【案例二】支持搜索的智能代理系统
接下来我们上手第二个实战案例 ------支持搜索的智能代理系统 ,我们要把这套系统搭建完成,并且将它规范定义为 LangGraph 图示化工作流架构。
案例介绍
案例一只是为了演示什么是 Graph 。对于 LangGraph ,实际上是要调用 LLM 来完成智能应用系统。因此该案例会将使用 Graph API ,来完成一个支持搜索、支持调用 LLM 的智能代理系统。核心功能如下:
- 智能对话与工具调用:基于聊天模型,能够理解用户问题并决定是否需要调用搜索工具
- 自动搜索整合 :通过
Tavily搜索工具获取实时信息,并将搜索结果整合到回答中 - 循环决策机制:能够多次调用工具和模型,直到获得满意答案
我们本次依旧使用 Tavily 搜索工具,这个工具在 LangChain 中已经详细讲解过基础用法,而 LangChain 里的工具、模型等基础组件,都可以直接复用在 LangGraph 中。和之前 LangChain 链式调用不同,本次核心是把知识搜索系统改造成图结构工作流的方式来编写代码,理解其图示化的构建逻辑。
流程设置如下:
根据实际自行拓展,例如我们可以用它来:
实时信息查询:查询最新新闻、股价、天气等
今天特斯拉的最新股价是多少?还有哪些重要的科技新闻?
事实核查:验证信息的准确性
有人说阿波罗登月是伪造的,请提供证据来验证登月的真实性
深度研究:多轮搜索获取全面信息
我需要关于 ' 人工智能在医疗诊断中的应用 ' 的最新研究论文、临床试验结果和专家观点,请提供全面的综述
知识扩展:补充模型知识库之外的信息
GPT-4o-mini 的训练数据截止到什么时候?之后有哪些重要的 AI 发展事件?
编码思路
构建 Graph 图,首先需要定义状态,然后定义并添加节点和边,最后编译它。编译提供了对图形结构的一些基本检查(没有孤立节点等)。
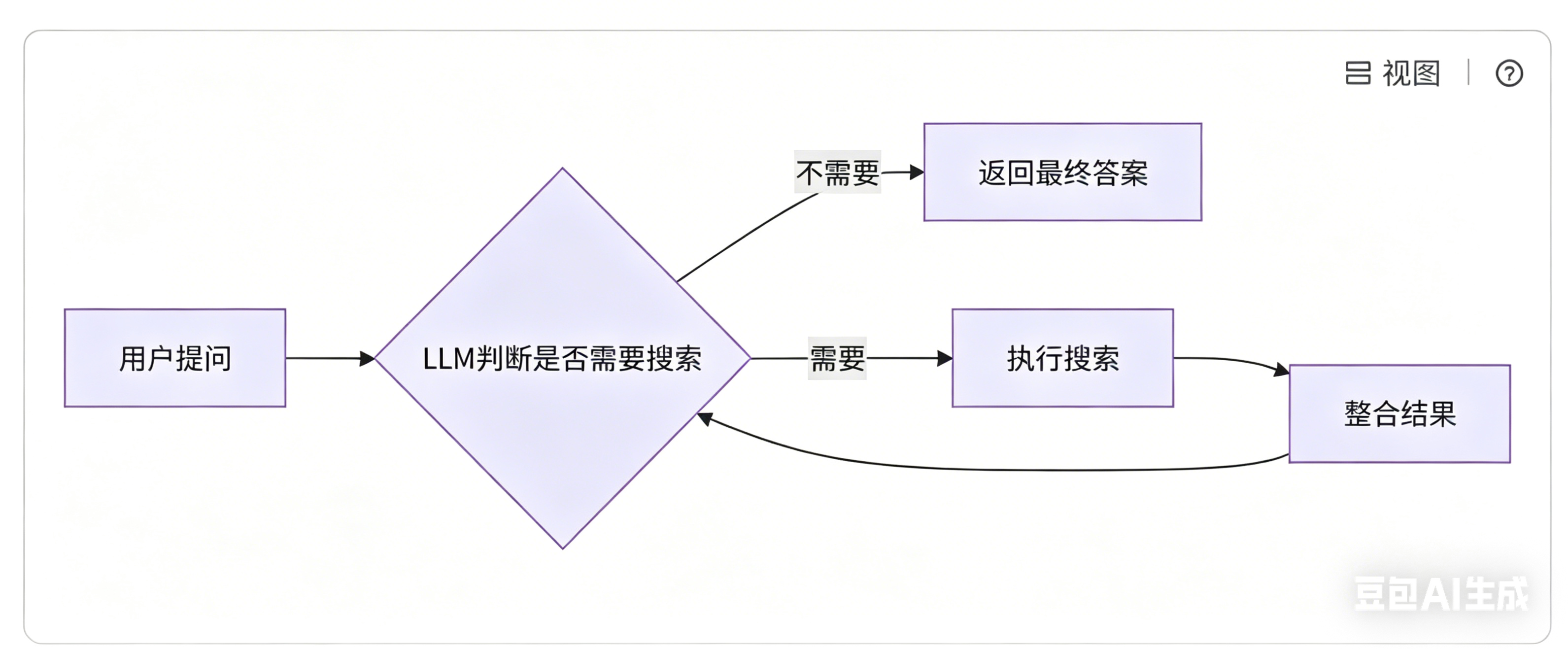
正式编码前,我们先梳理整套业务流程:第一步是用户输入提问 ,我们可以准备两类问题做对比,一类是需要实时数据的股价、天气类问题,一类是1+1等于几这类常识简单问题。
输入问题后,交由大模型自主判断 是否需要调用搜索工具:像股价、天气这类有时效性的问题,大模型训练数据存在时间截止,无法给出最新结果,必须触发网络搜索;而基础常识类问题,大模型可直接作答,无需调用工具。
如果判定需要搜索,就调用 Tavily 搜索工具执行检索,工具调用完成后会生成 ToolMessage;再由大模型结合用户原始问题与工具返回的检索结果,做内容整合,生成最终的 AIMessage 给到用户。结果整合完成后,会再次进入判断逻辑:若已有完整答案,就直接结束流程输出结果;若仍需补充信息,则继续循环检索、整合,直到给出最终答案。
在正式定义 LangGraph 节点和流程前,我们先回顾 LangChain 的消息规范体系:用户输入对应 HumanMessage,交给绑定工具的大模型后,会返回两种 AIMessage:
一种不带工具调用参数,直接给出最终答案;
另一种携带 tool_calls 工具调用参数 ,代表需要执行搜索工具。
一旦返回带工具调用的 AIMessage,就必须执行工具调用,工具执行后产出 ToolMessage;注意 ToolMessage 不能直接返回给用户,需要把 HumanMessage、带工具调用的 AIMessage、ToolMessage 整条消息列表再次交给大模型,由大模型整合生成最终的 AIMessage,这才是呈现给用户的最终回复。
