一、为什么选择 ElasticSearch?
1.1 为什么选择 ElasticSearch?
在电商、资讯等平台的搜索场景中,用户输入的关键词千变万化,传统数据库的字段匹配查询早已无法满足需求,eg:MySQL搜索多个字段模糊匹配,要多次全表扫描。
而 ElasticSearch(简称 ES)作为基于 Lucene 的分布式全文检索服务器 ,凭借词元匹配 + 倒排索引的核心机制,对外提供Restful 接口来操作索引、搜索,能轻松实现灵活的全文检索。
1.2 ES 核心特性
- 基于 Lucene 封装,隐藏底层复杂性,对外提供 RESTful API 操作索引 / 搜索;
- 分布式架构,支持实时搜索、高可用、高并发;
- 对比 Solr:现有 Solr 满足需求则无需替换,新项目优先选 ES(Github 等大规模场景验证)。
二、ElasticSearch 核心原理
2.1 倒排索引(核心)
 索引结构图
索引结构图
正排索引:文档→关键字(如同逐页查字典);
倒排索引: ES 实现高效检索的核心,本质是 "从关键字--->文档的映射",由三部分构成:
- 文档(Documents) :将搜索的文档以Document方式存储起来(类似字典的正文内容)。
- 分词 (trem) :将要搜索的文档内容分词,所有不重复的词组成分词列表(类似字典的目录)。
- 分词列表(trem---->documents) :每个分词与所属文档的映射关系。特点:①分词不重复;②不搜索的field(字段)不参加分词 eg:img;③停用词 '的','地','得'不参与分词
注意:搜索时从trem分词列表匹配
2.2 核心概念类比
为了快速理解 ES 的结构,我们可以和关系型数据库做类比:
| ElasticSearch | 关系型数据库 | 说明 |
|---|---|---|
| Index(索引库) | Database(数据库) | 存储一组结构相似的文档 |
| Type(类型) | Table(表) | ES6.x 后弱化,7.0 已移除 |
| Document(文档) | Row(行) | 最小数据单元,JSON 格式 |
| Field(字段) | Column(列) | 文档的属性,支持多类型 |
| Shard(分片) | 分库分表 | 分布式存储的核心,提升处理能力 |
| Replica(副本) | 数据备份 | 提升可用性,避免单点故障 |
三、ElasticSearch 环境搭建
3.1 环境要求
- JDK 版本:1.8.0_131 及以上;
- 系统资源:至少 4096 线程池、262144 字节虚拟内存,建议虚拟机内存≥1.5G;
- 安全限制:ES5.0 + 不允许 root 用户启动,需创建普通用户;
- 系统内核:CentOS 内核≥3.5(低于此版本需禁用相关插件)。
3.2 安装 ES(CentOS 为例)
ElasticSearch官网下载:https://www.elastic.co/cn/
步骤 1:创建专用用户
