nano-vllm 用千行代码拆解 vLLM 核心,是读懂大模型推理最快的捷径。
推理引擎运行时,每个 step 都要处理几件耗显存的事:新到的序列要一次性写入整段 prompt 的 KV;已在运行的序列每个 step 追加一个 token 的 KV;显存紧张时要把某条序列整体换出、把它占用的 KV 块全数归还;两条序列前缀相同时希望共用一份 KV 而不是各算一遍。这些动作都发生在"物理块"(PagedAttention 把 KV Cache 切出的定长槽位)这一粒度上,并且都在 step 的关键路径上------慢一点,整轮吞吐就会明显下降。
BlockManager 就是回答以下问题的组件:现在能不能给某条序列分配 N 个块?某条序列下一个 step 追加一个 token,需不需要新块?某条序列离场了,它占用的块怎么登记回去?两条序列共用同一块时,谁先离场谁该真正释放?整个 engine/block_manager.py 只有 120 行,但每个 step 都会经过它。
这 120 行围绕 4 个数据结构和 5 个公开 API 展开。其中 len(seq) % bs == 1 与 reversed(seq.block_table) 这两处最关键------前者把"是否需要新块"压缩成一行算术,后者只用一个 reversed 让 deque 起到 LRU 队列的作用。
1. 系统位置
BlockManager 是 Scheduler 内部的一个组件,做的事情只有一件:维护"哪些物理块空着、哪些被谁占着"。它不接触 KV 张量,整个 engine/block_manager.py 没有一行 import torch。真正持有 KV Cache 的是另一个模块 ModelRunner------它在启动时用 torch.empty 一次性申请一大块显存,按物理块切好备用。两者通过一份整数列表对齐:seq.block_table: list[int],每条序列各持一份,第 i 个元素是该序列第 i 个逻辑块所对应的物理块号;前向时 GPU 按下标查到对应的物理槽位,再去那里读 K/V。
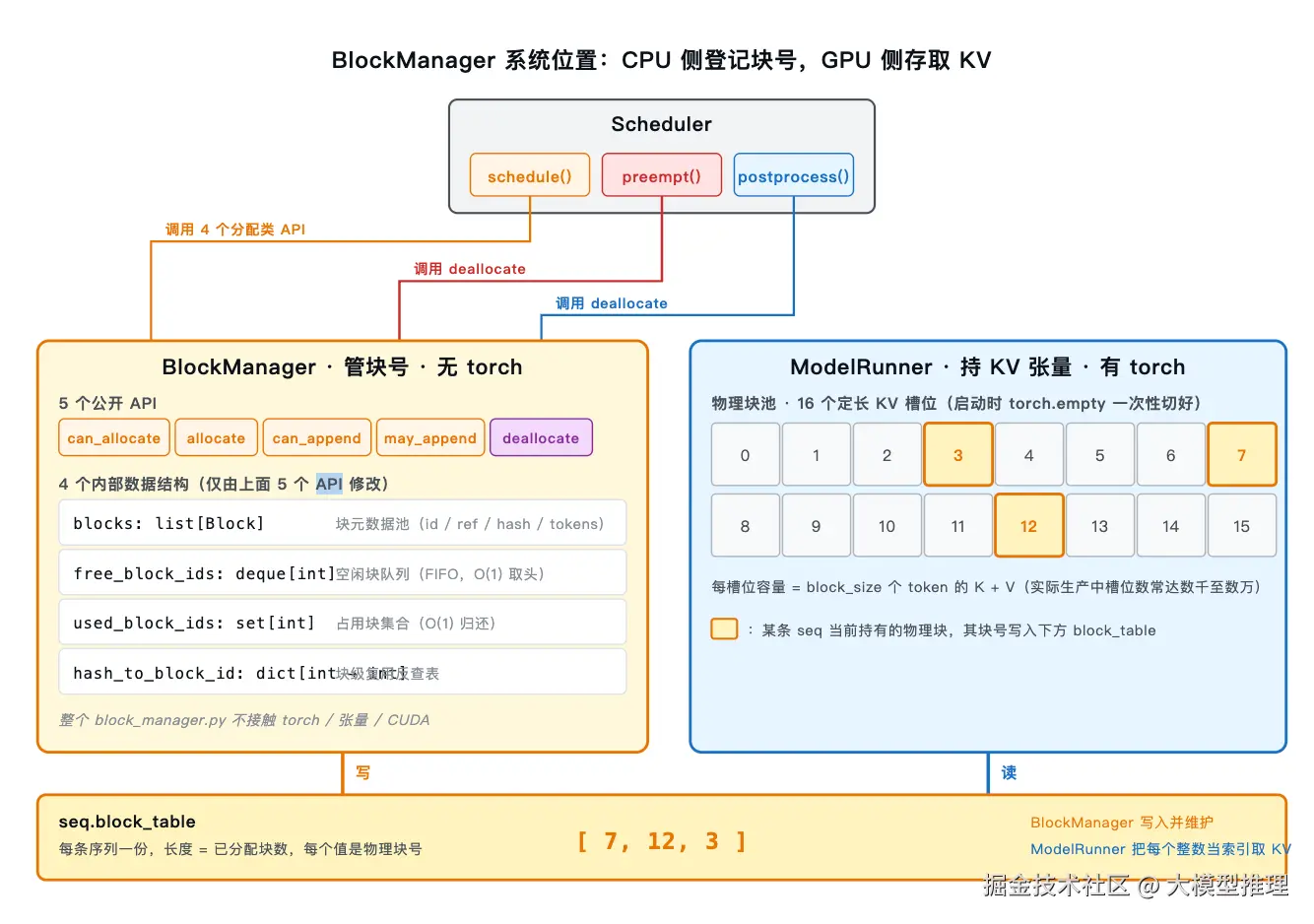
图自上而下分三块。先看上面的 Scheduler。
Scheduler 在三个时刻会调用 BlockManager(图中三种颜色的箭头,橙=schedule、红=preempt、蓝=postprocess):每个 step 开始时,由 schedule() 调用"分配类"的 4 个 API(can_allocate / allocate / can_append / may_append)做入场判断与块追加;显存不够时,由 preempt() 调 deallocate 把某条序列的块全部归还;序列写完一步后,由 postprocess() 调 deallocate 收尾。
BlockManager (黄色框)内部只有 4 个数据结构:blocks 块元数据池、free_block_ids 空闲块队列、used_block_ids 占用块集合、hash_to_block_id 块级复用反查表。这 4 个结构都只能由上方那 5 个公开 API 修改,对外不暴露。BlockManager 对系统其余部分修改的唯一状态,是每条序列的 seq.block_table------一串整数,每个整数是一个物理块号。
ModelRunner (蓝色框)持有 KV 张量。图中右侧的网格代表它在启动时切好的物理块池,共 16 个定长槽位(实际生产环境中常达数千至数万)。每个槽位容量等于 block_size 个 token 的 K + V。槽位之间是平等的,BlockManager 把哪几个槽位分给哪条序列,完全由它自己说了算。
底部的橙色长条就是这份 seq.block_table = [ 7, 12, 3 ]------它既是 BlockManager 的输出,也是 ModelRunner 的输入。BlockManager 写入并维护它(左侧橙色"写"箭头);ModelRunner 在前向时把每个整数当作物理块池的索引,到对应槽位上读 K/V(右侧蓝色"读"箭头)。图中网格里被高亮的 3、7、12 号槽位,正是列表中那三个整数指向的物理位置。CPU 侧只负责登记,GPU 侧只负责读取,两边完全靠这一个列表保持一致。