之前用 LangChain 实现工具调用时,最大的痛点是需要手动维护历史消息列表 :要手动把 AIMessage、ToolMessage 依次追加到消息记录中,多轮调用模型、手动管理消息,写法繁琐且不优雅。而 LangGraph 完美解决了这个问题:我们可以在状态 State 中定义一个消息列表 messages,配置追加合并策略,框架会自动帮我们维护对话历史,无需手动逐条添加消息,写法简洁优雅,还能完整留存对话上下文。
除此之外,我们还可以在状态中额外定义 llm_calls 整型字段,用来记录大模型调用次数 ,方便监控计费、统计模型调用频次。在业务系统中,状态里定义 messages 消息列表几乎是标配,核心优势有三点:
- 完整对话记忆:全程留存所有聊天消息,实现多轮对话上下文记忆;
- 全局上下文维护:任意节点都能读取完整历史消息,随时调用上下文信息;
- 状态持久化:图流程流转过程中,对话状态不会丢失,自动追加更新消息记录。
梳理完消息规范和状态设计后,我们再来精简设计 LangGraph 节点 :整套系统只需要两个核心节点就可以完成全部流程,无需拆分过多精细节点。
设置 Nodes
根据节点的单一职责特性,即每个节点只做一件事,我们可以设置:
第一个是大模型调用节点 :负责接收历史消息、调用大模型,返回带工具调用或不带工具调用的两种 AIMessage;
第二个是工具执行节点 :专门解析工具调用参数、执行 Tavily 搜索,生成并返回 ToolMessage。
即:
- 节点 1(
tool_node):专门负责搜索,获取搜索结果。 - 节点 2(
llm_call):专门负责调用 LLM,获取最终结果。
根据节点的独立性特性,即每个节点间不直接通信,而是通过 State 交互。它们接收 State,返回 State 的更新。
设置 State
根据状态的共享性特性,即所有节点都能读取和修改状态。LangGraph 在许多情况下,将以前的对话历史记录存储为 State 中的消息列表会很有帮助,这样就能通过 State 中的消息列表来跟踪整个对话的完整历史,这是构建对话系统的关键。
为此,我们可以在图状态中添加一个 messages 键,如下所示:
python
from langchain.messages import AnyMessage
from typing_extensions import TypedDict, Annotated
import operator
class MessagesState(TypedDict):
# 类型: list[AnyMessage] - 任意消息对象的列表
# 合并策略: operator.add - 使用加法操作符进行状态合并
# 效果: 当状态更新时,新的消息会追加到现有列表中,而不是替换
messages: Annotated[list[AnyMessage], operator.add]
# 类型: int - 整数值
# 用途: 跟踪LLM(大语言模型)的调用次数
llm_calls: int注意 Annotated[list[AnyMessage], operator.add] 这个注解特别重要:
operator.add表示新消息会追加到列表中,而不是替换;- 这确保了对话历史的连续性。
messages 的具体作用:
对话记忆
python
# 存储完整的对话流程
messages = [
HumanMessage(content="你好"),
AIMessage(content="你好! 我是AI助手"),
HumanMessage(content="什么是机器学习? "),
AIMessage(content="机器学习是...")