bash
# 创建用户组
groupadd elk
# 创建用户并设置密码
useradd admin
passwd admin
# 将用户加入组
usermod -G elk admin
# 分配目录权限
chown -R admin:elk /usr/upload
chown -R admin:elk /usr/local
# 切换用户
su admin步骤 2:解压安装
bash
# 下载ES安装包(以6.2.3为例)
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.3.tar.gz
# 解压
tar -zxvf elasticsearch-6.2.3.tar.gz -C /usr/local步骤 3:配置文件修改
ES 的核心配置文件位于config目录下,重点修改 3 个文件:
(1)elasticsearch.yml(核心配置)
yaml
cluster.name: power_shop # 集群名称
node.name: power_shop_node_1 # 节点名称
network.host: 0.0.0.0 # 允许外网访问
http.port: 9200 # HTTP端口
transport.tcp.port: 9300 # 集群通信端口
discovery.zen.ping.unicast.hosts: ["192.168.61.135:9300"] # 集群节点
path.data: /usr/local/elasticsearch-6.2.3/data # 数据存储路径
path.logs: /usr/local/elasticsearch-6.2.3/logs # 日志路径
http.cors.enabled: true # 允许跨域(对接head插件)
http.cors.allow-origin: /.*/ # 允许所有域名跨域
bootstrap.system_call_filter: false # 禁用内核检查(适配CentOS6)(2)jvm.options(JVM 内存配置)
properties
# 初始堆内存和最大堆内存,建议设为相等且不超过物理内存的1/2
-Xms512m
-Xmx512mlog4j2.properties:按需配置日志级别,默认即可。
(3)解决系统限制问题
①解决内核问题
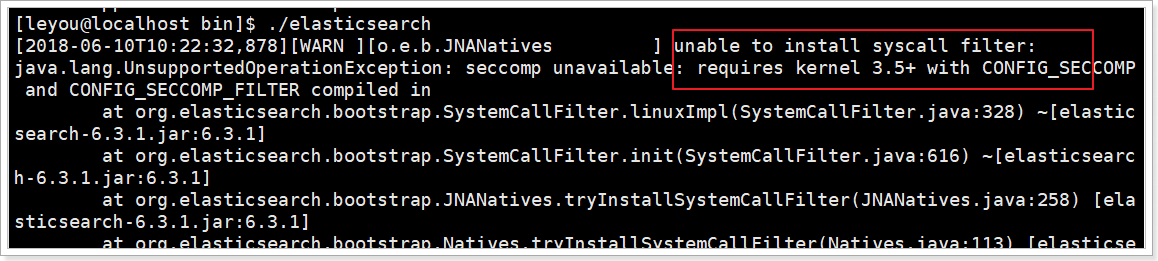
Elasticsearch的插件要求Linux内核版本至少3.5以上版本。禁用这个插件即可。
修改elasticsearch.yml文件,在最下面添加如下配置:
bash
bootstrap.system_call_filter: false②解决文件创建权限问题
bash
[1]: max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]Linux 默认来说,一般限制应用最多创建的文件是 4096个。但是 ES 至少需要 65536 的文件创建权限。我们用的是admin用户,而不是root,所以文件权限不足。