后面要讲的 4 个数据结构和 5 个 API,都在回答同一个问题:用最少的开销维护 seq.block_table 这串整数。
需要先建立一个概念:块级复用 。两条序列前缀相同时,让后到的那条直接把自己的 block_table 前几项指向前者已写满的物理块,省去对这段前缀重新做 prefill 的算力。本讲只讲 BlockManager 如何登记可被复用的物理块(在 Block.hash 与 hash_to_block_id 中留下入口),具体触发复用的时机、命中判断流程不在本讲范围之内。
2. Block 子对象
python
class Block:
block_id: int # 物理偏移,不变
ref_count: int # 持有此块的 seq 数(0 / 1 / >1)
hash: int # 块内容指纹(int64,-1 = 未标记)
token_ids: list # 块实际存放的 token 序列,用于内容校验把同一块的元数据聚拢到 Block 类里,可以按 block_id 一次取齐 ref_count / hash / token_ids,避免 4 个并列字典各查一次,也更便于阅读和扩展。
hash 字段先在这里作存在性说明:它是块内容的 int64 指纹(下文统一称作 hash,必要时括号补"指纹"二字作回忆性提示)。Scheduler 在 postprocess 阶段会扫描这一步内"刚写满"的块,调 hash_blocks 算出指纹并写入 Block.hash,同时把这条 hash → block_id 注册到反向索引 hash_to_block_id,作为块级复用的命中入口。此处仅作存在性说明,不展开具体计算方式与复用流程。
reset() 直接置 ref_count = 1 而不是 0:_allocate_block 的唯一调用语义就是分配后立刻被某条 seq 使用,因此 reset() 直接把 ref_count 置 1,省去调用方再 += 1。
3. 四个核心数据结构
python
self.blocks: list[Block] # 按 id O(1) 取
self.hash_to_block_id: dict[int, int] # 内容指纹反查物理块
self.free_block_ids: deque[int] # 空闲队列(FIFO 决定 LRU)
self.used_block_ids: set[int] # 在用集合(成员判定)| 结构 | 关键操作 | 复杂度 | 为什么是这种结构 |
|---|---|---|---|
blocks |
blocks[i] |
O(1) | 按 id 直接索引 |
hash_to_block_id |
get / del |
O(1) 平均 | 按内容指纹反查物理块(块级复用入口) |
free_block_ids |
popleft / append |
O(1) | 两端 O(1) 的双端队列;FIFO 顺序蕴含 LRU 时间序 |
used_block_ids |
in / add / remove |
O(1) | 只做成员判断,不需要顺序 |
hash_to_block_id 是块级复用的查询入口:一条新序列把自己前 k 块 token 各算出 hash,逐一去这张表里查"是否已有别的物理块存着相同 KV"。命中即可把那个物理块号直接挂到自己 block_table 上,省去这部分 prefill 的算力。
free_block_ids 选 deque 而不是 list 或 set 的理由:本组要求两端 O(1)。队头是分配口(popleft),队尾是归还口(append),队尾→队头的方向正好蕴含一种时间序------离队尾近的是最近释放的,离队头近的是最久没被使用的。这条时间序如何被复用为 LRU,§6 再展开。
