掌握 Prompt 高级技巧:CoT、ICL 与高效提示词框架指南
在与大语言模型(LLMs)交互时,提示词(Prompt)的质量直接决定了输出的质量 。本文将深入探讨提示工程中的核心技术,包括思维链(CoT)、上下文学习(ICL)以及三种业内认可的提示词编写技巧,帮助你更好地驾驭大模型 。
一、思维链(Chain-of-Thought, CoT)
思维链(Chain-of-Thought,简称 CoT)是提示工程领域的一项核心技术 。它聚焦于强化语言模型的复杂推理能力,要求模型在输出最终答案时,同步呈现中间推理步骤 。通过将复杂问题拆解为有序的子步骤求解,CoT 能助力模型更精准地理解和解决难题,弥补直接输出结果时可能存在的逻辑漏洞 。
CoT 的工作原理
CoT 重塑了模型传统的"输入-输出"映射模式,将其拓展为"输入-推理链(reasoning chain)-输出" 。通过显式输出中间步骤,它强化了算术、常识和符号推理等任务的表现 :
拆解问题:强制模型把复杂问题拆解成若干个小步骤,而不是直接跳到结论 。
显式推理:每一步都明确写出来,就像在草稿纸上演算一样 。
减少错误:如果模型算错了,用户能一眼看出错在哪一步 。
增强可信度:用户不仅能得到答案,还能看到模型的逻辑路径,避免了只得到一个"神谕式"的结果 。
CoT 案例对比
假设有这样一个问题:"小明有3个苹果,他又买了2个苹果,然后给了朋友1个。他现在有多少个苹果?"
普通 Prompt 的局限性:
问:小明有3个苹果,他又买了2个苹果,然后给了朋友1个。他现在有多少个苹果? 答:模型可能会直接给出一个答案 4 。
对于简单问题,直接输出答案或许能满足需求,但这缺乏推理过程 。用户无法追溯模型的思维方式,这在复杂任务中可能导致较高的错误率 。
使用 CoT Prompt:
问:帮我一步一步地推理以下问题:小明有3个苹果,他又买了2个苹果,然后给了朋友1个。他现在有多少个苹果?展示你的思考过程。答:小明有3个苹果。他又买了2个苹果,所以他现在有 3+2=53+2=53+2=5 个苹果。然后他给了朋友1个。所以他现在有 5−1=45-1=45−1=4 个苹果。
这种方式引导模型逐步推理,不仅结果更准确,解释也更清晰 。目前像 DeepSeek R1 这样的深度思考模型,其本质也是训练了推理数据,让模型在思考后再输出答案 。
二、上下文学习(In-Context Learning, ICL)
上下文学习(ICL)的核心在于让模型从任务相关的类比样本中学习 。它的工作方式是将若干特定形式的示例与当前输入通过 prompt 拼接到一起,作为大语言模型的输入 。简单来说,就是在提示词中加入几个完整的示例,让语言模型更好地理解当前任务,从而做出更准确的预测 。
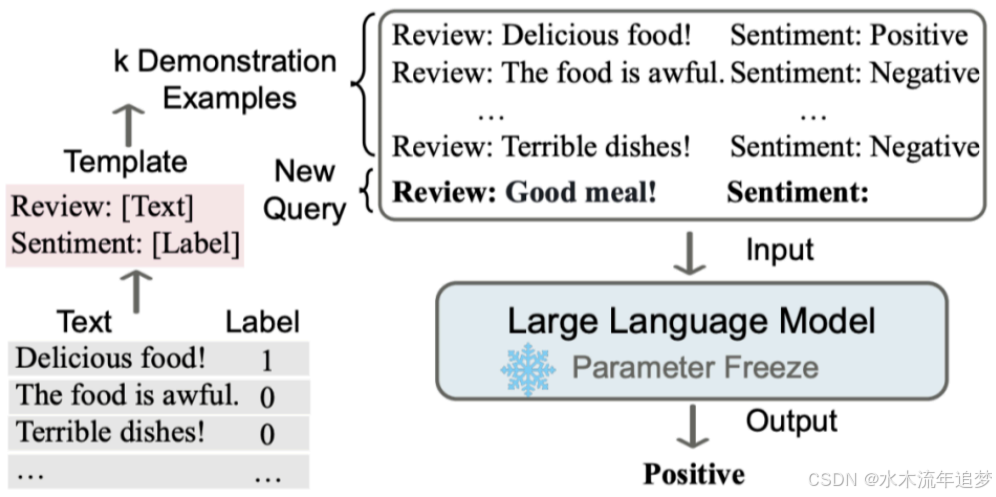
ICL 的分类
依据提示词中包含的示例条数,ICL 可分为三类 :
Few-Shot-CoT:借助多条"问题-示例样本-答案"样本引导模型推理,让模型学习拆解问题和显式推理的模式 。
One-Shot-CoT:提示词中只输入一条示例,模型根据这一条示例进行推理 。
Zero-Shot-CoT:不依赖示例,仅通过在指令中添加如"Let's think step by step"等魔法提示,极简式激活模型的分步思考潜能 。
ICL 的实现流程
ICL 的实现分为训练(Training)与推理(Inference)两个阶段 :
- 训练阶段(Warmup) :
在模型进入推理前,通过持续学习(Warmup)优化其 ICL 能力 。这有别于传统的 Finetune(聚焦特定任务),Warmup 旨在增强模型整体的 ICL 性能,使其更擅长从少量示例中学习 。根据数据是否依赖人工标注,Warmup 分为有监督与自监督两种 。
数据效率高:仅需少量训练数据即可显著提升 ICL 能力,持续增加数据则收益递减 。
潜力验证:这说明预训练模型本身已具备上下文学习潜力,Warmup 只是激活并优化它 。
非必需但推荐:虽然 ICL 不强制要求 Warmup,但实践中增加此步骤能大幅提升稳定性和效果 。
- 推理阶段 :
LLMs 的 ICL 性能高度依赖示例的设计 。相同的任务,若示例格式、顺序或内容不同,输出可能差异巨大 。因此,推理阶段的核心是通过示例选择、示例排序和示例格式化来优化上下文示例集 。
三、Prompt 编写的 3 项顶级技巧
业内认可的提示词编写技巧主要有以下三种 :
1. 使用 CO-STAR 框架
CO-STAR 框架涵盖了编写提示语句时需要考虑的六个方向 :
Context (上下文):提供任务的具体情景信息,确保回复具有相关性 。
Objective (目标):明确希望 LLM 执行的任务,使其将重点放在实现具体目标上 。
Style (风格):指明所需的写作风格(如某位名人、某行业专家),引导 LLM 使用契合的用词 。
Tone (语气):确定回复的态度(如正式、幽默、善解人意),确保产生共鸣 。
Audience (受众):确定回复对象(如专家、初学者),量身定制使其恰当且易于理解 。
Response (回复):提供所需的输出格式(如列表、JSON、报告),这对于程序化操作尤为重要 。
应用案例:起草一篇宣传 Alpha 公司新型吹风机 Beta 的 Facebook 帖子 。
使用 CO-STAR 的 Prompt 设计:
(上下文) 我想为我公司的新产品做广告。我的公司名叫Alpha,产品名叫Beta,是一种新型超快吹风机。(目标) 为我创建一个Facebook帖子,目的是让人们点击产品链接购买它。(风格) 效仿戴森等宣传类似产品的成功公司的写作风格。(语气) 有说服力的。(受众) 我公司在Facebook上的受众通常是老一代人。请针对这部分受众通常对美发产品的要求,量身定制你的帖子。(回复) Facebook上的帖子,简明扼要而又富有感染力。
2. 使用分隔符将提示词分段
分隔符可以是任何通常不会同时出现的特殊字符序列(如 ### 或 <<<>>>)。只要它们足够独特,LLM 就能将其理解为内容分隔符而非标点符号 。
XML 标签的高效性:
使用角括号括起来的 XML 标签(如 <tag> 和 </tag>)是一种非常有效的方法 。由于大模型接受过大量 XML 网页内容的训练,它们非常善于理解这种格式 。
XML 分隔符案例:
你是一名专业的政策解读人员,你需要阅读一篇英文政策文档,然后使用中文按照<<<模板>>>总结...
<POLICY>{政策文章内容}
</POLICY>请你根据以上政策,按照以下模板...
<POLICY_SUMMARY>{模板}
</POLICY_SUMMARY>
这样可以确保 LLM 清晰理解指令与被分隔内容之间的关系 。
3. 使用 LLM 系统提示 (System Prompt)
系统提示是一种独立于普通用户提示的附加提示,用于提供有关 LLM 行为方式的指令 。由于系统提示会自动与聊天中的每个新提示结合,它能确保 LLM 在整个交互过程中始终遵循这些规则 。
系统提示通常包含 :
任务定义:让 LLM 记住要做什么 。
输出格式:规范回复的形式 。
安全护栏:规定 LLM 不应该回复什么(例如限制特定话题) 。
RAG 系统提示模板案例:
你将使用给定的一段文本回答问题,文本内容在
<text>标签中,问题在<question>标签中。你需要使用JSON对象进行回复。如果文本中没有足够的信息,请将答案填写为未找到资料。切勿回答任何与人口统计信息相关的问题。
通过系统提示与用户提示中的 XML 标签配合,模型能精准理解全局指令与局部具体内容(如插入的文本和问题)的对应关系 。