]上下文维护
当专门负责调用 LLM 的节点(llm_call 节点)需要调用 LLM 时,可以通过 State 将整个 messages 历史作为上下文:
python
# LLM 基于完整的对话历史生成回复
response = llm.invoke(state["messages"])状态持久化
State 中的 messages 字段确保在图的各个节点之间传递时,对话状态不会丢失:
python
def node(state: MessagesState):
# 可以访问完整的对话历史
all_messages = state["messages"]
latest_message = state["messages"][-1]
# 处理并添加新消息
return {"messages": [new_ai_message]}因此,没有这个字段,系统就无法记住之前的对话内容,每次都会像第一次对话一样。
设置 Edges
节点确定后,再设计工作流的边逻辑:包含固定边和条件边。
- 固定边:流程起始节点固定走向大模型调用节点;工具执行节点执行完搜索后,固定回流到大模型调用节点,重新整合结果生成最终答案。
- 条件边 :以大模型调用节点为起点做分支判断 ------ 如果返回的
AIMessage带有tool_calls参数,就路由到工具节点执行搜索;如果没有工具调用参数,说明已生成最终答案,直接走向结束节点。
对于流程设置如下所示:
且已经定义了两个节点:
- 节点 1(
tool_node):专门负责搜索,获取搜索结果。 - 节点 2(
llm_call):专门负责调用 LLM,获取最终结果。
因此,可以定义以下逻辑:
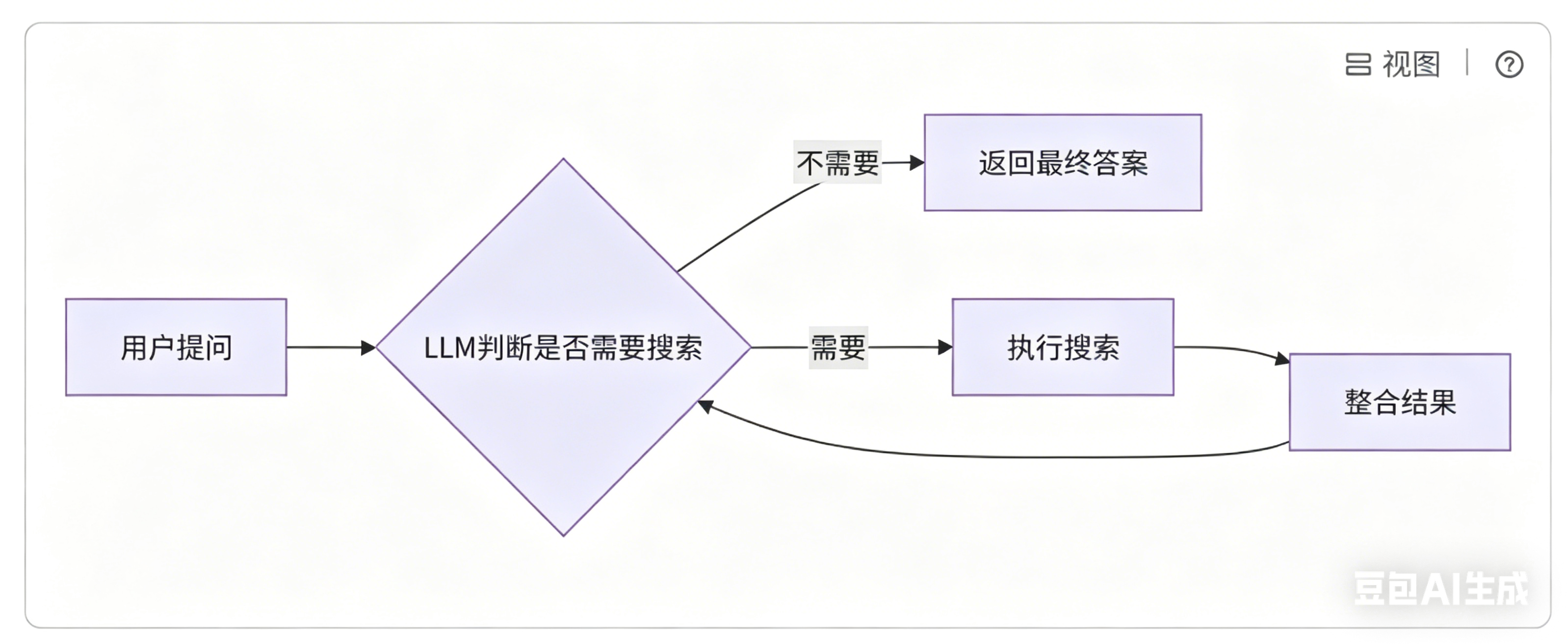
对于开始逻辑 :是当用户进行输入后,直接让 LLM 进行处理。是否需要搜索工具调用,也是通过 LLM 进行判断。因此图的入口点也是 llm_call 节点。
对于结束逻辑 :可以根据 LLM 返回的结构判断是否调用工具,来决定我们是应该继续循环还是停止循环:
- 如果 LLM 要调用工具,则进入
tool_node节点进行处理; - 如果 LLM 不要调用工具,则结束。
最终 Graph 效果如下图所示:
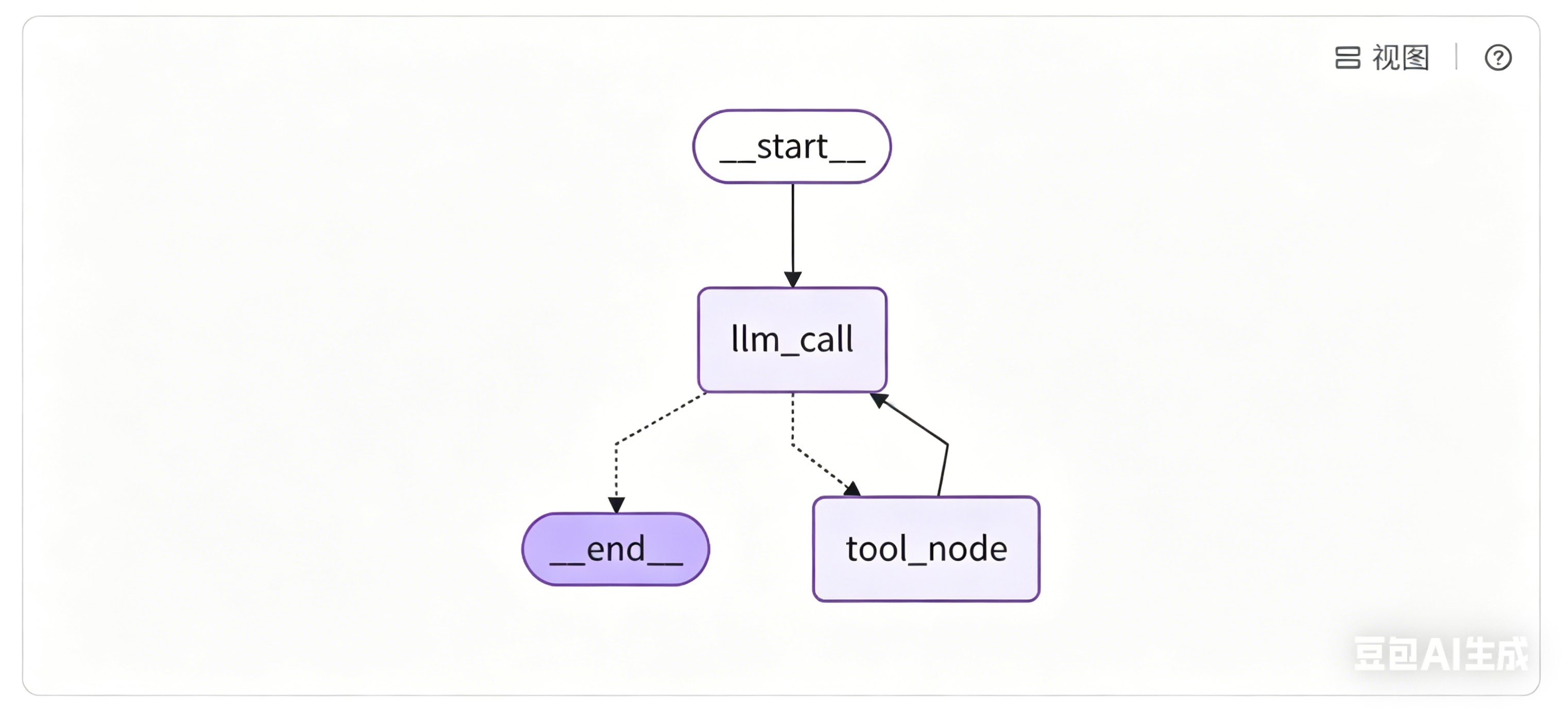
整套 LangGraph 工作流逻辑非常清晰:用户输入问题进入流程 → 进入大模型节点判断是否需要搜索 → 需要搜索则走工具节点执行检索,再回流大模型整合结果 → 无需搜索则直接结束流程输出答案。
最后总结代码实现的标准五步流程:
- 第一步自定义图状态 State;
- 第二步定义两大核心业务节点;
- 第三步创建 StateGraph 图结构并添加节点;
- 第四步配置固定边与条件边;
- 第五步编译图、调用执行并测试效果。
只要吃透 LangChain 消息规范、理解三种消息类型的生成逻辑,就能轻松完成节点与流程设计,多实操几次就能熟练掌握 LangGraph 图示化系统的搭建思路。
代码实现
步骤 1:准备工作,定义聊天模型和搜索工具
python
# 步骤 1: 定义工具和模型
from langchain.chat_models import init_chat_model
from langchain_tavily import TavilySearch
search = TavilySearch(max_results=4)
tools = [search]
# 绑定工具
model = init_chat_model("gpt-4o-mini", temperature=0)
model_with_tools = model.bind_tools(tools)步骤 2:定义状态
python
# 步骤 2: 定义状态
from langchain.messages import AnyMessage
from typing_extensions import TypedDict, Annotated