底层的基础操作只有两个:
python
def _allocate_block(self) -> int:
block_id = self.free_block_ids.popleft() # 从队头取最久未用的块号(LRU 端)
block = self.blocks[block_id] # 块号 → Block 元数据
if block.hash != -1 and self.hash_to_block_id.get(block.hash) == block_id:
del self.hash_to_block_id[block.hash] # ⚠️ 守卫:清掉脏 hash,避免再被命中
block.reset() # ref_count=1, hash=-1, token_ids=[]
self.used_block_ids.add(block_id) # 登记为"使用中"
return block_id
def _deallocate_block(self, block_id: int):
self.used_block_ids.remove(block_id) # 从"使用中"集合移除
self.free_block_ids.append(block_id) # 推回队尾,下次轮到队头才被复用(LRU)del self.hash_to_block_id[...] 这一行是安全守卫 :刚被 popleft 的块可能曾经登记在反向索引里(用作某段已写满前缀的复用入口),不清掉这条 entry,后续就会查到一个"内容即将被覆写"的脏块。hash != -1 是先决条件:hash == -1 是未标记标志位,代表这块从未被写满或刚被 reset 清空,不曾注册到反向索引,没有 entry 可清;这里先判 != -1 是为了跳过那些不应被复用、也不需要清守卫的块。
4. 五个公开 API 与四个数据结构的对应
上一节讲了底层的 _allocate_block / _deallocate_block,本节看 Scheduler 实际调用的 5 个公开 API 怎么编排它们,并梳理这 5 个 API 触达哪些数据结构。按生命周期三阶段成对出现:
 右侧 4 个数据结构正是 §3 介绍过的那 4 个。图中三种颜色分别对应 schedule / preempt / postprocess 三个调用阶段;左侧 5 个 API 通过箭头连接右侧 4 个数据结构,展示每个 API 实际触达哪些状态。
右侧 4 个数据结构正是 §3 介绍过的那 4 个。图中三种颜色分别对应 schedule / preempt / postprocess 三个调用阶段;左侧 5 个 API 通过箭头连接右侧 4 个数据结构,展示每个 API 实际触达哪些状态。
4.1 prefill 入场:can_allocate / allocate
python
def can_allocate(self, seq) -> int:
# 查询是否有可复用的物理块(本讲不展开机制),并预估"可复用几块、要新几块"
# 返回 -1(装不下)或可复用块数
def allocate(self, seq, num_cached_blocks):
# num_cached_blocks 是 can_allocate 返回的可复用块数,调用方原样传回
for i in range(num_blocks):
token_ids = seq.block(i)
h = compute_hash(...) if i < num_blocks - 1 else -1
block_id = self.hash_to_block_id.get(h, -1)
if block_id == -1 or self.blocks[block_id].token_ids != token_ids:
# ② 全新申请:未命中或内容碰撞,走底层分配
block_id = self._allocate_block()
else:
# ① 复用已存在的物理块:ref_count += 1(若在 free 池则同时移出)
...
