目录
[进程的四大关系 ---- 竞争、独立、并行、并发](#进程的四大关系 ---- 竞争、独立、并行、并发)
进程优先级
基本概念
进程优先级:进程得到CPU资源分配的先后顺序
优先级高的进程优先得到CPU资源,优先执行,配置进程优先级对多任务环境用处很大,可以改善系统性能
在CPU多核情况下,通过改变进程优先级,还可以把进程运行到指定的CPU上,这样一来,把不重要的进程安排到某个CPU,可以大大提高系统整体性能
查看系统进程
ps -l

UID:代表这个进程的执行者的身份
PID:代表这个进程的标示符
PPID:代表这个进程的父进程的标示符
PRI:代表这个进程的进程优先级,值越小越早被执行,值越大越晚被执行
NI:代表这个进程的nice值
PRI 和 NI
PRI:代表这个进程的进程优先级,表示这个进程得到CPU资源的先后顺序
那么NI是什么意思呢?
NI:表示进程可被执行的进程优先级的修正数值,理解下面的公式就理解了NI
PRI(显示值)= PRI(进程的默认值,Linux下默认为80)+ NI
通过修改nice值,可以修改进程的优先级,所以NI被称为进程优先级的修正数值
nice的取值范围为 -20 ~ 19 ,一共有40个级别。
更改进程优先级的方法
方法1:启动进程时指定优先级
适用对象:还没有启动的程序
nice -n nice值 命令
例如
把可执行程序 ./test 优先级调低
nice -n 10 ./test
把可执行程序 ./test 优先级调高
sudo nice -n -10 ./test
方法2:更改正在运行的进程的优先级
renice -n nice值 命令
用法与 nice 一致
top 命令
进入top后,按 "r" ->输入进程PID ->输入nice值
方法3:系统函数
这里不再论述,可以自主学习一下
进程的四大关系 ---- 竞争、独立、并行、并发
竞争性:系统进程数量多,而CPU资源少,所以进程之间是具有竞争性的。为了高效完成任务,更合理地分配CPU资源,便有了进程优先级
独立性:多进程运行期间互不干扰,独享各种资源
并行:多个进程在多个CPU或多核下同时进行运行
并发:多个进程在一个CPU且单核下采用进程切换的方式,在一段时间之内,让多个进程都得以推进
进程切换
基本概念
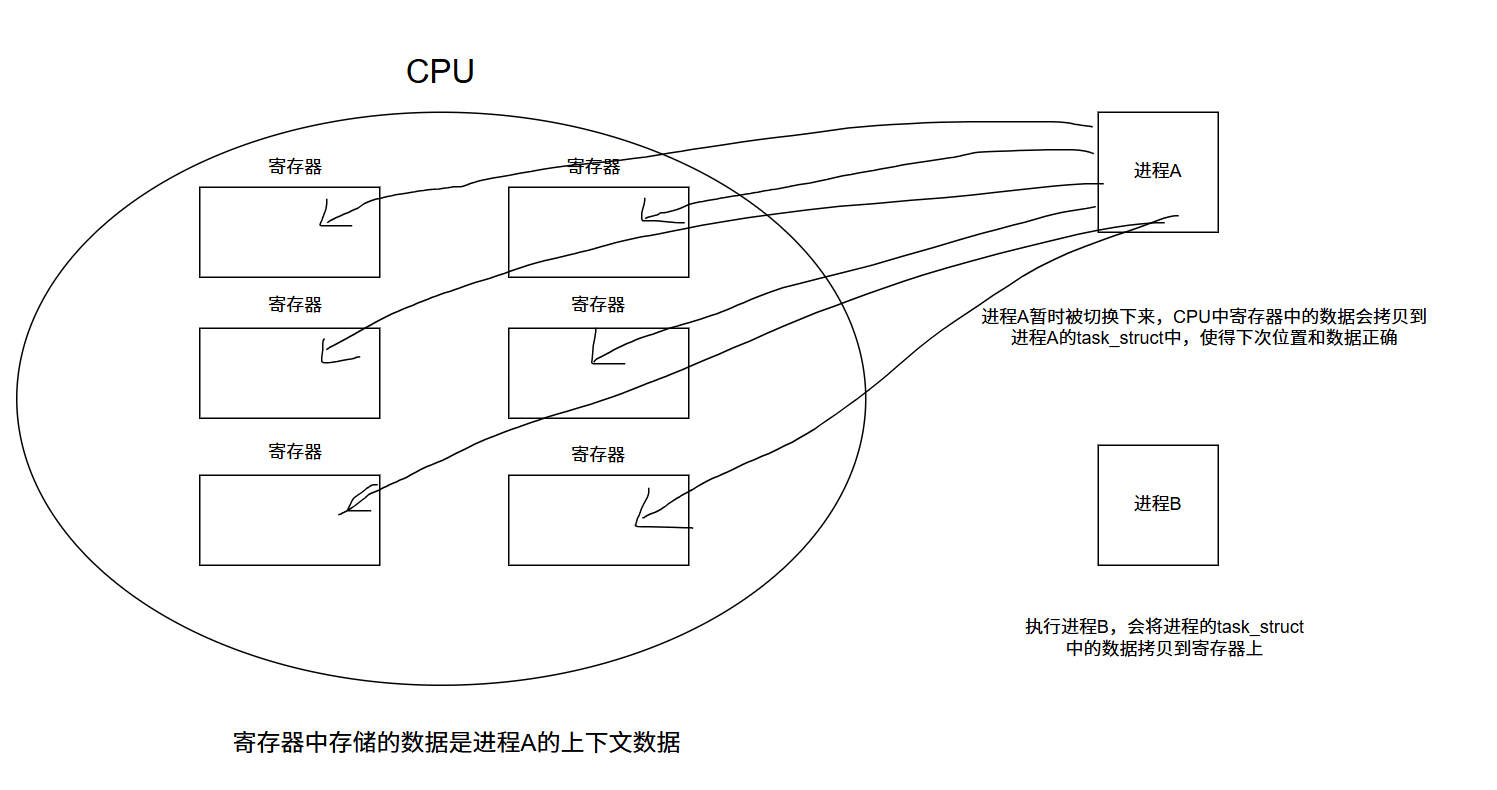
CPU上下文切换:本质CPU寄存器现场的保存 + 恢复,其实际含义是进程切换或者CPU寄存器切换
什么是上下文?
CPU正在运行进程时,所有寄存器里的值(例如:程序计数器,栈指针,状态寄存器等),这些寄存器现场,就是CPU的上下文。
进程切换:当多进程内核(内核调度器)决定运行其他进程时,它保存正在运行的进程的当前状态,也就是保存CPU寄存器中的全部内容,这些内容被保存到进程的task_struct中,这些工作完成后,就把下一个将要运行的进程的上一次的运行保存后的状态或者初次运行的状态重新加载到CPU寄存器中,并开始下一个进程的运行,这个全部过程称为进程切换
为什么要进行进程切换?
根本原因:CPU数量少,进程数量多
单核CPU同一时刻只能跑一个进程,但系统里有很多进程都要运行,就会使一些进程长时间得不到资源,从而使得进程饥饿现象普遍,大大降低了操作系统的效率,所以操作系统必须轮流让每个进程得到CPU资源,所以必须要进行进程切换
触发进程切换的条件
1.时间片用完(最常见)
时间片:当代计算机都是分时操作系统,每个进程都有它合适的时间片(其实就是计数器)。
Linux操作系统会给每个进程分配时间片,时间片一到,强制剥夺CPU,切换到下一个进程
- 进程主动放弃CPU,进程状态变为阻塞状态
进程需要等待某种事件的完成,从而变成阻塞状态,此时进程暂时不需要CPU,操作系统会进行进程切换
3.高优先级进程抢占
有更高优先级进程就绪了,立即强占当前进程,强制切换
4.中断/异常触发
硬件发生中断,操作系统会进行进程切换
Linux基于进程切换而实现的O(1)调度算法
cpp
struct runqueue {
spinlock_t lock;
/*
* nr_running and cpu_load should be in the same cacheline because
* remote CPUs use both these fields when doing load calculation.
*/
unsigned long nr_running;
#ifdef CONFIG_SMP
unsigned long cpu_load;
#endif
unsigned long long nr_switches;
/*
* This is part of a global counter where only the total sum
* over all CPUs matters. A task can increase this counter on
* one CPU and if it got migrated afterwards it may decrease
* it on another CPU. Always updated under the runqueue lock:
*/
unsigned long nr_uninterruptible;
unsigned long expired_timestamp;
unsigned long long timestamp_last_tick;
task_t *curr, *idle;
struct mm_struct *prev_mm;
prio_array_t *active, *expired, arrays[2];
int best_expired_prio;
atomic_t nr_iowait;
#ifdef CONFIG_SMP
struct sched_domain *sd;
/* For active balancing */
int active_balance;
int push_cpu;
task_t *migration_thread;
struct list_head migration_queue;
#endif
#ifdef CONFIG_SCHEDSTATS
/* latency stats */
struct sched_info rq_sched_info;
/* sys_sched_yield() stats */
unsigned long yld_exp_empty;
unsigned long yld_act_empty;
unsigned long yld_both_empty;
unsigned long yld_cnt;
/* schedule() stats */
unsigned long sched_noswitch;
unsigned long sched_switch;
unsigned long sched_cnt;
unsigned long sched_goidle;
/* pull_task() stats */
unsigned long pt_gained[MAX_IDLE_TYPES];
unsigned long pt_lost[MAX_IDLE_TYPES];
/* active_load_balance() stats */
unsigned long alb_cnt;
unsigned long alb_lost;
unsigned long alb_gained;
unsigned long alb_failed;
/* try_to_wake_up() stats */
unsigned long ttwu_cnt;
unsigned long ttwu_attempts;
unsigned long ttwu_moved;
/* wake_up_new_task() stats */
unsigned long wunt_cnt;
unsigned long wunt_moved;
/* sched_migrate_task() stats */
unsigned long smt_cnt;
/* sched_balance_exec() stats */
unsigned long sbe_cnt;
#endif
};明确认识:1个CPU拥有一个runqueue(运行队列)
如果有多个CPU就要考虑进程个数的负载均衡问题,通过负载因子来解决,很好理解,每个进程肯定要保证分配的任务数量合理,可以更好地发挥操作系统的性能

真正走入调度算法
prio_array_t *active, *expired, arrays2;
typedef struct prio_array prio_array_t;
struct prio_array {
unsigned int nr_active;
unsigned long bitmapBITMAP_SIZE; // BITMAP_SIXE 为 5
struct list_head queueMAX_PRIO; // MAX_PRIO 为 140
};
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO
#define MAX_PRIO (MAX_RT_PRIO + 40)
调度算法的结构
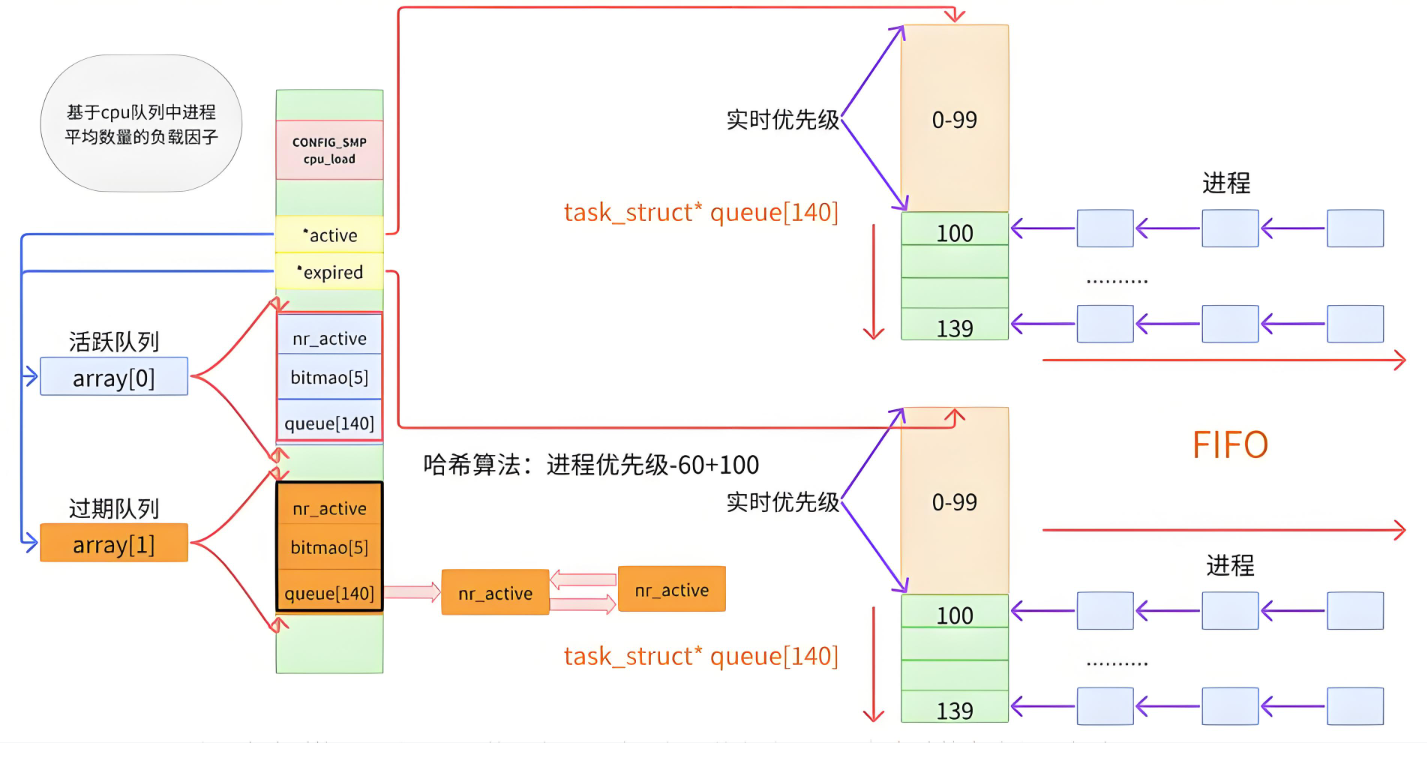
第一行代码说明,存在两个指针,一个指针指向活动队列,一个指针指向过期队列,以及一个大小为2的数组,这个数组一个为活动队列,一个为过期队列。
活动队列:CPU正在执行的运行队列。
过期队列:CPU讲活动队列中的进程基于时间片执行,如果没有执行完,则把其放到过期队列中,运行队列执行完就要执行过期队列中的进程。
下一个结构体为,活动队列和过期队列的结构
nr_arctive:这个运行队列中进程的数量
queue140:一个元素就是一个进程队列,相同优先级的进程按照FIFO规则进行排队调度,所以, 数组下标就是优先级!(这个调度算法设计就能很好地解释NI存在的价值)
普通优先级:对应的下标100 ~ 139 (nice的取值范围能很好地一亿对应)
实时优先级:0 ~ 99 (不关心,操作系统决定)
bitmap5:一共140个优先级,一共140个进程队列,为了提高查找非空队列的效率,就可以用 5*32个比特位表示队列是否为空,这样,便可以大大提高查找效率!(位图思想)
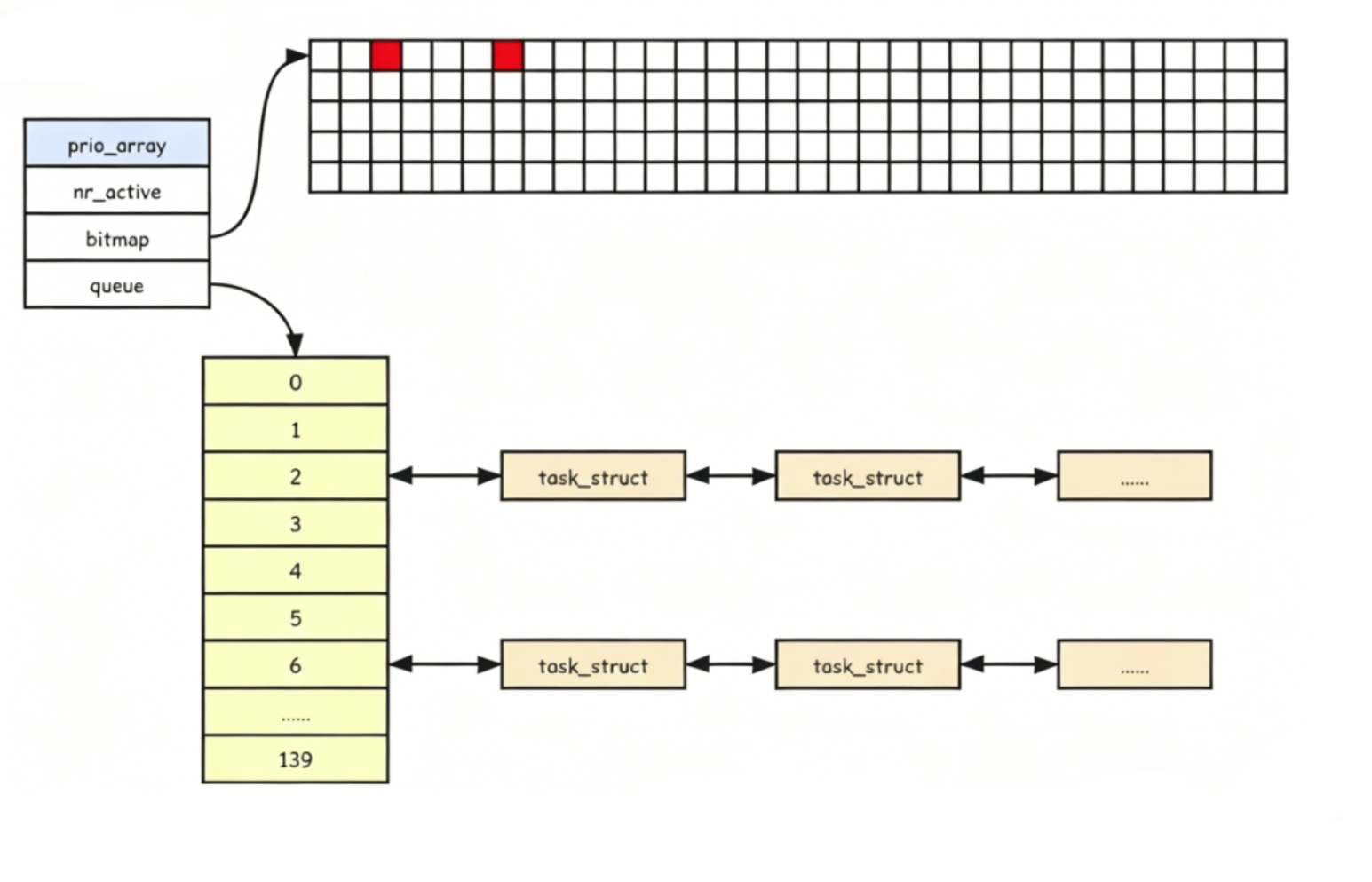
active指针和expired指针
active指针永远指向活动队列
expired指针永远指向过期队列
虽然CPU的执行,活动队列上的进程数量越来越少,过期队列上的进程数量越来越多,等到活动队列上的进程执行完,只需交换active指针和expired指针的内容,就相当于完成了active指向活动队列,expired指向过期队列。