import operator
class MessagesState(TypedDict):
# 类型: list[AnyMessage] - 任意消息对象的列表
# 合并策略: operator.add - 使用加法操作符进行状态合并
# 效果: 当状态更新时,新的消息会追加到现有列表中,而不是替换
messages: Annotated[list[AnyMessage], operator.add]
# 类型: int - 整数值
# 用途: 跟踪LLM(大语言模型)的调用次数
llm_calls: int步骤 3:定义模型节点
由于节点不需要返回整个状态模式,只需一个更新。且 operator.add 表示新消息会追加到列表中,而不是替换。因此模型节点代码如下:
python
# 步骤 3: 定义模型节点
from langchain.messages import SystemMessage
def llm_call(state: dict):
"""
LLM决定是否调用工具的函数节点
这个函数是LangGraph工作流中的一个节点,负责:
1. 接收当前状态(包含对话历史)
2. 调用绑定了工具的LLM模型
3. 让模型决定是否需要使用工具来回答用户问题
4. 返回更新后的状态
Args:
state (dict): 当前的工作流状态,包含以下键:
- "messages": 对话历史消息列表
- "llm_calls": 记录LLM被调用的次数(可选)
Returns:
dict: 更新后的状态,包含:
- "messages": 添加了LLM响应后的消息列表
- "llm_calls": 调用次数加1后的计数
"""
# 调用绑定了工具的LLM模型
# model_with_tools 是在之前步骤中创建的、绑定了工具列表的模型实例
# invoke() 方法会执行模型推理,让模型分析当前对话并决定:
# - 如果需要额外信息,模型会生成一个工具调用请求
# - 如果可以直接回答,模型会生成文本回复
response = model_with_tools.invoke(
# 构建输入消息列表,按照 LangChain 的标准格式
[
# 系统消息:设置模型的角色和行为准则
# 这个SystemMessage会告诉模型它的身份和可以使用的工具
SystemMessage(
content="你是一个乐于助人的助手,支持调用工具进行搜索。"
# 可以在这里添加更多系统指令,比如:
# - "搜索时请优先使用中文关键词"
# - "如果没有找到相关信息,请诚实告知用户"
)
]
# 加上当前的对话历史
# state["messages"] 包含了用户和助手之间的所有历史对话
# 这些消息的类型可能是:HumanMessage(用户)、AIMessage(助手)、ToolMessage(工具结果)
+ state["messages"]
)
# 返回更新后的状态
return {
# 更新消息列表:将LLM生成的响应追加到现有消息列表后面
# 这个响应可能是文本回复,也可能是工具调用请求
"messages": [response], # LangGraph会自动将这条消息与state["messages"]合并
# 更新调用计数器:记录LLM被调用的次数
# state.get('llm_calls', 0) 获取当前的调用次数,如果没有则默认为0
# + 1 表示本次调用增加一次计数
"llm_calls": state.get('llm_calls', 0) + 1
}步骤 4:定义工具节点
要点 1:回顾 AIMessage 消息结构
在学习 LangChain 篇章时,我们便知道当 LLM 需要调用工具时,LLM 输出结果 AIMessage 的结构如下所示:
python
AIMessage(
content='',
additional_kwargs={'refusal': None},
response_metadata={
...