seq.block_table.append(block_id)两个细节:
num_cached_blocks:can_allocate已经数出来这条 seq 前缀可复用几块,allocate直接拿来用,避免重复扫一遍 hashcan_allocate循环到num_blocks - 1:最后一块通常未写满,因此不参与块级复用判断blocks[block_id].token_ids != token_ids这一步是内容碰撞防护:64-bit 指纹极少碰撞,但一旦碰撞就会读到错误 KV,因此 hash 命中后还要再做一次完整 token 序列比较,比较失败则退回到全新申请分支
4.2 decode 增量:can_append / may_append
python
def can_append(self, seq) -> bool:
# 右边布尔 → 0/1:不需要新块=0,需要=1;左边是 free 池剩余块数
return len(self.free_block_ids) >= (len(seq) % self.block_size == 1)
def may_append(self, seq):
if len(seq) % self.block_size == 1: # 刚越过块边界,块表差一块
seq.block_table.append(self._allocate_block()) # 申请新块号挂到块表末尾len(seq) % bs == 1 是整个 BlockManager 中最关键的一行:
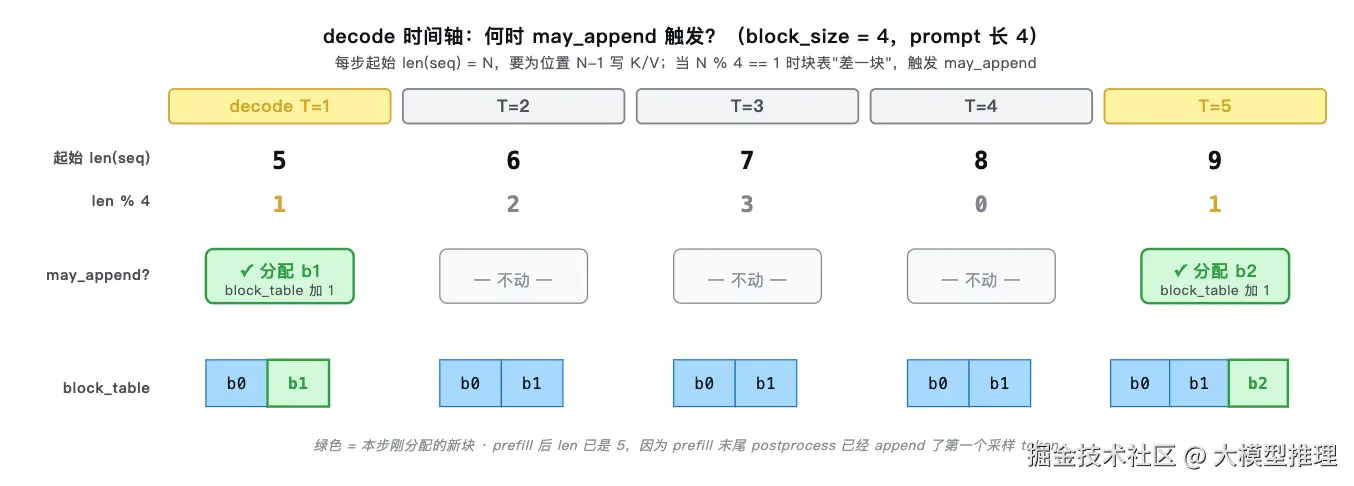 记
记 N = len(seq) 为序列当前总 token 数,bs = block_size。本步刚生成第 N 个 token(其下标为 N-1),需要将它的 K/V 写到块索引 ⌊(N-1)/bs⌋ 处。已分配块数等于"已写满或正在写的块数",即 ⌈(N-1)/bs⌉。当 N-1 是 bs 的整数倍(即上一块刚好写满)时 ⌈(N-1)/bs⌉ = (N-1)/bs;否则 ceil 等于整数除法的商加 1,即上一块尚未写满,仍在原块中追加。当 N-1 恰好落在新块的第 0 个位置(即 (N-1) mod bs == 0,等价于 N mod bs == 1),所需块索引比已分配块数大 1,块表"差一块"------触发 may_append。
can_append 中的一行 len(self.free_block_ids) >= (len(seq) % self.block_size == 1) 把两个判断合并写在一起。右边 len(seq) % self.block_size == 1 求得布尔值,被 Python 自动转换为 0 或 1,分别代表"本步无需新块"与"本步需要 1 块新块";左边是 free 池剩余块数。两边比较即"free 池剩余 ≥ 本步所需"。等号即恰好够用------剩 0 块且本步不要,或剩 1 块且本步要 1 块;再多 1 个 token 进来就要触发抢占。
