目录
- Milvus概述
-
- [是什么让 Milvus 如此之快?](#是什么让 Milvus 如此之快?)
- [Milvus 支持哪些搜索类型?](#Milvus 支持哪些搜索类型?)
- [选择哪个版本?2.6.x? 还是3.0.x ?](#选择哪个版本?2.6.x? 还是3.0.x ?)
- [Milvus 快速入门(Milvus Lite)](#Milvus 快速入门(Milvus Lite))
- [Milvus 部署方式](#Milvus 部署方式)
-
- [部署Milvus Lite](#部署Milvus Lite)
- 部署Standalone
-
- [在 Docker 中运行 Milvus(Linux)](#在 Docker 中运行 Milvus(Linux))
- [使用 Docker Compose 运行 Milvus(Linux)](#使用 Docker Compose 运行 Milvus(Linux))
- 部署Distributed
- 不同部署方式下的功能对比
- 度量类型
-
- 欧几里得距离(L2)
- [内积(Inner Product,IP)](#内积(Inner Product,IP))
- [余弦相似度(Cosine Similarity)](#余弦相似度(Cosine Similarity))
- [JACCARD 距离(JACCARD distance)](#JACCARD 距离(JACCARD distance))
- [MHJACCARD(MinHash Jaccard)](#MHJACCARD(MinHash Jaccard))
- [HAMMING 距离](#HAMMING 距离)
- [BM25 相似度](#BM25 相似度)
- 数据库(Database)
- [Collection 详解](#Collection 详解)
-
- [创建 Collection(Create Collection)](#创建 Collection(Create Collection))
-
- [设置 Shard 数量(Set Shard Number)](#设置 Shard 数量(Set Shard Number))
- [启用 mmap(Enable mmap)](#启用 mmap(Enable mmap))
- [设置 Collection TTL(生命周期)](#设置 Collection TTL(生命周期))
- [设置一致性级别(Consistency Level)](#设置一致性级别(Consistency Level))
- [启用动态字段(Enable Dynamic Field)](#启用动态字段(Enable Dynamic Field))
- [查看 Collections(View Collections)](#查看 Collections(View Collections))
- [Modify Collection(修改集合)](#Modify Collection(修改集合))
- [Load & Release(加载与释放)](#Load & Release(加载与释放))
- [设置集合 TTL(Set Collection TTL)](#设置集合 TTL(Set Collection TTL))
- [设置一致性级别(Consistency Level)](#设置一致性级别(Consistency Level))
- [管理分区(Manage Partitions)](#管理分区(Manage Partitions))
- [管理别名(Manage Aliases)](#管理别名(Manage Aliases))
- [删除 Collection(Drop Collection)](#删除 Collection(Drop Collection))
- [Schema和数据字段(Data Fields)](#Schema和数据字段(Data Fields))
-
- [主键字段与 AutoID(Primary Field & AutoID)](#主键字段与 AutoID(Primary Field & AutoID))
-
- 使用AutoID
- [使用手动 ID](#使用手动 ID)
- [AutoID 如何工作(How AutoID works)](#AutoID 如何工作(How AutoID works))
- [稠密向量(Dense Vector)](#稠密向量(Dense Vector))
-
- [使用稠密向量(Use dense vectors)](#使用稠密向量(Use dense vectors))
- [二进制向量(Binary Vector)](#二进制向量(Binary Vector))
-
- [使用二进制向量(Use binary vectors)](#使用二进制向量(Use binary vectors))
- [稀疏向量(Sparse Vector)](#稀疏向量(Sparse Vector))
- [字符串字段(String Field)](#字符串字段(String Field))
- [数值字段(Number Field)](#数值字段(Number Field))
- [Array 字段](#Array 字段)
- [结构体数组(Array of Structs)](#结构体数组(Array of Structs))
-
- 限制(Limits)
- [添加 Array of Structs](#添加 Array of Structs)
- [Geometry 字段](#Geometry 字段)
- [TIMESTAMPTZ 字段(适用于 Milvus 2.6.6+)](#TIMESTAMPTZ 字段(适用于 Milvus 2.6.6+))
- [JSON 字段](#JSON 字段)
-
- [JSON 索引(JSON Indexing)](#JSON 索引(JSON Indexing))
- [JSON Shredding](#JSON Shredding)
- [动态字段(Dynamic Field)](#动态字段(Dynamic Field))
-
- [在动态字段中为 Key 建索引(Index keys in the dynamic field)](#在动态字段中为 Key 建索引(Index keys in the dynamic field))
- [Nullable 与默认值(Nullable & Default)](#Nullable 与默认值(Nullable & Default))
-
- [默认值(Default Values)](#默认值(Default Values))
- [Analyzer 字段](#Analyzer 字段)
-
- [内置 Analyzer(Built-in Analyzer)](#内置 Analyzer(Built-in Analyzer))
- [自定义分析器(Custom analyzer)](#自定义分析器(Custom analyzer))
- [使用示例(Example use)](#使用示例(Example use))
- [修改集合字段(Alter Collection Field)](#修改集合字段(Alter Collection Field))
- [向已有集合中添加字段(Add Fields to an Existing Collection)](#向已有集合中添加字段(Add Fields to an Existing Collection))
- 最佳实践
-
- 搜索系统的数据模型设计
- [使用 Struct 数组进行数据模型设计(Array of Structs)](#使用 Struct 数组进行数据模型设计(Array of Structs))
- 结尾
之前写过一篇关于 ChromaDB 的学习笔记。当时更多是从"向量数据库是什么"这个角度出发,体验了一下本地化、轻量级向量检索的基本流程。
不过随着对 RAG、Embedding、语义检索这些概念理解得越来越多,我也逐渐意识到:像 ChromaDB 这种偏内存型、轻量化的方案,虽然非常适合学习和 Demo,但在数据规模、性能、分布式能力以及生产环境支持方面,还是和真正的向量数据库存在明显差异。
于是,我开始接触 Milvus。
这篇文章就作为一次新的学习记录,看看这个被很多 AI 检索系统使用的向量数据库,到底解决了哪些问题,又和之前使用过的 ChromaDB 有什么不同。
Milvus概述
Milvus(鹞)是一种隼形目鹰科(Accipitridae)中的猛禽,以飞行速度快、视力敏锐以及极强的环境适应能力而闻名。
Zilliz 以 "Milvus" 为名,推出了其开源的高性能、高扩展性向量数据库。它能够在从个人笔记本电脑到超大规模分布式系统的各种环境中高效运行,同时既提供开源版本,也提供云服务版本。
Milvus 由 Zilliz 开发,随后捐赠给了 LF AI & Data Foundation(隶属于 Linux Foundation)。如今,它已经成为全球最知名的开源向量数据库项目之一。
文本、图片、音频等非结构化数据,由于格式多样且包含丰富的语义信息,因此分析和处理起来往往比较困难。
为了更好地处理这些数据,通常会使用 Embedding(向量嵌入)技术,将非结构化数据转换为能够表达其核心特征的数值向量(Vector)。
这些向量随后会被存储到向量数据库中,从而支持高性能、可扩展的相似度搜索与数据分析。
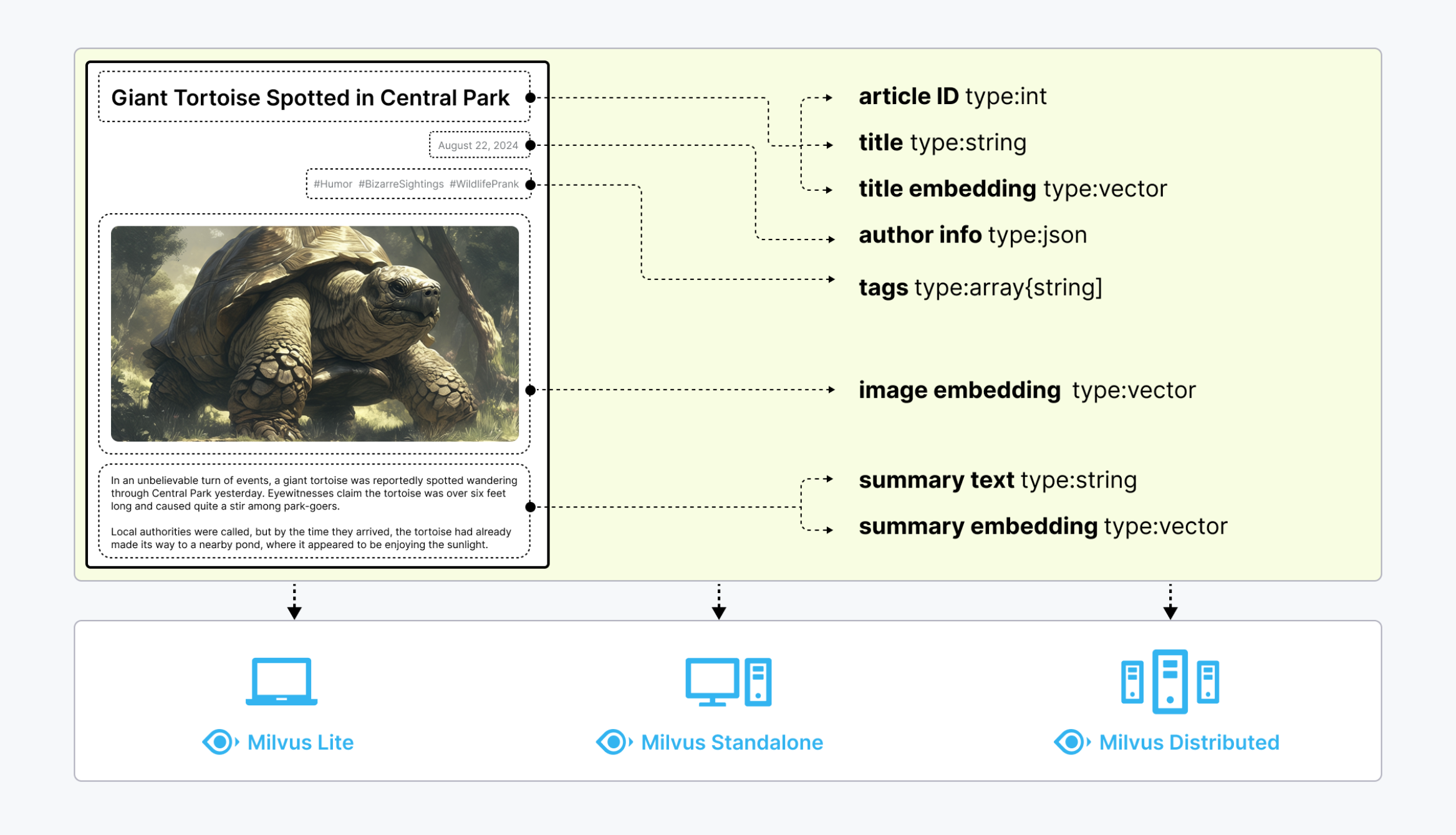
Milvus 提供了强大的数据建模能力,可以帮助开发者将非结构化数据或多模态数据组织为结构化集合(Collection)。它支持多种数据类型,包括:
- 常见数值类型
- 字符类型
- 多种向量类型
- Array
- Set
- JSON
因此,你无需维护多套数据库系统,就能够完成复杂的数据组织与检索需求。
Milvus 提供了三种部署模式,覆盖了从本地原型开发到超大规模生产集群的各种场景。
-
Milvus Lite(不支持windows)Milvus Lite 是一个 Python 库,可以非常方便地集成到应用中。
作为 Milvus 的轻量级版本,它非常适合:
- Jupyter Notebook 中的快速原型开发
- 边缘设备
- 资源受限环境
-
Milvus StandaloneMilvus Standalone 是单机版部署方案。
它会将所有组件打包进一个 Docker 镜像中,部署简单,非常适合:
- 本地开发
- 小规模测试
- 单机服务场景
-
Milvus DistributedMilvus Distributed 支持部署在 Kubernetes 集群中。
它采用云原生架构,专门面向:
- 十亿级向量数据
- 超大规模检索系统
- 高可用生产环境
该架构还能够保证关键组件的冗余能力,提高系统稳定性与可扩展性。
是什么让 Milvus 如此之快?
Milvus 从设计之初,就被定位为一个高性能向量数据库系统。
在大多数场景下,Milvus 的性能通常比其他向量数据库高出 2~5 倍(可参考 VectorDBBench 的测试结果)。这种高性能主要来源于以下几个关键设计:
-
面向硬件的优化(Hardware-aware Optimization)
为了让 Milvus 能够适配各种硬件环境,它针对多种硬件架构与平台进行了深度优化,包括:
- AVX512
- SIMD
- GPU
- NVMe SSD
也就是说,Milvus 并不仅仅依赖"算法快",而是会尽可能榨干底层硬件性能。
-
高级搜索算法(Advanced Search Algorithms)
Milvus 支持大量内存与磁盘索引/检索算法,包括:
- IVF
- HNSW
- DiskANN
- 等多种 ANN(近似最近邻)算法
而且这些算法都经过了深度优化。
相比于常见实现,例如:
- FAISS
- HNSWLib
Milvus 通常能够获得 30%~70% 更高的性能表现。
-
基于 C++ 的搜索引擎(Search Engine in C++)
一个向量数据库 80% 以上的性能,往往取决于搜索引擎本身。
Milvus 使用 C++ 编写核心搜索引擎,因为 C++ 具备:
- 更高性能
- 更底层的优化能力
- 更高效的资源管理
更重要的是,Milvus 内部集成了大量"硬件感知"优化代码,例如:
- 汇编级向量化(Assembly-level Vectorization)
- 多线程并行化
- 任务调度优化
从而最大程度利用 CPU 与硬件能力。
-
列式存储(Column-Oriented)
Milvus 是一个列式(Column-Oriented)向量数据库。
列式存储最大的优势在于数据访问模式。
传统行式数据库查询时,往往需要读取整行数据;而列式数据库只会读取查询涉及的字段,因此能够大幅减少数据读取量。
此外,基于列的数据结构还非常适合做向量化计算,可以一次性对整列数据执行操作,从而进一步提升性能。
2022 年,Milvus 已经支持十亿级向量数据。
到了 2023 年,它已经能够稳定支撑数百亿级向量规模,并服务于超过 300 家大型企业,包括:
- Salesforce
- PayPal
- Shopee
- Airbnb
- eBay
- NVIDIA
- IBM
- AT&T
- LINE
- ROBLOX
- 等众多大型企业。
Milvus 的云原生(Cloud-Native)以及高度解耦架构,使它能够随着数据增长持续横向扩展。
Milvus 本身是完全无状态(Stateless)的,因此可以非常方便地借助:
- Kubernetes
- 公有云平台
进行弹性扩容。
同时,Milvus 的核心组件之间解耦程度非常高。
系统中的三个关键任务:
- 向量搜索(Search)
- 数据写入(Insertion)
- 索引构建 / 数据压缩(Indexing / Compaction)
都被设计成了易于并行化的独立流程。
因此:
- Query Node
- Data Node
- Index Node
都能够独立进行横向扩展(Scale Out)与纵向扩展(Scale Up)。
这种设计能够更好地平衡:
- 性能
- 扩展能力
- 成本控制
从而适应超大规模向量检索场景。
Milvus 支持哪些搜索类型?
Milvus 提供了多种搜索能力,以满足不同业务场景的需求。
-
ANN Search(近似最近邻搜索)
ANN(Approximate Nearest Neighbor)搜索用于寻找与查询向量最接近的 Top K 向量。
这是向量数据库最核心的能力,也是语义搜索、RAG、推荐系统等场景中最常见的搜索方式。
-
Filtering Search(带过滤条件的搜索)
Filtering Search 会在指定过滤条件下执行 ANN 搜索。
例如:
- 只搜索某个用户的数据
- 只搜索指定时间范围的数据
- 只搜索某个分类下的内容
这使得向量搜索能够结合结构化条件一起工作。
-
Range Search(范围搜索)
Range Search 用于查找距离查询向量在指定半径范围内的数据。
与 Top K 搜索不同,它更关注"距离范围"而不是"返回数量"。
-
Hybrid Search(混合搜索)
Hybrid Search 支持基于多个向量字段执行 ANN 搜索。
例如:
- 图像向量 + 文本向量
- 标题向量 + 正文向量
- 多模态搜索
适用于复杂语义检索场景。
-
Full Text Search(全文搜索)
Milvus 支持基于 BM25 的全文检索。
也就是说,Milvus 不仅支持向量搜索,还支持传统关键词搜索能力。
这里的 BM25 是经典搜索引擎中的核心排序算法,被广泛应用于:
- 搜索引擎
- 文档检索
- Elasticsearch 类系统
-
Reranking(重排序)
Reranking 会在初次 ANN 搜索结果基础上,利用额外规则或第二阶段算法重新排序。
例如:
- 结合业务权重
- Cross Encoder 重排
- 多路召回融合
从而进一步提升搜索质量。
-
Fetch(主键获取)
Fetch 用于通过主键(Primary Key)直接获取数据。
类似传统数据库中的主键查询。
-
Query(表达式查询)
Query 用于基于指定表达式检索数据。
例如:
- age > 18
- category == "AI"
更接近传统数据库查询能力。
除了上述核心搜索能力之外,Milvus 还围绕 ANN 搜索提供了大量配套功能。
Milvus 提供了多种官方 SDK:
- RESTful API(官方)
- PyMilvus(Python SDK)
- Go SDK
- Java SDK
- Node.js SDK
- C# SDK(由微软贡献)
- C++ SDK
- Rust SDK(开发中)
除了基础数据类型外,Milvus 还支持多种高级数据类型以及对应距离计算方式。
Sparse Vector(稀疏向量)
适用于:
- BM25
- SPLADE
- 稀疏检索模型
Binary Vector(二值向量)
适用于:
- 图像特征
- 指纹特征
- 二进制编码场景
JSON 支持
Milvus 支持 JSON 字段,可以存储复杂结构化元数据。
Array 支持
支持数组类型字段。
Text(开发中)
未来将原生支持文本类型。
Geolocation(开发中)
未来将支持地理位置数据类型。
选择哪个版本?2.6.x? 还是3.0.x ?
在介绍 Milvus 的版本之前,有必要先简单说明一下软件工程中常见的发布阶段。
很多人会看到 "Alpha / Beta / RC / Release" 这些词,但并不清楚它们在工程上的实际含义。
下面是一个典型的软件发布生命周期:
-
Alpha(内部验证阶段)
Alpha 版本通常是:
- 功能刚完成初步实现
- 架构可能仍在频繁调整
- 主要用于开发团队内部测试
特点是:
- 功能不完整
- Bug 较多
- 接口可能随时变化
- 不建议任何生产使用
👉 可以理解为:"能跑,但不保证正确"
-
Beta(公开测试阶段)
Beta 版本意味着:
- 功能已经基本完成
- 开始对外开放测试
- 重点转向稳定性与问题修复
但仍然存在:
- 已知或未知 Bug
- 部分行为可能变更
- 性能与稳定性仍在优化
👉 可以理解为:"功能基本可用,但还在打磨"
-
RC(Release Candidate,发布候选版)
RC 版本是:
- 接近正式版本的最终候选
- 主要用于最后的验证
如果没有严重问题,就会升级为正式版。
👉 可以理解为:"几乎就是正式版"
-
Release / Stable(正式稳定版)
正式版本意味着:
- 功能基本冻结
- API 与行为保持稳定
- 面向生产环境使用
这是企业生产系统最常使用的版本类型。
👉 可以理解为:"可以放心上生产"
虽然 Milvus 的 3.0 已经从 Alpha 走到了 Beta 阶段,并且引入了诸如 Lake 生态整合、External Collection、Snapshot 等一系列新能力,但在软件工程实践中,Beta 版本通常仍然不被视为生产环境的稳定版本。
Beta 更偏向于:
- 功能验证阶段
- 架构演进阶段
- 生态兼容性测试阶段
- 以及早期用户反馈收集
换句话说,它已经"能用",但还没有完全"稳定可依赖"。
对于生产系统而言,稳定性、接口兼容性以及行为可预测性,往往比新特性更重要。
因此,本博客的内容将以 Milvus 2.6.x 系列为主线进行讲解与实践,原因主要包括:
-
生产成熟度更高
2.6.x 是已经经过大量企业验证的稳定版本,在:
- 长期运行稳定性
- 分布式一致性
- 查询性能表现
- 运维成熟度
方面都更可靠,更适合用于生产级系统参考。
-
API 与行为更稳定
相比 3.0 的架构演进与能力扩展,2.6.x 在接口层面:
- 变更频率更低
- 行为更可预测
- SDK 兼容性更稳定
这对于学习与落地实践尤为重要,避免因为版本变化导致概念混乱。
-
更适合作为学习与工程基线
对于向量数据库的学习而言,一个稳定版本更有利于理解核心概念,例如:
- 向量索引机制(IVF / HNSW / DiskANN)
- ANN 搜索流程
- Segment / Replica / Node 架构
- 数据写入与查询链路
- 分布式调度模型
这些核心能力在 2.6.x 中已经非常完整,并且结构清晰。
-
与 3.0 的关系
3.0 更像是一个"面向未来的架构升级版本",而 2.6.x 则是当前工程实践中更常见的"稳定生产基线"。
因此本博客会:
- 以 2.6.x 为主线
- 在关键地方补充 3.0 的演进方向
- 用对比方式说明架构变化
Milvus 快速入门(Milvus Lite)
Milvus Lite 是 PyMilvus 中内置的 Python 库,可以直接嵌入客户端应用中使用。(不支持windows)
同时,Milvus 也支持通过 Docker 和 Kubernetes 进行生产级部署。
在开始之前,请确保本地环境已安装:
- Python 3.8+
然后安装 pymilvus(包含 Python 客户端 + Milvus Lite):
bash
pip install -U pymilvus要创建一个本地 Milvus 向量数据库,只需要实例化一个 MilvusClient,并指定数据文件名,例如:
python
from pymilvus import MilvusClient
client = MilvusClient("milvus_demo.db")这将创建一个本地数据库文件 milvus_demo.db。
然后,我们来创建一个Collection !
在 Milvus 中,Collection 用于存储向量及其相关元数据。
你可以把它理解为传统 SQL 数据库中的"表(Table)"。
在创建 Collection 时,可以定义:
- Schema(结构)
- Index 参数(索引配置)
包括:
- 向量维度
- 索引类型
- 距离度量方式
在入门阶段,先使用默认配置。
python
if client.has_collection(collection_name="demo_collection"):
client.drop_collection(collection_name="demo_collection")
client.create_collection(
collection_name="demo_collection",
dimension=768,
)在上述配置中:
- 主键字段默认名为:
id - 向量字段默认名为:
vector - 距离度量(metric type)默认使用:COSINE(可以理解为计算两个向量相似度的算法,注意区分索引喝度量)
- 主键类型为整数(不自动递增,即未启用 auto-id)
当然,你也可以通过 schema 显式定义 Collection 结构。
然后我们来准备一些数据,我们使用向量进行文本语义搜索,因此需要将文本转换为 Embedding 向量。
这些向量可以通过 PyMilvus 提供的模型工具生成。
安装模型依赖
bash
pip install "pymilvus[model]"该包包含 PyTorch 等机器学习依赖。(你也可以使用hf的sentence_tranformer库或者外部的embeding接口)
如果是首次安装,可能需要一定时间下载。
将文本转换为向量(Embedding):
python
from pymilvus import model如果 HuggingFace 访问失败,可以使用镜像:
python
# import os
# os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'默认模型为:
paraphrase-albert-small-v2(约 50MB)
python
embedding_fn = model.DefaultEmbeddingFunction()示例文本
python
docs = [
"Artificial intelligence was founded as an academic discipline in 1956.",
"Alan Turing was the first person to conduct substantial research in AI.",
"Born in Maida Vale, London, Turing was raised in southern England.",
]生成向量
python
vectors = embedding_fn.encode_documents(docs)输出向量维度为:
python
print("Dim:", embedding_fn.dim, vectors[0].shape)结果:
Dim: 768 (768,)说明:
- 每条文本被编码成 768 维向量
- 与 Collection 定义的维度一致
Milvus 插入数据时,需要组织为"实体列表(list of dictionaries)",每条数据包含:
- id
- vector
- text
- metadata(如 subject)
python
data = [
{"id": i, "vector": vectors[i], "text": docs[i], "subject": "history"}
for i in range(len(vectors))
]
python
print("Data has", len(data), "entities, each with fields: ", data[0].keys())
print("Vector dim:", len(data[0]["vector"]))输出:
Data has 3 entities, each with fields: dict_keys(['id', 'vector', 'text', 'subject'])
Vector dim: 768接下来,我们将数据插入到集合(collection)中:
python
res = client.insert(collection_name="demo_collection", data=data)
print(res)输出结果:
json
{'insert_count': 3, 'ids': [0, 1, 2], 'cost': 0}现在我们可以进行语义搜索了。
方式是:
将查询文本转换为向量,然后在 Milvus 中进行向量相似度检索。
Milvus 支持一次提交一个或多个向量查询。
query_vectors 是一个向量列表,其中每个向量都是 float 数组。
python
query_vectors = embedding_fn.encode_queries(["Who is Alan Turing?"])如果没有 embedding 模型,也可以使用随机向量:
python
# query_vectors = [[random.uniform(-1, 1) for _ in range(768)]]执行向量检索:
python
res = client.search(
collection_name="demo_collection",
data=query_vectors,
limit=2,
output_fields=["text", "subject"],
)
print(res)返回结果示例:
json
data: [
[
{
'id': 2,
'distance': 0.5859,
'entity': {
'text': 'Born in Maida Vale, London, Turing was raised in southern England.',
'subject': 'history'
}
},
{
'id': 1,
'distance': 0.5118,
'entity': {
'text': 'Alan Turing was the first person to conduct substantial research in AI.',
'subject': 'history'
}
}
]
]搜索结果是一个二维结构:
- 外层:对应每一个 query
- 内层:该 query 的 Top-K 结果
每个结果包含:
- primary key(id)
- distance(与查询向量的距离)
- entity(返回的字段数据)
你还可以在向量搜索时加入过滤条件(metadata filter)。
在 Milvus 中,这些非向量字段被称为 scalar fields(标量字段)。
python
docs = [
"Machine learning has been used for drug design.",
"Computational synthesis with AI algorithms predicts molecular properties.",
"DDR1 is involved in cancers and fibrosis.",
]
vectors = embedding_fn.encode_documents(docs)
data = [
{"id": 3 + i, "vector": vectors[i], "text": docs[i], "subject": "biology"}
for i in range(len(vectors))
]
client.insert(collection_name="demo_collection", data=data)带过滤条件的搜索:
python
res = client.search(
collection_name="demo_collection",
data=embedding_fn.encode_queries(["tell me AI related information"]),
filter="subject == 'biology'",
limit=2,
output_fields=["text", "subject"],
)
print(res)返回结果示例
json
data: [
[
{
'id': 4,
'distance': 0.2703,
'entity': {
'text': 'Computational synthesis with AI algorithms predicts molecular properties.',
'subject': 'biology'
}
},
{
'id': 3,
'distance': 0.1642,
'entity': {
'text': 'Machine learning has been used for drug design.',
'subject': 'biology'
}
}
]
]默认情况下,标量字段(scalar fields)是不单独建立索引的。
如果在大规模数据中需要高效的过滤检索,可以:
- 使用固定 schema
- 为字段建立索引
来提升性能。
除向量搜索外的查询能力,Milvus还提供了 Query 查询
query() 用于根据条件或 ID 直接检索数据。
按条件查询:
python
res = client.query(
collection_name="demo_collection",
filter="subject == 'history'",
output_fields=["text", "subject"],
)按 ID 查询:
python
res = client.query(
collection_name="demo_collection",
ids=[0, 2],
output_fields=["vector", "text", "subject"],
)此外,可以通过 ID 或过滤条件删除数据。
按 ID 删除:
python
res = client.delete(
collection_name="demo_collection",
ids=[0, 2]
)
print(res)按条件删除
python
res = client.delete(
collection_name="demo_collection",
filter="subject == 'biology'"
)
print(res)输出:
json
[0, 2]
[3, 4, 5]由于 Milvus Lite 的数据存储在本地文件中,因此即使程序结束,也可以重新加载数据:
python
from pymilvus import MilvusClient
client = MilvusClient("milvus_demo.db")这会:
- 恢复已有 collection
- 继续写入数据
- 保留历史数据
如果要清空整个集合:
python
client.drop_collection(collection_name="demo_collection")Milvus Lite 适合:
- 本地 Python 学习
- 快速原型开发
但在生产环境中,通常会部署:
- Docker
- Kubernetes
所有部署模式共享同一套 API,因此迁移成本很低,只需要修改:
python
client = MilvusClient(uri="http://localhost:19530", token="root:Milvus")Milvus 部署方式
Milvus 是一个高性能、可扩展的向量数据库,能够覆盖从本地实验到超大规模生产系统的各种场景,例如:
- 在 Jupyter Notebook 中运行的小型 Demo
- 到 Kubernetes 集群中处理数百亿级向量的大型系统
目前 Milvus 主要提供三种部署方式:
- Milvus Lite
- Milvus Standalone
- Milvus Distributed
-
Milvus Lite
Milvus Lite 是一个 Python 库,可以直接嵌入到应用中使用。
作为轻量版本,它非常适合:
- Jupyter Notebook 快速原型开发
- 资源受限的智能设备或本地环境
Milvus Lite 的一个重要特点是:
它与其他 Milvus 部署模式使用完全一致的 API
这意味着:
- 你在 Milvus Lite 上写的代码
- 可以无缝迁移到其他 Milvus 集群(无需修改核心逻辑)
只需要安装:
bashpip install pymilvus然后创建本地向量数据库:
pythonMilvusClient("./demo.db")即可在本地文件中持久化数据。
-
Milvus Standalone
Milvus Standalone 是单机部署版本。
它将 Milvus 的所有组件打包在一个 Docker 镜像中,因此部署非常简单。
适用于:
- 有生产需求,但不想使用 Kubernetes
- 单机资源充足的中小规模系统
特点:
- 部署简单
- 运维成本低
- 支持完整 Milvus 功能
-
Milvus Distributed
Milvus Distributed 支持在 Kubernetes 集群上部署。
它采用云原生架构设计,核心特点是:
- 写入(ingestion)与查询(search)分离
- 不同任务由独立节点处理
- 关键组件支持冗余(replication)
因此具备:
- 更高可扩展性
- 更强高可用性
- 更灵活的资源调度能力
适用于:
- 企业级大规模向量检索系统
- 百亿级甚至更大规模数据场景
Milvus 的部署模式选择,通常取决于应用所处的开发阶段与数据规模。
如果你希望快速搭建一个原型系统,用于学习或验证想法,例如:
- RAG(检索增强生成)Demo
- AI 聊天机器人
- 多模态搜索系统
那么可以选择:
- Milvus Lite
- 或 Milvus Lite + Milvus Standalone 的组合
你可以在 Notebook 中使用 Milvus Lite 进行快速开发,例如:
- 尝试不同的 RAG chunking 策略
- 验证向量检索效果
- 快速迭代 AI 应用原型
当你的原型需要:
- 服务真实用户
- 或数据规模达到数百万级以上
可以迁移到 Milvus Standalone。
由于所有 Milvus 部署模式使用统一 API:
Milvus Lite 代码可以无缝复用
同时,数据也可以通过工具从 Lite 迁移到 Standalone。
当项目进入早期生产阶段,但仍处于:
- 产品市场匹配(PMF)探索期
- 更关注迭代速度而非极致扩展性
此时推荐使用:
Milvus Standalone
它的特点:
- 部署简单(单机 Docker)
- 运维成本低
- 可扩展至约 1 亿向量规模(视硬件而定)
适合:
- 初创业务
- 早期线上系统
- 中等规模搜索服务
当业务快速增长,数据规模超过单机能力时,应选择:
Milvus Distributed
该模式基于 Kubernetes 的云原生架构。
适用于:
- 数亿到数百亿级向量数据
- 高并发搜索系统
- 企业级 AI 检索服务
Milvus Distributed 支持:
- 计算与存储分离
- 读写分离(Search / Ingestion)
- 节点独立扩展
- 高可用与冗余机制
同时可以根据业务特点灵活调优,例如:
- 高读低写场景
- 高写低读场景
对于一些隐私敏感或离线场景,可以直接在设备本地部署:
Milvus Lite
例如:
- 本地文档搜索
- 设备端图像检索
- 私有数据处理
无需依赖云服务即可完成向量搜索。
总体选择建议,可以用数据规模做一个简单划分:
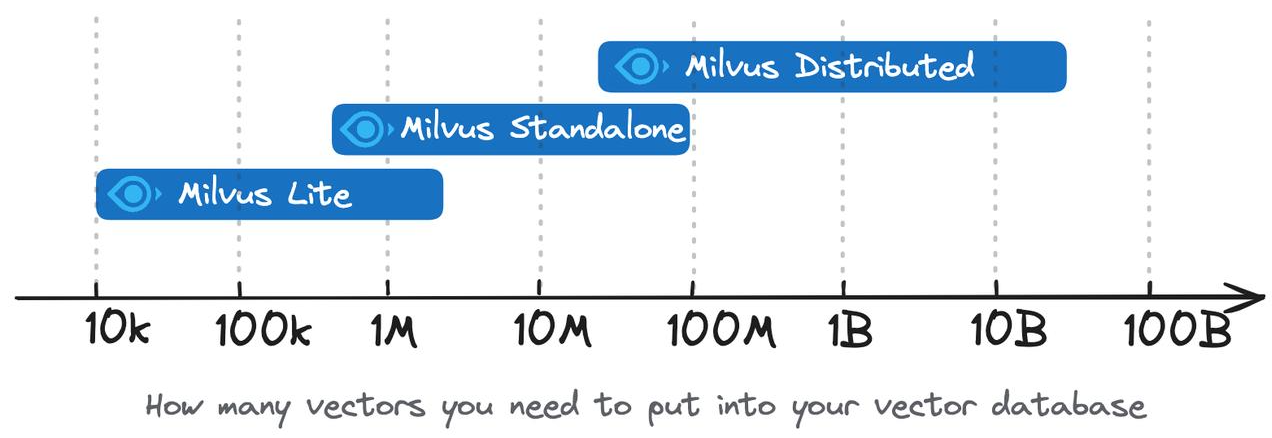
- Milvus Lite:适合百万级以内数据 + 学习 / Demo
- Milvus Standalone:适合千万到上亿级数据 + 中小生产
- Milvus Distributed:适合上亿到百亿级数据 + 企业级系统
部署Milvus Lite
它已经包含在 Milvus 的 Python SDK(PyMilvus)中,只需通过 pip 安装即可使用:
bash
pip install pymilvusMilvus Lite 当前支持以下操作系统环境:
- Ubuntu ≥ 20.04(x86_64 / arm64)
- macOS ≥ 11.0(Apple Silicon M1/M2 / x86_64)
部署Standalone
在安装 Milvus Standalone 实例之前,需要先检查你的硬件与软件环境是否满足要求。
硬件要求(Hardware Requirements)
| 组件 | 要求 | 推荐配置 | 说明 |
|---|---|---|---|
| CPU | Intel 第2代 Core 或更高 / Apple Silicon | Standalone:≥4核;Cluster:≥8核 | --- |
| CPU 指令集 | SSE4.2 / AVX / AVX2 / AVX-512 | 同左 | Milvus 的向量检索与索引构建依赖 SIMD 指令集,CPU 至少需要支持其中一种。 |
| 内存(RAM) | Standalone:8GB / Cluster:32GB | Standalone:16GB / Cluster:128GB | 取决于数据规模 |
| 硬盘 | SATA 3.0 SSD 或以上 | NVMe SSD 或以上 | 取决于数据量 |
Milvus 的向量相似度搜索和索引构建高度依赖:
SIMD(Single Instruction Multiple Data)指令集
因此 CPU 至少需要支持以下之一:
- SSE4.2
- AVX
- AVX2
- AVX-512
软件要求(Software Requirements)
| 操作系统 | 依赖软件 | 说明 |
|---|---|---|
| macOS ≥ 10.14 | Docker Desktop | Docker VM 至少分配 2 vCPU + 8GB 内存,否则可能安装失败 |
| Linux | Docker ≥ 19.03 + Docker Compose ≥ 1.25.1 | --- |
| Windows(启用 WSL2) | Docker Desktop | 建议将数据存放在 Linux 文件系统,而不是 Windows 文件系统 |
当使用 Docker 或 Docker Compose 安装 Milvus Standalone 时,以下依赖会自动安装和配置:
| 软件 | 版本 |
|---|---|
| etcd | 3.5.0 |
| MinIO | RELEASE.2024-12-18T13-15-44Z |
| Pulsar | 2.8.2 |
在 Docker 中运行 Milvus(Linux)
Milvus 提供了一个安装脚本,可以将 Milvus 作为 Docker 容器启动。
该脚本位于 Milvus 官方仓库中。
bash
curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed.sh启动 Docker 容器
bash
bash standalone_embed.sh start如果你需要在 Standalone 模式下使用 Backup:
建议使用 Docker Compose 部署方式
执行安装脚本后:
- 一个名为
milvus的 Docker 容器会启动 - 服务端口:19530
内置的ETCD:
- etcd 会与 Milvus 一起运行在同一容器中
- 端口:2379
- 配置文件:
embedEtcd.yaml
如需修改默认配置:
- 编辑
user.yaml - 然后重启服务
数据默认映射到:
./volumes/milvus你可以访问 WebUI:
http://127.0.0.1:9091/webui/用于查看当前 Milvus 实例状态与信息。
你可以通过修改 user.yaml 来覆盖默认配置。
例如修改健康检查超时时间:
bash
cat << EOF > user.yaml
Extra config to override default milvus.yaml
proxy:
healthCheckTimeout: 1000 # ms
EOF重启服务:
bash
bash standalone_embed.sh restart可以使用内置命令升级到最新版本:
bash
bash standalone_embed.sh upgrade升级命令会自动执行:
- 下载最新安装脚本与配置
- 拉取最新 Docker 镜像
- 重启容器
- 保留已有数据与配置
使用该命令是官方推荐的升级方式
停止服务:
bash
bash standalone_embed.sh stop删除数据:
bash
bash standalone_embed.sh delete使用 Docker Compose 运行 Milvus(Linux)
Milvus 在官方仓库中提供了 Docker Compose 配置文件。
使用 Docker Compose 启动 Milvus 的步骤如下。
bash
wget https://github.com/milvus-io/milvus/releases/download/v2.6.17/milvus-standalone-docker-compose.yml -O docker-compose.yml启动 Milvus
bash
sudo docker compose up -d执行后会看到:
Creating milvus-etcd ... done
Creating milvus-minio ... done
Creating milvus-standalone ... done如果命令执行失败,请检查是否使用了:
- Docker Compose V1
建议升级到:
- Docker Compose V2
各组件说明:
-
etcd(milvus-etcd)
- 不对外暴露端口
- 数据映射路径:
volumes/etcd
-
MinIO(milvus-minio)
- 本地端口:9090 / 9091
- 使用默认认证信息
- 数据路径:
volumes/minio
-
Milvus 主服务(milvus-standalone)
- 端口:19530
- WebUI:9091
- 数据路径:
volumes/milvus
检查运行状态
bash
sudo docker-compose ps示例输出:
Name Command State Ports
--------------------------------------------------------------------------------
milvus-etcd etcd ... Up 2379/tcp
milvus-minio docker-entrypoint ... Up (healthy) 9000/tcp
milvus-standalone milvus run standalone Up 19530, 9091你可以访问:
http://127.0.0.1:9091/webui/用于查看 Milvus 实例的运行状态。
如需修改默认配置,可以编辑容器内的:
/milvus/configs/user.yaml进入容器
bash
docker exec -it milvus-standalone bash修改配置示例
bash
cat << EOF > /milvus/configs/user.yaml
Extra config to override default milvus.yaml
proxy:
healthCheckTimeout: 1000
EOF重启生效
bash
docker restart milvus-standalone停止服务
bash
sudo docker compose down删除数据
bash
sudo rm -rf volumes部署Distributed
| 组件 | 要求 | 推荐配置 | 说明 |
|---|---|---|---|
| CPU | Intel 第2代 Core 或更高 / Apple Silicon | Standalone:≥4核;Cluster:≥8核 | --- |
| CPU 指令集 | SSE4.2 / AVX / AVX2 / AVX-512 | 同左 | Milvus 的向量相似度检索与索引构建依赖 SIMD 指令集,CPU 至少需要支持其中一种 |
| 内存(RAM) | Standalone:8GB / Cluster:32GB | Standalone:16GB / Cluster:128GB | 取决于数据规模 |
| 硬盘 | SATA 3.0 SSD 或云存储 | NVMe SSD 或更高 | 取决于数据量 |
建议在 Linux 系统上运行 Kubernetes 集群。
软件依赖列表:
| 操作系统 | 软件 |
|---|---|
| Linux | Kubernetes ≥ 1.16 |
| Linux | kubectl |
| Linux | Helm ≥ 3.0.0 |
| Linux(本地) | minikube |
| Linux(本地) | Docker ≥ 19.03 |
首先添加 Helm 仓库:
bash
helm repo add zilliztech https://zilliztech.github.io/milvus-helm/更新仓库
bash
helm repo update如果你只需要开发或测试,可以使用 Standalone:
bash
helm install my-release zilliztech/milvus \
--set image.all.tag=v2.6.17 \
--set cluster.enabled=false \
--set pulsarv3.enabled=false \
--set standalone.messageQueue=woodpecker \
--set woodpecker.enabled=true \
--set streaming.enabled=true集群模式部署(Cluster Mode)推荐用于生产环境:
bash
helm install my-release zilliztech/milvus \
--set image.all.tag=v2.6.17 \
--set pulsarv3.enabled=false \
--set woodpecker.enabled=true \
--set streaming.enabled=true \
--set indexNode.enabled=false该命令做了什么?
- 使用 Woodpecker 替代 Pulsar(更低维护成本)
- 启用 Streaming Node(性能优化)
- 禁用 Index Node(已由 Data Node 统一处理)
- 使用优化后的 v2.6.17 架构
如果仍想使用传统 Pulsar:
bash
helm install my-release zilliztech/milvus \
--set image.all.tag=v2.6.17 \
--set streaming.enabled=true \
--set indexNode.enabled=false安装完成后建议:
- 使用 Milvus Sizing Tool 优化资源配置
- 查看系统配置清单进行高级调优
如果遇到 PodDisruptionBudget 问题,可以使用:
bash
helm install my-release zilliztech/milvus \
--set pulsar.bookkeeper.pdb.usePolicy=false \
--set pulsar.broker.pdb.usePolicy=false \
--set pulsar.proxy.pdb.usePolicy=false \
--set pulsar.zookeeper.pdb.usePolicy=false通过检查 Pod 状态来验证部署是否成功:
bash
kubectl get pods在 v2.6.17 配置下,你应该看到类似如下的 Pod 列表:
text
NAME READY STATUS RESTARTS AGE
my-release-etcd-0 1/1 Running 0 3m23s
my-release-etcd-1 1/1 Running 0 3m23s
my-release-etcd-2 1/1 Running 0 3m23s
my-release-milvus-datanode-68cb87dcbd-4khpm 1/1 Running 0 3m23s
my-release-milvus-mixcoord-7fb9488465-dmbbj 1/1 Running 0 3m23s
my-release-milvus-proxy-6bd7f5587-ds2xv 1/1 Running 0 3m24s
my-release-milvus-querynode-5cd8fff495-k6gtg 1/1 Running 0 3m24s
my-release-milvus-streaming-node-xxxxxxxxx 1/1 Running 0 3m24s
my-release-minio-0 1/1 Running 0 3m23s
my-release-minio-1 1/1 Running 0 3m23s
my-release-minio-2 1/1 Running 0 3m23s
my-release-minio-3 1/1 Running 0 3m23s
my-release-pulsar-autorecovery-86f5dbdf77-lchpc 1/1 Running 0 3m24s
my-release-pulsar-bookkeeper-0 1/1 Running 0 3m23s
my-release-pulsar-bookkeeper-1 1/1 Running 0 98s
my-release-pulsar-broker-556ff89d4c-2m29m 1/1 Running 0 3m23s
my-release-pulsar-proxy-6fbd75db75-nhg4v 1/1 Running 0 3m23s
my-release-pulsar-zookeeper-0 1/1 Running 0 3m23s
my-release-pulsar-zookeeper-metadata-98zbr 0/1 Completed 0 3m24s在完成端口转发后,可以访问:
http://127.0.0.1:9091/webui/要从 Kubernetes 外部访问集群,需要进行端口转发(port-forward)。(话说官方helm不写一行svc配置是因为担心端口冲突,还是太懒了)
设置端口转发
bash
kubectl port-forward service/my-release-milvus 27017:19530连接信息
- 本地连接地址:
localhost:27017 - Milvus 默认端口:
19530
你可以通过修改 values.yaml 并重新应用 Helm 来更新 Milvus 集群配置。
创建一个包含目标配置的 values.yaml 文件。
例如,开启 proxy.http:
yaml
extraConfigFiles:
user.yaml: |+
proxy:
http:
enabled: true应用配置更新
bash
helm upgrade my-release zilliztech/milvus --namespace my-namespace -f values.yaml查看更新结果
bash
helm get values my-release输出中应包含刚刚更新的配置。
启用 WebUI 访问需要将 proxy Pod 端口转发到本地:
bash
kubectl port-forward --address 0.0.0.0 service/my-release-milvus 27018:9091访问地址
http://localhost:27018如果你的环境无法联网,可以使用以下流程部署 Milvus 集群。
获取 Kubernetes Manifest
bash
helm template my-release zilliztech/milvus > milvus_manifest.yaml说明
该命令会:
- 渲染 Helm chart
- 生成 Kubernetes manifest 文件
- 输出到
milvus_manifest.yaml
默认模式说明
该 manifest 会:
- 每个组件独立 Pod(集群模式)
如果要部署单机版:
bash
helm template my-release \
--set cluster.enabled=false \
--set etcd.replicaCount=1 \
--set minio.mode=standalone \
--set pulsarv3.enabled=false \
zilliztech/milvus > milvus_manifest.yaml也可以使用 values.yaml:
bash
helm template -f values.yaml my-release zilliztech/milvus > milvus_manifest.yaml下载镜像拉取脚本
bash
wget https://raw.githubusercontent.com/milvus-io/milvus/master/deployments/offline/requirements.txt
wget https://raw.githubusercontent.com/milvus-io/milvus/master/deployments/offline/save_image.py拉取并保存镜像
bash
pip3 install -r requirements.txt
python3 save_image.py --manifest milvus_manifest.yaml镜像会保存到当前目录的:
images/在离线环境加载镜像
bash
for image in $(find . -type f -name "*.tar.gz") ; do
gunzip -c $image | docker load;
done部署 Milvus
bash
kubectl apply -f milvus_manifest.yaml升级运行中的 Milvus 集群
bash
helm repo update
helm upgrade my-release zilliztech/milvus --reset-then-reuse-values卸载 Milvus
bash
helm uninstall my-release不同部署方式下的功能对比
Milvus 在不同部署模式下的功能支持对比如下:
客户端 / SDK 支持(SDK / Client Library)
| 功能 | Milvus Lite | Milvus Standalone | Milvus Distributed |
|---|---|---|---|
| 客户端支持 | Python / gRPC | Python / Go / Java / Node.js / C# / RESTful | Python / Go / Java / Node.js / C# / RESTful |
数据类型支持(Data Types)
三种部署模式均支持以下数据类型:
- Dense Vector(稠密向量)
- Sparse Vector(稀疏向量)
- Binary Vector(二进制向量)
- Boolean(布尔)
- Integer(整数)
- Floating Point(浮点数)
- VarChar(字符串)
- Array(数组)
- JSON
搜索能力(Search Capabilities)
三种模式均支持完整的向量与混合检索能力:
- Vector Search(ANN 搜索)
- Metadata Filtering(元数据过滤)
- Range Search(范围搜索)
- Scalar Query(标量查询)
- 主键查询(Get Entities by Primary Key)
- Hybrid Search(混合搜索)
CRUD 操作
- Milvus Lite:✔️
- Milvus Standalone:✔️
- Milvus Distributed:✔️
所有部署模式均支持完整的增删改查能力。
高级数据管理能力(Advanced Data Management)
| 功能 | Milvus Lite | Milvus Standalone | Milvus Distributed |
|---|---|---|---|
| 访问控制(Access Control) | N/A | ✔️ | ✔️ |
| 分区(Partition) | N/A | ✔️ | ✔️ |
| 分区键(Partition Key) | N/A | ✔️ | ✔️ |
| 物理资源分组 | N/A | ❌ | ✔️ |
一致性级别(Consistency Levels)
| 模式 | 支持情况 |
|---|---|
| Milvus Lite | Strong(强一致性) |
| Milvus Standalone | Strong / Bounded Staleness / Session / Eventual |
| Milvus Distributed | Strong / Bounded Staleness / Session / Eventual |
度量类型
相似度度量(Similarity Metrics)用于衡量向量之间的相似程度。选择合适的距离度量可以显著提升分类与聚类效果。
目前 Milvus 支持以下相似度度量类型:
- 欧几里得距离(L2)
- 内积(IP)
- 余弦相似度(COSINE)
- JACCARD
- HAMMING
- BM25(专用于稀疏向量的全文检索)
下表总结了不同字段类型与支持的度量方式:
| 字段类型 | 维度范围 | 支持的 Metric Types | 默认 Metric |
|---|---|---|---|
| FLOAT_VECTOR | 2--32,768 | COSINE, L2, IP | COSINE |
| FLOAT16_VECTOR | 2--32,768 | COSINE, L2, IP | COSINE |
| BFLOAT16_VECTOR | 2--32,768 | COSINE, L2, IP | COSINE |
| INT8_VECTOR | 2--32,768 | COSINE, L2, IP | COSINE |
| SPARSE_FLOAT_VECTOR | 无需指定维度 | IP, BM25(仅用于全文检索) | IP |
| BINARY_VECTOR | 8--32,768×8 | HAMMING, JACCARD, MHJACCARD | HAMMING |
-
对于
SPARSE_FLOAT_VECTOR:- 只有在全文检索(Full Text Search)场景下才使用 BM25
-
对于
BINARY_VECTOR:- dim 必须是 8 的倍数
各 Metric 的特性与取值范围:
| Metric | 含义 | 相似度趋势 | 取值范围 |
|---|---|---|---|
| L2 | 欧氏距离 | 越小越相似 | [0, ∞) |
| IP | 内积 | 越大越相似 | -1, 1 |
| COSINE | 余弦相似度 | 越大越相似 | -1, 1 |
| JACCARD | 集合相似度 | 越小越相似 | 0, 1 |
| MHJACCARD | MinHash 估计 Jaccard | 越小越相似 | 0, 1 |
| HAMMING | 汉明距离 | 越小越相似 | 0, dim |
| BM25 | 基于词频/逆文档频率/归一化的相关性评分 | 越大越相关 | [0, ∞) |
在 Array of Structs 字段 中对向量进行索引时,需要在上述 Metric 类型前加前缀 MAX_SIM。
-
浮点/混合向量类型
适用于:
- FLOAT_VECTOR
- FLOAT16_VECTOR
- BFLOAT16_VECTOR
- INT8_VECTOR
可使用:
- MAX_SIM_COSINE
- MAX_SIM_IP
- MAX_SIM_L2
-
二进制向量类型
适用于:
- BINARY_VECTOR
可使用:
- MAX_SIM_JACCARD
- MAX_SIM_HAMMING
欧几里得距离(L2)
本质上,欧几里得距离用于衡量连接两个点之间线段的长度。
其计算公式如下:
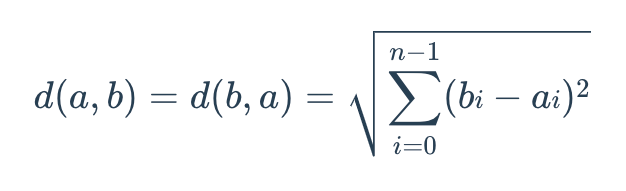
其中:
- a = (a0, a1,..., an-1)
- b = (b0, b1,..., bn-1)
表示 n 维欧几里得空间中的两个点。
欧几里得距离是最常用的距离度量之一,特别适用于连续型数据。
在 Milvus 中:
当选择 Euclidean distance(L2)作为度量方式时,系统只计算平方和部分(即开方之前的值)。
注解
在二维空间中,它就是我们熟悉的勾股定理;在高维向量空间(embedding)中,它只是扩展到了 n 维。
先看二维空间的情况,假设有两个点:
- A = (x₁, y₁)
- B = (x₂, y₂)
我们要算它们之间的直线距离。
你可以把 A → B 的移动拆成两步:
- 水平方向移动:Δx = x₂ - x₁
- 垂直方向移动:Δy = y₂ - y₁
这会形成一个直角三角形:
A •
|\
| \
| \
| \
| • B
|这个三角形满足:
- 直角边:Δx 和 Δy
- 斜边:A 到 B 的距离
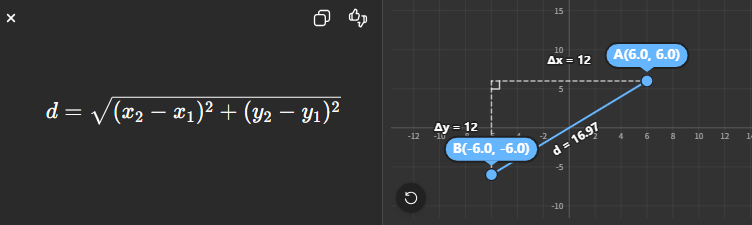
这就是标准的勾股定理形式:
斜边² = 两直角边²之和
同理,你可以把 embedding 看成一个点:
- A = 一段文本(比如"人工智能")
- B = 另一段文本(比如"机器学习")
模型把它们变成坐标点:
A = (1, 2)
B = (4, 6)那么欧几里得距离就是:
A 和 B 在平面上的"直线距离"
假设两个 3 维向量(两个一维张量):
A = (1, 2, 3)
B = (4, 6, 8)计算步骤:
- 差值:(-3, -4, -5)
- 平方: (9, 16, 25)
- 求和:50
- 开方:√50 ≈ 7.07
👉 距离 = 7.07
欧几里得距离有一个非常直观的含义:
| 距离 | 含义 |
|---|---|
| 0 | 完全相同(同一个向量) |
| 小 | 非常相似 |
| 大 | 差异很大 |
在 embedding 检索中:
距离越小 → 越相似
在 Milvus 中使用 L2 时有一个重要实现细节:
Milvus 默认不做开方计算
原因很简单:
- 开方不影响排序
- 但会增加计算成本
- 向量检索更关心"谁更近",不关心具体数值
L2 特别适合:
✔ 连续数值型数据
比如:
- 图像 embedding
- 音频特征
- 连续语义向量
✔ 不做归一化的 embedding
如果向量没有做 normalization:
- L2 可以同时反映"方向 + 长度差异"
和 Cosine 的核心区别
| 指标 | L2 | Cosine |
|---|---|---|
| 关注点 | 距离(绝对差异) | 方向(角度) |
| 是否受长度影响 | 是 | 否(归一化后) |
| 常见用途 | 图像 / 连续特征 | 文本 embedding |
内积(Inner Product,IP)
两个 embedding 的内积距离定义如下:
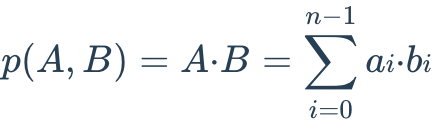
特点
- 当数据未归一化时,IP 更有意义
- 适用于同时关注"方向 + 大小"的场景
如果使用 IP 计算 embedding 相似度,必须先对向量进行归一化。
设 X' 是 X 的归一化结果:
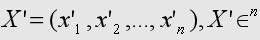
归一化后有如下关系:
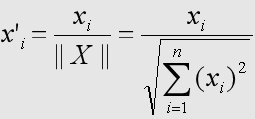
注解
内积(也叫点积)是向量相似度计算中非常重要的一种方式,它不仅关心"方向",也会受到"大小(模长)"的影响。
你可以这样理解两个向量:
- 向量 A:一个"箭头"
- 向量 B:另一个"箭头"
内积回答的问题是:
这两个箭头"有多同向 + 有多强"
✔ 三种典型情况
① 同方向(非常相似)
- 两个向量方向一致
- 数值也大
👉 内积 = 很大正数
② 垂直(完全无关)
- 方向 90°
- 没有重合部分
👉 内积 = 0
③ 反方向(完全相反)
- 一个向左,一个向右
👉 内积 = 负数
一个简单例子
id="ip_example"
A = (1, 2)
B = (3, 4)计算:
- 1×3 = 3
- 2×4 = 8
A · B = 3 + 8 = 11
👉 内积 = 11
内积"到底在衡量什么?"
内积其实可以拆成两个因素:
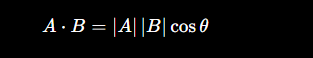
它同时包含:
- 向量长度(|A|, |B|)
- 夹角(cosθ)
所以,内积 =
"方向相似度" × "强度"
所以它有一个特点:✔ 向量越长,内积越大(即使方向一样)
这也是它和 cosine 最大区别之一。
为什么说 IP 适合"非归一化数据"?
因为:
-
如果数据本身就有"强度含义"
-
例如:
- 用户点击次数
- 文档权重
- TF-IDF 向量
👉 那么"长度"本身就是信息
IP vs Cosine(核心对比)
| 项目 | IP(内积) | Cosine |
|---|---|---|
| 是否考虑长度 | ✔ 是 | ✖ 否(归一化) |
| 是否考虑方向 | ✔ 是 | ✔ 是 |
| 是否适合 embedding | 取决于是否归一化 | 更稳定 |
| 是否容易被长度影响 | 是 | 否 |
如果向量做了归一化:
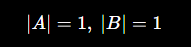
那么:

👉 结论:
归一化后:内积 = 余弦相似度
在 Milvus 中使用 IP 时:
-
返回的是"越大越相似"
-
不做归一化时:
- 长向量会天然占优势
常见误区
❌ 误区1:IP 就是 cosine
错的,只有在归一化之后才等价
❌ 误区2:IP 越大一定越相似
不一定:
- 可能只是向量"更长"
- 而不是更相关
余弦相似度(Cosine Similarity)
余弦相似度用于衡量两个向量之间夹角的余弦值,从而表示它们的相似程度。
可以把两个向量看作从同一原点(如 0,0,...)出发的线段,但指向不同方向。
对两个向量:
- A = (a0, a1,..., an-1)
- B = (b0, b1,..., bn-1)
其计算公式如下:
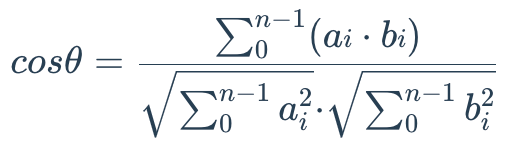
余弦相似度取值范围为:
-
-1, 1
典型情况:
- 相同方向(比例向量):1
- 正交(垂直):0
- 完全相反:-1
解释
- cosine 越大 → 夹角越小 → 越相似
- cosine 越小 → 夹角越大 → 越不相似
通过以下方式可以得到余弦距离:
cosine distance = 1 - cosine similarity
注解
余弦相似度(Cosine Similarity)是向量检索、Embedding 搜索、RAG、语义检索中最常用的相似度计算方式之一。
它关注的不是:
"两个向量距离多远"
而是:
"两个向量方向是否一致"
你可以把向量想象成:
从原点射出去的箭头
例如:
id="cosine_vec"
A ↗
B ↗余弦相似度不关心箭头长短,而只关心:
两个箭头之间的夹角
在 embedding 世界里:
- "方向"往往代表语义
- "长度"很多时候没有意义
例如:
id="cosine_text"
"人工智能"
"AI"
"机器学习"模型生成的 embedding:
- 方向接近 → 语义接近
- 方向不同 → 语义不同
因此:
embedding 检索更关注"方向相似"
而不是:
"谁的数值更大"
对两个向量:
- A = (a₀, a₁, ..., aₙ₋₁)
- B = (b₀, b₁, ..., bₙ₋₁)
余弦相似度定义如下:
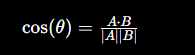
其中:
- A·B:向量内积
- |A|:向量长度(模长)
- θ:两个向量夹角
余弦相似度本质在做什么?
其实它是在:
"把长度影响消除后,再比较方向"
因为:
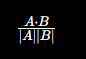
会把向量长度约掉。
余弦相似度范围:
-1,1
✔ 三种典型情况
| 夹角 | cosine 值 | 含义 |
|---|---|---|
| 0° | 1 | 完全同方向 |
| 90° | 0 | 无关 |
| 180° | -1 | 完全相反 |
一个非常直观的例子
假设:
id="cosine_ex1"
A = (1, 1)
B = (2, 2)虽然:
- B 更长
- 数值更大
但它们方向完全一致。
所以:
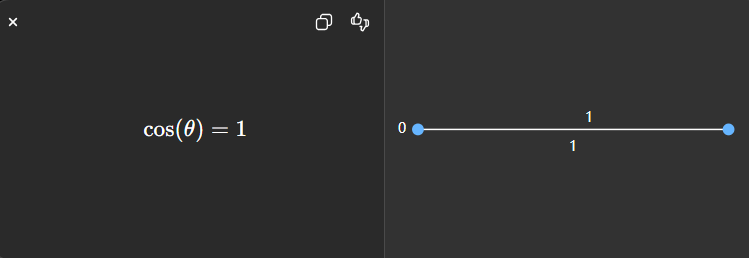
👉 完全相似
再看:
id="cosine_ex2"
A = (1, 0)
B = (0, 1)两个向量垂直:
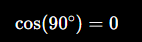
👉 完全无关
为什么 Cosine 特别适合 Embedding?
因为 embedding 模型训练时:
- 更关注"语义方向"
- 而不是向量绝对长度
所以:
✔ Cosine 可以消除长度噪声
例如:
id="noise_example"
"人工智能"
"人工智能!!!"两者长度可能不同:
- 但语义方向接近
- cosine 仍然很高
Cosine vs L2(核心区别)
| 指标 | Cosine | L2 |
|---|---|---|
| 关注点 | 方向 | 距离 |
| 是否受长度影响 | 否 | 是 |
| embedding 检索 | 非常常用 | 也常见 |
| 文本语义搜索 | 更主流 | 次之 |
Cosine vs IP(重点)
很多人会混淆:
- Cosine Similarity
- Inner Product(IP)
它们关系非常密切。
✔ 未归一化时
IP:
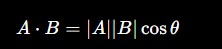
它同时受到:
- 长度
- 方向
影响。
✔ 归一化后
如果:
|A|=|B|=1
那么:
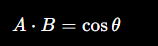
👉 此时:
内积 = 余弦相似度
在 Milvus 中:
- cosine 越大
- 表示向量越相似
通常:
- embedding 检索
- RAG
- 文本语义搜索
默认都会优先考虑:
COSINE
向量一定是"从原点出发的箭头"吗?
答案是:
在数学和机器学习里,通常可以这样理解。
但这里有一个容易混淆的点:
向量本质上表示:
"方向 + 大小"
例如:
id="vec1"
(3, 4)它表示:
- 向右 3
- 向上 4
为什么大家都从原点开始画?
因为:
向量本身不关心"起点"
只关心:
- 方向
- 长度
所以数学里通常默认:
把它平移到原点开始画
这样最方便分析。
举个例子,这两个其实是同一个向量:
id="same_vec"
A点 -> B点:向右3、向上4
C点 -> D点:向右3、向上4虽然位置不同:
- 但方向一样
- 长度一样
所以:
它们是同一个向量
为什么 embedding 也这样理解?
因为 embedding 本质上也是:
id="embed_vec"
[0.12, -0.33, 0.98, ...]它只是:
高维空间中的一个方向
所以我们会把 embedding:
- 看成从原点射出的箭头
- 用方向表示语义
在 embedding 空间里:
"方向相近" ≈ "语义相近"
例如:
id="semantics"
"猫"
"狗"
"宠物"它们在高维空间中:
- 方向可能接近
- 夹角较小
所以 cosine 相似度高。
什么是"归一化(Normalization)"?
这个概念在向量数据库和 embedding 里极其重要。
本质上:
归一化 = 把向量长度变成 1
但保留方向不变。
因为很多时候:
我们只关心方向,不关心长度。
例如:
id="normalize_ex1"
A = (1,1)
B = (100,100)它们:
- 长度差巨大
- 但方向完全一样
语义上可能也完全一致。
所以:
我们想消除"长度影响"
只保留:
- 方向信息
向量归一化公式:
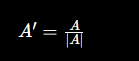
意思是:
用向量每个元素除以自己的长度
一个简单例子
原始向量:
id="normalize_ex2"
A = (3,4)它长度:
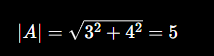
归一化后:
id="normalize_ex3"
A' = (3/5, 4/5)
= (0.6, 0.8)JACCARD 距离(JACCARD distance)
JACCARD 距离系数用于衡量两个集合之间的相似性,定义为:
两个集合交集的元素数量 ÷ 两个集合并集的元素数量
它只适用于有限集合(finite sample sets)。
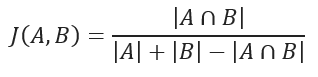
JACCARD 距离用于衡量数据集之间的"不相似度",计算方式为:
1 - JACCARD 相似度系数
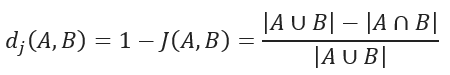
对于二进制变量(binary variables),JACCARD 距离等价于 Tanimoto 系数。
注解
前面的 L2、IP、Cosine 更多是在比较:
"两个数值向量有多接近"
而 JACCARD 不太一样。
它更关注:
"两个集合里,有多少内容是重复的"
因此:
-
JACCARD 更适合:
- 标签(tags)
- 关键词集合
- 用户兴趣集合
- 文档词集合
- 推荐系统
-
不太适合:
- embedding 浮点向量
假设:
用户 A 喜欢:
text
{电影, 游戏, 音乐, AI}用户 B 喜欢:
text
{游戏, AI, 编程}交集(共同部分)
text
{游戏, AI}数量:
text
2并集(所有不同元素)
text
{电影, 游戏, 音乐, AI, 编程}数量:
text
5因此,JACCARD 相似度
计算公式:
text
交集数量 ÷ 并集数量即:
text
2 / 5 = 0.4说明:
两个集合有 40% 的相似性。
Milvus 中使用的是:JACCARD Distance(距离)
它的定义:
text
1 - JACCARD Similarity因此:
text
1 - 0.4 = 0.6也就是说:
- 越接近 0 → 越相似
- 越接近 1 → 越不相似
为什么它特别适合"标签类数据"?
因为它不关心:
- 顺序
- 次数
- 数值大小
它只关心:
"有没有"
例如:
text
用户A:
{篮球, 足球, LOL}
用户B:
{LOL, 原神, 篮球}它只会统计:
- 共同标签
- 总标签数
而不会关心:
- 篮球排第几个
- LOL出现多少次
二维图解理解
假设:
text
A = {1,2,3,4}
B = {3,4,5,6}可以理解成:
text
A: ████
B: ████重叠部分:
text
{3,4}共同元素:
text
2 个总元素:
text
6 个所以:
text
JACCARD Similarity = 2 / 6 = 0.333JACCARD 和 Cosine 的核心区别
| 对比项 | JACCARD | Cosine |
|---|---|---|
| 比较对象 | 集合 | 向量 |
| 是否关心数值大小 | ❌ 不关心 | ✅ 关心 |
| 是否关心方向 | ❌ 不关心 | ✅ 关心 |
| 是否适合 embedding | ❌ | ✅ |
| 是否适合标签集合 | ✅ | 一般 |
| 本质 | 集合重叠率 | 向量夹角 |
实际业务案例:
-
推荐系统
例如:
用户 A 买过:
text{手机, 键盘, 鼠标}用户 B 买过:
text{键盘, 鼠标, 显示器}JACCARD 可以衡量:
两个用户消费兴趣是否相似
-
标签系统
例如:
文章标签:
text{AI, 大模型, RAG}另一篇:
text{AI, 向量数据库, Milvus}可以判断:
两篇文章主题是否接近
-
搜索去重
例如:
text网页A关键词集合 网页B关键词集合JACCARD 可以判断:
是否为重复网页
在 Milvus 中JACCARD 通常用于:
text
BINARY_VECTOR也就是:
二进制向量
例如:
text
101010101这种场景通常不是 embedding。
而是:
- 布尔特征
- 标签编码
- 哈希签名
- 布隆过滤器
- MinHash
为什么 JACCARD 不适合 embedding?
因为 embedding 里:
text
[0.123, -0.551, 0.991 ...]重点是:
- 数值大小
- 空间方向
- 语义距离
而 JACCARD 只会看:
text
有没有会丢失大量信息。
因此embedding 检索一般使用:
- COSINE
- IP
- L2
而不是 JACCARD。
MHJACCARD(MinHash Jaccard)
MinHash Jaccard(MHJACCARD)是一种用于大规模集合的高效近似相似度检索方法,例如:
- 文档词集合
- 用户标签集合
- 基因 k-mer 集合
MHJACCARD 不直接比较原始集合,而是比较:
MinHash 签名(MinHash signatures)
这些签名是集合的压缩表示,用于高效估计 JACCARD 相似度。
相比精确 JACCARD 计算:
- 速度更快
- 更适合大规模 / 高维数据
适用向量类型:
- BINARY_VECTOR
每个向量存储一个 MinHash signature:
- 每个维度对应一个独立哈希函数的最小哈希值
MHJACCARD 通过比较两个 MinHash signature:
统计相同位置的匹配比例
匹配越多 → 集合越相似
在 Milvus 中的定义
系统返回的是:
Distance = 1 - 估计相似度(匹配比例)
取值范围
- 0:完全相同(JACCARD 相似度 = 1)
- 1:完全不匹配(JACCARD 相似度 = 0)
注解
如果说 JACCARD 已经是在比较:
"两个集合有多少重叠"
那么 MHJACCARD 解决的是另一个更现实的问题:
当集合变得非常大时,怎么"快速近似"计算 JACCARD?
假设你有两个集合:
text
A = {100万个词}
B = {100万个词}如果直接算 JACCARD:
text
需要逐个做交集 + 并集复杂度很高。
在大规模场景(比如:
- 海量文档
- 搜索引擎
- 推荐系统
- 去重系统
)里:
精确 JACCARD 会变得太慢
MHJACCARD =
MinHash + JACCARD 的近似计算方法
核心思想:
不直接比较"完整集合",而是比较"压缩后的指纹"
我们可以把一个集合想象成:
text
{a, b, c, d, e, f, g, h, i}MinHash 做的事情是:
用多个哈希函数,把集合压缩成一个"签名(signature)"
例如:
text
Hash1 → 取最小值 → 5
Hash2 → 取最小值 → 9
Hash3 → 取最小值 → 2
...最终得到:
text
MinHash signature = [5, 9, 2, 7, 1, ...]MinHash 有一个非常重要的性质:
两个集合的 JACCARD 相似度 ≈ 它们 MinHash 签名的"匹配比例"
举个例子:
text
A signature: [1, 3, 5, 7, 9]
B signature: [1, 2, 5, 8, 9]对比:
| 位置 | A | B | 是否相同 |
|---|---|---|---|
| 1 | 1 | 1 | ✔ |
| 2 | 3 | 2 | ✘ |
| 3 | 5 | 5 | ✔ |
| 4 | 7 | 8 | ✘ |
| 5 | 9 | 9 | ✔ |
匹配比例:
text
3 / 5 = 0.6在 Milvus 中:
text
Distance = 1 - (MinHash匹配率)也就是说:
| 情况 | 含义 |
|---|---|
| 0 | 完全相同 |
| 0.3 | 很相似 |
| 1 | 完全不相似 |
MHJACCARD 非常适合:
-
海量文本去重
text网页A vs 网页B判断是否重复网页。
-
文档相似度
text新闻A vs 新闻B快速判断是否"同一事件"。
-
标签集合相似
text用户兴趣标签集合 -
超大规模搜索预过滤
在正式 embedding 检索前:
先用 MHJACCARD 做"粗筛"
HAMMING 距离
HAMMING 距离用于衡量两个等长二进制字符串之间的差异:
不同 bit 位的数量
示例
11011001
10011101异或结果:
01000100其中有 2 个 1,因此:
HAMMING distance = 2
注解
如果前面的 JACCARD 和 MHJACCARD 是在处理"集合是否相似",那么 HAMMING 距离处理的是另一类问题:
两个等长"二进制字符串",有多少个位置不一样
HAMMING 距离只关心一件事:
同一位置上,是不是"完全一致"
它不关心:
- 数值大小
- 相似程度
- 语义关系
只关心:
0 / 1 有没有对上
假设有两个二进制字符串:
text
A = 11011001
B = 10011101我们逐位对比:
| 位置 | A | B | 是否相同 |
|---|---|---|---|
| 1 | 1 | 1 | ✔ |
| 2 | 1 | 0 | ✘ |
| 3 | 0 | 0 | ✔ |
| 4 | 1 | 1 | ✔ |
| 5 | 1 | 1 | ✔ |
| 6 | 0 | 1 | ✘ |
| 7 | 0 | 0 | ✔ |
| 8 | 1 | 1 | ✔ |
不同的位置有:
text
第2位、第6位 → 共 2 个所以:
text
HAMMING distance = 2你可以把它想象成:
两条"完全对齐的字符串赛道"
每一位都是一个开关:
text
A: 1 1 0 1 1 0 0 1
B: 1 0 0 1 1 1 0 1HAMMING 距离就是:
"开关不一致的数量"
HAMMING 距离的特点
-
必须等长
textA: 10101 B: 110 ❌ 无法比较因为没有"对齐的位"。
-
只适用于离散/二进制数据
典型数据:
- 0/1 特征
- hash code
- 位向量(bit vector)
- 编码后的标签
-
不适用于 embedding
比如:
text[0.12, -0.55, 0.98]这种连续值不能用 HAMMING。
HAMMING 距离 vs 其他距离
| 类型 | 比较对象 | 核心思想 |
|---|---|---|
| L2 | 浮点向量 | 空间距离 |
| Cosine | 向量角度 | 方向相似 |
| JACCARD | 集合 | 重叠比例 |
| MHJACCARD | 集合(近似) | 指纹匹配 |
| HAMMING | 二进制串 | 位不同数量 |
BM25 相似度
BM25 是一种广泛使用的文本相关性评分方法,专用于全文检索。
它结合以下三个核心因素:
-
词频(TF)
- 表示词在文档中出现的频率
- 频率越高通常越重要
- 但通过参数 k1 控制"饱和效应",防止过度影响
-
逆文档频率(IDF)
- 衡量词在语料库中的稀有程度
- 出现文档越少 → 权重越高
-
文档长度归一化
- 长文档通常更容易得分更高
- BM25 使用参数 b 进行长度惩罚
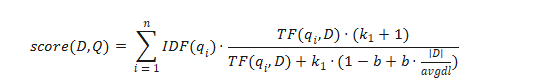
参数说明
- Q:查询文本
- D:文档
- TF(qi, D):词 qi 在文档 D 中出现次数
- IDF(qi):逆文档频率:
其中:
- N:语料库总文档数
- n(qi):包含词 qi 的文档数
其他参数
- |D|:文档长度
- avgdl:平均文档长度
k1 参数
- 控制词频影响
- 推荐范围:1.2 ~ 2.0
- Milvus 支持范围:0 ~ 3
b 参数
-
控制长度归一化强度
-
取值范围:0 ~ 1
- 0:不做归一化
- 1:完全归一化
注解
前面的 L2、Cosine、JACCARD、HAMMING,本质上都在解决:
"向量/集合之间怎么比较相似"
而 BM25 完全是另一条路线:
专门为"文本检索"设计的相关性评分函数
假设你在做搜索:
text
query = "AI search system"有两个文档:
text
D1: AI is widely used in search systems
D2: Artificial intelligence models are powerful问题是:
哪个文档更"相关"?
BM25 做的事情不是算距离,而是:
给每个文档打一个"相关性分数"
BM25 基于三个直觉:
-
词越多 → 越重要(TF)
如果一个词在文档里出现很多次:
text"AI AI AI AI AI"说明:
这个词对这个文档很重要
但 BM25 会做"抑制":
不会无限增长(防止刷词)
-
稀有词更重要(IDF)
比如:
词 出现情况 重要性 the 几乎所有文档 ❌ 不重要 transformer 少量文档 ✅ 很重要 所以:
越"稀有"的词权重越高
-
长文档要惩罚(长度归一化)
如果:
textD1: 10万字论文 D2: 100字短句长文档天然"更容易包含关键词",所以:
必须做归一化
否则会偏向长文本
可以把 BM25 理解为:
对每个 query 词,在文档里做一次"加权打分"
最终:
text
score(D, Q) = 所有 query 词贡献的总和一个非常直观的例子:
Query:
text
"AI search"文档 D1:
text
AI search system is widely used文档 D2:
text
AI models are powerfulD1:
- AI:出现
- search:出现
👉 两个关键词都命中
D2:
- AI:出现
- search:没出现
👉 命中更少
所以:
text
BM25(D1) > BM25(D2)BM25 和向量检索的区别(重点)
| 对比项 | BM25 | 向量检索(Cosine/L2) |
|---|---|---|
| 数据对象 | 文本 | embedding |
| 本质 | 关键词匹配 | 语义匹配 |
| 是否理解语义 | ❌ 不理解 | ✅ 理解 |
| 是否精确词匹配 | ✅ 必须匹配 | ❌ 不需要 |
| 适用场景 | 搜索引擎 | RAG / AI检索 |
BM25 本质是:
"词级别的加权匹配模型"
而 embedding 是:
"语义空间的距离模型"
在 Milvus 里:
text
BM25 = sparse vector search 的核心 metric它特别适合:
- 全文检索
- 关键词搜索
- RAG 中的 hybrid search(混合检索)
数据库(Database)
Milvus 在 Collection 之上引入了一个 数据库(Database)层,用于更高效地管理和组织数据,并支持多租户(multi-tenancy)能力。
在 Milvus 中:
Database 是用于组织和管理数据的逻辑隔离单元
你可以把它理解成:
比 collection 更高一层的"数据空间"
为什么需要 Database?
因为在多业务/多租户场景中:
- 用户 A 的数据
- 用户 B 的数据
- 不同项目的数据
如果都放在同一个空间里,会出现:
- 权限混乱
- 数据污染
- 管理困难
text
Database = 逻辑隔离层例如:
- database_A → 存用户 A 数据
- database_B → 存用户 B 数据
你可以通过 SDK 创建数据库:
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
client.create_database(
db_name="my_database_1"
)创建时还可以设置属性,比如副本数:
python
client.create_database(
db_name="my_database_2",
properties={
"database.replica.number": 3
}
)查看所有数据库:
python
client.list_databases()返回:
text
['default', 'my_database_1', 'my_database_2']查看数据库详情:
python
client.describe_database(
db_name="default"
)返回:
text
{"name": "default"}Milvus 支持给 database 配置一些"管理级参数"。
常见属性说明:
| 属性 | 类型 | 含义 |
|---|---|---|
| database.replica.number | integer | 数据库副本数 |
| database.resource_groups | string | 资源组 |
| database.diskQuota.mb | integer | 磁盘上限(MB) |
| database.max.collections | integer | 最大 collection 数量 |
| database.force.deny.writing | boolean | 禁止写入 |
| database.force.deny.reading | boolean | 禁止读取 |
| timezone | string | 时区配置 |
timezone 特别说明:
例如:
text
Asia/Shanghai
America/Chicago
UTC它主要用于:
时间类型字段(TIMESTAMPTZ)
修改数据库属性:
例如限制 collection 数量:
python
client.alter_database_properties(
db_name="my_database_1",
properties={
"database.max.collections": 10
}
)作用:
控制一个 database 内最多只能创建 10 个 collection
删除数据库属性(恢复默认):
例如取消限制:
python
client.drop_database_properties(
db_name="my_database_1",
property_keys=[
"database.max.collections"
]
)切换数据库(use database):
你可以在不重新连接 Milvus 的情况下切换 database:
python
client.use_database(
db_name="my_database_2"
)⚠️ 注意:
- REST API 不支持这个操作
- 只能 SDK 使用
删除数据库:
python
client.drop_database(
db_name="my_database_2"
)但有两个限制:
-
默认数据库不能删除
textdefault ❌ 不可删除 -
必须先清空 collection
text必须先 drop 所有 collections
Collection 详解
在 Milvus 中,你可以创建多个 Collection(集合) 来管理数据,并将数据以 Entity(实体) 的形式插入到 Collection 中。
Collection 和 Entity 类似于关系型数据库中的:
Collection 是一个二维结构:
列固定,行可变
- 列 = Field(字段)
- 行 = Entity(实体)
可以这样理解:
text
Collection = 一张"结构固定的表"Schema 与 Field(结构与字段)
在描述一个对象时,我们通常会说它的属性,例如:
- 大小
- 重量
- 位置
在 Milvus 中,这些就是:
Field(字段)
每个字段都有约束,例如:
- 数据类型(int / string / vector)
- 向量维度(dimension)
Schema 是什么?
Schema 就是:
Collection 中所有 Field 的定义 + 顺序
text
id: int64
text: varchar
vector: float_vector(768)这三者组合起来就是 Schema。
插入数据时:
必须包含 Schema 中定义的字段
如果你希望某些字段"可以不填",可以:
- 启用 dynamic field(动态字段)
如果你希望某些字段允许为空(nullable)或者有默认值,可以设置Nullable & Default
Primary Key(主键)与 AutoId
类似关系型数据库的主键:
用于唯一标识一条数据
例如:
text
id = 0在整个 Collection 中必须唯一。
-
只能是:
- integer
- string
如果启用 AutoId:
Milvus 会自动生成主键
此时:
✔ 插入数据时不需要传 id
✔ 系统自动分配唯一 ID
Index(索引)
索引的作用:
提升查询和搜索效率
特别重要:
- 向量字段索引是必须的
- 没有索引 → 搜索会非常慢
Entity(实体)
Entity 是:
Collection 中的一条完整记录
例如一行数据:
text
id: 1
text: "hello milvus"
vector: [...]特点
- 所有字段组成一个 Entity
- 可以插入很多 Entity
- 数据越多 → 内存占用越高 → 搜索变慢
Load & Release(加载与释放)
-
Load Collection
在查询之前必须:
把数据加载到内存
因为:
- Milvus 是内存加速搜索系统
加载后:
- index 文件
- raw data
都会进入内存
-
Release Collection
如果不再使用:
可以释放内存
用于:
- 节省资源
- 降低成本
Search & Query(搜索与查询)
-
Search(向量搜索)
流程:
textquery vector → 相似度计算 → 返回最相似结果使用 metric:
- COSINE
- L2
- IP
-
Query(精确查询)
用于:
按条件过滤数据(metadata filter)
Partition(分区)
Partition 是:
Collection 的子集
可以理解为:
text
Collection
├── Partition A
├── Partition B
└── Partition C作用
- 数据隔离
- 提升查询效率
- 缩小搜索范围
Shard(分片)
Shard 是:
Collection 的水平拆分
特点:
- 每个 shard 对应一个数据通道
- 默认会有一个 shard
- 可以增加 shard 提升吞吐
Alias(别名)
Alias = 别名机制
作用:
给 Collection 起多个"名字"
例如:
text
user_collection_v1 → alias: user
user_collection_v2 → alias: user代码不用改,只需要切换 alias。
Function(函数)
Milvus 支持:
在插入数据时自动生成字段
例如:
- full-text search
- sparse vector 自动生成
可以理解为:
text
原始文本 → 自动生成向量Consistency Level(一致性)
用于分布式系统:
数据一致性策略
Milvus 支持:
- Strong(强一致)
- Bounded Staleness(有界延迟)
- Session(一致会话)
- Eventually(最终一致)
创建 Collection(Create Collection)
你可以通过定义 schema(结构) 、索引参数 、度量方式(metric type),以及是否在创建时加载(load)collection,来创建一个 collection。
在 Milvus 中,collection 本质上是一个二维表结构:
- 列(columns)是字段(fields)
- 行(rows)是实体(entities)
也就是说:
每一列 = 一个字段
每一行 = 一个数据实体
为了实现这种结构化数据管理,必须使用 schema(模式)。
所有写入的数据(entity)都必须满足 schema 中定义的约束。
你可以完全控制一个 collection 的各个方面,包括:
- schema(结构)
- index 参数
- metric type(相似度度量方式)
- 是否创建后立即 load 到内存
创建 collection 的步骤一般分为三步:
- 创建 schema
- (可选)设置 index 参数
- 创建 collection
-
创建 Schema
schema 用于定义 collection 的数据结构。
创建 collection 时,需要根据业务需求设计 schema。
下面的代码示例创建了一个 schema,并:
-
启用 dynamic field(动态字段)
-
定义 3 个必填字段:
- my_id
- my_vector
- my_varchar
你还可以为标量字段设置默认值或允许为空(nullable),详见 Nullable & Default。
pythonfrom pymilvus import MilvusClient, DataType client = MilvusClient( uri="http://localhost:19530", token="root:Milvus" ) # 创建 schema schema = MilvusClient.create_schema( auto_id=False, enable_dynamic_field=True, ) # 添加字段 schema.add_field(field_name="my_id", datatype=DataType.INT64, is_primary=True) schema.add_field(field_name="my_vector", datatype=DataType.FLOAT_VECTOR, dim=5) schema.add_field(field_name="my_varchar", datatype=DataType.VARCHAR, max_length=512) -
-
(可选)设置索引参数
在某个字段上创建索引,可以显著加速查询与搜索。
索引本质上是:
用来记录 collection 内数据排序或组织方式的结构
在向量检索中,你需要指定:
- metric_type(距离度量方式)
- index_type(索引类型)
在 Milvus 中:
-
向量字段通常使用
AUTOINDEX -
metric type 可选:
- COSINE
- L2
- IP
标量字段(如 id、varchar)通常只需要 index_type。
需要注意的是:
对于向量字段,必须同时设置:
- index_type(索引类型)
- metric_type(相似度计算方式)
对于标量字段(scalar fields),只需要设置:
- index_type
python# 创建索引参数 index_params = client.prepare_index_params() # 给字段 my_id 建索引 index_params.add_index( field_name="my_id", index_type="AUTOINDEX" ) # 给向量字段建索引 + 指定相似度度量方式 index_params.add_index( field_name="my_vector", index_type="AUTOINDEX", metric_type="COSINE" ) -
创建 Collection
如果你在创建 collection 时已经设置了 index 参数 ,那么 Milvus 会在创建时自动加载(load)该 collection。
在这种情况下,所有在 index 参数中涉及的字段都会被自动建立索引。
下面的代码演示了:
- 如何在创建 collection 时同时设置索引
- 如何检查 collection 的加载状态(load state)
python# 创建 collection(同时加载索引) client.create_collection( collection_name="customized_setup_1", schema=schema, index_params=index_params ) res = client.get_load_state( collection_name="customized_setup_1" ) print(res)输出结果:
json{ "state": "<LoadState: Loaded>" }你也可以在创建 collection 时不设置任何 index 参数,之后再单独添加索引。
在这种情况下:
Milvus 不会在创建时自动加载该 collection
下面代码展示了:创建 collection(无索引)后的状态
pythonclient.create_collection( collection_name="customized_setup_2", schema=schema, ) res = client.get_load_state( collection_name="customized_setup_2" ) print(res)输出结果:
json{ "state": "<LoadState: NotLoad>" }
你可以在创建 collection 时配置一些属性,使其更适合你的业务场景。
下面是常见的可配置属性。
设置 Shard 数量(Set Shard Number)
Shard(分片)是 collection 的水平切分单元。
每个 shard 对应一个数据写入通道(data input channel)。
默认情况下:
- 每个 collection 只有 1 个 shard
你可以在创建 collection 时指定 shard 数量,用于优化:
- 数据规模
- 写入吞吐量
- 负载分布
设置 shard 数量的经验建议:
1)按数据规模
-
每约 2亿条数据 = 1 个 shard
-
或按存储量估算:
- 每约 100GB 数据 = 1 个 shard
2)按 stream node(流节点)数量
如果 Milvus 有多个 stream node:
-
建议使用多个 shards
-
让写入负载分散到不同节点
-
避免:
- 某些节点过载
- 某些节点空闲
python
client.create_collection(
collection_name="customized_setup_3",
schema=schema,
num_shards=1
)启用 mmap(Enable mmap)
Milvus 默认对所有 collection 启用 mmap。
mmap 的作用是:
将原始字段数据"映射"到内存中,而不是完全加载进内存
这样可以:
- 降低内存占用(memory footprint)
- 提高 collection 的容量上限
示例:创建 collection 并关闭 mmap:
python
client.create_collection(
collection_name="customized_setup_4",
schema=schema,
enable_mmap=False
)设置 Collection TTL(生命周期)
如果某个 collection 的数据需要在一定时间后自动删除,可以设置 TTL(Time-To-Live,存活时间),单位为秒。
当 TTL 到期后:
Milvus 会自动删除 collection 中的实体(entities)
需要注意:
-
删除是异步执行
-
在删除完成前:
- 仍然可以进行 search / query
示例:设置 TTL 为 1 天
python
client.create_collection(
collection_name="customized_setup_5",
schema=schema,
properties={
"collection.ttl.seconds": 86400
}
)建议TTL 至少设置为:
几天级别(not too small)
避免数据被过早清理。
设置一致性级别(Consistency Level)
在创建 collection 时,可以指定:
search / query 的数据一致性级别
你也可以在单次查询中临时修改它。
python
client.create_collection(
collection_name="customized_setup_6",
schema=schema,
consistency_level="Bounded",
)启用动态字段(Enable Dynamic Field)
collection 中的动态字段是一个预留字段:
$meta(JSON 类型)
启用后:
- 所有未在 schema 中定义的字段
- 会被自动存入
$meta
存储形式为:
key-value 结构
例如:
json
{
"name": "Alice",
"age": 20,
"extra_field": "xxx"
}其中:
- schema 里有:name, age
- extra_field → 会进入
$meta
查看 Collections(View Collections)
你可以获取当前已连接 database 中所有 collection 的名称列表,并查看某个指定 collection 的详细信息。
下面示例展示如何获取当前 database 中所有 collections 的名称列表。
python
from pymilvus import MilvusClient, DataType
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
res = client.list_collections()
print(res)如果你已经创建了一个名为 quick_setup 的 collection,那么输出结果可能如下:
python
["quick_setup"]你也可以获取某个 collection 的完整信息。
下面示例假设你已经创建了一个名为 quick_setup 的 collection。
python
res = client.describe_collection(
collection_name="quick_setup"
)
print(res)输出示例
python
{
'collection_name': 'quick_setup',
'auto_id': False,
'num_shards': 1,
'description': '',
'fields': [
{
'field_id': 100,
'name': 'id',
'description': '',
'type': <DataType.INT64: 5>,
'params': {},
'is_primary': True
},
{
'field_id': 101,
'name': 'vector',
'description': '',
'type': <DataType.FLOAT_VECTOR: 101>,
'params': {'dim': 768}
}
],
'functions': [],
'aliases': [],
'collection_id': 456909630285026300,
'consistency_level': 2,
'properties': {},
'num_partitions': 1,
'enable_dynamic_field': True
}Modify Collection(修改集合)
你可以对集合进行重命名,或者修改集合的配置。
你可以按如下方式重命名集合:
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
client.rename_collection(
old_name="my_collection",
new_name="my_new_collection"
)集合创建完成后,你仍然可以修改集合级别的属性。
Supported properties(支持的属性):
| Property | Description |
|---|---|
| collection.ttl.seconds | 如果集合中的数据需要在一段时间后删除,可以设置其 TTL(生存时间,单位秒)。TTL 到期后,Milvus 会删除集合中的所有实体。删除是异步的,因此在删除完成前仍然可以进行查询和搜索。详情见 Set Collection TTL。 |
| mmap.enabled | 内存映射(Mmap)允许直接访问磁盘上的大文件,使 Milvus 可以同时使用内存和磁盘存储索引与数据。通过按访问频率优化数据存放策略,可以在不影响查询性能的情况下扩展存储能力。详情见 Use mmap。 |
| partitionkey.isolation | 启用分区键隔离后,Milvus 会根据 Partition Key 对数据分组,并为每组单独创建索引。在查询时,会根据过滤条件中的 Partition Key 定位索引范围,从而避免扫描无关数据,大幅提升查询性能。详情见 Use Partition Key Isolation。 |
| dynamicfield.enabled | 为未开启动态字段的集合启用动态字段功能。启用后,可以插入 schema 未定义的字段。详情见 Dynamic Field。 |
| allow_insert_auto_id | 控制在启用 AutoID 时,是否允许用户提供主键值。 当设置为 "true":插入 / upsert / 批量导入时,如果提供主键则使用用户值,否则自动生成。 当设置为 "false":忽略或拒绝用户提供的主键,始终自动生成主键(默认值)。 |
| timezone | 指定该集合在处理时间敏感操作(尤其是 TIMESTAMPTZ 字段)时使用的默认时区。时间戳在内部以 UTC 存储,Milvus 会根据该设置进行显示与比较。如果设置该值,会覆盖数据库级默认时区;查询级别的 timezone 参数可以临时覆盖两者。该值必须是合法 IANA 时区(如 Asia/Shanghai、America/Chicago 或 UTC)。详情见 TIMESTAMPTZ Field。 |
示例 1:设置集合 TTL
下面代码演示如何设置集合的 TTL(生存时间):
python
from pymilvus import MilvusClient
client.alter_collection_properties(
collection_name="my_collection",
properties={"collection.ttl.seconds": 60}
)示例 2:启用 mmap
下面代码演示如何启用 mmap:
python
from pymilvus import MilvusClient
client.alter_collection_properties(
collection_name="my_collection",
properties={"mmap.enabled": True}
)示例 3:启用 Partition Key
下面代码演示如何启用 Partition Key(分区键):
python
from pymilvus import MilvusClient
client.alter_collection_properties(
collection_name="my_collection",
properties={"partitionkey.isolation": True}
)示例 4:启用动态字段(dynamic field)
下面代码演示如何启用动态字段:
python
from pymilvus import MilvusClient
client.alter_collection_properties(
collection_name="my_collection",
properties={"dynamicfield.enabled": True}
)示例 5:启用 allow_insert_auto_id
allow_insert_auto_id 属性允许在开启 AutoID 的情况下,在插入(insert)、更新(upsert)和批量导入时接受用户提供的主键值。
当设置为 "true" 时:
如果用户提供了主键值,则使用该值;否则自动生成主键。
默认值为 "false"。
下面代码演示如何启用该配置:
python
client.alter_collection_properties(
collection_name="my_collection",
properties={"allow_insert_auto_id": "true"}
)启用后:
- 如果插入数据中包含主键列 → 使用用户提供的值
- 如果未提供 → Milvus 自动生成
示例 6:设置集合时区
你可以通过 timezone 属性为集合设置默认时区。
该设置会影响集合中所有时间相关操作的数据解释与展示,包括:
- 数据插入
- 查询操作
- 查询结果展示
timezone 必须是合法的 IANA 时区标识,例如:
Asia/ShanghaiAmerica/ChicagoUTC
如果使用非法时区,会在修改属性时直接报错。
下面代码将集合时区设置为 Asia/Shanghai:
python
client.alter_collection_properties(
collection_name="my_collection",
properties={"timezone": "Asia/Shanghai"}
)你也可以通过删除属性来重置配置:
python
client.drop_collection_properties(
collection_name="my_collection",
property_keys=[
"collection.ttl.seconds"
]
)Load & Release(加载与释放)
加载集合是进行相似度搜索和查询的前置条件。
当你加载集合时,Milvus 会将索引文件以及所有字段的原始数据加载到内存中,以便快速响应搜索与查询请求。
在集合加载之后插入的新实体,会被自动索引并加载。
下面代码演示如何加载集合:
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
# 7. 加载集合
client.load_collection(
collection_name="my_collection"
)
res = client.get_load_state(
collection_name="my_collection"
)
print(res)
# 输出
# {
# "state": "<LoadState: Loaded>"
# }Milvus 支持只加载参与搜索和查询的字段,从而减少内存占用并提升查询性能。
⚠️ 注意:部分字段加载目前仍处于 Beta 阶段,不建议用于生产环境。
下面示例假设集合 my_collection 已创建,包含字段:
my_idmy_vector
python
client.load_collection(
collection_name="my_collection",
load_fields=["my_id", "my_vector"], # 只加载指定字段
skip_load_dynamic_field=True # 跳过动态字段加载
)再次检查加载状态:
python
res = client.get_load_state(
collection_name="my_collection"
)
print(res)
# 输出
# {
# "state": "<LoadState: Loaded>"
# }关于 load_fields
如果选择只加载部分字段,需要注意:
-
只有
load_fields中包含的字段:- 可以用于过滤(filter)
- 可以作为查询输出字段
并且:
- 必须包含 主键字段(primary key)
- 必须至少包含 一个向量字段
关于 dynamic field(动态字段)
可以通过 skip_load_dynamic_field 控制是否加载动态字段。
动态字段是一个名为 $meta 的 JSON 保留字段,用于存储所有 schema 未定义的字段及其 key-value 数据。
-
如果加载 dynamic field:
- 所有动态字段 key 都可用于过滤与输出
-
如果不需要:
- 设置
skip_load_dynamic_field=True可节省内存
- 设置
重新加载字段的注意事项
如果你想在集合已加载后再加载更多字段:
👉 必须先 release 集合,否则可能因为索引变化导致错误
搜索和查询是内存密集型操作。
因此建议释放当前不使用的集合以节省资源。
下面代码演示如何释放集合:
python
# 8. 释放集合
client.release_collection(
collection_name="my_collection"
)
res = client.get_load_state(
collection_name="my_collection"
)
print(res)
# 输出
# {
# "state": "<LoadState: NotLoad>"
# }设置集合 TTL(Set Collection TTL)
默认情况下,一旦数据被插入到集合中,它会一直保留。但在某些场景中,你可能希望在一段时间后自动清理或删除数据。此时可以配置集合的 TTL(Time-to-Live,生存时间)属性,当 TTL 到期后,Milvus 会自动删除对应数据。
TTL(生存时间)在数据库中通常用于以下场景:
数据在插入或更新后一段时间内有效,超过期限后自动失效并被清理。
例如:
如果你每天导入数据,但只需要保留最近 14 天的数据,那么可以将 TTL 设置为:
14 × 24 × 3600 = 1209600 秒这样 Milvus 会自动删除超过 14 天的数据,仅保留最近的数据内容。
- 已过期的实体不会出现在任何搜索或查询结果中
- 但它们可能仍然存在于存储中,直到后续的数据压缩(compaction)完成
- 通常 compaction 会在 24 小时内执行
你可以通过配置项控制 compaction 触发时间:
dataCoord.compaction.expiry.tolerance说明:
-
默认值:
-1- 表示使用系统默认的 compaction 周期
-
如果设置为正整数(例如
12):- 表示在数据过期后 12 小时 才触发 compaction
在 Milvus 中,TTL 是一个 以秒为单位的整数属性:
- 设置后,超过 TTL 的数据将被自动删除
- 删除是异步执行的(不会立即生效)
⚠️ 延迟说明(重要)
由于删除依赖以下机制:
- 垃圾回收(GC)
- 数据压缩(compaction)
这些过程是 异步且非固定时间执行的,因此:
数据在 TTL 到期后,可能不会立即从查询结果中消失
你可以在以下两个阶段设置 TTL:
- 创建集合时设置
- 修改已有集合的 TTL
创建集合时设置 TTL
python
from pymilvus import MilvusClient
# 设置 TTL
client.create_collection(
collection_name="my_collection",
schema=schema,
properties={
"collection.ttl.seconds": 1209600
}
)修改已有集合 TTL
python
client.alter_collection_properties(
collection_name="my_collection",
properties={"collection.ttl.seconds": 1209600}
)删除 TTL 设置(永久保留数据)
如果你希望数据永久保存,可以删除 TTL 配置:
python
client.drop_collection_properties(
collection_name="my_collection",
property_keys=["collection.ttl.seconds"]
)设置一致性级别(Consistency Level)
作为一个分布式向量数据库,Milvus 提供了多种一致性级别,以确保在读写操作期间,各个节点或副本能够访问相同的数据。
目前支持的一致性级别包括:
- Strong(强一致性)
- Bounded(有界一致性 / 有界过期)
- Eventually(最终一致性)
- Session(会话一致性)
其中,默认使用的是 Bounded 一致性级别。
Milvus 是一个"存储与计算分离"的系统。
在该架构中:
- DataNode 负责数据持久化,并最终将数据存储到如 MinIO/S3 这样的分布式对象存储中。
- QueryNode 负责 Search(搜索)等计算任务。
这些计算任务需要同时处理:
- Batch Data(批量数据)
- Streaming Data(流式数据)
简单来说:
- Batch Data 可以理解为已经写入对象存储的数据;
- Streaming Data 则是尚未写入对象存储的数据。
由于网络延迟的存在,QueryNode 往往无法立即获取最新的流式数据。如果不进行额外保护,直接对流式数据执行 Search,可能会遗漏大量尚未提交的数据点,从而影响搜索结果的准确性。
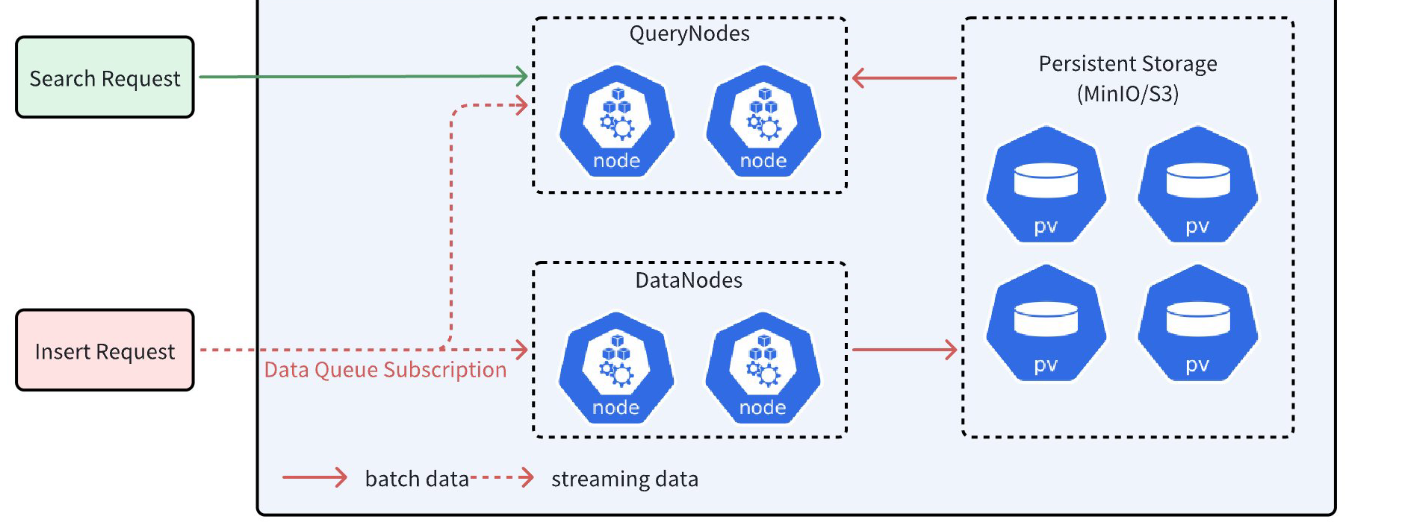
如上图所示,QueryNode 在接收到 Search 请求后,可以同时接收 Streaming Data 和 Batch Data。
但是由于网络延迟,QueryNode 获取到的 Streaming Data 可能是不完整的。
为了解决这个问题,Milvus 会:
- 为数据队列中的每条记录打上时间戳(timestamp)
- 持续向数据队列插入同步时间戳(syncTs)
当 QueryNode 收到一个同步时间戳(syncTs)后:
- 会将其设置为 ServiceTime
- 这意味着 QueryNode 能够"看见"该时间点之前的所有数据
基于 ServiceTime,Milvus 可以提供 GuaranteeTs(保证时间戳),以满足用户在一致性与可用性之间的不同需求。
用户可以在 Search 请求中指定 GuaranteeTs,用来告诉 QueryNode:
搜索范围必须包含某个指定时间点之前的数据。
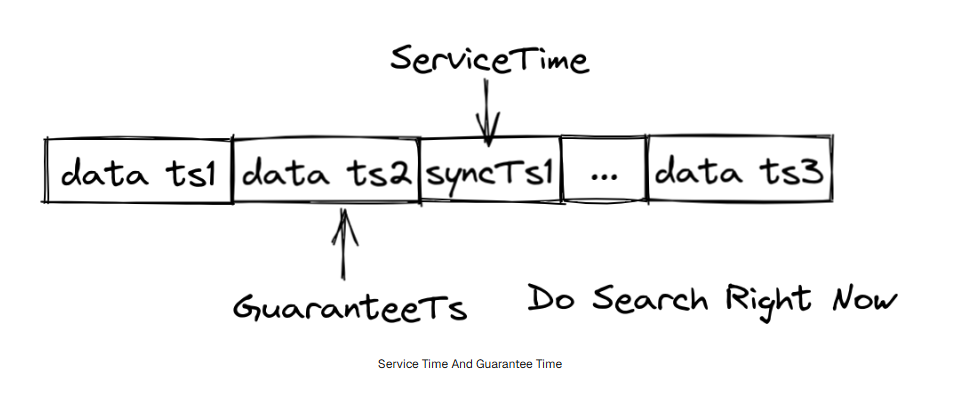
情况一:GuaranteeTs < ServiceTime
说明:
- 指定时间点之前的数据已经全部写盘完成
- QueryNode 可以立即执行 Search
情况二:GuaranteeTs > ServiceTime
说明:
- QueryNode 当前还未"追上"指定时间点的数据
- 必须等待 ServiceTime 超过 GuaranteeTs 后,才能执行 Search
一致性与延迟之间的权衡
用户需要在:
- 查询准确性(Consistency)
- 查询延迟(Latency)
之间做取舍。
如果:
- 对一致性要求高
- 不敏感于查询延迟
那么可以把 GuaranteeTs 设置得尽可能大。
如果:
- 希望尽快获得搜索结果
- 能接受一定的数据不准确
那么可以把 GuaranteeTs 设置得较小。
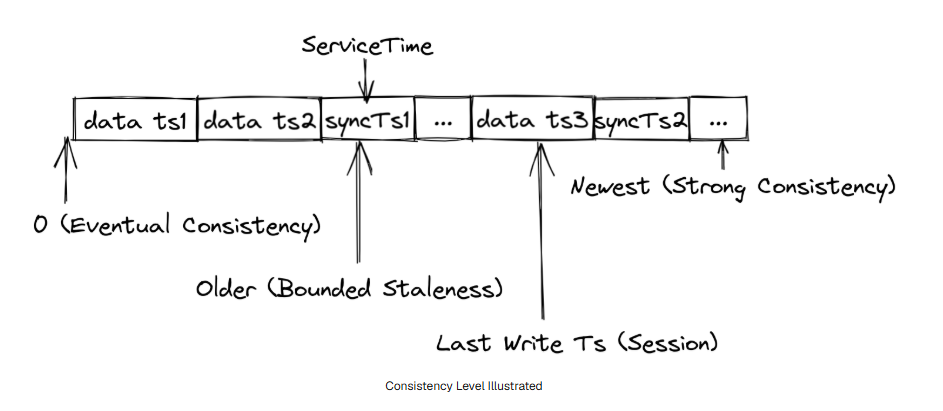
Milvus 提供了四种不同的一致性级别,它们本质上是对不同 GuaranteeTs 的封装。
Strong(强一致性)
使用最新时间戳作为 GuaranteeTs。
因此:
- QueryNode 必须等待
- 直到 ServiceTime ≥ GuaranteeTs
- 才能执行 Search 请求
特点:
- 数据最新
- 一致性最高
- 延迟也最高
Eventual(最终一致性)
GuaranteeTs 会被设置为一个极小值(例如 1)。
这样可以跳过一致性检查,使 QueryNode 在拿到 Batch Data 后立即执行 Search。
特点:
- 延迟最低
- 可能读不到最新数据
- 最终会一致
Bounded Staleness(有界过期一致性)
GuaranteeTs 会被设置为:
比最新时间戳稍早的某个时间点。
这样 QueryNode 可以:
- 容忍一定程度的数据丢失
- 换取更快的搜索速度
特点:
- 一致性与性能之间的折中
- Milvus 默认使用该模式
Session(会话一致性)
客户端最近一次写入数据的时间点会被作为 GuaranteeTs。
因此 QueryNode 能够保证:
至少可以查询到当前客户端自己写入的数据。
特点:
- "读己之写(Read Your Writes)"
- 适合交互式应用
Milvus 默认使用:
Bounded Staleness(一致性)
如果用户没有显式指定 GuaranteeTs:
- 则会使用最新的 ServiceTime 作为 GuaranteeTs。
你可以在:
- 创建 Collection 时
- 执行 Search/Search Iterator 时
- 执行 Query/Query Iterator 时
设置不同的一致性级别。
在创建 Collection 时,你可以为该 Collection 内的搜索和查询操作设置默认一致性级别。
下面的代码示例将一致性级别设置为 Bounded:
python
client.create_collection(
collection_name="my_collection",
schema=schema,
consistency_level="Bounded",
)consistency_level 参数可选值包括:
StrongBoundedEventuallySession
你始终可以为某一次特定的 Search 临时修改一致性级别。
下面的代码示例将一致性级别设置为 Bounded:
python
res = client.search(
collection_name="my_collection",
data=[query_vector],
limit=3,
search_params={"metric_type": "IP"},
consistency_level="Bounded",
)该修改:
- 仅对当前 Search 请求生效
- 不会影响 Collection 的默认一致性设置
该参数同样适用于:
- Hybrid Search(混合搜索)
- Search Iterator(搜索迭代器)
consistency_level 可选值包括:
StrongBoundedEventuallySession
你同样可以为某一次特定的 Query 临时设置一致性级别。
下面的代码示例将一致性级别设置为 Eventually:
python
res = client.query(
collection_name="my_collection",
filter="color like \"red%\"",
output_fields=["vector", "color"],
limit=3,
consistency_level="Eventually",
)该设置:
- 仅对当前 Query 请求生效
- 不影响其他请求
该参数同样适用于:
- Query Iterator(查询迭代器)
consistency_level 可选值包括:
StrongBoundedEventuallySession
管理分区(Manage Partitions)
Partition(分区)是 Collection(集合)的一个子集。
每个 Partition 与其所属 Collection 拥有相同的数据结构,但只包含该 Collection 中的一部分数据。
在创建 Collection 时,Milvus 会自动在 Collection 中创建一个名为 _default 的默认分区。
如果你不创建其他分区:
- 所有插入的数据(Entities)都会进入默认分区
- 所有 Search 和 Query 操作也都会在默认分区内执行
你可以创建更多分区,并根据特定规则将数据插入不同分区。
之后你就可以:
- 将 Search / Query 限制在某些特定分区中
- 从而提升搜索性能
一个 Collection 最多可以拥有:
1024 个 Partition(分区)
Partition Key 是一种基于 Partition 的搜索优化功能。
它允许 Milvus:
- 根据某个特定标量字段(scalar field)的值
- 自动将实体分配到不同 Partition 中
该功能有助于:
- 实现基于分区的多租户(multi-tenancy)
- 提高搜索性能
创建 Collection 时,Milvus 会自动创建 _default 分区。
你可以使用以下方式查看 Collection 中的所有 Partition:
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
res = client.list_partitions(
collection_name="my_collection"
)
print(res)
# Output
#
# ["_default"]你可以为 Collection 添加更多分区,并根据一定规则将实体插入这些分区。
python
client.create_partition(
collection_name="my_collection",
partition_name="partitionA"
)
res = client.list_partitions(
collection_name="my_collection"
)
print(res)
# Output
#
# ["_default", "partitionA"]以下代码用于检查某个 Collection 中是否存在指定分区。
python
res = client.has_partition(
collection_name="my_collection",
partition_name="partitionA"
)
print(res)
# Output
#
# True你可以单独加载 Collection 中的特定分区。
需要注意:
如果 Collection 中存在未加载的 Partition,
那么该 Collection 的 Load 状态仍会显示为 unloaded。
python
client.load_partitions(
collection_name="my_collection",
partition_names=["partitionA"]
)
res = client.get_load_state(
collection_name="my_collection",
partition_name="partitionA"
)
print(res)
# Output
#
# {
# "state": "<LoadState: Loaded>"
# }你也可以单独释放某些分区。
python
client.release_partitions(
collection_name="my_collection",
partition_names=["partitionA"]
)
res = client.get_load_state(
collection_name="my_collection",
partition_name="partitionA"
)
print(res)
# Output
#
# {
# "state": "<LoadState: NotLoaded>"
# }你可以在特定 Partition 中执行:
- insert(插入)
- upsert(更新或插入)
- delete(删除)
详细内容参考:
- Insert Entities into Partition
- Upsert Entities into Partition
- Delete Entities from Partition
你也可以仅在指定 Partition 内进行:
- Search(向量搜索)
- Query(条件查询)
详细内容参考:
- Conduct ANN Searches within Partitions
- Conduct Metadata Filtering within Partitions
你可以删除不再需要的 Partition。
但在删除之前:
必须先释放(release)该 Partition。
python
client.release_partitions(
collection_name="my_collection",
partition_names=["partitionA"]
)
client.drop_partition(
collection_name="my_collection",
partition_name="partitionA"
)
res = client.list_partitions(
collection_name="my_collection"
)
print(res)
# ["_default"]管理别名(Manage Aliases)
在 Milvus 中,Alias(别名)是 Collection 的一个"第二名称",并且是可变的(mutable)。
使用 Alias 可以提供一层抽象,使你能够:
在不修改应用代码的情况下,动态切换底层 Collection。
这在生产环境中尤其有用,例如:
- 无缝数据更新
- A/B 测试
- 蓝绿部署(Blue-Green Deployment)
- 灰度切换
- 在线索引升级
本页面将介绍如何:
- 创建 Alias
- 查看 Alias
- 重新分配 Alias
- 删除 Alias
Alias 的核心价值在于:
将客户端应用与具体的物理 Collection 名称解耦。
假设你的线上应用正在查询一个名为:
text
prod_data的 Collection。
现在你需要更新底层数据,但又不希望中断服务。
此时你可以这样操作:
第一步:创建新 Collection
例如创建:
text
prod_data_v2第二步:准备新数据
在 prod_data_v2 中:
- 导入新数据
- 构建索引
- 完成预热
第三步:切换 Alias
当新 Collection 准备完成后:
将 Alias:
text
prod_data从旧 Collection:
text
prod_data_v1原子性地切换到:
text
prod_data_v2应用程序始终访问:
text
prod_data因此:
- 应用代码无需修改
- 服务无需停机
- 用户无感知切换
这种机制非常适用于:
- 蓝绿部署
- 无停机数据更新
- 向量检索服务升级
Alias 的关键特性
一个 Collection 可以拥有多个 Alias
例如:
text
my_collection可以同时拥有:
text
alice
bob
prod
online等多个别名。
一个 Alias 同时只能指向一个 Collection
Alias 本质上类似:
text
alias -> collection的一对一映射。
当 Milvus 收到请求时会按以下顺序处理名称:
-
先检查是否存在同名 Collection
如果存在:
- 直接访问该 Collection
-
如果不存在
则继续检查:
> 该名称是否是某个 Collection 的 Alias
下面的代码示例演示如何为 Collection 创建 Alias。
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
# 9. Manage aliases
# 9.1. Create aliases
client.create_alias(
collection_name="my_collection_1",
alias="bob"
)
client.create_alias(
collection_name="my_collection_1",
alias="alice"
)这里:
bobalice
都指向:
text
my_collection_1下面的代码用于查看某个 Collection 拥有哪些 Alias。
python
# 9.2. List aliases
res = client.list_aliases(
collection_name="my_collection_1"
)
print(res)
# Output
#
# {
# "aliases": [
# "bob",
# "alice"
# ],
# "collection_name": "my_collection_1",
# "db_name": "default"
# }输出结果表示:
text
my_collection_1当前拥有两个 Alias:
- bob
- alice
下面的代码用于查看某个 Alias 指向哪个 Collection。
python
# 9.3. Describe aliases
res = client.describe_alias(
alias="bob"
)
print(res)
# Output
#
# {
# "alias": "bob",
# "collection_name": "my_collection_1",
# "db_name": "default"
# }这里表示:
text
bob -> my_collection_1你可以将某个 Alias 从一个 Collection 重新分配到另一个 Collection。
python
# 9.4 Reassign aliases to other collections
client.alter_alias(
collection_name="my_collection_2",
alias="alice"
)
res = client.list_aliases(
collection_name="my_collection_2"
)
print(res)
# Output
#
# {
# "aliases": [
# "alice"
# ],
# "collection_name": "my_collection_2",
# "db_name": "default"
# }
res = client.list_aliases(
collection_name="my_collection_1"
)
print(res)
# Output
#
# {
# "aliases": [
# "bob"
# ],
# "collection_name": "my_collection_1",
# "db_name": "default"
# }修改后:
text
alice -> my_collection_2
bob -> my_collection_1这就是 Alias 动态切换能力。
下面的代码用于删除 Alias。
python
# 9.5 Drop aliases
client.drop_alias(
alias="bob"
)
client.drop_alias(
alias="alice"
)删除后:
- Alias 不再存在
- Collection 本身不会被删除
- 数据不会受到影响
删除 Collection(Drop Collection)
如果某个 Collection 已经不再需要,你可以将其删除。
以下代码示例假设你已经存在一个名为:
text
my_collection的 Collection。
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
client.drop_collection(
collection_name="my_collection"
)执行后:
- Collection 会被删除
- Collection 中的数据也会被一并删除
- 相关索引与元数据也会被清理
因此在生产环境中执行该操作时需要谨慎。
Schema和数据字段(Data Fields)
Schema 定义了 Collection(集合)的数据结构。
在创建 Collection 之前,你需要先设计好 Schema。
在 Milvus 中,Collection Schema 类似于关系型数据库中的表结构(table)。
它定义了:
Milvus 如何组织 Collection 中的数据
一个 Collection Schema 通常包含:
- 主键(Primary Key)
- 至少一个向量字段(Vector Field)
- 若干标量字段(Scalar Fields)
在搜索系统中,数据模型设计通常包括:
-
分析业务需求
-
将信息抽象为 Schema
以"文本搜索"为例!
文本需要先转换为向量:
将字符串 → embedding → vector
从而支持向量检索(vector search)
除了向量,还可以存储:
- 发布时间(timestamp)
- 作者(author)
这些字段可以用于:
- 过滤(filter)
- 精确筛选(refinement)
例如:
- 只搜索某个日期之后的文章
- 或某个作者的内容
这些标量字段也可以:
- 一起返回
- 用于前端展示
唯一标识(ID)
每条数据需要唯一标识:
- int
- 或 string
例如:
- 12345
- article_001
创建 Schema(Create Schema)
python
from pymilvus import MilvusClient, DataType
schema = MilvusClient.create_schema()添加主键字段(Add Primary Field)
主键用于唯一标识一条数据:
- 仅支持
Int64或VarChar
python
schema.add_field(
field_name="my_id",
datatype=DataType.INT64,
is_primary=True,
auto_id=False,
)在添加字段时,你可以通过将其 is_primary 属性设置为 True 来显式指定该字段为主键字段。主键字段默认接受 Int64 类型的值,在这种情况下,其值应为类似 12345 这样的整数。如果选择在主键字段中使用 VarChar 类型,那么其值应为字符串,例如 my_entity_1234。
你可以将 autoId 属性设置为 True,从而让 Milvus 在数据插入时自动分配主键值。通常建议在所有情况下都使用 autoId,除非你确实需要手动管理主键。详细内容可参考 Primary Field & AutoId。
添加向量字段(Add Vector Fields)
向量字段用于存储稀疏或稠密的向量 embedding。在 Milvus 中,一个 Collection 最多可以添加四种向量字段。以下代码展示了如何添加一个向量字段:
python
schema.add_field(
field_name="my_vector",
datatype=DataType.FLOAT_VECTOR,
dim=5
)其中 dim 参数表示向量的维度,即该字段中每个向量的长度。FLOAT_VECTOR 表示该向量字段存储的是 32 位浮点数列表,通常用于表示 embedding。
除此之外,Milvus 还支持以下几种向量类型:
- FLOAT16_VECTOR:存储 16 位半精度浮点数,适用于内存或带宽受限的深度学习或 GPU 计算场景。
- BFLOAT16_VECTOR:存储 16 位浮点数,精度略低但指数范围与 Float32 相同,常用于深度学习以减少内存占用且不显著影响精度。
- INT8_VECTOR:由 8 位有符号整数(-128 到 127)组成,适用于量化神经网络(如 ResNet、EfficientNet),可显著减少模型体积并提升推理速度,仅带来轻微精度损失。注意该类型仅支持 HNSW 索引。
- BINARY_VECTOR:由 0 和 1 组成的向量,常用于图像处理和信息检索中的紧凑特征表示。
- SPARSE_FLOAT_VECTOR:用于稀疏向量表示,仅存储非零值及其位置索引。
添加标量字段(Add Scalar Fields)
在大多数场景中,标量字段用于存储向量数据的元信息,并配合元数据过滤进行 ANN 检索,从而提高搜索结果的准确性。Milvus 支持多种标量字段类型,包括 VarChar、Boolean、Int、Float 和 Double。
添加字符串字段(Add String Fields)
在 Milvus 中,可以使用 VarChar 字段存储字符串。示例如下:
python
schema.add_field(
field_name="my_varchar",
datatype=DataType.VARCHAR,
max_length=512
)添加数值字段(Add Number Fields)
Milvus 支持的数值类型包括 Int8、Int16、Int32、Int64、Float 和 Double。示例如下:
python
schema.add_field(
field_name="my_int64",
datatype=DataType.INT64,
)添加布尔字段(Add Boolean Fields)
Milvus 支持布尔类型字段,示例如下:
python
schema.add_field(
field_name="my_bool",
datatype=DataType.BOOL,
)添加复合字段(Add Composite Fields)
在 Milvus 中,复合字段是可以拆分为更小子结构的字段,例如 JSON 字段中的键,或 Array 字段中的索引。
添加 JSON 字段(Add JSON Fields)
JSON 字段通常用于存储半结构化数据。示例如下:
python
schema.add_field(
field_name="my_json",
datatype=DataType.JSON,
)添加数组字段(Add Array Fields)
数组字段用于存储元素列表,并且要求所有元素类型必须一致。示例如下:
python
schema.add_field(
field_name="my_array",
datatype=DataType.ARRAY,
element_type=DataType.VARCHAR,
max_capacity=5,
max_length=512,
)主键字段与 AutoID(Primary Field & AutoID)
在 Milvus 中,每个 Collection 都必须包含一个主键字段(Primary Field),用于唯一标识每一条实体(Entity)。该字段可以确保实体在插入、更新、查询和删除时不会产生歧义。
根据不同的使用场景,你既可以让 Milvus 自动生成 ID(AutoID),也可以手动指定 ID。
主键字段类似于传统数据库中的主键(Primary Key),用于作为每条数据的唯一标识。Milvus 会在 insert、upsert、delete 和 query 操作中使用该字段来管理实体。
主键字段需要满足以下要求:
- 每个 Collection 必须且只能有一个主键字段;
- 主键值不能为空;
- 数据类型需要在创建时指定,之后不能修改。
主键字段必须使用能够唯一标识实体的标量类型。
支持类型如下:
| 数据类型 | 说明 |
|---|---|
| INT64 | 64 位整数类型,通常与 AutoID 一起使用,也是大多数场景下推荐的选择。 |
| VARCHAR | 可变长度字符串类型,适用于 ID 来自外部系统的场景,例如商品编码、用户 ID 等。使用该类型时必须指定 max_length,用于定义字符串最大字节长度。 |
Milvus 支持两种主键分配模式:
| 模式 | 说明 | 适用场景 |
|---|---|---|
| AutoID | Milvus 自动为插入的数据生成唯一 ID。 | 大多数无需手动管理 ID 的场景。 |
| Manual ID | 插入数据时由用户手动指定 ID。 | 需要与外部系统或已有数据集保持一致的场景。 |
如果你不确定该使用哪种方式,建议优先选择 AutoID,因为它能够简化数据导入流程,并保证 ID 唯一性。
通常情况下,除非你确实需要手动管理主键,否则都建议使用 autoId。
使用AutoID
你可以让 Milvus 自动生成主键 ID。
第一步:创建启用 AutoID 的 Collection
在主键字段定义中设置:
python
auto_id=TrueMilvus 就会自动生成 ID。
python
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
schema = client.create_schema()
# 定义启用 AutoID 的主键字段
schema.add_field(
field_name="id", # 主键字段名
is_primary=True,
auto_id=True, # 由 Milvus 自动生成 ID,默认值为 False
datatype=DataType.INT64
)
# 定义其他字段
schema.add_field(
field_name="embedding",
datatype=DataType.FLOAT_VECTOR,
dim=4
) # 向量字段
schema.add_field(
field_name="category",
datatype=DataType.VARCHAR,
max_length=1000
) # VARCHAR 类型标量字段
# 创建 Collection
if client.has_collection("demo_autoid"):
client.drop_collection("demo_autoid")
client.create_collection(
collection_name="demo_autoid",
schema=schema
)第二步:插入数据
注意:
插入数据时不要包含主键字段。
因为:
Milvus 会自动生成主键 ID。
python
data = [
{"embedding": [0.1, 0.2, 0.3, 0.4], "category": "book"},
{"embedding": [0.2, 0.3, 0.4, 0.5], "category": "toy"},
]
res = client.insert(
collection_name="demo_autoid",
data=data
)
print("Generated IDs:", res.get("ids"))
# 输出示例:
# Generated IDs:
# [461526052788333649, 461526052788333650]当处理已存在的数据时,建议使用:
python
upsert()而不是:
python
insert()这样可以避免由于重复 ID 导致的错误。
使用手动 ID
如果你需要手动控制主键 ID,可以关闭 AutoID,并在插入数据时自行提供 ID。
第一步:创建不使用 AutoID 的 Collection
python
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
schema = client.create_schema()
# 定义不启用 AutoID 的主键字段
schema.add_field(
field_name="product_id",
is_primary=True,
auto_id=False, # 数据写入时手动提供 ID
datatype=DataType.VARCHAR,
max_length=100 # VARCHAR 类型必须指定 max_length
)
# 定义其他字段
schema.add_field(
field_name="embedding",
datatype=DataType.FLOAT_VECTOR,
dim=4
) # 向量字段
schema.add_field(
field_name="category",
datatype=DataType.VARCHAR,
max_length=1000
) # VARCHAR 标量字段
# 创建 Collection
if client.has_collection("demo_manual_ids"):
client.drop_collection("demo_manual_ids")
client.create_collection(
collection_name="demo_manual_ids",
schema=schema
)第二步:插入带有自定义 ID 的数据
在每次 insert 时:
必须包含主键字段。
python
# 每条数据都必须包含主键字段 product_id
data = [
{
"product_id": "PROD-001",
"embedding": [0.1, 0.2, 0.3, 0.4],
"category": "book"
},
{
"product_id": "PROD-002",
"embedding": [0.2, 0.3, 0.4, 0.5],
"category": "toy"
},
]
res = client.insert(
collection_name="demo_manual_ids",
data=data
)
print("Generated IDs:", res.get("ids"))
# 输出示例:
# Generated IDs:
# ['PROD-001', 'PROD-002']使用手动 ID 时,你需要自行负责:
- 保证所有 ID 全局唯一;
- 每次 insert/import 时都提供主键字段;
- 自行处理 ID 冲突与重复检测。
迁移已有 AutoID 数据(Migrate data with existing AutoIDs)
如果你在数据迁移时希望保留原有 ID,可以通过调用:
python
alter_collection_properties并开启:
python
allow_insert_auto_id = true这样即使 Collection 启用了 AutoID,Milvus 依然允许用户手动插入指定 ID。
详细配置请参考:
- Modify Collection
保证多集群间 AutoID 全局唯一
当运行多个 Milvus 集群时,需要为每个集群配置唯一的:
text
clusterID以避免 AutoID 冲突。
配置方式在初始化集群前,修改:
text
milvus.yaml中的:
yaml
common:
clusterID: 3 # 所有集群之间必须唯一(范围 0-7)其中:
text
clusterID用于标识生成该 AutoID 的集群。
取值范围:
text
0 - 7最多支持:
text
8 个集群Milvus 内部会自动处理 bit-reversal(位反转)逻辑,以支持未来扩展并避免 ID 冲突,因此除了配置 clusterID 外,不需要额外手动处理。
AutoID 如何工作(How AutoID works)
了解 AutoID 的内部生成机制,有助于你:
- 正确配置 clusterID
- 排查 ID 相关问题
AutoID 使用结构化的 64 位格式生成唯一 ID:
text
[sign_bit][cluster_id][physical_ts][logical_ts]各部分含义如下:
| 字段 | 说明 |
|---|---|
| sign_bit | 保留位,供内部使用 |
| cluster_id | 生成该 ID 的集群编号(0-7) |
| physical_ts | ID 生成时的毫秒级时间戳 |
| logical_ts | 用于区分同一毫秒内生成的多个 ID 的计数器 |
即使启用了 AutoID 且主键字段类型为:
text
VARCHARMilvus 实际上仍然会生成数值型 ID。
只是这些 ID 会以:
数字字符串(numeric string)
的形式存储,最大长度为:
text
20 个字符对应 uint64 的取值范围。
稠密向量(Dense Vector)
稠密向量(Dense Vector)是一种广泛应用于机器学习和数据分析中的数值化数据表示方式。它通常由实数数组构成,其中大部分甚至全部元素都为非零值。相比稀疏向量,稠密向量在相同维度下能够包含更多信息,因为每一个维度都具有实际意义。这种表示方式能够有效捕获复杂的模式与关系,使数据更容易在高维空间中进行分析和处理。稠密向量通常具有固定维度,可能是几十维、几百维,甚至上千维,例如 128、256、768 或 1024 维,具体取决于应用场景与模型设计。
稠密向量主要用于需要理解数据语义的场景,例如语义搜索(Semantic Search)和推荐系统(Recommendation System)。在语义搜索中,稠密向量能够帮助系统捕获查询与文档之间潜在的语义关系,从而提升搜索结果的相关性;在推荐系统中,则可以用于衡量用户与物品之间的相似性,从而提供更加个性化的推荐。
稠密向量通常表示为固定长度的浮点数数组,例如:
text
[0.2, 0.7, 0.1, 0.8, 0.3, ..., 0.5]这些向量的维度通常从几百维到几千维不等,例如:
text
128、256、768、1024每一个维度都用于表示对象的某种语义特征,因此可以通过相似度计算应用于多种场景。
虽然真实场景中的稠密向量通常是高维的,但二维示意图仍然能够表达几个关键概念:
-
多维表示(Multidimensional Representation)
每个点代表一个概念对象(例如 Milvus、向量数据库、检索系统等),其位置由各维度的数值共同决定。
-
语义关系(Semantic Relationships)
点与点之间的距离反映了概念之间的语义相似度。距离越近,说明语义越相关。
-
聚类效应(Clustering Effect)
语义相关的概念(例如 Milvus、向量数据库、检索系统)会自然聚集在空间中的相近位置,形成语义簇(semantic cluster)。
下面是一个真实的稠密向量示例,它表示文本:
text
Milvus is an efficient vector database对应的 embedding:
python
[
-0.013052909,
0.020387933,
-0.007869,
-0.11111383,
-0.030188112,
-0.0053388323,
0.0010654867,
0.072027855,
// ... 更多维度
]稠密向量可以通过多种 embedding 模型生成,例如:
- 图像领域中的 CNN 模型(如 ResNet、VGG)
- 文本领域中的语言模型(如 BERT、Word2Vec)
这些模型会将原始数据映射到高维空间中的一个点,从而提取并表达数据的语义特征。此外,Milvus 也提供了方便的方法来帮助用户生成和处理稠密向量,详见 Embeddings。
当数据完成向量化后,就可以将其存储到 Milvus 中,以便进行统一管理与向量检索。下图展示了这一基本流程。
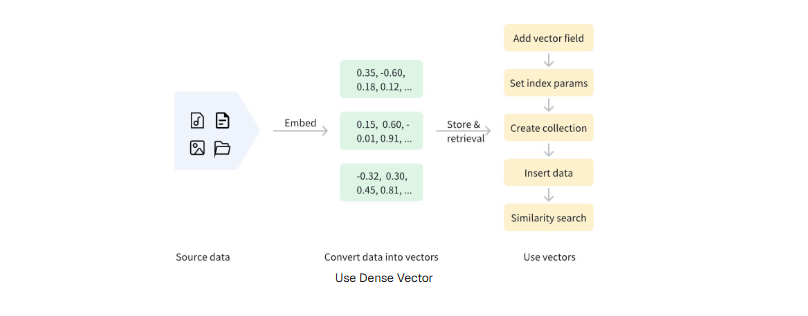
除了稠密向量之外,Milvus 还支持:
- 稀疏向量(Sparse Vector)
- 二值向量(Binary Vector)
其中:
- 稀疏向量适用于基于关键词或术语的精确匹配场景,例如关键词搜索与 term matching;
- 二值向量则适用于处理二值化数据,例如图像模式匹配与某些哈希场景。
详细内容可参考:
- Binary Vector
- Sparse Vector
使用稠密向量(Use dense vectors)
要在 Milvus 中使用稠密向量,首先需要在创建 Collection 时定义一个用于存储稠密向量的向量字段。这个过程包括:
- 将
datatype设置为支持的稠密向量类型; - 使用
dim参数指定向量维度。
下面的示例中,我们创建了一个名为 dense_vector 的向量字段,用于存储稠密向量。该字段类型为 FLOAT_VECTOR,维度为 4。
python
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
schema = client.create_schema(
auto_id=True,
enable_dynamic_fields=True,
)
schema.add_field(
field_name="pk",
datatype=DataType.VARCHAR,
is_primary=True,
max_length=100
)
schema.add_field(
field_name="dense_vector",
datatype=DataType.FLOAT_VECTOR,
dim=4
)稠密向量字段支持的数据类型:
| 数据类型 | 说明 |
|---|---|
| FLOAT_VECTOR | 存储 32 位浮点数,常用于科学计算与机器学习中的高精度向量表示,适合需要精确区分相似向量的场景。 |
| FLOAT16_VECTOR | 存储 16 位半精度浮点数,适用于深度学习与 GPU 计算。在对精度要求不高的场景下(如推荐系统召回阶段)可以减少存储占用。 |
| BFLOAT16_VECTOR | 存储 16 位 Brain Floating Point(bfloat16)数据,指数范围与 Float32 相同但精度更低,适合需要快速处理大量向量的场景,例如大规模图像检索。 |
| INT8_VECTOR | 存储由 8 位整数构成的向量,每个元素范围为 -128 到 127。适用于量化深度学习模型(如 ResNet、EfficientNet),能够减少模型大小并提高推理速度,同时仅带来轻微精度损失。注意:该类型仅支持 HNSW 索引。 |
为了加速语义搜索,需要为向量字段创建索引。索引能够显著提高大规模向量数据的检索效率。
python
index_params = client.prepare_index_params()
index_params.add_index(
field_name="dense_vector",
index_name="dense_vector_index",
index_type="AUTOINDEX",
metric_type="IP"
)在上面的示例中:
- 为
dense_vector字段创建了名为dense_vector_index的索引; - 使用的索引类型为
AUTOINDEX; metric_type="IP"表示使用 Inner Product(内积)作为距离度量方式。
Milvus 提供了多种索引类型,以满足不同场景下的向量检索需求。其中 AUTOINDEX 是一种简化使用体验的自动索引类型,用于降低向量检索的学习成本。
Milvus 同时还支持多种距离计算方式(Metric Types)。
当向量字段与索引参数设置完成后,就可以创建包含稠密向量的 Collection。下面的示例通过 create_collection 方法创建一个名为 my_collection 的 Collection。
python
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)Collection 创建完成后,可以使用 insert 方法插入包含稠密向量的数据。
需要注意:
插入向量的维度必须与创建字段时指定的
dim一致。
python
data = [
{"dense_vector": [0.1, 0.2, 0.3, 0.7]},
{"dense_vector": [0.2, 0.3, 0.4, 0.8]},
]
client.insert(
collection_name="my_collection",
data=data
)基于稠密向量的语义搜索是 Milvus 的核心功能之一。它能够根据向量之间的距离,快速找到与查询向量最相似的数据。
执行相似度搜索时,需要:
- 准备查询向量;
- 设置搜索参数;
- 调用
search方法。
python
search_params = {
"params": {"nprobe": 10}
}
query_vector = [0.1, 0.2, 0.3, 0.7]
res = client.search(
collection_name="my_collection",
data=[query_vector],
anns_field="dense_vector",
search_params=search_params,
limit=5,
output_fields=["pk"]
)
print(res)
# Output
# data: ["[{'id': '453718927992172271', 'distance': 0.7599999904632568, 'entity': {'pk': '453718927992172271'}}, {'id': '453718927992172270', 'distance': 0.6299999952316284, 'entity': {'pk': '453718927992172270'}}]"]关于相似度搜索参数的更多说明,可参考:
- Basic ANN Search
二进制向量(Binary Vector)
二进制向量(Binary Vector)是一种特殊的数据表示形式,它会将传统的高维浮点向量转换为仅由 0 和 1 组成的二进制向量。这种转换不仅能够压缩向量大小,还可以在保留语义信息的同时降低存储与计算成本。当某些特征不需要非常高的数值精度时,二值向量能够在较低资源消耗下,较好地保留原始浮点向量的大部分信息与可用性。
二进制向量在很多场景中都具有重要应用价值,尤其是在对计算效率和存储优化要求较高的场景下。例如在大型 AI 系统(如搜索引擎、推荐系统)中,需要实时处理海量数据,而二值向量由于体积更小,可以有效降低延迟与计算成本,同时不会显著损失准确率。此外,在移动设备、嵌入式设备等资源受限环境中,由于内存和算力有限,二值向量也非常适合用于实现复杂 AI 功能,并维持较高性能。
二值向量是一种将复杂对象(如图像、文本、音频)编码为固定长度二进制值的方法。在 Milvus 中,二值向量通常表示为 bit 数组或 byte 数组。例如,一个 8 维二值向量可以表示为:
text
[1, 0, 1, 1, 0, 0, 1, 0]下面的示意图展示了二值向量如何表示文本中的关键词存在情况。在该示例中,使用一个 10 维二值向量表示两段不同文本(Text 1 和 Text 2),其中每一个维度对应词汇表中的一个单词:
1表示该单词在文本中出现;0表示该单词未出现。
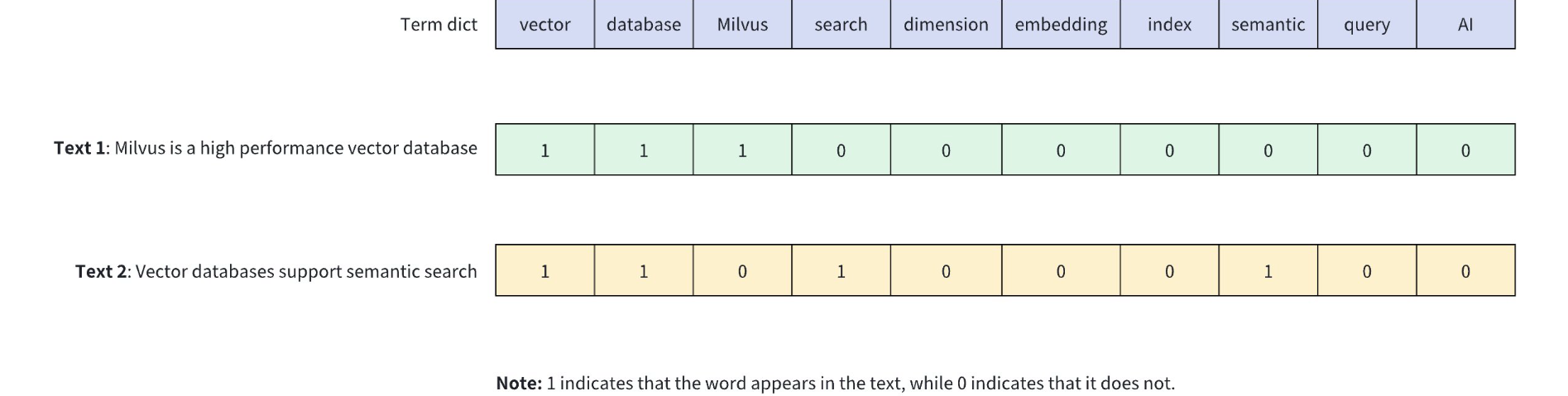
二值向量具有以下特点:
-
高效存储(Efficient Storage)
每个维度仅需 1 bit 存储空间,因此能够显著减少存储占用。
-
快速计算(Fast Computation)
向量之间的相似度可以通过 XOR 等位运算快速计算。
-
固定长度(Fixed Length)
无论原始文本长度如何,向量长度始终固定,因此更容易进行索引与检索。
-
简单直观(Simple and Intuitive)
能够直接表示关键词是否存在,因此适合某些特定检索任务。
二值向量可以通过多种方式生成。例如:
- 在文本处理中,可以基于预定义词汇表,根据单词是否出现来设置对应 bit;
- 在图像处理中,可以使用感知哈希算法(如 pHash)生成图像的二值特征;
- 在机器学习场景中,也可以对模型输出进行二值化处理,从而得到二值向量表示。
当数据完成二值向量化后,就可以存储到 Milvus 中,用于统一管理与向量检索。下图展示了其基本流程。
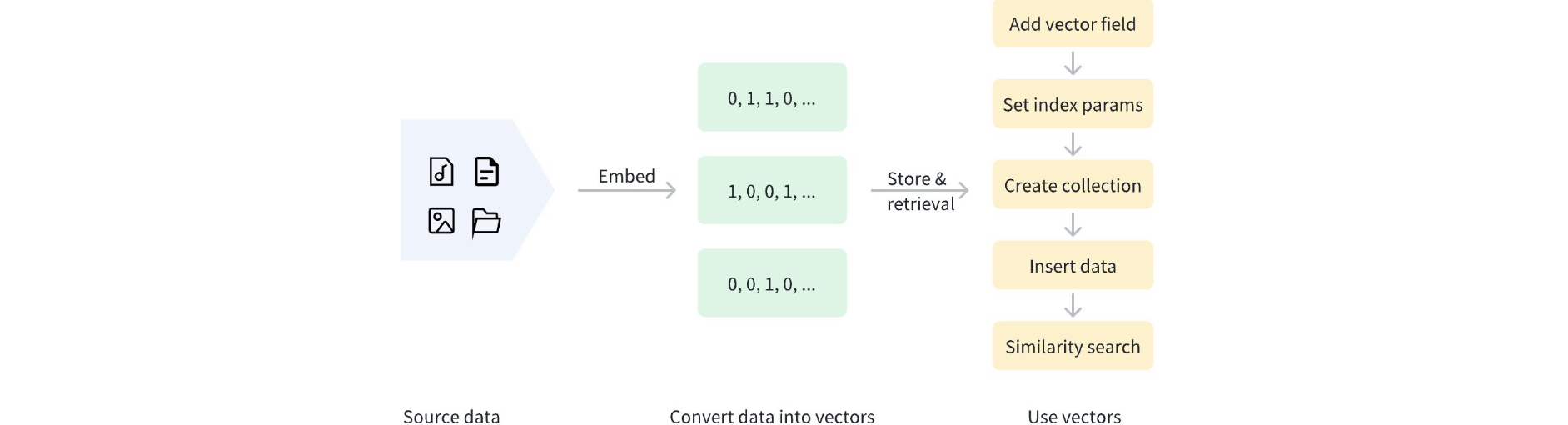
虽然二值向量在某些场景下具有非常高的效率,但它的表达能力相对有限,因此较难捕获复杂的语义关系。因此在实际应用中,二值向量通常会与其他向量类型结合使用,以在效率与表达能力之间取得平衡。
更多内容可参考:
- Dense Vector
- Sparse Vector
使用二进制向量(Use binary vectors)
要在 Milvus 中使用二值向量,首先需要在创建 Collection 时定义一个用于存储二值向量的字段。这个过程包括:
- 将
datatype设置为支持的二值向量类型BINARY_VECTOR; - 使用
dim参数指定向量维度。
需要注意:
dim必须是 8 的倍数
因为二值向量在插入时会被转换为 byte 数组,每 8 个 0/1 值会被压缩为 1 个 byte。
例如:
dim = 128- 需要 16 字节(128 ÷ 8 = 16)
下面示例中创建了一个名为 binary_vector 的向量字段:
python
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
schema = client.create_schema(
auto_id=True,
enable_dynamic_fields=True,
)
schema.add_field(
field_name="pk",
datatype=DataType.VARCHAR,
is_primary=True,
max_length=100
)
schema.add_field(
field_name="binary_vector",
datatype=DataType.BINARY_VECTOR,
dim=128
)为了提升搜索速度,需要为二值向量字段创建索引,这可以显著提高大规模向量数据的检索效率。
python
index_params = client.prepare_index_params()
index_params.add_index(
field_name="binary_vector",
index_name="binary_vector_index",
index_type="AUTOINDEX",
metric_type="HAMMING"
)在这个例子中:
- 索引名称为
binary_vector_index - 使用
AUTOINDEX自动索引类型 - 使用
HAMMING(汉明距离)作为相似度计算方式
Milvus 提供多种索引类型,AUTOINDEX 是一种简化使用的自动索引方案,用于降低向量检索的学习成本。
当二值向量与索引配置完成后,可以创建 Collection:
python
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)创建完成后,可以使用 insert 方法插入二值向量数据。
需要注意:
二值向量必须以 byte 数组形式提供
每 8 个 bit 会被打包成 1 个 byte
例如:
- 128 维向量 = 16 bytes
下面是一个转换函数示例:
python
def convert_bool_list_to_bytes(bool_list):
if len(bool_list) % 8 != 0:
raise ValueError("The length of a boolean list must be a multiple of 8")
byte_array = bytearray(len(bool_list) // 8)
for i, bit in enumerate(bool_list):
if bit == 1:
index = i // 8
shift = i % 8
byte_array[index] |= (1 << shift)
return bytes(byte_array)构造二值向量数据:
python
bool_vectors = [
[1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0] + [0] * 112,
[0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1] + [0] * 112,
]
data = [
{
"binary_vector": convert_bool_list_to_bytes(bool_vector)
}
for bool_vector in bool_vectors
]
client.insert(
collection_name="my_collection",
data=data
)相似度搜索是 Milvus 的核心能力之一,可以根据向量距离快速找到最相似的数据。
使用二值向量搜索时:
- 查询向量也必须转换为 byte 数组;
- 维度必须与
dim一致; - 每 8 个 bit 转换为 1 byte。
python
search_params = {
"params": {"nprobe": 10}
}
query_bool_list = [1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0] + [0] * 112
query_vector = convert_bool_list_to_bytes(query_bool_list)
res = client.search(
collection_name="my_collection",
data=[query_vector],
anns_field="binary_vector",
search_params=search_params,
limit=5,
output_fields=["pk"]
)
print(res)
# Output
# data: ["[{'id': '453718927992172268', 'distance': 10.0, 'entity': {'pk': '453718927992172268'}}]"]稀疏向量(Sparse Vector)
稀疏向量(Sparse Vector)是一种在信息检索与自然语言处理中用于捕捉"表层词项匹配 "的重要表示方法。与擅长语义理解的稠密向量不同,稀疏向量通常在特定词语或文本标识符检索中提供更加可预测和稳定的匹配结果。
稀疏向量是一种特殊的高维向量,其中绝大多数维度的值为 0,只有少数维度是非零值。
如下图所示:
-
稠密向量通常表示为连续数组,例如:
[0.3, 0.8, 0.2, 0.3, 0.1] -
稀疏向量则只存储非零值及其所在维度索引,通常表示为键值对形式,例如:
[{2: 0.2}, ..., {9997: 0.5}, {9999: 0.7}]

通过分词(tokenization)和评分机制,文档可以被表示为词袋模型(Bag-of-Words)向量,其中每个维度对应词表中的一个词。只有在文档中出现的词才会有非零值,从而形成稀疏向量表示。
稀疏向量通常可以通过两类方法生成:
-
传统统计方法
例如:
- TF-IDF(词频-逆文档频率)
- BM25(Best Matching 25)
这些方法根据词语在语料中的出现频率和重要性为每个词分配权重,计算得到每个 token 对应维度的分数。
Milvus 内置了基于 BM25 的全文检索能力,可以自动将文本转换为稀疏向量,无需手动预处理。这种方式非常适合关键词检索场景,尤其是在强调精确匹配的应用中。
-
神经网络稀疏嵌入模型(Neural Sparse Embeddings)
另一种方式是通过深度学习模型生成稀疏表示,这些模型通常基于 Transformer 架构,通过学习大规模数据来扩展词项并赋予权重,从而更好地表达语义上下文。
Milvus 同样支持来自外部模型的稀疏向量,例如 SPLADE 等模型生成的 embedding。更多内容可参考 Embeddings。
稀疏向量及其原始文本都可以存储在 Milvus 中,以实现高效检索。整体流程如下图所示。
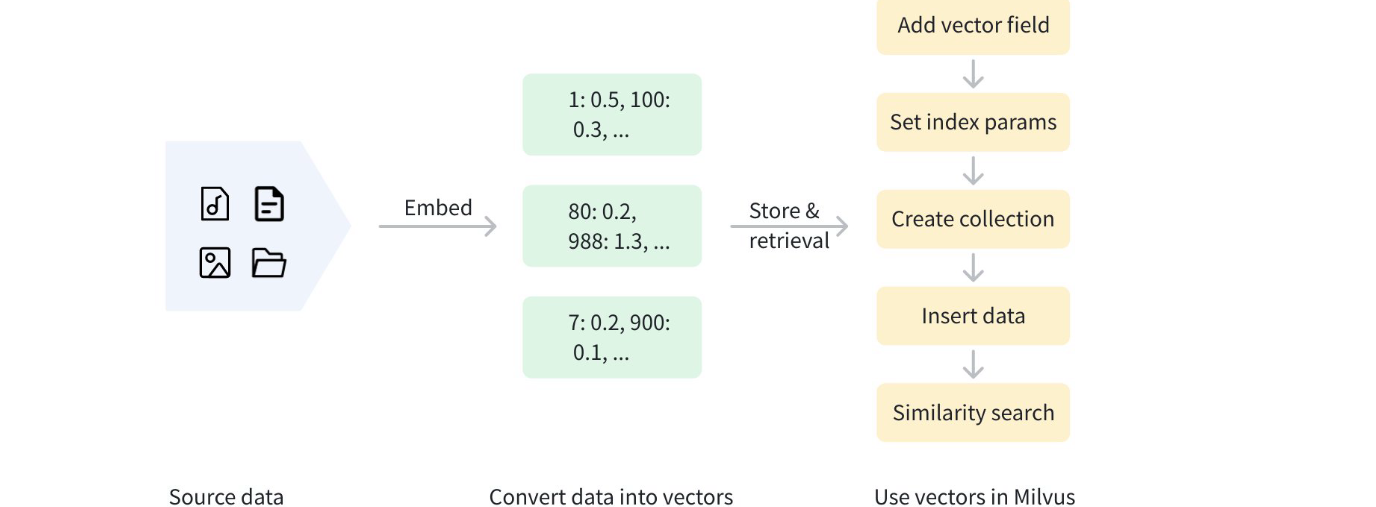
除了稀疏向量之外,Milvus 还支持:
- 稠密向量(Dense Vector)
- 二值向量(Binary Vector)
其中:
- 稠密向量适用于捕捉深层语义关系;
- 二值向量适用于快速相似度计算与内容去重;
- 稀疏向量则适用于关键词匹配与精确检索场景。
更多内容可参考:
- Dense Vector
- Binary Vector
使用稀疏向量
在以下章节中,我们将演示如何存储来自已学习的稀疏嵌入模型(如 SPLADE)的向量。如果你想用它来补充基于稠密向量的语义搜索,通常更推荐使用 BM25 的全文检索功能,而不是 SPLADE,因为前者更简单易用。
如果你已经通过评估并决定使用 SPLADE,可以参考 Embeddings 来了解如何生成稀疏向量。
Milvus 支持以下几种稀疏向量输入格式:
-
字典列表(List of Dictionaries)
格式为:
text{dimension_index: value, ...}示例:
pythonsparse_vectors = [ {27: 0.5, 100: 0.3, 5369: 0.6}, {100: 0.1, 3: 0.8} ] -
稀疏矩阵(Sparse Matrix / scipy.sparse)
使用
scipy.sparse的 CSR 矩阵:pythonfrom scipy.sparse import csr_matrix indices = [[27, 100, 5369], [3, 100]] values = [[0.5, 0.3, 0.6], [0.8, 0.1]] sparse_vectors = [ csr_matrix((vals, ([0]*len(idx), idx)), shape=(1, 5369+1)) for idx, vals in zip(indices, values) ] -
元组列表(List of Tuple Iterables)
例如:
pythonsparse_vector = [ [(27, 0.5), (100, 0.3), (5369, 0.6)], [(100, 0.1), (3, 0.8)] ]
在创建 Collection 之前,需要先定义 schema,用于指定字段结构,并可选地定义将文本转换为稀疏向量的函数。
在 Milvus 中使用稀疏向量时,需要在 schema 中包含以下字段:
- 一个
SPARSE_FLOAT_VECTOR字段,用于存储稀疏向量(可以是直接输入或由文本自动生成) - 通常还会保存原始文本(VARCHAR 字段)
python
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
schema = client.create_schema(
auto_id=True,
enable_dynamic_fields=True,
)
schema.add_field(
field_name="pk",
datatype=DataType.VARCHAR,
is_primary=True,
max_length=100
)
schema.add_field(
field_name="sparse_vector",
datatype=DataType.SPARSE_FLOAT_VECTOR
)
schema.add_field(
field_name="text",
datatype=DataType.VARCHAR,
max_length=65535,
enable_analyzer=True
)该示例包含三个字段:
- pk:主键字段,VARCHAR 类型,最大长度 100,自动生成
- sparse_vector:稀疏向量字段(SPARSE_FLOAT_VECTOR)
- text:原始文本字段,VARCHAR 类型,最大长度 65535,并启用文本分析器
如果使用 Milvus 内置 BM25 或基于文本自动生成稀疏向量,需要额外配置函数(function)。插入数据时也可以省略sparse_vector 字段。
稀疏向量索引与稠密向量类似,但在以下方面不同:
- index_type(索引类型)
- metric_type(距离度量)
- params(索引参数)
python
index_params = client.prepare_index_params()
index_params.add_index(
field_name="sparse_vector",
index_name="sparse_inverted_index",
index_type="SPARSE_INVERTED_INDEX",
metric_type="IP",
params={
"inverted_index_algo": "DAAT_MAXSCORE"
}
)说明:
-
索引类型:SPARSE_INVERTED_INDEX
-
距离度量:IP(内积)
-
算法可选:
- DAAT_MAXSCORE
- DAAT_WAND
- TAAT_NAIVE
更多内容参考:
- SPARSE_INVERTED_INDEX
- Metric Types
- Full Text Search
创建 Collection(Create Collection)
python
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)插入时必须提供所有非自动生成字段。
如果使用 BM25 自动生成稀疏向量,则可以省略 sparse_vector 字段。
python
data = [
{
"text": "information retrieval is a field of study.",
"sparse_vector": {1: 0.5, 100: 0.3, 500: 0.8}
},
{
"text": "information retrieval focuses on finding relevant information in large datasets.",
"sparse_vector": {10: 0.1, 200: 0.7, 1000: 0.9}
}
]
client.insert(
collection_name="my_collection",
data=data
)执行稀疏向量搜索前,需要准备:
- 查询向量
- 搜索参数
python
search_params = {
"params": {"drop_ratio_search": 0.2} # 可调参数,范围 0~1
}
query_data = [{1: 0.2, 50: 0.4, 1000: 0.7}]执行搜索:
python
res = client.search(
collection_name="my_collection",
data=query_data,
limit=3,
output_fields=["pk"],
search_params=search_params,
consistency_level="Strong"
)
print(res)输出示例:
text
data: ["[{'id': '453718927992172266', 'distance': 0.6299999952316284, 'entity': {'pk': '453718927992172266'}}, {'id': '453718927992172265', 'distance': 0.10000000149011612, 'entity': {'pk': '453718927992172265'}}]"]字符串字段(String Field)
在 Milvus 中,VARCHAR 是用于存储字符串数据的数据类型。
当你定义一个 VARCHAR 字段时,必须指定两个参数:
- 将
datatype设置为DataType.VARCHAR - 指定
max_length,用于定义该字段可存储的最大字节数,取值范围为 1 ~ 65,535
Milvus 支持 VARCHAR 字段的 null 值和默认值。要启用这些能力,需要设置:
nullable=Truedefault_value="xxx"
详细说明可参考 Nullable & Default。
在 Milvus 中,可以在 schema 中定义 VARCHAR 字段来存储字符串数据。
下面示例定义了两个 VARCHAR 字段:
varchar_field1:最大 100 字节,允许 null,默认值为"Unknown"varchar_field2:最大 200 字节,允许 null,无默认值
如果在 schema 中设置 enable_dynamic_fields=True,Milvus 允许插入未提前定义的字段,但这可能增加查询复杂度并影响性能。详细可参考 Dynamic Field。
python
from pymilvus import MilvusClient, DataType
SERVER_ADDR = "http://localhost:19530"
client = MilvusClient(uri=SERVER_ADDR)
schema = client.create_schema(
auto_id=False,
enable_dynamic_fields=True,
)
schema.add_field(
field_name="varchar_field1",
datatype=DataType.VARCHAR,
max_length=100,
nullable=True,
default_value="Unknown"
)
schema.add_field(
field_name="varchar_field2",
datatype=DataType.VARCHAR,
max_length=200,
nullable=True
)
schema.add_field(field_name="pk", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=3)索引可以提升查询与搜索性能。在 Milvus 中:
- 向量字段索引是必需的
- 标量字段索引是可选的
下面示例对两个字段建立索引:
varchar_field1(标量字段)embedding(向量字段)
两者都使用 AUTOINDEX 自动索引类型,Milvus 会自动选择最合适的索引实现。
此外,还可以为 VARCHAR 字段构建 NGRAM 索引以加速 LIKE 查询。详情可参考 NGRAM。
python
index_params = client.prepare_index_params()
index_params.add_index(
field_name="varchar_field1",
index_type="AUTOINDEX",
index_name="varchar_index"
)
index_params.add_index(
field_name="embedding",
index_type="AUTOINDEX",
metric_type="COSINE"
)当 schema 和索引都定义完成后,即可创建 Collection:
python
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)创建完成后,可以插入符合 schema 的数据。
python
data = [
{"varchar_field1": "Product A", "varchar_field2": "High quality product", "pk": 1, "embedding": [0.1, 0.2, 0.3]},
{"varchar_field1": "Product B", "pk": 2, "embedding": [0.4, 0.5, 0.6]},
{"varchar_field1": None, "varchar_field2": None, "pk": 3, "embedding": [0.2, 0.3, 0.1]},
{"varchar_field1": "Product C", "varchar_field2": None, "pk": 4, "embedding": [0.5, 0.7, 0.2]},
{"varchar_field1": None, "varchar_field2": "Exclusive deal", "pk": 5, "embedding": [0.6, 0.4, 0.8]},
{"varchar_field1": "Unknown", "varchar_field2": None, "pk": 6, "embedding": [0.8, 0.5, 0.3]},
{"varchar_field1": "", "varchar_field2": "Best seller", "pk": 7, "embedding": [0.8, 0.5, 0.3]},
]
client.insert(
collection_name="my_collection",
data=data
)插入数据后,可以通过 query 方法按条件过滤数据。
查询 varchar_field1 = "Product A"
python
filter = 'varchar_field1 == "Product A"'
res = client.query(
collection_name="my_collection",
filter=filter,
output_fields=["varchar_field1", "varchar_field2"]
)
print(res)查询 varchar_field2 为 null
python
filter = 'varchar_field2 is null'
res = client.query(
collection_name="my_collection",
filter=filter,
output_fields=["varchar_field1", "varchar_field2"]
)
print(res)查询 varchar_field1 = "Unknown"
python
filter = 'varchar_field1 == "Unknown"'
res = client.query(
collection_name="my_collection",
filter=filter,
output_fields=["varchar_field1", "varchar_field2"]
)
print(res)带过滤条件的向量搜索(Vector search with filter expressions)
向量搜索也可以与标量过滤条件结合使用。
例如:
python
filter = 'varchar_field2 == "Best seller"'
res = client.search(
collection_name="my_collection",
data=[[0.3, -0.6, 0.1]],
limit=5,
search_params={"params": {"nprobe": 10}},
output_fields=["varchar_field1", "varchar_field2"],
filter=filter
)
print(res)输出示例:
text
data: [
"[{'id': 7, 'distance': -0.04468163847923279, 'entity': {'varchar_field1': '', 'varchar_field2': 'Best seller'}}]"
]数值字段(Number Field)
数值字段(Number Field)是一种标量字段,用于存储数值类型数据。这些值可以是整数,也可以是浮点数,通常用于表示数量、度量值或任何需要进行数学计算的数据。
下表描述了 Milvus 支持的数值字段类型:
| 字段类型 | 说明 |
|---|---|
| BOOL | 布尔类型,用于存储 true/false,适用于表示二值状态 |
| INT8 | 8 位整数,适用于小范围整数 |
| INT16 | 16 位整数,中等范围整数 |
| INT32 | 32 位整数,适用于一般整数数据,如数量、用户 ID |
| INT64 | 64 位整数,适用于大范围数据,如时间戳或全局唯一 ID |
| FLOAT | 32 位浮点数,适用于一般精度数据,如评分、温度 |
| DOUBLE | 64 位双精度浮点数,适用于高精度数据,如金融计算或科学计算 |
要声明一个数值字段,只需要将 datatype 设置为上述任意一种数值类型,例如 DataType.INT64 或 DataType.FLOAT。
Milvus 支持数值字段的 null 值和默认值。要启用这些能力,需要设置:
nullable=Truedefault_value=xxx
在 schema 中可以定义数值字段来存储数值数据。下面示例包含两个数值字段:
age:整数类型,允许 null,默认值为 18price:浮点数类型,允许 null,无默认值
如果设置 enable_dynamic_fields=True,Milvus 允许插入未预先定义的字段,但可能增加查询复杂度并影响性能。详情可参考 Dynamic Field。
python
from pymilvus import MilvusClient, DataType
SERVER_ADDR = "http://localhost:19530"
client = MilvusClient(uri=SERVER_ADDR)
schema = client.create_schema(
auto_id=False,
enable_dynamic_fields=True,
)
schema.add_field(
field_name="age",
datatype=DataType.INT64,
nullable=True,
default_value=18
)
schema.add_field(
field_name="price",
datatype=DataType.FLOAT,
nullable=True
)
schema.add_field(field_name="pk", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=3)索引可以提升查询与检索性能。在 Milvus 中:
- 向量字段索引是必需的
- 标量字段索引是可选的
下面示例对 embedding 和 age 两个字段建立索引:
python
index_params = client.prepare_index_params()
index_params.add_index(
field_name="age",
index_type="AUTOINDEX",
index_name="age_index"
)
index_params.add_index(
field_name="embedding",
index_type="AUTOINDEX",
metric_type="COSINE"
)创建 Collection
python
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)插入数据(Insert data)
python
data = [
{"age": 25, "price": 99.99, "pk": 1, "embedding": [0.1, 0.2, 0.3]},
{"age": 30, "pk": 2, "embedding": [0.4, 0.5, 0.6]},
{"age": None, "price": None, "pk": 3, "embedding": [0.2, 0.3, 0.1]},
{"age": 45, "price": None, "pk": 4, "embedding": [0.9, 0.1, 0.4]},
{"age": None, "price": 59.99, "pk": 5, "embedding": [0.8, 0.5, 0.3]},
{"age": 60, "price": None, "pk": 6, "embedding": [0.1, 0.6, 0.9]}
]
client.insert(
collection_name="my_collection",
data=data
)使用过滤表达式查询(Query with filter expressions)
查询 age > 30
python
filter = 'age > 30'
res = client.query(
collection_name="my_collection",
filter=filter,
output_fields=["age", "price", "pk"]
)
print(res)查询 price 为 null
python
filter = 'price is null'查询 age = 18
python
filter = 'age == 18'带过滤条件的向量搜索(Vector search with filter expressions)数值字段过滤也可以与向量搜索结合使用:
python
filter = "25 <= age <= 35"
res = client.search(
collection_name="my_collection",
data=[[0.3, -0.6, 0.1]],
limit=5,
search_params={"params": {"nprobe": 10}},
output_fields=["age", "price"],
filter=filter
)
print(res)在这个例子中:
- 先定义查询向量
- 再加过滤条件
25 <= age <= 35
这样结果既满足向量相似度,又满足年龄范围约束。
Array 字段
ARRAY 字段用于存储同一数据类型的有序元素集合。下面是 ARRAY 字段存储数据的示例:
json
{
"tags": ["pop", "rock", "classic"],
"ratings": [5, 4, 3]
}限制
默认值:ARRAY 字段不支持默认值。不过你可以将 nullable 设置为 True 以允许空值,详情可参考 Nullable & Default。
数据类型:ARRAY 中的所有元素必须是相同的数据类型,该类型由 element_type 参数指定。当 element_type 为 VARCHAR 时,还必须为数组元素指定 max_length。element_type 支持 Milvus 的所有标量类型,但不包括 JSON。
数组容量:ARRAY 中元素数量必须小于等于创建时定义的最大容量 max_capacity,取值范围为 1 到 4096 的整数。
字符串处理:ARRAY 中的字符串按原样存储,不做语义转义或转换。例如 'a"b'、"a'b"、'a\'b'、"a\"b" 会按原样保存,而 'a'b' 和 "a"b" 会被视为非法值。
添加 ARRAY 字段
在 Milvus 中使用 ARRAY 字段时,需要在创建 schema 时定义相应字段类型,包括:
将 datatype 设置为 ARRAY。
通过 element_type 指定数组元素的数据类型,同一数组中的元素必须类型一致。
通过 max_capacity 指定数组最大容量,即最多可存储的元素数量。
下面是包含 ARRAY 字段的 schema 定义示例:
如果在定义 schema 时设置 enable_dynamic_fields=True,Milvus 允许插入未提前定义的字段,但这会增加查询与管理复杂度,并可能影响性能,详情参考 Dynamic Field。
python
# Import necessary libraries
from pymilvus import MilvusClient, DataType
# Define server address
SERVER_ADDR = "http://localhost:19530"
# Create a MilvusClient instance
client = MilvusClient(uri=SERVER_ADDR)
# Define the collection schema
schema = client.create_schema(
auto_id=False,
enable_dynamic_fields=True,
)
# Add `tags` and `ratings` ARRAY fields with nullable=True
schema.add_field(
field_name="tags",
datatype=DataType.ARRAY,
element_type=DataType.VARCHAR,
max_capacity=10,
max_length=65535,
nullable=True
)
schema.add_field(
field_name="ratings",
datatype=DataType.ARRAY,
element_type=DataType.INT64,
max_capacity=5,
nullable=True
)
schema.add_field(field_name="pk", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=3)设置索引参数
下面示例对 embedding 向量字段和 tags ARRAY 字段都创建索引,使用 AUTOINDEX 类型。该类型会自动选择最合适的索引实现。你也可以为不同字段自定义 index type 和参数,详情参考 Index Explained。
python
index_params = client.prepare_index_params()
# Index `tags` with AUTOINDEX
index_params.add_index(
field_name="tags",
index_type="AUTOINDEX",
index_name="tags_index"
)
# Index `embedding` with AUTOINDEX and specify similarity metric type
index_params.add_index(
field_name="embedding",
index_type="AUTOINDEX",
metric_type="COSINE"
)创建集合
完成 schema 和索引定义后,即可创建包含 ARRAY 字段的 collection。
python
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)插入数据
创建 collection 后,可以插入包含 ARRAY 字段的数据。
python
data = [
{
"tags": ["pop", "rock", "classic"],
"ratings": [5, 4, 3],
"pk": 1,
"embedding": [0.12, 0.34, 0.56]
},
{
"tags": None, # 整个 ARRAY 为空
"ratings": [4, 5],
"pk": 2,
"embedding": [0.78, 0.91, 0.23]
},
{ # tags 字段完全缺失
"ratings": [9, 5],
"pk": 3,
"embedding": [0.18, 0.11, 0.23]
}
]
client.insert(
collection_name="my_collection",
data=data
)使用 filter 表达式查询
插入数据后,可以通过 query 方法按条件查询:
查询 tags 不为空的记录:
python
filter = 'tags IS NOT NULL'查询 ratings 第一个元素大于 4 的记录:
python
filter = 'ratings[0] > 4'向量检索 + 过滤条件
除了标量过滤,还可以在向量搜索中结合 ARRAY 条件,例如:
python
filter = 'tags[0] == "pop"'此外,Milvus 还支持更高级的 ARRAY 过滤操作,如 ARRAY_CONTAINS、ARRAY_CONTAINS_ALL、ARRAY_CONTAINS_ANY 和 ARRAY_LENGTH,用于增强查询能力,详情可参考 ARRAY Operators。
结构体数组(Array of Structs)
Milvus 中的 Array of Structs 字段用于在一个实体中存储一组有序的 Struct(结构体)元素。Array 中的每个 Struct 都遵循同一个预定义 schema,该 schema 由多个向量字段和标量字段组成。
下面是一个包含 Array of Structs 字段的 collection 示例实体:
json
{
'id': 0,
'title': 'Walden',
'title_vector': [0.1, 0.2, 0.3, 0.4, 0.5],
'author': 'Henry David Thoreau',
'year_of_publication': 1845,
'chunks': [
{
'text': 'When I wrote the following pages, or rather the bulk of them...',
'text_vector': [0.3, 0.2, 0.3, 0.2, 0.5],
'chapter': 'Economy',
},
{
'text': 'I would fain say something, not so much concerning the Chinese and...',
'text_vector': [0.7, 0.4, 0.2, 0.7, 0.8],
'chapter': 'Economy'
}
]
}在上面的例子中,chunks 字段就是一个 Array of Structs 字段,其中每个 Struct 元素都包含自己的字段:text、text_vector 和 chapter。
限制(Limits)
数据类型
在创建 collection 时,可以使用 Struct 类型作为 Array 元素的数据类型。但你不能在已有 collection 中新增 Array of Structs 字段,并且 Milvus 也不支持将 Struct 作为普通字段类型使用。
Array 中的 Struct 共享同一个 schema,这个 schema 必须在创建字段时定义。
Struct schema 可以包含向量字段和标量字段,支持如下类型:
- 向量类型:FLOAT_VECTOR
- 标量类型:VARCHAR、INT8/16/32/64、FLOAT、DOUBLE、BOOLEAN
在 collection + Struct 层级中,向量字段总数(包括 Struct 内部)不能超过 10。
可空与默认值
Array of Structs 字段不支持 nullable,也不支持默认值。
函数支持
不能通过函数从 Struct 内的标量字段生成向量字段。
索引类型与度量类型
Collection 中所有向量字段都必须建索引。对 Struct 内的向量字段进行索引时,Milvus 会将每个 Struct 的 embedding 组织成 embedding list,并对整个 list 进行索引。
支持使用 AUTOINDEX 或 HNSW 作为索引类型,并支持如下度量方式:
- MAX_SIM_COSINE
- MAX_SIM_IP
- MAX_SIM_L2
注意:Array of Structs 中的标量字段不支持建索引。
Upsert 行为
Struct 不支持 merge 模式的 upsert,但可以使用 override 模式进行更新。具体差异参考 Upsert Entities。
标量过滤
在查询或检索中,不能对 Array of Structs 字段或其内部字段进行 filter 条件过滤。
添加 Array of Structs
在 Milvus 中使用 Array of Structs 时,需要在创建 collection schema 时定义 ARRAY 字段,并将元素类型设为 Struct,步骤如下:
- 设置字段类型为
DataType.ARRAY - 将
element_type设置为DataType.STRUCT - 创建 Struct schema,并在其中定义字段
- 在 ARRAY 字段中通过
struct_schema引用该 Struct schema - 通过
max_capacity指定每个实体最多包含多少个 Struct - (可选)可以为 Struct 内字段设置
mmap.enabled来优化冷热数据管理
下面是示例代码:
python
from pymilvus import MilvusClient, DataType
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
schema = client.create_schema()
# 主键字段
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, auto_id=True)
# 标量字段
schema.add_field(field_name="title", datatype=DataType.VARCHAR, max_length=512)
schema.add_field(field_name="author", datatype=DataType.VARCHAR, max_length=512)
schema.add_field(field_name="year_of_publication", datatype=DataType.INT64)
# 向量字段
schema.add_field(field_name="title_vector", datatype=DataType.FLOAT_VECTOR, dim=5)
# 创建 Struct schema
struct_schema = client.create_struct_field_schema()
struct_schema.add_field("text", DataType.VARCHAR, max_length=65535)
struct_schema.add_field("chapter", DataType.VARCHAR, max_length=512)
struct_schema.add_field(
"text_vector",
DataType.FLOAT_VECTOR,
mmap_enabled=True,
dim=5
)
# Array of Structs 字段
schema.add_field(
"chunks",
datatype=DataType.ARRAY,
element_type=DataType.STRUCT,
struct_schema=struct_schema,
max_capacity=1000
)上面的代码中,高亮部分展示了如何在 schema 中添加 Array of Structs 字段的完整流程。
设置索引参数
索引对所有向量字段都是强制要求的,包括 collection 中的向量字段,以及 Struct 内部定义的向量字段。
不同索引类型对应的参数有所不同,具体可参考 Index Explained 以及你所选索引类型的相关文档。
对于 embedding list(嵌入列表),需要将索引类型设置为 AUTOINDEX 或 HNSW,并使用 MAX_SIM_COSINE 作为 metric_type,用于衡量 embedding list 之间的相似度。
python
# 创建索引参数
index_params = client.prepare_index_params()
# 为 collection 中的向量字段创建索引
index_params.add_index(
field_name="title_vector",
index_type="AUTOINDEX",
metric_type="L2",
)
# 为 Struct 内的向量字段创建索引
index_params.add_index(
field_name="chunks[text_vector]",
index_type="AUTOINDEX",
metric_type="MAX_SIM_COSINE",
)创建 collection
当 schema 和 index 都准备好之后,就可以创建包含 Array of Structs 字段的 collection。
python
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)插入数据
创建 collection 后,可以按如下方式插入包含 Array of Structs 的数据:
python
data = {
'title': 'Walden',
'title_vector': [0.1, 0.2, 0.3, 0.4, 0.5],
'author': 'Henry David Thoreau',
'year_of_publication': 1845,
'chunks': [
{
'text': 'When I wrote the following pages, or rather the bulk of them...',
'text_vector': [0.3, 0.2, 0.3, 0.2, 0.5],
'chapter': 'Economy',
},
{
'text': 'I would fain say something, not so much concerning the Chinese and...',
'text_vector': [0.7, 0.4, 0.2, 0.7, 0.8],
'chapter': 'Economy'
}
]
}
client.insert(
collection_name="my_collection",
data=[data]
)基于 Array of Structs 的向量检索
你可以对 collection 中的向量字段以及 Struct 内部的向量字段进行向量检索。
具体做法是:在 search 的 anns_field 参数中使用"Array字段名 + Struct内字段名"的组合形式,并使用 EmbeddingList 来组织查询向量。
Milvus 提供 EmbeddingList,用于更清晰地组织 Array of Structs 中 embedding list 的查询向量。每个 EmbeddingList 至少包含一个向量 embedding,并返回 topK 个结果。
需要注意的是,EmbeddingList 只能用于普通 search() 请求,不支持 range search、grouping search,也不支持 search_iterator()。
python
from pymilvus.client.embedding_list import EmbeddingList
# 每个 embedding list 会触发一次搜索
embeddingList1 = EmbeddingList()
embeddingList1.add([0.2, 0.9, 0.4, -0.3, 0.2])
embeddingList2 = EmbeddingList()
embeddingList2.add([-0.2, -0.2, 0.5, 0.6, 0.9])
embeddingList2.add([-0.4, 0.3, 0.5, 0.8, 0.2])
# 单个 embedding list 查询
results = client.search(
collection_name="my_collection",
data=[embeddingList1],
anns_field="chunks[text_vector]",
search_params={"metric_type": "MAX_SIM_COSINE"},
limit=3,
output_fields=["chunks[text]"]
)上面的查询中,chunks[text_vector] 用于指定 Struct 中的 text_vector 字段,你可以在 anns_field 和 output_fields 中使用这种写法。
返回结果是最相似的 top3 实体列表。
输出(多个 embedding list)
你也可以在 data 中传入多个 EmbeddingList,从而分别得到多组查询结果:
python
results = client.search(
collection_name="my_collection",
data=[embeddingList1, embeddingList2],
anns_field="chunks[text_vector]",
search_params={"metric_type": "MAX_SIM_COSINE"},
limit=3,
output_fields=["chunks[text]"]
)
print(results)每个 embedding list 都会触发一次独立的搜索,并返回对应的 top-K 结果列表。
Geometry 字段
在构建地理信息系统(GIS)、地图工具或基于位置的服务时,你通常需要存储和查询几何数据。Milvus 中的 GEOMETRY 数据类型提供了一种原生方式,用于存储和查询灵活的几何数据,从而解决这一问题。
当你需要将向量相似性与空间约束结合时,可以使用 GEOMETRY 字段,例如:
- 基于位置服务(LBS):在某个街区内查找相似兴趣点(POI)
- 多模态搜索:检索"距离某个点 1km 内的相似图片"
- 地图与物流:查询区域内资产或路径相交的路线
要使用 GEOMETRY 字段,需要升级 SDK 到最新版本。
GEOMETRY 字段是 Milvus 中一种由 schema 定义的数据类型(DataType.GEOMETRY),用于存储几何数据。
在使用几何字段时,数据的输入与查询均采用 WKT(Well-Known Text)格式,这是一种人类可读的几何表示方式。
在内部,Milvus 会将 WKT 转换为 **WKB(Well-Known Binary)**以提高存储和处理效率,但用户无需直接处理 WKB。
GEOMETRY 支持以下几种几何对象:
-
POINT
POINT (x y)示例:
POINT (13.403683 52.520711)(x=经度,y=纬度) -
LINESTRING
LINESTRING (x1 y1, x2 y2, ...)示例:
LINESTRING (13.40 52.52, 13.41 52.51) -
POLYGON
POLYGON ((x1 y1, x2 y2, x3 y3, x1 y1))示例:
POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10)) -
MULTIPOINT
MULTIPOINT ((x1 y1), (x2 y2), ...) -
MULTILINESTRING
MULTILINESTRING ((...), (...)) -
MULTIPOLYGON
MULTIPOLYGON (((...)), ((...))) -
GEOMETRYCOLLECTION
GEOMETRYCOLLECTION(POINT(...), LINESTRING(...), POLYGON(...))
使用 GEOMETRY 字段的流程包括:
- 在 schema 中定义字段
- 插入几何数据
- 使用空间过滤表达式进行查询
Step 1:定义 GEOMETRY 字段
在创建集合时显式定义 GEOMETRY 字段:
python
from pymilvus import MilvusClient, DataType
import numpy as np
dim = 8
collection_name = "geo_collection"
milvus_client = MilvusClient("http://localhost:19530")
schema = milvus_client.create_schema(enable_dynamic_field=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("embeddings", DataType.FLOAT_VECTOR, dim=dim)
schema.add_field("geo", DataType.GEOMETRY, nullable=True)
schema.add_field("name", DataType.VARCHAR, max_length=128)
milvus_client.create_collection(
collection_name,
schema=schema,
consistency_level="Strong"
)其中 nullable=True 表示该字段允许为空。
Step 2:插入数据
插入 WKT 格式的几何数据:
python
geo_points = [
'POINT(13.399710 52.518010)',
'POINT(13.403934 52.522877)',
...
]插入记录:
python
rows = [
{"id": 1, "name": "Shop A", "embeddings": ..., "geo": geo_points[0]},
{"id": 2, "name": "Shop B", "embeddings": ..., "geo": geo_points[1]},
]
insert_result = milvus_client.insert(collection_name, rows)Step 3:过滤操作
在使用 GEOMETRY 过滤前,需要:
- 为所有向量字段创建索引
- 将集合加载到内存
GEOMETRY 过滤语法:
{operator}(geo_field, '{wkt}')或距离查询:
ST_DWITHIN(geo_field, '{wkt}', distance)说明:
- operator:几何函数(如 ST_CONTAINS / ST_INTERSECTS)
- geo_field:字段名
- wkt:WKT 几何表达
- distance:距离阈值(仅 ST_DWITHIN)
示例 1:矩形区域查询
python
filter=f"st_within(geo, '{bounding_box_wkt}')"返回位于该区域内的所有点。
示例 2:1km 范围查询
python
filter=f"st_dwithin(geo, '{central_point_wkt}', 1000)"查询距离中心点 1km 内的实体。
示例 3:向量 + 空间过滤
python
filter=f"st_within(geo, '{bounding_box_wkt}')"在向量搜索时叠加空间约束。
默认情况下,如果 GEOMETRY 没有索引,会进行全表扫描,在大数据集上较慢。
可以使用 RTREE 索引加速空间查询。
注意事项
-
dynamic field 能存 GEOMETRY 吗?
不能,必须在 schema 中显式定义。
-
支持 mmap 吗?
支持。
-
支持 nullable 或默认值吗?
支持,默认值使用 WKT 格式。
TIMESTAMPTZ 字段(适用于 Milvus 2.6.6+)
在跨地区时间处理的应用中,例如电商系统、协作工具或分布式日志系统,你需要能够精确处理带时区的时间戳。Milvus 的 TIMESTAMPTZ 数据类型提供了这一能力,它可以存储带时区信息的时间数据。
TIMESTAMPTZ 是 Milvus 中一种 schema 定义的数据类型(DataType.TIMESTAMPTZ),用于处理时区感知的时间输入,并在内部统一存储为 UTC 时间。
特点如下:
-
输入格式:ISO 8601 格式(带时区偏移)
- 例如:
2025-05-01T23:59:59+08:00 - 表示 2025 年 5 月 1 日 23:59:59(UTC+8)
- 例如:
-
内部存储:统一转换为 UTC(协调世界时)
-
比较与排序:所有操作基于 UTC 执行,保证跨时区一致性
TIMESTAMPTZ 字段支持:
nullable=True:允许空值default_value:支持 ISO 8601 时间字符串作为默认值
TIMESTAMPTZ 的使用流程与其他标量字段一致:
定义字段 → 插入数据 → 查询/过滤
Step 1:定义 TIMESTAMPTZ 字段
在创建集合时显式定义 TIMESTAMPTZ 字段:
python
import time
from pymilvus import MilvusClient, DataType
import datetime
import pytz
server_address = "http://localhost:19530"
collection_name = "timestamptz_test123"
client = MilvusClient(uri=server_address)
if client.has_collection(collection_name):
client.drop_collection(collection_name)
schema = client.create_schema()
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("tsz", DataType.TIMESTAMPTZ, nullable=True)
schema.add_field("vec", DataType.FLOAT_VECTOR, dim=4)
client.create_collection(
collection_name,
schema=schema,
consistency_level="Session"
)Step 2:插入数据
插入带时区的 ISO 8601 时间字符串。
示例中插入 8193 条数据,每条包含:
- ID
- 带时区时间(上海时间)
- 4维向量
python
data_size = 8193
shanghai_tz = pytz.timezone("Asia/Shanghai")
data = [
{
"id": i + 1,
"tsz": shanghai_tz.localize(
datetime.datetime(2025, 1, 1, 0, 0, 0)
+ datetime.timedelta(days=i)
).isoformat(),
"vec": [float(i) / 10 for i in range(4)],
}
for i in range(data_size)
]
client.insert(collection_name, data)Step 3:过滤操作
TIMESTAMPTZ 支持:
- 比较操作(==, !=, <, >, <=, >=)
- 时间区间计算
- 时间组件提取
在查询前必须满足:
- 已为向量字段创建索引
- 集合已加载到内存
示例:创建索引 + 加载
python
index_params = client.prepare_index_params()
index_params.add_index(
field_name="vec",
index_type="AUTOINDEX",
metric_type="COSINE"
)
client.create_index(collection_name, index_params)
client.load_collection(collection_name)时间过滤查询
示例 1:不等于查询
python
expr = "tsz != ISO '2025-01-03T00:00:00+08:00'"
results = client.query(
collection_name=collection_name,
filter=expr,
output_fields=["id", "tsz"],
limit=10
)说明:
tsz:TIMESTAMPTZ 字段- ISO 时间字符串:带时区的时间字面量
!=:不等于操作
区间运算
TIMESTAMPTZ 支持 INTERVAL(ISO 8601 duration)运算:
text
P1D = 1天
PT3H = 3小时
P2DT6H = 2天6小时示例:时间加减
python
expr = "tsz + INTERVAL 'P0D' != ISO '2025-01-03T00:00:00+08:00'"支持:
tsz + INTERVAL 'P3D'(加3天)tsz - INTERVAL 'PT2H'(减2小时)
时间 + 向量混合搜索
可以同时使用:
- 向量相似性
- 时间过滤
python
filter = "tsz > ISO '2025-01-05T00:00:00+08:00'"
res = client.search(
collection_name=collection_name,
data=[[0.1, 0.2, 0.3, 0.4]],
limit=5,
filter=filter,
output_fields=["id", "tsz"],
)高级用法
时区管理层级
| 层级 | 参数 | 范围 | 优先级 |
|---|---|---|---|
| Database | timezone | 整个数据库 | 低 |
| Collection | timezone | 单个集合 | 中 |
| Query/Search | timezone | 单次请求 | 高 |
默认情况下:
- TIMESTAMPTZ 没有索引 → 全表扫描 → 慢
可以使用:
STL_SORT 索引
来加速时间查询。
TIMESTAMPTZ 的本质是:
"统一转 UTC 存储 + 支持时区输入 + 支持时间计算 + 可用于向量过滤"
JSON 字段
在构建产品目录、内容管理系统或用户偏好引擎等应用时,你通常需要在向量嵌入之外存储灵活的元数据。不同类别的产品属性不同、用户偏好不断变化、文档结构也可能非常复杂。Milvus 中的 JSON 字段通过支持灵活的结构化数据存储与查询,在不牺牲性能的情况下解决了这一问题。
JSON 字段是 Milvus 中一种由 schema 定义的数据类型(DataType.JSON),用于存储结构化的键值数据。
与传统固定列不同,JSON 字段支持:
- 嵌套对象
- 数组
- 混合数据类型
同时提供多种索引能力以支持高效查询。
json
{
"metadata": {
"category": "electronics",
"brand": "BrandA",
"in_stock": true,
"price": 99.99,
"string_price": "99.99",
"tags": ["clearance", "summer_sale"],
"supplier": {
"name": "SupplierX",
"country": "USA",
"contact": {
"email": "support@supplierx.com",
"phone": "+1-800-555-0199"
}
}
}
}在这个例子中,metadata 是一个 JSON 字段,包含:
- 扁平字段(category、price)
- 数组(tags)
- 嵌套对象(supplier)
JSON key 只能使用:
- 字母
- 数字
- 下划线
禁止使用:
- 空格
- 特殊字符
- 点号(
.)
否则可能导致查询解析错误。
JSON 字段与动态字段容易混淆,但用途不同:
| 特性 | JSON 字段 | 动态字段 |
|---|---|---|
| Schema定义 | 显式声明 DataType.JSON | 隐式 $meta 字段 |
| 使用场景 | 结构固定的 JSON 数据 | 灵活/不断变化的数据 |
| 控制权 | 用户定义字段结构 | 系统自动管理 |
| 查询方式 | metadata"key" | dynamic_key 或 $meta"key" |
使用 JSON 字段的流程:
定义字段 → 插入数据 → 查询/过滤
定义 JSON 字段
python
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
schema = client.create_schema(auto_id=False, enable_dynamic_field=True)
schema.add_field(field_name="product_id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=5)
schema.add_field(
field_name="metadata",
datatype=DataType.JSON,
nullable=True
)
client.create_collection(
collection_name="product_catalog",
schema=schema
)插入数据
python
entities = [
{
"product_id": 1,
"vector": [0.1, 0.2, 0.3, 0.4, 0.5],
"metadata": {
"category": "electronics",
"brand": "BrandA",
"in_stock": True,
"price": 99.99,
"string_price": "99.99",
"tags": ["clearance", "summer_sale"],
"supplier": {
"name": "SupplierX",
"country": "USA",
"contact": {
"email": "support@supplierx.com",
"phone": "+1-800-555-0199"
}
}
}
}
]
client.insert(collection_name="product_catalog", data=entities)过滤操作
使用 JSON 过滤前必须:
- 已创建向量索引
- 已加载 collection 到内存
创建索引
python
index_params = client.prepare_index_params()
index_params.add_index(
field_name="vector",
index_type="AUTOINDEX",
metric_type="COSINE"
)
client.create_index("product_catalog", index_params)
client.load_collection("product_catalog")在满足这些前置条件之后,你就可以使用下面这些表达式,根据 JSON 字段中的值对集合进行过滤。这些过滤表达式利用了特定的 JSON path 语法以及专用操作符。
要查询某个具体 key,可以使用方括号语法访问 JSON 字段:
json_field_name["key"]对于嵌套 key,可以逐级访问:
json_field_name["key1"]["key2"]示例:过滤 category 等于 "electronics" 的数据
python
# 定义过滤表达式
filter = 'metadata["category"] == "electronics"'
client.search(
collection_name="product_catalog", # 集合名称
data=[[0.1, 0.2, 0.3, 0.4, 0.5]], # 查询向量(必须与集合维度一致)
limit=5, # 返回结果的最大数量
filter=filter, # 过滤条件
output_fields=["product_id", "metadata"] # 返回字段
)示例:过滤嵌套字段 supplier"country" 等于 "USA"
python
# 定义过滤表达式
filter = 'metadata["supplier"]["country"] == "USA"'
res = client.search(
collection_name="product_catalog", # 集合名称
data=[[0.1, 0.2, 0.3, 0.4, 0.5]], # 查询向量
limit=5,
filter=filter,
output_fields=["product_id", "metadata"]
)
print(res)Milvus 还提供了一些专门用于 JSON 数组查询的操作符,例如:
-
json_contains(identifier, expr)判断 JSON 数组中是否包含某个元素或子数组
-
json_contains_all(identifier, expr)判断 JSON 数组是否包含所有指定元素
-
json_contains_any(identifier, expr)判断 JSON 数组是否至少包含其中一个元素
示例:查找 tags 中包含 "summer_sale" 的商品
python
# 定义过滤表达式
filter = 'json_contains(metadata["tags"], "summer_sale")'
res = client.search(
collection_name="product_catalog",
data=[[0.1, 0.2, 0.3, 0.4, 0.5]],
limit=5,
filter=filter,
output_fields=["product_id", "metadata"]
)
print(res)示例:查找 tags 中包含任意一个指定值的商品
python
# 定义过滤表达式
filter = 'json_contains_any(metadata["tags"], ["electronics", "new", "clearance"])'
res = client.search(
collection_name="product_catalog",
data=[[0.1, 0.2, 0.3, 0.4, 0.5]],
limit=5,
filter=filter,
output_fields=["product_id", "metadata"]
)
print(res)更多关于 JSON 专用操作符的内容,可以参考 JSON Operators。
默认情况下,如果对 JSON 字段进行查询但没有启用加速机制,会对所有行执行全表扫描。在大规模数据集上,这可能会比较慢。为了提升 JSON 查询性能,Milvus 提供了高级索引与存储优化能力。
下表总结了不同优化技术的区别及适用场景:
| 技术 | 适用场景 | 数组加速 | 说明 |
|---|---|---|---|
| JSON Indexing | 少量高频访问 key,或特定 array key 上的数组查询 | 支持(仅索引的 array key) | 需要预先选择 key,如果 schema 变化需要维护 |
| JSON Shredding | 多 key 通用加速、适用于多样化查询 | 不支持(不会加速数组内部值) | 需要额外存储配置,数组仍需单独索引 |
| NGRAM Index | 通配符搜索、文本子串匹配 | 不适用 | 不适用于数值或范围查询 |
你可以组合使用这些方法,例如:
- 使用 JSON Shredding 提升整体查询性能
- 对高频 array key 使用 JSON Indexing
- 对文本字段使用 NGRAM Indexing 做灵活模糊搜索
注意事项:
-
JSON 字段大小有限制吗?
单个 JSON 字段最大为 65,536 bytes。
-
JSON 字段支持默认值吗?
不支持。
但可以在定义字段时设置
nullable=True来允许空值。更多信息参考:Nullable & Default。
-
JSON key 命名有什么规范?
为了保证查询与索引兼容性:
- 仅允许使用字母、数字和下划线
- 避免使用特殊字符、空格或点号(如
. /等)
不符合规范的 key 可能会导致过滤表达式解析失败。
-
Milvus 如何处理 JSON 中的字符串?
Milvus 会原样存储 JSON 字符串,不会进行语义转换。
如果字符串引号使用不当,可能会在解析时报错。
合法示例:
"a\"b","a'b","a\\b"
非法示例:
'a"b','a\'b'
JSON 索引(JSON Indexing)
JSON 字段在 Milvus 中提供了一种灵活存储结构化元数据的方式。但如果不建立索引,对 JSON 字段的查询会退化为全表扫描,随着数据量增长会明显变慢。JSON 索引可以通过在 JSON 数据内部创建索引,实现快速查询。
JSON 索引适用于:
- 结构化 schema 且 key 相对固定的场景
- 对特定 JSON path 做等值或范围查询
- 需要精确控制哪些 key 参与索引的场景
- 面向特定字段的存储优化型加速查询
对于结构复杂、查询模式多变的 JSON 文档,可以考虑使用 JSON Shredding 作为替代方案。
创建 JSON 索引时,需要指定:
- JSON path:要索引的数据位置
- 数据类型(cast type):索引时如何解释数据
- 可选类型转换函数:索引时对数据进行类型转换
索引写法示例
python
# 准备索引参数
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="<json_field_name>", # JSON 字段名称
index_type="AUTOINDEX", # 必须是 AUTOINDEX 或 INVERTED
index_name="<unique_index_name>", # 索引名称
params={
"json_path": "<path_to_json_key>", # JSON 内要索引的 key 路径
"json_cast_type": "<data_type>", # 该字段的目标数据类型
# "json_cast_function": "<cast_function>" # 可选:索引时进行类型转换
}
)参数说明
| 参数 | 说明 | 示例 |
|---|---|---|
| field_name | JSON 字段名 | "metadata" |
| index_type | 索引类型(必须是 AUTOINDEX 或 INVERTED) | "AUTOINDEX" |
| index_name | 索引名称(唯一) | "category_index" |
| json_path | JSON 内部字段路径 | 'metadata["category"]' / 'metadata["supplier"]["contact"]["email"]' / 'metadata' |
| json_cast_type | 索引时的数据类型 | "VARCHAR" |
| json_cast_function | 可选类型转换函数 | "STRING_TO_DOUBLE" |
Milvus 支持在索引阶段将 JSON 数据转换为以下类型,以便更高效地过滤:
| 类型 | 说明 | 示例 |
|---|---|---|
| BOOL / bool | 布尔类型,用于 true/false 查询 | true, false |
| DOUBLE / double | 数值类型(整数/浮点均可) | 42, 99.99 |
| VARCHAR / varchar | 字符串类型 | "electronics", "BrandA" |
| ARRAY_BOOL / array_bool | 布尔数组 | true, false |
| ARRAY_DOUBLE / array_double | 数值数组 | 1.2, 3.14, 42 |
| ARRAY_VARCHAR / array_varchar | 字符串数组 | "tag1", "tag2" |
| JSON / json | 整个 JSON 对象或子对象 | 任意 JSON 结构 |
👉 注意:数组内部元素类型必须一致,否则无法高效索引。
更多细节参考 Array Field。
当 JSON 数据类型不规范时(例如数字以字符串存储),可以通过 json_cast_function 在索引时进行转换。
| 函数 | 转换 | 使用场景 |
|---|---|---|
| STRING_TO_DOUBLE / string_to_double | 字符串 → 数值 | 将 "99.99" 转为 99.99 |
如果转换失败(例如非数字字符串),该值会被跳过,不会进入索引。
创建 JSON 索引(Create JSON Indexes)
示例 JSON 结构
json
{
"metadata": {
"category": "electronics",
"brand": "BrandA",
"in_stock": true,
"price": 99.99,
"string_price": "99.99",
"tags": ["clearance", "summer_sale"],
"supplier": {
"name": "SupplierX",
"country": "USA",
"contact": {
"email": "support@supplierx.com",
"phone": "+1-800-555-0199"
}
}
}
}在创建任何 JSON 索引之前,需要先准备索引参数:
python
# 准备索引参数
index_params = MilvusClient.prepare_index_params()示例 1:索引简单 JSON key
为 category 字段创建索引,以支持按商品类别的快速过滤:
python
index_params.add_index(
field_name="metadata",
index_type="AUTOINDEX", # JSON path 索引必须是 AUTOINDEX 或 INVERTED
index_name="category_index", # 唯一索引名称
params={
"json_path": 'metadata["category"]', # JSON key 路径
"json_cast_type": "varchar" # 数据类型
}
)示例 2:索引嵌套 key
为嵌套字段 supplier.contact.email 创建索引,用于供应商邮箱搜索:
python
index_params.add_index(
field_name="metadata",
index_type="AUTOINDEX",
index_name="email_index",
params={
"json_path": 'metadata["supplier"]["contact"]["email"]',
"json_cast_type": "varchar"
}
)示例 3:索引时进行类型转换
当数值被错误存成字符串时,可以使用 STRING_TO_DOUBLE 在索引阶段转换类型:
python
index_params.add_index(
field_name="metadata",
index_type="AUTOINDEX",
index_name="string_to_double_index",
params={
"json_path": 'metadata["string_price"]',
"json_cast_type": "double",
"json_cast_function": "STRING_TO_DOUBLE"
}
)⚠️ 注意:如果某条数据转换失败(例如 "invalid" 这种非数字字符串),该值会被跳过,不会进入索引,也不会出现在过滤结果中。
示例 4:索引整个 JSON 对象
可以对整个 JSON 对象建立索引,从而支持对任意字段的查询。
当 json_cast_type="JSON" 时,系统会自动:
- 展平 JSON 结构(nested key 变为平坦路径)
- 自动推断数据类型(数值 / 字符串 / 布尔 / 日期等)
- 覆盖所有 key 和嵌套路径,使其可查询
python
index_params.add_index(
field_name="metadata",
index_type="AUTOINDEX",
index_name="metadata_full_index",
params={
"json_path": "metadata",
"json_cast_type": "JSON"
}
)也可以只索引部分结构,例如 supplier:
python
index_params.add_index(
field_name="metadata",
index_type="AUTOINDEX",
index_name="supplier_index",
params={
"json_path": 'metadata["supplier"]',
"json_cast_type": "JSON"
}
)定义完所有索引后,将其应用到 collection:
python
MilvusClient.create_index(
collection_name="your_collection_name",
index_params=index_params
)索引完成后,JSON 查询会自动使用这些索引,从而显著提升性能。
注意事项:
-
如果查询类型和索引类型不一致会怎样?
如果 filter 里的类型和
json_cast_type不一致,Milvus 可能不会使用索引,而退化为全表扫描(性能较慢)。👉 最佳实践:
确保 filter 类型与索引 cast 类型一致,例如:
json_cast_type="double"→ 必须用数值比较(>, <, ==)
-
JSON key 在不同记录中类型不一致怎么办?
可能导致部分索引失效。
例如:
99.99(数值)"99.99"(字符串)
如果索引是
double:- 数值会被索引
- 字符串会被跳过
-
同一个 JSON key 可以建多个索引吗?
不可以。每个 JSON key 只能创建一个索引。
但可以:
- 索引整个 JSON 对象
- 同时索引某个嵌套 key
-
JSON 字段支持默认值吗?
不支持。
但可以设置:
textnullable=True来允许空值。
JSON Shredding
JSON Shredding 通过将传统的行式存储转换为优化后的列式存储来加速 JSON 查询。在保留 JSON 数据建模灵活性的同时,Milvus 在底层执行列式优化,从而显著提升数据访问与查询效率。
JSON Shredding 对大多数 JSON 查询场景都有效。当满足以下条件时,其性能提升尤为明显:
- 更大、更复杂的 JSON 文档:文档越大,性能收益越明显
- 读多写少的工作负载:对 JSON key 进行频繁过滤、排序或检索
- 混合查询模式:跨不同 JSON key 的查询可受益于混合存储方式
JSON Shredding 的处理过程分为三个阶段,以实现高效查询优化。
阶段 1:数据写入与 Key 分类
当新的 JSON 文档写入时,Milvus 会持续采样并分析数据,为每个 JSON key 构建统计信息,包括出现频率以及类型稳定性(即该 key 在不同文档中的数据类型是否一致)。
基于这些统计信息,JSON key 会被划分为以下几类:
| Key 类型 | 描述 |
|---|---|
| Typed keys(类型稳定键) | 在大多数文档中存在,并且数据类型始终一致(例如始终为整数或字符串) |
| Dynamic keys(动态键) | 经常出现,但数据类型混合(例如有时是字符串,有时是整数) |
| Shared keys(共享键) | 出现频率较低或嵌套较深的键,低于配置阈值 |
考虑如下 JSON 数据:
json
{"a": 10, "b": "str1", "f": 1}
{"a": 20, "b": "str2", "f": 2}
{"a": 30, "b": "str3", "f": 3}
{"a": 40, "b": 1, "f": 4} // b 变为混合类型
{"a": 50, "b": 2, "e": "rare"} // e 出现频率低分类结果如下:
- Typed keys:
a、f(始终为整数) - Dynamic keys:
b(字符串/整数混合) - Shared keys:
e(低频出现)
阶段 2:存储优化
基于第一阶段的分类结果,Milvus 会调整存储结构并采用列式优化格式。
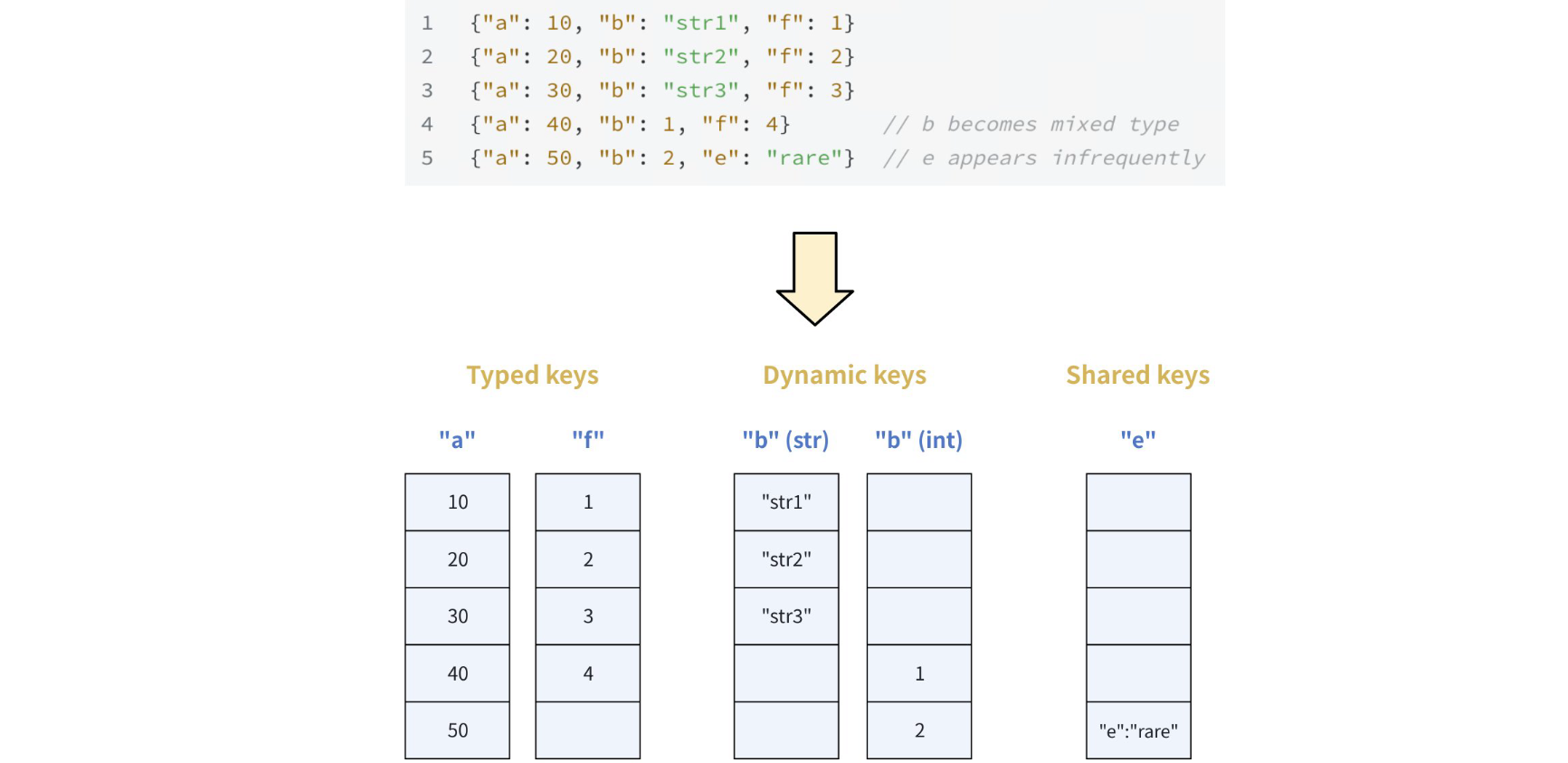
-
Shredded columns(拆分列)
对于 typed keys 和 dynamic keys,会写入独立列中。查询时可以直接扫描相关列,无需解析完整 JSON 文档,从而提升查询速度。
-
Shared column(共享列)
所有 shared keys 会存储在一个统一的紧凑二进制 JSON 列中,并在其上构建倒排索引。
该索引用于加速低频 key 查询,通过快速过滤数据,缩小扫描范围。
阶段 3:查询执行
查询阶段会根据 predicate 自动选择最优执行路径:
-
快速路径(Fast path)
针对 typed/dynamic keys(例如
json['a'] < 100),直接访问专用列 -
优化路径(Optimized path)
针对 shared keys(例如
json['e'] = 'rare'),使用倒排索引快速定位数据
在 milvus.yaml 中设置:
yaml
common:
enabledJSONShredding: true启用后,新写入的数据会自动触发 shredding 处理,无需额外操作。
大多数情况下默认配置已足够,但可以根据需求进行调整:
| 参数 | 描述 | 默认值 | 建议 |
|---|---|---|---|
common.enabledJSONShredding |
是否启用 JSON shredding 构建与加载 | false | 必须设为 true 才生效 |
common.usingjsonShreddingForQuery |
是否使用 shredding 加速查询 | true | 出现异常时可关闭以回退旧路径 |
queryNode.mmap.jsonShredding |
是否使用 mmap 加载 shredding 数据 | true | 一般保持默认,仅在内存受限时调整 |
dataCoord.jsonShreddingMaxColumns |
shredded columns 最大 key 数 | 1024 | JSON key 非常多时可适当提高 |
dataCoord.jsonShreddingRatioThreshold |
key 被纳入 shredding 的最低出现比例 | 0.3 | 提高该值可减少参与 shredding 的 key 数;降低则扩大覆盖范围 |
如何选择 JSON Shredding vs JSON Indexing?
JSON Shredding 适合:
- 文档中 key 出现频繁
- JSON 结构复杂
- 读多写少的场景
- 多 key 混合查询
但:
- 小 JSON 文档收益较低
- key 在整个 JSON 中占比越小,收益越大
- 不支持数组内部 key 的加速(这一点需要 JSON Index)
JSON Indexing 适合:
- 明确的 key 定向查询
- 结构简单的 JSON
- 更低存储开销
- 数组 key 的加速需求
动态字段(Dynamic Field)
Milvus 允许你通过一个特殊功能------动态字段(dynamic field) ------来插入结构灵活、可演进的实体数据。该功能通过一个名为 $meta 的隐藏 JSON 字段 实现,它会自动存储所有在 schema 中未显式定义的字段。
当启用动态字段后,Milvus 会在每条实体中自动添加一个隐藏字段 $meta。该字段类型为 JSON,因此可以存储任意 JSON 兼容的数据结构,并支持使用 JSON path 语法进行索引和查询。
在数据写入时,所有未在 schema 中声明的字段都会自动以 key-value 形式存入该动态字段中。
你无需手动管理 $meta,Milvus 会自动处理。
例如,如果你的 collection schema 只定义了 id 和 vector,但插入如下数据:
json
{
"id": 1,
"vector": [0.1, 0.2, 0.3],
"name": "Item A",
"category": "books"
}其中 name 和 category 未在 schema 中定义。
在启用动态字段后,Milvus 内部会将其存储为:
json
{
"id": 1,
"vector": [0.1, 0.2, 0.3],
"$meta": {
"name": "Item A",
"category": "books"
}
}这样,你可以在不修改 schema 的情况下持续扩展数据结构。
常见使用场景
- 存储可选字段或低频字段
- 记录随实体变化的元数据
- 通过对
$meta中特定 key 建索引,实现灵活过滤
动态字段支持 Milvus 提供的所有标量类型,这些类型用于 $meta 内 key 的 value:
支持类型包括:
- 字符串(VARCHAR)
- 整型(INT8 / INT32 / INT64)
- 浮点数(FLOAT / DOUBLE)
- 布尔值(BOOL)
- 标量数组(ARRAY)
- JSON 对象(JSON)
示例:
json
{
"brand": "Acme",
"price": 29.99,
"in_stock": true,
"tags": ["new", "hot"],
"specs": {
"weight": "1.2kg",
"dimensions": { "width": 10, "height": 20 }
}
}上述所有字段都会存储在 $meta 中。
在创建 schema 时设置enable_dynamic_field=True即可启动动态字段:
python
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
schema = client.create_schema(
auto_id=False,
enable_dynamic_field=True,
)
schema.add_field(field_name="my_id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="my_vector", datatype=DataType.FLOAT_VECTOR, dim=5)
client.create_collection(
collection_name="my_collection",
schema=schema
)动态字段允许你插入 schema 中未定义的字段,这些字段会自动写入 $meta。
python
entities = [
{
"my_id": 1,
"my_vector": [0.1, 0.2, 0.3, 0.4, 0.5],
"overview": "Great product",
"words": 150,
"dynamic_json": {
"varchar": "some text",
"nested": {
"value": 42.5
},
"string_price": "99.99"
}
}
]
client.insert(collection_name="my_collection", data=entities)在动态字段中为 Key 建索引(Index keys in the dynamic field)
Milvus 支持使用 JSON path 索引(JSON path indexing),对动态字段中的指定 key 创建索引。这些 key 可以是标量值,也可以是 JSON 对象中的嵌套字段。
对动态字段 key 建索引是可选的。即使不创建索引,也可以对这些 key 进行查询或过滤,但性能会较慢,因为需要进行全表扫描(brute-force search)。
创建 JSON path 索引时,需要指定:
-
JSON path(json_path):要索引的 JSON key 或嵌套字段路径
- 示例:
metadata["category"] - 表示索引引擎在 JSON 结构中的具体位置
- 示例:
-
JSON cast type(json_cast_type):Milvus 在索引时用于解析该字段值的数据类型
- 必须与实际字段数据类型一致
- 具体类型列表参考 Supported JSON cast types
由于动态字段本质是 JSON 字段,因此可以使用 JSON path 对其中任意 key 建索引,包括简单标量和复杂嵌套结构。
JSON path 示例:
- 简单 key:
overview、words - 嵌套 key:
dynamic_json['varchar']、dynamic_json['nested']['value']
python
index_params = client.prepare_index_params()
# 索引简单字符串 key
index_params.add_index(
field_name="overview",
index_type="AUTOINDEX",
index_name="overview_index",
params={
"json_cast_type": "varchar",
"json_path": "overview"
}
)
# 索引简单数值 key
index_params.add_index(
field_name="words",
index_type="AUTOINDEX",
index_name="words_index",
params={
"json_cast_type": "double",
"json_path": "words"
}
)
# 索引 JSON 对象中的嵌套 key
index_params.add_index(
field_name="dynamic_json",
index_type="AUTOINDEX",
index_name="json_varchar_index",
params={
"json_cast_type": "varchar",
"json_path": "dynamic_json['varchar']"
}
)
# 索引更深层嵌套 key
index_params.add_index(
field_name="dynamic_json",
index_type="AUTOINDEX",
index_name="json_nested_index",
params={
"json_cast_type": "double",
"json_path": "dynamic_json['nested']['value']"
}
)如果动态字段 key 的数据格式不规范(例如数字被存成字符串),可以使用 cast 函数在建索引时进行转换:
python
index_params.add_index(
field_name="dynamic_json",
index_type="AUTOINDEX",
index_name="json_string_price_index",
params={
"json_path": "dynamic_json['string_price']",
"json_cast_type": "double",
"json_cast_function": "STRING_TO_DOUBLE"
}
)如果类型转换失败(例如 "not_a_number" 这种无法转为数字的字符串),该值会被跳过,不会被索引。
应用索引到 collection
python
client.create_index(
collection_name="my_collection",
index_params=index_params
)插入动态字段 key 后,可以使用标准 filter 表达式进行过滤:
- 非 JSON key(字符串/数字/布尔)可以直接引用
- JSON 对象 key 使用 JSON path
示例:
python
filter = 'overview == "Great product"'
filter = 'words >= 100'
filter = 'dynamic_json["nested"]["value"] < 50'动态字段 key 默认不会返回 ,必须在 output_fields 中显式指定:
python
results = client.search(
collection_name="my_collection",
data=[[0.1, 0.2, 0.3, 0.4, 0.5]],
filter=filter,
limit=10,
output_fields=[
"overview",
'dynamic_json["varchar"]'
]
)重要说明
- 动态字段 key 不会默认返回
- 必须显式指定
output_fields - JSON path 语法需与过滤语法一致
Nullable 与默认值(Nullable & Default)
Milvus 允许你为标量字段(primary field 除外)设置 nullable 属性和默认值。
对于标记为 nullable=True 的字段,在插入数据时可以选择不提供该字段,或者显式设置为 null,系统会将其视为 null 处理,不会报错。
当字段设置了默认值时,如果插入数据时未提供该字段,系统会自动使用默认值填充。
nullable 与默认值的能力可以简化从其他数据库迁移到 Milvus 的过程,使得处理包含空值的数据集以及保留默认值逻辑更加方便。在创建 collection 时,可以为可能缺失数据的字段启用这两个能力。
限制(Limits)
-
只有标量字段(scalar fields,且不包括主键字段)支持默认值和
nullable属性 -
JSON 和 Array 字段不支持默认值
-
默认值与
nullable属性只能在创建 collection 时设置,之后不可修改 -
标记为
nullable的字段不能作为分区键(partition key),详情参考 Partition Key -
对启用了
nullable的标量字段创建索引时,null值会被排除在索引之外 -
JSON 和 ARRAY 字段在使用
IS NULL/IS NOT NULL时,是按列级别判断:- 只判断整个 JSON/ARRAY 是否为 null
- 不会识别 JSON 内部某个 key 是否为 null
- 详情参考 Basic Operators
nullable 属性允许字段存储 null 值,从而在处理不完整数据时更灵活。
创建 collection 时通过 nullable=True 开启(默认是 False)。
示例:创建一个名为 my_collection 的集合,并将 age 字段设为可空:
python
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri='http://localhost:19530')
schema = client.create_schema(
auto_id=False,
enable_dynamic_schema=True,
)
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=5)
schema.add_field(field_name="age", datatype=DataType.INT64, nullable=True)
index_params = client.prepare_index_params()
index_params.add_index(field_name="vector", index_type="AUTOINDEX", metric_type="L2")
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)在 nullable 字段中,可以:
- 插入
null - 或者直接省略该字段
python
data = [
{"id": 1, "vector": [0.1, 0.2, 0.3, 0.4, 0.5], "age": 30},
{"id": 2, "vector": [0.2, 0.3, 0.4, 0.5, 0.6], "age": None},
{"id": 3, "vector": [0.3, 0.4, 0.5, 0.6, 0.7]}
]
client.insert(collection_name="my_collection", data=data)查询与搜索中的 null 值
Search(向量搜索)
如果字段包含 null,返回结果中该字段也会显示为 null:
python
res = client.search(
collection_name="my_collection",
data=[[0.1, 0.2, 0.4, 0.3, 0.128]],
limit=2,
search_params={"params": {"nprobe": 16}},
output_fields=["id", "age"]
)返回示例:
text
[
{'id': 1, 'distance': 0.1583, 'entity': {'age': 30, 'id': 1}},
{'id': 2, 'distance': 0.2827, 'entity': {'age': None, 'id': 2}}
]Query(标量过滤)
在使用过滤条件时:
null值参与比较时结果始终为 false- 不会被选中
python
results = client.query(
collection_name="my_collection",
filter="age >= 0",
output_fields=["id", "age"]
)结果:
text
[
{"id": 1, "age": 30}
]查询所有数据(包含 null)
如果想返回 null 值数据,需要不加过滤条件:
python
null_results = client.query(
collection_name="my_collection",
filter="",
output_fields=["id", "age"],
limit=10
)返回示例:
text
[
{"id": 2, "age": None},
{"id": 3, "age": None}
]默认值(Default Values)
默认值是为标量字段预先设置的值。当插入数据时,如果没有为某个具有默认值的字段提供数据,系统会自动使用该默认值。
在创建 collection 时,可以通过 default_value 参数为字段指定默认值。
下面示例将 age 的默认值设置为 18,status 的默认值设置为 "active":
python
schema = client.create_schema(
auto_id=False,
enable_dynamic_schema=True,
)
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=5)
schema.add_field(field_name="age", datatype=DataType.INT64, default_value=18)
schema.add_field(field_name="status", datatype=DataType.VARCHAR, default_value="active", max_length=10)
index_params = client.prepare_index_params()
index_params.add_index(field_name="vector", index_type="AUTOINDEX", metric_type="L2")
client.create_collection(collection_name="my_collection", schema=schema, index_params=index_params)在插入数据时,如果字段:
- 被省略
- 或显式设置为
null
系统都会自动使用默认值。
python
data = [
{"id": 1, "vector": [0.1, 0.2, ..., 0.128], "age": 30, "status": "premium"},
{"id": 2, "vector": [0.2, 0.3, ..., 0.129]}, # age 和 status 使用默认值
{"id": 3, "vector": [0.3, 0.4, ..., 0.130], "age": 25, "status": None}, # status 使用默认值
{"id": 4, "vector": [0.4, 0.5, ..., 0.131], "age": None, "status": "inactive"} # age 使用默认值
]
client.insert(collection_name="my_collection", data=data)带默认值的字段在语义上与普通字段一致:
- 可以参与向量搜索
- 可以参与标量过滤
例如,在搜索时,age = 18(默认值)的实体会被正常返回:
python
res = client.search(
collection_name="my_collection",
data=[[0.1, 0.2, 0.4, 0.3, 0.5]],
search_params={"params": {"nprobe": 16}},
filter="age == 18",
limit=10,
output_fields=["id", "age", "status"]
)返回示例:
text
[
{'id': 2, 'distance': 0.050000004, 'entity': {'id': 2, 'age': 18, 'status': 'active'}},
{'id': 4, 'distance': 0.45000002, 'entity': {'id': 4, 'age': 18, 'status': 'inactive'}}
]Query 示例可以直接用默认值进行过滤:
python
# 查询 age 等于默认值 18 的数据
default_age_results = client.query(
collection_name="my_collection",
filter="age == 18",
output_fields=["id", "age", "status"]
)
# 查询 status 等于默认值 "active" 的数据
default_status_results = client.query(
collection_name="my_collection",
filter='status == "active"',
output_fields=["id", "age", "status"]
)下表总结了 nullable 与 default_value 在不同组合下的行为:
| Nullable | Default Value | 默认值类型 | 用户输入 | 结果 | 示例 |
|---|---|---|---|---|---|
| ✅ | ✅ | 非 null | None/null | 使用默认值 | age=18,输入null → 存18 |
| ✅ | ❌ | - | None/null | 存储 null | middle_name → null |
| ❌ | ✅ | 非 null | None/null | 使用默认值 | status="active" |
| ❌ | ❌ | - | None/null | 报错 | email → 直接拒绝 |
| ❌ | ✅ | null | None/null | 报错 | username 默认null也不允许 |
Analyzer 字段
在文本处理领域,**Analyzer(分析器)**是一个关键组件,用于将原始文本转换为结构化、可检索的格式。
每个 analyzer 通常由两个核心部分组成:
- Tokenizer(分词器)
- Filter(过滤器)
二者共同作用,将输入文本拆分为 token(词元),并对 token 进行清洗与优化,从而用于高效索引与检索。
在 Milvus 中,analyzer 在创建 collection 时配置(当 schema 中包含 VARCHAR 字段时)。
analyzer 生成的 tokens 可以用于:
- 构建关键词索引(keyword matching)
- 转换为稀疏向量(sparse embeddings),用于全文检索(full text search)
使用 analyzer 会对性能产生一定影响:
全文检索(Full Text Search)
- DataNode 和 QueryNode 的数据消费速度会变慢
- 因为必须等待分词完成
- 新写入数据在变得可检索之前需要更长时间
关键词匹配(Keyword Match)
- 索引构建速度变慢
- 因为必须等待分词完成后才能建立索引
Milvus 的 analyzer 由以下部分组成:
- 1 个 tokenizer
- 0 个或多个 filter
Tokenizer 用于将文本拆分成离散的 token(词元),这些 token 可以是:
- 单词(words)
- 短语(phrases)
具体取决于 tokenizer 类型。
Filter 用于对 token 进行进一步处理,例如:
- 转为小写(lowercase)
- 去除停用词(stop words)
⚠️ 目前 tokenizer 仅支持 UTF-8 编码,未来版本将支持更多格式。
Milvus 提供两类 analyzer:
-
内置 analyzer(Built-in Analyzer)
- 预定义配置
- 开箱即用
- 无需复杂设置
- 适用于通用场景
-
自定义 analyzer(Custom Analyzer)
- 可自定义 tokenizer
- 可自定义 filter(0 个或多个)
- 适用于高级场景
- 用于精细控制文本处理逻辑
如果在创建 collection 时未配置 analyzer:
👉 Milvus 默认使用 standard analyzer
为了获得更好的检索效果,应根据语言选择 analyzer:
- 英语:standard / english
- 中文、日文、韩文:推荐使用语言专用 analyzer 或自定义 tokenizer(如
lindera,icu等)
⚠️ standard analyzer 对多语言(尤其 CJK)不一定最优。
内置 Analyzer(Built-in Analyzer)
Milvus 中的内置 analyzer 是预先配置好的分词器(tokenizer)和过滤器(filter)组合,用户可以直接使用,无需自行定义组件。
每个内置 analyzer 本质上是一个模板,包含:
- 预设 tokenizer
- 预设 filter
- 可选的参数(用于定制行为)
例如使用 standard 内置 analyzer,只需在 type 中指定名称即可,并可选择性添加参数,例如 stop_words:
python
analyzer_params = {
"type": "standard", # 使用 standard 内置 analyzer
"stop_words": ["a", "an", "for"] # 定义需要过滤的停用词
}可以使用 run_analyzer 方法查看分词结果:
python
text = "An efficient system relies on a robust analyzer to correctly process text for various applications."
result = client.run_analyzer(
text,
analyzer_params
)输出结果
text
['efficient', 'system', 'relies', 'on', 'robust', 'analyzer', 'to', 'correctly', 'process', 'text', 'various', 'applications']可以看到:
- 停用词
"a","an","for"被成功过滤 - 其余有意义的词被保留下来并正确分词
上面的 standard 内置 analyzer 等价于以下自定义配置:
python
analyzer_params = {
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stop",
"stop_words": ["a", "an", "for"]
}
]
}Milvus 提供以下内置 analyzer,每个针对不同文本场景设计:
standard
- 通用文本处理
- 标准分词 + 小写化处理
english
- 针对英文优化
- 内置英文停用词支持
chinese
- 针对中文文本优化
- 支持中文语言结构的分词处理
自定义分析器(Custom analyzer)
对于更高级的文本处理需求,Milvus 中的自定义分析器允许你通过指定 分词器(tokenizer) 和 过滤器(filter) 来构建一个定制化的文本处理流水线。这种方式非常适合需要精细控制的特殊场景。
分词器是自定义分析器中必选组件,它是整个分析流程的起点,用于将输入文本拆分为独立的单元(tokens)。
分词规则取决于具体的 tokenizer 类型,例如按空格或标点符号切分。这样可以让每个词或短语被独立处理。
例如,文本:
"Vector Database Built for Scale"会被分词为:
text
["Vector", "Database", "Built", "for", "Scale"]tokenizer 配置示例:
python
analyzer_params = {
"tokenizer": "whitespace",
}过滤器是可选组件,用于对 tokenizer 输出的 tokens 进行进一步加工或清洗。
例如,对分词结果:
text
["Vector", "Database", "Built", "for", "Scale"]应用 lowercase 过滤器后:
text
["vector", "database", "built", "for", "scale"]过滤器可以是内置的,也可以是自定义的。
Milvus 提供了一些开箱即用的过滤器,只需指定名称即可使用:
- lowercase:将文本转换为小写,实现大小写不敏感匹配(参考 Lowercase)
- asciifolding:将非 ASCII 字符转换为 ASCII 等价形式(参考 ASCII folding)
- alphanumonly:只保留字母和数字,移除其他字符(参考 Alphanumonly)
- cnalphanumonly:只保留中文字符、英文字母和数字(参考 Cnalphanumonly)
- cncharonly:只保留中文字符(参考 Cncharonly)
示例:
python
analyzer_params = {
"tokenizer": "standard", # 必须:指定分词器
"filter": ["lowercase"], # 可选:内置过滤器
}自定义过滤器允许你针对特定需求进行更细粒度配置。
你需要指定 type 并根据类型提供对应参数。
常见可自定义过滤器类型包括:
- stop:移除停用词(如 "of", "to")(参考 Stop)
- length:根据长度过滤 token(例如限制最大长度)(参考 Length)
- stemmer:词干提取,将单词还原为词根(参考 Stemmer)
示例(自定义 stop filter):
python
analyzer_params = {
"tokenizer": "standard", # 必须
"filter": [
{
"type": "stop",
"stop_words": ["of", "to"]
}
]
}使用示例(Example use)
在这个示例中,你将创建一个集合 schema,其中包含:
-
一个用于向量嵌入(embeddings)的向量字段
-
两个 VARCHAR 文本字段,用于文本处理:
- 一个使用内置分析器(built-in analyzer)
- 另一个使用自定义分析器(custom analyzer)
在将这些配置应用到集合之前,你会先通过 run_analyzer 方法分别验证每个分析器的效果。
Step 1:初始化 MilvusClient 并创建 schema
首先初始化 Milvus 客户端,并创建一个新的 schema。
python
from pymilvus import MilvusClient, DataType
# 初始化 Milvus client
client = MilvusClient(uri="http://localhost:19530")
# 创建 schema
schema = client.create_schema(auto_id=True, enable_dynamic_field=False)Step 2:定义并验证 analyzer 配置
配置并验证内置分析器(english)
配置: 使用内置英文分析器
验证: 使用 run_analyzer 确认分词结果是否符合预期
python
# 内置英文分析器配置
analyzer_params_built_in = {
"type": "english"
}
# 验证内置分析器
sample_text = "Milvus simplifies text analysis for search."
result = client.run_analyzer(sample_text, analyzer_params_built_in)
print("Built-in analyzer output:", result)预期输出:
text
['milvus', 'simplifi', 'text', 'analysi', 'search']配置并验证自定义分析器
配置:
- 使用 standard tokenizer
- 使用 lowercase 过滤器
- 添加 length 过滤器(限制 token 长度)
- 添加 stop words 过滤器
验证: 使用 run_analyzer 检查结果是否符合预期
python
# 自定义分析器配置
analyzer_params_custom = {
"tokenizer": "standard",
"filter": [
"lowercase", # 转小写
{
"type": "length", # 限制 token 长度
"max": 40
},
{
"type": "stop", # 停用词过滤
"stop_words": ["of", "for"]
}
]
}
# 验证自定义分析器
sample_text = "Milvus provides flexible, customizable analyzers for robust text processing."
result = client.run_analyzer(sample_text, analyzer_params_custom)
print("Custom analyzer output:", result)预期输出:
text
['milvus', 'provides', 'flexible', 'customizable', 'analyzers', 'robust', 'text', 'processing']Step 3:将字段添加到 schema
在验证完成后,将 analyzer 配置应用到字段中。
-
使用内置分析器的字段
title_enpythonschema.add_field( field_name='title_en', datatype=DataType.VARCHAR, max_length=1000, enable_analyzer=True, analyzer_params=analyzer_params_built_in, enable_match=True, ) -
使用自定义分析器的字段
titlepythonschema.add_field( field_name='title', datatype=DataType.VARCHAR, max_length=1000, enable_analyzer=True, analyzer_params=analyzer_params_custom, enable_match=True, ) -
添加向量字段
pythonschema.add_field( field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=3 ) -
添加主键字段
pythonschema.add_field( field_name="id", datatype=DataType.INT64, is_primary=True )
Step 4:准备索引参数并创建集合
python
# 向量字段索引
index_params = client.prepare_index_params()
index_params.add_index(
field_name="embedding",
metric_type="COSINE",
index_type="AUTOINDEX"
)
# 创建集合
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)修改集合字段(Alter Collection Field)
你可以修改集合字段的属性,以改变列约束或强化数据完整性规则。
需要注意的是:
-
每个集合只能有 一个主键字段(primary field)
- 在创建集合时已经确定后,不能修改主键字段或其属性
-
每个集合只能有 一个分区键(partition key)
- 在创建时确定后,不能修改分区键
VarChar 字段有一个属性 max_length,用于限制字段值的最大字符数。你可以修改这个属性。
下面示例假设集合中有一个名为 varchar 的 VarChar 字段,并修改它的 max_length:
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
client.alter_collection_field(
collection_name="my_collection",
field_name="varchar",
field_params={
"max_length": 1024
}
)数组字段(ARRAY field)有两个属性:
element_type:定义数组元素的数据类型max_capacity:限制数组中元素的最大数量
其中:
element_type不可修改- 只能修改
max_capacity
下面示例假设集合中有一个名为 array 的数组字段,并修改其 max_capacity:
python
client.alter_collection_field(
collection_name="my_collection",
field_name="array",
field_params={
"max_capacity": 64
}
)内存映射(Mmap)允许直接访问磁盘上的大文件,使 Milvus 可以同时在内存和磁盘中存储索引与数据。
这种机制可以根据访问频率优化数据分布,在不影响搜索性能的情况下扩展存储能力。
下面示例假设集合中有一个字段 doc_chunk,并启用 mmap:
python
client.alter_collection_field(
collection_name="my_collection",
field_name="doc_chunk",
field_params={"mmap.enabled": True}
)向已有集合中添加字段(Add Fields to an Existing Collection)
Milvus 支持在已有集合中动态新增字段,这使得你可以随着业务需求变化灵活扩展数据结构。
在向集合添加字段前,请注意以下限制:
- 可以添加标量字段(scalar fields) ,如 INT64、VARCHAR、FLOAT、DOUBLE 等
❌ 不能向已有集合添加向量字段(vector field) - 新增字段必须设置为 nullable=True
(用于兼容历史数据中没有该字段的记录) - 向已加载(loaded)的集合添加字段会增加内存占用
- 每个集合的字段数量存在上限(详见 Milvus Limits)
- 字段名在静态字段中必须唯一
- 对于未启用
enable_dynamic_field=True创建的集合,不能新增$meta字段来开启动态字段功能
python
from pymilvus import MilvusClient, DataType
# 连接 Milvus 服务
client = MilvusClient(
uri="http://localhost:19530"
)场景 1:快速添加可为空字段(nullable field)
最简单的扩展方式是添加可为空字段,适用于快速新增属性的场景。
python
client.add_collection_field(
collection_name="product_catalog",
field_name="created_timestamp", # 新字段名称
data_type=DataType.INT64, # 标量类型
nullable=True # 必须为 True
)行为说明:
- 操作几乎立即返回(非阻塞)
- 新字段会很快生效(存在短暂同步延迟)
- 所有已有数据默认值为 NULL
- 新数据可以写 NULL 或实际值
查询结果示例:
json
{
"id": 1,
"created_timestamp": null
}场景 2:添加带默认值的字段
如果希望旧数据不显示 NULL,而是有一个默认值,可以设置 default_value。
python
client.add_collection_field(
collection_name="product_catalog",
field_name="priority_level", # 新字段
data_type=DataType.VARCHAR, # 字符串类型
max_length=20, # 字符串长度限制
nullable=True, # 必须为 True
default_value="standard" # 默认值
)行为说明:
- 所有已有记录会自动填充默认值
- 新数据若未提供该字段,也会使用默认值
- 字段几乎立即可用(短暂同步延迟)
查询结果示例:
json
{
"id": 1,
"priority_level": "standard"
}最佳实践
搜索系统的数据模型设计
信息检索系统(Information Retrieval Systems),也称为搜索引擎,是许多 AI 应用的核心基础能力,例如检索增强生成(RAG)、视觉搜索以及商品推荐系统。这些系统的核心在于一个经过精心设计的数据模型,用于组织、索引并高效检索信息。
Milvus 允许你通过集合(Collection)Schema 来定义搜索数据模型,将非结构化数据、其对应的稠密或稀疏向量表示,以及结构化元数据统一组织起来。无论你处理的是文本、图像还是其他数据类型,这份实践指南都将帮助你理解并应用关键 Schema 概念,从而设计出可用的搜索数据模型。

搜索系统的数据模型设计,本质上是分析业务需求,并将信息抽象为 Schema 表达的数据结构。一个良好的 Schema 不仅有助于对齐业务目标,还能保证数据一致性与服务质量。同时,合理选择数据类型与索引方式,对成本与性能也至关重要。
一、业务需求分析
要有效满足业务需求,首先需要分析用户会提出哪些查询,以及这些查询对应的检索方式。
需要明确用户可能执行的查询类型,从而保证 Schema 覆盖真实场景并优化性能,例如:
- 基于自然语言检索文档
- 根据参考图片或文本描述进行相似搜索
- 按名称、类别、品牌等属性检索商品
- 基于结构化元数据过滤(如时间、标签、评分)
- 多条件混合查询(如视觉搜索中同时考虑图像语义与文本描述)
根据用户查询类型选择合适的检索方式,常见方式包括:
- 语义检索(Semantic Search):基于稠密向量相似度,适用于文本、图像等非结构化数据
- 全文检索(Full-text Search):结合关键词匹配与词法分析,用于提升精确检索能力
- 元数据过滤(Metadata Filtering):在向量检索基础上增加条件过滤(如时间范围、类别)
二、将业务需求转为数据模型
下一步是将业务需求转化为具体的数据模型,明确核心数据组成及其检索方式:
需要存储的数据类型包括:
- 原始内容(文本、图片、音频等)
- 元数据(标题、标签、作者等)
- 上下文属性(时间戳、用户行为等)
数据类型映射示例:
- 文本描述 → string(VARCHAR)
- 图像 / 文档向量 → dense / sparse vector
- 分类 / 标签 → string / array / bool
- 数值属性(价格、评分) → int / float
- 结构化信息(作者、供应商) → JSON
三、Schema 设计
在 Milvus 中,数据模型通过 Collection Schema 表达。
Schema 设计的关键在于合理定义字段,每个字段代表一种数据类型,并在检索过程中承担不同角色。
Milvus 的字段主要分为两类:
- 向量字段(Vector Field)
- 标量字段(Scalar Field)
向量字段用于存储非结构化数据的嵌入表示,例如文本、图像、音频等。
根据数据类型不同,向量可以是:
- 稠密向量(Dense Vector):用于语义检索
- 稀疏向量(Sparse Vector):用于全文/词法匹配
- 二进制向量(Binary Vector):用于资源受限场景
一个 Collection 可以包含多个向量字段,用于支持多模态或混合检索。
Milvus 支持的向量类型包括:
- FLOAT_VECTOR(稠密向量)
- SPARSE_FLOAT_VECTOR(稀疏向量)
- BINARY_VECTOR(二进制向量)
标量字段用于存储结构化元数据,例如数字、字符串、日期等。
这些字段可以:
- 与向量结果一起返回
- 用于过滤与排序
- 限制搜索范围(如类别、时间范围)
支持的数据类型包括:
BOOL、INT8/16/32/64、FLOAT、DOUBLE、VARCHAR、JSON、ARRAY
四、Schema 高级能力设计
仅仅映射数据类型是不够的,还需要理解字段之间的关系以及 Milvus 提供的高级能力。
主键用于唯一标识实体,是 Schema 必须字段:
- 类型必须为 INT 或 VARCHAR
- 必须设置
is_primary=True - 可选开启
auto_id
分区用于提升查询效率:
- 通过分区字段限制搜索范围
- 只扫描相关数据分区
- 显著提升检索性能
Analyzer 用于文本处理:
- 将文本转为 token
- 去除停用词
- 词形还原
- 用于全文检索与关键词匹配
Milvus 支持在 Schema 中定义内置函数:
例如:
- BM25:将 VARCHAR 自动转换为稀疏向量
- 支持全文检索
- 实现"自动特征工程"
Milvus 的搜索数据模型本质是:
用 Schema 把 "文本/结构化数据/向量/检索逻辑(analyzer + index + function)" 统一建模成一个可检索系统。
一个真实世界示例
字段设计说明:
| 字段 | 数据来源 | 检索方式 | 主键 | 分区键 | 分析器 | 函数输入/输出 |
|---|---|---|---|---|---|---|
| article_id (INT64) | 自动生成(auto_id) | Get 查询 | 是 | 否 | 否 | 否 |
| title (VARCHAR) | 文章标题 | 文本匹配(Text Match) | 否 | 否 | 是 | 否 |
| timestamp (INT32) | 发布日期 | 按分区过滤 | 否 | 是 | 否 | 否 |
| text (VARCHAR) | 文章原始文本 | 多向量混合检索 | 否 | 否 | 是 | 输入 |
| text_dense_vector (FLOAT_VECTOR) | 文本 embedding 模型生成的稠密向量 | 基础向量检索 | 否 | 否 | 否 | 否 |
| text_sparse_vector (SPARSE_FLOAT_VECTOR) | 由内置 BM25 函数生成的稀疏向量 | 全文检索 | 否 | 否 | 否 | 输出 |
首先创建一个空 Schema,用于定义数据模型的基础结构:
python
from pymilvus import MilvusClient
schema = MilvusClient.create_schema()Schema 创建完成后,需要定义组成数据的各个字段,并指定其数据类型与属性。
python
from pymilvus import DataType
schema.add_field(
field_name="article_id",
datatype=DataType.INT64,
is_primary=True,
auto_id=True,
description="article id"
)
schema.add_field(
field_name="title",
datatype=DataType.VARCHAR,
enable_analyzer=True,
enable_match=True,
max_length=200,
description="article title"
)
schema.add_field(
field_name="timestamp",
datatype=DataType.INT32,
description="publish date"
)
schema.add_field(
field_name="text",
datatype=DataType.VARCHAR,
max_length=2000,
enable_analyzer=True,
description="article text content"
)
schema.add_field(
field_name="text_dense_vector",
datatype=DataType.FLOAT_VECTOR,
dim=768,
description="text dense vector"
)
schema.add_field(
field_name="text_sparse_vector",
datatype=DataType.SPARSE_FLOAT_VECTOR,
description="text sparse vector"
)在本示例中,各字段关键能力如下:
-
主键(Primary Key)
article_id作为主键,并开启auto_id=True,用于自动生成唯一 ID。 -
分区键(Partition Key)
timestamp作为分区键,用于按时间维度进行数据分区过滤。 -
文本分析器(Analyzer)
对
title和text字段启用 analyzer:title:用于文本匹配(Text Match)text:用于全文检索与混合检索
-
函数输入(Function Input)
text作为 BM25 函数输入字段 -
函数输出(Function Output)
text_sparse_vector存储 BM25 生成的稀疏向量
为了增强查询能力,可以在 Schema 中添加函数,用于自动生成衍生字段。
例如:BM25 全文检索函数
python
from pymilvus import Function, FunctionType
bm25_function = Function(
name="text_bm25",
input_field_names=["text"],
output_field_names=["text_sparse_vector"],
function_type=FunctionType.BM25,
)
schema.add_function(bm25_function)该示例将 BM25 内置函数添加到 Schema 中:
- 输入:
text字段 - 输出:
text_sparse_vector字段 - 作用:将文本自动转换为稀疏向量,用于全文检索
这个 Schema 的本质是:
用一个 Collection 同时支持「语义检索(dense vector)+ 关键词检索(BM25 sparse vector)+ 元数据过滤 + 分区优化 + 文本分析」
使用 Struct 数组进行数据模型设计(Array of Structs)
现代 AI 应用,尤其是在物联网(IoT)与自动驾驶领域,通常需要对复杂的结构化事件进行建模与推理。例如:
- 带时间戳与向量嵌入的传感器读数
- 包含错误码与音频片段的诊断日志
- 包含位置、速度与场景上下文的行程片段
这些场景都要求数据库能够原生支持嵌套数据的写入与检索。
Milvus 不再要求用户将原子化结构拆解为扁平模型,而是引入 Struct 数组(Array of Structs) ------ 数组中的每个 Struct 都可以同时包含标量字段与向量字段,从而保持数据的语义完整性。
在自动驾驶与多模态检索等现代 AI 应用中,数据结构通常是嵌套且异构的。
传统扁平数据模型难以表达如下关系:
- "一篇文档包含多个标注文本块"
- "一个驾驶场景包含多个行为片段"
Array of Structs 正是为解决这些问题而设计。
Array of Structs 允许你存储一个有序的结构化元素集合,每个 Struct 可以包含:
- 多个标量字段
- 多个向量嵌入字段
因此它非常适用于:
-
层级数据(Hierarchical Data)
例如:
- 一本书包含多个文本分块
- 一个视频包含多个标注帧
-
多模态嵌入(Multimodal Embeddings)
每个 Struct 可以同时包含:
- 文本 embedding
- 图像 embedding
- 以及元数据
-
时序 / 顺序数据(Temporal Data)
例如:
- 时间序列数据
- 自动驾驶中的逐帧事件记录
与以下传统方式相比:
- JSON Blob 存储
- 多 Collection 拆分存储
Array of Structs 提供:
- 原生 Schema 约束
- 向量索引能力
- 更高效的存储与查询性能
在遵循《搜索数据模型设计》原则基础上,使用 Array of Structs 时还需注意以下几点:
一、定义 Struct Schema
在添加 Array 字段之前,需要先定义 Struct 内部结构:
- 每个字段必须显式声明类型
- 支持标量类型(VARCHAR / INT / BOOL 等)
- 支持向量类型(FLOAT_VECTOR)
建议:
👉 Struct 尽量精简,只保留检索或展示所需字段
👉 避免冗余元数据
二、合理设置 max capacity
Array 字段必须设置最大容量(max capacity):
例如:
- 每个文档最多 1000 个 text chunk
- 每个驾驶场景最多 100 个行为片段
⚠️ 注意:
- 过高会浪费存储与内存
- 需要根据业务上限进行合理估算
三、Struct 内向量字段索引
所有向量字段都必须建立索引,包括:
- Collection 级向量字段
- Struct 内的向量字段
推荐索引类型:
- AUTOINDEX
- HNSW
推荐度量方式:
- MAX_SIM 系列(用于多向量语义检索)
真实案例:自动驾驶 CoVLA 数据集建模
Comprehensive Vision-Language-Action(CoVLA)数据集由 Turing Motors 提出,并被 2025 年冬季计算机视觉应用会议(WACV 2025)收录。该数据集为自动驾驶领域 Vision-Language-Action(VLA)模型的训练与评估提供了丰富基础。
每个数据样本通常是一个视频片段,不仅包含原始视觉输入,还包含结构化的文本标注,用于描述:
-
自车行为(ego vehicle behavior)
例如:"在避让对向车辆的同时向左并线"
-
检测到的目标对象(detected objects)
例如:前车、行人、交通信号灯
-
逐帧场景描述(frame-level caption)
这种层级化、多模态的数据结构,使其成为 Array of Structs(结构体数组)特性的理想应用场景。
步骤 1:将数据集映射为 Collection Schema
CoVLA 是一个大规模多模态驾驶数据集,包含:
-
10,000 个视频片段
-
总计超过 80 小时视频
-
以 20Hz 频率采样帧
-
每一帧都带有自然语言描述,以及车辆状态与检测目标坐标信息
video_1 (VIDEO) # video.mp4
├── video_id (INT)
├── video_url (STRING)
├── frames (ARRAY)
│ ├── frame_1 (STRUCT)
│ │ ├── caption (STRUCT)
│ │ │ ├── plain_caption
│ │ │ ├── rich_caption
│ │ │ ├── risk
│ │ │ ├── risk_correct
│ │ │ ├── risk_yes_rate
│ │ │ ├── weather
│ │ │ ├── weather_rate
│ │ │ ├── road
│ │ │ ├── road_rate
│ │ │ ├── is_tunnel
│ │ │ ├── is_tunnel_yes_rate
│ │ │ ├── is_highway
│ │ │ ├── is_highway_yes_rate
│ │ │ ├── has_pedestrian
│ │ │ ├── has_carrier_car
│ │ ├── traffic_light (STRUCT)
│ │ │ ├── index
│ │ │ ├── class
│ │ │ ├── bbox
│ │ ├── front_car (STRUCT)
│ │ │ ├── has_lead
│ │ │ ├── lead_prob
│ │ │ ├── lead_x
│ │ │ ├── lead_y
│ │ │ ├── lead_speed_kmh
│ │ │ ├── lead_a
│ ├── frame_2 (STRUCT)
│ ├── ...
video_2
...
video_n
可以看出 CoVLA 数据集具有非常明显的层级结构:
- 多个 JSONL 文件组织标注信息
- 视频数据以 MP4 存储
- 帧级数据高度结构化且嵌套
在 Milvus 中,可以使用:
- JSON 字段(JSON Field)
- Array of Structs 字段
来构建嵌套结构。
但需要注意:
- 如果嵌套结构中包含向量嵌入,则必须使用 Array of Structs
- Struct 内部不支持再次嵌套 Struct
- 因此必须对数据进行适度扁平化(flatten)
下图(略)展示了该数据集在 Milvus 中的建模方式。
上面的图展示了一个视频片段的结构,包含以下字段:
-
video_id 作为主键字段,类型为 INT64 整数。
-
states 是一个原始 JSON 数据体,存储当前视频中每一帧里自车(ego vehicle)的状态信息。
-
captions 是一个 Struct(结构体)数组,其中每个 Struct 包含以下字段:
-
frame_id:用于标识当前视频中的具体帧。
-
plain_caption :对当前帧的描述,不包含环境信息(如天气、路况等);对应的向量表示为 plain_cap_vector。
-
rich_caption :包含环境信息的完整帧描述;对应的向量表示为 rich_cap_vector。
-
risk :描述自车在当前帧中面临的风险;对应的向量表示为 risk_vector。
-
以及该帧的其他属性,例如 road(道路)、weather(天气)、is_tunnel(是否隧道)、has_pedestrian(是否有行人)等。
-
-
traffic_lights 是一个 JSON 对象,包含当前帧中检测到的所有交通灯信息。
-
front_cars 也是一个 Struct 数组,包含当前帧中检测到的所有前车(领先车辆)信息。
步骤 2:初始化 schema
首先,我们需要分别初始化三个部分的 schema:caption Struct、front_cars Struct 以及整个 collection 的 schema。
初始化 Caption Struct 的 schema
python
client = MilvusClient("http://localhost:19530")
# 创建 caption struct 的 schema
schema_for_caption = client.create_struct_field_schema()为该 Struct 添加字段:
python
schema_for_caption.add_field(
field_name="frame_id",
datatype=DataType.INT64,
description="自车行为所属的帧ID"
)
schema_for_caption.add_field(
field_name="plain_caption",
datatype=DataType.VARCHAR,
max_length=1024,
description="对自车行为的简洁描述"
)
schema_for_caption.add_field(
field_name="plain_cap_vector",
datatype=DataType.FLOAT_VECTOR,
dim=768,
description="plain_caption 对应的向量表示"
)
schema_for_caption.add_field(
field_name="rich_caption",
datatype=DataType.VARCHAR,
max_length=1024,
description="包含环境信息的自车行为描述"
)
schema_for_caption.add_field(
field_name="rich_cap_vector",
datatype=DataType.FLOAT_VECTOR,
dim=768,
description="rich_caption 对应的向量表示"
)
schema_for_caption.add_field(
field_name="risk",
datatype=DataType.VARCHAR,
max_length=1024,
description="自车风险描述"
)
schema_for_caption.add_field(
field_name="risk_vector",
datatype=DataType.FLOAT_VECTOR,
dim=768,
description="风险描述对应的向量表示"
)
schema_for_caption.add_field(
field_name="risk_correct",
datatype=DataType.BOOL,
description="风险评估是否正确"
)
schema_for_caption.add_field(
field_name="risk_yes_rate",
datatype=DataType.FLOAT,
description="风险存在的置信概率"
)
schema_for_caption.add_field(
field_name="weather",
datatype=DataType.VARCHAR,
max_length=50,
description="天气情况"
)
schema_for_caption.add_field(
field_name="weather_rate",
datatype=DataType.FLOAT,
description="天气判断的置信概率"
)
schema_for_caption.add_field(
field_name="road",
datatype=DataType.VARCHAR,
max_length=50,
description="道路类型"
)
schema_for_caption.add_field(
field_name="road_rate",
datatype=DataType.FLOAT,
description="道路类型判断的置信概率"
)
schema_for_caption.add_field(
field_name="is_tunnel",
datatype=DataType.BOOL,
description="是否为隧道"
)
schema_for_caption.add_field(
field_name="is_tunnel_yes_rate",
datatype=DataType.FLOAT,
description="隧道判断的置信概率"
)
schema_for_caption.add_field(
field_name="is_highway",
datatype=DataType.BOOL,
description="是否为高速公路"
)
schema_for_caption.add_field(
field_name="is_highway_yes_rate",
datatype=DataType.FLOAT,
description="高速公路判断的置信概率"
)
schema_for_caption.add_field(
field_name="has_pedestrian",
datatype=DataType.BOOL,
description="是否存在行人"
)
schema_for_caption.add_field(
field_name="has_pedestrian_yes_rate",
datatype=DataType.FLOAT,
description="行人存在的置信概率"
)
schema_for_caption.add_field(
field_name="has_carrier_car",
datatype=DataType.BOOL,
description="是否存在运输车辆"
)初始化 Front Car Struct 的 schema
虽然 front car 不包含向量字段,但由于数据量较大,仍需要使用 Struct Array,而不能使用 JSON。
python
schema_for_front_car = client.create_struct_field_schema()添加字段:
python
schema_for_front_car.add_field(
field_name="frame_id",
datatype=DataType.INT64,
description="该前车信息所属帧ID"
)
schema_for_front_car.add_field(
field_name="has_lead",
datatype=DataType.BOOL,
description="是否存在前车"
)
schema_for_front_car.add_field(
field_name="lead_prob",
datatype=DataType.FLOAT,
description="前车存在的置信概率"
)
schema_for_front_car.add_field(
field_name="lead_x",
datatype=DataType.FLOAT,
description="前车相对自车的 x 坐标"
)
schema_for_front_car.add_field(
field_name="lead_y",
datatype=DataType.FLOAT,
description="前车相对自车的 y 坐标"
)
schema_for_front_car.add_field(
field_name="lead_speed_kmh",
datatype=DataType.FLOAT,
description="前车速度(km/h)"
)
schema_for_front_car.add_field(
field_name="lead_a",
datatype=DataType.FLOAT,
description="前车加速度"
)初始化 Collection schema
python
schema = client.create_schema()添加主表字段:
python
schema.add_field(
field_name="video_id",
datatype=DataType.VARCHAR,
description="主键",
max_length=16,
is_primary=True,
auto_id=False
)
schema.add_field(
field_name="video_url",
datatype=DataType.VARCHAR,
max_length=512,
description="视频地址"
)添加复杂字段(Array + Struct)
python
schema.add_field(
field_name="captions",
datatype=DataType.ARRAY,
element_type=DataType.STRUCT,
struct_schema=schema_for_caption,
max_capacity=600,
description="当前视频的帧级 caption 信息"
)
schema.add_field(
field_name="traffic_lights",
datatype=DataType.JSON,
description="当前视频中的交通灯信息(按帧)"
)
schema.add_field(
field_name="front_cars",
datatype=DataType.ARRAY,
element_type=DataType.STRUCT,
struct_schema=schema_for_front_car,
max_capacity=600,
description="当前视频中的前车信息(按帧)"
)步骤 3:设置索引参数
所有向量字段都必须建立索引。对于 Struct 中的向量字段,需要使用 AUTOINDEX 或 HNSW 作为索引类型,并使用 MAX_SIM 系列度量方式来计算 embedding list 之间的相似度。
python
index_params = client.prepare_index_params()为不同向量字段创建索引:
python
index_params.add_index(
field_name="captions[plain_cap_vector]",
index_type="AUTOINDEX",
metric_type="MAX_SIM_COSINE",
index_name="captions_plain_cap_vector_idx", # 目前必须显式指定
index_params={"M": 16, "efConstruction": 200}
)
index_params.add_index(
field_name="captions[rich_cap_vector]",
index_type="AUTOINDEX",
metric_type="MAX_SIM_COSINE",
index_name="captions_rich_cap_vector_idx",
index_params={"M": 16, "efConstruction": 200}
)
index_params.add_index(
field_name="captions[risk_vector]",
index_type="AUTOINDEX",
metric_type="MAX_SIM_COSINE",
index_name="captions_risk_vector_idx",
index_params={"M": 16, "efConstruction": 200}
)建议对 JSON 字段启用 JSON Shredding,以提升这些字段的过滤性能。
步骤 4:创建集合
当 schema 和索引都准备完成后,就可以创建集合:
python
client.create_collection(
collection_name="covla_dataset",
schema=schema,
index_params=index_params
)步骤 5:插入数据
Turing Motors 将 CoVLA 数据集拆分为多个文件,包括:
- 原始视频(.mp4)
- 状态数据(states.jsonl)
- captions(captions.jsonl)
- 红绿灯信息(traffic_lights.jsonl)
- 前车信息(front_cars.jsonl)
你需要将这些文件中同一个 video clip 的数据合并后再写入 Milvus。
下面是针对单个 video clip 的数据合并示例脚本:
-
初始化依赖
pythonimport json from openai import OpenAI openai_client = OpenAI( api_key='YOUR_OPENAI_API_KEY', )pythonvideo_id = "0a0fc7a5db365174" # 表示一个包含 600 帧的视频 -
读取前车数据(front_cars)
pythonentries = [] front_cars = [] with open(f'data/front_car/{video_id}.jsonl', 'r') as f: for line in f: entries.append(json.loads(line)) for entry in entries: for key, value in entry.items(): value['frame_id'] = int(key) front_cars.append(value) -
读取交通灯数据(traffic_lights)
pythonentries = [] traffic_lights = [] frame_id = 0 with open(f'data/traffic_lights/{video_id}.jsonl', 'r') as f: for line in f: entries.append(json.loads(line)) for entry in entries: for key, value in entry.items(): if not value or (value['index'] == 1 and key != '0'): frame_id += 1 if value: value['frame_id'] = frame_id traffic_lights.append(value) else: value_dict = {'frame_id': frame_id} traffic_lights.append(value_dict) -
读取 captions 并生成向量
pythonentries = [] captions = [] with open(f'data/captions/{video_id}.jsonl', 'r') as f: for line in f: entries.append(json.loads(line))定义 embedding 函数:
pythondef get_embedding(text, model="embeddinggemma:latest"): response = openai_client.embeddings.create(input=text, model=model) return response.data[0].embedding为 caption 添加向量:
pythonfor entry in entries: for key, value in entry.items(): value['frame_id'] = int(key) if "plain_caption" in value and value["plain_caption"]: value["plain_cap_vector"] = get_embedding(value["plain_caption"]) if "rich_caption" in value and value["rich_caption"]: value["rich_cap_vector"] = get_embedding(value["rich_caption"]) if "risk" in value and value["risk"]: value["risk_vector"] = get_embedding(value["risk"]) captions.append(value) -
组合成最终数据结构
pythondata = { "video_id": video_id, "video_url": f"https://your-storage.com/{video_id}", "captions": captions, "traffic_lights": traffic_lights, "front_cars": front_cars } -
插入 Milvus
pythonclient.insert( collection_name="covla_dataset", data=[data] )python# {'insert_count': 1, 'ids': ['0a0fc7a5db365174'], 'cost': 0}
结尾
最开始接触向量库的时候,我的理解其实非常朴素:
就是把文本或者图片变成 embedding,然后用 cosine similarity 做相似度计算,找最接近的结果。
说得直白一点,这个阶段的理解基本还停留在"大学作业级别"。
但在系统性学习 Milvus 之后,会明显感觉到一件事:
Milvus 并不是一个"带向量能力的数据库",而是一个围绕"向量检索体系"重构的数据系统。
它的复杂程度,已经不只是工程问题,而是一个跨越多个学科的系统设计问题。
Milvus 的复杂性在于,它把很多原本分散在不同系统里的能力统一了:
- 传统数据库的:主键、索引、分区、分片
- 搜索系统的:倒排索引、分词、BM25
- 机器学习系统的:embedding、向量空间建模
- 信息检索系统的:召回、过滤、排序、多路融合
- 甚至还有:JSON、动态字段、复杂结构建模
当这些能力叠加在一起时,它就不再是一个"工具",而是一个"体系"。
如果只是做 CRUD 或者简单 schema,其实上手 Milvus 并不难。
真正的门槛在后面:
- 为什么这个字段适合做 vector,而那个字段只能做 filter?
- 什么情况下用 dense vector,什么情况下用 sparse vector?
- 分词、analyzer、BM25、shredding 这些机制如何协同?
- schema 如何设计才能支撑检索效果,而不仅仅是"能存数据"?
- hybrid search 的权重如何设计?
这些问题已经不只是"写代码"的问题,而更像是在做一个小型的信息检索系统设计。
某种程度上,它确实会让人意识到:
想把搜索做好,本质上是一个建模问题,而不是一个调用 API 的问题。
Milvus 这种系统有一个很明显的特点:
- 入门很快
- 误解也很快
- 精通很慢
很多人第一次用的时候,基本都是:
- 创建 schema
- 定义 varchar / int / vector
- 写入数据
- search 一下
然后觉得"就这样"。
但往后走一步就会发现,真正决定效果的东西根本不是这些 API,而是:
- 数据怎么组织
- 向量怎么生成
- 索引怎么建
- 过滤条件怎么设计
- 召回和排序怎么组合
越往后越容易产生一种感觉:
不是系统难,而是你对"数据如何被理解"这件事还不够理解。
这篇博客整体上和官方文档的重合度确实很高,甚至可以说大部分内容就是"重写 + 结构化整理"。
但这也是我一贯的学习方式:
"手抄一遍胜过眼过千遍"
很多知识如果只是阅读,其实很容易"看懂但不会用"。
只有在重新组织一遍结构、重新表达一遍逻辑的过程中,才会暴露出真正不理解的地方。
这种方式有点像古代的注疏体系:
- 原文是官方文档(《水经》)
- 我的内容更像是解释、补充和结构化整理(《水经注疏》)
重点不在于"原创性",而在于:
把复杂系统重新用自己的认知体系跑一遍
Milvus 这个系统给我最大的感受其实不是"它很强",而是:
它把"数据结构设计"和"检索系统设计"这两件事,强行融合在了一起。
这也意味着,使用它的人不能只是工程师,也不能只是算法工程师,而更像是一个"跨界角色"。
既要懂工程实现,也要懂数据建模,还要理解向量空间的基本数学直觉。
对于很多开发者来说,这确实不轻松。
但换个角度看,这也是它有意思的地方。
如果说这篇博客有什么真正的意义,可能不是"讲清楚了 Milvus",而是:
让自己意识到:搜索系统这件事,比想象中复杂得多,也更有系统性。