},
id='lc_run--30b6a3d7-1bd0-4093-8a36-9b43bea458fc-0',
tool_calls=[
{
'name': 'tavily_search',
'args': {
'query': '西安天气',
'search_depth': 'basic'
},
'id': 'call_XAa0MF8j9YQp6FK28tqIvpB',
'type': 'tool_call'
}
],
usage_metadata={
...
}
)其中包含一个 tool_calls 属性。此属性包括执行工具所需的一切,包括工具名称和输入参数。有了这些内容,便可以进行工具调用。
要点 2:构造 ToolMessage
仅仅成功调用工具还不行,我们需要将工具的返回构造成 ToolMessage,再传输给聊天模型。才能给我们返回真正需要的答案:
- 将工具输出传递给聊天模型,包括
HumanMessage、AIMessage(工具调用)、ToolMessage - 聊天模型根据以上消息列表的输入,将最终结果
AIMessage返回。
可以使用下面这种方式定义 ToolMessage:
python
# ToolMessage 的创建和使用示例
# 导入必要的类
from langchain_core.messages import ToolMessage
# 创建 ToolMessage 对象
tool_message = ToolMessage(
content=工具的返回, # 工具执行后返回的结果内容
tool_call_id=tool_calls[n]["id"] # 对应工具调用的唯一标识符
)要点 3:在 State 中访问 messages
由于 LangChain 允许传输下面这种格式的消息:
python
{
"messages": [
{
"type": "human",
"content": "message"
}
]
}但 State 中对于 message 的更新,总是会反序列化为 LangChain Message 格式!如将上述格式反序列化为下面这种格式:
python
{
"messages": [
HumanMessage(content="message")
]
}因此,应该使用点表示法来访问消息属性,例如要访问 AIMessage 中的 tool_calls 属性时,应使用 state["messages"][-1].tool_calls 来获取。
因此,定义工具节点完整代码如下:
python
# 步骤 4: 定义工具节点
from langchain.messages import ToolMessage
# 创建一个字典,将工具名称映射到工具对象本身
# 这样可以快速根据工具名称找到对应的工具实例
# 格式:{"工具名称1": 工具对象1, "工具名称2": 工具对象2, ...}
# 例如:{"tavily_search": TavilySearch对象, "calculator": Calculator对象}
tools_by_name = {tool.name: tool for tool in tools}
def tool_node(state: dict):
"""
执行工具调用的节点函数
这个函数负责:
1. 从状态中提取LLM请求的工具调用信息
2. 根据工具名称找到对应的工具实例
3. 执行工具并获取执行结果
4. 将结果包装成ToolMessage格式返回
工作流程:
LLM节点 → 生成tool_calls → 工具节点 → 执行工具 → 返回ToolMessage → 回到LLM节点
Args:
state (dict): 当前的工作流状态,必须包含:
- "messages": 消息列表,最后一条消息应该是包含tool_calls的AIMessage
- AIMessage.tool_calls: 包含多个工具调用请求的列表
Returns:
dict: 更新后的状态,包含:
- "messages": ToolMessage列表,每个ToolMessage对应一个工具执行结果
Example:
输入state示例:
{
"messages": [
AIMessage(
content="",
tool_calls=[
{
"id": "call_123",
"name": "tavily_search",
"args": {"query": "人工智能新闻"}
},
{
"id": "call_456",
"name": "calculator",
"args": {"expression": "100 * 0.15"}
}
]
)
]
}
输出state示例:
{
"messages": [
ToolMessage(content="搜索到的新闻内容...", tool_call_id="call_123"),
ToolMessage(content="15.0", tool_call_id="call_456")
]
}
"""
# 初始化结果列表,用于存储所有工具执行的结果
# 每个结果都会被包装成一个ToolMessage对象
result = []
# 获取最后一条消息(应该是包含tool_calls的AIMessage)
# state["messages"][-1] 访问消息列表的最后一项
last_message = state["messages"][-1]
# 遍历LLM请求中的所有工具调用
# last_message.tool_calls 是一个列表,可能包含0个、1个或多个工具调用请求
# 每个tool_call的格式:
# {
# "id": "唯一标识符", # 用于匹配工具调用和结果
# "name": "工具名称", # 对应tools_by_name中的键
# "args": {"参数名": "参数值"} # 传递给工具的参数
# }
for tool_call in last_message.tool_calls:
# 步骤1: 根据工具名称获取对应的工具实例
# tools_by_name[tool_call["name"]] 快速找到工具对象
# 例如:tool_call["name"] = "tavily_search"
# 那么 tool = TavilySearch实例
tool = tools_by_name[tool_call["name"]]
# 步骤2: 执行工具,传入参数
# tool.invoke(tool_call["args"]) 调用工具并传入参数
# 例如:search_tool.invoke({"query": "人工智能新闻"})
# observation 是工具返回的原始结果(字符串、字典或其他格式)
observation = tool.invoke(tool_call["args"])
# 步骤3: 将工具执行结果包装成ToolMessage
# ToolMessage的作用:
# - 标准化工具返回结果的格式
# - 通过tool_call_id将结果与请求关联
# - 让LLM能够理解这是工具的执行结果
tool_message = ToolMessage(
content=observation, # 工具返回的具体内容
tool_call_id=tool_call["id"] # 重要!必须与请求中的id匹配
)
# 步骤4: 将ToolMessage添加到结果列表
result.append(tool_message)