4.3 离场归还:deallocate
python
def deallocate(self, seq):
for block_id in reversed(seq.block_table): # 倒序:让前缀块沉到 free deque 队尾(第 6 节)
block = self.blocks[block_id]
block.ref_count -= 1 # 每条引用这块的 seq 各减一次
if block.ref_count == 0: # 最后一个引用走了才真正归还
self._deallocate_block(block_id)
seq.num_cached_tokens = 0 # 重置此序列在 hash_to_block_id 中已命中的 token 计数
# (块级复用的累计量),便于下次复用判断
seq.block_table.clear() # 清空块表,序列与所有物理块脱钩减引用计数,ref_count == 0 表示没有任何 seq 还持有这块,可推回 free deque 等待复用;ref_count > 0 意味着仍有别的 seq 在用这块(共享前缀场景),此次 deallocate 不能动它的物理位置。reversed 的作用见第 6 节。
5. 块生命周期
把 5 个 API 收束成"块视角"的状态机:
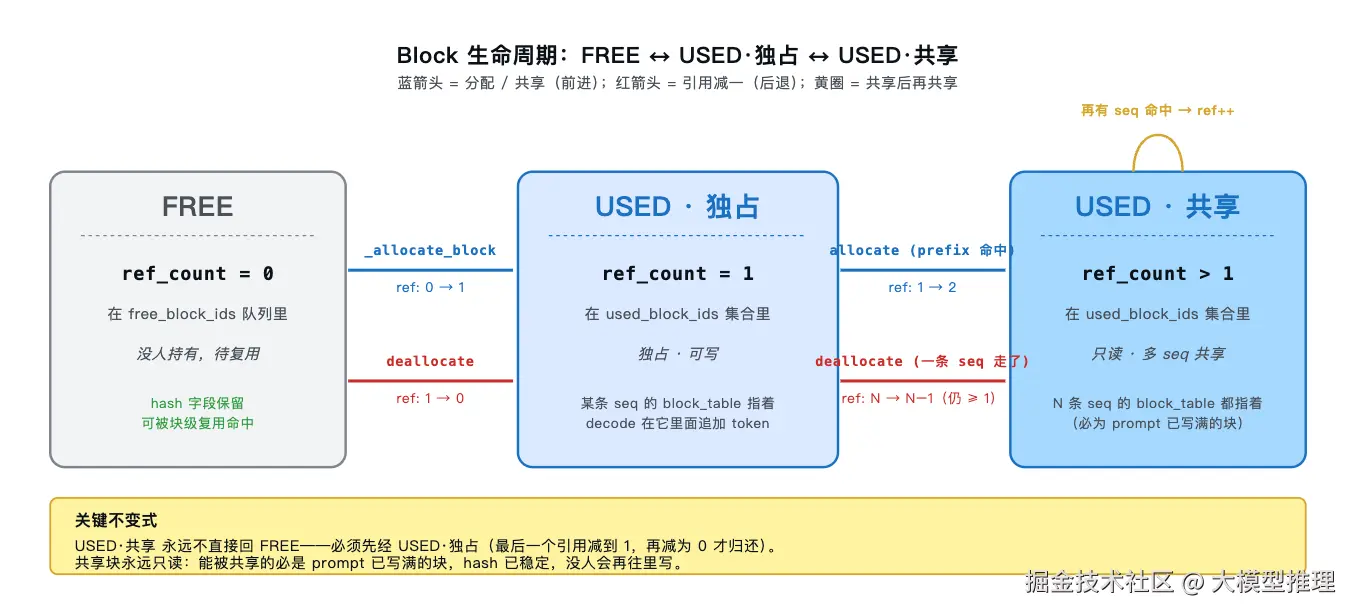
图中以圆角矩形表示块的三种状态,分别对应 ref_count 取 0 / 1 / >1 三态:
- FREE(
ref_count == 0) :没有任何seq.block_table指向它,块在 free deque 队列里等待复用。 - USED·独占(
ref_count == 1) :恰好一条 seq 的block_table指向它,归这条 seq 独占、可写。 - USED·共享(
ref_count > 1) :N 条 seq 的block_table同时指向它,只读(详见下文)。
箭头标注触发该转移的 API。读图前先界定三个概念。
hash 是什么? 块内容(block_size 个 token id)经 hash 函数压成的一个 int64 指纹(实现里用的是 xxhash)------相同 token 序列必然算出相同 hash。反过来 hash_to_block_id 字典就成了一张反向索引:哪个物理块已经存着某段 token 的 KV。如果未来有别的 seq 想用相同 token 序列的 KV,可以通过这个反向索引找回这块。本讲不展开具体复用流程。