使用root用户修改配置文件:
bash
vim /etc/security/limits.conf追加下面的内容:
bash
* soft nofile 65536
* hard nofile 65536③解决线程开启限制问题
bash
[2]: max number of threads [1024] for user [admin] is too low, increase to at least [4096]默认的 Linux 限制 root 用户开启的进程可以开启任意数量的线程,其他用户开启的进程可以开启1024 个线程。必须修改限制数为4096+。因为 ES 至少需要 4096 的线程池预备。
如果虚拟机的内存是 1G,最多只能开启 3000+个线程数。至少为虚拟机分配 1.5G 以上的内存。
使用root用户修改配置:
bash
vim /etc/security/limits.d/90-nproc.conf修改下面的内容:
bash
* soft nproc 1024改为:
bash
* soft nproc 4096④解决虚拟内存问题
bash
[3]: max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]ES 需要开辟一个 262144字节以上空间的虚拟内存。
使用root用户修改配置文件:
bash
vim /etc/sysctl.conf追加下面内容:
bash
vm.max_map_count=655360 #限制一个进程可以拥有的VMA(虚拟内存区域)的数量然后执行命令,让sysctl.conf配置生效:
bash
sysctl -p步骤 4:启动与测试
bash
bash
./elasticsearch
#或
# 后台启动ES
/usr/local/elasticsearch-6.2.3/bin/elasticsearch -d
# 测试是否启动成功(浏览器访问或curl)
curl http://192.168.204.132:9200返回如下 JSON 表示启动成功:
json
{
"name" : "power_shop_node_1",
"cluster_name" : "power_shop",
"version" : {
"number" : "6.2.3",
"lucene_version" : "7.2.1"
},
"tagline" : "You Know, for Search"
}3.3 安装 Kibana(ES 可视化工具)
Kibana 是 ES 的官方管理工具,支持语法调试、数据可视化,推荐在 Windows 安装(简单):
- 下载对应版本:https://www.elastic.co/cn/downloads/past-releases/kibana-6-2-3
- 修改
config/kibana.yml:
yaml
bash
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: http://192.168.18.135:9200 # 指向ES地址启动:bin/kibana.bat(Windows),访问http://127.0.0.1:5601即可。
3.4 安装 Head 插件
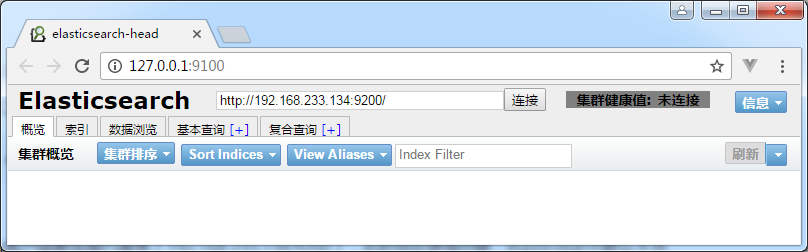
Head 是 ES 的第三方可视化插件,用来监视ES的状态,并通过head客户端和ES服务进行交互,比如创建映射、创建索引等:
bash
# 下载源码
git clone https://github.com/mobz/elasticsearch-head.git
# 安装依赖并启动
cd elasticsearch-head
npm install
npm run start访问http://127.0.0.1:9100,输入 ES 地址即可连接。
四、ES 快速入门(核心操作)
4.1 索引库(Index)管理
索引库包含若干相似结构的 Document 数据,相当于数据库的database。
(1)创建索引
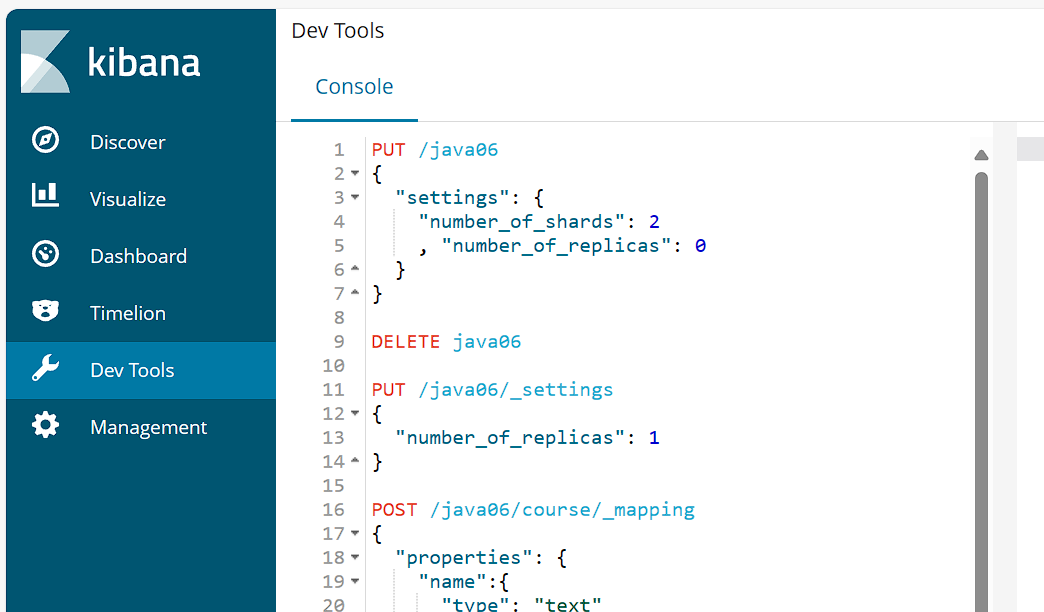
json
# PUT /索引名
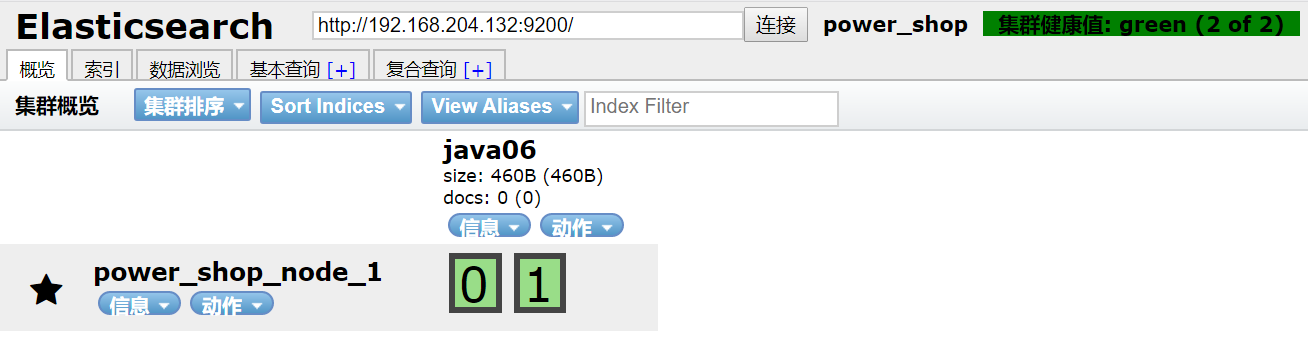
PUT /java06
{
"settings": {
"number_of_shards": 2, # 主分片数(一旦创建不可修改)
"number_of_replicas": 1 # 副本数(可动态修改)
}
}number_of_shards - 表示一个索引库将拆分成多片分别存储不同的结点,提高了ES的处理能力
number_of_replicas - 是为每个 primary shard分配的replica shard数量,提高了ES的可用性,
注意:number_of_replicas 如果只有一台机器,设置为0
运行后:
(2)修改索引(仅副本数)
json
PUT /java06/_settings
{
"number_of_replicas" : 0
}**注意:**索引一旦创建,primary shard 数量不可变化,可以改变replica 数量。
(3)删除索引
json
DELETE /java064.2 type管理
映射用于定义文档的字段类型、分词器等规则,相当于数据库的表结构:
| elasticsearch | 关系数据库 |
|---|---|
| index(索引库) | database(数据库) |
| type(类型) | table(表) |
| document(文档) | row(记录) |
| field(域) | column(字段) |
注意:6.0之前的版本有type(类型)概念,type相当于关系数据库的表,ES6.x 版本之后,type概念被弱化ES官方将在ES7.0版本中彻底删除type。
json
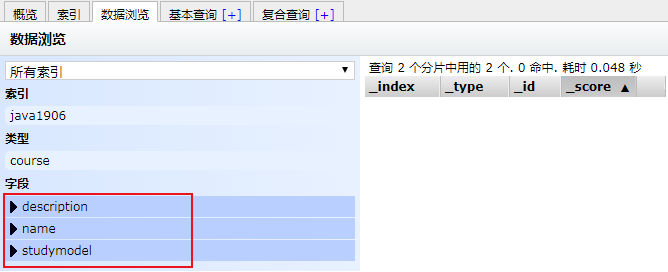
(1) 创建type
bash
POST /java06/course/_mapping
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text"
},
"studymodel": {
"type": "keyword"
}
}
}效果:
(2) 查询type
查询所有索引的映射:
bash
GET /java06/course/_mapping查询id为1的映射:
bash
GET /java06/course/1(3) 更新type
映射创建成功可以添加新字段,已有字段不允许更新。
(4) 删除type
通过删除索引来删除映射。
4.3 文档(Document)管理
(1)新增文档
json
# 手动指定ID
PUT /java06/course/1
{
"name":"Python从入门到精通",
"description":"人生苦短,我用Python",
"studymodel":"201002",
"price":29.9,
"timestamp":"2024-01-01",
"pic":"python.jpg"
}
# 自动生成ID
POST /java06/course
{
"name":".NET从入门到精通",
"description":".NET程序员的进阶之路",
"studymodel":"201003",
"price":39.9
}(2)查询文档
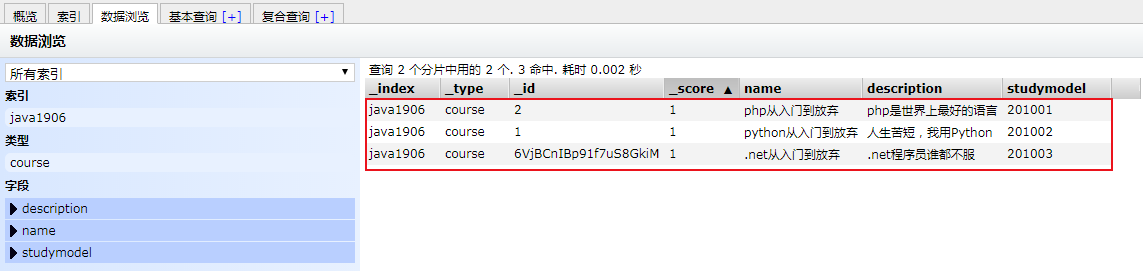
json
# 根据ID查询
GET /java06/course/1
# 全文检索(搜索name包含"入门"的文档)
GET /java06/course/_search?q=name:入门
# 查询所有文档
GET /java06/course/_search通过head查询数据:
(3)删除文档
json
DELETE /java06/course/14.4 IK 分词器(中文分词必备)
ES 默认的分词器对中文支持极差(单字分词),需安装 IK 分词器解决:
- 下载对应版本:https://github.com/medcl/elasticsearch-analysis-ik
- 解压到 ES 的
plugins/ik目录,重启 ES;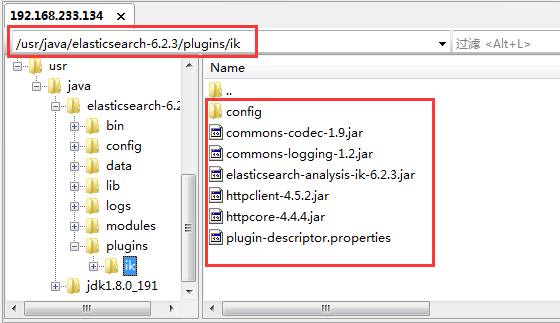
- 两种分词模式:
ik_max_word:细粒度分词,往es写入时使用(如 "中华人民共和国" 拆分为多个关键词);ik_smart:粗粒度分词,搜索时使用(如 "中华人民共和国" 仅拆分为自身)。
测试分词效果
json
POST /_analyze
{
"text":"中华人民共和国人民大会堂",
"analyzer":"ik_smart"
}自定义词库
IKAnalyzer.cfg.xml:配置扩展词典和停用词典
iK分词器自带的main.dic的文件为扩展词典,stopword.dic为停用词典。注意文件格式为utf-8
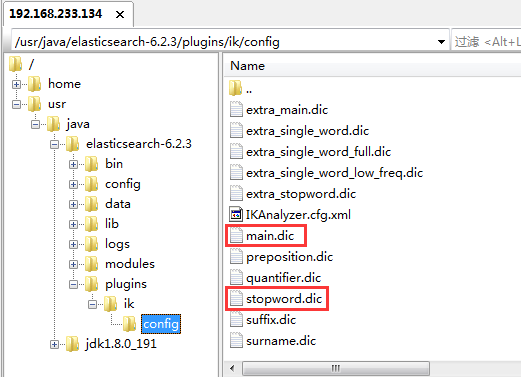
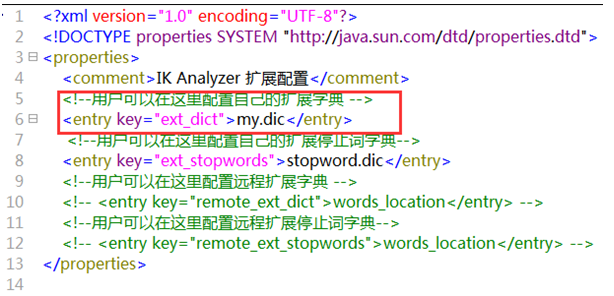
若需支持专有词汇(如公司名、行业术语),可在 IK 的config目录新建my.dic,添加自定义词汇后,修改IKAnalyzer.cfg.xml引入该词库即可。
4.5 ES 读写核心逻辑
(1)数据路由 documnet routing
当客户端创建document时,es需要确定这个document放在该index哪个shard上,这个过程就是document routing。
路由过程:
路由算法:shard = hash(id) %number_of_primary_shards
id:document的_id,可能是手动指定,也可能是自动生成,决定一个document在哪个shard上
number_of_primary_shards*:*主分片數量。
(2)primary shard数量不可变原因
这也是主分片数不可改的原因(改后路由算法失效,无法查询数据)。
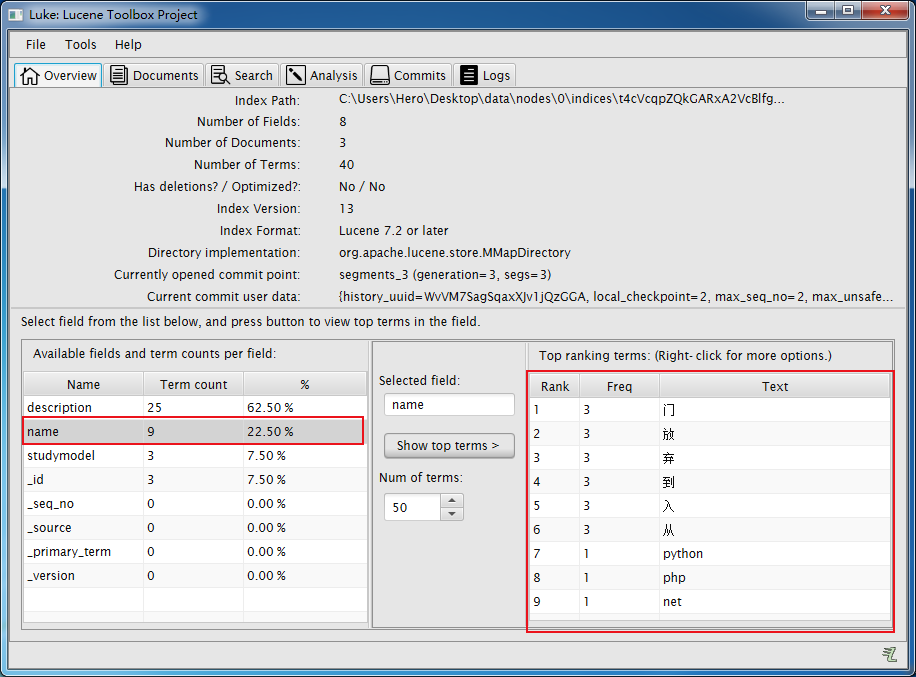
4.6 luke查看ES的逻辑结构
-
拷贝elasticsearch-6.2.3/data到windows
-
双击luke.bat,启动luke(注意:jdk版本需要1.8.0...)
-
使用luke打开data\nodes\0\indices路径
效果:
六、Field 详细配置
6.1 核心属性
表格
| 属性 | 说明 |
|---|---|
| type | 字段类型(text/keyword/date/numeric 等) |
| analyzer | 索引时分词器(如 ik_max_word) |
| search_analyzer | 搜索时分词器(如 ik_smart) |
| index | 是否索引(false 则不可搜索) |
| _source | 控制原始字段是否存储 / 过滤字段 |
6.2 常用字段类型
(1)Text(文本字段)
支持分词,用于全文检索(如商品名称、描述):
json
"name": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
}(2)Keyword(关键字字段)
不分词,用于精确查询 / 排序 / 聚合(如手机号、邮政编码):
json
"studymodel":{
"type":"keyword"
}(3)Date(日期字段)
支持自定义格式,用于时间排序:
json
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd"
}(4)Numeric(数值字段)
支持排序、区间搜索(如价格、数量):
json
"price": {
"type": "float"
}