefined);
return <input type="submit" value={submitText} />;
// 浏览器期望显示 "Submit",但 React 设置 value=undefined 后变成空白
}React 的解决方案:
jsx
// React 的处理逻辑:
if (isButton && (props.value === undefined || props.value === null)) {
return; // 直接返回,不设置 value
}
// 正确用法 1:不设置 value,使用浏览器默认文本
<input type="submit" /> // 显示 "Submit" 或本地化文本
// 正确用法 2:明确设置 value
<input type="submit" value="提交表单" /> // 显示 "提交表单"
// 避免的错误用法:
<input type="submit" value={undefined} /> // React 会跳过设置,保留默认文本
<input type="submit" value={null} /> // React 会跳过设置,保留默认文本这个处理确保了在没有明确 value 的情况下,用户能看到有意义的按钮文本,而不是空白按钮。
场景二:SSR hydration 中的用户输入保护
在服务端渲染(SSR)的场景下,存在一个时间窗口:HTML 已经发送到浏览器,但 React 还没有完成 hydration。在这个窗口期,用户可能已经开始输入。如果 React 在 hydration 时强制设置初始值,会覆盖用户的输入,造成非常糟糕的用户体验。
问题场景示例:
jsx
// 服务端渲染的组件
function SearchForm() {
const [query, setQuery] = useState("");
return (
<input
type="text"
value={query}
onChange={(e) => setQuery(e.target.value)}
/>
);
}下面用甘特图展示 SSR hydration 的完整时间线和可能出现的问题:

从甘特图可以看出关键的时间冲突点:
- 300ms:用户看到页面并开始准备输入
- 320-500ms:用户正在输入 "React"
- 450ms:React hydration 开始
- 冲突:如果此时 React 设置
node.value = "",会清空用户输入
下面用流程图展示正确和错误两种处理方式的对比:
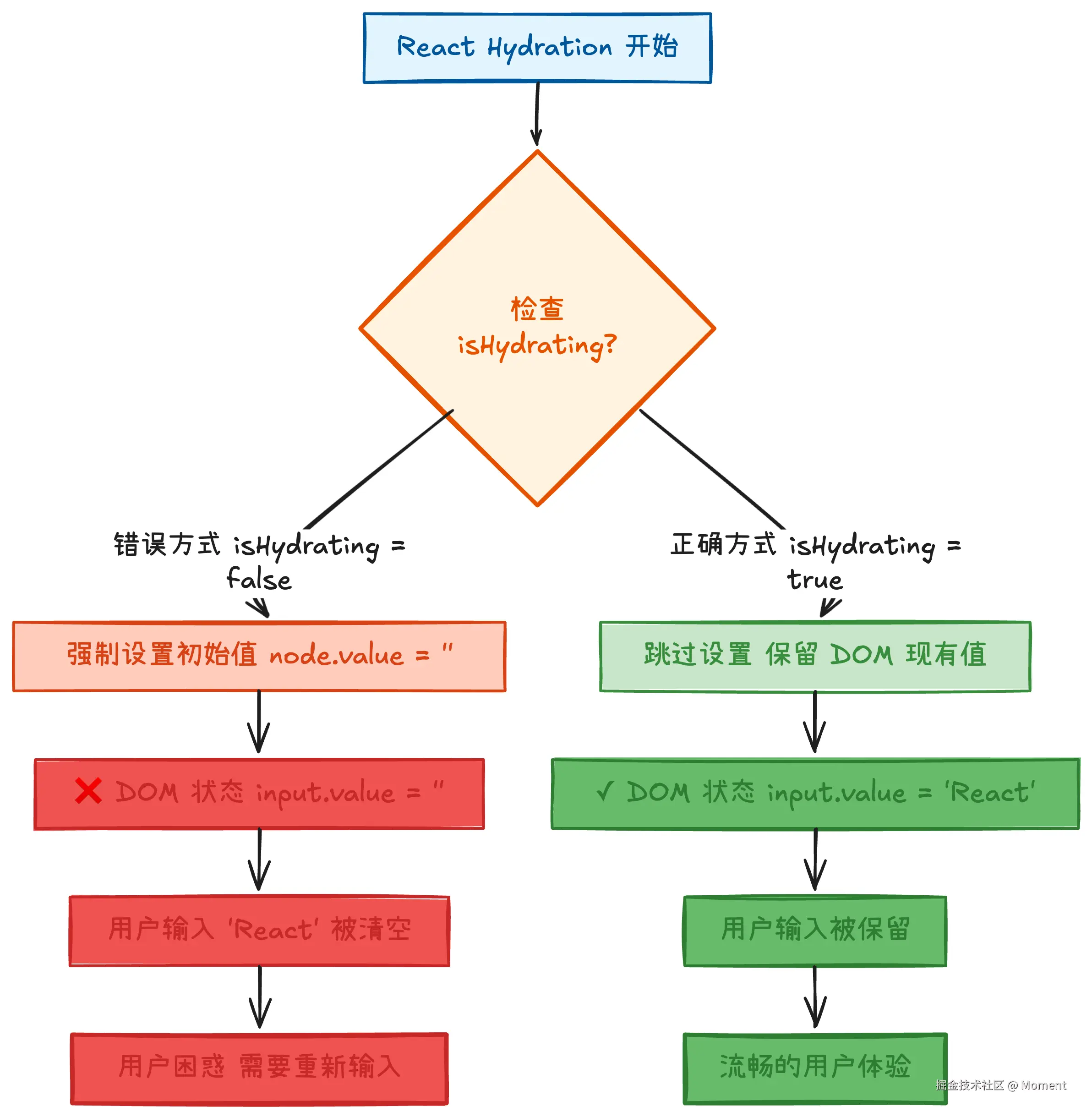
React 的保护机制:
ts
// React 在 hydration 时的处理:
if (!isHydrating) {
node.value = initialValue; // 只在非 hydration 时设置
} else {
// hydration 时跳过设置,保留 DOM 中已有的值
// 这个值可能是:
// 1. 服务端渲染的初始值
// 2. 用户在 hydration 前输入的值 ← 重点保护这个!
}这个保护机制确保了即使在网络较慢的情况下,用户的输入也不会丢失。
场景三:实验性特性 disableInputAttributeSyncing
这是一个实验性的性能优化特性,允许 React 不同步 input 元素的 value 属性(attribute)和 value 属性(property)。理解这需要先了解 HTML 中 attribute 和 property 的区别:
attribute vs property 的区别:
js
// HTML: <input value="initial" />
// attribute(HTML 属性):
input.getAttribute("value"); // → "initial"(永远不变)
// property(DOM 属性):
input.value; // → 当前输入的值(动态变化)
// 用户输入 "hello" 后:
input.getAttribute("value"); // → 还是 "initial"
input.value; // → "hello"标准模式(disableInputAttributeSyncing = false):
jsx
<input value={value} onChange={handleChange} />;
// React 会同时设置:
input.value = value; // property(实际显示的值)
input.defaultValue = value; // attribute(影响表单重置)
// 优点:行为完整,表单重置正常工作
// 缺点:额外的 DOM 操作,性能略差实验模式(disableInputAttributeSyncing = true):
jsx
<input value={value} onChange={handleChange} />;
// React 只设置:
input.value = value; // property(实际显示的值)
// 不设置 defaultValue(attribute)
// 优点:减少 DOM 操作,性能更好
// 缺点:表单重置可能不符合预期实际影响对比:
jsx
function TestForm() {
const [value, setValue] = useState("初始值");
return (
<form>
<input value={value} onChange={(e) => setValue(e.target.value)} />
<button type="reset">重置</button>
</form>
);
}
// 标准模式:
// 1. 用户输入 "新内容"
// 2. 点击 "重置" 按钮
// 3. input.value 恢复为 "初始值" ✓
// 实验模式:
// 1. 用户输入 "新内容"
// 2. 点击 "重置" 按钮
// 3. input.value 可能不会恢复(因为 attribute 没有设置)❌这个特性目前还在实验阶段,React 团队在权衡性能提升和功能完整性之间的取舍。
第二部分:checked 和 defaultChecked 的处理
ts
// 处理 checked 状态
// 首先需要处理一个 Chrome bug:
// 设置 defaultChecked 有时会影响 checked 的值(即使在元素分离后)
// 参考:https://bugs.chromium.org/p/chromium/issues/detail?id=608416
// 临时清空 name 属性,避免干扰 radio button 组
const name = node.name;
if (name !== '') {
node.name = '';
}
if (disableInputAttributeSyncing) {
// 实验性特性:不同步 checked 属性
// checked 属性永远不会被自动赋值,必须手动设置
// 在 hydration 时不设置,以免修改用户已有的输入
if (!isHydrating) {
updateChecked(element, props);
}
// 只有当 defaultChecked 被定义时才赋值
// 这样可以节省 DOM 写操作(对于 text input、submit/reset 不需要)
if (props.hasOwnProperty('defaultChecked')) {
// 这个巧妙的操作:先取反再取反
// 目的是强制触发 Chrome 的内部状态更新,避免 bug
node.defaultChecked = !node.defaultChecked;
node.defaultChecked = !!props.defaultChecked;
}
} else {
// 标准模式:同步 checked 属性
// 同时赋值 checked 属性和 defaultChecked 属性,优先级:
// 1. React 的 checked prop(如果存在)
// 2. React 的 defaultChecked prop(如果存在)
// 3. 否则为 false
// 同样的巧妙操作:先取反再取反
node.defaultChecked = !node.defaultChecked;
node.defaultChecked = !!node._wrapperState.initialChecked;
}
// 恢复 name 属性
if (name !== '') {
node.name = name;
}
}这部分代码处理 checkbox 和 radio 的 checked 状态,涉及浏览器 bug 修复、组件隔离和用户输入保护等多个复杂场景:
场景一:Chrome defaultChecked bug 的巧妙修复
Chrome 浏览器存在一个长期未修复的 bug(Chromium Issue #608416):设置 defaultChecked 属性时,有时会意外地影响 checked 属性的值,即使在元素已经从 DOM 树分离后仍然会发生。这会导致 checkbox 和 radio button 的状态不正确。
问题的本质:
js
// Chrome 的 bug 行为:
const checkbox = document.createElement("input");
checkbox.type = "checkbox";
checkbox.checked = true; // 用户勾选了
// 正常情况:设置 defaultChecked 不应该影响 checked
checkbox.defaultChecked = false;
// Bug:checked 的值可能被意外改变!
console.log(checkbox.checked); // 期望:true,实际:可能变成 false ❌React 的巧妙解决方案(双重取反技巧):
ts
// React 的处理代码:
node.defaultChecked = !node.defaultChecked; // 第一步:先取反
node.defaultChecked = !!props.defaultChecked; // 第二步:再设置为目标值下面用流程图展示双重取反如何绕过 Chrome bug:
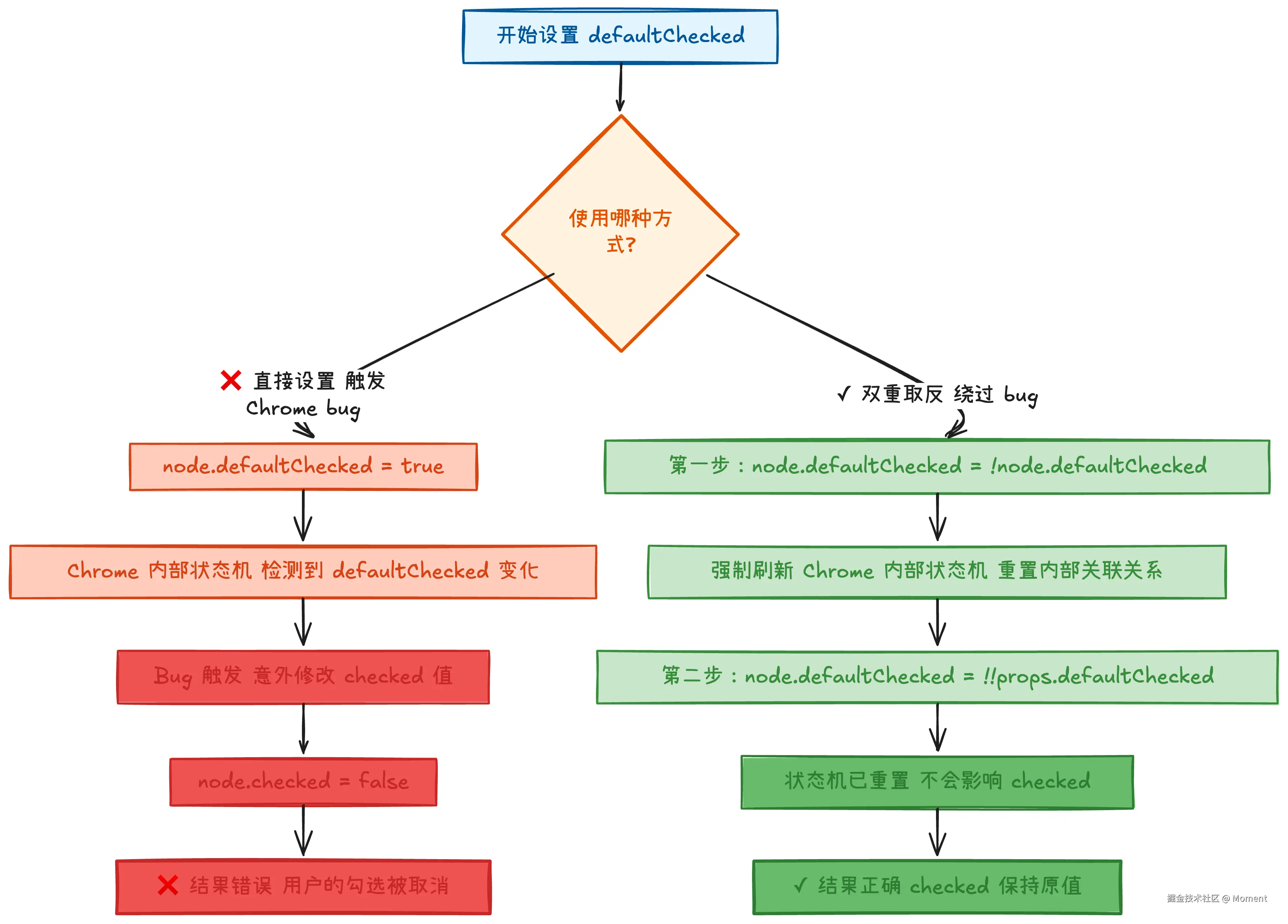
为什么这样有效?
- 第一次取反:强制 Chrome 刷新内部状态机,重新计算
defaultChecked和checked的关系 - 第二次赋值:此时状态机已经正确更新,设置目标值不会影响
checked - 这个操作类似于"敲一下电视机让它正常工作",虽然看起来奇怪,但确实能绕过 bug
实际效果对比:
jsx
function CheckboxTest() {
const [checked, setChecked] = useState(true);
return (
<input
type="checkbox"
checked={checked}
onChange={(e) => setChecked(e.target.checked)}
/>
);
}
// 不使用双重取反(可能触发 bug):
node.defaultChecked = true;
// → checked 可能被意外改变 ❌
// 使用双重取反(绕过 bug):
node.defaultChecked = !node.defaultChecked;
node.defaultChecked = true;
// → checked 保持正确的值 ✓这个解决方案虽然看起来不太优雅,但它是经过大量测试验证的最可靠方法,在所有版本的 Chrome 中都能正常工作。
场景二:Radio button 组的隔离保护
Radio button 通过相同的 name 属性形成互斥组,同一时间只能有一个按钮被选中。当 React 设置其中一个按钮的 defaultChecked 时,浏览器可能会触发组内的同步机制,影响其他按钮的状态。为了避免这种副作用,React 采用了临时隔离策略。
Radio button 组的同步机制:
html
<!-- Radio button 组:同一时间只能选中一个 -->
<input type="radio" name="gender" value="male" id="male" />
<input type="radio" name="gender" value="female" id="female" />
<script>
// 当设置一个 radio 的 defaultChecked 时:
document.getElementById("male").defaultChecked = true;
// 浏览器内部会:
// 1. 检查 name="gender" 的所有 radio button
// 2. 如果其他按钮是 checked,可能取消选中
// 3. 更新组内的状态同步
</script>React 的隔离策略:
ts
// React 的处理流程:
const name = node.name; // 保存原始 name
// 第一步:临时移除出组
if (name !== "") {
node.name = ""; // 清空 name,将按钮从组中移除
}
// 第二步:安全地设置 defaultChecked
node.defaultChecked = !node.defaultChecked;
node.defaultChecked = !!props.defaultChecked;
// 此时按钮是孤立的,不会触发组同步
// 第三步:恢复到组中
if (name !== "") {
node.name = name; // 恢复 name,重新加入组
}下面用流程图展示 Radio button 组的隔离处理过程:
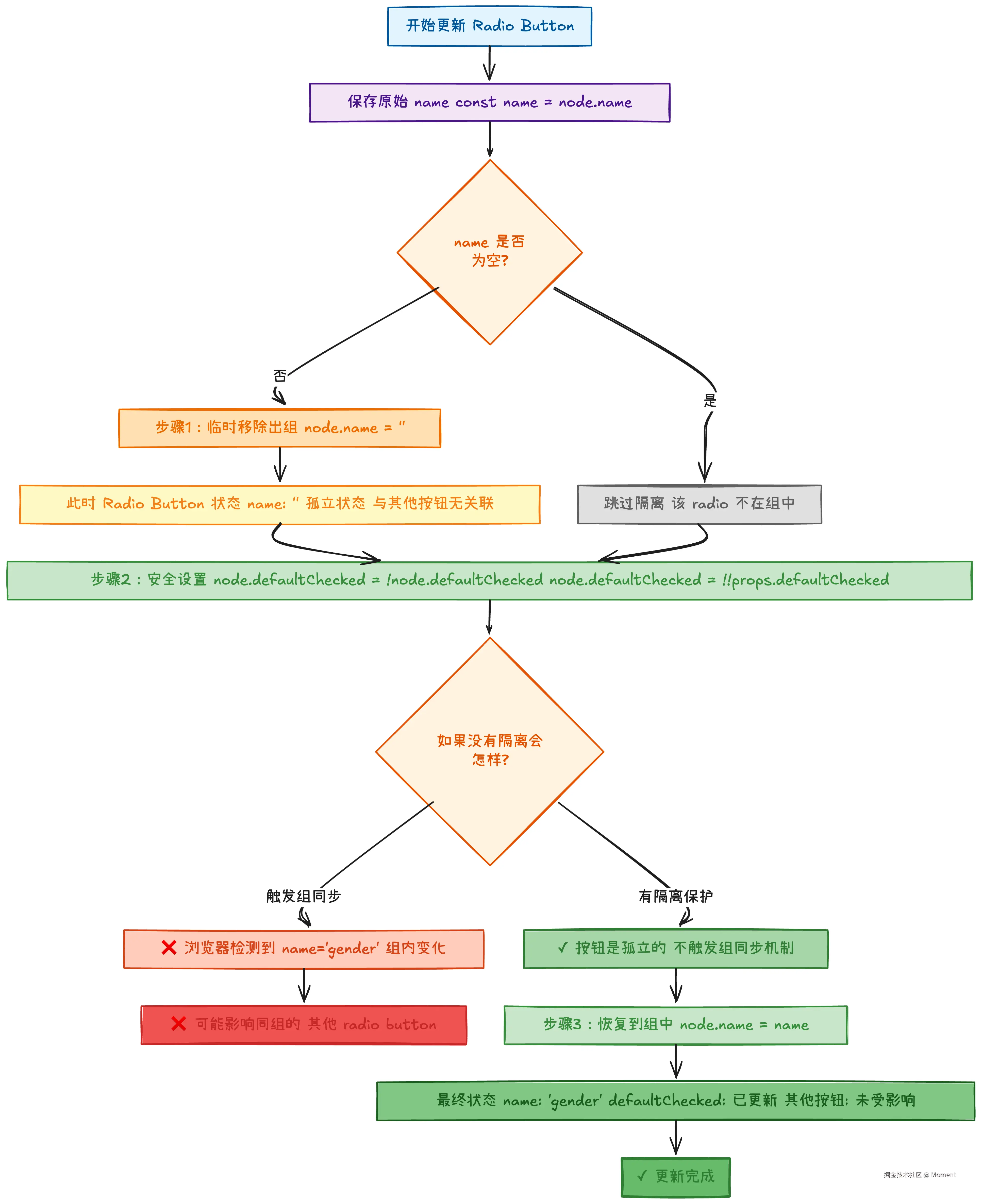
为什么这样有效?
jsx
// 场景:更新一个 radio button
function GenderSelector() {
const [gender, setGender] = useState("male");
return (
<>
<input
type="radio"
name="gender"
value="male"
checked={gender === "male"}
onChange={(e) => setGender(e.target.value)}
/>
<input
type="radio"
name="gender"
value="female"
checked={gender === "female"}
onChange={(e) => setGender(e.target.value)}
/>
</>
);
}
// 不使用隔离(可能出现问题):
// 更新 male 按钮时:
// node.name = 'gender' // 按钮在组中
// node.defaultChecked = true
// → 浏览器同步组状态,female 可能被意外影响 ❌
// 使用隔离(安全):
// 更新 male 按钮时:
// node.name = '' // 临时移出组
// node.defaultChecked = true // 安全设置
// node.name = 'gender' // 恢复到组中
// → 不影响 female 按钮 ✓这个策略确保了每个 radio button 的状态更新都是独立的,不会因为浏览器的组同步机制而相互干扰。
场景三:SSR hydration 中的 checkbox/radio 状态保护
与文本输入类似,checkbox 和 radio button 在 SSR hydration 时也需要保护用户的交互。用户可能在 React hydration 完成前就点击了 checkbox 或选择了 radio button,这些操作必须被保留。
问题时序(Checkbox 场景):
jsx
// 服务端渲染的组件
function TermsAcceptance() {
const [accepted, setAccepted] = useState(false);
return (
<label>
<input
type="checkbox"
checked={accepted}
onChange={(e) => setAccepted(e.target.checked)}
/>
我同意服务条款
</label>
);
}下面用甘特图展示 Checkbox 在 SSR hydration 中的时间线:
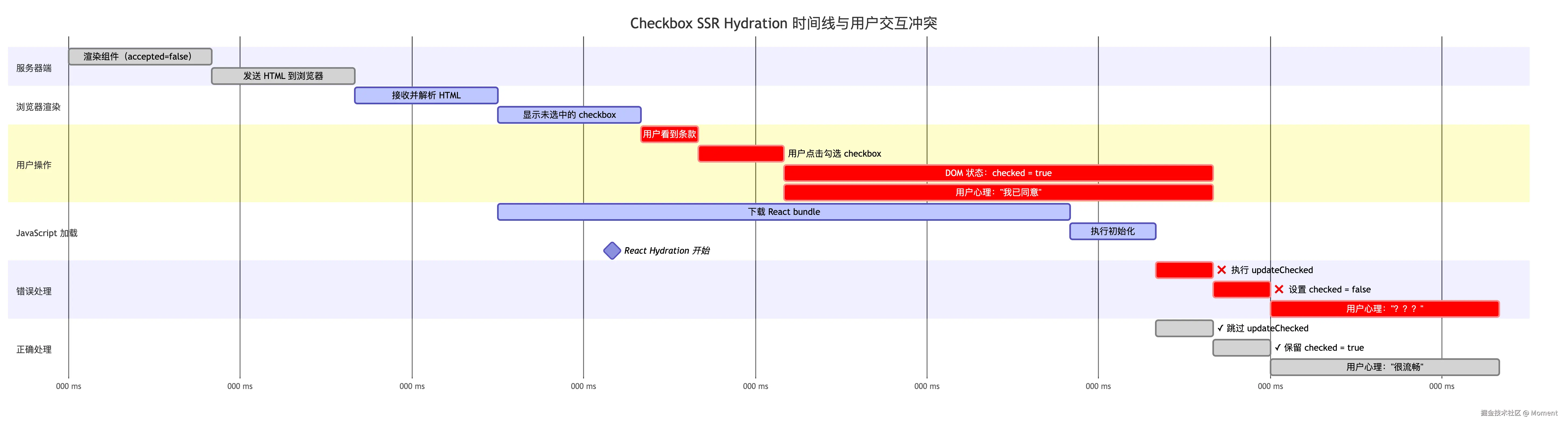
从甘特图可以清晰看到关键的冲突点:
- 220-250ms:用户点击并勾选 checkbox
- 250-400ms:用户认为已经同意,checked = true
- 380ms:React hydration 开始
- 冲突时刻:如果执行
updateChecked,会将checked重置为false,用户的操作被抹除
React 的保护机制:
ts
// React 在 hydration 时的处理:
if (!isHydrating) {
updateChecked(element, props); // 正常更新:设置 checked 状态
} else {
// hydration 时跳过更新
// 保留 DOM 中已有的状态,可能是:
// 1. 服务端渲染的初始状态
// 2. 用户在 hydration 前的操作 ← 重点保护这个!
}Radio button 场景(更复杂):
jsx
function PaymentMethod() {
const [method, setMethod] = useState("credit");
return (
<>
<label>
<input
type="radio"
name="payment"
value="credit"
checked={method === "credit"}
onChange={(e) => setMethod(e.target.value)}
/>
信用卡
</label>
<label>
<input
type="radio"
name="payment"
value="debit"
checked={method === "debit"}
onChange={(e) => setMethod(e.target.value)}
/>
借记卡
</label>
</>
);
}Radio button 组的 hydration 更复杂,因为涉及多个按钮的互斥状态。下面用甘特图展示完整时间线:
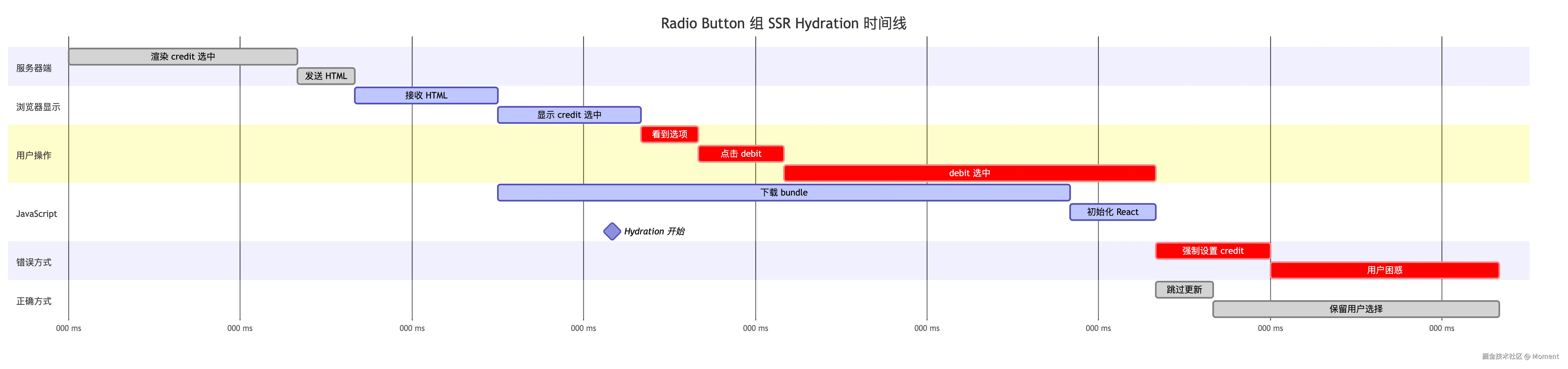
从甘特图可以看出 Radio button 组的复杂性:
- 220-250ms:用户点击 debit 按钮
- 250-400ms:DOM 状态变为
credit.checked = false,debit.checked = true - 380ms:React hydration 开始
- 关键决策:
- 错误方式:强制设置初始状态,恢复为
credit.checked = true,覆盖用户选择 - 正确方式:跳过更新,保留用户的选择
debit.checked = true
- 错误方式:强制设置初始状态,恢复为
Radio button 比 checkbox 更复杂,因为涉及组内的互斥关系。React 的保护机制确保了整个组的状态都不会被意外覆盖。
这个保护机制确保了无论用户的操作有多快,他们的选择都不会在 hydration 时丢失,提供了流畅的用户体验,让使用 React 的小朋友不会有那么多问号。
下面用流程图总结 React 的 hydration 保护机制:
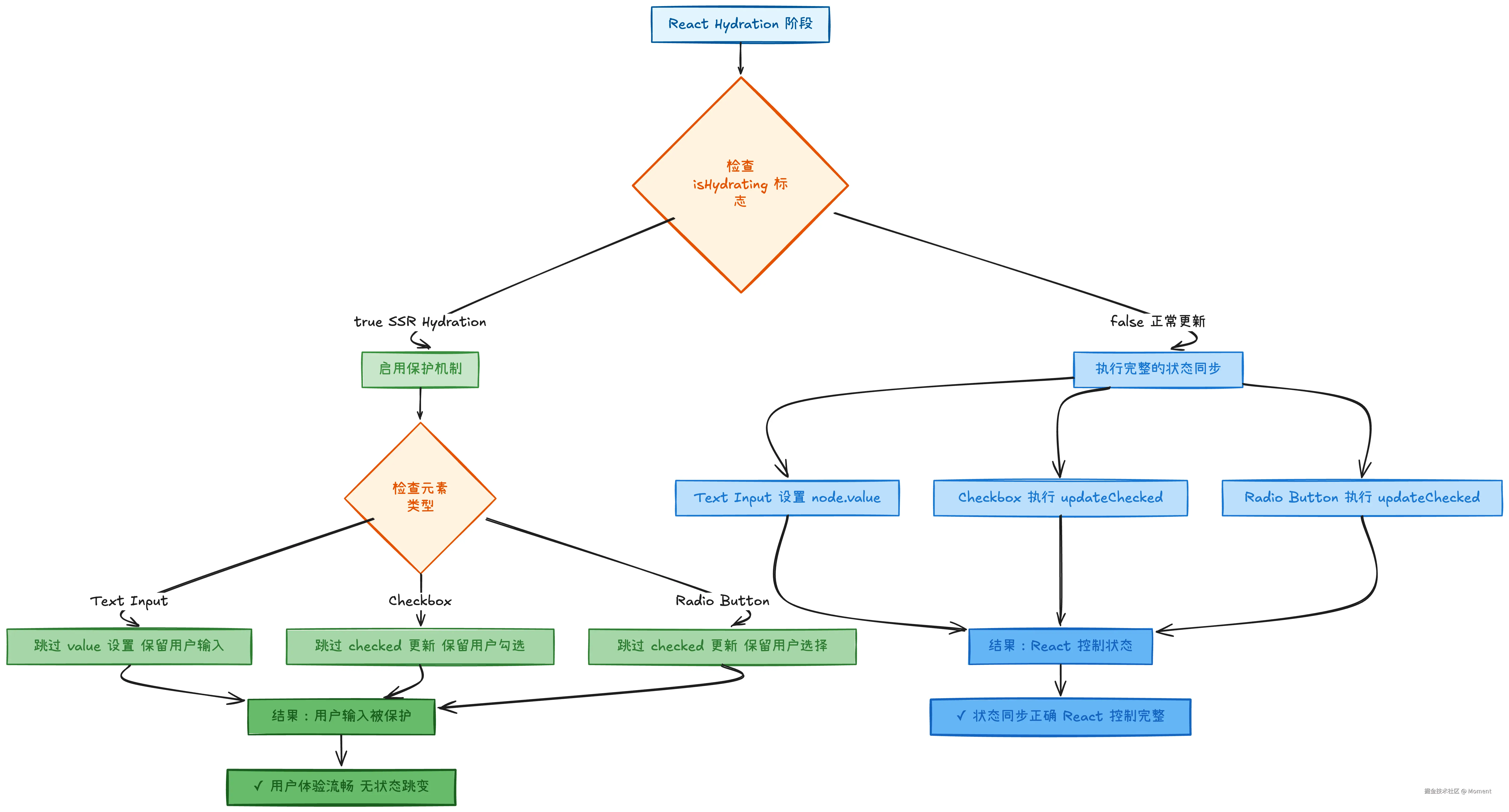
关键设计思想:
- 区分场景:通过
isHydrating标志区分正常更新和 SSR hydration - 选择性保护:只在 hydration 时跳过状态设置,保护用户已有的交互
- 类型无关:Text Input、Checkbox、Radio Button 都使用相同的保护策略
- 用户优先:在服务端状态和用户操作冲突时,优先保留用户的操作
整体流程总结:
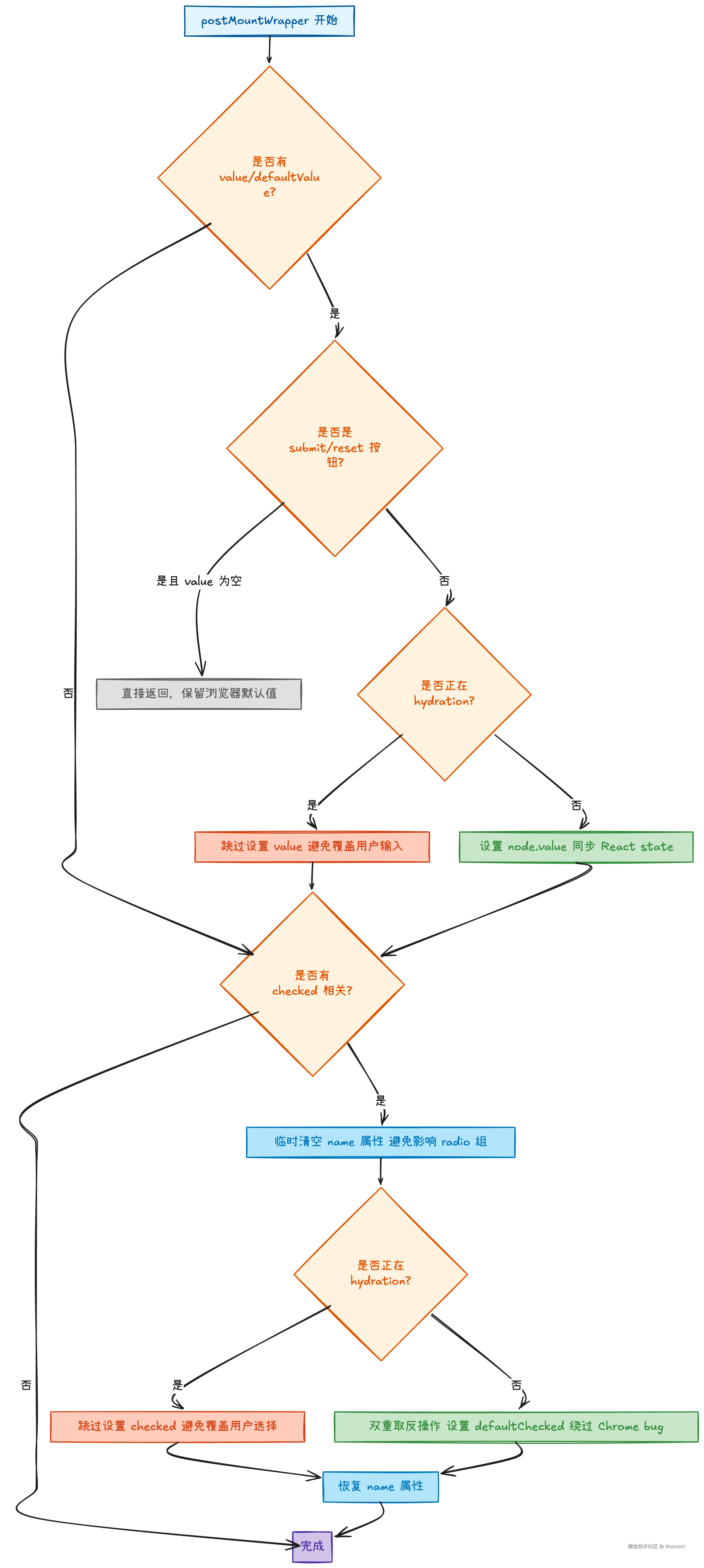
关键要点总结:
- SSR hydration 优先:在 hydration 时不覆盖用户输入,这是正确性的保证
- 浏览器 bug 处理:针对 Chrome 的 bug 使用双重取反技巧
- 特殊元素处理:submit/reset 按钮不覆盖浏览器默认值
- Radio button 隔离:临时清空 name 避免影响同组按钮
- 实验性特性支持:
disableInputAttributeSyncing允许不同的同步策略
这个函数完美体现了 React 团队对细节的极致追求,为了确保在各种场景和浏览器中都能正确工作,处理了大量的边界情况。
trapClickOnNonInteractiveElement 函数详解
这是一个针对 Mobile Safari bug 的兼容性修复函数:
ts
function noop() {}
export function trapClickOnNonInteractiveElement(node: HTMLElement) {
// Mobile Safari 在非交互元素上不会正确地触发冒泡的 click 事件
// 解决方法:在目标节点上附加一个空的 click 监听器
// 参考:https://www.quirksmode.org/blog/archives/2010/09/click_event_del.html
node.onclick = noop;
}下面用流程图展示 Mobile Safari bug 和 React 的修复方案:
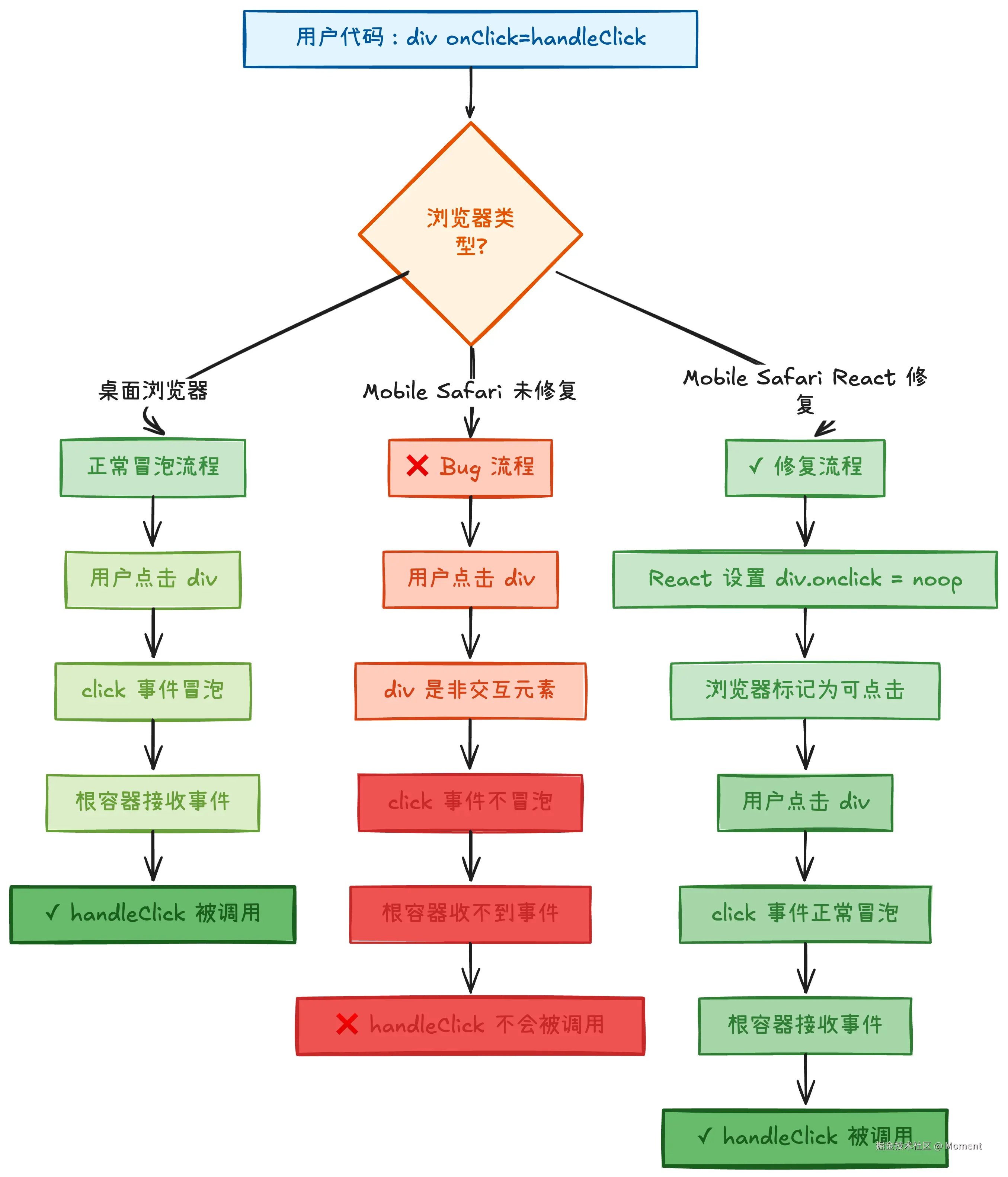
触发条件和影响范围:
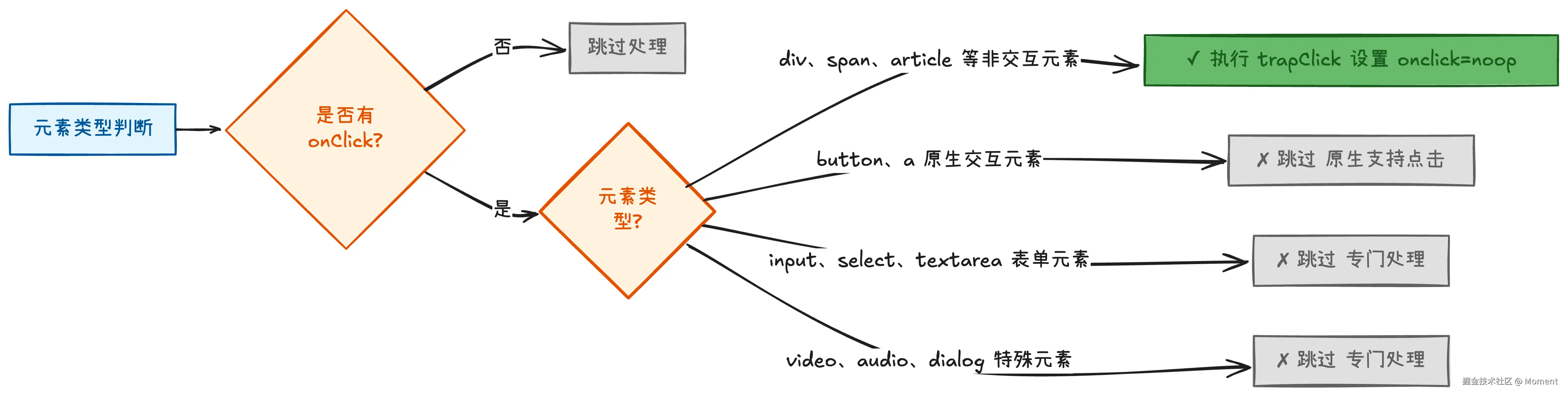
核心设计思想:
- 为什么用
onclick属性?简单高效,自动覆盖,无需清理 - 为什么用空函数
noop?只需标记元素可点击,真正处理在事件委托中 - 为什么所有浏览器都执行?开销小(只设置属性),确保行为一致
这个简单的函数体现了 React 对浏览器兼容性的精细处理。
React 事件系统的分类处理
React 的事件系统根据事件的特性采用了两种不同的监听策略:事件委托和非委托事件。下面的流程图展示了 React 如何判断和处理不同类型的事件:
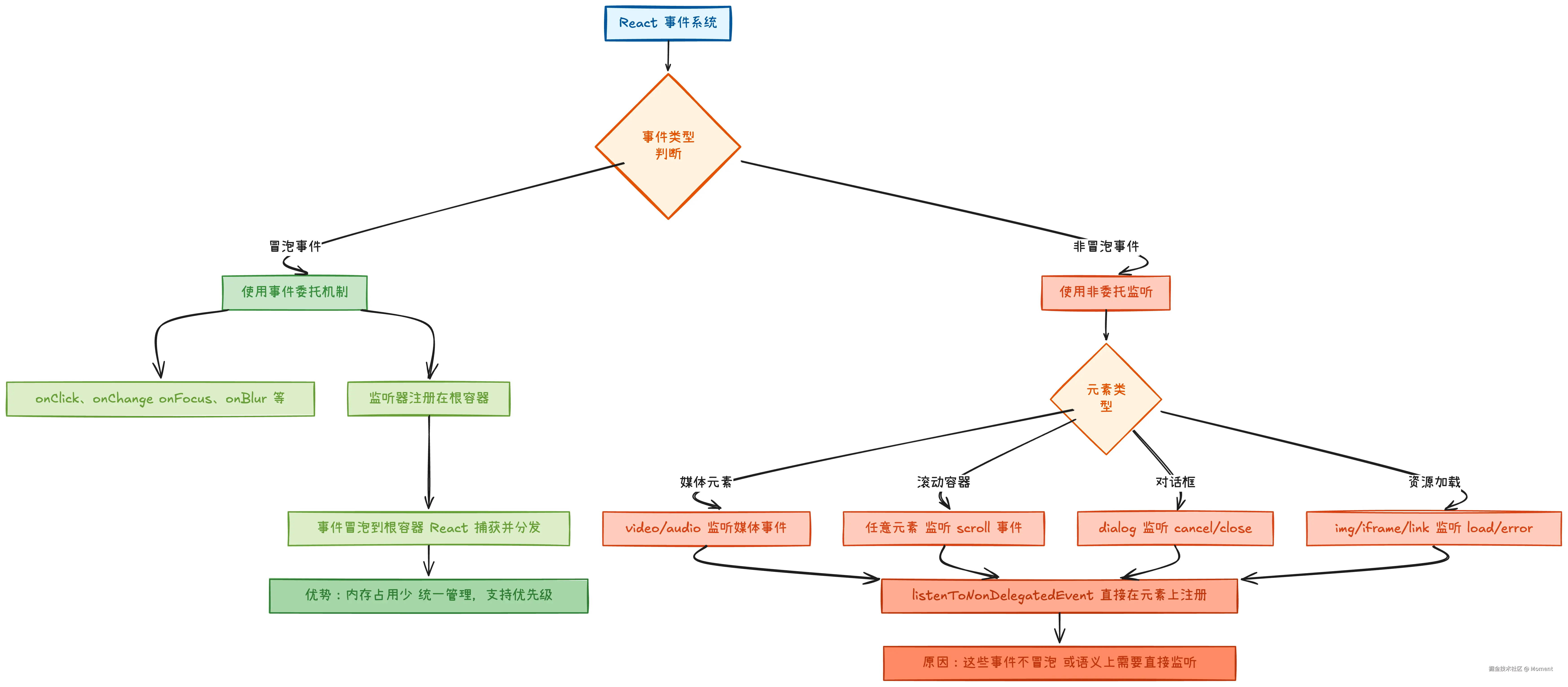
举例说明 input 元素的完整处理流程。下面的流程图展示了受控组件和非受控组件的不同处理路径:
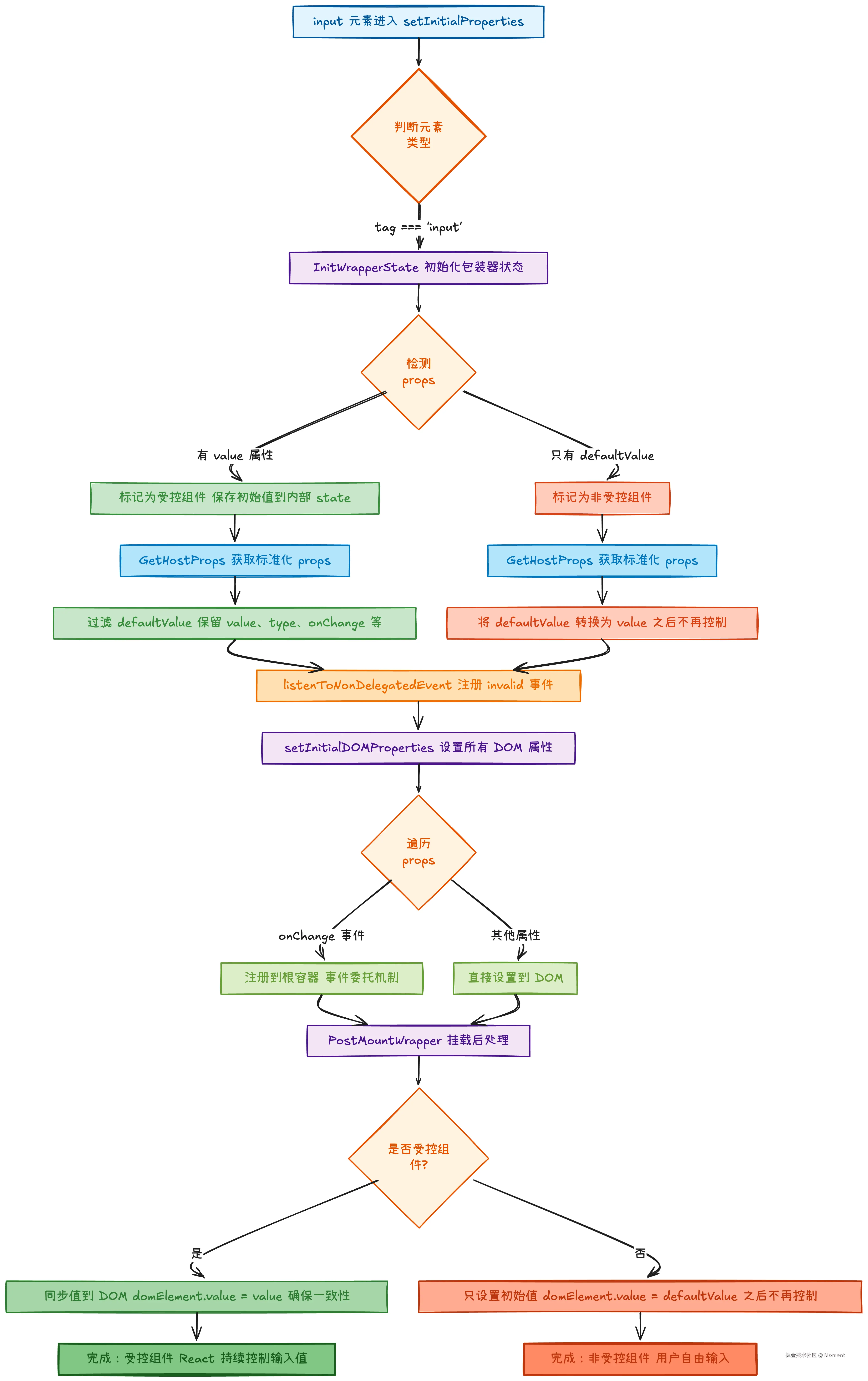
从流程图可以清晰看出受控组件和非受控组件的关键区别:
受控组件通过 value 绑定 React 状态,每次输入都会触发 onChange 更新状态并重新渲染,React 确保 DOM 值与状态一致。
jsx
<input type="text" value={value} onChange={handleChange} />非受控组件通过 defaultValue 设置初始值,用户输入直接修改 DOM,React 不再干预后续的值更新。
jsx
<input type="text" defaultValue="初始值" />核心区别在于,受控组件由 React 完全控制输入值,而非受控组件只在初始化时与 React 同步,后续依赖 DOM 控制。
setInitialDOMProperties 完整源码解析
setInitialDOMProperties 是实际设置 DOM 属性的核心函数,通过 for...in 循环遍历 props,根据属性类型进行分类处理。
ts
function setInitialDOMProperties(
tag: string,
domElement: Element,
rootContainerElement: Element | Document | DocumentFragment,
nextProps: Object,
isCustomComponentTag: boolean
): void {
for (const propKey in nextProps) {
if (!nextProps.hasOwnProperty(propKey)) {
continue;
}
const nextProp = nextProps[propKey];
if (propKey === "style") {
// 样式属性:转换为 CSS 字符串或设置到 element.style
setValueForStyles(domElement, nextProp);
} else if (propKey === "dangerouslySetInnerHTML") {
// innerHTML 属性:直接设置 HTML 内容(需防范 XSS)
const nextHtml = nextProp ? nextProp.__html : undefined;
if (nextHtml != null) {
setInnerHTML(domElement, nextHtml);
}
} else if (propKey === "children") {
// children 属性:只处理文本或数字类型
if (typeof nextProp === "string") {
// textarea 空字符串特殊处理(IE11 兼容性)
const canSetTextContent = tag !== "textarea" || nextProp !== "";
if (canSetTextContent) {
setTextContent(domElement, nextProp);
}
} else if (typeof nextProp === "number") {
setTextContent(domElement, "" + nextProp);
}
} else if (
propKey === "suppressContentEditableWarning" ||
propKey === "suppressHydrationWarning"
) {
// React 内部属性:跳过,不设置到 DOM
} else if (propKey === "autoFocus") {
// autoFocus:延迟到 commit 阶段处理(DOM 插入后才能聚焦)
} else if (registrationNameDependencies.hasOwnProperty(propKey)) {
// 事件属性:React 合成事件系统
if (nextProp != null) {
// scroll 事件不冒泡,需直接在元素上监听
if (propKey === "onScroll") {
listenToNonDelegatedEvent("scroll", domElement);
}
// 其他事件在根容器上注册(事件委托)
}
} else if (nextProp != null) {
// 普通 HTML 属性:className、id、title、data-* 等
setValueForProperty(domElement, propKey, nextProp, isCustomComponentTag);
}
}
}属性处理优先级和分类逻辑:
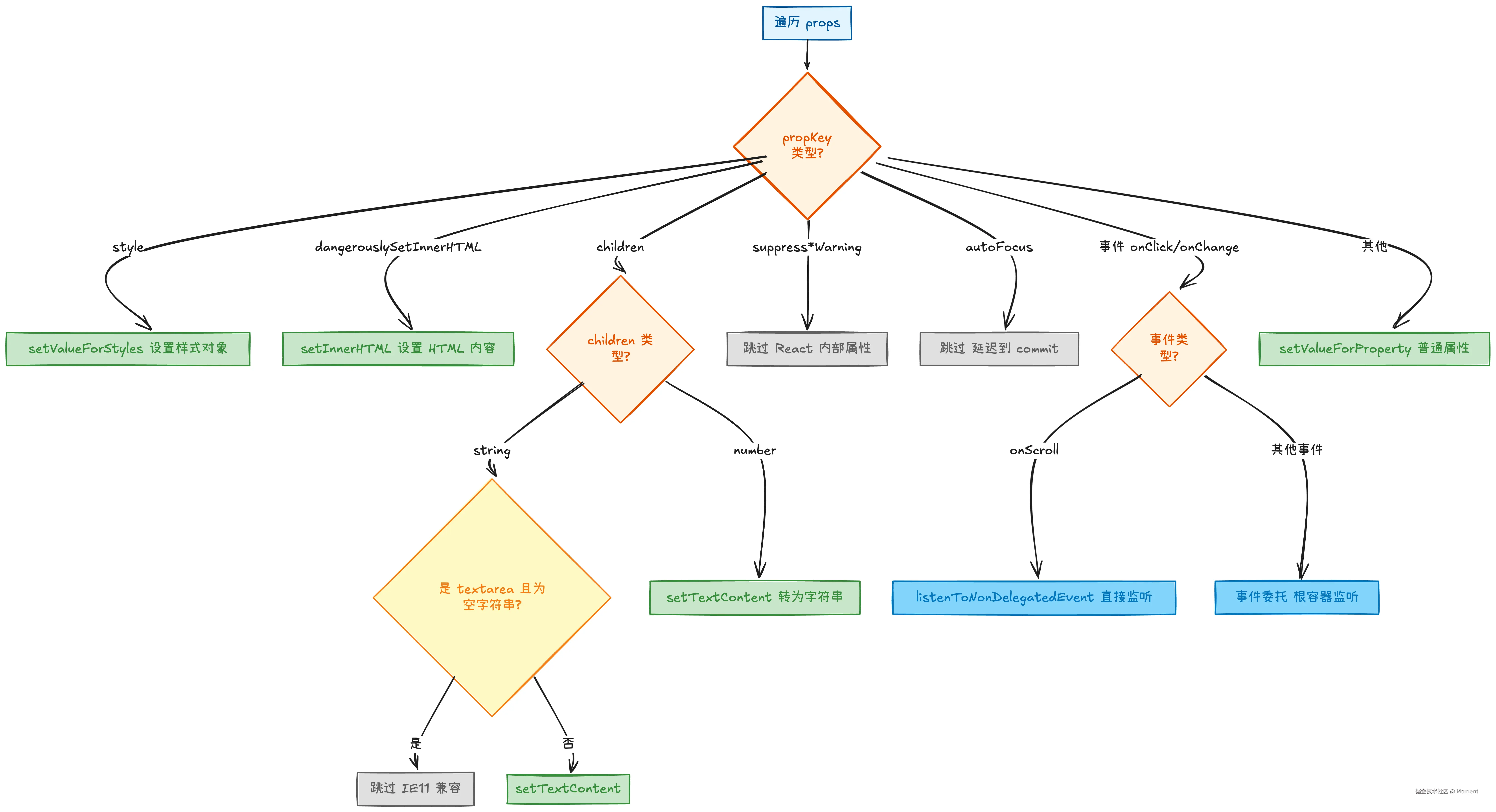
textarea 的空字符串特殊处理
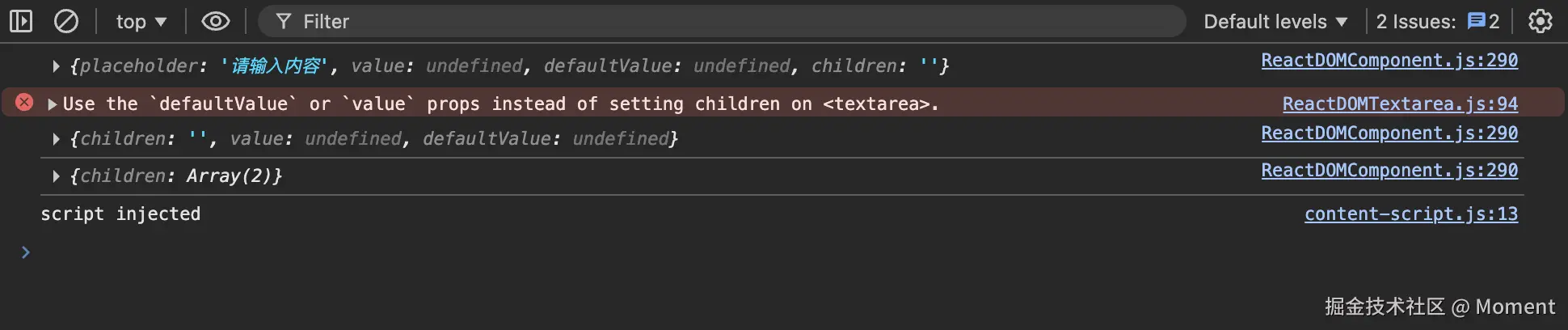
这是针对 IE11 的兼容性修复:如果给 <textarea> 设置空的 textContent,会导致 placeholder 不显示,必须等到用户聚焦并失焦后才会显示。
jsx
// React 不会设置 textContent(避免 IE11 bug)
<textarea>{''}</textarea>
// placeholder 能正常显示
<textarea placeholder="请输入内容"></textarea>我们会在浏览器看到如下输出警告:
autoFocus 的延迟处理
autoFocus 在 completeWork 阶段跳过,因为此时 DOM 还未插入页面。只有插入文档后的元素才能被聚焦,因此延迟到 commit 阶段执行。
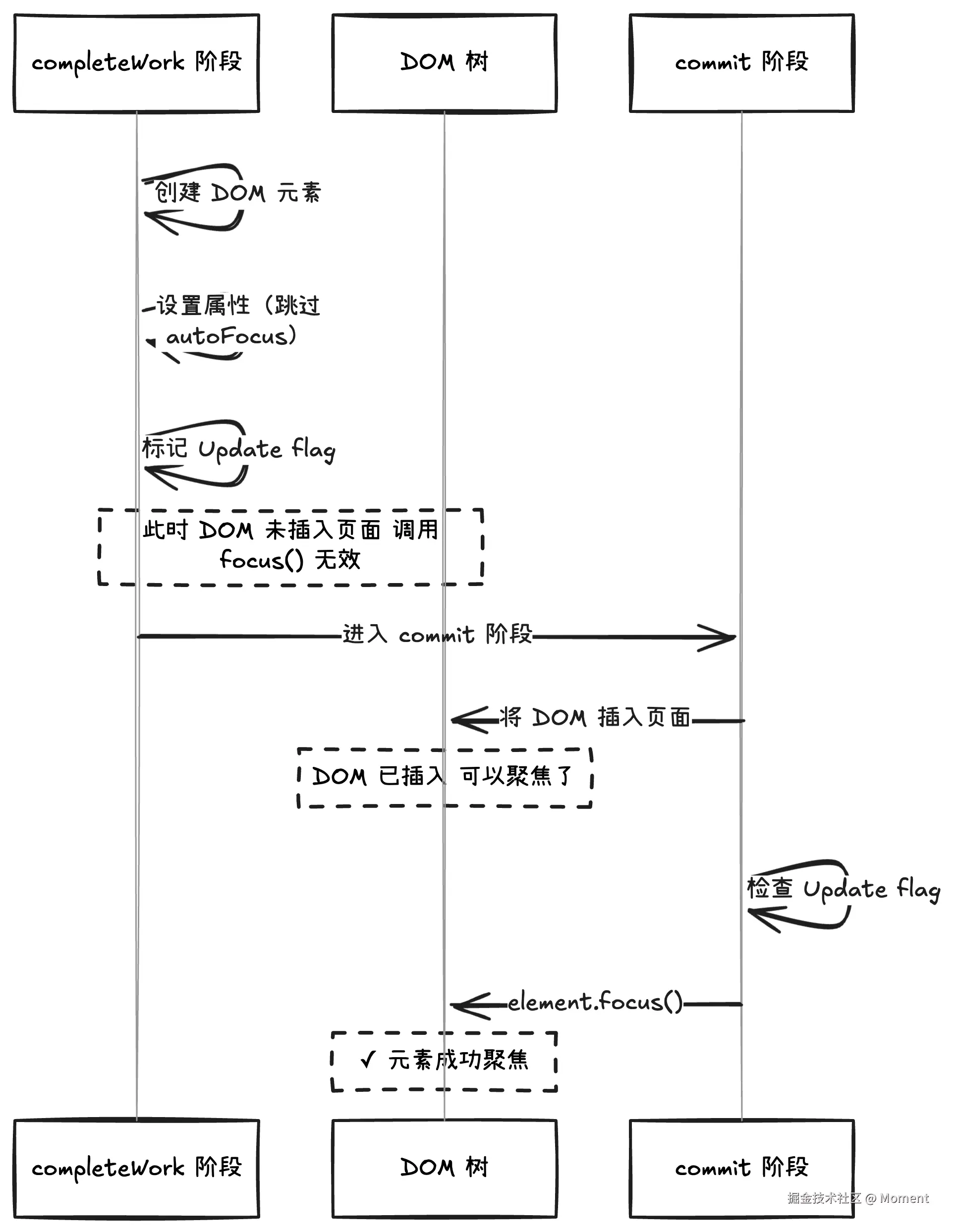
onScroll 事件的特殊处理
scroll 事件不冒泡,无法使用事件委托,必须直接在元素上监听。其他事件(如 onClick)则通过事件委托在根容器统一处理。

属性设置的优先级顺序
React 的 if-else 顺序不是随意的,而是确保属性之间的覆盖关系正确:
style→ 最常用,需要特殊处理(对象转 CSS)dangerouslySetInnerHTML→ 可能覆盖所有子节点children→ 文本内容(会被 innerHTML 覆盖)- 内部属性 → 跳过不处理
autoFocus→ 延迟处理- 事件属性 → 注册监听器
- 普通属性 → 其他 HTML 属性
如果同时设置 dangerouslySetInnerHTML 和 children,innerHTML 优先,children 被忽略。
appendAllChildren 完整源码解析
在挂载阶段,当我们为一个 DOM 元素创建好 DOM 实例后,接下来就需要把它的子节点都挂载上去。但这里有个有趣的问题:Fiber 树中不仅有真实的 DOM 节点(如 <div>、<span>),还有各种"虚拟"的节点,比如函数组件、类组件、Fragment 等。这些虚拟节点只是 React 内部用来组织代码的抽象概念,浏览器根本不认识它们。
appendAllChildren 的任务就是在这样一棵混杂着真实和虚拟节点的 Fiber 树中,找出所有真正的 DOM 节点,并按照正确的顺序挂载到父元素上。它采用深度优先遍历的方式,遇到真实 DOM 就追加,遇到虚拟节点就继续深入查找。
ts
appendAllChildren = function (
parent: Instance,
workInProgress: Fiber,
needsVisibilityToggle: boolean,
isHidden: boolean
) {
let node = workInProgress.child;
while (node !== null) {
if (node.tag === HostComponent || node.tag === HostText) {
// 找到了真实 DOM 节点或文本节点,追加到父元素
appendInitialChild(parent, node.stateNode);
} else if (node.tag === HostPortal) {
// Portal 比较特殊,它的子节点要渲染到别的地方,这里直接跳过
} else if (node.child !== null) {
// 遇到了组件、Fragment 这些虚拟节点,继续往下找真实 DOM
node.child.return = node;
node = node.child;
continue;
}
if (node === workInProgress) {
return; // 绕了一圈回到起点,说明所有子节点都处理完了
}
// 当前节点处理完了,看看有没有兄弟节点
while (node.sibling === null) {
// 没有兄弟节点,就往上回溯
if (node.return === null || node.return === workInProgress) {
return; // 回到了起点或根节点,遍历结束
}
node = node.return;
}
// 找到了兄弟节点,继续处理
node.sibling.return = node.return;
node = node.sibling;
}
};这个遍历过程看似复杂,实际上遵循一个简单的原则:优先向下找(child),找不到就向右找(sibling),还找不到就向上回溯(return)。整个过程就像是在树林里找宝藏,遇到岔路就钻进去,走到尽头就返回继续找下一条路。
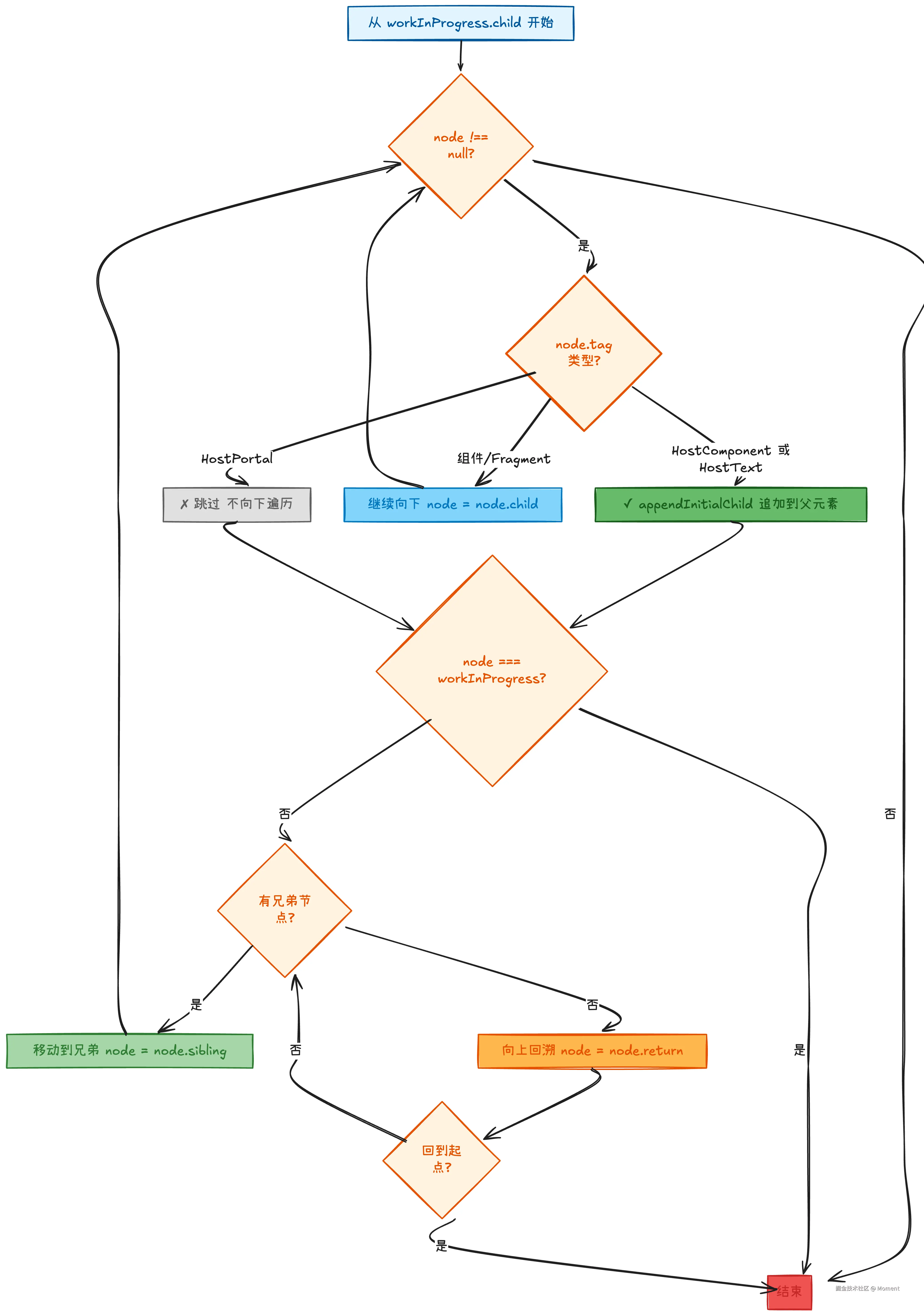
从这个流程图可以看出,整个遍历过程就是一个不断判断和移动的循环:先判断节点类型决定是否追加,然后判断是否还有子节点或兄弟节点,最后决定下一步往哪走。这种设计保证了无论 Fiber 树有多复杂,最终都能按正确的顺序找到并追加所有真实 DOM 节点。
Fiber 树到 DOM 树的转换
你可能会好奇,为什么有些节点会被追加,有些会被跳过?原因在于浏览器只认识真实的 DOM 元素,而 React 的组件、Fragment 这些概念是浏览器不知道的。所以 appendAllChildren 在遍历时,只会把 HostComponent(原生 DOM 元素)和 HostText(文本节点)追加到 DOM 树中,遇到组件和 Fragment 时则会继续深入查找它们的子节点。
jsx
// Fiber 树结构
<div> // HostComponent ✓ 追加到 DOM
<MyComponent> // FunctionComponent ✗ 跳过,但深入查找子节点
<span>Hello</span> // HostComponent ✓ 追加到 DOM
<Fragment> // Fragment ✗ 跳过,但深入查找子节点
<p>World</p> // HostComponent ✓ 追加到 DOM
</Fragment>
</MyComponent>
</div>
// 最终浏览器看到的 DOM 结构
<div>
<span>Hello</span>
<p>World</p>
</div>可以看到,MyComponent 和 Fragment 在最终的 DOM 结构中都不见了,它们只是 React 用来组织代码的工具,最终只有真实的 DOM 元素才会被挂载到页面上。
Portal 的特殊处理
Portal 是 React 中一个很有意思的特性,它允许我们把组件的内容渲染到 DOM 树的其他位置。比如弹窗(Modal)通常需要渲染在 body 的最顶层,而不是嵌套在某个深层的 div 里,这样才能保证弹窗的层级和样式不受父元素影响。
jsx
// 组件的逻辑位置在 #app 中
<div id="app">
<MyComponent>
{createPortal(<Modal />, document.getElementById('modal-root'))}
</MyComponent>
</div>
// 但 Modal 的实际渲染位置在 #modal-root
<div id="modal-root">
<Modal />
</div>对于 Portal 节点,appendAllChildren 会直接跳过,不会继续向下遍历。因为 Portal 的子节点会由 React 的其他机制负责追加到 Portal 指定的目标容器中,而不是当前的父节点。这样就实现了逻辑位置和渲染位置的分离。
实际遍历示例
为了更直观地理解整个遍历过程,我们来看一个实际的例子。假设有这样一个组件结构:
jsx
<div id="parent">
<Header />
<span>文本</span>
</div>;
function Header() {
return (
<>
<h1>标题</h1>
<p>副标题</p>
</>
);
}在 Fiber 树中,Header 组件会被展开成它的返回内容,Fragment 也会被展开。appendAllChildren 需要从这棵复杂的 Fiber 树中找出所有真实的 DOM 节点,并按照正确的顺序追加到 div 元素上。
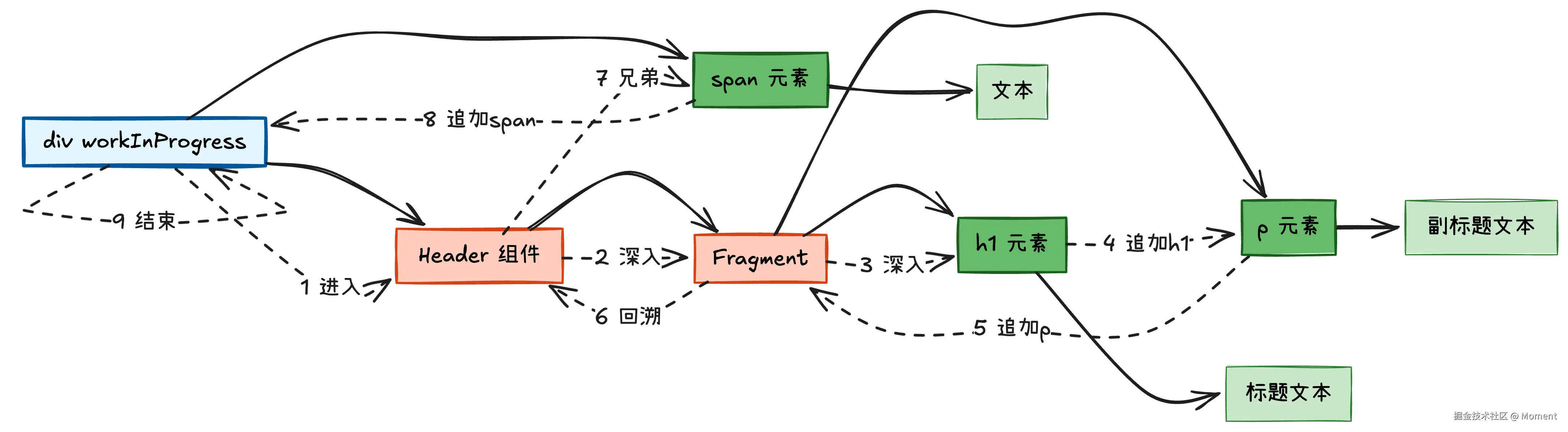
从这个流程图可以清晰地看到整个遍历过程:蓝色的 div 是起点,橙色的 Header 和 Fragment 是需要跳过的虚拟节点,深绿色的 h1、p、span 是会被追加的真实 DOM 元素,浅绿色的是文本节点。虚线箭头展示了遍历的完整路径,从步骤 1 开始深入查找,步骤 4、5、8 是实际的 DOM 追加操作,步骤 6 是回溯过程,步骤 7 是移动到兄弟节点,最后步骤 9 回到起点结束。
下面用时间线来看看每一步的操作:

这条时间线展示了遍历的完整过程:前三步是向下深入的过程,遇到了两个虚拟节点(Header 和 Fragment),最终找到了第一个真实节点 h1。然后是 DOM 追加阶段,依次将 h1 和 p 追加到 div 上。接着是回溯阶段,从 p 一路向上回到 Header。最后继续遍历兄弟节点 span,追加后回到起点,整个过程结束。最终 div 包含了三个子元素:<h1>标题</h1>、<p>副标题</p>、<span>文本</span>。
小结
appendAllChildren 的设计体现了深度优先遍历的核心思想。它首先优先向下查找子节点,如果没有找到合适的节点,就会向右查找兄弟节点,找不到再回溯到父节点,并继续这个过程。在遍历时,它会自动跳过抽象节点(如组件和 Fragment),只将真实的 DOM 节点追加到父元素中。对于像 Portal 这样的特殊节点,它会被跳过,因为它的子节点需要渲染到其他地方。与此同时,React 还巧妙地维护了 Fiber 节点间的 return 指针,确保 Fiber 树的结构始终完整。这使得 appendAllChildren 成为一个既简洁又高效的函数,它解决了如何从混合了虚拟和真实节点的 Fiber 树中,构建出浏览器可以理解的 DOM 树这一复杂问题。
HostText(文本节点)
文本节点是 React 中最简单的节点类型,它直接对应浏览器的文本节点。虽然看起来简单,但在 SSR(服务端渲染)场景下,文本节点的处理涉及到复杂的 hydration 匹配逻辑。React 需要判断当前的文本节点是否能与服务端渲染的 DOM 节点匹配,如果匹配失败还要决定是继续尝试下一个节点,还是直接插入新节点。
ts
case HostText: {
const newText = newProps;
if (current && workInProgress.stateNode != null) {
// 更新阶段:对比新旧文本
const oldText = current.memoizedProps;
updateHostText(current, workInProgress, oldText, newText);
} else {
// 挂载阶段:创建新的文本节点或尝试 hydration
workInProgress.stateNode = createTextInstance(
newText,
rootContainerInstance,
currentHostContext,
workInProgress,
);
}
bubbleProperties(workInProgress);
return null;
}updateHostText 函数的完整实现比想象中复杂,它主要是处理 SSR hydration 的情况:
ts
function updateHostText(current, workInProgress) {
if (current === null) {
// 首次挂载,尝试 hydration
tryToClaimNextHydratableInstance(workInProgress);
}
// 对于文本节点,这里不需要做任何事情
// 真正的文本对比和更新会在 completeWork 之后的阶段处理
return null;
}可以看到,updateHostText 的核心工作是调用 tryToClaimNextHydratableInstance 来尝试 hydration。这个函数包含了复杂的匹配逻辑:
ts
function tryToClaimNextHydratableInstance(fiber: Fiber): void {
if (!isHydrating) {
return; // 不在 hydration 模式,直接返回
}
let nextInstance = nextHydratableInstance;
if (!nextInstance) {
// 情况1:没有可以 hydrate 的 DOM 节点了
if (shouldClientRenderOnMismatch(fiber)) {
warnNonhydratedInstance((hydrationParentFiber: any), fiber);
throwOnHydrationMismatch(fiber);
}
// 将这个 Fiber 标记为需要插入的新节点
insertNonHydratedInstance((hydrationParentFiber: any), fiber);
isHydrating = false;
hydrationParentFiber = fiber;
return;
}
const firstAttemptedInstance = nextInstance;
if (!tryHydrate(fiber, nextInstance)) {
// 情况2:第一次尝试匹配失败
if (shouldClientRenderOnMismatch(fiber)) {
warnNonhydratedInstance((hydrationParentFiber: any), fiber);
throwOnHydrationMismatch(fiber);
}
// 基于启发式策略:尝试下一个兄弟节点
// 这个策略基于直觉而非数据,可能不完美但大多数情况有效
nextInstance = getNextHydratableSibling(firstAttemptedInstance);
const prevHydrationParentFiber: Fiber = (hydrationParentFiber: any);
if (!nextInstance || !tryHydrate(fiber, nextInstance)) {
// 情况3:第二次尝试也失败,放弃 hydration
insertNonHydratedInstance((hydrationParentFiber: any), fiber);
isHydrating = false;
hydrationParentFiber = fiber;
return;
}
// 情况4:第二次尝试成功
// 说明第一个节点是多余的,需要删除
// 我们需要为这个多余的 DOM 节点创建一个 dummy fiber 来调度删除操作
deleteHydratableInstance(prevHydrationParentFiber, firstAttemptedInstance);
}
// 情况5:第一次尝试就成功,完美匹配
}这段代码体现了 React hydration 的容错策略。当遇到不匹配时,React 不会立即放弃,而是会尝试"向前看一个节点",因为可能是服务端多渲染了一个节点,或者客户端少了一个节点。只有在第二次尝试也失败后,React 才会放弃 hydration,转而在客户端插入新节点。
Hydration 匹配的完整流程:
这个流程图展示了 React hydration 的五种可能情况,其中最有意思的是"情况 4":第一次匹配失败,第二次成功。这说明服务端渲染时多了一个节点,React 会智能地删除这个多余节点,然后继续 hydration。
让我们通过一个实际的例子来理解这个过程:
假设服务端渲染的 HTML 是:
html
<div>
<!-- 多余的注释节点 -->
Hello World
</div>而客户端期望的结构是:
jsx
<div>Hello World</div>Hydration 过程:
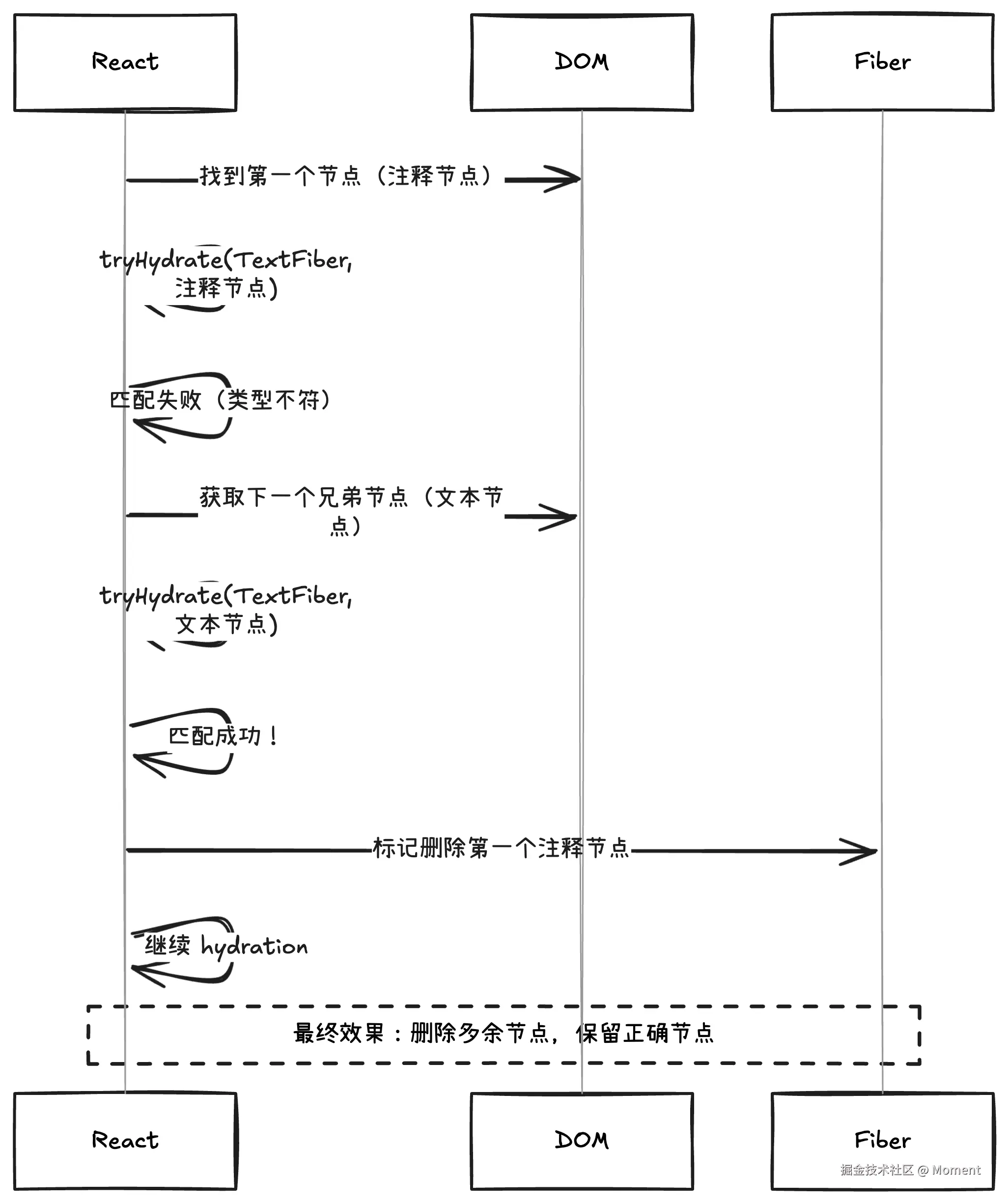
这种容错机制非常实用,因为在实际开发中,服务端和客户端的输出可能因为各种原因(环境变量、注释、空白字符等)产生细微差异。React 的启发式策略能够在大多数情况下自动修复这些差异,而不需要完全放弃 hydration 重新渲染整个子树。
React 的 hydration 策略体现了"先尝试修复,再考虑重建"的原则。遇到不匹配时,会先向前看一个节点,给服务端和客户端一次"对齐"的机会。只有在确认无法对齐后,才会放弃 hydration,插入新节点。这种策略在保证功能正确性的同时,最大程度地复用了服务端渲染的 DOM 结构,提升了性能和用户体验。
HostRoot(根节点)
HostRoot 是整个 React 应用的根节点,它对应的是我们调用 createRoot(container) 创建的根容器。根节点的处理比较特殊,因为它需要处理一些全局性的状态,比如 Context 的切换、SSR 的 hydration 等。
ts
case HostRoot: {
const fiberRoot = workInProgress.stateNode;
// 处理 context 的切换
// 当使用 ReactDOM.createRoot() 的 onRecoverableError 等配置时
// 这些配置信息会存储在 pendingContext 中,在这里应用到真正的 context
if (fiberRoot.pendingContext) {
fiberRoot.context = fiberRoot.pendingContext;
fiberRoot.pendingContext = null;
}
// 处理首次渲染或 hydration
if (current === null || current.child === null) {
// 检查是否是 SSR hydration
const wasHydrated = popHydrationState(workInProgress);
if (wasHydrated) {
// hydration 成功,标记更新
// 这会在 commit 阶段触发一些 hydration 相关的处理
markUpdate(workInProgress);
}
}
// 更新根容器
// 这个函数会处理根容器的 cache、context 等全局状态
updateHostContainer(current, workInProgress);
bubbleProperties(workInProgress);
return null;
}根节点的处理流程:
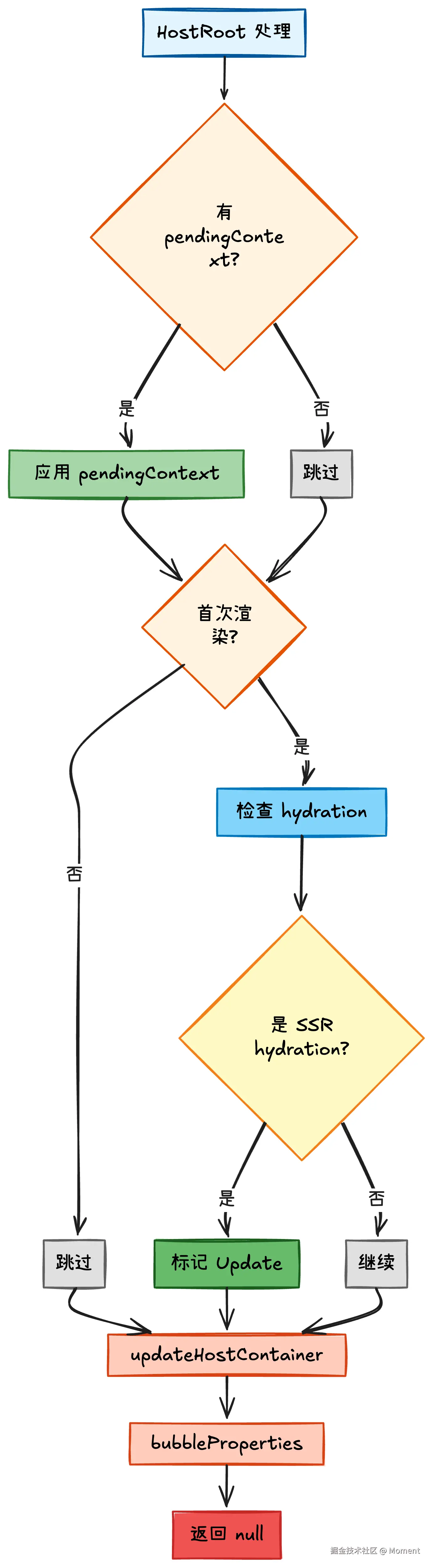
根节点的处理看似简单,实际上是整个 React 应用状态管理的关键节点,它承担着应用级别的配置和状态协调工作。
Suspense 和 SuspenseList
Suspense 是 React 中处理异步加载的核心组件,它的 completeWork 处理逻辑非常复杂,涉及到 SSR hydration、缓存管理、可见性控制、重试机制等多个方面。当子组件抛出 Promise 时,Suspense 会显示 fallback 内容,等 Promise resolve 后再显示真实内容。
完整的 SuspenseComponent 处理逻辑:
ts
case SuspenseComponent: {
popSuspenseContext(workInProgress);
const nextState: null | SuspenseState = workInProgress.memoizedState;
// 第一部分:Dehydrated Boundary 的特殊处理
// 这是 SSR hydration 的核心逻辑
// 未来可能会将其重构为独立的 fiber 类型
if (
current === null ||
(current.memoizedState !== null &&
current.memoizedState.dehydrated !== null)
) {
const fallthroughToNormalSuspensePath = completeDehydratedSuspenseBoundary(
current,
workInProgress,
nextState,
);
if (!fallthroughToNormalSuspensePath) {
if (workInProgress.flags & ShouldCapture) {
// 特殊情况:还有未完成的 hydration 节点
// 将其视为不匹配,回退到客户端渲染
return workInProgress;
} else {
// hydration 未完成,要么是首次渲染,要么是有东西挂起了
return null;
}
}
// 继续执行正常的 Suspense 路径
}
// 第二部分:捕获异步操作的处理
if ((workInProgress.flags & DidCapture) !== NoFlags) {
// 有东西挂起了,使用 fallback 子节点重新渲染
workInProgress.lanes = renderLanes;
// 不重置 effect 列表
if (
enableProfilerTimer &&
(workInProgress.mode & ProfileMode) !== NoMode
) {
transferActualDuration(workInProgress);
}
// 不冒泡属性
return workInProgress;
}
// 第三部分:状态变化检测
const nextDidTimeout = nextState !== null;
const prevDidTimeout =
current !== null &&
(current.memoizedState: null | SuspenseState) !== null;
// 第四部分:Cache 管理
if (enableCache && nextDidTimeout) {
const offscreenFiber: Fiber = (workInProgress.child: any);
let previousCache: Cache | null = null;
if (
offscreenFiber.alternate !== null &&
offscreenFiber.alternate.memoizedState !== null &&
offscreenFiber.alternate.memoizedState.cachePool !== null
) {
previousCache = offscreenFiber.alternate.memoizedState.cachePool.pool;
}
let cache: Cache | null = null;
if (
offscreenFiber.memoizedState !== null &&
offscreenFiber.memoizedState.cachePool !== null
) {
cache = offscreenFiber.memoizedState.cachePool.pool;
}
if (cache !== previousCache) {
// 运行 passive effects 来保留/释放缓存
offscreenFiber.flags |= Passive;
}
}
// 第五部分:可见性状态变化处理
if (nextDidTimeout !== prevDidTimeout) {
if (enableTransitionTracing) {
const offscreenFiber: Fiber = (workInProgress.child: any);
offscreenFiber.flags |= Passive;
}
// 当边界的挂起状态发生变化时,需要调度一个 effect 来切换子树的可见性
// 从 fallback -> primary:内部的 Offscreen fiber 会在其正常的 complete 阶段调度这个 effect
// 从 primary -> fallback:内部的 Offscreen fiber 没有 complete 阶段
// 所以我们需要在这里调度它的 effect
if (nextDidTimeout) {
const offscreenFiber: Fiber = (workInProgress.child: any);
offscreenFiber.flags |= Visibility;
if ((workInProgress.mode & ConcurrentMode) !== NoMode) {
const hasInvisibleChildContext =
current === null &&
(workInProgress.memoizedProps.unstable_avoidThisFallback !==
true ||
!enableSuspenseAvoidThisFallback);
if (
hasInvisibleChildContext ||
hasSuspenseContext(
suspenseStackCursor.current,
(InvisibleParentSuspenseContext: SuspenseContext),
)
) {
// 如果这是在一个不可见的树中或者是新的渲染,显示这个边界是可以的
renderDidSuspend();
} else {
// 否则,我们将要隐藏内容,所以应该尽可能延长挂起时间
renderDidSuspendDelayIfPossible();
}
}
}
}
// 第六部分:重试监听器
const wakeables: Set<Wakeable> | null = (workInProgress.updateQueue: any);
if (wakeables !== null) {
// 调度一个 effect 来附加重试监听器到 promise
workInProgress.flags |= Update;
}
// 第七部分:Suspense 回调
if (
enableSuspenseCallback &&
workInProgress.updateQueue !== null &&
workInProgress.memoizedProps.suspenseCallback != null
) {
// 总是通知回调
workInProgress.flags |= Update;
}
// 第八部分:冒泡属性和性能统计
bubbleProperties(workInProgress);
if (enableProfilerTimer) {
if ((workInProgress.mode & ProfileMode) !== NoMode) {
if (nextDidTimeout) {
// 不将超时的 Suspense 子树中的时间计入基础持续时间
const primaryChildFragment = workInProgress.child;
if (primaryChildFragment !== null) {
workInProgress.treeBaseDuration -= ((primaryChildFragment.treeBaseDuration: any): number);
}
}
}
}
return null;
}Suspense 的处理流程可以分为八个关键部分,让我们逐一理解:
1. Dehydrated Boundary 处理
这是 SSR hydration 的核心逻辑。当服务端渲染的 Suspense 边界在客户端 hydration 时,React 需要特殊处理。completeDehydratedSuspenseBoundary 会尝试完成 hydration,如果失败(比如遇到不匹配),会返回 false,此时要么回退到客户端渲染,要么继续等待。
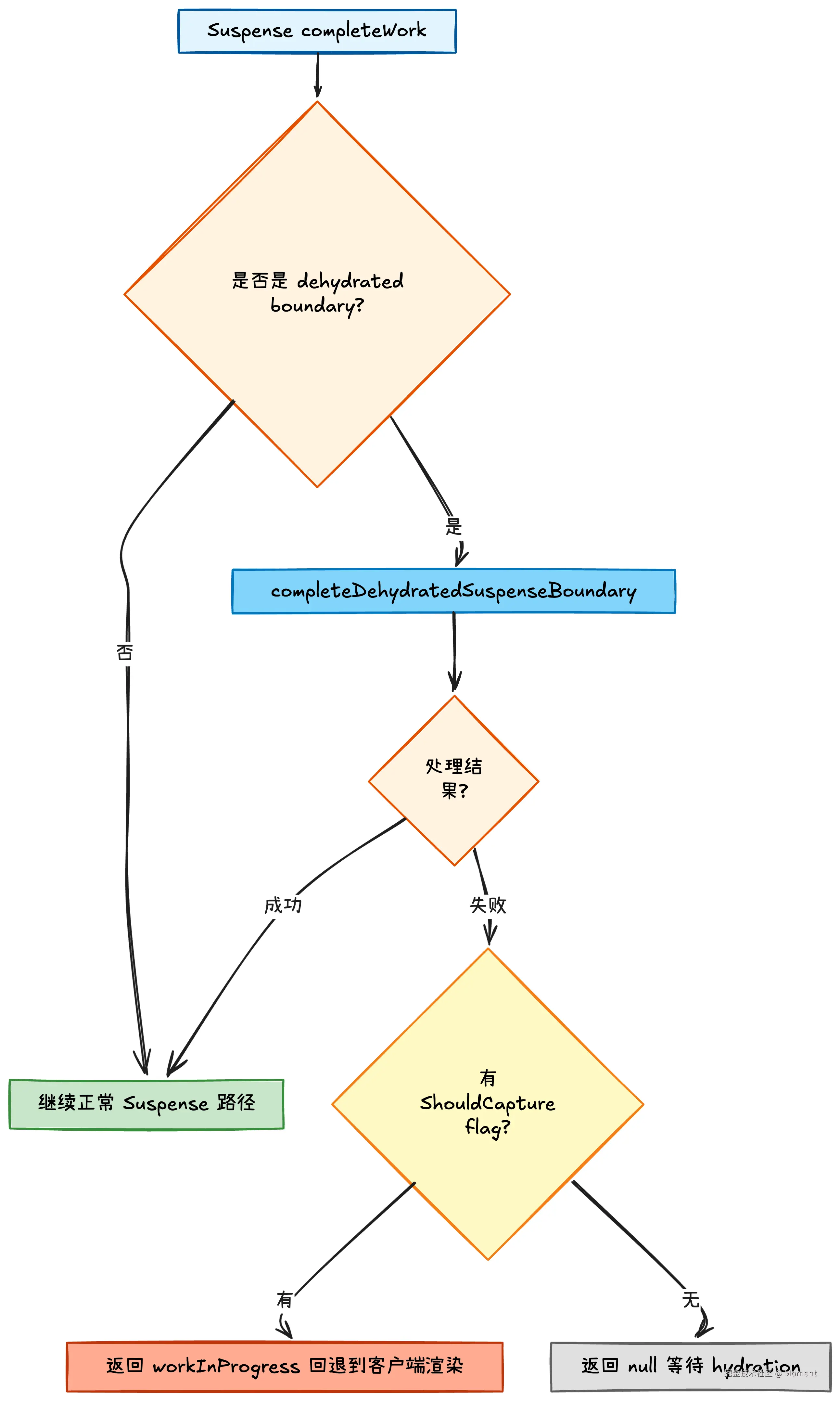
2. 异步捕获处理
当检测到 DidCapture flag 时,说明子组件抛出了 Promise。此时 React 会返回 workInProgress fiber 本身,触发重新渲染,但这次会渲染 fallback 内容而不是子组件。注意这里不会冒泡属性,避免影响父组件。
3. 状态变化检测
通过对比 nextDidTimeout(下一个状态是否超时)和 prevDidTimeout(上一个状态是否超时),判断 Suspense 的状态是否发生了变化。这个信息会用于后续的缓存管理和可见性控制。
4. Cache 管理
React 18 引入了缓存功能,Suspense 需要管理缓存的生命周期。当 Suspense 从 primary 切换到 fallback 时,需要保留缓存以便之后恢复;当从 fallback 切换回 primary 时,可能需要释放旧缓存。通过对比新旧缓存对象,决定是否标记 Passive flag 来触发缓存的保留或释放。
5. 可见性控制
这是最复杂的部分。当 Suspense 状态变化时,需要控制子树的可见性:
- 从 primary → fallback:隐藏真实内容,显示 loading 状态
- 从 fallback → primary:隐藏 loading,显示真实内容
重要的是,React 使用 Visibility flag 而不是直接删除或者创建 DOM,这样可以保留子组件的状态。
同时,React 会根据当前上下文决定挂起策略:
- 如果是在不可见的树中(比如被
<Offscreen>包裹),或者是新的渲染,调用renderDidSuspend() - 否则,调用
renderDidSuspendDelayIfPossible(),尽可能延长挂起时间,避免显示短暂的 loading 状态
6. 重试监听器
wakeables 是一个 Promise 集合(Set<Wakeable>),当这些 Promise resolve 时,需要重新渲染 Suspense。React 会标记 Update flag,在 commit 阶段附加监听器到这些 Promise 上。
7. Suspense 回调
开发者可以通过 suspenseCallback prop 获取 Suspense 状态变化的通知。当检测到有回调函数时,标记 Update flag 以便在 commit 阶段调用它。
8. 性能统计
在 Profiler 模式下,React 需要准确统计组件的渲染时间。对于超时的 Suspense,其 fallback 内容的渲染时间不应该计入真实内容的 treeBaseDuration,所以需要减去 primary 子片段的时间。
Suspense 的完整生命周期:
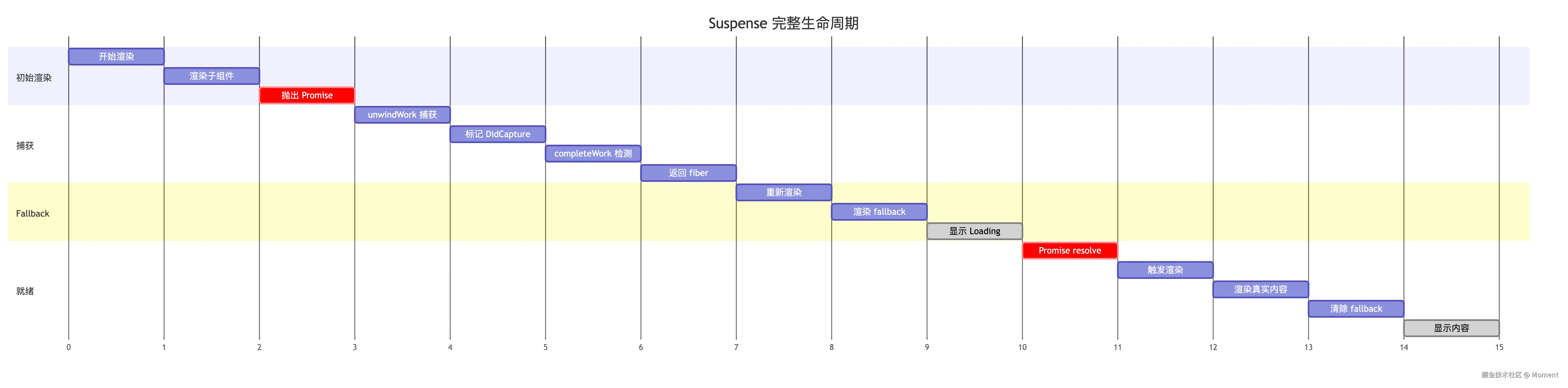
Suspense 状态机:

Suspense 通过细粒度的状态管理、智能的挂起策略、以及缓存和可见性控制,Suspense 能够在异步加载时提供流畅的用户体验。特别是 renderDidSuspendDelayIfPossible 这样的策略,会尽量避免显示短暂的 loading 状态(比如内容在 100ms 内就加载完成),减少页面"闪烁",让应用看起来更加流畅。
Offscreen 组件
Offscreen 组件是 React 18 引入的强大特性,它实现了"看不见但还活着"的理念:组件被隐藏但保留状态。与传统的条件渲染或 display: none 不同,Offscreen 不会卸载组件,而是将其移出可见区域,在需要时能立即恢复。这在选项卡切换、路由预加载、虚拟列表等场景中非常有用。
完整的 Offscreen 处理逻辑:
ts
case OffscreenComponent:
case LegacyHiddenComponent: {
popRenderLanes(workInProgress);
const nextState: OffscreenState | null = workInProgress.memoizedState;
const nextIsHidden = nextState !== null;
// 第一部分:可见性变化检测
if (current !== null) {
const prevState: OffscreenState | null = current.memoizedState;
const prevIsHidden = prevState !== null;
if (
prevIsHidden !== nextIsHidden &&
// LegacyHidden 不做任何隐藏,它只是预渲染
(!enableLegacyHidden || workInProgress.tag !== LegacyHiddenComponent)
) {
workInProgress.flags |= Visibility;
}
}
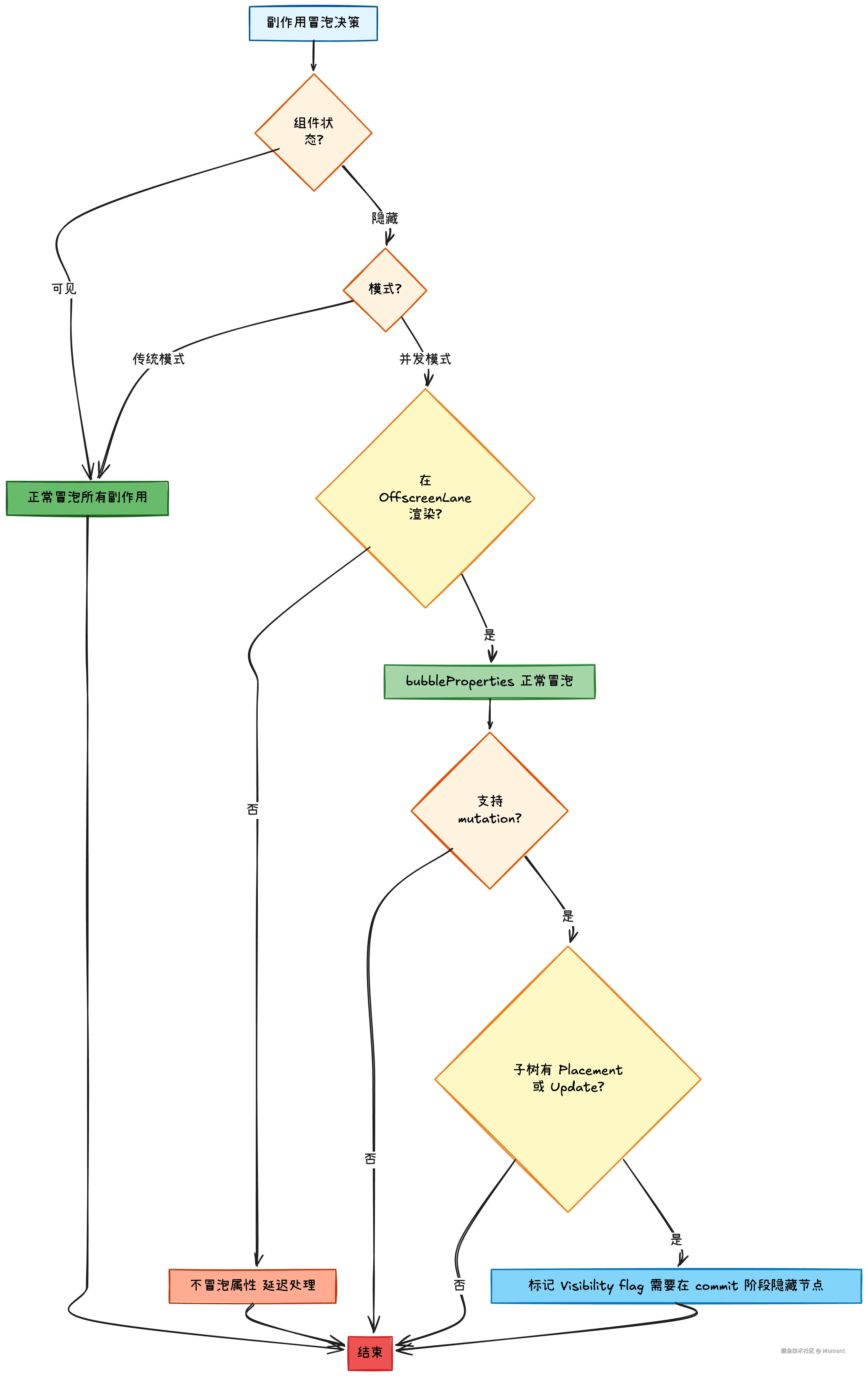
// 第二部分:副作用冒泡策略
if (!nextIsHidden || (workInProgress.mode & ConcurrentMode) === NoMode) {
// 情况1:可见状态,或者传统模式
// 正常冒泡所有副作用
bubbleProperties(workInProgress);
} else {
// 情况2:隐藏状态 + 并发模式
// 除非我们在 offscreen 优先级下渲染,否则不冒泡属性
if (includesSomeLane(subtreeRenderLanes, (OffscreenLane: Lane))) {
bubbleProperties(workInProgress);
if (supportsMutation) {
// 检查隐藏的子树中是否有插入或更新
// 如果有,需要在 commit 阶段隐藏这些节点
// 所以调度一个 visibility effect
if (
(!enableLegacyHidden ||
workInProgress.tag !== LegacyHiddenComponent) &&
workInProgress.subtreeFlags & (Placement | Update)
) {
workInProgress.flags |= Visibility;
}
}
}
}
// 第三部分:Cache 管理
if (enableCache) {
let previousCache: Cache | null = null;
if (
current !== null &&
current.memoizedState !== null &&
current.memoizedState.cachePool !== null
) {
previousCache = current.memoizedState.cachePool.pool;
}
let cache: Cache | null = null;
if (
workInProgress.memoizedState !== null &&
workInProgress.memoizedState.cachePool !== null
) {
cache = workInProgress.memoizedState.cachePool.pool;
}
if (cache !== previousCache) {
// 运行 passive effects 来保留/释放缓存
workInProgress.flags |= Passive;
}
}
// 第四部分:Transition 清理
popTransition(workInProgress, current);
return null;
}Offscreen 的处理可以分为四个关键部分:
1. 可见性变化检测
React 会对比当前状态和之前状态,判断可见性是否发生了变化。注意这里有个特殊处理:LegacyHiddenComponent 不参与可见性控制,因为它只是用于预渲染,并不真正隐藏内容。
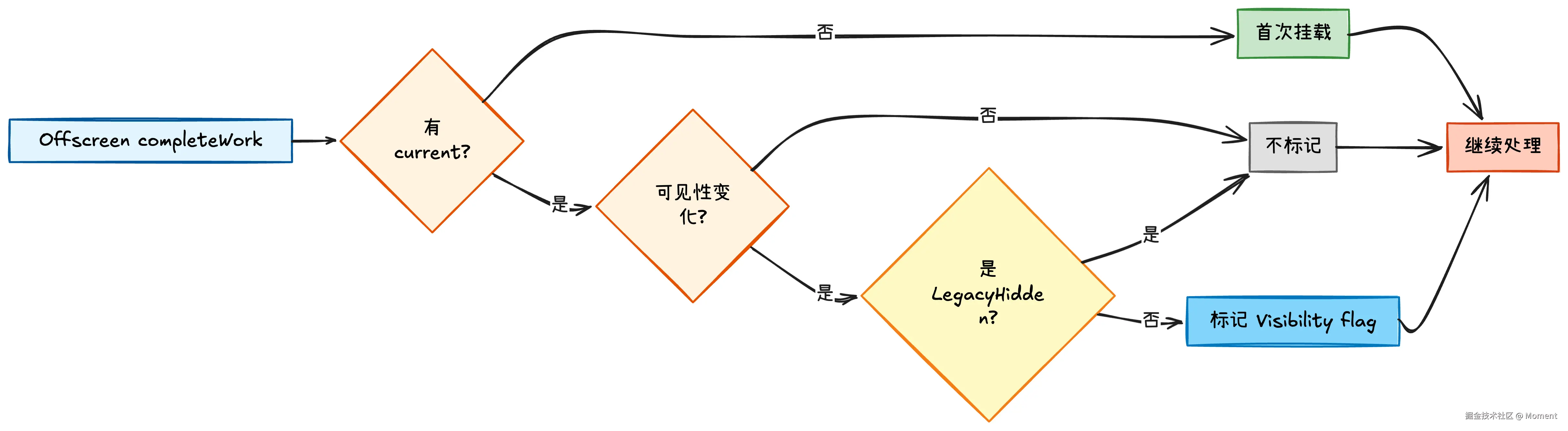
2. 副作用冒泡策略
这是 Offscreen 最复杂的部分,React 会根据不同的条件选择不同的冒泡策略:
这个策略的关键在于 OffscreenLane 的判断。当隐藏的 Offscreen 组件在后台更新时,React 会使用 OffscreenLane 这个特殊的优先级。只有在这个优先级下,才会冒泡副作用。这样设计的原因是:
- 隐藏的内容通常优先级较低,不需要立即处理
- 但如果正在主动更新隐藏的内容(比如预加载),就需要正常处理副作用
- 如果隐藏的子树中有新增或更新的节点,需要标记
Visibilityflag,在 commit 阶段将这些节点设置为隐藏状态
3. Cache 管理
与 Suspense 类似,Offscreen 也需要管理缓存。当组件从可见切换到隐藏时,需要保留缓存以便将来恢复;当从隐藏切换到可见时,可能需要更新缓存。通过对比新旧缓存对象,决定是否标记 Passive flag。
4. Transition 清理
popTransition 用于清理 Transition 相关的状态。Offscreen 组件可能参与 Transition 动画,需要在完成时清理相关状态。
Offscreen 的三种工作模式:
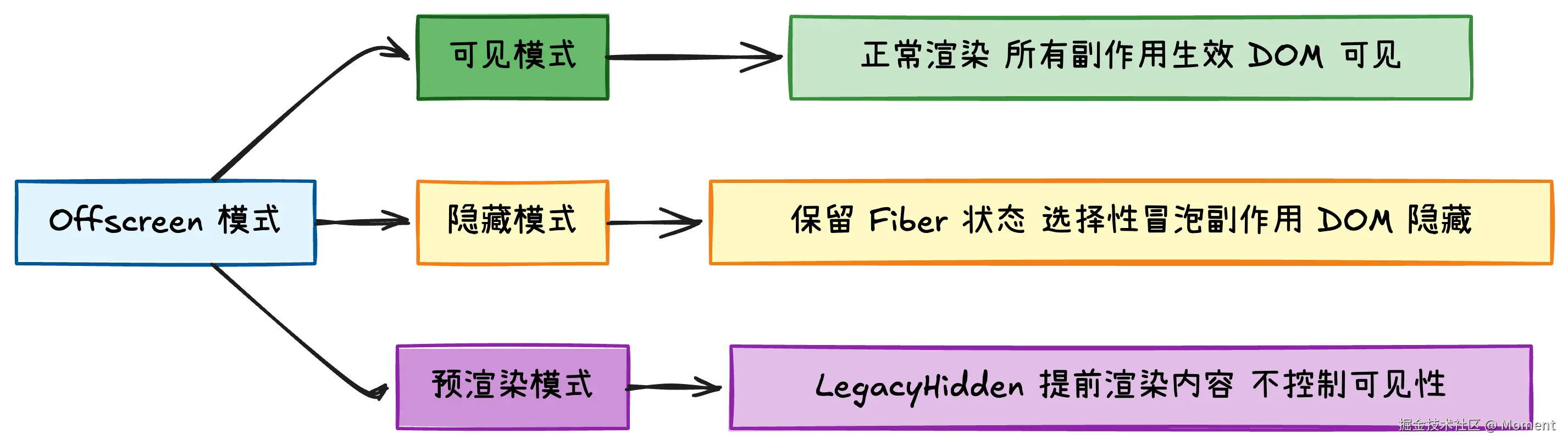
从 Offscreen 到 Activity:React 19 的新组件
Offscreen 是 React 内部的 Fiber 节点类型,在 React 19 中,它以 <Activity> 组件的形式正式对外开放了。你可以在官方文档中找到完整的使用说明。
<Activity> 最简单的用法就是控制组件的显示和隐藏:
jsx
import { Activity } from "react";
function App() {
const [isShowingSidebar, setIsShowingSidebar] = useState(true);
return (
<Activity mode={isShowingSidebar ? "visible" : "hidden"}>
<Sidebar />
</Activity>
);
}这个组件解决的核心问题是:传统的条件渲染 {condition && <Component />} 会在隐藏时完全销毁组件状态,而 <Activity> 只是把组件"藏起来",状态还在。
举个实际的例子。假设我们有个侧边栏,里面有个可展开的菜单:
jsx
function Sidebar() {
const [isExpanded, setIsExpanded] = useState(false);
return (
<nav>
<button onClick={() => setIsExpanded(!isExpanded)}>Overview</button>
{isExpanded && (
<ul>
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>
)}
</nav>
);
}如果用传统方式隐藏侧边栏({show && <Sidebar />}),用户展开菜单后,关闭再打开侧边栏,菜单会重新收起。但用 <Activity> 包裹,菜单的展开状态会被保留,用户体验好很多。
除了保留状态,<Activity> 还会保留 DOM。比如用户在表单里输入了一半内容,即使标签页切换了,回来时输入的内容还在(这对 <textarea> 和 <input> 这种不受控组件特别有用)。
更有意思的是预渲染场景。我们可以把可能要显示的内容提前渲染好,但先藏着:
jsx
function App() {
const [activeTab, setActiveTab] = useState("home");
return (
<>
<TabButton onClick={() => setActiveTab("home")}>Home</TabButton>
<TabButton onClick={() => setActiveTab("video")}>Video</TabButton>
<Activity mode={activeTab === "home" ? "visible" : "hidden"}>
<Home />
</Activity>
<Activity mode={activeTab === "video" ? "visible" : "hidden"}>
<Video />
</Activity>
</>
);
}这样两个标签页的内容都已经渲染好了,切换时没有任何延迟,体验特别流畅。
<Activity> 在 SSR 场景下也很有用。React 可以先让页面的关键部分变得可交互,把次要的部分(比如评论区)放在 <Activity> 里延迟 hydrate:
jsx
function Page() {
return (
<>
<Post /> {/* 先 hydrate 这个 */}
<Activity>
<Comments /> {/* 后 hydrate 这个 */}
</Activity>
</>
);
}这样用户能更快地开始交互,页面加载感觉更快了。
不过有几个坑要注意。<Activity> 隐藏组件时会用 display: none,同时清理所有的 Effects。大部分组件都没问题,但像 <video> 这种标签有点特殊:
jsx
function VideoTab() {
return <video src="..." controls />;
}
// 如果用 Activity 隐藏,视频的音频还在播放!
<Activity mode="hidden">
<VideoTab />
</Activity>;因为 <video> 标签还在 DOM 里(只是 display: none),音频会继续播放。解决办法是加个 Effect:
jsx
function VideoTab() {
const ref = useRef();
useLayoutEffect(() => {
const video = ref.current;
return () => video.pause(); // 清理函数在隐藏时暂停视频
}, []);
return <video ref={ref} src="..." controls />;
}类似的标签还有 <audio> 和 <iframe>,如果有副作用都需要在 Effect 的清理函数里处理。
从 Offscreen 到 Activity,React 把这个强大的功能开放出来了。底层的实现逻辑(副作用冒泡、OffscreenLane、Visibility flag)都没变,只是现在开发者可以直接用了。这让我们能做出更流畅的交互,特别是在选项卡、抽屉、模态框这些频繁显示隐藏的场景。
unwindWork:错误和中断的处理
当渲染过程中出问题了(比如组件抛错误、Suspense 遇到 Promise),React 需要"倒带"回去找到能处理这个问题的地方。这就是 unwindWork 做的事情。
完整的 unwindWork 源码:
ts
function unwindWork(
current: Fiber | null,
workInProgress: Fiber,
renderLanes: Lanes
) {
// 先清理 Tree Context(用于追踪组件树的位置)
popTreeContext(workInProgress);
switch (workInProgress.tag) {
case ClassComponent: {
const Component = workInProgress.type;
// 如果是 Legacy Context Provider,清理 context 栈
if (isLegacyContextProvider(Component)) {
popLegacyContext(workInProgress);
}
const flags = workInProgress.flags;
if (flags & ShouldCapture) {
// 这是个 Error Boundary,可以捕获错误
workInProgress.flags = (flags & ~ShouldCapture) | DidCapture;
// Profiler 模式下记录渲染时间
if (
enableProfilerTimer &&
(workInProgress.mode & ProfileMode) !== NoMode
) {
transferActualDuration(workInProgress);
}
return workInProgress; // 返回这个 fiber,触发重新渲染
}
return null; // 不能处理,继续向上找
}
case HostRoot: {
const root: FiberRoot = workInProgress.stateNode;
// 清理 Cache
if (enableCache) {
const cache: Cache = workInProgress.memoizedState.cache;
popCacheProvider(workInProgress, cache);
}
// 清理 Transition
popRootTransition(workInProgress, root, renderLanes);
popHostContainer(workInProgress);
popTopLevelLegacyContextObject(workInProgress);
resetMutableSourceWorkInProgressVersions();
const flags = workInProgress.flags;
if (
(flags & ShouldCapture) !== NoFlags &&
(flags & DidCapture) === NoFlags
) {
// Root 出错了,需要卸载所有子节点重新来
workInProgress.flags = (flags & ~ShouldCapture) | DidCapture;
return workInProgress;
}
return null;
}
case HostComponent: {
popHostContext(workInProgress);
return null;
}
case SuspenseComponent: {
popSuspenseContext(workInProgress);
const suspenseState: null | SuspenseState = workInProgress.memoizedState;
// SSR hydration 的特殊情况
if (suspenseState !== null && suspenseState.dehydrated !== null) {
if (workInProgress.alternate === null) {
// 新挂载的 dehydrated 组件抛错,这是个 bug
throw new Error(
"Threw in newly mounted dehydrated component. This is likely a bug in " +
"React. Please file an issue."