为什么 FREE 状态下 hash 仍然有效? 因为 deallocate 只清 seq.block_table、把 block_id 推回 free deque------没动 Block.hash 字段,也没删 hash_to_block_id 里的 entry 。这块的指纹和反向索引都还指着它,KV 数据物理上也还在池里。一条新 seq 带相同前缀过来时能查到、能把它从 free 队列中取出并将 ref_count 重置为 1 直接复用。_allocate_block 里那条脏 hash 守卫处理的正是反向场景:如果不是被命中复用,而是被 popleft 走(即将被新内容覆写),那旧 hash 必须清掉,否则下次有人查这个 hash 会读到内容已变的脏块。结论:释放并不意味着失效------这是块级复用的物理基础。
共享块(USED·共享,ref_count > 1)是什么? 多条 seq 的 block_table 同时指着同一物理块------它们在 attention forward 时都读同一份 KV,由此一份已算好的 KV 可被多条 seq 共用,避免重复计算。典型场景:相同 system prompt 的并发请求。
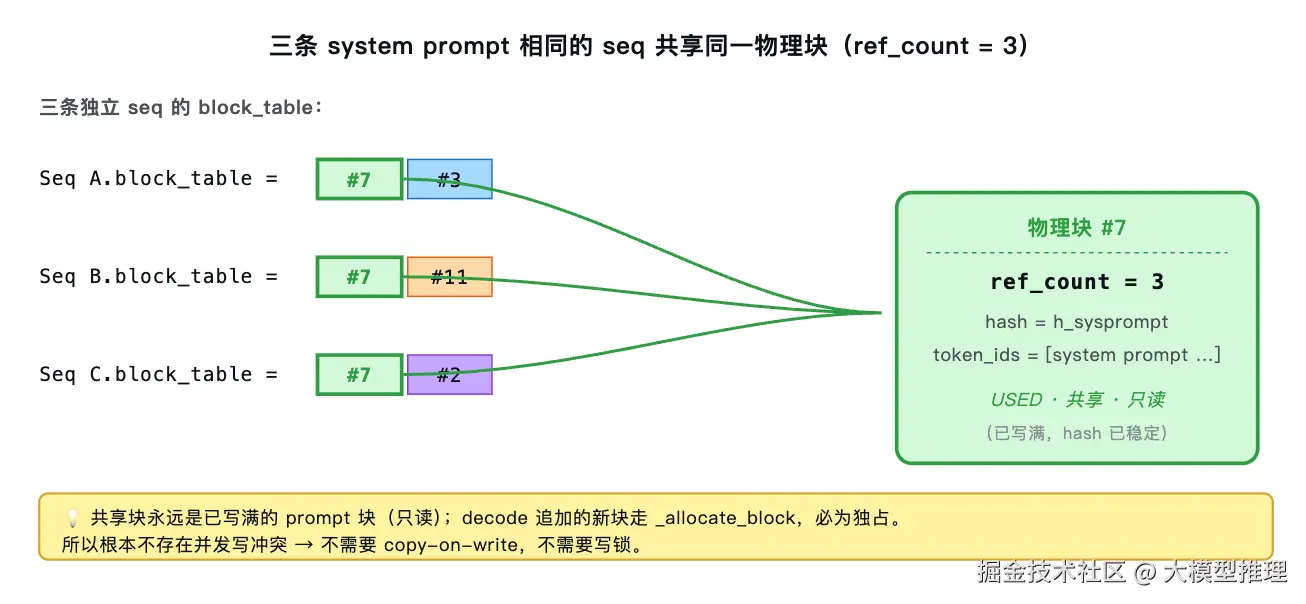 图中绿色边框的 #7 块即被三条 seq 同时持有的共享块,
图中绿色边框的 #7 块即被三条 seq 同时持有的共享块,ref_count = 3;蓝、橙边框是各自独占的后续块。
为什么共享的必是"已写满的 prompt 块"? 两个条件都得满足:
- 写满 → 指纹稳定:半满块还会追加 token,hash 会变。若半满块可共享,每追加一个 token 都要通知所有共享方失效,失效开销会很高。因此"写满 + 算 hash + 注册到反向索引"是一组动作------只有满足这一组动作的块才有资格被命中、被共享。
- prompt → 内容固定 :prompt 是 prefill 一次性算完的,token 序列确定;decode 是逐 token 采样,带随机性,两条 seq 此刻输出相同下一步也可能分叉。所以 decode 产生的块永远独占 ------
may_append总是调用_allocate_block申请新块就是这个原因。
合起来:能被共享的块都是写满的、内容不会再变的、指纹已稳定的、注册到反向索引中的 prompt 块。USED·共享 不直接回 FREE 也是同一套约束的体现:每次 deallocate 只把 ref_count 减 1;当 ref_count 从 N(>1)减到 1,块仍被一条 seq 持有,状态由"共享"降为"独占";只有再被那条 seq deallocate,ref_count 才到 0,块才真正回到 FREE。
对比 fork 式 KV 复用------每条 seq 各拷贝一份后再独立修改------这里 attention 是只读访问,共享块期间不会被任何 seq 写入,所以不需要 copy-on-write,也不需要写锁------这是 PagedAttention 在引擎层省去的一类实现复杂度。