# 返回更新后的状态
# {"messages": result} 会如何处理?
# 在LangGraph中,返回的消息会自动与state中的现有消息合并
# 最终state["messages"]会变成:原来的消息 + result中的ToolMessages
return {"messages": result}步骤 5:构建图,设置节点与边
对于开始逻辑:是当用户进行输入后,直接让 LLM 进行处理。是否需要搜索工具调用,也是通过 LLM 进行判断。因此图的入口点则是 llm_call 节点。
对于结束逻辑:可以根据 LLM 返回的结构判断是否调用工具,来决定我们是应该继续循环还是停止循环:
- 如果 LLM 要调用工具,则进入
tool_node节点进行处理; - 如果 LLM 不要调用工具,则结束。
python
# 步骤 5: 构建图
from langgraph.graph import StateGraph, START, END
from typing import Literal, List
def should_continue(state: MessagesState) -> Literal["tool_node", END]:
"""
条件路由函数:根据LLM的响应决定下一步执行路径
这个函数是LangGraph中的条件边(conditional edge)的核心组件,
它根据当前状态判断工作流应该走向哪个节点。
工作流程:
1. LLM节点执行后,会产生响应(可能包含tool_calls)
2. 这个函数检查LLM的响应
3. 如果LLM请求调用工具 → 路由到工具执行节点
4. 如果LLM直接回答了问题 → 结束流程
Args:
state (MessagesState): 当前工作流状态,包含消息列表
state["messages"] 中的最后一条消息通常是LLM的响应
Returns:
Literal["tool_node", END]: 返回下一个节点的名称
- "tool_node": 表示需要执行工具
- END: 表示流程结束(LangGraph内置常量,表示终止)
Example:
场景1 - 需要工具:
state["messages"][-1] = AIMessage(
tool_calls=[{"name": "search", "args": {...}}]
)
→ 返回 "tool_node"
场景2 - 不需要工具:
state["messages"][-1] = AIMessage(content="这是最终答案")
→ 返回 END
"""
# 从状态中获取消息列表
messages = state["messages"]
# 获取最后一条消息(应该是LLM节点的响应)
# 在LangGraph中,节点返回的消息会自动追加到消息列表末尾
last_message = messages[-1]
# 检查LLM是否请求调用工具
# tool_calls 属性在AIMessage中定义,当LLM绑定了工具并决定使用时,
# 这个属性会包含一个列表,每个元素是一个工具调用请求
# 格式示例:
# last_message.tool_calls = [
# {
# "id": "call_abc123",
# "name": "tavily_search",
# "args": {"query": "人工智能新闻"}
# }
# ]
if last_message.tool_calls:
# 如果LLM请求使用工具,则路由到工具节点
# 工具节点会执行这些工具调用并返回结果
return "tool_node"
# 如果LLM没有请求工具(即直接生成了答案),则结束流程
# END 是LangGraph内置常量,表示工作流终止
return END
# 创建状态图构建器
# StateGraph 是LangGraph的核心类,用于定义状态机的工作流
# 泛型参数 MessagesState 指定了状态的数据结构
agent_builder = StateGraph(MessagesState)
# ===== 添加节点 =====
# 节点是工作流中的处理单元,每个节点都是一个可调用对象(函数)
# 节点接收当前状态,返回更新后的状态
# 添加LLM调用节点
# 这个节点负责调用大语言模型,决定是否需要工具
agent_builder.add_node("llm_call", llm_call)
# 添加工具执行节点
# 这个节点负责执行LLM请求的工具调用
agent_builder.add_node("tool_node", tool_node)
# ===== 定义流程边 =====
# 1. 添加起始边
# START 是LangGraph内置常量,表示工作流的入口点
# 从START连接到"llm_call"节点,意味着工作流开始时自动执行llm_call
agent_builder.add_edge(START, "llm_call")
# 2. 添加条件边(最重要的部分)
# 条件边允许根据状态动态决定下一个节点,实现循环和控制流
agent_builder.add_conditional_edges(
# 参数1: source (源节点)
# 指定从哪个节点出发,这里是从"llm_call"节点出发
"llm_call",
# 参数2: path (路由函数)
# 指定用于判断下一个节点的函数
# should_continue 函数会检查LLM响应,返回下一个节点的名称
should_continue,
# 参数3: path_map (路径映射,可选)
# 明确指定路由函数可能返回的所有节点名称
# 这有助于类型检查和错误验证,不是必须的,但推荐提供
[
"tool_node", # 如果需要执行工具,路由到这个节点
END # 如果已完成,路由到结束
]
)
# 3. 添加普通边
# 从工具节点连接回LLM节点,形成循环
# 工作流程:LLM → 工具 → LLM → (可能再次工具) → 最终结束
agent_builder.add_edge("tool_node", "llm_call")
# 这条边的作用:
# - 工具节点执行完毕后,将结果(ToolMessages)返回给LLM
# - LLM会理解工具结果,然后决定:
# a) 如果信息足够,生成最终答案(不再调用工具)
# b) 如果还需要更多信息,继续调用其他工具
# ===== 编译图 =====
# compile() 方法将图定义转换为可执行的工作流
# 编译过程会进行验证:
# - 检查所有节点是否都已添加
# - 检查边是否形成有效的路径
# - 确保没有孤立节点
# - 验证条件边的返回值有效
agent = agent_builder.compile()
# 编译后得到的 agent 是一个可调用对象,可以:
# - agent.invoke(state) - 同步执行整个工作流
# - agent.stream(state) - 流式执行,逐步返回结果
# - agent.ainvoke(state) - 异步执行步骤 6:可视化图
我们可以通过 Mermaid 图表,来展示出 Graph 效果。Mermaid 是一种使用文本生成流程图、饼状图、甘特图等图表的描述语言,它可以帮助用户以简单、直观的方式创建各种类型的图表,包括流程图、时序图、甘特图等。Mermaid 在线绘图工具:https://www.yyshare.com/front-end/9729/
使用姿势:
- LangGraph 中,编译后的图提供了获取 Graph 可绘制表示的方法:
get_graph(),其参数xray=True或xray=1,表示显示详细视图。 - 再通过
draw_mermaid_png(),将图形转换为 Mermaid 格式并生成 PNG 图片的二进制数据。 - 最后需要导入
matplotlib库用于图像显示。
代码如下:
python
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
# 生成 Mermaid 图表并保存为图片
mermaid_code = agent.get_graph(xray=True).draw_mermaid_png()
# 保存文件
with open("./jpg/graph1.jpg", "wb") as f:
f.write(mermaid_code)
# 使用 matplotlib 显示图像
img = mpimg.imread("./jpg/graph1.jpg")
plt.imshow(img) # 显示图片
plt.axis('off') # 关闭坐标轴
plt.show() # 弹出窗口显示图片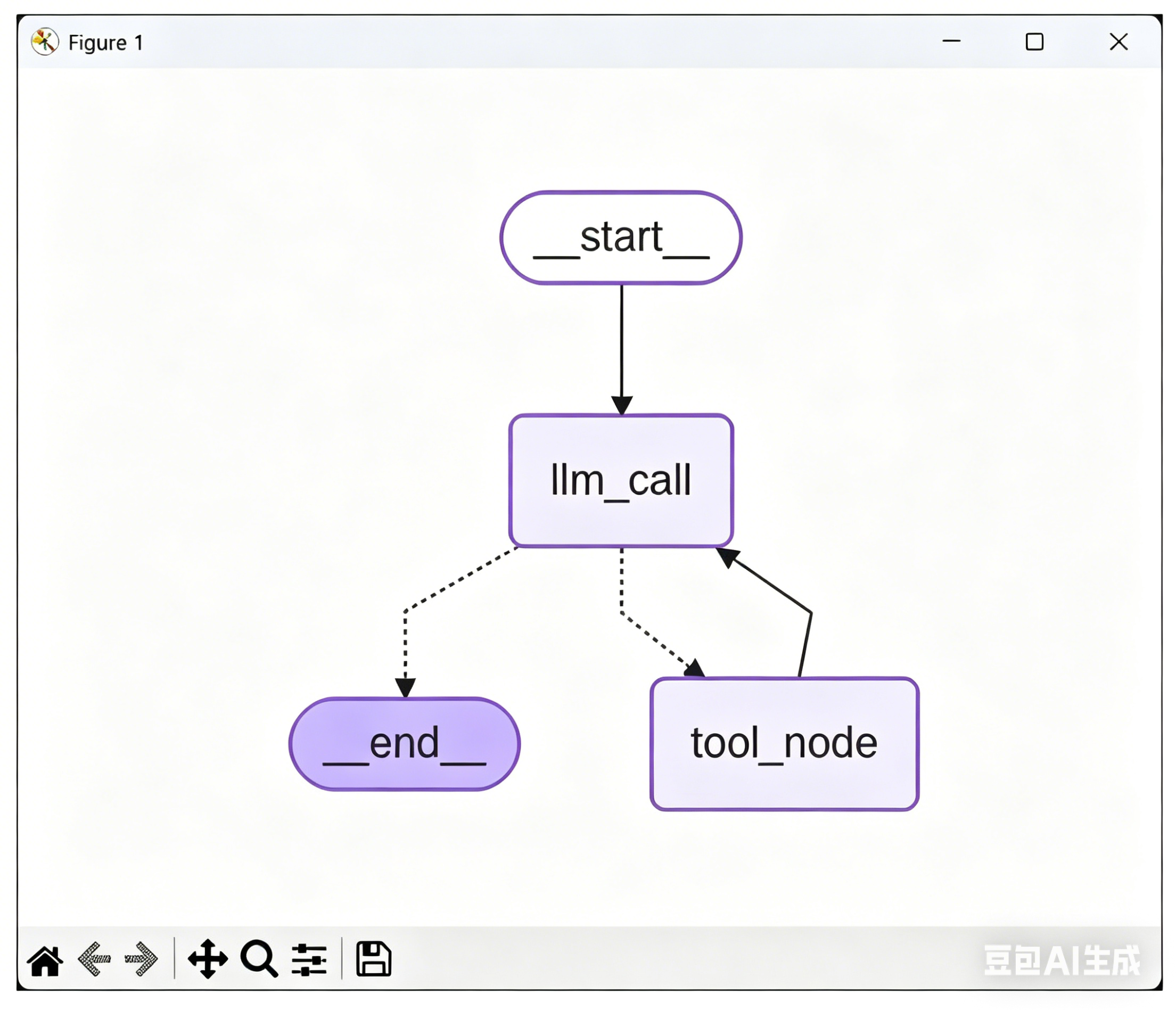
步骤 7:执行(非流式与流式)
- 使用
invoke()方法进行非流式执行:
python
from langchain.messages import HumanMessage
messages = agent.invoke({
"messages": [
HumanMessage(content="今天西安的天气如何? ")
]
})
print(f"调用 LLM 总次数: {messages['llm_calls']}次")
for m in messages["messages"]:
m.pretty_print()运行结果:
python
调用 LLM 总次数: 2次
======================= Human Message =======================
今天西安的天气如何?
======================= Ai Message =======================
Tool Calls:
tavily_search (call_6LQafbVZn9qCzWix40b3auPI)
Call ID: call_6LQafbVZn9qCzWix40b3auPI
Args:
query: 西安天气
time_range: day
======================= Tool Message =======================
{'query': '西安天气', 'follow_up_questions': None, 'answer': None, 'images': [], 'results': [{'url': 'https://feeds-drcn.cloud.huawei.com.cn/landingpage/latest?docid=10512921993454170538700817&to_app=hwbrowser&dy_scenario=relate&tn=8f7efc36ddc74442b888d848e6ae3f3b32b722a839fa5de71583e48ad5dc75fb&channel=HW_JINGXUAN_ZH&ctype=news&cpid=666&r=CN&emuiVer=27', 'title': '陕西省西安市今日天气(11月26日)', 'content': '今晨6时,西安晴,气温0℃,东北风3-4级,相对湿度88%。 预计,今天白天多云,最高气温13.7℃,微风,今天夜间晴,最低气温-1.1℃,微风。 ', 'score': 0.826278, 'raw_content': None}, {'url': 'https://weather.cma.cn/web/weather/V8870.html', 'title': '西安 - 中国气象局-天气预报-城市预报', 'content': '13℃ 2℃ 12℃ 12℃ 12℃ 2℃ 1℃ | 气温 | 13℃ | 5.3℃ | 4℃ | 2.6℃ | 3.5℃ | 10.5℃ | 10.5℃ | 12.2℃ | | 气温 | 10.5℃ | 10.5℃ | 12.2℃ | 10.4℃ | 7.6℃ | 5.5℃ | 4.4℃ | 3.3℃ | | 气温 | 2℃ | 10.2℃ | 11℃ | 11.8℃ | 5.4℃ | 5.2℃ | 4.9℃ | 4.3℃ | | 气温 | 8.3℃ | 16.6℃ | 16.8℃ | 12.8℃ | 8.6℃ | 7.4℃ | 4℃ | 4.3℃ | | 气温 | 4.5℃ | 11℃ | 12℃ | 11.2℃ | 5.9℃ | 5℃ | 3.4℃ | 3.1℃ | | 气温 | 2.2℃ | 7.6℃ | 10.6℃ | 9.6℃ | 8.5℃ | 5.3℃ | 2.1℃ | 1.6℃ |', 'score': 0.82492816, 'raw_content': None}, {'url': 'https://shaanxi.weather.com.cn/xian/index.shtml', 'title': '西安天气预报 - 陕西', 'content': '城市预报列表(11-26 07:30发布)。西安: 17℃/2℃。长安: 14℃/0℃。临潼: 15℃/', 'score': 0.7265231, 'raw_content': None}, {'url': 'https://weather.yahoo.co.jp/weather/world/CN/57036/', 'title': '西安(シーアン)(中国)の天気 - Yahoo!天気・災害', 'content': '西安(シーアン)(中国)の今日・明日・週間天気予報が確認できます。天気、最低気温、最高気温はもちろん、現地時刻、日の出、日の入り時刻までわかります。', 'score': 0.7060491, 'raw_content': None}], 'response_time': 0.86, 'request_id': '4d571ab8-52b8-4628-94d9-e37c5ae9727f'}
======================= Ai Message =======================
今天西安的天气情况如下:
- **今晨6时**: 晴,气温0℃,东北风3-4级,相对湿度88%。
- **白天气温**: 预计最高气温13.7℃,天气多云,微风。
- **夜间气温**: 预计最低气温-1.1℃,天气晴,微风。
如果需要更详细的信息,可以查看以下链接:
- [陕西省西安市今日天气](https://feeds-drcn.cloud.huawei.com.cn/landingpage/latest?docid=10512921993454170538700817&to_app=hwbrowser&dy_scenario=relate&tn=8f7efc36ddc74442b888d848e6ae3f3b32b722a839fa5de71583e48ad5dc75fb&channel=HW_JINGXUAN_ZH&ctype=news&cpid=666&r=CN&emuiVer=27)
- [中国气象局 - 西安天气预报](https://weather.cma.cn/web/weather/V8870.html)
- [西安天气预报 - 陕西](https://shaanxi.weather.com.cn/xian/index.shtml)- 使用
stream()进行流式输出:
python
from langchain.messages import HumanMessage
for chunk in agent.stream({
"messages": [HumanMessage(content="今天西安的天气如何? ")]
}):
print(chunk)注意,这里的流式,指的是 Graph 执行步骤的流式输出 ,即途径节点的过程。每个节点对 Graph State 的更新值(注:并非是更新后的值),都可以通过这种方式追踪。由此,chunk 类型为 dict:key 代表节点名称;value 代表将更新的 State 值。