);
}
resetHydrationState();
}
const flags = workInProgress.flags;
if (flags & ShouldCapture) {
// 捕获到 Promise 或错误,准备显示 fallback
workInProgress.flags = (flags & ~ShouldCapture) | DidCapture;
if (
enableProfilerTimer &&
(workInProgress.mode & ProfileMode) !== NoMode
) {
transferActualDuration(workInProgress);
}
return workInProgress;
}
return null;
}
case SuspenseListComponent: {
popSuspenseContext(workInProgress);
// SuspenseList 自己不捕获任何东西,应该由嵌套的 Suspense 处理
return null;
}
case HostPortal:
popHostContainer(workInProgress);
return null;
case ContextProvider:
const context: ReactContext<any> = workInProgress.type._context;
popProvider(context, workInProgress);
return null;
case OffscreenComponent:
case LegacyHiddenComponent:
popRenderLanes(workInProgress);
popTransition(workInProgress, current);
return null;
case CacheComponent:
if (enableCache) {
const cache: Cache = workInProgress.memoizedState.cache;
popCacheProvider(workInProgress, cache);
}
return null;
default:
return null;
}
}unwindWork 的核心逻辑很简单:检查当前 fiber 有没有 ShouldCapture flag。有的话,说明这个节点能处理错误(比如 Error Boundary)或能显示 fallback(比如 Suspense),就把 flag 改成 DidCapture,返回这个 fiber。没有的话,返回 null,让 React 继续往上找。
除了处理错误,unwindWork 还要做很多清理工作,比如:
- 清理各种 context(Legacy Context、New Context、Host Context)
- 清理 Cache 和 Transition 状态
- 重置 hydration 状态
- 清理 Suspense context
举几个实际的例子:
场景 1:组件抛出错误
jsx
class ErrorBoundary extends React.Component {
state = { hasError: false };
static getDerivedStateFromError(error) {
return { hasError: true };
}
componentDidCatch(error, info) {
console.log("捕获到错误:", error);
}
render() {
if (this.state.hasError) {
return <h1>出错了</h1>;
}
return this.props.children;
}
}
function BuggyComponent() {
throw new Error("我崩了!");
}
<ErrorBoundary>
<BuggyComponent />
</ErrorBoundary>;当 BuggyComponent 抛错时:
- beginWork 或 completeWork 捕获到错误
- 给 BuggyComponent 的 fiber 标记
Incompleteflag - 开始调用 unwindWork,一层层往上找
- 找到 ErrorBoundary,它有
ShouldCaptureflag - unwindWork 把 flag 改成
DidCapture,返回 ErrorBoundary 的 fiber - React 重新渲染 ErrorBoundary,这次会走到
if (this.state.hasError)分支 componentDidCatch被调用
场景 2:Suspense 遇到 Promise
jsx
function ProfilePage() {
const user = fetchUser(); // 如果还在加载,会抛出 Promise
return <div>{user.name}</div>;
}
<Suspense fallback={<Spinner />}>
<ProfilePage />
</Suspense>;当 fetchUser() 抛出 Promise 时:
- ProfilePage 渲染时抛出 Promise
- React 捕获这个 Promise,给 ProfilePage 标记
Incomplete - unwindWork 开始往上找
- 找到 Suspense,它有
ShouldCaptureflag - unwindWork 把 flag 改成
DidCapture,返回 Suspense 的 fiber - React 重新渲染 Suspense,这次显示 fallback(Spinner)
- 等 Promise resolve 后,再次触发渲染,这次能正常显示 user.name
场景 3:SSR hydration 出错
jsx
// 服务端渲染的 HTML
<div id="root">
<Suspense fallback={<div>Loading...</div>}>
<AsyncContent />
</Suspense>
</div>
// 客户端 hydration 时,如果 AsyncContent 的内容不匹配
// unwindWork 会检查 suspenseState.dehydrated
// 如果是新挂载的组件出错,会抛出异常(这是个 bug)
// 否则重置 hydration 状态,继续处理还有一个相关的函数是 unwindInterruptedWork,它处理的是渲染被中断的情况(不是错误,只是被打断了):
ts
function unwindInterruptedWork(
current: Fiber | null,
interruptedWork: Fiber,
renderLanes: Lanes
) {
popTreeContext(interruptedWork);
switch (interruptedWork.tag) {
case ClassComponent: {
const childContextTypes = interruptedWork.type.childContextTypes;
if (childContextTypes !== null && childContextTypes !== undefined) {
popLegacyContext(interruptedWork);
}
break;
}
case HostRoot: {
const root: FiberRoot = interruptedWork.stateNode;
if (enableCache) {
const cache: Cache = interruptedWork.memoizedState.cache;
popCacheProvider(interruptedWork, cache);
}
popRootTransition(interruptedWork, root, renderLanes);
popHostContainer(interruptedWork);
popTopLevelLegacyContextObject(interruptedWork);
resetMutableSourceWorkInProgressVersions();
break;
}
// ... 其他 case 的清理工作
}
}unwindInterruptedWork 和 unwindWork 的区别是:
unwindWork处理错误,需要判断能不能捕获(检查 ShouldCapture)unwindInterruptedWork只是清理状态,不判断捕获,也不返回 fiber
比如用户在一个低优先级更新进行到一半时,突然有个高优先级更新进来了,React 会中断当前的渲染,用 unwindInterruptedWork 清理已经处理过的节点的状态,然后开始新的渲染。
这两个函数就像是 React 的"后悔药",让它能从各种意外情况中恢复过来,继续运行。
bubbleProperties:副作用怎么往上传
bubbleProperties 是回溯阶段的核心函数,它做的事情很简单,就是把子节点的副作用标记(flags)和更新优先级(lanes)收集起来,往上传给父节点。这样在 commit 阶段,React 只需要看根节点的 subtreeFlags,就知道整棵树有没有副作用要处理。
完整的源码:
ts
function bubbleProperties(completedWork: Fiber) {
// 先判断是不是 bailout(跳过了)
// 如果 alternate 的 child 和当前的 child 是同一个,说明子节点没变,直接复用了
const didBailout =
completedWork.alternate !== null &&
completedWork.alternate.child === completedWork.child;
let newChildLanes = NoLanes;
let subtreeFlags = NoFlags;
if (!didBailout) {
// 没有 bailout,正常收集副作用
if (enableProfilerTimer && (completedWork.mode & ProfileMode) !== NoMode) {
// Profiler 模式:需要统计渲染时间
let actualDuration = completedWork.actualDuration;
let treeBaseDuration = ((completedWork.selfBaseDuration: any): number);
let child = completedWork.child;
while (child !== null) {
newChildLanes = mergeLanes(
newChildLanes,
mergeLanes(child.lanes, child.childLanes),
);
subtreeFlags |= child.subtreeFlags;
subtreeFlags |= child.flags;
// 累加子节点的实际渲染时间
// 注意:只有实际工作的 fiber 才会有 actualDuration
// 如果 fiber 被 clone 了,actualDuration 会重置为 0
actualDuration += child.actualDuration;
// 累加子节点的基础渲染时间
treeBaseDuration += child.treeBaseDuration;
child = child.sibling;
}
completedWork.actualDuration = actualDuration;
completedWork.treeBaseDuration = treeBaseDuration;
} else {
// 普通模式:只收集 flags 和 lanes
let child = completedWork.child;
while (child !== null) {
newChildLanes = mergeLanes(
newChildLanes,
mergeLanes(child.lanes, child.childLanes),
);
subtreeFlags |= child.subtreeFlags;
subtreeFlags |= child.flags;
// 更新 return 指针,保证树的一致性
// 注释说这是个 code smell,因为它假设 commit 阶段不会和 render 阶段并发
// 将来重构成 alternate 模型时会解决这个问题
child.return = completedWork;
child = child.sibling;
}
}
completedWork.subtreeFlags |= subtreeFlags;
} else {
// bailout 了,但还是要收集 lanes 和静态副作用
if (enableProfilerTimer && (completedWork.mode & ProfileMode) !== NoMode) {
// Profiler 模式:只收集 treeBaseDuration
let treeBaseDuration = ((completedWork.selfBaseDuration: any): number);
let child = completedWork.child;
while (child !== null) {
newChildLanes = mergeLanes(
newChildLanes,
mergeLanes(child.lanes, child.childLanes),
);
// 关键:只收集 StaticMask 标记的副作用
// StaticMask 的副作用和 fiber/hook 的生命周期一样长
// 其他副作用只在一次 render + commit 中有效,bailout 时要忽略
subtreeFlags |= child.subtreeFlags & StaticMask;
subtreeFlags |= child.flags & StaticMask;
treeBaseDuration += child.treeBaseDuration;
child = child.sibling;
}
completedWork.treeBaseDuration = treeBaseDuration;
} else {
// 普通模式:只收集静态副作用
let child = completedWork.child;
while (child !== null) {
newChildLanes = mergeLanes(
newChildLanes,
mergeLanes(child.lanes, child.childLanes),
);
// 只收集静态副作用
subtreeFlags |= child.subtreeFlags & StaticMask;
subtreeFlags |= child.flags & StaticMask;
child.return = completedWork;
child = child.sibling;
}
}
completedWork.subtreeFlags |= subtreeFlags;
}
completedWork.childLanes = newChildLanes;
return didBailout;
}这个函数主要做四件事:
- 判断有没有 bailout(跳过渲染)
- 收集所有子节点的 lanes(更新优先级)
- 收集所有子节点的 flags(副作用标记)
- 如果是 Profiler 模式,还要统计渲染时间
先说说 bailout 是什么。当一个组件满足这些条件时,React 会跳过它的渲染:
- props 没变
- state 没变
- context 没变
- 没有强制更新
bailout 的组件会直接复用上次的子节点,所以 completedWork.child === completedWork.alternate.child。
bailout 和非 bailout 的区别主要在收集副作用时:
jsx
// 非 bailout:收集所有副作用
subtreeFlags |= child.subtreeFlags;
subtreeFlags |= child.flags;
// bailout:只收集静态副作用
subtreeFlags |= child.subtreeFlags & StaticMask;
subtreeFlags |= child.flags & StaticMask;为什么 bailout 只收集静态副作用?因为大部分副作用只在一次渲染中有效,下次渲染时就失效了。但有些副作用(比如 Ref、Passive)是"静态"的,它们和 fiber 或 hook 的生命周期一样长,即使 bailout 了也要保留。
StaticMask 定义了哪些是静态副作用:
ts
// ReactFiberFlags.js
export const StaticMask = LayoutMask | PassiveMask | RefMask | MaySuspendCommit;再说说 Profiler 模式的时间统计。Profiler 会记录两个时间:
actualDuration:实际渲染耗时(只统计真正工作的组件)treeBaseDuration:基准渲染耗时(统计整棵子树)
jsx
<Profiler
id="App"
onRender={(id, phase, actualDuration) => {
console.log(`${id} 的 ${phase} 阶段耗时 ${actualDuration}ms`);
}}
>
<App />
</Profiler>非 bailout 时,actualDuration 会累加子节点的时间:
ts
actualDuration += child.actualDuration;但 bailout 时不累加,因为没有实际工作。注释里说得很清楚:
When a fiber is cloned, its actualDuration is reset to 0. This value will only be updated if work is done on the fiber (i.e. it doesn't bailout).
也就是说,如果 fiber 被 clone 了,actualDuration 会重置为 0。只有真正渲染的 fiber 才有 actualDuration。
最后说说那个 child.return = completedWork 为什么被标记为 code smell。注释说:
This is a code smell because it assumes the commit phase is never concurrent with the render phase. Will address during refactor to alternate model.
意思是,这段代码假设 commit 阶段不会和 render 阶段并发。但 React 的并发模式可能会打破这个假设,所以将来会重构。不过现在还没重构,所以代码还在。
举个实际的例子,假设有这样的组件树:
jsx
<App>
{" "}
// 有副作用(Update)
<Header>
{" "}
// bailout 了
<Logo /> // 有副作用(Ref)
</Header>
<Content>
{" "}
// 有副作用(Placement)
<Article />
</Content>
</App>bubbleProperties 的执行过程:

这个图展示了副作用如何从叶子节点一层层冒泡到根节点。虚线箭头表示副作用的冒泡方向,最终 App 节点收集到了 Ref + Placement(相当于 Ref | Placement)的 subtreeFlags 和自己的 Update flag。
最终 App 的 subtreeFlags = Ref | Placement,flags = Update。commit 阶段只需要检查 App,就知道子树里有 Ref、Placement 和 Update 三种副作用。
这就是 bubbleProperties 的作用:把散落在各处的副作用收集起来,方便 commit 阶段快速判断。
副作用标记(Flags)
在 completeWork 阶段,会为需要在 commit 阶段处理的节点标记不同的 flags。React 使用位运算来高效地管理这些标记,就像任务优先级中的 lane 模型一样,flags 也采用了二进制位掩码的方式。
Flags 的完整定义
React 在 Fiber 架构中定义了 26 个不同的 flags,每个 flag 占据一个二进制位。以下是完整的 flags 定义:
ts
// ReactFiberFlags.js
export type Flags = number;
// 没有操作
export const NoFlags = /* */ 0b00000000000000000000000000;
// 标记节点已执行工作(开发模式使用)
export const PerformedWork = /* */ 0b00000000000000000000000001;
// DOM 操作相关
export const Placement = /* */ 0b00000000000000000000000010; // 插入节点
export const Update = /* */ 0b00000000000000000000000100; // 更新节点
export const Deletion = /* */ 0b00000000000000000000001000; // 删除节点(已废弃)
export const ChildDeletion = /* */ 0b00000000000000000000010000; // 删除子节点
export const ContentReset = /* */ 0b00000000000000000000100000; // 重置文本内容
// 生命周期相关
export const Callback = /* */ 0b00000000000000000001000000; // setState callback
export const DidCapture = /* */ 0b00000000000000000010000000; // 已捕获错误或 Promise
export const ForceClientRender = /* */ 0b00000000000000000100000000; // 强制客户端渲染
// Ref 相关
export const Ref = /* */ 0b00000000000000001000000000; // ref 需要更新
export const Snapshot = /* */ 0b00000000000000010000000000; // getSnapshotBeforeUpdate
// Hooks 相关
export const Passive = /* */ 0b00000000000000100000000000; // useEffect
// SSR Hydration 相关
export const Hydrating = /* */ 0b00000000000001000000000000; // 正在 hydrating
// 可见性相关(Suspense/Offscreen)
export const Visibility = /* */ 0b00000000000010000000000000; // 可见性变化
export const StoreConsistency = /* */ 0b00000000000100000000000000; // Store 一致性检查
// 生命周期副作用 Mask
export const LifecycleEffectMask =
Passive | Update | Callback | Ref | Snapshot | StoreConsistency;
// 所有 commit 阶段的副作用 Mask
export const HostEffectMask = /* */ 0b00000000000111111111111111;
// 工作状态标记(不是真正的副作用)
export const Incomplete = /* */ 0b00000000001000000000000000; // 工作未完成
export const ShouldCapture = /* */ 0b00000000010000000000000000; // 应该捕获错误/Promise
export const ForceUpdateForLegacySuspense = /* */ 0b00000000100000000000000000; // 强制更新(遗留 Suspense)
export const DidPropagateContext = /* */ 0b00000001000000000000000000; // Context 已传播
export const NeedsPropagation = /* */ 0b00000010000000000000000000; // 需要传播
export const Forked = /* */ 0b00000100000000000000000000; // 已分叉
// 静态标记(与特定渲染无关,用于 fiber 的持久化特征)
export const RefStatic = /* */ 0b00001000000000000000000000; // 静态 ref
export const LayoutStatic = /* */ 0b00010000000000000000000000; // 静态 layout effect
export const PassiveStatic = /* */ 0b00100000000000000000000000; // 静态 passive effect
// 开发模式标记(用于 double invoking)
export const MountLayoutDev = /* */ 0b01000000000000000000000000; // mount 时的 layout 调试
export const MountPassiveDev = /* */ 0b10000000000000000000000000; // mount 时的 passive 调试
// commit 阶段使用的组合 Mask(通过检查 subtreeFlags 跳过没有副作用的树)
export const BeforeMutationMask =
Update |
Snapshot |
(enableCreateEventHandleAPI ? ChildDeletion | Visibility : 0);
export const MutationMask =
Placement |
Update |
ChildDeletion |
ContentReset |
Ref |
Hydrating |
Visibility;
export const LayoutMask = Update | Callback | Ref | Visibility;
export const PassiveMask = Passive | ChildDeletion;
// 不会在 clone 时重置的静态标记
export const StaticMask = LayoutStatic | PassiveStatic | RefStatic;位运算操作
React 使用位运算来高效地操作 flags,就像 lane 模型一样,flags 也支持集合运算:
ts
// 1. 添加 flag(按位或)
workInProgress.flags |= Update;
// 等价于:workInProgress.flags = workInProgress.flags | Update;
// 2. 移除 flag(按位与非)
workInProgress.flags &= ~Update;
// 等价于:workInProgress.flags = workInProgress.flags & (~Update);
// 3. 检查是否包含 flag(按位与)
if ((workInProgress.flags & Update) !== NoFlags) {
// 包含 Update flag
}
// 4. 检查是否不包含 flag
if ((workInProgress.flags & Incomplete) === NoFlags) {
// 不包含 Incomplete flag
}
// 5. 同时添加多个 flags
workInProgress.flags |= Update | Ref;
// 6. 检查是否包含任意一个 flag(按位与 + 判断)
if ((workInProgress.flags & (Update | Ref)) !== NoFlags) {
// 包含 Update 或 Ref
}
// 7. 使用 Mask 批量检查多个 flag
if ((workInProgress.subtreeFlags & MutationMask) !== NoFlags) {
// 子树中有 Placement、Update、ChildDeletion、ContentReset、Ref、Hydrating 或 Visibility
}为什么使用位运算?
在 React 任务优先级中我们学习了 lane 模型采用位运算的优势,flags 同样采用这种方式。让我们回顾一下位运算的三大优势:
内存效率高
一个 32 位整数可以表示 32 个布尔值,而不需要创建对象或数组:
ts
// 不使用位运算(低效)- 需要约 200 字节
const flags = {
hasUpdate: true,
hasPlacement: false,
hasRef: true,
hasSnapshot: false,
hasPassive: true,
// ... 更多标记
};
// 使用位运算(高效)- 只需要 4 字节
const flags = 0b00000000000000101000000100; // Update | Ref | Passive运算速度快
位运算是 CPU 级别的操作,比对象属性访问和数组遍历快得多:
ts
// 对象方式(需要多次属性查找)
if (flags.hasUpdate || flags.hasRef) {
// 处理更新
}
// 位运算方式(一次运算完成)
if ((flags & (Update | Ref)) !== NoFlags) {
// 处理更新
}组合方便
可以使用 Mask 一次性检查多个 flag,避免多次判断:
ts
// 不使用 Mask(需要多次判断)
if (
(fiber.flags & Placement) !== NoFlags ||
(fiber.flags & Update) !== NoFlags ||
(fiber.flags & ChildDeletion) !== NoFlags ||
(fiber.flags & ContentReset) !== NoFlags ||
(fiber.flags & Ref) !== NoFlags ||
(fiber.flags & Hydrating) !== NoFlags ||
(fiber.flags & Visibility) !== NoFlags
) {
// 处理 mutation
}
// 使用 Mask(一次判断)
if ((fiber.flags & MutationMask) !== NoFlags) {
// 处理 mutation
}subtreeFlags 的妙用
在旧版本的 React 中,使用链表结构来收集副作用(Effect List)。但在新版本中,使用 subtreeFlags 可以更高效:
ts
// 旧版本:维护 Effect List 链表
let nextEffect = firstEffect;
while (nextEffect !== null) {
// 处理每个有副作用的节点
commitWork(nextEffect);
nextEffect = nextEffect.nextEffect;
}
// 新版本:commitMutationEffects 入口函数
export function commitMutationEffects(
root: FiberRoot,
finishedWork: Fiber,
committedLanes: Lanes
) {
inProgressLanes = committedLanes;
inProgressRoot = root;
// 直接调用递归函数,从根节点开始处理
commitMutationEffectsOnFiber(finishedWork, root, committedLanes);
inProgressLanes = null;
inProgressRoot = null;
}
// commitMutationEffectsOnFiber 内部会根据 subtreeFlags 决定是否遍历子树
function commitMutationEffectsOnFiber(finishedWork, root, lanes) {
// 检查子树是否有副作用
if ((finishedWork.subtreeFlags & MutationMask) !== NoFlags) {
// 有副作用,递归处理子节点
let child = finishedWork.child;
while (child !== null) {
commitMutationEffectsOnFiber(child, root, lanes);
child = child.sibling;
}
}
// 检查当前节点是否有副作用
if ((finishedWork.flags & MutationMask) !== NoFlags) {
// 处理当前节点的副作用(插入、更新、删除等)
commitMutationEffectsOnFiberImpl(finishedWork, root);
}
}这种方式的优势:
- 不需要维护额外的 Effect List 链表结构
- 通过 subtreeFlags 可以快速跳过没有副作用的整个子树
- 减少了指针操作和内存开销,提高了性能
这个设计在 completeWork 中得到了巧妙的体现,通过 bubbleProperties 函数,子节点的副作用标记会逐层向上冒泡,最终在 commit 阶段,React 只需检查根节点的 subtreeFlags,就能了解整棵树需要处理的部分,从而避免了遍历整棵树的额外开销。
总结
completeWork 是 Fiber 树构造的回溯阶段,它和 beginWork 形成了完美的配合。beginWork 向下遍历负责 diff,completeWork 向上回溯负责创建 DOM 和收集副作用。
在这个阶段,React 做了这些事情:在挂载时创建 DOM 节点,在更新时通过 diffProperties 计算属性差异并生成 updatePayload,然后通过 bubbleProperties 把子树的副作用一层层往上冒泡。特别要注意的是,这里创建的 DOM 只是存在内存中,并没有插入到页面里,因为 render 阶段是可以被打断的,如果直接插入 DOM,用户可能会看到半成品界面。
等 completeWork 结束后,React 手里已经有了一张完整的"施工图纸":fiber 树上标记了哪些节点需要处理(flags),哪些子树有变化(subtreeFlags),需要更新哪些属性(updateQueue)。有了这些信息,commit 阶段就可以一口气把所有变更应用到页面上,既快又不会被打断。
这种设计的巧妙之处在于把"计算该做什么"和"真正去做"分开了。render 阶段(可中断)专心计算和准备,commit 阶段(不可中断)快速执行。就像做饭一样,备菜的时候可以随时停下来处理其他事,但炒菜的时候就得一气呵成。这样既保证了用户体验,又让高优先级任务插队、并发渲染这些高级特性成为可能。
附加问题:React 如何实现增量渲染
React 的增量渲染正是通过 Fiber 架构和协调器来实现的。整个渲染过程被拆分成多个增量步骤,分布在多个时间片段中执行,而不是一次性完成。
通过时间分片的方式,页面的渲染过程被分成了多个增量步骤进行。React 使用虚拟 DOM 和 Diff 算法对比前后两个状态的差异,然后只更新真正需要变化的部分,而不是重新渲染整个组件树。这种渐进式的渲染方式避免了长时间的渲染阻塞,让页面可以更快地显示,从而保持页面的流畅性和响应性。
简单来说,beginWork 和 completeWork 的配合就是增量渲染的核心实现:把大任务拆成小步骤,每个步骤都可以暂停和恢复,只更新变化的部分。这就是 React Fiber 架构的精妙之处!