6. reversed 是 LRU 的关键
LRU(Least Recently Used)即最久未被使用的优先被驱逐。这里的目标是让最不该被覆写的块------通常是已成为多条 seq 共用前缀的那些------在 free 队列里待得最久,越久不被 popleft 选中,越有机会等到下一次复用命中。
deallocate 中的 reversed(seq.block_table) 并非随意的实现选择:

图中左右两图分别对应顺序释放与倒序释放:左图按 [block0, block1, block2, ...] 的顺序逐个 append 到 free deque,前缀块 block0 落在队首,下一次 popleft 立即被取走;右图按反向顺序依次 append,前缀块 block0 最后入队,落在队尾,最迟才会被 popleft 选中覆写。
结论:
- 倒序释放 + deque popleft 取 / append 入:前缀块(最有复用价值的部分)沉到队尾,最不易被覆写
- 没有专门的 LRU 数据结构,靠 deque 方向性已经足够
- 如果没有
reversed,前缀块会被优先覆写,块级复用率会显著下降
7. 总结
把这一讲的几个要点串起来:
- 位置定位 :BlockManager 由 Scheduler 持有,对外只修改
seq.block_table这串整数;真正的 KV 张量在 ModelRunner------它管的是块号,不是 KV 张量本身。 - 4 个 O(1) 元数据结构 :
blocks索引 Block 对象、free_block_ids排空闲队列、used_block_ids判成员、hash_to_block_id按内容指纹反查物理块,全 O(1)。 - 5 个 API 按生命周期分组 :
schedule()调can_allocate / allocate / can_append / may_append,preempt()调deallocate,postprocess()调deallocate。 - 块的三态 :
ref_count区分 FREE / USED·独占(=1)/ USED·共享(>1)。USED·共享 不直接回 FREE,必经 USED·独占。 - 释放并不意味着失效 :
deallocate不清Block.hash、也不删hash_to_block_identry------这是已释放物理块仍可被新序列复用的物理基础。 reversed(seq.block_table):归还时倒序遍历,让最有复用价值的前缀块沉到 free deque 队尾,最不易被覆写------免去专门 LRU 数据结构。
下面这段视频把"一块物理 KV 块的一生"完整跑了一遍------它怎么被分配、写满、归还到 free deque、又被新请求复用: